
Как сделать нарастающий итог sql
Часто бывает необходимо для каждой строки упорядоченной таблицы подсчитать сумму значений числового столбца из строк, выше- или нижестоящих по порядку, включая данную. Это и есть задача расчета накопительного итога. Например, из таблицы, отсортированной по столбцу time:
нужно получить следующую таблицу:
Для лучшего понимания поставим более конкретную задачу для базы данных "Окраска":
Задача 1
Для каждого момента времени, когда происходила окраска квадрата с q_id = 10, найти суммарное количество потраченной на него краски к этому моменту времени.
Таблица utB включает столбцы b_datetime, b_vol. Для каждого значения X из столбца b_datetime, необходимо подсчитать сумму b_vol по всем строкам, где момент времени b_datetime ≤ X.
Решим задачу двумя самыми распространенными методами.
1) Подзапрос в предложении SELECT
В этом методе предполагается вычисление накопительного итога подзапросом. Поспешив, можно написать следующий запрос:
Однако этот запрос неверный! Дело в том, что квадрат с номером 10 одновременно могли окрашивать разные баллончики, в итоге при таких окрасках получим дубликаты строк:
Ошибка ликвидируется добавлением DISTINCT в первый SELECT, но тогда для каждой строки с одинаковыми значениями b_datetime будет вычисляться подзапрос, а лишь затем устраняться дубликаты. Поэтому в данном случае лучше исключить дубликаты заранее. Например, так:
2) Декартово произведение
Метод заключается в том, что таблица соединяется сама с собой по условию X >= b_datetime. Затем считается сумма b_vol с группировкой по b_datetime. При этом значения X не должны повторяться, иначе в результате одни и те же строки попадут в итоговую сумму несколько раз! Выглядит это следующим образом:
Если в таблице Т2 убрать DISTINCT, то получим следующий ошибочный результат:
Рассмотренный пример специально подобран немного выходящий за рамки темы. Потому, как почти всегда, параллельно с вычислением накопительного итога, необходимо следить за разного рода нюансами. Что и было проделано.
Дополнение
Оба метода требуют нескольких чтений из таблицы. Иногда этого можно избежать, используя генерацию числовой последовательности. Для дальнейших рассуждений переформулируем задачу.
Задача 2
Каждому моменту времени, когда совершалась окраска квадрата с q_id = 10, сопоставить номер окраски в порядке возрастания b_datetime. Для каждого такого номера найти суммарное количество потраченной на квадрат краски к этому моменту времени.
Теперь, если бы мы использовали первый метод, то соединяли бы таблицы с условием не на время, а на номер. Часто так и бывает. И реализация первого метода выглядела бы так:
Здесь использована функция Transact-SQL ROW_NUMBER() для нумерации строк.
Заметим, что таблица T2 представляет собой последовательность натуральных чисел, и для её создания вовсе не обязательно производить чтение из utB! Достаточно просто сгенерировать числовую последовательность. Единственное, что препятствует этому - мы не знаем, сколько членов в последовательности нам понадобится. Зато мы знаем, что b_vol - целое, больше нуля, а количество краски в квадрате не превышает 765. Поэтому достаточно сгенерировать 765 членов. Количество членов можно выяснить и подзапросом, в некоторых случаях это полезно. Всё зависит от задачи. В итоге получим следующий запрос:
В данном случае применение такого приема конечно не оправдано. Но если вместо T1 будет таблица, полученная в результате выполнения сложного ресурсоёмкого запроса, то возможность избежать её соединения с собой (её второе вычисление) значительно повысит производительность. А данный пример взят для простоты изложения.
Оконные функции начинают вести себя интересно, если внутрь OVER добавить ORDER BY .
Посмотри внимательно на столбцы count_current и count_total в результате запроса:
С sum(pi.count) over () AS count_total все понятно. Так как в over ничего не указано, то sum вычисляется по всем строкам.
Но если внутри over написать ORDER BY , то функция будет вычисляться не по всем строкам, а от первой строки и до текущей, включительно (не совсем так конечно, но об этом в следующих заданиях).
Чтобы вычислить агрегатную функцию по окну с указанием ORDER BY внутри over , делай так:
- Разбивай все строки результата на группы в соответствии с PARTITION BY , указанным в over . В нашем случае PARTITION BY опущен, поэтому группа у нас одна - все строки.
- Сортируй строки в группах в порядке, указанном в ORDER BY внутри over .
- Вычисляй функцию последовательно для строк, начиная с первой. Для каждой очередной строки для вычисления значения бери строки от начала и до текущей.
Для наглядности у результате у нас строки отсортированы в том же порядке, что и при вычислении оконной функции.
Для первой строки берем одну единственную строку
С ORDER BY себя так ведут все агрегатные оконные функции, не только sum .

Как будет выглядеть код?
SELECT
DATE,
CITY,
SALES,
SUM(SALES) OVER (PARTITION BY CITY ORDER BY DATE RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS RUNNING_TOTAL
FROM YOUR_TABLE
Умеют ли такое другие DBMS - не в курсе, извиняй.
Зависит от того, какой именно диалект SQL вы используете. В некоторых это сделать не получится.
Можно нарастающую сумму вытащить подзапросом, в MS SQL сработает такой код
select date, city, sales, total=(select sum(sales) from MyTable1 T1 where T1.date
Мы постоянно добавляем новый функционал в основной интерфейс проекта. К сожалению, старые браузеры не в состоянии качественно работать с современными программными продуктами. Для корректной работы используйте последние версии браузеров Chrome, Mozilla Firefox, Opera, Microsoft Edge или установите браузер Atom.

Оконные функции — это мощнейший инструмент аналитика, который с легкостью помогает решать множество задач.
Если вам нужно произвести вычисление над заданным набором строк, объединенных каким-то одним признаком, например идентификатором клиента, вам на помощь придут именно они.
Можно сравнить их с агрегатными функциями, но, в отличие от обычной агрегатной функции, при использовании оконной функции несколько строк не группируются в одну, а продолжают существовать отдельно. При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле. Этот функционал очень полезен для построения аналитических отчетов, расчета скользящего среднего и нарастающих итогов, а также для расчетов различных моделей атрибуции.
Принцип работы

Синтаксис
Окно определяется с помощью обязательной инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
Теперь разберем как поведет себя множество строк при использовании того или иного ключевого слова функции. А тренироваться будем на простой табличке содержащей дату, канал с которого пришел пользователь и количество конверсий:


PARTITION BY
Теперь применим инструкцию PARTITION BY, которая определяет столбец, по которому будет производиться группировка и является ключевой в разделении набора строк на окна:

ORDER BY
Попробуем отсортировать значения внутри окна при помощи ORDER BY:

ROWS или RANGE
Инструкция ROWS позволяет ограничить строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей.
Инструкция RANGE, в отличие от ROWS, работает не со строками, а с диапазоном строк в инструкции ORDER BY. То есть под одной строкой для RANGE могут пониматься несколько физических строк одинаковых по рангу.
Обе инструкции ROWS и RANGE всегда используются вместе с ORDER BY.
В выражении для ограничения строк ROWS или RANGE также можно использовать следующие ключевые слова:
Разберем на примере:

Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Виды функций
Оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM – возвращает сумму значений в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются);
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце.
Пример использования агрегатных функций с оконной инструкцией OVER:

Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках.

Функции смещения
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
- LAG илиLEAD – функция LAG обращается к данным из предыдущей строки окна, а LEAD к данным из следующей строки. Функцию можно использовать для того, чтобы сравнивать текущее значение строки с предыдущим или следующим. Имеет три параметра: столбец, значение которого необходимо вернуть, количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE или LAST_VALUE — с помощью функции можно получить первое и последнее значение в окне. В качестве параметра принимает столбец, значение которого необходимо вернуть.

Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
- CUME_DIST — вычисляет интегральное распределение (относительное положение) значений в окне;
- PERCENT_RANK — вычисляет относительный ранг строки в окне;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить (в этой статье я рассказываю как посчитать медиану, благодаря этой функции);
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP.

Кейс. Модели атрибуции
Благодаря модели атрибуции можно обоснованно оценить вклад каждого канала в достижение конверсии. Давайте попробуем посчитать две разных модели атрибуции с помощью оконных функций.
У нас есть таблица с id посетителя (им может быть Client ID, номер телефона и тп.), датами и количеством посещений сайта, а также с информацией о достигнутых конверсиях.

Первый клик
В Google Analytics стандартной моделью атрибуции является последний непрямой клик. И в данном случае 100% ценности конверсии присваивается последнему каналу в цепочке взаимодействий.
Попробуем посчитать модель по первому взаимодействию, когда 100% ценности конверсии присваивается первому каналу в цепочке при помощи функции FIRST_VALUE.

Произведем агрегацию и получим отчет.

С учетом давности взаимодействий
В этом случае работает правило: чем ближе к конверсии находится точка взаимодействия, тем более ценной она считается. Попробуем рассчитать эту модель при помощи функции DENSE_RANK.

Теперь используем этот запрос для того, чтобы распределить ценность равную 1 (100%) по всем точкам на пути к конверсии.

И теперь, если сделать агрегацию, можно увидеть как распределилась ценность по каналам.

В статье мы рассмотрим возможность Transact-SQL формировать отчеты, как со строкой общего итога, так и со строками промежуточных итогов, для этих целей в MS SQL Server существуют такие операторы как ROLLUP, CUBE и GROUPING SETS, именно о них мы сегодня и поговорим.

Возможность построения отчетов на Transact-SQL очень полезная, мы с Вами уже об этом говорили, когда рассматривали оператор PIVOT, который может транспонировать набор данных, теперь давайте научимся писать запросы, в которых будут выделяться промежуточные итоги и итоги в целом. В Transact-SQL сделать это можно с помощью операторов ROLLUP, CUBE и GROUPING SETS.
Как Вы, наверное, догадываетесь, для того чтобы подсчитать итог или подытог, необходимо прибегнуть к агрегатным функциям и, соответственно, к группировке данных, поэтому операторы ROLLUP, CUBE и GROUPING SETS относятся к конструкции GROUP BY, т.е. являются расширением GROUP BY.
Эти операторы естественно отличаются друг от друга, поэтому в процессе рассмотрения мы будем их сравнивать, но для начала давайте определимся с тестовыми данными для примеров.
Исходные данные для примеров
В качестве SQL сервера у нас будет выступать Microsoft SQL Server Express 2014, а запросы будем писать в Management Studio Express.
Мы как всегда будем использовать выдуманные данные, и в этот раз я предлагаю вот такие, таблицу, которая будет содержать список сотрудников с указанием отдела, в котором они работают, а также сумму их заработка по годам.
А данные вот такие
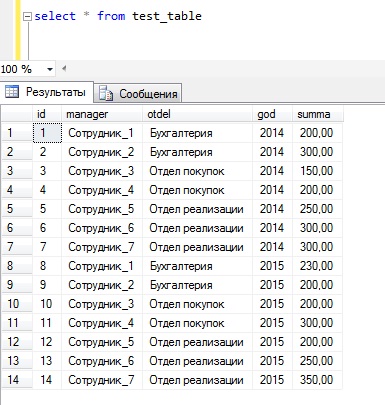
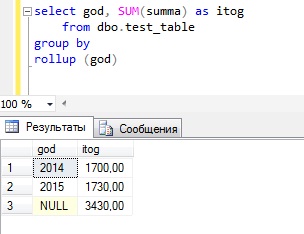
ROLLUP
ROLLUP – оператор Transact-SQL, который формирует промежуточные итоги для каждого указанного элемента и общий итог.
Для того чтобы понять, как работает данный оператор, предлагаю сразу перейти к примерам, и допустим, что нам необходимо получить сумму расхода на оплату труда по отделам и по годам, и сначала давайте попробуем написать запрос с группировкой без использования оператора ROLLUP.
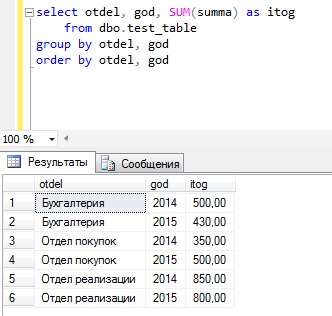
Как видите, группировка у нас получилась и в принципе мы видим что, например, в бухгалтерии в 2014 был такой расход, а 2015 такой, но иногда руководство хочет видеть и общую информацию, например, общий расход по каждому отделу. Для этих целей мы можем использовать оператор ROLLUP.
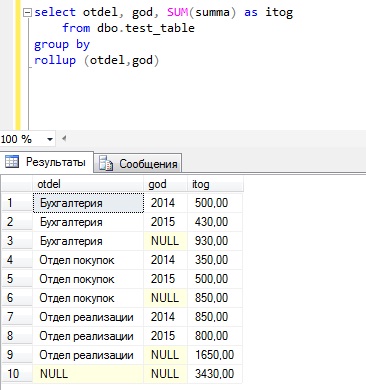
Строки со значением NULL и есть промежуточные итоги по отделам, а самая последняя строка общий итог. Согласитесь, что это уже более наглядно.
Можно также использовать rollup и с группировкой по одному полю, например:
Группировка по отделам с общим итогом
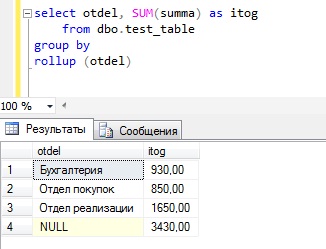
Группировка по годам с общим итогом
CUBE — оператор Transact-SQL, который формирует результаты для всех возможных перекрестных вычислений.
Давайте напишем практически такой же SQL запрос, только вместо rollup укажем cube и посмотрим на полученный результат.
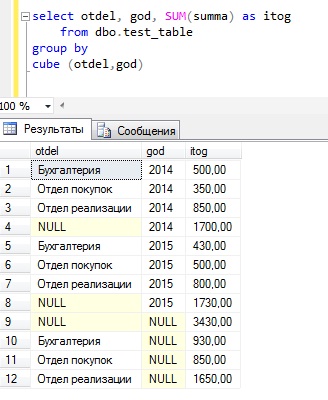
В данном случае отличие от rollup заключается в том, что группировка и промежуточные итоги выполнены как для otdel, так и для god.
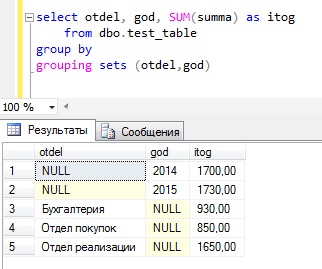
GROUPING SETS
GROUPING SETS – оператор Transact-SQL, который формирует результаты нескольких группировок в один набор данных, другими словами, он эквивалентен конструкции UNION ALL к указанным группам.
Пример GROUPING SETS
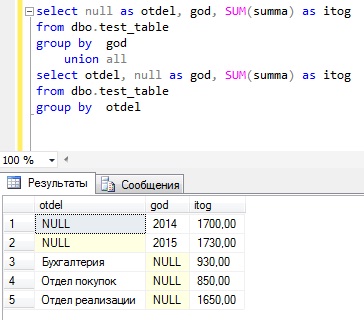
тот же результат, но с использованием UNION ALL
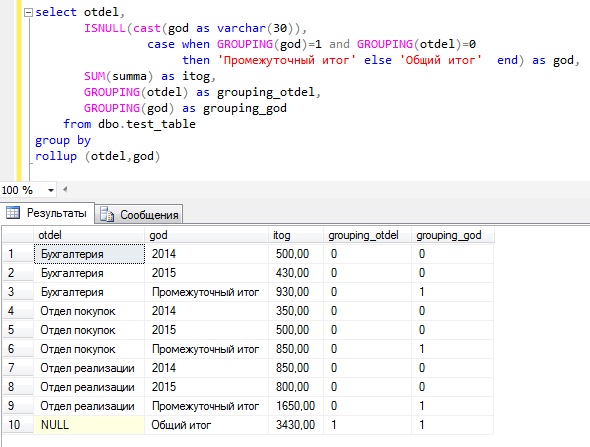
А сейчас предлагаю поговорить еще об одной полезной возможности, которая напрямую относится к перечисленным выше операторам, а именно о функции GROUPING.
GROUPING – функция Transact-SQL, которая возвращает истину, если указанное выражение является статистическим, и ложь, если выражение нестатистическое.
Данная функция создана для того, чтобы отличить статистические строки, которые добавил SQL сервер, от строк, которые и есть сами данные, так как когда используешь много группировок, запутаться в строках очень легко.
Читайте также: