
Как посмотреть файл по ссылке
Если нет подходящей ссылки для тестирования формы, скопируйте вот эту :
Как скачивать ссылку онлайн скрипт - подробный разбор:
Для того, чтобы написать рабочий код скачивания ссылки онлайн нам понадобится:
Далее нам потребуется тег ссылки
input для вставки адреса файла, который надо скачать.
Кнопку, button - по которой будем нажимать.
<a href="" download style="display:none">Скачай файл</a><input > <button на меня</button>
Далее нам понадобится js + отправим в атрибут href из поля для ввода ссылки.
И откроем ссылку, чтобы нажать по ней!
<script>id_button.onclick = function () idurl.href = idinput.value;
idurl.style = "display:block";
>
</script>
Соберем весь код вместе:
<a href="" download style="display:none">Скачай файл</a><input > <button на меня</button>
<script>
id_button.onclick = function () idurl.href = idinput.value;
idurl.style = "display:block";
>
</script>
Несколько поисковых запросов про скачивание фалов по ссылке. например
как скачать xml файл по ссылке
скачать пдф файл по ссылке
Чем отличается скачивание определенного типа файла по ссылке?
Для того, чтобы скачать файл с разрешением "xml" или "пдф". выше приведенной
Какое разрешение у вашего файла.
Данная форма может скачать любой файл онлайн с любого сайта!
Есть несколько исключений!
Файл должен существовать!
Скачивание должно быть разрешено(запрет может быть организован разными способами!).
скачать файл с Google диска по ссылке
Для того, чтобы скачать файл с Google диска по ссылке нам потребуется:Создадим ссылку на любой документ, чтобы вы смогли убедиться, что данный файл существует!
Далее нажимаем ссылку и проходим на страницу диска:
В открытом окне ссылки Google диска ищем кнопку скачать! Нажимаем!
Почему возникает вопрос - "скачать файл с Google диска по ссылке"
Мое предположение : скорее всего человек видит " НЕ " активную ссылку и не знает, что нужно с ней делать?Это решается до банальности просто! Выделяем полностью ссылку.
Нажимаем ПКМ по выделенному элементу.
Ищем строку перейти :

Почему возникает вопрос - ‘скачать файл с Google диска по ссылке‘ А далее я уже рассказал.
Если с вами поделились ссылкой на файл или папку, вы можете просмотреть их с публичной страницы, скопировать на свой Диск или скачать.
Просмотреть файл или папку с публичной страницы
Скопировать на свой Диск
Если с вами поделились ссылкой на файл или папку, которые хранятся на Яндекс.Диске, вы можете скопировать их на свой Диск.
Чтобы скопировать файл или папку, перейдите по полученной ссылке и нажмите кнопку Сохранить на Яндекс.Диск . Файл или папка будут помещены в папку Загрузки вашего Диска.
В папку Загрузки вы можете перейти из панели слева.
Если с вами поделились ссылкой на файл или папку, которые хранятся на Яндекс.Диске, вы можете скачать их на свой компьютер или мобильное устройство.
Внимание. Опубликованную папку можно скачать на компьютер в виде архива, если ее размер не превышает 5 ГБ и в ней меньше 500 файлов. На публичной странице нажмите кнопку Сохранить на Яндекс.Диск . Папка будет помещена в папку Загрузки вашего Диска. Внимание. Если вы используете или раньше использовали двухфакторную аутентификацию, для авторизации в программе Яндекс.Диск нужен одноразовый пароль, сгенерированный мобильным приложением «Яндекс.Ключ» . В контекстном меню нужной папки выберите Создать копию на компьютере .Скачанная папка не синхронизируется с облаком. Если вы скачали папку, изменили в ней что-то и хотите, чтобы изменения появились на Яндекс.Диске, загрузите папку туда вручную.
Если вы хотите скачать папку и синхронизировать ее с облаком, в контекстном меню выберите Сохранить на компьютере .
Не скачивается файл
Иногда при работе с Диском перестают работать кнопки, не загружаются элементы страницы, не открываются фото, не скачиваются файлы или браузер сообщает об ошибке.
Скачивание публичного файла ограничено
Если публичный файл был скачан много раз в течение суток, включается лимит — скачивание может быть ограничено на сутки. Если вы не хотите ждать, сохраните файл на свой Диск с помощью кнопки Сохранить на Яндекс.Диск . Чтобы скачивать публичные файлы без ограничений, оформите подписку на Яндекс 360.
Примечание. Скачивать можно только публичные папки, в которых меньше 500 файлов, или папки размером до 5 ГБ. Папки большего размера вы можете сохранить на свой Диск.Чтобы уменьшить расход трафика, браузер сохраняет копии посещенных страниц в кеше. Когда вы повторно просматриваете страницы, браузер может загружать их данные из памяти. Например, если вы измените имя файла через программу для компьютера, а браузер загрузит из памяти информацию об этом файле, вы увидите неактуальное имя файла.
Попробуйте обновить страницу, чтобы принудительно загрузить ее из интернета. Если проблема не решится, очистите кеш браузера и удалите все файлы cookie.
Расширения блокируют Яндекс.Диск
Диск может работать некорректно из-за дополнений и расширений в браузере. Чтобы проверить это, временно отключите их. Если Диск работает неправильно из-за блокировщика рекламы или расширения-антивируса, добавьте страницу Диска в исключения этого расширения. Подробнее см. в разделах Настроить блокировщики рекламы, Настроить исключения для сайтов.
Простой 10 комментариев

Сергей Карбивничий, если немного поменять код и попробовать прочитать именно .docx - да.
например:
тут мы видим, что эта библиотека открывает .docx, но с места на жестком диске
попробую по шагам проговорить, что я пытаюсь сделать.
1/ я получаю .content из ссылки
2/ засовываю то, что лежит в file в BytesIO и применяю .read()
file = BytesIO(file).read()
3/ пытаюсь декодировать имеющийся байтник
file = file.decode('cp65001', 'ignore')
Сергей Ильин, doc - бинарный формат. Его нельзя просто так "прочитать", нужно использовать какие-то библиотеки, которые этот формат смогут разобрать.
Конкретно вот textract не умеет из переменной, только из файла. Значит, надо записать во временный файл и его уже обрабатывать. Или всё-таки поискать другие библиотеки.
shurshur, я понимаю про док, поэтому и написал на q/a. В моих поисках "открыть док-файл по ссылке" я смог только textract найти, но он, как вы справедливо указали, умеет только с жесткого диска открывать. Была идея как-то в process подпихнуть бинарник, но она провалилась ( или, может, я делаю что-то не то. Сергей Ильин, насколько я понимаю, textract - это изначально абстрактный модуль, нацеленный через работу с помощью плагинов. Эти плагины могут делать что угодно, в том числе вызывать внешние команды, общаться с софтом через интерфейсы типа COM итд итп. Работа только с передачей файла по имени ограничивает разработчика, но зато расширяет возможности плагинов. Если есть желание, можно поразбираться в устройстве textract и понять, как конкретно он обрабатывает файлы .doc, может быть, можно его без особых усилий слегка переработать под себя.Ты же выводишь содержимое док в консоль.
вы предлагаете сохранять файл? есть возможность его прочитать без этого?Файл уже прочитан. Но это не текстовый файл, его содержимое можно посмотреть только в программе, поддерживающей .DOC, но не в консоли. Можно вызвать её из скрипта и указать в качестве аргумента путь к сохранённому файлу. Соответсвенно, для этого его нужно сохранить на диске и открывать оттуда.
Может быть, есть какие-то библиотеки, которые могут извлечь текст из DOC, или можно найти утилиту для конвертации DOC в TXT и его можно вывести в консоль, но какой в этом смысл ?


БЕЗ скриптов, макросов, регулярных выражений и командной строки.
Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что те могут скоро исчезнуть, а также менеджерам, собирающим базы контактов для рассылок.
Есть три основные цели извлечения/сохранения данных с сайта на свой компьютер:
- Чтобы не пропали;
- Чтобы использовать чужие картинки, видео, музыку, книги в своих проектах (от школьной презентации до полноценного веб-сайта);
- Чтобы искать на сайте информацию средствами Spotlight, когда Google не справляется (к примеру поиск изображений по exif-данным или музыки по исполнителю).
Ситуации, когда неожиданно понадобится автоматизированно сохранить какую-ту информацию с сайта, могут случиться с каждым и надо быть к ним готовым. Если вы умеете писать скрипты для работы с утилитами wget/curl, то можете смело закрывать эту статью. А если нет, то сейчас вы узнаете о самых простых приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт целиком для просмотра оффлайн
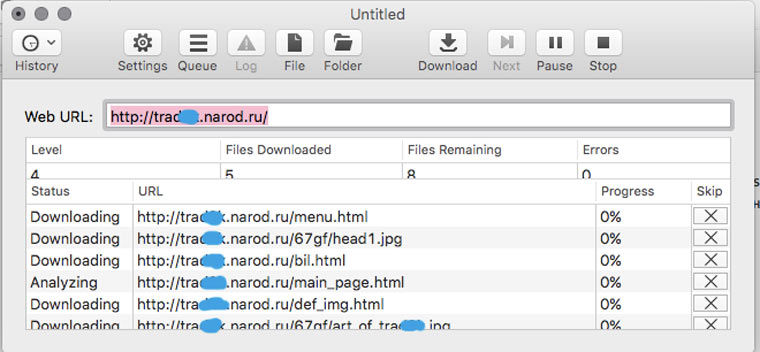
В OS X это можно сделать с помощью приложения HTTrack Website Copier, которая настраивается схожим образом.
Пользоваться Site Sucker очень просто. Открываем программу, выбираем пункт меню File -> New, указываем URL сайта, нажимаем кнопку Download и дожидаемся окончания скачивания.
2. Прикидываем сколько на сайте страниц
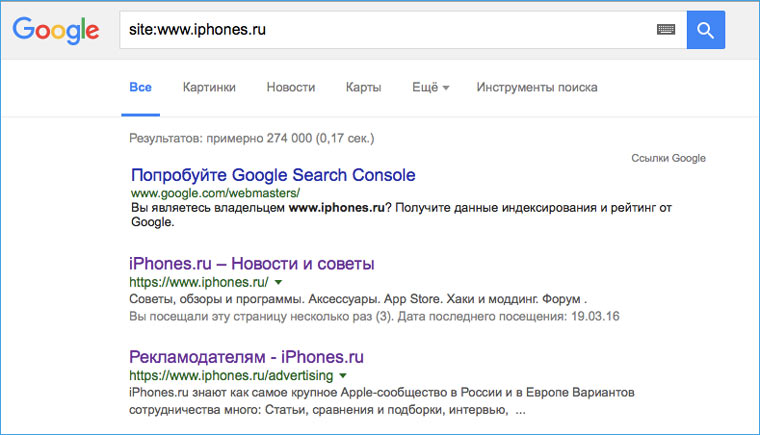
Перед тем как браться за скачивание сайта, необходимо приблизительно оценить его размер (не затянется ли процесс на долгие часы). Это можно сделать с помощью Google. Открываем поисковик и набираем команду site: адрес искомого сайта. После этого нам будет известно количество проиндексированных страниц. Эта цифра не соответствуют точному количеству страниц сайта, но она указывает на его порядок (сотни? тысячи? сотни тысяч?).
3. Устанавливаем ограничения на скачивание страниц сайта
![]()
Если вы обнаружили, что на сайте тысячи страниц, то можно ограничить число уровней глубины скачивания. К примеру, скачивать только те страницы, на которые есть ссылка с главной (уровень 2). Также можно ограничить размер загружаемых файлов, на случай, если владелец хранит на своем ресурсе tiff-файлы по 200 Мб и дистрибутивы Linux (и такое случается).
Сделать это можно в Settings -> Limits.
4. Скачиваем с сайта файлы определенного типа
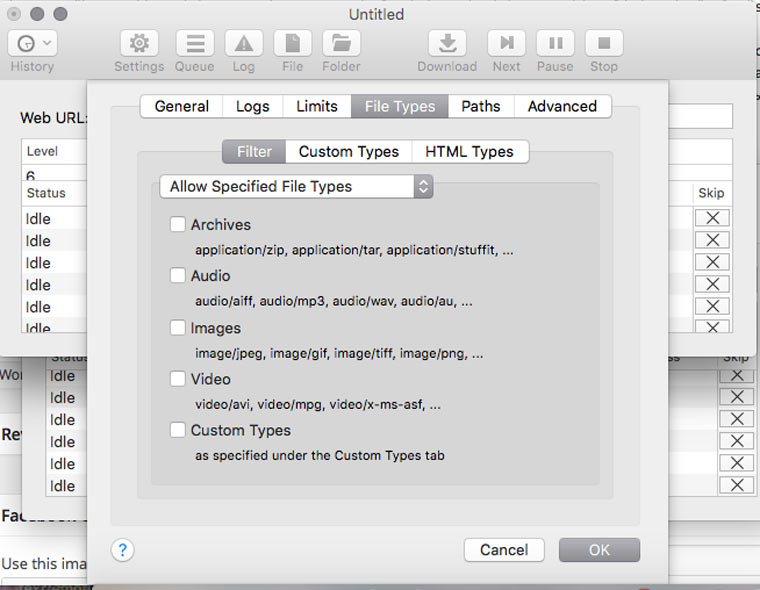
В Settings -> File Types -> Filters можно указать какие типы файлов разрешено скачивать, либо какие типы файлов запрещено скачивать (Allow Specified Filetypes/Disallow Specifies Filetypes). Таким образом можно извлечь все картинки с сайта (либо наоборот игнорировать их, чтобы места на диске не занимали), а также видео, аудио, архивы и десятки других типов файлов (они доступны в блоке Custom Types) от документов MS Word до скриптов на Perl.
5. Скачиваем только определенные папки
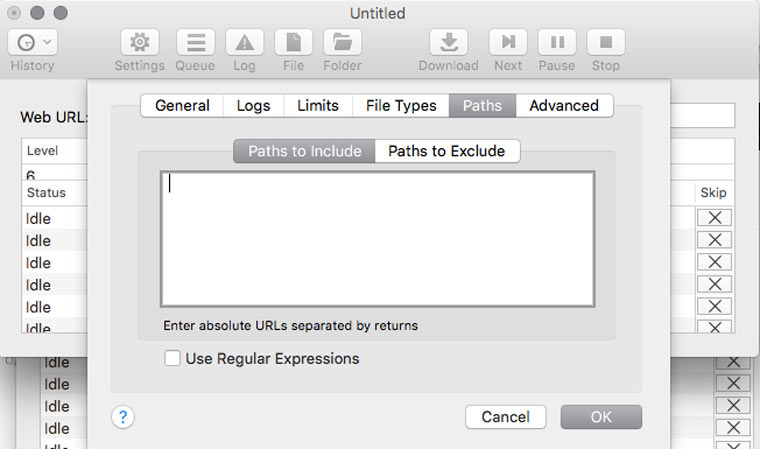
Если на сайте есть книги, чертежи, карты и прочие уникальные и полезные материалы, то они, как правило, лежат в отдельном каталоге (его можно отследить через адресную строку браузера) и можно настроить SiteSucker так, чтобы скачивать только его. Это делается в Settings -> Paths -> Paths to Include. А если вы хотите наоборот, запретить скачивание каких-то папок, то их адреса надо указать в блоке Paths to Exclude
6. Решаем вопрос с кодировкой
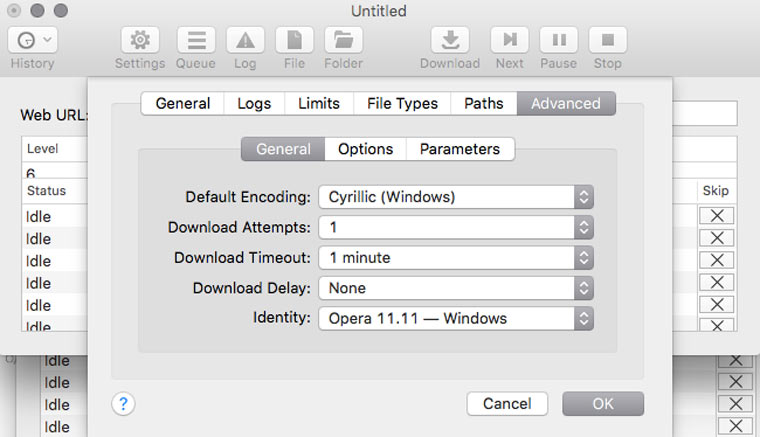
Если вы обнаружили, что скачанные страницы вместо текста содержат кракозябры, там можно попробовать решить эту проблему, поменяв кодировку в Settings -> Advanced -> General. Если неполадки возникли с русским сайтом, то скорее всего нужно указать кодировку Cyrillic Windows. Если это не сработает, то попробуйте найти искомую кодировку с помощью декодера Лебедева (в него надо вставлять текст с отображающихся криво веб-страниц).
7. Делаем снимок веб-страницы
Это может пригодиться для сравнения разных версий дизайна сайта, запечатления на память длинных эпичных перепалок в комментариях или в качестве альтернативы способу сохранения сайтов, описанного в предыдущих шести пунктах.
8. Сохраняем картинки только с определенной страницы
9. Извлекаем HEX-коды цветов с веб-сайта
10. Извлекаем из текста адреса электронной почты
11. Извлекаем из текста номера телефонов
А если надо отфильтровать в тексте заголовки, даты и прочую информацию, то к вам на помощь придут регулярные выражения и Sublime Text.
(2 голосов, общий рейтинг: 4.50 из 5)
Как сделать при переходе по ссылке чтобы открытие происходило во всплывающем окне?
Здравствуйте! Клацаю по ссылке и появляется всплывающее окно Мне нужно сделать кнопку чтобы.
Как сделать скачивание файла по ссылке в html?
Люди как сделать скачивание файла по ссылке в html. К примеру, форматов pdf или doc, так чтобы они.
Mod_rewrite и открытие PDF файла по ссылке
Здравствуйте! Не могу открыть PDF файл по ссылке. На сайте открываю страницу с руководством.
Как сделать ссылку на открытие EXEшного файла?
Как сделать ссылку на открытие EXEшного файла?
Это настройки клиента - веб сервер на это поведение влиять не может.
Возможно такого поведения возможно добиться через уязвимость в браузере, но это ненадежное рещение будет.
Чтобы заставить MSIE запускать файлы без предупреждения сделай на всех машинах слудющее
- добавь свой сайт в зону Trusted sites
- Далее в настройках безопасности Trusted sites выставляем опцию
Launching applications and unsafe files = Enable
хееееее
это я и сам знаю
а как при таком варианте
корпоративная сеть, около 40 тыс компьютеров, реально подсадить на автозапуск EXE по одной ссылке нужно около 1 тыс компов
географически находятся за неделю не проедешь
я физически в трастах не смогу всем прописать, даже если радмин поставлю или батник кривления реестра для MSIE нарисую (его тоже нужно стартовать)
Я не думаю, что возможен запуск EXE без подтверждения пользователя без изменения настроек безопаности. Сам понимаешь, что иначе это было бы подарком для вирусописателей. Зачем нужен такой сценарий работы?
Как вариант можно попробовать написать свой ActiveX, который будет автоматически установлен на компьютер пользователя при первом посещении страницы (потребуется, само собой, его одобрение на это). При последующих визитах на эту страницу, ActiveX будет запускаться уже установленный ActiveX без 'лишних' запросов на запуск.
ладно согласен, хотя есть вариант запуска EXE не только на сервере, но и по ссылке на сайте запуск EXE на клиенте, так называемое Windows Script Hosts
а вот простой вопрос, упарился я уже его решать, ни кто ответить не хочет
с виду самый обычный текст, но.
где и как указать в этом тексте, если флеха не может выполниться, например запустить или найти ActiveX, чтобы она показывала картинку, например
и как правильно и какие файлы нужно положить, чтобы ActiveX с минимальным количеством вопросов по строке из CodeBase грузанулся клиенту и все заработало, че тока не делал
ссылки на макромедию не предлагать, корпоративная сеть, в ней нет интернета
Читайте также: