
Может ли обучить современный компьютер идентифицировать определенный объект на фотографии
ИНС (искусственные нейросети) – это математическая модель функционирования традиционных для живых организмов нейросетей, которые представляют собой сети нервных клеток. Как и в биологическом аналоге, в искусственных сетях основным элементом выступают нейроны, соединенные между собой и образующие слои, число которых может быть разным в зависимости от сложности нейросети и ее назначения (решаемых задач).
Пожалуй, самая популярная задача нейросетей – распознавание визуальных образов. Сегодня создаются сети, в которых машины способны успешно распознавать символы на бумаге и банковских картах, подписи на официальных документах, детектировать объекты и т.д. Эти функции позволяют существенно облегчить труд человека, а также повысить надежность и точность различных рабочих процессов за счет отсутствия возможности допущения ошибки из-за человеческого фактора.
Применение нейронной сети в распознавании изображений
Работа с изображениями — важная сфера применения технологий Deep Learning. Глобально все изображения со всех камер мира составляют библиотеку неструктурированных данных. Задействовав нейросети, машинное обучение и искусственный интеллект, эти данные структурируют и используют для выполнения различных задач: бытовых, социальных, профессиональных и государственных, в частности, обеспечения безопасности.Основой всех архитектур для видеонаблюдения является анализ, первой фазой которого будет распознавание изображения (объекта). Затем искусственный интеллект с помощью машинного обучения распознает действия и классифицирует их.
Для того чтобы распознать изображение, нейронная сеть должна быть прежде обучена на данных. Это очень похоже на нейронные связи в человеческом мозге — мы обладаем определенными знаниями, видим объект, анализируем его и идентифицируем.
Нейросети требовательны к размеру и качеству датасета, на котором она будет обучаться. Датасет можно загрузить из открытых источников или собрать самостоятельно
На практике означает, что до определённого предела чем больше скрытых слоев в нейронной сети, тем точнее будет распознано изображение. Как это реализуется?
Картинка разбивается на маленькие участки, вплоть до нескольких пикселей, каждый из которых будет входным нейроном. С помощью синапсов сигналы передаются от одного слоя к другому. Во время этого процесса сотни тысяч нейронов с миллионами параметров сравнивают полученные сигналы с уже обработанными данными.
Проще говоря, если мы просим машину распознать фотографию кошки, мы разобьем фото на маленькие кусочки и будем сравнивать эти слои с миллионами уже имеющихся изображений кошек, значения признаков которых сеть выучила.
В какой-то момент увеличение числа слоёв приводит к просто запоминанию выборки, а не обучению. Далее - за счёт хитрых архитектур.
Как нейросеть решает задачи по распознаванию образов
Нейронная сеть для распознавания изображений – это, пожалуй, наиболее популярный способ применения НС. При этом вне зависимости от особенностей решаемых задач, она работает по этапам, наиболее важные среди которых рассмотрим ниже.
В качестве распознаваемых образов могут выступать самые разные объекты, включая изображения, рукописный или печатный текст, звуки и многое другое. При обучении сети ей предлагаются различные образцы с меткой того, к какому именно типу их можно отнести. В качестве образца применяется вектор значений признаков, а совокупность признаков в этих условиях должна позволить однозначно определить, с каким классом образов имеет дело НС.
Важно при обучении научить сеть определять не только достаточное количество и значения признаков, чтобы выдавать хорошую точность на новых изображениях, но и не переобучиться, то есть, излишне не «подстроиться» под обучающую выборку из изображений. После завершения правильного обучения НС должна уметь определять образы (тех же классов), с которыми она не имела дела в процессе обучения.
Важно учитывать, что исходные данные для нейросети должны быть однозначны и непротиворечивы, чтобы не возникали ситуации, когда НС будет выдавать высокие вероятности принадлежности одного объекта к нескольким классам.
В целом создание нейронной сети для распознавания изображений включает в себя:
Мультиканальное вовлечение граждан
Повсеместное использование аналитики
Создание множества независимых систем по учету трудовых ресурсов в каждом регионе
Цифровая идентификация граждан +
Мультиканальное вовлечение граждан
Рабочая сила в цифровом формате
Уменьшение количества использования аналитических отчетах на всех этапах государственного управления
Цифровая идентификация граждан +
Мультиканальное вовлечение граждан
Повсеместное использование аналитики
Рабочая сила в цифровом формате
Создание неизменяющегося подхода для противодействия киберугрозам
Цифровая идентификация граждан +
Всё из перечисленного +
История в медицинской карточке +
Стоимость биржевых инструментов +
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Сильная внутренняя экспертиза команды в области подхода управления с помощью данных +
Хранить данные в бумажном виде в архиве
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Понимать, какой информацией располагает компания, а чего не хватает +
Хранить данные в бумажном виде в архиве
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Определить методы сбора, анализа и интерпретации результатов +
Хранить данные в бумажном виде в архиве
Достаточные знания и компетенции
Профицит квалифицированных кадров
Дефицит квалифицированных кадров +
Достаточные знания и компетенции
Достаточные знания и компетенции
Профицит квалифицированных кадров
Задачи цифровой трансформации общества
Социально значимые задачи +
Основной независимый ресурс наборов открытых государственных данных, на котором собраны и структурированы существующие на сегодня в России наборы данных.+
Открытый ресурс, в который выгружают персональные данные граждан с целью продажи и передачи третьим лицам
В терминологии специалистов – историческое событие, после которого было открыто, что можно использовать данные в управлении процессами (продажи, менеджмент и т.д.)
Аналитическая панель, наглядное представление информации о бизнес-процессах, трендах, зависимостях и других метриках в компактном виде, которое позволяет увидеть значения конкретных показателей и динамику их изменений
Способ защиты данных с помощью визуальных решений
Создание информационных систем, создание отчетов, обеспечение финансирования
Накопление данных, анализ данных, первичную обработку данных
Поиск источников данных, извлечение данных, преобразование данных +
Постановку и решение задач, построение графиков, визуализацию
Поиск аномалий, классификацию, восстановление регрессии
Математическая модель, построенная по принципу сигнальной системы живых организмов.
Приложения, помогающие обучаться, создавать образы и обобщать информацию.
Математическая модель, построенная по принципу организации колоний общественных насекомых.
Всемирная система объединённых компьютерных сетей для хранения, обработки и передачи информации
Математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. +
Мобильные приложения крупных компаний
Платформы, которые охватывают все сферы жизни человека и помогают ему получать услуги от бизнеса и государства дистанционно +
Сайты органов государственной власти
Сервисы, запущенные на современных суперкомпьютерах.
Платформы, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма.
Машинное обучение – одно из направлений Искусственного Интеллекта. Данное направление состоит из методов, которые позволяют делать выводы на основе данных.
Искусственный интеллект – одно из направлений Машинного Обучения. Данное направление занимается имитированием поведения человека.
Искусственный Интеллект и Машинное Обучение – это направления Глубокого обучения нейронных сетей.
Искусственный Интеллект – это алгоритмы, связанные с обучением цифровых нейронных сетей. Машинное обучение - это алгоритмы работы с табличными данными.
Искусственный Интеллект занимается задачами имитации деятельности мозга человека. Машинное обучение – это процесс, в ходе которого обучается Искусственный Интеллект. +

Начинаю серию уроков (мини-курс) о распознавании изображений и обнаружении объектов.
Мини-курс, который я пишу, будет состоять из 8 уроков по приблизительно следующей тематике:
- Распознавание изображений с использованием традиционных методов компьютерного зрения
- Обнаружение объектов с использованием традиционных методов компьютерного зрения
- Как обучить и протестировать собственный детектор объектов OpenCV
- Распознавание изображений с использованием глубокого обучения
Краткая история распознавания изображений и обнаружения объектов
При таком огромном успехе в распознавании изображений обнаружение объектов на основе глубокого обучения было неизбежным. Такие методы, как Faster R-CNN, производят челюсти. Отбрасывание результатов по нескольким классам объектов. Мы узнаем об этом в следующих публикациях, но пока имейте в виду, что если вы не изучили алгоритмы распознавания изображений и обнаружения объектов на основе глубокого обучения для своих приложений, вы можете упустить огромную возможность получить лучшие результаты.
Распознавание изображений (также известное как классификация изображений)
Чтобы упростить задачу, в этом посте мы сосредоточимся только на двухклассовых (бинарных) классификаторах. Вы можете подумать, что это очень ограничивающее предположение, но имейте в виду, что многие популярные детекторы объектов (например, детектор лиц и детектор пешеходов) имеют под капотом бинарный классификатор. Например, внутри детектора лиц находится классификатор изображений, который сообщает, является ли участок изображения лицом или фоном.
Анатомия классификатора изображений

На следующей диаграмме показаны этапы работы традиционного классификатора изображений.
Интересно, что многие традиционные алгоритмы классификации изображений компьютерного зрения следуют этому конвейеру, в то время как алгоритмы, основанные на глубоком обучении, полностью обходят этап извлечения признаков. Давайте рассмотрим эти шаги более подробно.
Шаг 1: предварительная обработка
Обратите внимание, что я не прописываю, какие шаги предварительной обработки являются хорошими. Причина в том, что никто заранее не знает, какой из этих шагов предварительной обработки даст хорошие результаты. Вы пробуете несколько разных, и некоторые из них могут дать немного лучшие результаты. Вот абзац из Далала и Триггса
Мы оценили несколько представлений входных пикселей, включая цветовые пространства в оттенках серого, RGB и LAB, опционально со степенным (гамма) выравниванием. Эти нормализации имеют лишь умеренное влияние на производительность, возможно, потому, что последующая нормализация дескриптора дает аналогичные результаты. Мы используем информацию о цвете, когда она доступна. Цветовые пространства RGB и LAB дают сравнимые результаты, но ограничение оттенками серого снижает производительность на 1,5% при 10–4 кадрах в секунду. Гамма-сжатие с квадратным корнем для каждого цветового канала улучшает производительность при низких значениях FPPW (на 1% при 10–4 кадрах в секунду), но логарифмическое сжатие слишком велико и ухудшает его на 2% при 10–4 кадрах в секунду.
Как вы видете, авторы не знали заранее, какую предварительную обработку использовать. Они делали разумные предположения и использовали метод проб и ошибок.
В рамках предварительной обработки входное изображение или фрагмент изображения также обрезаются и изменяются до фиксированного размера. Это важно, потому что следующий шаг, извлечение признаков, выполняется на изображении фиксированного размера.
Шаг 2: извлечение признаков
В качестве конкретного примера давайте посмотрим на извлечение признаков с помощью гистограммы ориентированных градиентов (HOG).
Histogram of Oriented Gradients (HOG) или гистограмма направленного градиента
Алгоритм извлечения признаков преобразует изображение фиксированного размера в вектор признаков фиксированного размера. В случае обнаружения пешеходов дескриптор объекта HOG вычисляется для фрагмента изображения размером 64 \times 128 и возвращает вектор размером 3780 . Обратите внимание, что исходный размер этого фрагмента изображения был 64 \times 128 \times 3 = 24,576 , который сокращен до 3780 дескриптором HOG.
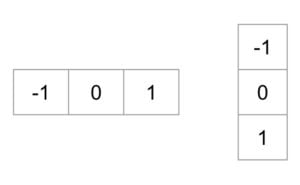
HOG основан на идее, что внешний вид локального объекта может быть эффективно описан распределением (гистограммой) направлений краев (направленных градиентов). Шаги по вычислению дескриптора HOG для изображения размером 64 × 128 перечислены ниже.
Расчет градиента: вычисление градиентов x и y изображений и, исходя из исходного изображения. Это можно сделать, отфильтровав исходное изображение следующими ядрами.
-
Используя изображения градиента и, можно вычислить величины g_x и g_y направления градиента, используя следующие уравнения:
Шаг 3: алгоритм классификации (подробнее)
В предыдущем разделе мы узнали, как преобразовать изображение в вектор признаков. В этом разделе мы узнаем, как алгоритм классификации принимает этот вектор признаков в качестве входных данных и выводит метку класса (например, кошка или фон).
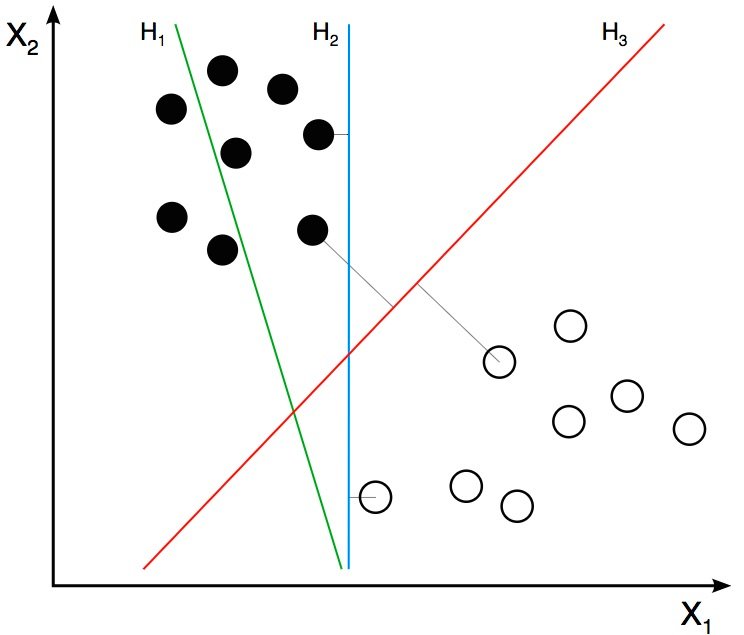
На предыдущем шаге мы узнали, что дескриптор HOG изображения является вектором признаков длиной 3 780. Мы можем думать об этом векторе как о точке в 3 780-мерном пространстве. Визуализировать пространство большого измерения невозможно, поэтому немного упростим ситуацию и представим, что вектор признаков был двухмерным.
Оптимизация SVM
Пока все хорошо, но я знаю, что у вас есть один важный вопрос, на который нет ответа. Что, если объекты, принадлежащие двум классам, нельзя разделить с помощью гиперплоскости? В таких случаях, SVM по-прежнему находит лучшую гиперплоскость, решая задачу оптимизации, которая пытается увеличить расстояние гиперплоскости от двух классов, одновременно пытаясь обеспечить правильную классификацию многих обучающих примеров. Этот компромисс контролируется параметром C. Когда значение C мало, выбирается гиперплоскость с большим запасом за счет большего числа ошибочных классификаций. И наоборот, когда C велико, выбирается гиперплоскость меньшего поля, которая пытается правильно классифицировать гораздо больше примеров.
Теперь вы можете быть сбиты с толку, какое значение выбрать для C. Выберите то значение, которое лучше всего работает на тестовом наборе, которого не было в обучающей выборке.

Распознавание изображений (часть искусственного интеллекта (ИИ)) является еще одной популярной тенденцией, набирающей обороты в настоящее время – к 2021 году ожидается, что ее рынок достигнет почти 39 миллиарда долларов. Теперь пришло время присоединиться к тренду и узнать, что такое распознавание изображений и как оно работает.
Что такое распознавание изображений?
Как всегда, давайте начнем с основ. Прежде всего, вы должны помнить, что распознавание и обработка изображений не являются синонимами. Обработка изображения означает преобразование изображения в цифровую форму и выполнение определенных операций с ним. В результате можно извлечь некоторую информацию из такого изображения.
Этапы обработки изображений:
- Обработка цветного изображения – обработка цветов.
- Улучшение изображения – улучшение качества изображения и извлечение скрытых деталей.
- Восстановление изображения – очистка изображения от пятен и других неприятных вещей.
- Представление и описание – визуализация данных.
- Получение изображения – захват и конвертация изображения.
- Сжатие и распаковка изображений – изменение размера и разрешения изображения.
- Морфологическая обработка – описание структуры объектов изображения.
- Распознавание изображений – выявление особенностей объектов изображения.
Теперь вы видите, что распознавание изображений является одним из этапов обработки изображений. Те специфические особенности, которые были упомянуты, включают людей, места, здания, действия, логотипы и другие возможные переменные на изображениях. Следовательно, распознавание изображений – это процесс идентификации и обнаружения объекта в цифровом изображении и одно из применений компьютерного зрения. Иногда это также называют классификацией изображений, и это применяется в большом количестве отраслей.
Как работает распознавание изображений?
Теперь несколько слов о том, как работает распознавание изображений. Первым шагом здесь является сбор и организация данных. В отличие от людей, компьютеры воспринимают изображение как векторное или растровое изображение.

Поэтому после создания конструкций, изображающих объекты и особенности изображения, компьютер анализирует их. Затем данные упорядочиваются – важная информация извлекается, а ненужная исключается. Вторым этапом процесса распознавания изображений является построение прогнозирующей модели. Алгоритм классификации должен быть тщательно обучен, иначе он не сможет выполнять свои функции. Когда все сделано и протестировано, вы можете пользоваться функцией распознавания изображений.
Как ИИ помогает распознавать изображения?
Искусственный интеллект делает возможными все функции распознавания изображений. Чтобы дать вам лучшее понимание, вот некоторые из них:
1. Распознавание лиц.
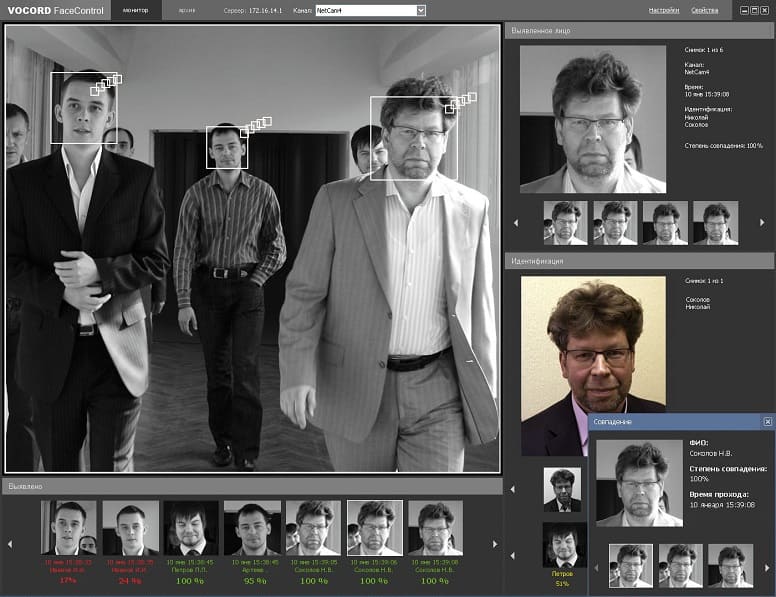
С помощью ИИ система распознавания лиц сопоставляет черты лица с изображения, а затем сравнивает эту информацию с базой данных, чтобы найти совпадение. Распознавание лиц используется производителями мобильных телефонов (как способ разблокировки смартфона), социальными сетями (распознавание людей на изображении, которое вы загружаете, и их пометка), и т.д. Тем не менее, такие системы вызывают много проблем конфиденциальности, так как иногда данные могут быть собраны без разрешения пользователя. Кроме того, даже самые передовые системы не могут гарантировать 100% точность. Что если система распознавания лиц смешивает случайного пользователя с преступником? Это не то, чего кто-то хочет, но это все еще возможно. Однако технологии постоянно развиваются поэтому однажды эта проблема может исчезнуть.
2. Распознавание объектов.

Системы распознавания объектов выбирают и идентифицируют объекты из загруженных изображений (или видео). Визуальный поиск, вероятно, является наиболее популярным приложением этой технологии.
3. Распознавание образов.

Распознавание образов означает поиск и извлечение определенных рисунков в заданном изображении. Это могут быть текстуры, выражения лица и т.д.
4. Анализ изображения.

Вам нужно краткое изложение конкретного изображения? Используйте ИИ для анализа изображений. В результате все объекты изображения (формы, цвета и т. д.) будут проанализированы, и вы получите полезную информацию об изображении.
Распознавание объектов — это метод компьютерного зрения для идентификации объектов на изображениях или видео. Распознавание объектов является основным результатом алгоритмов глубокого и машинного обучения. При просмотре фотографий или видео, человек может легко распознать людей, предметы, сцены и визуальные детали. Цель состоит в обучении компьютера делать то, что естественно для людей: достичь уровня понимания того, что содержит изображение.

Изображение 1. Использование распознавания объектов для идентификации различных категорий объектов.
Распознавание объектов является важной технологией беспилотных автомобилей, позволяющая им распознавать знаки остановок или отличать пешехода от фонарного столба. Он также полезен в различных приложениях, таких как идентификация заболеваний в биовизуализации, промышленном контроле и роботизированном зрении.
Распознавание объектов и обнаружение объектов
Обнаружение объектов и распознавание объектов являются схожими методами для идентификации объектов, но они различаются по своему исполнению. Обнаружение объектов — это процесс обнаружения экземпляров объектов на изображениях. В случае глубокого обучения методы обнаружения объектов — это подмножество методов распознавания объектов, когда объект не только идентифицируется, но и располагается на изображении. Это позволяет идентифицировать несколько объектов и размещать их на одном изображении.

Изображение 2. Распознавание объектов (слева) и обнаружение объектов (справа).
Как работает распознавание объектов
Возможно использование различных подходов для распознавания объектов. В последнее время методы машинного и глубокого обучения стали популярными подходами к проблемам распознавания объектов. Обе технологии учатся распознавать объекты на изображениях, но они различаются по своему исполнению.

Изображение 3. Методы машинного обучения и глубокого обучения для распознавания объектов.
В следующем разделе объясняются различия между машинным обучением и глубоким обучением для распознавания объектов и показано, как реализовать оба подхода.
Методы распознавания объектов
Распознавание объектов с использованием глубокого обучения
Методы глубокого обучения стали популярным методом распознавания объектов. Модели глубокого обучения, такие как сверточные нейронные сети (или CNN), используются для автоматического изучения присущих объекту свойств, чтобы идентифицировать этот объект. Например, CNN может научиться определять различия между кошками и собаками, анализируя тысячи изображений и изучая характеристики, различающие кошек и собак.
Существует два подхода к распознаванию объектов с использованием глубокого обучения:
- Обучение модели с нуля. Чтобы обучить глубокую сеть с нуля, необходимо собирать очень большой размеченный набор данных и разработать архитектуру сети, которая будет изучать характеристики и строить модель. Результаты могут быть впечатляющими, но этот подход требует большого количества обучающих данных, а также необходимо настраивать уровни и веса в CNN.
- Использование предварительно обученной модели глубокого обучения: большинство приложений глубокого обучения используют подход трансферного обучения – процесс, который включает в себя точную настройку предварительно обученной модели. Для начала берется существующая сеть, такая как AlexNet или GoogLeNet, и вводятся новые данные, содержащие ранее неизвестные классы. Этот метод требует меньше времени и может обеспечить более быстрый результат, поскольку модель уже обучена на тысячах или миллионах изображений.
Глубокое обучение предлагает высокий уровень точности, но требует большого количества данных для точных прогнозов.

Изображение 4: Приложение глубокого обучения, демонстрирующее распознавание объектов ресторанной еды.
Распознавание объектов с помощью машинного обучения
Методы машинного обучения также популярны для распознавания объектов и предлагают отличные от глубокого обучения подходы. Распространенные примеры методов машинного обучения являются:
- извлечение функций HOG с помощью модели машинного обучения SVM;
- модели «мешков слов» (bag-of-words) с такими функциями, как SURF и MSER;
- алгоритм Виолы-Джонса, который можно использовать для распознавания различных объектов, включая лица и верхнюю часть тела.
Процесс машинного обучения
Для распознавания объектов с использованием стандартного подхода машинного обучения необходимо начать с набора изображений (или видео) и выбрать соответствующие характеристика в каждом изображении. Например, алгоритм извлечения элементов может извлекать элементы ребер или углов, которые можно использовать для различения классов в пользовательских данных.
Эти функции добавляются в модель машинного обучения, которая разделяет эти характеристики на отдельные категории, а затем использует эту информацию при анализе и классификации новых объектов.
Вы можете использовать различные алгоритмы машинного обучения и методы извлечения признаков, которые предлагают множество комбинаций для создания точной модели распознавания объектов.

Изображение 5: Рабочий процесс машинного обучения для распознавания объектов.
Использование машинного обучения для распознавания объектов дает гибкость в выборе наилучшего сочетания функций и классификаторов для обучения. Он может достичь точных результатов с минимальными данными.
Машинное обучение и глубокое обучение для распознавания объектов
Выбор наилучшего подхода к распознаванию объектов зависит от поставленной задачи. В большинстве случаев машинное обучение может быть эффективным методом, особенно если известно, какие характеристики изображения лучше всего использовать для различения классов объектов.
Главное, о чем следует помнить при выборе между машинным и глубоким обучением, - это наличие у мощного графического процессора и множества размеченных обучающих изображений. Если ответ на любой из этих вопросов отрицательный, подход машинного обучения может быть лучшим выбором. Методы глубокого обучения, как правило, лучше работают с большим количеством изображений, а графический процессор помогает сократить время, необходимое для обучения модели.

Изображение 6. Ключевые факторы выбора между глубоким обучением и машинным обучением.
Другие методы распознавания объектов
В зависимости от задачи может быть достаточно других, более простых подходов к распознаванию объектов:
- сопоставление с шаблоном, при котором используется небольшое изображение или шаблон для поиска совпадающих областей на большом изображении.
- сегментация изображений и анализ BLOB-объектов, при котором используются простые свойства объекта, такие как размер, цвет или форма.
Как правило, если объект можно распознать с помощью простого подхода, такого как сегментация изображения, лучше всего начать с более простого подхода. Это может обеспечить надежное решение, которое не требует сотен или тысяч обучающих изображений или чрезмерно сложного решения.
Распознавание объектов с помощью MATLAB
Глубокое обучение и машинное обучение
С помощью всего нескольких строк кода MATLAB® возможно создавать модели машинного и глубокого обучения для распознавания объектов, не будучи экспертом.
Использование MATLAB для распознавания объектов позволяет добиться успеха за меньшее время, поскольку позволяет:
- использовать свой опыт в предметной области и изучать науку о данных с MATLAB:
Вы можете использовать MATLAB, чтобы учиться и получать опыт в области машинного и глубокого обучения. MATLAB делает изучение этих областей практичным и доступным. Кроме того, MATLAB позволяет экспертам в предметной области создавать модели распознавания объектов вместо того, чтобы передавать задачу специалистам по данным, которые могут не знать отрасль или задачу.
- использовать приложения для разметки данных и построения моделей:
MATLAB позволяет создавать модели машинного и глубокого обучения с минимальным кодом.
С помощью приложения Classification Learner можно быстро создавать модели машинного обучения и сравнивать различные алгоритмы машинного обучения без написания кода.
Используя приложение Image Labeler, можно интерактивно размечать объекты на изображениях и автоматизировать разметку в видеороликах для обучения и тестирования моделей глубокого обучения. Этот интерактивный и автоматизированный подход может привести к лучшим результатам за меньшее время.
- объединять распознавание объектов в единый процесс:
MATLAB может объединить несколько операций в один рабочий процесс. С MATLAB можно думать и программировать в одной среде. Он предлагает инструменты и функции для глубокого и машинного обучения, а также для ряда областей, которые используются в этих алгоритмах, таких как робототехника, компьютерное зрение и аналитика данных.
MATLAB автоматизирует развертывание моделей в корпоративных системах, кластерах, облаках и встроенных устройствах.
Читайте также: