
Какие элементы находятся на уровне микроархитектуры современных компьютеров
Используемая вами версия браузера не рекомендована для просмотра этого сайта.
Установите последнюю версию браузера, перейдя по одной из следующих ссылок.
Успевайте делать больше с меньшими затратами
Передовые разработки в микроархитектуре позволяют создавать более компактные и более производительные устройства. Также они являются основой бизнес-модели Intel и ее успеха. Благодаря продуманной конструкции и интеллектуальным процессорным технологиям Intel по-прежнему лидирует в отрасли, разрабатывая еще более портативные транзисторы для создания более энергоэффективных и производительных процессорных ядер.
Что такое микроархитектура?
Микроархитектура — это схема элементов микросхемы. Эта схема, объединенная с передовой нанотехнологией, расширяет возможности вычислительных устройств и повышает их энергоэффективность. Специалисты Intel по микроархитектурам продолжают делать гигантские шаги вперед в области инноваций и не так давно представили первые в мире трехмерные 22-нанометровые транзисторы.
Что нового
Узнайте о преимуществах новой микроархитектуры Intel® (прежнее название — Haswell), которая поддерживает более быстрые и более компактные платформы и обеспечивает улучшенное качество HD-графики, более высокий уровень безопасности, уменьшенное время отклика и превосходную мобильность благодаря автоматической настройке беспроводной связи.
Разработка трехмерной 22-нанометровой микроархитектуры
В соответствии с законом Мура и моделью «Тик-так» корпорация Intel продолжает развивать свои исторические достижения в области микроархитектур, успешно тестируя первый трехмерный 22-нанометровый транзистор и разрабатывая 14-нанометровые технологии следующего поколения.
Представленная в процессорах Intel® Core™ 3-го поколения трехмерная 22-нанометровая микроархитектура Intel® знаменует новый уровень в фундаментальной структуре компьютерных микросхем. До этих пор транзисторы представляли собой исключительно двухмерные (плоские) устройства. В трехмерном транзисторе Intel® используются три затвора, которые размещаются вокруг кремниевого канала в трехмерной структуре, обеспечивая непревзойденное сочетание высокой производительности и сверхнизкого энергопотребления.
Эта новая технология позволяет Intel создавать еще более мощные микропроцессоры, предоставляющие повышенную производительность и увеличенное время автономной работы при меньших финансовых затратах, а также создавать еще более компактные устройства, такие как Ultrabook™.
Микроархитектура процессора Intel® Atom™
Постоянные инновации в микроархитектуре лежат в основе Intel® Atom™, самого маленького и самого универсального процессора из семейства Intel. Процессор Intel® Atom™ позволил создать широкий спектр переносных устройств, включая нетбуки, планшетные ПК, карманные ПК, смартфоны, интеллектуальные телевизоры, интеллектуальные системы и бытовую электронику, обеспечив компактные устройства беспрецедентной производительностью обработки аудио и видео.
Архитектура Intel® Many Integrated Core
Архитектура Intel® Many Integrated Core (архитектура Intel® MIC) — это новейшая передовая разработка в сфере быстродействия суперкомпьютеров, производительности и совместимости. Она обеспечивает на одном кристалле пиковую производительность до одного триллиона операций с плавающей запятой. В архитектуре Intel MIC интенсивно используются параллельные вычисления. Она ориентирована на рынок высокопроизводительных вычислений (HPC), на котором параллельная обработка используется для моделирования климата, создания финансовых моделей, выполнения генетического анализа и обработки медицинских изображений и других применений.
Другие видеоролики. Внимание: в данном разделе могут быть представлены материалы на английском языке.
Объяснение принципа работы 14-нанометровых транзисторов — следование закону Мура
Сотрудник корпорации Intel Марк Бор (Mark Bohr) рассказывает о новой 14-нанометровой транзисторной технологии и о том, как каналы транзисторов tri-gate, которые стали выше, тоньше и расположены ближе друг к другу, обеспечивают более высокую производительность, меньшее энергопотребление и более продолжительное время автономной работы для расширения возможностей компьютеров.
Марк Бор о нанотехнологиях: объяснение принципов работы 22-нанометровой технологии
Трехмерные транзисторы Intel® Tri-Gate, а также возможность их массового производства, ознаменовали собой существенное изменение основной структуры компьютерной микросхемы. Узнайте подробнее об истории транзисторов.
В последнее время я много писал о компьютерных сетях. Но и строении и структуре современных компьютеров тоже не стоит забывать. Также как и в компьютерных сетях существует эталонная модель OSI, компьютер тоже делится на уровни. Однако функции да и само деление на уровни созданы по иным причинам, чем в компьютерных сетях. Далее все это излагается в довольно простой и понятной форме.
Многоуровневая структура компьютера: языки, уровни и виртуальные машины
Существует огромная разница между тем, что удобно людям, и тем, что могут компьютеры. Люди хотят сделать X, но компьютеры могут сделать только Y. Из-за этого возникает проблема.
Вышеупомянутую проблему можно решить двумя способами. Оба способа подразумевают разработку новых команд, более удобных для человека, чем встроенные команды. Эти новые команды в совокупности формируют язык, который мы будем называть Я 1. Встроенные машинные команды тоже формируют язык, и мы будем называть его Я 0. Компьютер может выполнять только программы, написанные на его машинном языке Я 0. Два способа решения проблемы различаются тем, каким образом компьютер будет выполнять программы, написанные на языке Я 1, — ведь в конечном итоге компьютеру доступен только машинный язык Я 0.
Первый способ выполнения программы, написанной на языке Я 1, подразумевает замену каждой команды эквивалентным набором команд на языке Я 0. В этом случае компьютер выполняет новую программу, написанную на языке Я 0, вместо старой программы, написанной на Я 1. Эта технология называется трансляцией.
Второй способ означает создание программы на языке Я 0, получающей в качестве входных данных программы, написанные на языке Я 1. При этом каждая команда языка Я 1 обрабатывается поочередно, после чего сразу выполняется эквивалентный ей набор команд языка Я 0. Эта технология не требует составления новой программы на Я 0. Она называется интерпретацией, а программа, которая осуществляет интерпретацию, называется интерпретатором.
Между трансляцией и интерпретацией много общего. В обоих подходах компьютер в конечном итоге выполняет набор команд на языке Я 0, эквивалентных командам Я 1. Различие лишь в том, что при трансляции вся программа Я 1 переделывается в программу Я 0, программа Я 1 отбрасывается, а новая программа на Я 0 загружается в память компьютера и затем выполняется.
При интерпретации каждая команда программы на Я 1 перекодируется в Я 0 и сразу же выполняется. В отличие от трансляции, здесь не создается новая программа на Я 0, а происходит последовательная перекодировка и выполнение команд. С точки зрения интерпретатора, программа на Я 1 есть не что иное, как «сырые» входные данные. Оба подхода широко используются как вместе, так и по отдельности.
Впрочем, чем мыслить категориями трансляции и интерпретации, гораздо проще представить себе существование гипотетического компьютера или виртуальной машины, для которой машинным языком является язык Я 1. Назовем такую виртуальную машину М 1, а виртуальную машину для работы с языком Я 0 — М 0. Если бы такую машину М 1 можно было бы сконструировать без больших денежных затрат, язык Я 0, да и машина, которая выполняет программы на языке Я 0, были бы не нужны. Можно было бы просто писать программы на языке Я 1, а компьютер сразу бы их выполнял. Даже с учетом того, что создать виртуальную машину, возможно, не удастся (из-за чрезмерной дороговизны или трудностей разработки), люди вполне могут писать ориентированные на нее программы. Эти программы будут транслироваться или интерпретироваться программой, написанной на языке Я 0, а сама она могла бы выполняться существующим компьютером. Другими словами, можно писать программы для виртуальных машин так, как будто эти машины реально существуют.
Трансляцию и интерпретацию возможно выполнить только в том случае, когда Я 0 и Я 1 не сильно отличаются друг от друга. Но ведь цель создания Я 1 заключалась в создании языка более удобного для человека. Очевидно что она не может быть достигнута. Чтобы решить эту проблему можно создать еще одну виртуальную машину М 2 и язык Я 2, который будет более понятен для человека, чем Я 1. При этом, программы написанные на языке Я 2 могут транслироваться на язык Я 1 или выполняться интерпретатором, написанным на языке Я 1.
Изобретение целого ряда языков, каждый из которых более удобен для человека, чем предыдущий, может продолжаться до тех пор, пока мы не дойдем до подходящего нам языка. Каждый такой язык использует своего предшественника как основу, поэтому мы можем рассматривать компьютер в виде ряда уровней, такая структура изображена на рисунке ниже. Язык, находящийся в самом низу иерархической структуры компьютера, — самый примитивный, а тот, что расположен на ее вершине — самый сложный.

Многоуровневая структура компьютера
Современные многоуровневые компьютеры
Современные компьютеры можно представить как структуру, состоящую из 6 уровней:

Структура шестиуровневого компьютера
Ради полноты нужно упомянуть о существовании еще одного уровня, который расположен ниже нулевого. Этот уровень не показан на рис. выше, так как он попадает в сферу электронной техники и, следовательно, не рассматривается из-за сложности материала. Он называется уровнем физических устройств. На этом уровне находятся транзисторы, которые для разработчиков компьютеров являются примитивами. Объяснить, как работают транзисторы, — задача физики.
Уровень 0: Цифровой логический уровень
Объекты цифрового логического уровня — вентили. Хотя вентили состоят из аналоговых компонентов, таких как транзисторы, они могут быть точно смоделированы как цифровые устройства. У каждого вентиля есть один или несколько цифровых входов (сигналов, представляющих 0 или 1). Вентиль вычисляет простые функции этих сигналов, такие как И или ИЛИ. Каждый вентиль формируется из нескольких транзисторов. Несколько вентилей формируют 1 бит памяти, который может содержать 0 или 1. Биты памяти, объединенные в группы, например, по 16, 32 или 64, формируют регистры. Каждый регистр может содержать одно двоичное число до определенного предела. Из вентилей также может состоять сам компьютер.
Уровень 1: уровень Микроархитектуры
Следующий уровень называется уровнем микроархитектуры. На этом уровне находятся совокупности 8 или 32 регистров, которые формируют локальную память и схему, называемую АЛУ (арифметико-логическое устройство). АЛУ выполняет простые арифметические операции. Регистры вместе с АЛУ формируют тракт данных, по которому поступают данные. Тракт данных работает следующим образом. Выбирается один или два регистра, АЛУ производит над ними какую-либо операцию, например сложения, после чего результат вновь помещается в один из этих регистров.
На некоторых машинах работа тракта данных контролируется особой программой, которая называется микропрограммой. На других машинах тракт данных контролируется аппаратными средствами.
На машинах, где тракт данных контролируется программным обеспечением, микропрограмма — это интерпретатор для команд на уровне 2. Микропрограмма вызывает команды из памяти и выполняет их одну за другой, используя при этом тракт данных. Например, при выполнении команды ADD она вызывается из памяти, ее операнды помещаются в регистры, АЛУ вычисляет сумму, а затем результат переправляется обратно. На компьютере с аппаратным контролем тракта данных происходит такая же процедура, но при этом нет программы, интерпретирующей команды уровня 2.
Уровень 2: уровень архитектуры набора команд
Уровень 2 мы будем называть уровнем архитектуры набора команд. Каждый производитель публикует руководство для компьютеров, которые он продает, под названием «Руководство по машинному языку X», «Принципы работы компьютера У» и т. п. Подобное руководство содержит информацию именно об этом уровне. Описываемый в нем набор машинных команд в действительности выполняется микропрограммой-интерпретатором или аппаратным обеспечением. Если производитель поставляет два интерпретатора для одной машины, он должен издать два руководства по машинному языку, отдельно для каждого интерпретатора.
Уровень 3: уровень операционной системы
Этот уровень обычно является гибридным. Большинство команд в его языке есть также и на уровне архитектуры набора команд (команды, имеющиеся на одном из уровней, вполне могут быть представлены и на других уровнях). У этого уровня есть некоторые дополнительные особенности: новый набор команд, другая организация памяти, способность выполнять две и более программы одновременно и некоторые другие. При построении уровня 3 возможно больше вариантов, чем при построении уровней 1 и 2.
Новые средства, появившиеся на уровне 3, выполняются интерпретатором, который работает на втором уровне. Этот интерпретатор был когда-то назван операционной системой. Команды уровня 3, идентичные командам уровня 2, выполняются микропрограммой или аппаратным обеспечением, но не операционной системой. Другими словами, одна часть команд уровня 3 интерпретируется операционной системой, а другая часть — микропрограммой. Вот почему этот уровень считается гибридным. Мы будем называть этот уровень уровнем операционной системы.
Между уровнями уровнем архитектуры набора команд и уровнем операционной системы есть существенная разница. Нижние три уровня задуманы не для того, чтобы с ними работал обычный программист. Они изначально ориентированы на интерпретаторы и трансляторы, поддерживающие более высокие уровни. Эти трансляторы и интерпретаторы составляются так называемыми системными программистами, которые специализируются на разработке новых виртуальных машин. Уровни с четвертого и выше предназначены для прикладных программистов, решающих конкретные задачи.
Еще одно изменение, появившееся на уровне операционной системы, — механизм поддержки более высоких уровней. Уровни 2 и 3 обычно интерпретируются, а уровни 4, 5 и выше
обычно, хотя и не всегда, транслируются.
Другое отличие между уровнями 1, 2, 3 и уровнями 4, 5 и выше — особенность языка. Машинные языки уровней 1, 2 и 3 — цифровые. Программы, написанные на этих языках, состоят из длинных рядов цифр, которые воспринимаются компьютерами, но малопонятны для людей. Начиная с уровня 4, языки содержат слова и сокращения, понятные человеку.
Уровень 4: уровень Ассемблера
Уровень 4 представляет собой символическую форму одного из языков более низкого уровня. На этом уровне можно писать программы в приемлемой для человека форме. Эти программы сначала транслируются на язык уровня 1, 2 или 3, а затем интерпретируются соответствующей виртуальной или фактически существующей машиной. Программа, которая выполняет трансляцию, называется ассемблером.
Уровень 5: уровень языка прикладных программистов
Уровень 5 обычно состоит из языков, разработанных для прикладных программистов. Такие языки называются языками высокого уровня. Существуют сотни языков высокого уровня. Наиболее известные среди них — С, C++, Java, LISP и Prolog. Программы, написанные на этих языках, обычно транслируются на уровень 3 или 4. Трансляторы, которые обрабатывают эти программы, называются компиляторами. Отметим, что иногда также имеет место интерпретация. Например, программы на языке Java сначала транслируются на язык, напоминающий ISA и называемый байт-кодом Java, который затем интерпретируется.
В некоторых случаях уровень 5 состоит из интерпретатора для конкретной прикладной области, например символической логики. Он предусматривает данные и операции для решения задач в этой области, выраженные при помощи специальной терминологии.
Таким образом, компьютер проектируется как иерархическая структура уровней, которые надстраиваются друг над другом. Каждый уровень представляет собой определенную абстракцию различных объектов и операций. Рассматривая компьютер подобным образом, мы можем не принимать во внимание ненужные нам детали и, таким образом, сделать сложный предмет более простым для понимания.
Набор типов данных, операций и характеристик каждого отдельно взятого уровня называется архитектурой. Архитектура связана с программными аспектами. Например, сведения о том, сколько памяти можно использовать при написании программы, — часть архитектуры. Аспекты реализации (например, технология, применяемая при реализации памяти) не являются частью архитектуры. Изучая методы проектирования программных элементов компьютерной системы, мы изучаем компьютерную архитектуру. На практике термины «компьютерная архитектура» и «компьютерная организация» употребляются как синонимы.
Несколько лет назад, во времена господства бренда Pentium, первого появления торговой марки Intel Core и одноимённой микроархитектуры (Architecture 101), на слайдах о будущих процессорах впервые было упомянуто следующее поколение микроархитектуры Intel с рабочим названием Gesher ("мост" на иврите), что чуть позже трансформировалось в Sandy Bridge.

В ту давнюю пору господства процессоров NetBurst, когда только-только начали проступать контуры грядущих ядер Nehalem, а мы знакомились с особенностями внутреннего строения первых представителей микроархитектуры Core - Conroe для настольных систем, Merom - для мобильных и Woodcrest - для серверных…
Словом, когда трава была зелёная, а до Sandy Bridge было ещё как до Луны, уже тогда представители Intel говорили, что это будет совершенно новая процессорная микроархитектура. Именно так, cкажем, сегодня можно представить таинственную микроархитектуру Haswell, которая появится после поколения Ivy Bridge, которое, в свою очередь, придёт на смену Sandy Bridge в следующем году.
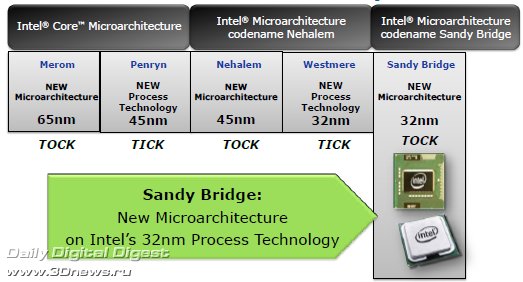
Однако чем ближе дата выпуска новой микроархитектуры, чем больше мы узнаём об её особенностях, тем больше становятся заметны сходства соседних поколений, и тем более очевиден эволюционный путь изменений в схемотехнике процессоров. И действительно, если между начальными реинкарнациями первой архитектуры Core - Merom/Conroe, и первенцем второго поколения Core – Sandy Bridge - на самом деле пролегает пропасть различий, то нынешняя последняя версия поколения Core - ядро Westmere - и грядущая, рассматриваемая сегодня первая версия поколения Core II - ядро Sandy Bridge, могут показаться схожими.
И всё же различия существенны. Настолько существенны, что теперь окончательно можно говорить о конце 15-летней эпохи микроархитектуры P6 (Pentium Pro) и о появлении нового поколения микроархитектуры Intel.
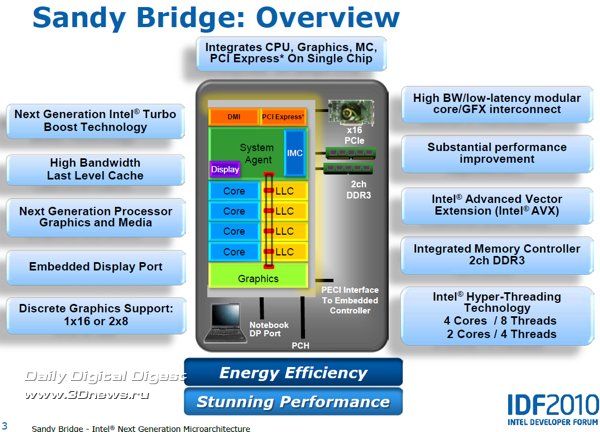
Чип Sandy Bridge – это четырёхъядерный 64-битный процессор с изменяемой (out-of-order) последовательностью исполнения команд, поддержкой двух потоков данных на ядро (HT), исполнением четырёх команд за такт; с интегрированным графическим ядром и интегрированным контроллером памяти DDR3; с новой кольцевой шиной, поддержкой 3- и 4-операндных (128/256-битных) векторных команд расширенного набора AVX (Advanced Vector Extensions); производство которого налажено на линиях с соблюдением норм современного 32-нм технологического процесса Intel.
Так, вкратце, одним предложением можно попробовать охарактеризовать новое поколение процессоров Intel Core II для мобильных и настольных систем, массовые поставки которых начнутся в самое ближайшее время.


Процессоры Intel Core II на базе микроархитектуры Sandy Bridge будут поставляться в новом 1155-контактном конструктиве LGA1155 под новые системные платы на чипсетах Intel 6 Series.

Примерно такая же микроархитектура будет актуальна и для серверных решений Intel Sandy Bridge-EP, разве что с актуальными отличиями в виде большего количества процессорных ядер (до восьми), соответствующего процессорного разъёма LGA2011, большего объёма кеша L3, увеличенного количества контроллеров памяти DDR3 и поддержкой PCI-Express 3.0.
Предыдущее поколение, микроархитектура Westmere в исполнении Arrandale и Clarkdale для мобильных и настольных систем, представляет собой конструкцию из двух кристаллов - 32-нм процессорного ядра и дополнительного 45-нм «сопроцессора» с графическим ядром и контроллером памяти на борту, размещённых на единой подложке и производящих обмен данными посредством шины QPI. По сути, на этом этапе инженеры Intel, используя преимущественно предыдущие наработки, создали этакую интегрированную гибридную микросхему.
При создании архитектуры Sandy Bridge разработчики закончили начатый на этапе создания Arrandale/Clarkdale процесс интеграции и разместили все элементы на едином 32-нм кристалле, отказавшись при этом от классического вида шины QPI в пользу новой кольцевой шины. Суть микроархитектуры Sandy Bridge при этом осталась в рамках прежней идеологии Intel, которая делает ставку на увеличение суммарной производительности процессора за счёт улучшения «индивидуальной» эффективности каждого ядра.

Структуру чипа Sandy Bridge можно условно разделить на следующие основные элементы: процессорные ядра, графическое ядро, кеш-память L3 и так называемый «Системный агент» (System Agent).
В общем и целом структура микроархитектуры Sandy Bridge понятна. Наша сегодняшняя задача – выяснить назначение и особенности реализации каждого из элементов этой структуры.
Вся история модернизации процессорных микроархитектур Intel последних лет неразрывно связана с последовательной интеграцией в единый кристалл всё большего количества модулей и функций, ранее располагавшихся вне процессора: в чипсете, на материнской плате и т.д. Соответственно, по мере увеличения производительности процессора и степени интеграции чипа, требования к пропускной способности внутренних межкомпонентных шин росли опережающими темпами. До поры до времени, даже после внедрения графического чипа в архитектуру чипов Arrandale/Clarkdale, удавалось обходиться межкомпонентными шинами с привычной перекрёстной топологией - этого было достаточно.

Однако эффективность такой топологии высока лишь при небольшом количестве компонентов, принимающих участие в обмене данными. В микроархитектуре Sandy Bridge для повышения общей производительности системы разработчики решили обратиться к кольцевой топологии 256-битной межкомпонентной шины, выполненной на основе новой версии технологии QPI (QuickPath Interconnect), расширенной, доработанной и впервые реализованной в архитектуре серверного чипа Nehalem-EX (Xeon 7500), а также планировавшейся к применению совместно с архитектурой чипов Larrabee .
Кольцевая шина в версии архитектуры Sandy Bridge для настольных и мобильных систем (Core II) служит для обмена данными между шестью ключевыми компонентами чипа: четырьмя процессорными ядрами x86, графическим ядром, кешем L3 и системным агентом. Шина состоит из четырёх 32-байтных колец: шины данных (Data Ring), шины запросов (Request Ring), шины мониторинга состояния (Snoop Ring) и шины подтверждения (Acknowledge Ring), на практике это фактически позволяет делить доступ к 64-байтному интерфейсу кеша последнего уровня на два различных пакета. Управление шинами осуществляется с помощью коммуникационного протокола распределённого арбитража, при этом конвейерная обработка запросов происходит на тактовой частоте процессорных ядер, что придаёт архитектуре дополнительную гибкость при разгоне. Производительность кольцевой шины оценивается на уровне 96 Гбайт в секунду на соединение при тактовой частоте 3 ГГц, что фактически в четыре раза превышает показатели процессоров Intel предыдущего поколения.
Кольцевая топология и организация шин обеспечивает минимальную латентность при обработке запросов, максимальную производительность и отличную масштабируемость технологии для версий чипов с различным количеством ядер и других компонентов. По словам представителей компании, в перспективе к кольцевой шине может быть "подключено" до 20 процессорных ядер на кристалл, и подобный редизайн, как вы понимаете, может производиться очень быстро, в виде гибкой и оперативной реакции на текущие потребности рынка. Кроме того, физически кольцевая шина располагается непосредственно над блоками кеш-памяти L3 в верхнем уровне металлизации, что упрощает разводку дизайна и позволяет сделать чип более компактным.
L3 - кеш-память последнего уровня, LLC
Как вы уже успели заметить, на слайдах Intel кеш-память L3 обозначается как «кеш последнего уровня», то есть, LLC - Last Level Cache. В микроархитектуре Sandy Bridge кеш L3 распределён не только между четырьмя процессорными ядрами, но, благодаря кольцевой шине, также между графическим ядром и системным агентом, в который, среди прочего, входит модуль аппаратного ускорения графики и блок видеовыхода. При этом специальный трассировочный механизм упреждает возникновение конфликтов доступа между процессорными ядрами и графикой.

Каждое из четырёх процессорных ядер имеет прямой доступ к «своему» сегменту кеша L3, при этом каждый сегмент кеша L3 предоставляет половину ширины своей шины для доступа кольцевой шины данных, при этом физическая адресация всех четырёх сегментов кеша обеспечивается единой хэш-функцией. Каждый сегмент кеша L3 обладает собственным независимым контроллером доступа к кольцевой шине, он отвечает за обработку запросов по размещению физических адресов. Кроме того, контроллер кеша постоянно взаимодействует с системным агентом на предмет неудачных обращений к L3, контроля межкомпонентного обмена данными и некешируемых обращений.

Дополнительные подробности о строении и особенностях функционирования кеш-памяти L3 процессоров Sandy Bridge будут появляться далее по тексту, в процессе знакомства с микроархитектурой, по мере возникновения необходимости.
Ранее вместо определения System Agent в терминологии Intel фигурировало так называемое «Неядро» - Uncore, то есть, «всё, что не входит в Core», а именно кеш L3, графика, контроллер памяти, другие контроллеры вроде PCI Express и т.д. Мы же по привычке частенько называли большую часть этого элементами северного моста, перенесённого из чипсета в процессор.

Системный агент микроархитектуры Sandy Bridge включает в себя контроллер памяти DDR3, модуль управления питанием (Power Control Unit, PCU), контроллеры PCI-Express 2.0, DMI, блок видеовыхода и пр. Как и все остальные элементы архитектуры, системный агент подключен в общую систему посредством высокопроизводительной кольцевой шины.
Архитектура стандартной версии системного агента Sandy Bridge подразумевает наличие 16 линий шины PCI-E 2.0, которые также могут быть распределены на две шины шины PCI-E 2.0 по 8 линий, или на одну шину PCI-E 2.0 на 8 линий и две шины PCI-E 2.0 по четыре линии. Двухканальный контроллер памяти DDR3 отныне «вернулся» на кристалл (в чипах Clarkdale он располагался вне процессорного кристалла) и, скорее всего, теперь будет обеспечивать значительно меньшую латентность.
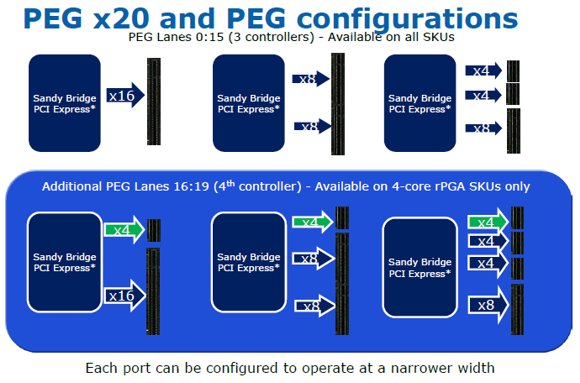
Тот факт, что контроллер памяти в Sandy Bridge стал двухканальным, вряд ли обрадует тех, кто уже успел вывалить немалые суммы за оверклокерские комплекты трёхканальной памяти DDR3. Что ж, бывает, теперь будут актуальны наборы лишь из одного, двух или четырёх модулей.
По поводу возвращения к двухканальной схеме контроллера памяти у нас имеются кое-какие соображения. Возможно, в Intel начали подготовку микроархитектур к работе с памятью DDR4? Которая, из-за ухода от топологии «звезды» на топологию «точка-точка» в версиях для настольных и мобильных систем будут по определению только двухканальной (для серверов будут применяться специальные модули-мультиплексоры). Впрочем, это всего лишь догадки, для уверенных предположений пока что недостаточно информации о самом стандарте DDR4.
Расположенный в системном агенте контроллер управления питанием отвечает за своевременное динамичное масштабирование напряжений питания и тактовых частот процессорных ядер, графического ядра, кешей, контроллера памяти и интерфейсов. Что особенно важно подчеркнуть, управление питанием и тактовой частотой производится независимо для процессорных ядер и графического ядра.

Совершенно новая версия технологии Turbo Boost реализована не в последнюю очередь благодаря этому контроллеру управления питанием. Дело в том, что, в зависимости от текущего состояния системы и сложности решаемой задачи, микроархитектура Sandy Bridge позволяет технологии Turbo Boost «разогнать» ядра процессора и встроенную графику до уровня, значительно превышающего TDP на достаточно долгое время. И действительно, почему бы не воспользоваться такой возможностью штатно, пока система охлаждения ещё холодная и может обеспечить больший теплоотвод, чем уже разогретая?
Кроме того, что технология Turbo Boost позволяет теперь штатно «разгонять» все четыре ядра за пределы TDP, также стоит отметить, что управление производительностью и тепловым режимом графических ядер в чипах Arrandale/Clarkdale, по сути, только встроенных, но не до конца интегрированных в процессор, производилось с помощью драйвера. Теперь, в архитектуре Sandy Bridge, этот процесс также возложен на контроллер PCU. Такая плотная интеграция системы управления напряжением питания и частотами позволила реализовать на практике гораздо более агрессивные сценарии работы технологии Turbo Boost, когда и графика, и все четыре ядра процессора при необходимости и соблюдении определённых условий могут разом работать на повышенных тактовых частотах со значительным превышением TDP, но без каких-либо побочных последствий.

Принцип работы новой версии технологии Turbo Boost, реализованной в процессорах Sandy Bridge, отлично описывается в мультимедийной презентации, показанной в сентябре на Форуме Intel для разработчиков в Сан-Франциско. Представленный ниже видеоролик с записью этого момента презентации расскажет вам о Turbo Boost быстрее и лучше, чем любой пересказ.
Насколько эффективно эта технология будет работать в серийных процессорах, нам ещё предстоит узнать, но то, что показывали специалисты Intel во время закрытой демонстрации возможностей Sandy Bridge в дни IDF в Сан Франциско, просто поражает: и прирост тактовой частоты, и, соответственно, производительность процессора и графики, одномоментно могут достичь просто фантастических уровней.
Есть информация, что для штатных систем охлаждения режим такого «разгона» с помощью Turbo Boost и превышением TDP будет ограничен в BIOS периодом в 25 секунд. Но что если производители системных плат смогут гарантировать более качественный отвод тепла с помощью какой-нибудь экзотической системы охлаждения? Тут и открывается раздолье для оверклокеров…

Каждое из четырёх ядер Sandy Bridge может быть при необходимости независимо переведено в режим минимального энергопотребления, графическое ядро также можно перевести в очень экономичный режим. Кольцевая шина и кеш L3, в силу их распределения между другими ресурсами, не могут быть отключены, однако для кольцевой шины предусмотрен специальный экономичный ждущий режим, когда она не нагружена, а для кеш-памяти L3 применяется традиционная технология отключения неиспользуемых транзисторов, уже известная нам по предыдущим микроархитектурам. Таким образом, процессоры Sandy Bridge в составе мобильных ПК обеспечивают длительную автономную работу при питании от аккумулятора.
Модули видеовыхода и мультимедийного аппаратного декодирования также входят в число элементов системного агента. В отличие от предшественников, где аппаратное декодирование было возложено на графическое ядро (о его возможностях мы поговорим в следующий раз), в новой архитектуре для декодирования мультимедийных потоков используется отдельный, гораздо более производительный и экономичный модуль, и лишь в процессе кодирования (сжатия) мультимедийных данных используются возможности шейдерных блоков графического ядра и кеш L3.

В соответствии с современными веяниями, предусмотрены инструменты воспроизведения 3D-контента: аппаратный модуль декодирования Sandy Bridge способен без труда обрабатывать сразу два независимых потока MPEG2, VC1 или AVC в разрешении Full HD.
Сегодня мы познакомились со структурой нового поколения микроархитектуры Intel Core II с рабочим названием Sandy Bridge, разобрались со строением и принципом работы ряда ключевых элементов этой системы: кольцевой шины, кеш-памяти L3 и системного агента, в состав которого входит контроллер памяти DDR3, модуль управления питанием и другие компоненты.
Однако это лишь малая часть новых технологий и идей, реализованных в микроархитектуре Sandy Bridge, не менее впечатляющие и масштабные изменения коснулись архитектуры процессорных ядер и интегрированной графической системы. Так что на этом наш рассказ о Sandy Bridge не заканчивается - продолжение следует.
Читайте также: