
Как расшифровывается название фреймворка cams для оценки готовности перехода к devops

Собрали небольшой словарик часто употребляемых терминов и сокращений DevOps-инженерами.
Agile (Гибкая разработка программного обеспечения)- методология доставки программного обеспечения, основанная на коротких итерационных этапах разработки, где каждый спринт должен приводить к эксплуатационному продукту. Это позволяет легко корректировать требования проекта в случае необходимости и дает возможность творчества и гибкости в командах разработчиков.
Amazon AWS — Amazon Web Services — самый популярный поставщик облачных услуг (CSP) согласно отчету о состоянии DevOps за 2017 год, предлагающий широкий спектр услуг облачных вычислений для предприятий любого масштаба.
Apache — один из самых популярных веб-серверов с открытым исходным кодом (уступает только NGINX), кроссплатформенный инструмент для запуска веб-сайтов и приложений.
ALB — Балансировка нагрузки приложений — сервис AWS, используемый для разделения входящего трафика между несколькими экземплярами приложений в нескольких зонах доступности для обеспечения бесперебойной работы вашего приложения.
ASG — Auto Scaling Group — сервис AWS, используемый для объединения нескольких экземпляров EC2 в логические группы в целях проектирования инфраструктуры и простоты управления; группа состоит из идентичных экземпляров, которые добавляются или удаляются в соответствии с требованиями рабочей нагрузки.
AWS CLI — интерфейс командной строки AWS — инструмент AWS для управления различными сервисами и продуктами AWS из терминала командной строки.
Bastion host — специальный сервер, используемый для доступа к частным сетям и противостояния хакерским атакам. Обычно размещает одно приложение (например, прокси-сервер) и ключи SSH для доступа и управления базовой облачной инфраструктурой.
Ветвление — ветви представляют собой отдельные копии кода проекта на GitHub или другой системе контроля версий кода, что позволяет многим разработчикам работать над проектом одновременно.
Bucket — логическая единица в Amazon S3 (Simple Storage Service), используемая для хранения нескольких типов объектов (в основном, различных данных и метаданных, которые их описывают).
Back-end — программный движок, к которому у пользователя нет прямого доступа. Этот механизм получает запросы от пользовательского интерфейса и выполняет определенные операции, включая загрузку и сохранение данных в базе данных и т.д.
Сборка — это конкретная версия программного кода, в основном называемая этапом разработки новых функций. Наиболее важными являются сборки Canary, где новый код тестируется на соответствие существующим функциональным возможностям приложения в рабочей среде.
Bare-metal — случай, когда программное обеспечение установлено на физических устройствах (жестких дисках), пропуская уровень виртуализации.
Canary release — промежуточный сервер, который является точной копией производственной среды. Там запускаются новые сборки программного обеспечения, чтобы обеспечить соответствие существующим функциям и коду перед развертыванием их для всей пользовательской базы.
CI / CD — Непрерывная интеграция / Непрерывная доставка — основа современной культуры DevOps. CI гарантирует, что новый код передается в централизованное хранилище кода несколько раз в день, чтобы пройти автоматические модульные тесты и ускорить сборку нового программного обеспечения. Если тесты пройдены успешно, CD гарантирует, что новая версия приложения будет автоматически отправлена в промежуточную и производственную среды без простоев службы. Рабочий процесс CI / CD гарантирует, что все ошибки будут найдены и исправлены на ранней стадии, а продукт будет доступен в любое время.
Кластер — это набор взаимосвязанных экземпляров ( серверы без поддержки , виртуальные машины, модули Kubernetes и т. Д.), Которые рассматриваются как единое целое для обеспечения балансировки нагрузки, автоматического масштабирования и высокой доступности.
Commit (Комит) — процесс отправки кода в репозиторий Git и полученный фрагмент кода.
Управление конфигурацией — процесс установки и поддержания требуемых параметров программной экосистемы с помощью инструментов автоматического управления конфигурацией, таких как Kubernetes, Ansible, Puppet, Chef, Saltstack и т. Д.
DevOps — методология доставки программного обеспечения, а также набор практик, рабочих процессов и инструментов, необходимых для обеспечения надежной автоматизации ИТ-операций с постоянным повышением качества.
Dark launch (Темный запуск) — практика выпуска кода в производственную среду без уведомления пользователей о новых доступных функциях. Код запускается в производство для заключительного этапа тестирования, затем объявляется о выпуске новой функции, а сама функция уже доступна.
Docker — платформа с открытым исходным кодом для создания, доставки и запуска контейнеров приложений. Docker является основой современных облачных вычислений, поскольку он позволяет максимально эффективно использовать облачные ресурсы, обеспечивая повсеместный уровень для построения облачной инфраструктуры.
Фреймворк Django — это высокоуровневый фреймворк Python, ориентированный на чистый дизайн, быструю разработку и высокую производительность приложений. Нашел широкое применение в веб-разработке и обработке больших данных.
Datadog — эффективный сервис облачного мониторинга, позволяющий анализировать процессы в любой инфраструктуре, базе данных или приложении в любом масштабе, используя платформу на основе SaaS.
Среда (Environment) — все ресурсы сервера (ОС, библиотеки, API, инструменты и платформы и т. Д.), Необходимые для запуска программного обеспечения на различных этапах его жизненного цикла (разработка, тестирование, подготовка, производство).
ElasticSearch — RESTful, распределенный движок для поиска и анализа данных, построенный на Apache Lucene. Как ядро стека Elastic, Elasticsearch позволяет хранить и обрабатывать данные из нескольких облачных инструментов мониторинга и ведения журналов.
Envoy — мощный прокси C ++ для обработки трафика между микросервисами.
FluentD — инструмент для сбора и обработки данных с открытым исходным кодом, написанный на Ruby. Он позволяет вводить данные из огромного количества инструментов, таких как ElasticSearch, и выводить данные на широкий выбор панелей мониторинга, настроенных с использованием нескольких плагинов.
Fargate — Amazon Fargate — это сервис Amazon для запуска контейнеров Docker в управляемой инфраструктуре, такой как EKS, без необходимости что-либо настраивать. Он работает по схеме выставления счетов без сервера — вы указываете, что необходимо сделать, и оплачиваете потребляемые ресурсы без какой-либо ручной настройки кластера.
Helm — менеджер приложений, работающий поверх Kubernetes. Этот инструмент позволяет управлять микросервисами в масштабе с помощью удобных диаграмм Хелма и обеспечивает бесперебойную работу сложной инфраструктуры Kubernetes.
Инфраструктура — весь комплекс оборудования, программного обеспечения и процессов, необходимых для запуска приложений, а также для сбора, управления и хранения данных.
IaC — Инфраструктура как код — один из базовых принципов DevOps. Это означает, что конфигурация инфраструктуры выполняется с помощью машиночитаемых декларативных файлов, а не вручную или с использованием интерактивных инструментов. Эти файлы (например, манифесты Kubernetes или Terraform ) могут храниться в репозиториях GitHub, настраиваться и корректироваться так же, как и код, что обеспечивает эффективную автоматизацию обеспечения инфраструктуры.
IaaS — инфраструктура как услуга, модель управления ИТ, в которой вычислительные ресурсы и службы, необходимые для их работы, предоставляются в качестве службы, обеспечивающей функционирование различных платформ и приложений.
Пропускная способность ввода / вывода — количество операций ввода / вывода в секунду, характеристика пропускной способности сети или накопителя.
Ingress controller — программный модуль, используемый для обеспечения балансировки нагрузки в модулях Kubernetes.
Jenkins — Java-сервер с открытым исходным кодом, позволяющий автоматизировать доставку программного обеспечения.
Работа в Jenkins — процесс в Jenkins, необходимый для сборки кода, запуска модульных тестов, генерации метрик качества кода, развертывания новых версий приложений в рабочей среде и т. д.
Kibana — часть стека Elastic, отвечающая за визуализацию данных и навигацию по кластеру ELK.
Logstash — часть стека Elastic, отвечающая за сбор, обработку и передачу данных на сервер. Logstash необходим для создания решений для облачного мониторинга .
Lead time (Время выполнения) — время, необходимое для перемещения нового пакета кода из коммита в релиз.
MTTR — среднее время до восстановления — среднее ожидаемое время, когда отказавший системный компонент снова заработает; основной параметр сценариев восстановления после сбоев, системного стресс-тестирования и проверки производительности.
Node (узел, нода) — физическая или виртуальная машина в кластере Kubernetes, используемая для размещения модулей, которые запускают контейнеры Docker.
Node pool (Пул узлов) — пул узлов Kubernetes — это группа из нескольких точек кластера, объединяющих машины с одинаковой конфигурацией, которые по сути можно рассматривать и управлять ими как одним объектом.
Nexus3 — платформа управления выпуском от Sonatype, созданная для объединения входных сигналов от нескольких модулей с открытым исходным кодом, чтобы обеспечить быстрый, безопасный и эффективный жизненный цикл доставки программного обеспечения.
OpenStack — платформа с открытым исходным кодом для создания локальных облачных инфраструктур.
OpenShift — платформа управления контейнерами корпоративного уровня для Kubernetes, работающая в локальных облачных инфраструктурах, разработанная Red Hat.
PaaS — платформа как услуга, модель доставки программного обеспечения, когда разработчики получают все необходимые библиотеки, инструменты и сервисы для разработки программного обеспечения со всей базовой инфраструктурой, которая обрабатывается платформой, предоставляющей сервис.
Prometheus — решение для облачного мониторинга с открытым исходным кодом с мощным языком запросов, базой данных временных рядов, моделью данных измерений и возможностями интеллектуального оповещения.
Pod — базовое структурное подразделение Kubernetes, группа контейнеров Docker, развернутых на одном хосте.
Playbook — Ansible playbook — это инструкции по развертыванию инфраструктуры с подробными руководствами по выполнению серии команд для выполнения конкретных задач.
ProxMox — основанная на Debian платформа с открытым исходным кодом для развертывания и управления виртуальными машинами.
Production environment (PROD, Производственная среда)- среда, в которой программный продукт или услуга используется целевой аудиторией.
Rollback (Откат) — ручное или автоматическое восстановление ранее сохраненного состояния программы или базы данных.
Regression testing (Регрессионное тестирование) — комплексное тестирование обновленной версии продукта, чтобы убедиться, что последняя сборка не оказала негативного влияния на уже имеющуюся функциональность.
S3 — Amazon Simple Storage Service — сервис облачных вычислений для хранения любых объектов данных, необходимых для стабильной работы ваших приложений.
Snapshot (Amazon EBS snapshot EBS) — команда для создания статической копии содержимого вашего экземпляра EC2 в целях резервного копирования и восстановления.
Staging environment (Stage, промежуточная среда) — контролируемая копия вашей производственной среды, максимально напоминающая ее. Это позволяет тестировать новые версии программного обеспечения, чтобы находить ошибки перед выпуском в эксплуатацию.
Technical debt (Технический долг) — концепция нежелательного количества работы разработчиков, необходимого для исправления простого кода, используемого для быстрого получения результатов, вместо того, чтобы тратить время на разработку и внедрение наилучшего решения.
Модульное тестирование (Unit testing) — основа CI / CD, модульное тестирование — это практика тестирования кода приложения небольшими блоками на основе кода автоматизированного тестирования перед сборкой приложения, чтобы минимизировать время, необходимое для обнаружения и исправления ошибок, сокращая время выхода на рынок.
VPC peering — AWS VPC — это сервис, который логически изолирует определенное количество общедоступного облака AWS для создания виртуальных частных облаков. AWS VPC peering позволяет объединить ресурсы нескольких таких облаков в случае необходимости.
Vault — продукт Hashicorp для безопасного хранения таких секретов, как ключи SSH, токены, пароли, ключи API и другие важные элементы инфраструктуры Kubernetes.
Zabbix — сервис мониторинга облачной инфраструктуры с открытым исходным кодом для отслеживания состояния различных сетевых ресурсов и сервисов. Состоит из сервера и агентов, которые обеспечивают интеллектуальное оповещение для распределенных систем.

CALMS — это фреймворк для оценки готовности компании к внедрению процессов DevOps, а также способ измерить успешность внедрения DevOps. Эту аббревиатуру придумал Джез Хамбл, один из авторов книги The DevOps Handbook (Руководство по DevOps). Она расшифровывается как «культура, автоматизация, бережливость, измерения и распространение знаний».
Культура
DevOps — это не просто процесс или другой подход к разработке. Это изменение корпоративной культуры. Основной составляющей культуры DevOps является сотрудничество.
Никакие инструменты и средства автоматизации не помогут, если разработчики и специалисты сферы ИТ / операционной поддержки не объединят усилия. DevOps не решает проблемы с инструментарием — DevOps решает проблемы, связанные с человеческим фактором.
DevOps можно рассматривать как развитие команд, следующих принципам agile, однако в этом случае также включены команды по эксплуатации. Верной стратегией будет формировать команды, ориентированные на продукт, а не на выполнение определенных функций. Определите умения, необходимые для создания долгосрочного продукта, включая разработку, контроль качества, управление продуктом, проектирование, деятельность по эксплуатации, управление проектами и т. д. Не стоит поручать все одной команде или нанимать «профессионалов DevOps»; гораздо важнее сформировать команды на основе продукта, которые будут эффективно сотрудничать.
Есть вещи, которые укрепляют сотрудничество, например стремление к общей цели и наличие плана для ее совместного достижения. В некоторых компаниях внезапный переход к формированию команд на основе продукта может стать слишком радикальной и преждевременной мерой. Поэтому нужно предпринимать более осторожные действия. Команды разработчиков могут (и должны) пригласить соответствующих участников команд по эксплуатации к участию в планировании спринтов, ежедневных стендапах и демонстрациях спринтов. Команды по эксплуатации могут пригласить на свои собрания главных разработчиков. Так — легко и непринужденно — они могут оставаться в курсе работы, идей и проблем друг друга.
Связанные материалы
Сведения о преимуществах DevOps
Связанные материалы
Создание культуры DevOps
Проблемы и экстренные ситуации как нельзя лучше проверяют культуру DevOps. Способны ли разработчики, инженеры по эксплуатации и специалисты по работе с клиентами вместе штурмовать проблему и решать ее, как одна команда? Ищет ли команда способ улучшить результаты при устранении будущих проблем во время разбора инцидента (вместо поиска виноватых)? Если ответ на эти вопросы «Да», значит, в вашей организации существует культура DevOps.
Наиболее успешные компании внедряют культуру DevOps в каждом отделе и на всех уровнях организационной структуры. Для такого широкого масштаба термин «DevOps» часто оказывается слишком узким и не используется. Такие компании имеют открытые каналы для коммуникации и часто общаются. Они руководствуются принципом, по которому удовлетворенность клиента в равной степени зависит от усилий команды по управлению продуктами и команды разработчиков. Они понимают, что DevOps — задача не для одной команды. Это задача для всех сотрудников.
Автоматизация
Автоматизация позволяет устранить монотонную ручную работу, сформировать воспроизводимые процессы и создать надежные системы.
Создание сборок, тестирование, развертывание и реализация автоматизации — вот с чего обычно начинают команды, еще не использующие эти принципы в работе. И еще: какая цель может сплотить разработчиков, тестировщиков и операторов лучше, чем построение систем, пользу от которых получат все участники процесса?
Команды, ранее не использовавшие автоматизацию, обычно начинают с непрерывной поставки — метода, который предполагает прогон каждого изменения кода через серию автоматизированных тестов (часто с использованием облачной инфраструктуры) — с последующей упаковкой сборок и их продвижением через среды с помощью автоматизированных развертываний.
«Почему?», — спросите вы. Компьютеры выполняют тестирование строже и добросовестнее, чем люди. Благодаря этим тестам можно раньше выявить баги и уязвимости. Наконец, при автоматизированных развертываниях специалисты по ИТ/эксплуатации получают оповещения об отклонениях среды, что позволяет минимизировать неожиданности в момент выпуска релиза.
Еще одно важное преимущество DevOps — использование принципа «конфигурация как код». Разработчики стремятся создать модульные, компонуемые приложения: такие приложения более надежны и удобны в обслуживании. Этот принцип применим и к инфраструктурам, в которых размещаются приложения, — как к облачным, так и к локальным сетевым ресурсам компании.
«Конфигурация как код» и «непрерывная поставка» — этим варианты автоматизации в мире DevOps не ограничиваются, но они заслуживают отдельного упоминания, так как позволяют улучшить взаимодействие между разработчиками и операционными командами. И когда DevOps использует автоматизированные развертывания для отправки тщательно протестированного кода в идентично настроенные среды, проверка работоспособности ПО на отдельных машинах теряет актуальность.
Бережливость
При упоминании слова «бережливый» в контексте программного обеспечения на ум сразу приходят мысли об устранении действий с низкой полезностью и ускорении процессов — то есть о том, как стать более решительными и гибкими. Еще более актуальными для DevOps являются понятия непрерывного совершенствования и принятия поражений, которые закладывают основу экспериментального мышления.
Люди с мышлением DevOps находят возможности для непрерывного совершенствования повсюду. Некоторые возможности — например, проведение регулярных ретроспектив для совершенствования процессов в команде — лежат на поверхности. Другие — например, A/B-тестирование различных подходов к адаптации новых пользователей продукта — не столь очевидны.
Благодаря agile-разработке идея о непрерывном совершенствовании стала модной. Первые приверженцы agile-методики доказали, что простой продукт, отданный клиенту сегодня, гораздо ценнее идеального продукта, отданного клиенту через полгода. Если продукт постоянно совершенствуется, клиент будет и дальше использовать его.
Кстати, вы знаете, что неудачи неизбежны? Поэтому стоит учить свою команду принимать поражения, восстанавливаться после них и делать соответствующие выводы (некоторые называют этот процесс «антихрупкостью»). Мы в Atlassian считаем, что если вы периодически не сталкиваетесь с неудачами, значит, вы работаете не в полную силу.
В контексте DevOps сбои не рассматриваются как проступки, за которые последует наказание. Команды признают, что однажды все может пойти наперекосяк, поэтому при выполнении сборки закладывается возможность быстрого обнаружения проблем и оперативного восстановления. Во время разбора инцидентов акцент делается не на поиске виноватых, а на местах «обрушения» процессов и их укреплении. Почему? Потому что непрерывное совершенствование и сбои тесно связаны между собой.
Измерения
Измерить можно практически все. Но это не значит, что вам обязательно нужно измерять все показатели. Давайте обратимся к agile-разработке и начнем с основ.
- Сколько времени проходит от разработки до развертывания?
- Как часто ошибки или сбои возникают повторно?
- Как долго выполняется восстановление после системного сбоя?
- Сколько человек использует ваш продукт в настоящее время?
- Каким был приток/отток пользователей на этой неделе?
При наличии прочного основания проще фиксировать более сложные показатели по использованию возможностей, путям клиентов и соглашениям об уровне обслуживания (SLA). Полученные данные пригодятся при разработке дорожных карт и определении дальнейших шагов.
Благодаря этим замечательным данным вашей команде будет проще принимать решения, и, что еще важнее, этой информацией можно делиться с другими, в частности с командами из других отделов. Например, ваша маркетинговая команда хочет получить новые эффектные функции, которые можно продать. Но в данный момент вы наблюдаете высокий отток клиентов из-за значительного технического долга в продукте. Подкрепив дорожную карту пользовательскими данными (даже если продукт требует множества исправлений при малом количестве функций), вам будет проще достигнуть консенсуса и получить одобрение со стороны заинтересованных лиц.
Обмен
Извечный конфликт между командами по разработке и эксплуатации во многом обусловлен отсутствием общих целей. Мы считаем, что совместная ответственность и общий успех помогают сгладить разногласия. Отношение к разработчикам сразу улучшится, если они помогут команде по эксплуатации с одной из самых тяжелых задач — обработкой заявок (раньше это называлось «работой с пейджером»). В основе DevOps лежит идея о том, что выпуском и обеспечением работы приложения должны заниматься люди, которые выполняли его разработку.
Из этой идеи родилась фраза «кто разработал, тот и поддерживает», которая побуждает команды к активному участию. Это не значит, что вам нужно нанять разработчиков, и они по мановению волшебной палочки сразу станут отличными операторами. Это значит, что разработчикам и операторам нужно взаимодействовать в течение всего жизненного цикла приложения. Более того, отчеты показали, что улучшить показатели поставки и повысить производительность можно лишь благодаря проверке кода и продуктов со стороны коллег. Внешние проверяющие оказались не более эффективными, чем полный отказ от проверок.
В командах, использующих DevOps, часто вводится совмещенная должность, в рамках которой разработчики решают проблемы, выявленные конечными пользователями, и одновременно выявляют и устраняют неполадки в рабочей версии продукта. Такие специалисты занимаются решением срочных проблем, выявленных клиентами, при необходимости создают патчи и работают в бэклоге с неисправностями, выявленными клиентами. «Разработчик на поддержке» получает обширную информацию о работе приложения в реальных условиях. А благодаря высокой доступности команд разработчиков для операционной команды, между этими командами возникает доверие и взаимное уважение.
Как бы сильно мы ни желали, чтобы по мановению волшебной палочки все команды превратились в высокоэффективные команды DevOps, в реальности такое превращение потребует сочетания методов, принципов культуры и инструментов. Но, как вы уже знаете, преимущества от преодоления разобщенности между командами по разработке и эксплуатации того стоят. Вас ждет повышение доверия, более быстрый выпуск релизов, повышение надежности развертываний и ускорение цикла обратной связи между командами и клиентами.
Внедрение методики DevOps — непростая задача. И тем не менее при наличии правильного настроя, усилий и инструментов организация может внедрить принципы DevOps, которые дают значительные преимущества.

During his career, he has successfully managed enterprise software development tools in all phases of their lifecycle, from cradle to grave. He has driven organization-wide process improvement with results of greater productivity, higher quality, and improved customer satisfaction. He has built multi-national agile teams that value self-direction and self-organization. When not speaking or coding, you are likely to find Ian indulging his passions in parsers, meta-programming, and domain-specific languages.

Разработка (development) и эксплуатация (operations) продолжительное время были изолированными модулями. Код писали программисты, а системные администраторы отвечали за его развертывание и интеграцию. В рамках одного проекта специалисты работали отдельно, поскольку связь между двумя разрозненными хранилищами была ограничена.
Этот метод работал с 1970 года, пока доминировала каскадная модель процесса разработки программного обеспечения, известная как Waterfall. Методика предполагала последовательный переход между этапами без пропусков и возвращений на предыдущие стадии.
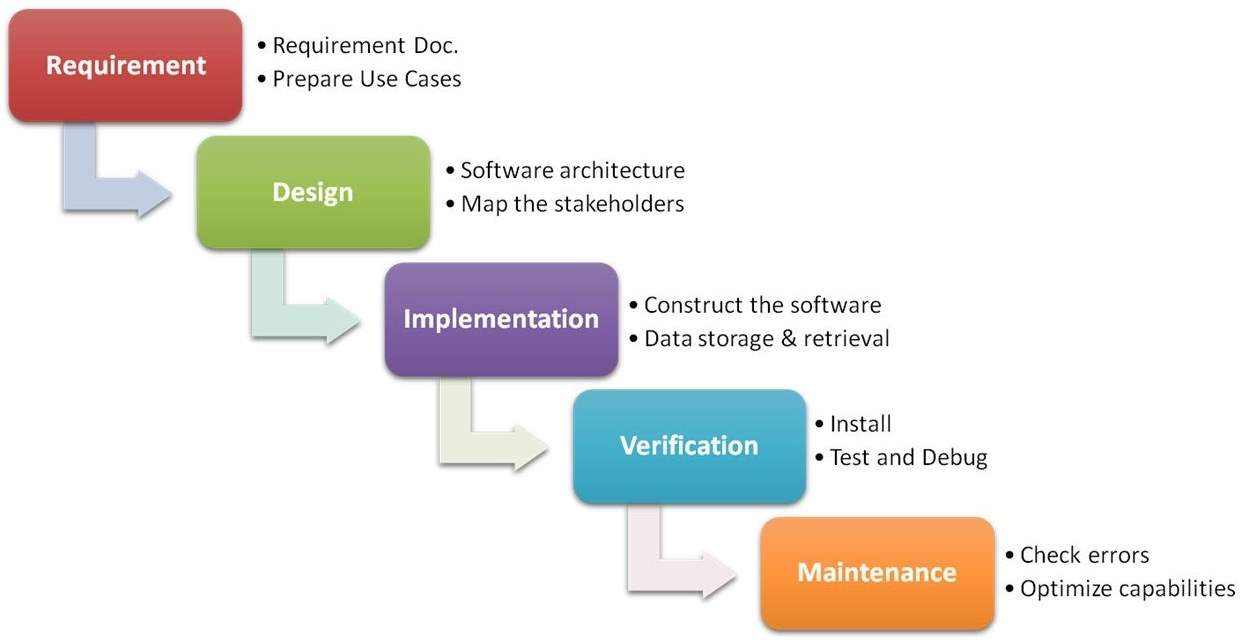
Схема методологии Waterfall
Со временем Waterfall была раскритикована за недостаточную гибкость, а ее основная цель – формальное управление проектом, приносила ущерб срокам, стоимости и качеству.
Команды нуждались в гибкости во время разработки программного обеспечения. Необходимость реализации проекта в форме коротких "спринтов" и выпуска более частых (от двух недель, до двух дней) релизов потребовали нового подхода.В 2001 году на смену Waterfall пришла гибкая методология разработки или Agile. Она включает ряд подходов и практик, основанных на четырех ценностях и 12 принципах «Манифеста гибкой разработки программного обеспечения» . Сюда также относят SCRUM , Kanban , Lean , Feature-driven development (FDD) и другие сходные подходы.
Agile применяется к организации работы небольших групп, которые создают продукт короткими итерациями (от двух до четырех недель). Каждая итерация выглядит как программный проект, который включает все типовые задачи: планирование, анализ требований, проектирование, программирование, тестирование, документирование. В конце итерации заказчик получает рабочий продукт.

Схема подхода Agile
Методология Agile критиковали за отсутствие управления требованиями. Заказчик может выставить новые требования в конце каждой итерации, что противоречит архитектуре уже созданного продукта. Частые изменения и усовершенствования продукта могут привести к массовому рефакторингу и плавающей стоимости проекта в итоге.
Идея и культура DevOps
Методология DevOps получила широкое распространение после организованной бельгийским разработчиком Патриком Дебуа в 2009 году конференции DevOpsDays. Главная идея DevOps заключается в том, чтобы устранить перекладывание ответственности на других членов команды в больших коллективах. Взаимозависимость между созданием и эксплуатацией программного обеспечения преследовала цель привить команде новую культуру разработки продукта.Культура DevOps предполагает, что каждый из членов команды ответственен за конечный результат. Базируется она на нескольких основных положениях:
- Регулярное сотрудничество и общение. Команда должна работать слаженно, понимать потребности и ожидания всех ее членов.
- Постепенное развертывание. Внедрение постепенного развертывания позволяет группам доставки выпускать продукт, имея возможность вносить обновления и делать откат, если что-то пойдет не так.
- Общая ответственность. Все члены команды должны двигаться к единой цели и отвечать за проект в равной степени.
- Решение проблем на ранних этапах. Методология DevOps требует, чтобы в жизненном цикле проекта задачи выполнялись как можно быстрее. Это помогает оперативно решать возникшие проблемы.
Принципы DevOps
В 2010 году Дэймоном Эдвардсом и Джоном Уиллисом была разработана модель CAMS, ключевые идеи которой стали принципами DevOps. Согласно ей, развитие DevOps идет в трех направлениях: люди, процессы и инструменты. При этом важна поддержка каждого пункта на всех этапах развития.
Аббревиатура CAMS расшифровывается следующим образом:
Классические бизнес-модели в IT разделяют специалистов по разработке и эксплуатации на две отдельные группы. До появления DevOps они общались на разных языках, ведь перед разработчиками стояла задача быстро внедрять инновации, а операционный персонал отвечал за поддержание стабильной среды и инфраструктуры.
Конкурирующие рабочие цели создавали между специалистами по разработке и эксплуатации недопонимание, поэтому основная задача DevOps – изменить бизнес-культуру, разделить ответственность двух групп и объединить их профессиональные навыки.
Автоматизация
Следуя пути DevOps, код требуется переводить из стадии разработки в производство непрерывно в автоматическом режиме, поэтому автоматизацию можно считать синонимом DevOps.
В идеале автоматизировать нужно почти все:
- инфраструктуру;
- выпуски программного обеспечения ( software releases) ;
- тестирование;
- развертывание;
- основные задачи по безопасности;
- политику соглашений;
- задачи управления конфигурацией.
Автоматизация упрощает рабочие процессы, сокращает количество сбоев и откатов, уменьшает количество ошибок, которые возникают при ручной настройке. Повышение эффективности, улучшение производительности и польза для конечного потребителя – главные преимущества автоматизации.
Измерение необходимо для постоянного предложения ценности и улучшений. В DevOps важно отслеживать ключевые показатели, которые зависят от целей проекта.
Измерять нужно показатели следующих процессов:
- мониторинга и отслеживания производительности на протяжении всего жизненного цикла разработки программного обеспечения;
- сбора, анализа и предоставления способов реагирования на обратную связь;
- анализа ошибок и способов их предотвращения;
- оказания помощи командам в работе над общими целями.
DevOps способствует развитию только в том случае, если конкретные показатели собираются и анализируются непрерывно.
DevOps подразумевает тесное сотрудничество специалистов по разработке и эксплуатации. Большое внимание уделяется прозрачности и открытости в коллективе. Чем больше знаний распространяется между сотрудниками, тем больше обратной связи они получают – это помогает улучшить их работу в целом.
DevOps и Agile
DevOps является естественным продолжением гибких подходов и подходов к непрерывной доставке. DevOps и Agile могут дополнять друг друга и применяться в тандеме, но сравнивать эти методологии не стоит.По сути DevOps объединяет две разрозненные команды (разработку и эксплуатацию), чтобы обеспечить быстрые выпуски программного обеспечения. Agile ориентирован на сотрудничество небольших команд друг с другом для быстрого реагирования на изменчивые потребности пользователей.
Основные различия между DevOps и Agile:
- Разработка, тестирование и развертывание программного обеспечения происходят как в DevOps, так и в Agile. Подход Agile характерен тем, что разработка завершается сразу после развертывания. DevOps же включает операции, которые происходят постоянно, например, мониторинг и модификации программного обеспечения;
- В Agile разные специалисты несут ответственность за разработку, тестирование и развертывание программного обеспечения. В DevOps за все эти процессы отвечают специально обученные инженеры;
- Agile выступает за поэтапное развертывание после каждого спринта. Для DevOps характерна непрерывная доставка (до нескольких раз в день).
Жизненный цикл DevOps
Выделим основные этапы проекта, следующего принципам DevOps:
- Непрерывное развитие;
- Непрерывная интеграция;
- Непрерывное тестирование;
- Непрерывное развертывание;
- Непрерывный мониторинг;
- Постоянная обратная связь.
Эти этапы гарантируют оптимизацию всех процессов разработки, от предложения до производства и поставки.
Непрерывное развитие
На первом этапе происходит планирование и кодирование программного обеспечения, а также формируется видение проекта.
Код может быть написан на любом языке, но поддерживается с помощью средств контроля версий. Процесс поддержки называется управлением исходным кодом (SCM). В нем используются следующие инструменты: Git, SVN, Mercurial, CVS и JIRA.Непрерывная интег рация
На этом этапе чаще всего применяется Jenkins. Когда в репозитории Git происходят изменения, Jenkins извлекает обновленный код и готовит сборку. Упакованный код переходит к следующему этапу и пересылается либо на рабочий, либо на тестовый сервер.
Этап включает в себя не только компиляцию кода, но и проверку, модульное тестирование, интеграционное тестирование и упаковку. Непрерывная интеграция нового кода в существующий исходный код помогает отразить изменения для конечных пользователей.Непрерывное тестирование
На этапе непрерывного тестирования разрабатываемое программное обеспечение проверяется на наличие ошибок. Автоматическое тестирование позволяет разработчикам экономить силы и время.
Для непрерывного тестирования используются следующие инструменты: Selenium, TestNG, JUnit и т.д. Они позволяют инженерам QA тестировать несколько баз кода параллельно, чтобы гарантировать отсутствие недостатков в функциональности. При этом тестируемое приложение часто запускается в виртуальной среде или контейнерах, например, с помощью Docker.Автоматическое тестирование выполняет Selenium, а отчеты генерирует TestNG. Весь этап можно автоматизировать с помощью инструмента непрерывной интеграции Jenkins. В конце, протестированный код повторно отправляется на этап непрерывной интеграции для обновления исходного кода.
Непрерывное развертывание
Когда код развертывается на производственных серверах, важно получить корректный результат на всех серверах.
Управление конфигурацией – ключевой процесс на этом этапе. Он обеспечивает точное развертывание приложения и поддерживает согласованность конфигураций на всех серверах.
Ansible, Puppet и Chef – инструменты, которые чаще всего используются в DevOps для быстрого и непрерывного развертывания нового кода.Не менее важную роль на данном этапе играют инструменты контейнеризации. Vagrant и Docker обеспечивают согласованность в различных средах – от разработки и тестирования, до подготовки и производства.
Непрерывный мониторинг
Важный этап жизненного цикла DevOps, на котором в реальном времени отслеживается производительность приложения. Для этого автоматически собираются определенные показатели телеметрии и метаданных, а также настраиваются оповещения об отклонениях в работе.
Непрерывный мониторинг помогает поддерживать доступность сервисов. Он также определяет угрозы и основные причины повторяющихся системных ошибок, а проблемы безопасности автоматически решаются в момент появления.
Активное участие в непрерывном мониторинге участвуют операционные группы. Они наблюдают за действиями пользователей, проверяют системы на предмет необычного поведения и отслеживают наличие ошибок.
Для этого используются следующие популярные инструменты: Prometheus, Splunk, ELK Stack, Nagios и другие. Они обеспечивают полный контроль над производительностью системы, рабочего сервера и приложения.Постоянная обратная связь
Непрерывная обратная связь – особый этап, на котором анализируются улучшения, сделанные на этапах непрерывного тестирования и непрерывной интеграции.Чтобы оценить результаты изменений в конечном продукте, необходимо получить обратную связь от клиентов. Процесс разработки приложения обновляется с учетом их отзывов – после этого разработчики начинают вносить изменения в продукт. Когда отзывы становятся положительными, открывается путь для выпуска новых версий, либо для поддержки приложения.

Павел Олейников (OPM)
Рейтинг: 320
Автоматизация процессов разработки с применением DevOps-практик помогает получать более качественный и осмысленный результат. На конференции Infostart Event 2019 Inception в ходе мастер-класса «Практика применения DevOps» команда Инфостарта разложила «по полочкам» инструментарий, который используется для каждого из процессов DevOps, и показала, как работать с ними на практике. В первой части выступил Павел Олейников – он сделал обзор инструментов, которые можно использовать при автоматизации процессов разработки, и рассказал про работу с Git (в том числе в EDT).Меня зовут Павел Олейников, я представляю команду Инфостарта, и в этом мастер-классе я и мои коллеги Светлана Попова, Виталий Подымников и Валерий Пронин расскажем вам о том, как можно применять практики DevOps при разработке в 1С – какие для этого есть инструменты в принципе, что из этого мы используем в своей работе, и как именно мы эти инструменты применяем.
Мастер-класс будет разбит на четыре части:
Я расскажу про процессы DevOps, инструменты, используемые для каждого из них, и про работу с Git;
а Валерий с учетом того, что мы показали, сделает скрипт для Jenkins, который будет собирать проект, тестировать его и выдавать в результате – либо релиз в виде cf-файла, либо рассылку в почту об ошибках.
Процессы DevOps

Эмиль Карапетян в своем докладе рассказал, что такое DevOps и как его использовать в команде разработчиков. А мы более подробно рассмотрим его процессы.
Coding – это написание кода, управление версиями, качество кода;
Testing – тестирование приложения;
Packaging – сборка релиза;
Releasing – управление обновлением рабочей базы;
Configuring – управление инфраструктурой;
И Monitoring – это контроль того, как все это работает с точки зрения железа и с точки зрения отзывов от пользователей (сбор обратной связи).

Coding. В процессе написания кода нам могут понадобиться следующие инструменты:
конфигуратор 1С и хранилище 1С в качестве системы управления версиями;
мы можем вести разработку в EDT и хранить исходники в локальном хранилище Git, используя GitLab при совместной работе с кодом;
для проверки качества кода мы можем использовать SonarQube с плагином BSL, а при непосредственной работе в EDT – плагин BSL, который написал Александр Капралов;
так как мы разрабатываем в EDT, мы можем редактировать код, используя обычный блокнот или редактор VS Code (это удобно, если вносить небольшие изменения именно в код, а не в формы). Вообще VS Code + Git очень удобно использовать даже в качестве обычной записной книжки, чтобы писать доклад и всегда иметь возможность просмотреть историю изменений – тогда и Dropbox не нужен.
OneScript – кроссплатформенная реализация виртуальной машины, которая позволяет писать на языке 1С скрипты по автоматизации различных действий и запускать их из консоли. Создатель OneScript – Андрей Овсянкин.
И Jenkins – чтобы все это автоматизировать. Потому что, можно запускать эти процессы вручную, можно написать для этого батники, а можно использовать Jenkins и построить сборочную линию, которая будет все это запускать по очереди.

Building. Второй процесс – сборка. Здесь тоже используется:
Jenkins – чтобы запускать скрипты автоматически;
OneScript – чтобы команды в скриптах были на знакомом языке;
а 1С и EDT здесь нужны, потому что команды OneScript для сборки конфигураций, которые дальше будут тестироваться, запускают или тот же конфигуратор 1С в пакетном режиме, или утилиту ring от EDT.

Testing. Для тестирования приложений можно использовать:
«Сценарное тестирование» от фирмы «1С» либо связку СППР и Vanessa Automation. Светлана Попова в своем докладе более подробно расскажет, какие плюсы и минусы от этих вариантов мы увидели.
Jenkins – чтобы все это запускалось автоматически;
OneScript – чтобы скрипты по запуску инструментов тестирования были на знакомом языке;
и Allure – для красивого представления отчетов.

Packaging, Releasing – при автоматизированной сборке релиза и обновлении рабочей базы у нас используется все то же самое, что было на процессе Building – это Jenkins, 1С, EDT, OneScript.

Процессы Configuring и Monitoring я объединил, потому что у нас в Инфостарте инфраструктурой занимаются внешние подрядчики, и все инструменты, показанные на слайде, пока находятся не у нас – мы отсюда используем только BPM, это наша внутренняя система для учета задач, заявок.
Методология DevOps
DevOps – это не только автоматизация работы, это также регламенты, инструкции, способы работы.
Получается, что даже набор правил, регламентов, внутренних инструкций для разработчиков в вашей компании – это тоже DevOps, потому что DevOps не говорит про автоматизацию, он говорит про то, что процессы должны быть.
И мы все этим занимаемся. Мы все пишем код, договариваемся, кто, как его будет писать. Мы можем использовать правила из стандартов разработки фирмы «1С», можем придумывать для своих команд свои правила. Но если мы соблюдаем правила, это значит, мы уже в принципе проводим какой-то анализ кода. То же самое с тестированием – если вы хотя бы запускаете отчет и видите, что он что-то выдает, вы делаете маленькое, но тестирование.
Я к тому, что мы все всегда занимаемся DevOps, он у нас есть. Одни процессы могут быть не сильно развиты, другие отработаны лучше, но в каком-то виде он все равно есть. И то, что мы называем DevOps – это:
В первую очередь завязано на регламентацию процессов – чтобы эти процессы были не просто придуманы, а еще и где-то зафиксированы, и все их понимали.
И второе – чтобы эти процессы были автоматизированы и запускались сами. Чтобы программист писал код и не думал о том, как обновлять базу. Он пишет код, а всем остальным занимаются другие инженеры.
Варианты использования практик DevOps
Давайте посмотрим, какие сборочные линии из этих инструментов можно сделать.
Первый вариант – разработка в конфигураторе через хранилище

Это самый простой вариант для старта, когда:
программисты работают так, как они привыкли – они пишут код в конфигураторе 1С и отправляют в хранилище то, что написали;
дальше мы автоматизировано выгружаем исходники из хранилища 1С в Git с помощью GitSync – при выгрузке в хранилище у нас каждое помещение в хранилище будет отдельным коммитом, и в принципе можно будет отследить, кто, что туда положил;
потом по выгруженным исходникам запускаем проверку качества с помощью SonarQube;
после проверки качества проводится тестирование;
и в случае, если все хорошо, мы можем из файлов, которые находятся в Git, подготовить cf и дальше релизить его на рабочую базу (либо в базу для демонстрации и уже оттуда обновлять – здесь все зависит от того, у кого какие процессы).
Второй вариант – разработка в EDT через Git

Мы попробовали перевести разработку некоторых наших решений в EDT – это удобная платформа, интересная, со своими нюансами. Если привыкнуть к тому, что она еще сырая (там еще не все работает корректно), то почти идеально. Иногда бывают ошибки, но есть очень много плюсов, которые мне лично понравились.
В этом случае разработчики пишут код непосредственно в EDT;
EDT сразу связано с Git, сам проект в EDT – это набор файлов, который уже находится в локальном репозитории.
Непосредственно в процессе написания кода в EDT мы проверяем его качество с помощью BSL-плагина от Александра Капралова – чтобы сам программист посмотрел, что он там написал.
А когда разработчики выгружают свои изменения конфигурации в общую ветку develop, у нас отдельно запускается проверка качества с помощью SonarQube. Эта проверка показывает ситуацию в целом – кто сколько допустил ошибок, насколько дублируется код у разных разработчиков – потому что такое тоже может быть.

Как можно использовать сам Git?
Можно использовать вариант, когда у нас есть одна ветка master и каждый разработчик создает под себя отдельную ветку, в которой что-то меняет, тестирует, а потом заливает в master.
Можно все ветки разработчиков выгружать в ветку develop, где будет проходить тестирование, а ветку master вести отдельно, и выгружать туда только протестированнные изменения – такой вариант используется у нас.
А можно обратиться к опыту разработчиков, которые создали методику GitFlow. В ней есть две обязательные ветки:
master – это рабочая система;
develop (основная ветка, с которой ведется работа);
под каждую задачу создаются отдельные ветки, в которых ведется разработка;
после того как содержимое ветки develop протестировали, данные отправляются в ветку release, а оттуда уже в master;
если вдруг возникает необходимость внести быстрые изменения, появляется ветка maintenance, в которую вносятся изменения, и они сразу же мержатся и в master, и в develop, а из develop во все ветки задач. Это нужно для того, чтобы ветки разработчиков у нас всегда были более продвинутыми (пусть даже не всегда протестированными и рабочими), чем master, и чтобы никакие изменения не потерялись.
Практика работы с Git
Давайте перейдем к практике, посмотрим, что такое Git.
Git – это система, которая позволяет контролировать, как изменяются файлы, поэтому использование Git для конфигураций 1С стало возможным после того, как платформа 1С научилась выгружать исходники конфигураций в виде файлов. Это позволило вести версионный контроль изменений кода, не заглядывая в хранилище 1С.
Чтобы создать хранилище Git, мне привычнее использовать консоль, потому что, как оказалось, во многих приложениях для работы с Git перевод некоторых команд на русский язык сбивает с толку – мне проще писать команды в консоли просто на английском.

После того, как вы поставите Git на Windows, у вас в контекстном меню появится возможность открыть для этого каталога консоль (Git Bash Here).

Открываем консоль и создаем репозиторий командой
При этом в открытом каталоге сразу создалась папка .git, в которой будет храниться вся информация об истории и настройках этого репозитория.

Мы здесь просто создадим текстовый файл и добавим его в индекс командой
В индексе Git хранит информацию о том, что именно он будет сохранять в дальнейшем.

Git сохраняет изменения не в любой момент, когда мы что-то изменяем в репозитории – для сохранения нужно «закоммитить» изменения.
Текущий коммит в Git я сохраняю командой
В этот момент сохраняется слепок состояния файла.

Если мы сделаем команду:

Если мы сейчас добавим какой-то текст в файл, который лежит в Git, то, когда я спрошу: «Что случилось с этой папкой» по команде:
Git подсказывает, что файл был изменен.

Опять добавляем изменения в индекс:
И делаем еще один коммит.

Для перехода между ветками или коммитами есть команда checkout, с помощью которой мы можем создать ветку test:
Git нам из текущего состояния создал ветку test и сразу перешел на нее.

Давайте внесем изменения в файл – добавим еще одну строку.
А теперь посмотрим, как эти изменения отразятся в Git – занесем изменения в индекс и сделаем еще один коммит.
Сейчас наш текстовый документ, который находится в ветке test, содержит две строки. На самом деле Git в своей папке хранит и предыдущий файл, который был в ветке master.

Чтобы его получить, мы просто переходим в ветку master:
Обратите внимание, у нас в файле осталась только первая строка.
То есть Git для каждого измененного проиндексированного файла в момент коммита сохраняет слепок состояния, а в своей базе хранит состояния на момент коммитов.
Работа с Git в EDT
Когда мы разрабатываем в EDT, то у нас конфигурация – это набор файлов, с которыми точно так же можно работать в Git, просто этих файлов будет больше – масштаб будет другой.
Давайте запустим EDT и посмотрим, как в нем можно работать с Git.

В EDT мы ведем разработку конфигурации «Конференция». Это та самая программа, в которой вас регистрировали при входе на мероприятие.

Как видите, проект в EDT – это просто набор файлов.

Мы можем открыть этот каталог в текстовом редакторе и просто внести сюда какие-то изменения прямо в модули.

Например, находясь в среде VS Code, изменим модуль справочника «Призы» – добавим в него комментарий.

Вернемся в EDT и видим, что она тоже отследила, что мы изменили модуль справочника «Призы» изменения, и у нас в модуле объекта появился комментарий.

При переключении между ветками EDT динамически подхватывается состояние проекта. Например, создадим новую ветку командой:

И в новой ветке поменяем конфигурацию – удалим с формы списка справочника «Участники» какие-нибудь элементы.

И даже если мы зафиксируем изменения командой:
А потом вернемся на нашу основную ветку:

И мы видим, что форма вернулась. То есть мы можем ошибиться в одной ветке, но вернуться обратно, как будто ничего не было. А про ту ветку просто забываем, как про страшный сон.
В следующих частях продолжим рассказывать:
Данная статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2019 Inception. Больше статей можно прочитать здесь.
Читайте также: