
Как скопировать запрос power query из одного файла в другой
Блог о Microsoft Power BI Desktop, Excel и Power Query
Экспорт кода запросов из Power Query
и Power BI с помощью Copy/ Paste
Текст представляет собой адаптированный перевод статьи Chris Webb (Крис Уэбб),
оригинал – Exporting Your Queries' M Code From Power Query And Power BI Using Copy/Paste
Крис Вебб (Chris Webb) — независимый эксперт, консультант по технологиям Analysis Services, MDX, Power Pivot, DAX, Power Query и Power BI. Его блог — это кладезь информации на тему перечисленных технологий. Вот уже более 10 лет он пишет про BI-решения от Microsoft. Количество его статей перевалило за 1000! Также Крис выступает на большом количестве различных конференций вроде SQLBits, PASS Summit, PASS BA Conference, SQL Saturdays и участвует в различных сообществах.
Крис любезно разрешил нам переводить его статьи на русский язык. И это одна из них.
Экспорт кода запросов из Power Query и Power BI с помощью Copy/ Paste
В нашей давней статье мы описывали метод экспорта кода всех запросов в Power Query при помощи кнопки Send A Frown. Полезная вещь, если необходимо получить текст кода в документ. К сожалению, этот трюк не работает в Power BI Desktop. Зато теперь есть способ лучше – использовать механизм copy/paste, работоспособный как в Power Query так и Power BI Desktop. Пользоваться им просто. При копировании запроса в Query Editor можно делать вставку не только в другой Query Editor (вставка между Power Query и Power BI также работает), но и в любой другой текстовый редактор. Кроме того, при копировании в Query Editor можно выбрать несколько запросов, и весь код вставится целевое место.

Красным шрифтом написано:
1. Выделите запросы
2. Щелкните правой кнопкой мыши и выберете Copy
3. Вставьте в Notepad код выбранных запросов
Помните, что поскольку свойства каждого шага запроса становятся комментариями, они также копируются.
Duplicate
В Power Query мы получили данные из Интернета и выбрали этот источник:

Скажем, для этой таблицы мы делаем некоторые преобразования. Например; удаление дополнительного символа «^» из последнего столбца (столбец «Год»);

а затем некоторые другие преобразования, поэтому мы получаем несколько шагов для этого запроса.

После выполнения всех этих преобразований вы понимаете, что эти данные предназначены только для первых ста бестселлеров, потому что на этой веб-странице нет оставшихся фильмов. Чтобы получить оставшиеся, вам нужно перейти на страницу 2, у которой есть другой URL-адрес, но с той же структурой данных.

Итак, что вам нужно сделать? Вы снова должны пройти все эти шаги на странице 2. Давайте сохраним этот пример как статический и базовый (потому что в сложных сценариях, когда у вас много страниц, вы можете использовать функции и параметры для прокрутки всех страниц и объединить их все вместе). Предположим, вы хотите осуществить все те действия, которые сделали для первой страницы, для второй страницы. Для этого; вы можете использовать Duplicate.
Создайте дубликат Box Office Mojo (мы его назвали, Box Office Mojo Page 1)

Когда вы создаете Duplicate-запрос, это будет точная копия первого запроса со всеми его шагами. Эти два запроса точно похожи друг на друга. Никакой разницы!

Duplicate в точности копирует запрос со всеми применяемыми его шагами в качестве нового запроса.
После создания копии вы можете перейти на исходный шаг, чтобы изменить URL-адрес:

Используя Duplicate, вам удалось скопировать запрос со всеми его шагами, а затем внести изменения в новый запрос. Исходный запрос не поврежден.
Duplicate - это опция выбора, когда вы хотите скопировать запрос, но выполнить другую конфигурацию пошагово.
Reference
Reference - еще один способ копирования запроса. Однако большая разница в том, что при обращении к запросу новый запрос будет иметь только один шаг: поиск из исходного запроса. Указанный запрос не будет иметь примененных шагов исходного запроса. Давайте посмотрим на этот вариант в действии. Продолжая приведенный выше пример; допустим, мы хотим создать новый запрос, который является результатом объединения результатов страницы 1 и страницы 2. Однако мы не хотим изменять какие-либо существующие запросы, потому что мы хотим использовать их как источник для других операций.
При щелчке правой кнопкой мыши на Box Office Mojo Page 1, мы можем создать Reference

Reference создаст новый запрос, который является копией Box Office Mojo Page 1, но содержит только один шаг:

Единственный шаг в новом запросе - поиск данных из исходного запроса. Что это значит? Это означает, что если вы внесете изменения в исходный запрос, это повлияет на этот новый запрос.
Reference создаст новый запрос, который имеет только один шаг: получение данных из исходного запроса.
Теперь мы можем использовать этот запрос, чтобы добавить в Box Office Mojo Page 2;

Результатом будет запрос, содержащий обе страницы;

Чтобы узнать больше об append и о различиях в Merge, прочитайте этот пост в блоге. В этом примере; мы использовали опцию Reference, чтобы создать копию исходного запроса, а затем продолжить некоторые дополнительные шаги. Для Reference есть много других способов использования.
Reference - хороший выбор, когда вы хотите разветвить запрос на разные шаблоны. По одному пути будет следовать ряд шагов, а по другому -разные шаги, и оба разделяют некоторые шаги в исходном запросе.
После выполнения добавления в этом примере рекомендуется снять флажок enable load на Page 1 и Page 2 запроса, чтобы сохранить некоторую память в Power BI.

Зависимость запросов
Выяснение того, какой запрос от какого зависит (или на какой ссылается) может быть проблематично, когда у вас слишком много запросов. Вот почему у нас есть опция меню Query Dependency на вкладке View Power Query;

В нашем примере выше это диаграмма зависимостей запросов

Duplicate или Reference
Теперь, когда вы знакомы с двумя вариантами копирования запроса, давайте более подробно рассмотрим их разницу.
Изоляция от оригинала или зависимость к оригиналу
Duplicate создает новую копию со всеми существующими шагами. Новая копия будет изолирована от исходного запроса. Вы можете внести изменения в исходный или новый запрос, и они НЕ будут влиять друг на друга. С другой стороны, Reference - это новая копия с единственным шагом: получение данных из исходного запроса. Если вы внесете изменения в исходный запрос, будет затронут новый запрос. Например, если вы удалите столбец из исходного запроса, новый запрос не будет иметь его, если он использовал метод Reference для копирования.
Ограничение ссылки
Вы не можете использовать ссылаемые запросы во всех ситуациях. В качестве примера; Если у вас есть запрос 1, а затем вы создали ссылку из него в качестве запроса 2. Вы не можете использовать результат запроса 2 в запросе 1! Это создаст круговую ссылку. Вы комбинируете запрос со ссылкой на сам запрос, это невозможно!

Некоторые действия, вызывающие Reference или Duplicate
В Power Query есть несколько действий, которые запускают Reference или Duplicate, давайте проверим эти параметры:
Append Queries as New или Merge Queries as New - это действие Reference
Эти два действия создают ссылку из исходного запроса, а затем добавляют или присоединяются к другим запросам.

Add as New Query - это действие Duplicate
Верьте или нет, когда вы щелкаете правой кнопкой мыши по столбцу или ячейке и выбираете Add as New Query, вы создаете дубликат исходного запроса.

Иногда это может вводить в заблуждение, потому что вы можете ожидать, что новый запрос будет исходить из оригинала, и с изменением оригинала этот запрос также изменится. Правда, в том, что это дублирующее действие, и после этого действия исходный запрос и новая копия будут изолированы друг от друга.

Copy и Paste не относятся ни к Duplicate, ни к Reference!
Это очередное неправильное представление о том, что Copy и Paste похожи на Duplicate. Это не так, и это и не Reference. Когда вы выполняете это действие по простому запросу (имеется в виду запрос, который не получен из любых других запросов), вы получаете результат, похожий на Duplicate.

Но когда вы делаете Copy и Paste на запрос, который получен из других запросов, результатом является копия всех исходных запросов. Вот результат копирования и вставки на Box Office Mojo All Pages (который получен из страницы 1 и стр. 2).

Резюме
Это продолжение перевода книги Кен Пульс и Мигель Эскобар. Язык М для Power Query. Главы не являются независимыми, поэтому рекомендую читать последовательно.
Power Query имеет специальную опцию для импорта всех файлов из папки. Эта глава посвящена импорту двоичных файлов, таких как TXT и CSV. Следующая глава посвящена импорту данных из нескольких книг Excel. Примеры файлов для этой главы разбиты на четыре подпапки: Begin, 2008 – More, 2009, 2010. Большинство скриншотов получено в Excel 365 (июль 2019). Упоминаются отличия, замеченные в Excel 2019.
Создайте новую книгу, пройдите на вкладку Данные, кликните Получить данные –> Из файла –> Из папки:
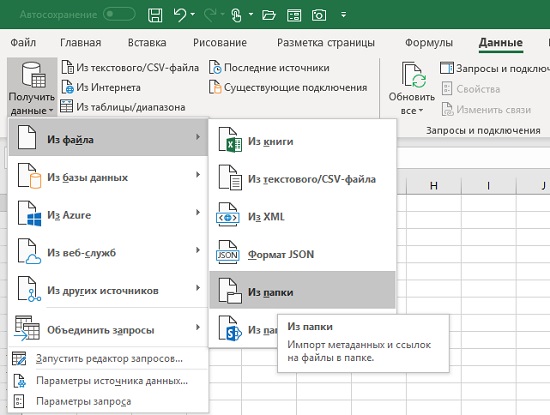
Рис. 4.1. Меню импорта файлов из папки
В окне Папка выберите папку Begin (рис. 4.2), нажмите Ok.
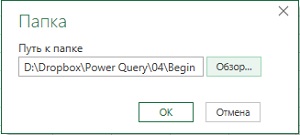
Рис. 4.2. Выбор папки для импорта файлов
Откроется окно, в котором отражаются все файлы в папке и их тип:
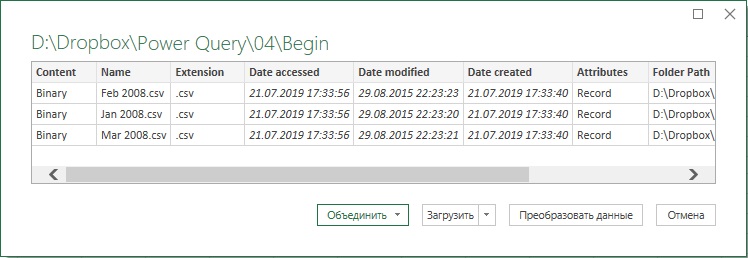
Рис. 4.3. Окно предварительного просмотра содержимого выбранной паки; в Excel 2019 кнопка Преобразовать данные называется Изменить; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Нажмите Преобразовать данные, и список файлов загрузится в редактор Power Query:

Рис. 4.4. Окно загрузки файлов в редакторе Power Query
В этой главе вы будете объединять csv-файлы из четырех папок. Прежде чем идти дальше, вы должны отфильтровать список, чтобы оставить только csv-файлы. Если этого не сделать, а кто-то в будущем поместит в вашу папку Excel-файл, это может сломать загрузку.
Для начала застрахуйтесь от того, что расширение может быть набрано в верхнем CSV или нижнем csv регистре (поскольку текстовые фильтры чувствительны к регистру). Щелкните правой кнопкой мыши на заголовке столбца Extension (расширение) –> Преобразование –> нижний регистр. Далее щелкните стрелку фильтра в столбце Extension, пройдите по меню Текстовые фильтры –> Равно, и в открывшемся окне фильтрация строк, установите равно csv (рис. 4.5). Поскольку у вас в папке есть только csv-файлы, то кликнув на стрелку фильтра вы увидите Выбрать все. Не переживайте, в строке формул отразился правильный фильтр (см. строку формул на рис. 4.4). Обратите внимание, что в фильтре перед csv нужна точка.
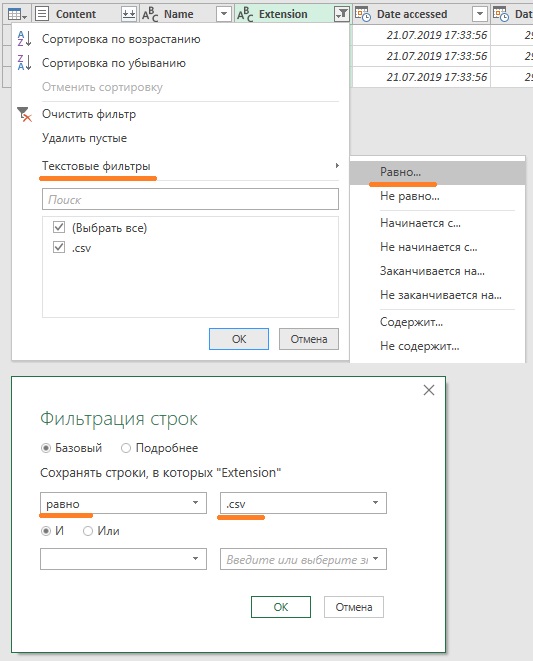
Рис. 4.5. Установка фильтра для файлов загрузки
Объединение файлов
Посмотрите на значки в первых трех столбцах текущего запроса:
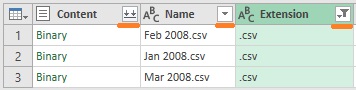
Рис. 4.6. Пиктограммы первых трех столбцов текущего запроса
В столбце Name отображается значок невыбранного фильтра, в столбце Extension – примененный фильтр. Но самым замечательным является значок в столбце Content. Эта пиктограмма появляется на столбцах, содержащих двоичные файлы, и при ее нажатии происходит объединение файлов. Сначала откроется окно предварительного просмотра (рис. 4.7), а после нажатия Ok, все файлы из папки Begin объединятся в один запрос, и будут импортированы в редактор Power Query (рис. 4.8). Любопытно, что в Excel 2019 при импорте был также добавлен столбец Source.Name, содержащий имя файла в каждой строке трансакции. Таким образом, можно было бы обойтись без части ухищрений, описанных ниже))
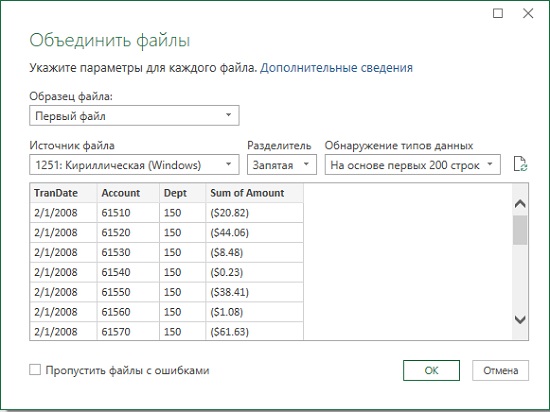
Рис. 4.7. Окно предварительного просмотра Объединить файлы
Переименуйте столбцы, измените тип данных с использованием локали, удалите ошибки, переименуйте запрос в Transactions, кликните Закрыть и загрузить (подробнее см. главу 2).
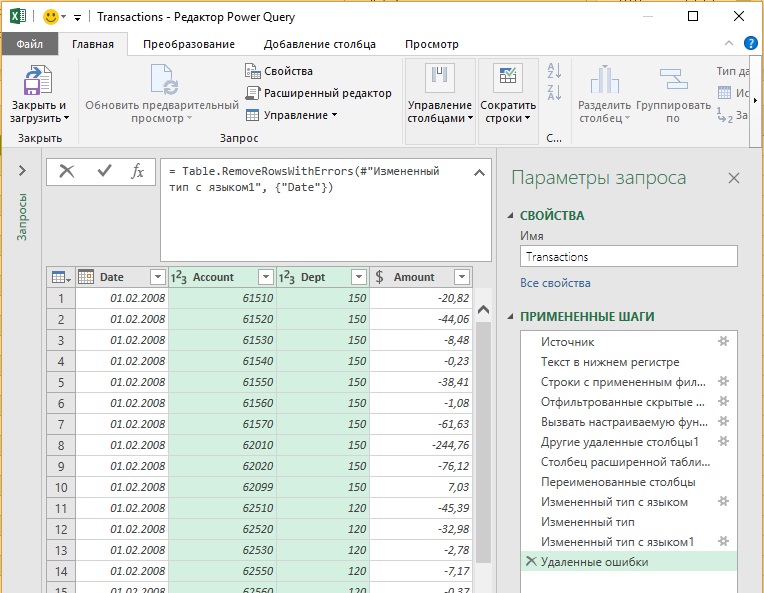
Рис. 4.8. Объединенные данные в окне редактора Power Query
Убедитесь, что таблица в Excel включает данные за три месяца. Создайте сводную:
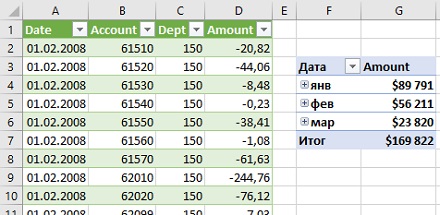
Рис. 4.9. Сводная таблица на основе объединенных данных из трех файлов из папки Begin
Добавление новых файлов
Добавить новые файлы в запрос довольно просто:
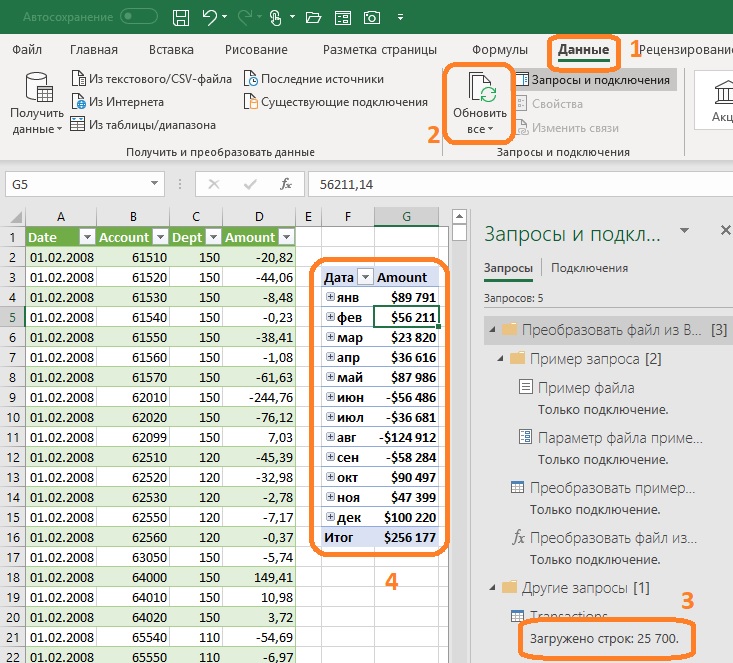
Рис. 4.10. Добавление новых файлов в запрос
Перетащите папки 2009 и 2010 в папку Begin. Повторите операции обновления запроса и обновления сводной таблицы.
Рекурсия. Для добавления новых файлов в запрос не потребовалось перемещать файлы в корень папки Begin. Power Query по умолчанию использует рекурсию, т.е. проверяет корневую и все вложенные папки на наличие файлов с правильным расширением. Это позволяет сохранить файлы в отдельных папках, например, по годам (если это необходимо).
Если вы откроете редактор запросов и перейдете на шаг Источник, то увидите, что для каждого файла указан путь к папке. Если требуется, вы можете применить фильтры к этому столбцу, чтобы включить только корневую папку или исключить определенные папки.
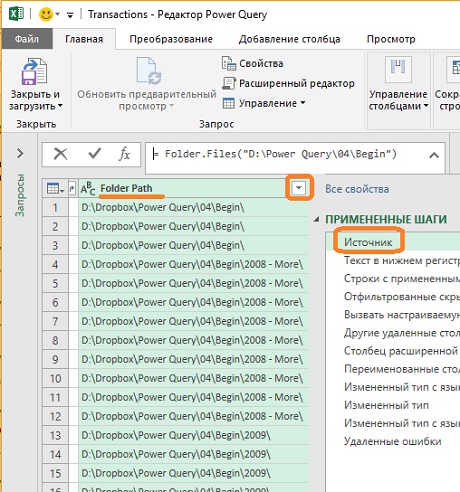
Рис. 4.11. С помощью фильтрации можно включать в запрос только нужные папки
Сохранение свойств файла при импорте
Допустим ваша бухгалтерская система настроена так, что экспортирует список транзакций в файл и присваивает ему имя месяца и года (например, Feb 2008.csv). Система не включает даты транзакций в файл, поскольку все они относятся к дате окончания месяца. При импорте нескольких файлов жизненно важно указать дату в каждой строке.
Вернитесь в редактор запросов. Перейдите на шаг Отфильтрованные скрытые файлы1. Выберите столбец Name, удерживая нажатой клавишу Ctrl, выберите столбец Content. Щелкните правой кнопкой мыши один из выделенных столбцов, выберите Удалить другие столбцы.
Power Query обрабатывая каждый шаг перед переходом к следующему. Это означает, что в отличие от Excel, он не требует наличия столбцов, в которых установлен фильтр. Учитывая это, и поскольку вы уже отфильтровали csv-файлы, вы можете удалить и этот столбец.
Во-первых, вы удалили все посторонние столбцы самым надежным способом. Это способ лучше, чем выделение столбцов, которые нужно удалить. Если в будущем в таблице появятся дополнительные столбцы, они всё равно будут удалены, так как команда фактически говорит: «оставь только столбцы Name и Content». Во-вторых, из-за порядка, в котором вы выбрали столбцы, вы перевернули порядок, в котором они представлены в редакторе Power Query:
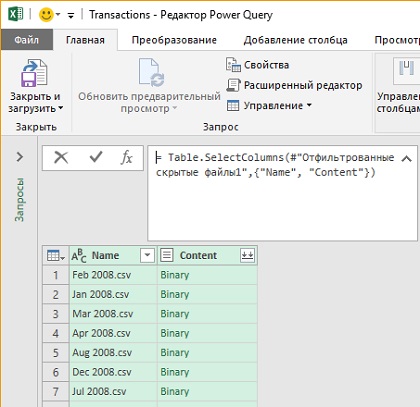
Рис. 4.12. Два оставшихся столбца расположены в порядке обратном, к тому что был до команды Удалить другие столбцы
Следующая задача – преобразовать имена файлов в допустимые даты конца месяца:
- Щелкните правой кнопкой мыши столбец Name, выберите Замена значений
- Замените .csv на пусто
- Еще раз щелкните правой кнопкой мыши столбец Name, выберите Замена значений
- Замените ˽ (пробел) на ˽1,˽ (пробел, единица, запятая, пробел)
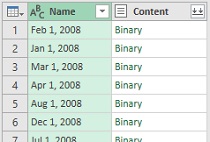
Рис. 4.13. Промежуточный результат преобразований
Теперь от первого числа месяца можно перейти к последнему дню месяца:
- Щелкните правой кнопкой мыши столбец Name –> Тип изменения –> Дата
- Перейдите на вкладку Преобразование –> Дата –> Месяц –> Конец месяца
- Щелкните правой кнопкой мыши столбец Name –> Переименовать –> Date
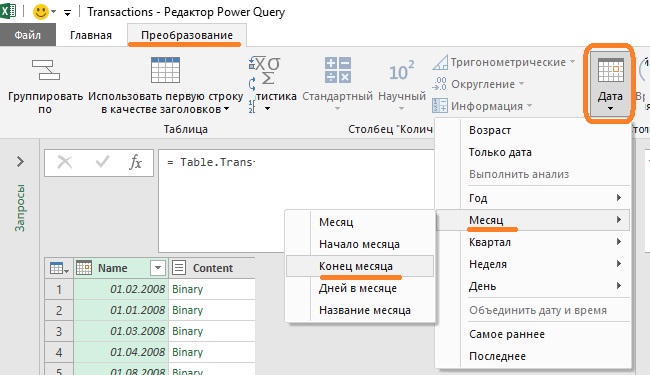
Рис. 4.14. Преобразование первого числа месяца в последнее число месяца
Нет необходимости этот набор дат импортировать с использованием локали, так как Power Query правильно распознает полнотекстовую дату.
Объединение свойств файла с двоичным содержимым
На этом этапе вы готовы объединить даты окончания месяца со всеми строками внутри двоичных файлов. Проблема в том, что стандартное нажатие кнопки объединить двоичные файлы (см. рис. 4.6) выбросит столбец Date, над которым вы так усердно работали. Поэтому вам нужно извлечь содержимое каждого двоичного файла:
- Перейдите на вкладку Добавление столбца –> Настраиваемый столбец
- Введите формулу: =Csv.Document([Content]). Внимание! Формулы Power Query чувствительны к регистру.
- Нажмите Ok
Если вы не хотите вводить длинное имя поля, вы можете просто дважды щелкнуть его в списке полей при создании формулы пользовательского столбца. Это поместит поле в формулу в обрамлении квадратных скобок. В результате появится новый столбец под названием Пользовательская. В каждой строке этого столбца содержится таблица (Table):
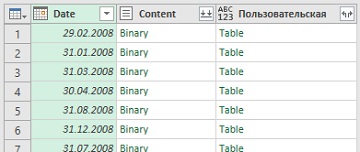
Рис. 4.15. В запрос добавлен пользовательский столбец
Csv.Document() – это функция, которую можно использовать для преобразования содержимого двоичного файла в таблицу. [Content] – просто ссылка на имя столбца. Любопытно, что функции Txt.Document() не существует. Для преобразовать содержимое текстового файла в таблицу, также используете Csv.Document().
Чтобы увидеть, что находится внутри любого из этих двоичных файлов, щелкните пустое пространство рядом со словом Table (1 на ри. 4.16). Откроется окно предварительного просмотра (2). Если вы щелкните на само слово Table, Power Query попытается запустить очередной шаг навигации. Кликните Отмена.
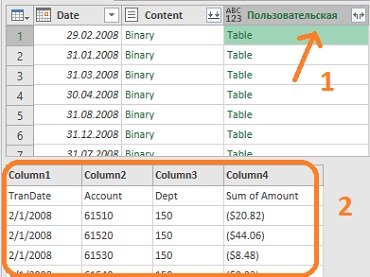
Рис. 4.16. Предварительный просмотр таблицы
Правой кнопкой мыши кликните заголовок столбца Content –> Удалить. Нажмите маленький двуглавый символ стрелки в правом верхнем углу столбца Пользовательский:
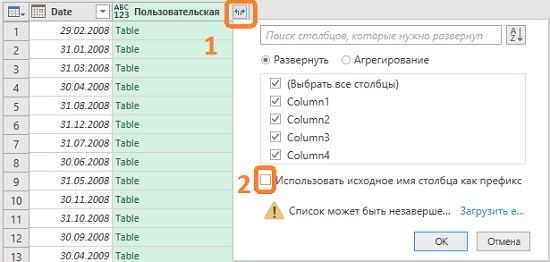
Рис. 4.17. Окно выбора столбцов Table, которые нужно развернуть
Это диалоговое окно позволяет выбрать, какие столбцы следует развернуть. Если некоторые столбцы вам не нужны, снимите галку. Вы уже видели в предварительном просмотре, что каждый из четырех столбцов содержит полезную информацию, поэтому сохраните их все. Снимите флажок Использовать исходное имя столбца как префикс. Если вы оставите его, Power Query добавит префикс Пользовательская к названию каждого столбца. Так что они будут иметь названия Пользовательская.Столбец1, Пользовательская.Column2, и так далее. В нашем случае, это не так важно, так как на следующем шаге вы выполните операцию Использовать первую строку в качестве заголовков.
При нажатии кнопки Ok (рис. 4.17) все столбцы разворачиваются, но Power Query сохраняет столбец Date (в отличие от функции объединения двоичных файлов, которая удалила его). Еще раз подчеркну. Это произошло потому, что мы развернули не двоичные файлы, а пользовательские таблицы.
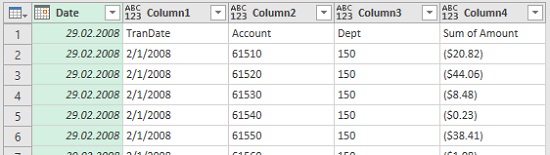
Рис. 4.18. При разворачивании таблиц Table столбец Date сохраняется
Повысьте заголовки. Обратите внимание, что первый столбец Date превратился в 29.02.2008. Переименуйте его в Month End. Удалите шаг Столбец расширенной таблицы1. В первом примере он выполнял функцию разворачивания двоичных файлов. Остальные шаги должны продолжить измененную первую часть запроса (переименование, измененный тип с локалью, удаление ошибок).
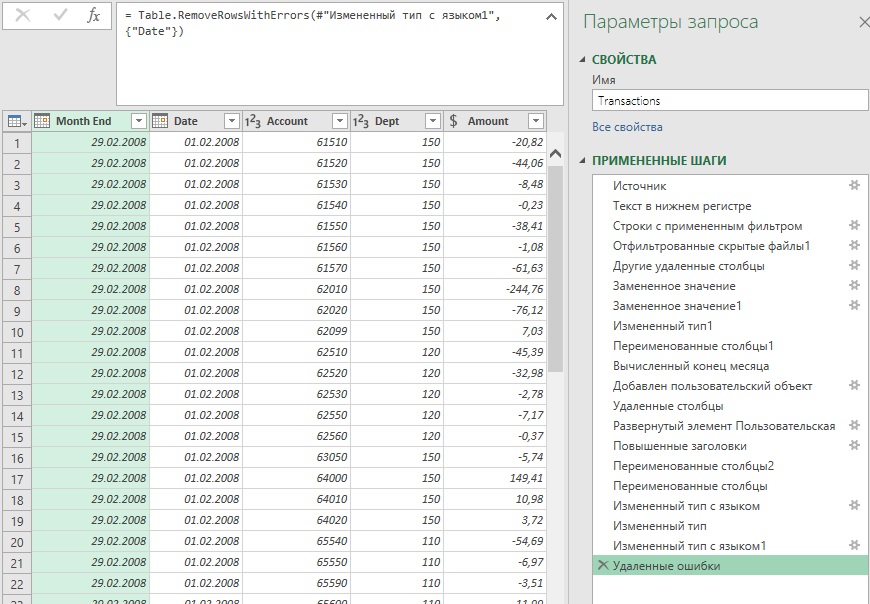
Рис. 4.19. Все файлы, импортированные из папки, сохранили дату на основе свойств файла
Измените имя запроса на ManualCombine. На вкладке Главная кликните Закрыть и загрузить. Если вы обновите сводную таблицу, то увидите, что она соответствует полученной ранее (см. рис. 4.10), с той лишь разницей, что появилось новое поле Month End.
Резюме. Импорт отдельных файлов, как описано в главе 2, как правило, является стартовым, когда вы только осваиваете работу с Power Query. Этот подход хорошо работает если набор данных стабилен, или требования к преобразованию различных файлов отличаются. Если же вы предполагаете, что решение на основе Power Query может масштабироваться, используйте подход, описанный в этой главе. Даже если сегодня в папке будет только один файл. Зато потом вам просто нужно будет поместить новый файл в папку и нажать Обновить. Иногда немного предвидения может значительно облегчить будущие работы.
Power Query умеет подключаться к разным источникам. Далее рассмотрим, как получить данные из книги Excel.
Таблицы Excel
Лучше всего данные хранить в таблице Excel, это самый удобный и распространенный источник для Power Query. На ленте даже есть специальная кнопка.
Чтобы загрузить таблицу в редактор Power Query, достаточно выделить любую ее ячейку и нажать Данные → Получить и преобразовать данные → Из таблицы/диапазона.

Примечание. В вашей версии Excel расположение кнопок и их названия могут отличаться.
Если то же самое проделать с обычным диапазоном, то Excel вначале преобразует диапазон в таблицу Excel, а потом запустит Power Query.

Запросу присваивается имя таблицы Excel, которая является источником данных. Поэтому желательно сразу дать таблице говорящее название. Не обязательно, конечно, но желательно. В противном случае рекомендуется переименовать сам запрос, чтобы затем его можно было легко найти среди других запросов книги.
Данные находятся в Power Query. Новые значения, внесенные в исходную таблицу, автоматически попадут в запрос после его обновления. Далее в редакторе Power Query делают обработку данных и выгружают либо в виде таблицы Excel, либо оставляют в памяти Excel в виде подключения.

Именованный диапазон Excel
Источником для Power Query может быть не только таблица Excel. Например, вы получили красивый отформатированный отчет и не хотите вносить в него изменения. Тогда нужно использовать именованный диапазон. Самый простой способ создать именованный диапазон – это выделить область на листе и ввести название в поле Имя.

Либо выполнить команду Формулы → Определенные имена → Присвоить имя. В Excel будет создан новый объект, к которому можно обращаться, например, в формулах. Диапазон виден в Диспетчере имен.

Здесь перечислены все именованные диапазоны, формулы и таблицы. Среди них есть и только что созданный Отчет.
Теперь можно стать на любую ячейку внутри именованного диапазона (или выбрать его из выпадающего списка в поле Имя) и вызвать ту же команду: Данные → Получить и преобразовать данные → Из таблицы/диапазона. Произойдет загрузка данных в Power Query.

Такой способ позволяет «не портить» исходные данные. Но у него есть и очевидный недостаток: новые строки, которые выйдут за пределы именованного диапазона, не попадут в запрос.
Динамический именованный диапазон Excel
Решить данную проблему можно, создав динамический именованный диапазон. Это такой диапазон, который задается формулой и автоматически расширяется до последней заполненной ячейки.
Внести статичное имя в поле Имя на этот раз не получится. Поэтому заходим в Формулы → Определенные имена → Задать имя (или нажимаем Создать в Диспетчере имен), указываем название будущего динамического диапазона ДинамОтчет и внизу вместо ссылки записываем формулу:
Ко всем ссылкам этой формулы Excel еще автоматически добавит название листа.

Смысл формулы следующий. Верхняя левая ячейка диапазона фиксируется ($A$2), а правая нижняя определяется формулой, которая возвращает адрес последней заполненной строки в столбце B.
Но не все так просто. Excel видит это имя лишь как формулу, а не диапазон. Как же его увидит Power Query? Делаем ход конем.
Создаем пустой запрос Power Query Данные → Получить и преобразовать данные → Получить данные → Из других источников → Пустой запрос. Открывается пустой запрос, где в строке формул нужно ввести:
После ввода формулы (нажатием Enter) Power Query обратится к текущей книге и выведет все объекты, среди которых есть и наш динамический диапазон ДинамОтчет.

Название запроса не подхватывается, поэтому придется изменить самостоятельно.
Чтобы извлечь содержимое объекта, в этой же строке правой кнопкой мыши кликаем по Table, далее выбираем Детализация.

Power Query разворачивает таблицу и даже делает некоторые шаги обработки: повышает заголовки и задает нужный формат для столбцов.

Теперь в запрос будут попадать новые строки, несмотря на то, что исходные данные не являются таблицей Excel.
Вот такие приемы импорта данных в Power Query из книги Excel. Самый распространенный из них – это импорт из таблицы Excel. Тем не менее, в случае необходимости можно прибегнуть к альтернативам, создав именованный или динамический именованный диапазон.
Консолидация данных из разных таблиц Excel
Одна из насущных задач, с которыми сталкиваются пользователи, – консолидация данных. Под консолидацией понимается объединение нескольких таблиц в одну. До появления Power Query это была довольно трудоемкая операция, особенно, если процесс требовал автоматизации. Хотя в эксель есть специальная команда Данные → Работа с данными → Консолидация, пользоваться ей не удобно. Мне, по крайней мере. Появление Power Query в корне изменило представление о том, как нужно объединять таблицы.
Рассмотрим пример. В некоторый файл каждый месяц вносится отчет о продажах в формате таблицы Excel. Каждая таблица при этом имеет соответствующее название: Январь_2018, Февраль_2018 и т.д. Необходимо объединить все таблицы книги в одну. Как бы скопировать и вставить одну под другой, создав при этом дополнительный столбец, указывающий, к какой таблице принадлежит конкретная строка. Задача не одноразовая, а с заделом на будущее, поэтому нужно предусмотреть появление в этом файле новых таблиц.
Процесс начинается с запуска пустого запроса: Данные → Получить и преобразовать данные → Создать запрос → Из других источников → Пустой запрос
Затем в строке формул вводим знакомую команду
Power Query показывает все таблицы в текущей книге.

Их нужно развернуть кнопкой с двумя стрелками в названии поля Content (на скриншоте ниже выделено красным кружком).

Если есть лишние столбцы, то их можно не выводить, сняв соответствующую галку. Также лучше убрать галку напротив опции Использовать исходное имя столбца как префикс. Нажимаем Ok.

Все таблицы находятся на одном листе, а рядом колонка с названием источника, откуда взята каждая строка.
Данные загружены. Можно приступать к их обработке. Ограничимся преобразованием названий таблиц в настоящую дату, чтобы затем использовать для сведения данных по месяцам.
Визуально мы наблюдаем и месяц, и год. Но Power Query такое название воспринимает, как текст. Поэтому делаем следующее.
Удалим нижнее подчеркивание. Правой кнопкой мыши по названию столбца Name → Замена значений.

В следующем окне настроек указываем, что меняем _ на пусто, то есть в нижнем поле ничего не указываем.

Подчеркивание удаляется из названия.
Поиск и замена здесь работает так же, как и в обычном Excel.
Далее запускаем команду Преобразование → Столбец «Дата и время» → Дата → Выполнить анализ.

Power Query распознает дату и меняет формат колонки. Мы также переименовываем столбец на Период.

Полученную таблицу можно использовать для анализа данных. Выгрузим ее на лист Excel.
Главная → Закрыть и загрузить.

Но что-то пошло не так. Во-первых, внизу таблицы пустая строка; во-вторых, при выгрузке произошла одна ошибка. Обновим запрос (справа от названия запроса значок обновления).

Что-то еще больше пошло не так. Даты исчезли, снизу таблицы добавились новые строки, а количество ошибок уже 19. Спокойствие, только спокойствие! Дело вот в чем.
Помните, на первом шаге мы получили все таблицы из файла? Так ведь и выгруженная таблица – это тоже таблица! Получается, Power Query взял 3 исходных таблицы, обработал, выгрузил на лист Excel и на следующем круге видит уже 4 таблицы!

При повторном обновлении запрос захватывает их все, а т.к. таблица выхода имеет другую структуру, то возникают ошибки.
Короче, из запроса нужно исключить таблицу, которая получается на выходе (Запрос1). Есть разные подходы, самый простой – это добавить шаг фильтрации. Выделяем в правой панели первый шаг Источник, открываем фильтр в колонке с названиями, снимаем галку с таблицы Запрос1 → Ok.

Снова выгружаем таблицу в Excel и на этот раз все в порядке.

Сделаем с помощью сводной таблицы маленький отчет по месяцам.

Прошло время, и в файл добавили новую таблицу с продажами за апрель.

Требуется обновить сводный отчет. Представьте на минуту, как это происходит в обычном Эксель: таблица копируется в самый низ общего источника, продлевается колонка с датой, изменяется диапазон для сводной таблицы, обновляется весь отчет.
А вот, как это выглядит при использовании Power Query.
Достаточно два раза нажать кнопку Обновить все (первый раз – для обновления запроса, второй – для сводной таблицы).

На добавление в отчет новых данных вместе с их обработкой потребовалось несколько секунд.
Вот за это мы так любим Power Query.
Читайте также: