
Конец файла не в конце строки вставлен символ новой строки
Как убрать символ новой строки (\n) при чтении строк из файла pascal>
Здравствуйте, дорогие программисты! Помогите сделать программу, которая будет считывать текст из.
Непонятный символ в конце строки при чтении файла
всем привет) подскажите, пожалуйста:) когда я считываю строку из файла(txt), то в конце появляется.
Как отступить символ при чтении файла? Как перейти на следующую строку?
использую библиотеку fstream. у меня два вопроса: первый: как отступить символ при чтении из.
Выведите строку в MessageBox-е например. а разве не "\r\n" нужно использовать в Windows?
"\\n" это видимо уже студия экранирует (смотрите в дебаггере?)
вот эта часть кода отвечает за чтение из файла. Как не трудно заметить, то тут и можно при помощи дебагера заметить экранацию.
Добавлено через 1 минуту
при выводе через MessageBox выводит строку, которая уже экранированная
Добавлено через 1 минуту
"\\n" это видимо уже студия экранирует (смотрите в дебаггере?) я специально у файле вставляю "\n", чтобы вставить в контрол перевод строки xunicorn, как ты вставляешь?
и опять же, повторюсь - не "\n" а "\r\n" xunicorn, как ты вставляешь?
и опять же, повторюсь - не "\n" а "\r\n" я не пишу из потока у файл, а наоборот - из файла у поток.
ЗЫ: все равно ничего не вышло. xunicorn, еще раз: покажи как вставляешь.
если ты не будешь отвечать на наши вопросы, никто не будет отвечать на твои.
есть строки у файле
"
в наличии \n 248 грн
Видеокарта Asus PCI-E GeForce 210 1024Mb, 64bit, DDR3 (210-SL-TC1GD3-L)\nГарантия: 3 года;
"
я их считываю построчно. Потом эти строки запихиваю например у TextBox. И у меня задача - чтобы текст, который стоит после знака разделителя новой строки писался с новой строки в TextBox-e.
Если вставляю
"
в наличии \r\n 231 грн
Видеокарта Power Color PCI-E Radeon HD5450 1024Mb, 64bit, DDR3 (AX5450 1GBK3-SHV2)\r\nГарантия: 2 года;
"
тоже спецсимволы экранируются, и в TextBox-e выводится
"
в наличии \r\n 231 грн
Видеокарта Power Color PCI-E Radeon HD5450 1024Mb, 64bit, DDR3 (AX5450 1GBK3-SHV2)\r\nГарантия: 2 года;
"
Иногда при просмотре диффов коммитов через git log или git diff можно заметить следующий вывод:
Или на GitHub в интерфейсе для просмотра диффов:
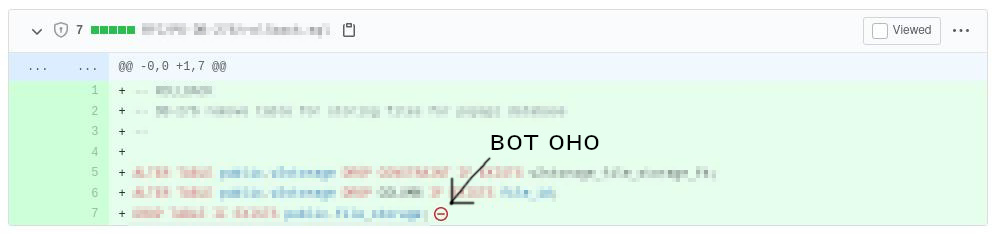
Почему это так важно, что Git и GitHub предупреждают нас об этом? Давайте разберемся.
Что может быть проще, чем текстовый файл? Просто текстовые данные — как хранятся на диске, так и отображаются. На самом деле правительство нам врёт всё немного сложнее.
Оффтопик про управляющие символы ASCII
Не все символы, которые содержатся в текстовых файлах, имеют визуальное представление. Такие символы ещё называют "управляющими", и к ним относятся, например:
- нулевой символ ( x00 , \0 ) — часто используется для кодирования конца строки в памяти; т.е. программа считывает символы из памяти по одному до тех пор, пока не встретит нулевой символ, и тогда строка считается завершённой;
- табуляция ( \x09 , \t ) — используется для выравнивания данных по границе столбца, так что это выглядит как таблица;
- перевод строки ( \x0a , \n ) — используется для разделения текстовых данных на отдельные строки;
- возврат каретки ( \x0d , \r ) — переместить курсор в начало строки;
- возврат на один символ ( \x08 , \b ) — переместить курсор на один символ назад;
- звонок ( \x07 , \a ) — если набрать этот символ в терминале, то будет бибикающий символ; именно так консольные программы, типа vim , бибикают на пользователей; .
Многие эти символы пришли к нам из эпохи печатных машинок, поэтому у них такие странные названия. И действительно, в контексте печатной машинки или принтера такие операции, как перевод строки (сместить лист бумаги вверх так, чтобы печатающая головка попала на следующую строку), возврат каретки (переместить печатающую головку в крайнее левое положение) и возврат на один символ назад, обретают смысл. При помощи возврата на один символ назад создавались жирные символы (печатаешь символ, возвращаешься назад и печатаешь его ещё раз) и буквы с диакритическими знаками, такие как à или ã (печатаешь символ, возвращаешься назад и печатаешь апостроф или тильду). Но зачем печатной машинке бибикалка?
Сегодня многие из этих символов потеряли смысл, но некоторые до сих пор выполняют функцию, схожую с исходной.
Текстовые редакторы отображают текстовые файлы в некоем адаптированном виде, преобразуя непечатаемые символы, например, переносы строк и табуляции преобразуются в настоящие отдельные строки или выравнивающие отступы.
Для набора символа переноса строки достаточно нажать клавишу "Enter", но на разных платформах этот символ закодируется по-разному:
- в Unix-совместимых системах (включая современные версии macOS) используется один символ перевода строки ( LF );
- в Windows используется сразу два символа — возврат каретки ( CR ) и перевод строки ( LF );
- в очень старых версиях Mac OS (до 2001 года) использовался один символ CR .
Как видите, Windows точнее всего эмулирует поведение печатной машинки.
В языках программирования символ новой строки часто кодируют при помощи бэкслэш-последовательностей, таких как \n или \r\n . Нужно понимать разницу между такой последовательностью и настоящим символом переноса строки. Если в редакторе в файле *.txt просто набрать \n и сохранить, то вы получите ровно то, что написали. Символом переноса строки оно не станет. Нужно что-то, что заменит эти бэкслэш-последовательности на настоящие символы переноса строки (например, компилятор или интерпретатор языка программирования).
Согласно определению из стандарта POSIX, который тоже пришёл к нам из эпохи печатных машинок:
Строка — это последовательность из нуля или более символов, не являющихся символом новой строки, и терминирующего символа новой строки.
Почему важен этот стандарт? Возможен миллиард способов реализовать одно и то же, и только благодаря стандартам, таким как POSIX, мы имеем сейчас огромное количество качественного ПО, которое не конфликтует друг с другом.
Т.е. если вы не ставите символ переноса строки в конце строки, то формально по стандарту такая строка не является валидной. Множество утилит из Unix, которыми я пользуюсь каждый день, написано в согласии с этим стандартом, и они просто не могут правильно обрабатывать такие "сломанные" строки.
Давайте, например, через Python создадим такой файл со сломанными строками:
Сколько по-вашему в этом файле строк? Три? Давайте посмотрим, что об этом файле думает утилита wc , которая с флагом -l умеет считать количество строк в файле:
Упс! wc нашла только 2 строки!
Давайте создадим еще один файл:
И попробуем теперь склеить два созданных файла при помощи утилиты cat :
Название cat — это сокращение от "конкатенация", и никак не связано с котиками. А жаль.
И опять какой-то странный результат! В большинстве случаев это не то, чего вы бы ожидали, но вполне возможны ситуации, когда вам нужен именно такой результат. Именно поэтому утилита cat не может самостоятельно вставлять отсутствующие символы переноса строки, иначе это сделало бы её поведение неконсистентным.
Это только пара примеров, но многие другие утилиты, которые работают с текстом (например, diff , grep , sed ), имеют такие же проблемы. Собственно говоря, это даже не проблемы, а их задокументированное поведение.
Ещё доводы:
Самый простой способ перестать думать о пустых строках и начать жить — это настроить свой текстовый редактор или IDE на автоматическое добавление символа переноса строки в конец файлов:
- PyCharm и другие IDE JetBrains: Settings > Editor > General > Ensure an empty line at the end of a file on Save ;
- VS Code: "files.insertFinalNewline": true .
Для других редакторов смотрите настройку здесь.
Возможно, такая маленькая деталь, как перенос строки в конце файла и не кажется очень важной, а тема вообще кажется спорной, но боюсь, что у нас нет другого выбора, кроме как принять это правило за данность и просто выработать привычку (или настроить инструментарий) всегда ставить символ новой строки в любых текстовых файлах, даже если этого не требуется явно. Это считается распространённой хорошей практикой, и как минимум убережёт вас и ваших коллег от всяких неожиданных эффектов при работе с утилитами Unix.
В текстовом редакторе это выглядит как лишняя пустая строка в конце файла:
Недавно я читал книгу «Компьютерные системы: архитектура и программирование. Взгляд программиста». Там, в главе про систему ввода-вывода Unix, авторы упомянули о том, что в конце файла нет особого символа EOF .

Если вы читали о системе ввода-вывода Unix/Linux, или экспериментировали с ней, если писали программы на C, которые читают данные из файлов, то это заявление вам, вероятно, покажется совершенно очевидным. Но давайте поближе присмотримся к следующим двум утверждениям, относящимся к тому, что я нашёл в книге:
- EOF — это не символ.
- В конце файлов нет некоего особого символа.
EOF — это не символ
Почему кто-то говорит или думает, что EOF — это символ? Полагаю, это может быть так из-за того, что в некоторых программах, написанных на C, можно найти код, в котором используется явная проверка на EOF с использованием функций getchar() и getc() .
Это может выглядеть так:
Если заглянуть в справку по getchar() или getc() , можно узнать, что обе функции считывают следующий символ из потока ввода. Вероятно — именно это является причиной возникновения заблуждения о природе EOF . Но это — лишь мои предположения. Вернёмся к мысли о том, что EOF — это не символ.
А что такое, вообще, символ? Символ — это самый маленький компонент текста. «A», «a», «B», «b» — всё это — разные символы. У символа есть числовой код, который в стандарте Unicode называют кодовой точкой. Например — латинская буква «A» имеет, в десятичном представлении, код 65. Это можно быстро проверить, воспользовавшись командной строкой интерпретатора Python:
Или можно взглянуть на таблицу ASCII в Unix/Linux:

Выясним, какой код соответствует EOF , написав небольшую программу на C. В ANSI C константа EOF определена в stdio.h , она является частью стандартной библиотеки. Обычно в эту константу записано -1 . Можете сохранить следующий код в файле printeof.c , скомпилировать его и запустить:
Скомпилируем и запустим программу:
У меня эта программа, проверенная на Mac OS и на Ubuntu, сообщает о том, что EOF равняется -1 . Есть ли какой-нибудь символ с таким кодом? Тут, опять же, можно проверить коды символов в таблице ASCII, можно взглянуть на таблицу Unicode и узнать о том, в каком диапазоне могут находиться коды символов. Мы же поступим иначе: запустим интерпретатор Python и воспользуемся стандартной функцией chr() для того, чтобы она дала бы нам символ, соответствующий коду -1 :
Как и ожидалось, символа с кодом -1 не существует. Значит, в итоге, EOF , и правда, символом не является. Переходим теперь ко второму рассматриваемому утверждению.
В конце файлов нет некоего особого символа
Может, EOF — это особенный символ, который можно обнаружить в конце файла? Полагаю, сейчас вы уже знаете ответ. Но давайте тщательно проверим наше предположение.
Возьмём простой текстовый файл, helloworld.txt, и выведем его содержимое в шестнадцатеричном представлении. Для этого можно воспользоваться командой xxd :
Как видите, последний символ файла имеет код 0a . Из таблицы ASCII можно узнать о том, что этот код соответствует символу nl , то есть — символу новой строки. Это можно выяснить и воспользовавшись Python:
Так. EOF — это не символ, а в конце файлов нет некоего особого символа. Что же такое EOF ?
Что такое EOF?
EOF (end-of-file) — это состояние, которое может быть обнаружено приложением в ситуации, когда операция чтения файла доходит до его конца.
Взглянем на то, как можно обнаруживать состояние EOF в разных языках программирования при чтении текстового файла с использованием высокоуровневых средств ввода-вывода, предоставляемых этими языками. Для этого напишем очень простую версию cat , которая будет называться mcat . Она побайтно (посимвольно) читает ASCII-текст и в явном виде выполняет проверку на EOF . Программу напишем на следующих языках:
- ANSI C
- Python 3
- Go
- JavaScript (Node.js)
ANSI C
Начнём с почтенного C. Представленная здесь программа является модифицированной версией cat из книги «Язык программирования C».
Вот некоторые пояснения, касающиеся вышеприведённого кода:
- Программа открывает файл, переданный ей в виде аргумента командной строки.
- В цикле while осуществляется копирование данных из файла в стандартный поток вывода. Данные копируются побайтово, происходит это до тех пор, пока не будет достигнут конец файла.
- Когда программа доходит до EOF , она закрывает файл и завершает работу.
Python 3
В Python нет механизма явной проверки на EOF , похожего на тот, который имеется в ANSI C. Но если посимвольно читать файл, то можно выявить состояние EOF в том случае, если в переменной, хранящей очередной прочитанный символ, будет пусто:
Запустим программу и взглянём на возвращаемые ей результаты:
Вот более короткая версия этого же примера, написанная на Python 3.8+. Здесь используется оператор := (его называют «оператор walrus» или «моржовый оператор»):
Запустим этот код:
В Go можно явным образом проверить ошибку, возвращённую Read(), на предмет того, не указывает ли она на то, что мы добрались до конца файла:
JavaScript (Node.js)
В среде Node.js нет механизма для явной проверки на EOF . Но, когда при достижении конца файла делается попытка ещё что-то прочитать, вызывается событие потока end.
Низкоуровневые системные механизмы
Как высокоуровневые механизмы ввода-вывода, использованные в вышеприведённых примерах, определяют достижение конца файла? В Linux эти механизмы прямо или косвенно используют системный вызов read(), предоставляемый ядром. Функция (или макрос) getc() из C, например, использует системный вызов read() и возвращает EOF в том случае, если read() указывает на возникновение состояния достижения конца файла. В этом случае read() возвращает 0 . Если изобразить всё это в виде схемы, то получится следующее:

Получается, что функция getc() основана на read() .
Напишем версию cat , названную syscat , используя только системные вызовы Unix. Сделаем мы это не только из интереса, но и из-за того, что это вполне может принести нам какую-то пользу.
Вот эта программа, написанная на C:
В этом коде используется тот факт, что функция read() , указывая на достижение конца файла, возвращает 0 .

В этом уроке мы изучаем различные способы добавления текста в конец файла в Linux.
Каждая операционная система на основе Unix имеет концепцию «места по умолчанию для вывода».
Каждый называет это «стандартный вывод» или «stdout», произносится как standard out.
Ваша оболочка (вероятно, bash или zsh) постоянно следит за местом вывода по умолчанию.
Когда ваша оболочка видит новый вывод, она выводит его на экран, чтобы вы могли его увидеть.
Процедура выглядит следующим образом:
Добавить текст в конец файла с помощью команды echo:
Добавить вывод команды в конец файла:
Добавление строк в конец файла
Мы можем добавить текстовые строки, используя этот символ перенаправления >> или мы можем записать данные и вывод команды в текстовый файл.
Используя этот метод, файл будет создан, если его не существует.
Добавление результата вывода данных команды в конец файла
Вы также можете добавить данные или запустить команду и добавить вывод в нужный файл.
Вы можете использовать любую команду, которая может выводить ее результат на терминал, что означает почти все инструменты командной строки в Linux.
Альтернативные методы
Давайте посмотрим, как добавить что-либо в файл с помощью утилиты tee, awk и sed Linux.
Использование инструмента командной строки tee
Команда Tee читает стандартный ввод и записывает его как в стандартный вывод, так и в один или несколько файлов.
Команда названа в честь Т-разветвителя, используемого в сантехнике.
Он прерывает вывод программы, так что вывод может быть отображен и сохранен в файле.
Использование инструмента командной строки awk
Awk в основном используется для сканирования и обработки шаблонов.
Использование инструмента командной строки sed
Команда Sed в Linux расшифровывается как потоковый редактор (stream editor) и может выполнять множество функций с файлом, таких как поиск, поиск и замена, вставка или удаление.
Используя sed, вы можете редактировать файлы, даже не открывая его, что значительно ускоряет поиск и замену чего-либо в файле.
Добавить несколько строк в файл
Есть несколько способов добавить несколько строк в файл одновременно.
Вы можете, конечно, добавлять строки одну за другой:
Заключение
Есть способы добавить текст к концу определенного номера строки в файле или в середине строки с помощью регулярных выражений, но мы рассмотрим это в другой статье.
Дайте нам знать, какой метод для добавления в конец файла вы считаете лучшим в разделе комментариев.
Делить комментариями и добавляйте статьи в соц. сети, если они вам нравятся!
Читайте также: