
Как работает память микропроцессора
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес --> Линейный (виртуальный)--> Физический

Все линейное адресное пространство разбито на сегменты. Адресное пространство каждого процесса имеет по крайней мере три сегмента:
Сегмент кода. (содержит команды из нашей программы, которые будут исполнятся.)
Сегмент данных. (Содержит данные, то бишь переменные)
Сегмент стека, про который я писал выше.
Линейный адрес вычисляется по формуле:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Базовый адрес сегмента кода берется из регистра CS. Значение смещения для сегмента кода берется из регистра EIP, в котором хранится адрес инструкции, после исполнения которой, значение EIP увеличивается на размер этой команды. Если команда занимает 4 байта, то значение EIP увеличивается на 4 байта и будет указывать уже на следующую инструкцию. Все это делается автоматически без участия программиста.
Сегментов кода может быть несколько в нашей памяти. В нашем случае он один.
Сегмент данных
Данные загружаются в регистры DS, ES, FS, GS
Это значит что сегментов данных может быть до 4х. На нашей картинке он один.
Смещение внутри сегмента данных задается как операнд команды. По дефолту используется сегмент на который указывает регистр DS. Для того чтобы войти в другой сегмент надо это непосредственно указать в команде префикса замены сегмента.
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес.
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке:
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
В зависимости от 55 G-бита(гранулярити), предел может измеряться в байтах при нулевом значении бита и тогда максимальный предел составит 1 мб, или в значении 1, предел измеряется страницами, каждая из которых равна 4кб. и максимальный размер такого сегмента будет 4Гб.
Для сегмента стека предел будет в интервале:
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.

Расмотрим теперь непосредственно память микропроцессора.
Микросхема ROM.
В предыдущей статье мы поговорили об адресных шинах, шинах данных, о каналах RD WR. Эти шины и каналы соединяются с RAM, с ROM либо в наиболее часто встречающихся случаях и с RAM и с ROM. В нашем демонстрационном микропроцессоре (схема в предыдущей статье) есть адресная шина шириной 8 битов и шина данных шириной 8 битов. Это означает, что микропроцессор может адресовать (2 8 ) 256 байтов памяти, и может считать или записать 8 битов памяти за один раз.
ROM обозначает постоянную память и имеет постоянные предварительно установленные байты информации. Адресная шина говорит микросхеме ROM, какой байт получить и поместить в шину данных. Когда декодер открывает канал read, микросхема ROM представляет выбранный её байт на шину данных.
Микросхема RAM.

RAM обозначает оперативную память и содержит байты информации, которые микропроцессор может считывать либо записывать в зависимости от поставленных задач. Одна проблема с сегодняшними микросхемами RAM состоит в том, что они забывают все, как только питание уходит. Именно поэтому компьютер и нуждается в ROM.
К сведению…, все компьютеры содержат постоянную память. Возможно создать простой компьютер, который не будет иметь RAM, т.к. много микроконтроллеров помещают свою горстку байтов для RAM непосредственно в микросхему процессора, а вот создать компьютер, который не содержит ROM невозможно. В персональных компьютерах ROM называют BIOS (Базовая система ввода-вывода). Когда микропроцессор запускается, он начинает выполнять инструкции, которые находятся непосредственно в BIOS. Инструкции BIOS запускают тестирование аппаратных средств в машине, после прохождения, которого переходит к жесткому диску для поиска загрузочной записи. Этот загрузочный сектор – скажем маленькая программа (набор инструкций) BIOS помещает в RAM и микропроцессор тогда начинает выполнять инструкции уже этого загрузочного сектора из RAM. Программа загрузочного сектора говорит микропроцессору, что еще необходимо считать с жесткого диска в RAM поочередно, согласно приоритетам. Таким образом микропроцессор загружает установленную операционную систему и переходит уже непосредственно к выполнению её команд.
Инструкции по микропроцессору.
Даже у невероятно простого микропроцессора, показанного в предыдущем примере, будет довольно большой набор инструкций. Этот набор инструкций выполнен как битовые комбинации, у каждой из которых есть различное значение, когда она загружена в регистр инструкций. Как правило люди не особенно хорошо запоминают битовых комбинаций команд, поэтому для процессоров определен ряд коротких слов с определенными значениями, для представления различных битовых комбинаций. Эту набор слов называют ассемблером процессора. Ассемблер может перевести слова на их битовые комбинации очень легко, и затем уже перекодированная информация ассемблера помещается в память микропроцессора для выполнения.
Приведу небольшой (не полный) набор инструкций по ассемблеру, которые программист может использовать для микропроцессора в нашем примере:
- LOADA mem – Загрузка значения регистра А из памяти;
- LOADB mem - Загрузка значения регистра В из памяти;
- CONB con – Загрузка константы в регистр В;
- SAVEB mem - Сохранение значения регистра В в памяти;
- SAVEC mem - Сохранение значения регистра С в памяти;
- ADD – Суммировать А и В и сохранить в С;
- SUB - Вычесть А и В и сохранить в С;
- MUL - Умножить A и B и сохранить результат в C;
- DIV - Разделить A и B и сохранить результат в C;
- COM - Сравнить A и B и сохранить результат в тестовом регистре;
- JUMP addr – Перейти по адресу;
- JEQ addr – Перейти по адресу если равно;
- JNEQ addr - Перейти по адресу если не равно;
- JG addr - Перейти по адресу если больше;
- JGE addr - Перейти по адресу если больше или равно;
- JL addr - Перейти по адресу если меньше;
- JLE addr Перейти по адресу если меньше или равно;
- STOP – Остановить выполнение. И т.д.
Вот такими командами руководствуется микропроцессор в процессе работы, которые содержаться в ROM, регистре команд и декодере инструкций.
При работе процессора и выполнения команд ассемблера число доступных транзисторов имеет огромный эффект на производительность процессора. Как было замечено ранее, типичная инструкция в процессоре 8088 взяла бы 15 тактов, чтобы выполниться. Из-за проекта множителя потребовалось приблизительно 80 циклов только, чтобы сделать одно 16-разрядное умножение на 8088. С большим количеством транзисторов намного множители увеличиваются, и следовательно процессор будет способен к выполнению вычислений за один цикл.
Увеличения числа транзисторов способствовало возникновению технологии конвейерной обработки, так в конвейерной архитектуре, выполнение инструкций перекрывают друг друга. К примеру если процессору бы потребовалось пять тактов, чтобы выполнить каждую инструкцию, то при конвейерной архитектуре может быть пять инструкций на различных этапах выполнения одновременно. И образно это, похоже, что одна инструкция завершает каждый такт.
У многих современных процессоров есть декодеры многоадресной команды и каждый декодер имеет собственный конвейер. Декодеры учитывают потоки многоадресной команды, и это значит, что больше чем одна инструкция может завершиться во время каждого такта. Такой метод работы является довольно сложным процессом, и соответственно для него требуется большое количество транзисторов.
Тенденции
Тенденция в проекте процессора прежде всего была к полным 32-разрядным ALU с быстрым выполнением операций с плавающей точкой встроенным конвейерным выполнением с потоками многоадресной команды. Последние разработки это - 64-разрядные ALU, и как мы знаеи 64 разрядные процессоры уже полностью поглотили рынок. Также была тенденция к специальным инструкциям (как инструкции MMX), которые делают определенные операции особенно эффективно, планируется добавление аппаратной поддержки виртуальной памяти и L1, кэширующегося на микросхеме процессора. Все эти тенденции увеличивают количество транзисторов, приводя их количество к многомиллионным транзисторным станциям, которые доступны уже сегодня. Эти процессоры могут выполнить приблизительно несколько миллиардов инструкций в секунду!

В англоязычной литературе микропроцессор часто называют CPU (central processing unit, [единым] модулем центрального процессора). Причина такого названия кроется в том, что современный процессор представляет собою единый чип. Первый микропроцессор в истории человечества был создан корпорацией Intel в далеком 1971 году.
Роль Intel в истории микропроцессорной индустрии

Речь идет о модели Intel 4004. Мощным он не был и умел выполнять только действия сложения и вычитания. Одновременно он мог обрабатывать всего четыре бита информации (то есть был 4-битным). Но для своего времени его появление стало значительным событием. Ведь весь процессор поместился в одном чипе. До появления Intel 4004, компьютеры базировались на целом наборе чипов или дискретных компонентов (транзисторов). Микропроцессор 4004 лег в основу одного из первых портативных калькуляторов.
Далее процессоры начали развиваться и обрастать мощью. Каждый, кто хоть немного знаком с историей микропроцессорной индустрии, помнит, что на смену 8088 пришли 80286. Затем настал черед 80386, за которым следовали 80486. Потом были несколько поколений «Пентиумов»: Pentium, Pentium II, III и Pentium 4. Все это «интеловские» процессоры, основанные на базовой конструкции 8088. Они обладали обратной совместимостью. Это значит, что Pentium 4 мог обработать любой фрагмент кода для 8088, но делал это со скоростью, возросшей примерно в пять тысяч раз. С тех пор прошло не так много лет, но успели смениться еще несколько поколений микропроцессоров.
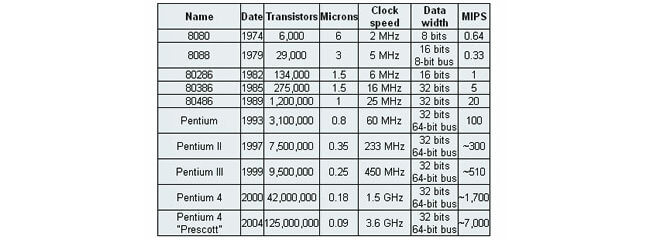
С 2004 года Intel начала предлагать многоядерные процессоры. Число используемых в них транзисторов возросло на миллионы. Но даже сейчас процессор подчиняется тем общим правилам, которые были созданы для ранних чипов. В таблице отражена история микропроцессоров Intel до 2004 года (включительно). Мы сделаем некоторые пояснения к тому, что означают отраженные в ней показатели:
Существует непосредственная связь между тактовой частотой, а также количеством транзисторов и числом операций, выполняемых процессором за одну секунду. Например, тактовая частота процессора 8088 достигала 5 МГЦ, а производительность: всего 0,33 миллиона операций в секунду. То есть на выполнение одной инструкции требовалось порядка 15 тактов процессора. В 2004 году процессоры уже могли выполнять по две инструкции за один такт. Это улучшение было обеспечено увеличением количества процессоров в чипе.
Чип также называют интегральной микросхемой (или просто микросхемой). Чаще всего это маленькая и тонкая кремниевая пластинка, в которую «впечатаны» транзисторы. Чип, сторона которого достигает двух с половиной сантиметров, может содержать десятки миллионов транзисторов. Простейшие процессоры могут быть квадратиками со стороной всего в несколько миллиметров. И этого размера достаточно для нескольких тысяч транзисторов.
Логика микропроцессора

Чтобы понять, как работает микропроцессор, следует изучить логику, на которой он основан, а также познакомиться с языком ассемблера. Это родной язык микропроцессора.
Микропроцессор способен выполнять определенный набор машинных инструкций (команд). Оперируя этими командами, процессор выполняет три основные задачи:
- C помощью своего арифметико-логического устройства, процессор выполняет математические действия: сложение, вычитание, умножение и деление. Современные микропроцессоры полностью поддерживают операции с плавающей точкой (с помощью специального арифметического процессора операций с плавающей точкой)
- Микропроцессор способен перемещать данные из одного типа памяти в другой
- Микропроцессор обладает способностью принимать решение и, на основании принятого им решения, «перепрыгивать», то есть переключаться на выполнение нового набора команд
- Address bus (адресную шину). Ширина этой шины может составлять 8, 16 или 32 бита. Она занимается отправкой адреса в память
- Data bus (шину данных): шириной 8, 16, 32 или 64 бита. Эта шина может отправлять данные в память или принимать их из памяти. Когда говорят о «битности» процессора, речь идет о ширине шины данных
- Каналы RD (read, чтения) и WR (write, записи), обеспечивающие взаимодействие с памятью
- Clock line (шина синхронизирующих импульсов), обеспечивающая такты процессора
- Reset line (шина стирания, шина сброса), обнуляющая значение счетчика команд и перезапускающая выполнение инструкций
На данной диаграмме не отображены линии управления дешифратора команд, которые можно выразить в виде следующих «приказов»:
- «Регистру A принять значение, поступающее в настоящий момент от шины данных»
- «Регистру B принять значение, поступающее в настоящий момент от шины данных»
- «Регистру C принять значение, поступающее в настоящий момент от арифметико-логического устройства»
- «Регистру счетчика команд принять значение, поступающее в настоящий момент от шины данных»
- «Адресному регистру принять значение, поступающее в настоящий момент от шины данных»
- «Регистру команд принять значение, поступающее в настоящий момент от шины данных»
- «Счетчику команд увеличить значение [на единицу]»
- «Счетчику команд обнулиться»
- «Активировать один из из шести буферов сортировки» (шесть отдельных линий управления)
- «Сообщить арифметико-логическому устройству, какую операцию ему выполнять»
- «Тестовому регистру принять тестовые биты из АЛУ»
- «Активировать RD (канал чтения)»
- «Активировать WR (канал записи)»
В дешифратор команд поступают биты данных из тестового регистра, канала синхронизации, а также из регистра команд. Если максимально упростить описание задач дешифратора инструкций, то можно сказать, что именно этот модуль «подсказывает» процессору, что необходимо сделать в данный момент.
Память микропроцессора

Знакомство с подробностями, касающимися компьютерной памяти и ее иерархии помогут лучше понять содержание этого раздела.
Выше мы писали о шинах (адресной и данных), а также о каналах чтения (RD) и записи (WR). Эти шины и каналы соединены с памятью: оперативной (ОЗУ, RAM) и постоянным запоминающим устройством (ПЗУ, ROM). В нашем примере рассматривается микропроцессор, ширина каждой из шин которого составляет 8 бит. Это значит, что он способен выполнять адресацию 256 байт (два в восьмой степени). В один момент времени он может считывать из памяти или записывать в нее 8 бит данных. Предположим, что этот простой микропроцессор располагает 128 байтами ПЗУ (начиная с адреса 0) или 128 байтами оперативной памяти (начиная с адреса 128).
Модуль постоянной памяти содержит определенный предварительно установленный постоянный набор байт. Адресная шина запрашивает у ПЗУ определенный байт, который следует передать шине данных. Когда канал чтения (RD) меняет свое состояние, модуль ПЗУ предоставляет запрошенный байт шине данных. То есть в данном случае возможно только чтение данных.
Из оперативной памяти процессор может не только считывать информацию, он способен также записывать в нее данные. В зависимости от того, чтение или запись осуществляется, сигнал поступает либо через канал чтения (RD), либо через канал записи (WR). К сожалению, оперативная память энергозависима. При отключении питания она теряет все размещенные в ней данные. По этой причине компьютеру необходимо энергонезависимое постоянное запоминающее устройство.
Более того, теоретически компьютер может обойтись и вовсе без оперативной памяти. Многие микроконтроллеры позволяют размещать необходимые байты данных непосредственно в чип процессора. Но без ПЗУ обойтись невозможно. В персональных компьютерах ПЗУ называется базовой системой ввода и вывода (БСВВ, BIOS, Basic Input/Output System). Свою работу при запуске микропроцессор начинает с выполнения команд, найденных им в BIOS.
Команды BIOS выполняют тестирование аппаратного обеспечения компьютера, а затем они обращаются к жесткому диску и выбирают загрузочный сектор. Этот загрузочный сектор является отдельной небольшой программой, которую BIOS сначала считывает с диска, а затем размещает в оперативной памяти. После этого микропроцессор начинает выполнять команды расположенного в ОЗУ загрузочного сектора. Программа загрузочного сектора сообщает микропроцессору о том, какие данные (предназначенные для последующего выполнения процессором) следует дополнительно переместить с жесткого диска в оперативную память. Именно так происходит процесс загрузки процессором операционной системы.
Инструкции микропроцессора

Даже простейший микропроцессор способен обрабатывать достаточно большой набор инструкций. Набор инструкций является своего рода шаблоном. Каждая из этих загружаемых в регистр команд инструкций имеет свое значение. Людям непросто запомнить последовательность битов, поэтому каждая инструкция описывается в виде короткого слова, каждое из которых отражает определенную команду. Эти слова составляют язык ассемблера процессора. Ассемблер переводит эти слова на понятный процессору язык двоичных кодов.
Приведем список слов-команд языка ассемблера для условного простого процессора, который мы рассматриваем в качестве примера к нашему повествованию:
Английские слова, обозначающие выполняемые действия, в скобках приведены неспроста. Так мы можем видеть, что язык ассемблера (как и многие другие языки программирования) основан на английском языке, то есть на привычном средстве общения тех людей, которые создавали цифровые технологии.
Работа микропроцессора на примере вычисления факториала

Рассмотрим работу микропроцессора на конкретном примере выполнения им простой программы, которая вычисляет факториал от числа «5». Сначала решим эту задачку «в тетради»:
факториал от 5 = 5! = 5 * 4 * 3 * 2 * 1 = 120
На языке программирования C этот фрагмент кода, выполняющего данное вычисление, будет выглядеть следующим образом:
Когда эта программа завершит свою работу, переменная f будет содержать значение факториала от пяти.
Компилятор C транслирует (то есть переводит) этот код в набор инструкций языка ассемблера. В рассматриваемом нами процессоре оперативная память начинается с адреса 128, а постоянная память (которая содержит язык ассемблера) начинается с адреса 0. Следовательно, на языке данного процессора эта программа будет выглядеть так:
// Предположим, что a по адресу 128// Предположим, что F по адресу 1290 CONB 1 // a=1;1 SAVEB 1282 CONB 1 // f=1;3 SAVEB 1294 LOADA 128 // if a > 5 the jump to 175 CONB 56 COM7 JG 178 LOADA 129 // f=f*a;9 LOADB 12810 MUL11 SAVEC 12912 LOADA 128 // a=a+1;13 CONB 114 ADD15 SAVEC 12816 JUMP 4 // loop back to if17 STOP
Теперь возникает следующий вопрос: а как же все эти команды выглядят в постоянной памяти? Каждая из этих инструкций должна быть представлена в виде двоичного числа. Чтобы упростить понимание материала, предположим, что каждая из команд языка ассемблера рассматриваемого нами процессора имеет уникальный номер:
Будем считать эти порядковые номера кодами машинных команд (opcodes). Их еще называют кодами операций. При таком допущении, наша небольшая программа в постоянной памяти будет представлена в таком виде:
// Предположим, что a по адресу 128// Предположим, что F по адресу 129Addr машинная команда/значение0 3 // CONB 11 12 4 // SAVEB 1283 1284 3 // CONB 15 16 4 // SAVEB 1297 1298 1 // LOADA 1289 12810 3 // CONB 511 512 10 // COM13 14 // JG 1714 3115 1 // LOADA 12916 12917 2 // LOADB 12818 12819 8 // MUL20 5 // SAVEC 12921 12922 1 // LOADA 12823 12824 3 // CONB 125 126 6 // ADD27 5 // SAVEC 12828 12829 11 // JUMP 430 831 18 // STOP
Как вы заметили, семь строчек кода на языке C были преобразованы в 18 строчек на языке ассемблера. Они заняли в ПЗУ 32 байта.
Декодирование

Разговор о декодировании придется начать c рассмотрения филологических вопросов. Увы, далеко не все компьютерные термины имеют однозначные соответствия в русском языке. Перевод терминологии зачастую шел стихийно, а поэтому один и тот же английский термин может переводиться на русский несколькими вариантами. Так и случилось с важнейшей составляющей микропроцессорной логики «instruction decoder». Компьютерные специалисты называют его и дешифратором команд и декодером инструкций. Ни одно из этих вариантов названия невозможно назвать ни более, ни менее «правильным», чем другое.
Дешифратор команд нужен для того, чтобы перевести каждый машинный код в набор сигналов, приводящих в действие различные компоненты микропроцессора. Если упростить суть его действий, то можно сказать, что именно он согласует «софт» и «железо».
Рассмотрим работу дешифратора команд на примере инструкции ADD, выполняющей действие сложения:
- В течение первого цикла тактовой частоты процессора происходит загрузка команды. На этом этапе дешифратору команд необходимо: активировать буфер сортировки для счетчика команд; активировать канал чтения (RD); активировать защелку буфера сортировки на пропуск входных данных в регистр команд
- В течение второго цикла тактовой частоты процессора команда ADD декодируется. На этом этапе арифметико-логическое устройство выполняет сложение и передает значение в регистр C
- В течение третьего цикла тактовой частоты процессора счетчик команд увеличивает свое значение на единицу (теоретически, это действие пересекается с происходившим во время второго цикла)
Каждая команда может быть представлена в виде набора последовательно выполняемых операций, которые в определенном порядке манипулируют компонентами микропроцессора. То есть программные инструкции ведут ко вполне физическим изменениям: например, изменению положения защелки. Некоторые инструкции могут потребовать на свое выполнение двух или трех тактовых циклов процессора. Другим может потребоваться даже пять или шесть циклов.
Микропроцессоры: производительность и тенденции

Количество транзисторов в процессоре является важным фактором, влияющим на его производительность. Как было показано ранее, в процессоре 8088 на выполнение одной инструкции требовалось 15 циклов тактовой частоты. А чтобы выполнить одну 16-битную операцию, уходило и вовсе порядка 80 циклов. Так был устроен умножитель АЛУ этого процессора. Чем больше транзисторов и чем мощнее умножитель АЛУ, тем больше всего успевает сделать процессор за один свой такт.
Многие транзисторы поддерживают технологию конвейеризации. В рамках конвейерной архитектуры происходит частичное наложение выполняемых инструкций друг на друга. Инструкция может требовать на свое выполнение все тех же пяти циклов, но если процессором одновременно обрабатываются пять команд (на разных этапах завершенности), то в среднем на выполнение одной инструкции потребуется один цикл тактовой частоты процессора.
Во многих современных процессорах дешифратор команд не один. И каждый из них поддерживает конвейеризацию. Это позволяет выполнять более одной инструкции за один такт процессора. Для реализации этой технологии требуется невероятное множество транзисторов.
64-битные процессоры
Хотя массовое распространение 64-битные процессоры получили лишь несколько лет назад, они существуют уже сравнительно давно: с 1992 года. И Intel, и AMD предлагают в настоящее время такие процессоры. 64-битным можно считать такой процессор, который обладает 64-битным арифметико-логическим устройством (АЛУ), 64-битными регистрами и 64-битными шинами.
Основная причина, по которой процессорам нужна 64-битность, состоит в том, что данная архитектура расширяет адресное пространство. 32-битные процессоры могут получать доступ только к двум или четырем гигабайтам оперативной памяти. Когда-то эти цифры казались гигантскими, но миновали годы и сегодня такой памятью никого уже не удивишь. Несколько лет назад память обычного компьютера составляла 256 или 512 мегабайт. В те времена четырехгигабайтный лимит мешал только серверам и машинам, на которых работают большие базы данных.
Но очень быстро оказалось, что даже обычным пользователям порой не хватает ни двух, ни даже четырех гигабайт оперативной памяти. 64-битных процессоров это досадное ограничение не касается. Доступное им адресное пространство в наши дни кажется бесконечным: два в шестьдесят четвертой степени байт, то есть что-то около миллиарда гигабайт. В обозримом будущем столь гигантской оперативной памяти не предвидится.
64-битная адресная шина, а также широкие и высокоскоростные шины данных соответствующих материнских плат, позволяют 64-битным компьютерам увеличить скорость ввода и вывода данных в процессе взаимодействия с такими устройствами, как жесткий диск и видеокарта. Эти новые возможности значительно увеличивают производительность современных вычислительных машин.
Но далеко не все пользователи ощутят преимущества 64-битной архитектуры. Она необходима, прежде всего, тем, кто занимается редактированием видео и фотографий, а также работает с различными большими картинками. 64-битные компьютеры по достоинству оценены ценителями компьютерных игр. Но те пользователи, которые с помощью компьютера просто общаются в социальных сетях и бродят по веб-просторам да редактируют текстовые файлы никаких преимуществ этих процессоров, скорее всего, просто не почувствуют.
Инструмент проще, чем машина. Зачастую инструментом работают руками, а машину приводит в действие паровая сила или животное.
Компьютер тоже можно назвать машиной, только вместо паровой силы здесь электричество. Но программирование сделало компьютер таким же простым, как любой инструмент.
Процессор — это сердце/мозг любого компьютера. Его основное назначение — арифметические и логические операции, и прежде чем погрузиться в дебри процессора, нужно разобраться в его основных компонентах и принципах их работы.
Два основных компонента процессора
Устройство управления
Устройство управления (УУ) помогает процессору контролировать и выполнять инструкции. УУ сообщает компонентам, что именно нужно делать. В соответствии с инструкциями он координирует работу с другими частями компьютера, включая второй основной компонент — арифметико-логическое устройство (АЛУ). Все инструкции вначале поступают именно на устройство управления.
Существует два типа реализации УУ:
- УУ на жёсткой логике (англ. hardwired control units). Характер работы определяется внутренним электрическим строением — устройством печатной платы или кристалла. Соответственно, модификация такого УУ без физического вмешательства невозможна.
- УУ с микропрограммным управлением (англ. microprogrammable control units). Может быть запрограммирован для тех или иных целей. Программная часть сохраняется в памяти УУ.
УУ на жёсткой логике быстрее, но УУ с микропрограммным управлением обладает более гибкой функциональностью.
Арифметико-логическое устройство
Это устройство, как ни странно, выполняет все арифметические и логические операции, например сложение, вычитание, логическое ИЛИ и т. п. АЛУ состоит из логических элементов, которые и выполняют эти операции.
25–27 ноября, Онлайн, Беcплатно
Большинство логических элементов имеют два входа и один выход.
Ниже приведена схема полусумматора, у которой два входа и два выхода. A и B здесь являются входами, S — выходом, C — переносом (в старший разряд).
Схема арифметического полусумматора
Хранение информации — регистры и память
Как говорилось ранее, процессор выполняет поступающие на него команды. Команды в большинстве случаев работают с данными, которые могут быть промежуточными, входными или выходными. Все эти данные вместе с инструкциями сохраняются в регистрах и памяти.
Регистры
Регистр — минимальная ячейка памяти данных. Регистры состоят из триггеров (англ. latches/flip-flops). Триггеры, в свою очередь, состоят из логических элементов и могут хранить в себе 1 бит информации.
Прим. перев. Триггеры могут быть синхронные и асинхронные. Асинхронные могут менять своё состояние в любой момент, а синхронные только во время положительного/отрицательного перепада на входе синхронизации.
По функциональному назначению триггеры делятся на несколько групп:
- RS-триггер: сохраняет своё состояние при нулевых уровнях на обоих входах и изменяет его при установке единице на одном из входов (Reset/Set — Сброс/Установка).
- JK-триггер: идентичен RS-триггеру за исключением того, что при подаче единиц сразу на два входа триггер меняет своё состояние на противоположное (счётный режим).
- T-триггер: меняет своё состояние на противоположное при каждом такте на его единственном входе.
- D-триггер: запоминает состояние на входе в момент синхронизации. Асинхронные D-триггеры смысла не имеют.
Для хранения промежуточных данных ОЗУ не подходит, т. к. это замедлит работу процессора. Промежуточные данные отсылаются в регистры по шине. В них могут храниться команды, выходные данные и даже адреса ячеек памяти.
Принцип действия RS-триггера
Память (ОЗУ)
ОЗУ (оперативное запоминающее устройство, англ. RAM) — это большая группа этих самых регистров, соединённых вместе. Память у такого хранилища непостоянная и данные оттуда пропадают при отключении питания. ОЗУ принимает адрес ячейки памяти, в которую нужно поместить данные, сами данные и флаг записи/чтения, который приводит в действие триггеры.
Прим. перев. Оперативная память бывает статической и динамической — SRAM и DRAM соответственно. В статической памяти ячейками являются триггеры, а в динамической — конденсаторы. SRAM быстрее, а DRAM дешевле.
Команды (инструкции)
Команды — это фактические действия, которые компьютер должен выполнять. Они бывают нескольких типов:
- Арифметические: сложение, вычитание, умножение и т. д.
- Логические: И (логическое умножение/конъюнкция), ИЛИ (логическое суммирование/дизъюнкция), отрицание и т. д.
- Информационные: move , input , outptut , load и store .
- Команды перехода: goto , if . goto , call и return .
- Команда останова: halt .
Прим. перев. На самом деле все арифметические операции в АЛУ могут быть созданы на основе всего двух: сложение и сдвиг. Однако чем больше базовых операций поддерживает АЛУ, тем оно быстрее.
Инструкции предоставляются компьютеру на языке ассемблера или генерируются компилятором высокоуровневых языков.
В процессоре инструкции реализуются на аппаратном уровне. За один такт одноядерный процессор может выполнить одну элементарную (базовую) инструкцию.
Группу инструкций принято называть набором команд (англ. instruction set).
Тактирование процессора
Быстродействие компьютера определяется тактовой частотой его процессора. Тактовая частота — количество тактов (соответственно и исполняемых команд) за секунду.
Частота нынешних процессоров измеряется в ГГц (Гигагерцы). 1 ГГц = 10⁹ Гц — миллиард операций в секунду.
Чтобы уменьшить время выполнения программы, нужно либо оптимизировать (уменьшить) её, либо увеличить тактовую частоту. У части процессоров есть возможность увеличить частоту (разогнать процессор), однако такие действия физически влияют на процессор и нередко вызывают перегрев и выход из строя.
Выполнение инструкций
Инструкции хранятся в ОЗУ в последовательном порядке. Для гипотетического процессора инструкция состоит из кода операции и адреса памяти/регистра. Внутри управляющего устройства есть два регистра инструкций, в которые загружается код команды и адрес текущей исполняемой команды. Ещё в процессоре есть дополнительные регистры, которые хранят в себе последние 4 бита выполненных инструкций.
Ниже рассмотрен пример набора команд, который суммирует два числа:
- LOAD_A 8 . Это команда сохраняет в ОЗУ данные, скажем, <1100 1000> . Первые 4 бита — код операции. Именно он определяет инструкцию. Эти данные помещаются в регистры инструкций УУ. Команда декодируется в инструкцию load_A — поместить данные 1000 (последние 4 бита команды) в регистр A .
- LOAD_B 2 . Ситуация, аналогичная прошлой. Здесь помещается число 2 ( 0010 ) в регистр B .
- ADD B A . Команда суммирует два числа (точнее прибавляет значение регистра B в регистр A ). УУ сообщает АЛУ, что нужно выполнить операцию суммирования и поместить результат обратно в регистр A .
- STORE_A 23 . Сохраняем значение регистра A в ячейку памяти с адресом 23 .
Вот такие операции нужны, чтобы сложить два числа.
Все данные между процессором, регистрами, памятью и I/O-устройствами (устройствами ввода-вывода) передаются по шинам. Чтобы загрузить в память только что обработанные данные, процессор помещает адрес в шину адреса и данные в шину данных. Потом нужно дать разрешение на запись на шине управления.

У процессора есть механизм сохранения инструкций в кэш. Как мы выяснили ранее, за секунду процессор может выполнить миллиарды инструкций. Поэтому если бы каждая инструкция хранилась в ОЗУ, то её изъятие оттуда занимало бы больше времени, чем её обработка. Поэтому для ускорения работы процессор хранит часть инструкций и данных в кэше.
Если данные в кэше и памяти не совпадают, то они помечаются грязными битами (англ. dirty bit).
Поток инструкций
Современные процессоры могут параллельно обрабатывать несколько команд. Пока одна инструкция находится в стадии декодирования, процессор может успеть получить другую инструкцию.

Однако такое решение подходит только для тех инструкций, которые не зависят друг от друга.
Если процессор многоядерный, это означает, что фактически в нём находятся несколько отдельных процессоров с некоторыми общими ресурсами, например кэшем.
Все современное оборудование, от беспроводных наушников до сложнейших рабочих станций работает под управлением процессора. Каждый из нас знает, что процессор – это мозг устройства, он принимает команды от пользователя, делает вычисления и предоставляет результаты.
Но в тонкостях работы разбираются единицы. В этой статье мы постараемся доступно устранить подобный пробел в знаниях.
Транзисторы и кодирование информации
О том, что первые компьютеры занимали целые комнаты и даже отдельные здания, вы наверняка знаете. Вычисления они производили при помощи электромеханических реле и вакуумных ламп. Революция произошла в 60 годах, когда появились первые кремниевые транзисторы. Позже на их основе были разработаны интегральные монолитные схемы – прототипы современных процессоров.
В основе каждого транзистора находится кремниевая структура. Поскольку кремний – материал, обладающий свойствами полупроводника, в зависимости от условий он может пропускать электрический ток или нет. Прошедший заряд – это единица, отсутствие заряда – ноль. Именно с помощью этих двух значений строится бинарный код, с помощью которого компьютер общается с пользователем. Другую информацию он воспринимать не способен.
Для того, чтоб процессор понимал пользователя, были придуманы логические вилки (операторы). Мы все их знаем из курса информатики в школе: и/или, если/то/иначе. Такие команды позволяют компьютеру исходя из заданных условий принимать решения.
Что такое техпроцесс?
Производительность процессора в рамках одной серии или семейства напрямую зависит от количества транзисторов: чем больше транзисторов, тем больше комбинаций составляется в единицу времени, и тем больше вычислений производит устройство.
У первого процессора Intel 4004, вышедшего в 1971 году было 2250 транзисторов. Pentium 4 вмещал 42 млн транзисторов. Современные процессоры Epyc от AMD оснащены 39,54 миллиардами кремниевых транзисторов.
С размером транзисторов тесно связано понятие – техпроцесс.
Техпроцесс каждый из производителей диктует по своему. Кто-то размером транзистора целиком, кто-то размером только одной части – затвора. Третий вариант, который будет самым правильным – размер шага при производстве, то есть минимальным размером элемента, которым может оперировать разработчик при построении схемы. Так-же следует учесть, что производители указывают наименьший элемент, тогда как некоторые электронные элементы, от которых невозможно отказаться могут иметь размеры в десятки раз больше.
Тактовая частота
Это понятие зачастую является определяющим при покупке процессора.
Заряды проходящие через транзисторы создает тактовый генератор. Количество импульсов в единицу времени определяет скорость работы процессора. Однако он есть не в каждом процессоре. Может встречаться и другая конфигурация: на плате есть один или несколько тактовых генераторов, и они-же могут быть опционально включены в микропроцессоры.
Обязательный элемент каждого процессора – частотный резонатор, он дает корректный отклик на запрос в случае исправности, или не дает, что сообщает системе о неисправности элемента.
В основе каждого генератора имеется кварцевый кристалл. Он генерирует импульс с частотой около 100 МГц. На текущий момент могут еще довольно часто встречаться генераторы с частотой 33 МГц, особенно на дискретных контроллерах, например звуковых платах, sata/hba адаптерах и интерфейсных usb/com расширителях. Чтоб увеличить частоту, генерируемые кварцем колебания проходят через специальные узлы – множители. Они позволяют повысить частоты при пиковых нагрузках или снизить их, если нагрузка уменьшается или компьютер находится в простое.
Кстати, множители – это те самые узлы, которые отвечают за динамическое увеличение частоты в нагрузке и ее снижении в простое. Также они могут позволять разгон в случае отсутствия на них блокировки на повышение сверх штатного значения. Подробнее с этой темой можно ознакомиться в нашей статье .
У процессоров с разблокированным множителем пользователь по собственному желанию может увеличить тактовые частоты. Современные процессоры могут разгоняться на 20 – 30 % и даже больше.
Архитектура
Архитектура процессора – это компоновка транзисторов. Транзисторы объединяются в массивы – ядра. Каждое ядро в процессоре может независимо от других выполнять различные задачи, для этого регулярно повторяется следующий цикл действий:
- Получение информации.
- Раскодирование.
- Выполнение вычисления.
- Фиксация результата.
Вычисления выполняются по специальным алгоритмам и инструкциям, которые хранятся во временной памяти процессора.
Чтоб увеличить производительность процессора, современные компьютерные ядра делятся на 2 потока. Каждый поток занимается выполнением отдельных вычислений, обеспечивая процессору многозадачность и уменьшая очереди задач.
Кэш: зачем процессору собственная память?
Жесткие и твердотельные диски, а также оперативная память работают недостаточно быстро, чтоб обеспечить все нужды процессора. Поэтому каждый микрочип оснащен собственной сверхбыстрой кэш-памятью, хранящей данные с которыми в конкретный момент, работает процессор. Также в кэш-памяти размещаются инструкции по выполнению конкретных задач.
Что такое система на чипе?
Современные процессоры для телефонов, планшетов и ноутбуков уже давно перестали быть отдельными вычислительными центрами, специализирующимися на выполнении конкретных задач. Современный процессор – это целая система, которая включает собственно блоки для выполнения задач – ядра, а также модуль для отрисовки изображений – графический адаптер. Роль ядер выполняют исполнительные блоки, которых значительно больше, чем в CPU, и которые параллельно выполняют миллионы задач. Также некоторые системы могут содержать и дополнительные опции, например, центр беспроводного соединения 5G или технологию передачи данных Thunderbolt.
Читайте также: