Как перекодировать файл в utf 8
Основные понятия
Юнико́д, или Унико́д (англ. Unicode™) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
Пример: команда wc имеет ключ -c для подсчета байтов и ключ -m для подсчета символов.
Имена файлов
Имена файлов были перекодированы автоматически с помощью утилиты convmv:
Каждому пользователю, в домашнем каталоге которого утилита convmv переименовала хотя бы один файл, был автоматически выслан журнал переименований.
При необходимости можно выполнить обратное преобразование:
После проверки вывода команды повторить с ключем --notest. Ключ -r включает рекурсивный обход каталогов.
Содержимое файлов
Для потокового перекодирования используется команда:
Редактор Emacs может автоматически распознать кодировку текста при открытии файла. Принудительно задать кодировку открытия или сохранения файла в редакторе Emacs можно следующим образом:
- Ввести комбинацию клавиш C-x RET c .
- Внизу экрана будет запрошена кодировка, которую вы хотите применить для следующей команды.
- Введите команду, которая будет выполнена с применением введенной на предыдущем шаге кодировки, например:
- комбинацию клавиш для открытия файла: C-x C-f ;
- комбинацию клавиш для сохранения файла: C-x C-s .
Приложения
Текстовый терминал из Windows
Для корректного отображения русского текста при входе на серверы кафедры с помощью терминального клиента PuTTY нужно указать в настройках:
- Раздел Window/Translation
- Character set translation on recieved data: UTF-8
Текстовый терминал из Linux
Если системная локаль не UTF-8, то необходимо запустить X-терминал с поддержкой UTF-8 и выполнить вход по ssh из него.
Если системная локаль UTF-8, то никаких дополнительных действий предпринимать не надо.
Если по какой-то причине при входе по ssh не установились правильно переменные окружения локали (вывод команды locale не содержит строки LANG=ru_RU.UTF-8 ), то необходимо выполнить команду:
WinSCP
Для корректного отображения русских имен файлов:
- Раздел Environment
- UTF-8 encoding for filenames: On
- После выполнения перекодировки содержимого tex-файла (см. Содержимое файлов) необходимо сменить кодировку в преамбуле:
- Также необходимо подключить пакет ucs:
- Для установки диакритических знаков (ударений) нужно использовать полную форму стандартной записи \', т.е.:
Bibtex
Кодировка текста – это схема нумерации символов, в которой каждому символу, цифре или знаку присвоено соответствующее число. Кодировку используют для сохранения и обработки текста на компьютере. Каждый раз при сохранении текста в файл он сохраняется с использованием определенной схемы кодирования, и при открытии этого файла необходимо использовать такую же схему, иначе восстановить исходный текст не получится. Самыми популярными кодировками для кириллицы сейчас являются UTF-8, Windows-1251 (CP1251, ANSI).
Для того чтобы программа смогла правильно открыть текстовый файл, иногда приходится вручную менять кодировку, перекодируя текст из одной схемы в другую. Например, не редко возникают проблемы с открытием файлов CSV, XML, SQL, TXT, PHP.
В этой небольшой статье мы расскажем о том, как изменить кодировку текстового файла на UTF-8, Windows-1251 или любую другую.
Блокнот Windows
Если вы используете операционную систему Windows 10 или Windows 11, то вы можете изменить кодировку текста с помощью стандартной программы Блокнот. Для этого нужно открыть текстовый файл с помощью Блокнота и воспользоваться меню « Файл – Сохранить как ».
![меню Файл – Сохранить как]()
В открывшемся окне нужно указать новое название для файла, выбрать подходящую кодировку и нажать на кнопку « Сохранить ».
![изменить кодировку в Блокноте]()
К сожалению, для подобных задач программа Блокнот часто не подходит. С ее помощью нельзя открывать документы большого размера, и она не поддерживает многие кодировки. Например, с помощью Блокнота нельзя открыть текстовые файлы в DOS 866.
Notepad++
Notepad++ (скачать) является одним из наиболее продвинутых текстовых редакторов. Он обладает подсветкой синтаксиса языков программирования, позволяет выполнять поиск и замену по регулярным выражениям, отслеживать изменения в файлах, записывать и воспроизводить макросы, считать хеш-сумы и многое другое. Одной из основных функций Notepad++ является поддержка большого количества кодировок текста и возможность изменения кодировки текстового файла в UTF-8 или Windows 1251.
Для того чтобы изменить кодировку текста с помощью Notepad++ файл нужно открыть в данной программе. Если программа не смогла правильно определить схему кодирования текста, то это можно сделать вручную. Для этого нужно открыть меню « Кодировки – Кириллица » и выбрать нужный вариант.
![выбрать кодировку в Notepad++]()
После открытия текста можно изменить его кодировку. Для этого нужно открыть меню « Кодировки » и выбрать один из вариантов преобразования. Notepad++ позволяет изменить текущую кодировку текста на ANSI (Windows-1251), UTF-8, UTF-8 BOM, UTF-8 BE BOM, UTF-8 LE BOM.
![изменить кодировку в Notepad++]()
После преобразования файл нужно сохранить с помощью меню « Файл – Сохранить » или комбинации клавиш Ctrl-S.
Akelpad
Akelpad (скачать) – достаточно старая программа для работы с текстовыми файлами, которая все еще актуальна и может быть полезной. Фактически Akelpad является более продвинутой версией стандартной программы Блокнот из Windows. С его помощью можно открывать текстовые файлы большого размера, которые не открываются в Блокноте, выполнять поиск и замену с использованием регулярных выражений и менять кодировку текста.
Для того чтобы изменить кодировку текста с помощью Akelpad файл нужно открыть в данной программе. Если после открытия файла текст не читается, то нужно воспользоваться меню « Файл – Открыть ».
![открыть файл в Akelpad]()
В открывшемся окне нужно выделить текстовый файл, снять отметку « Автовыбор » и выбрать подходящую кодировку из списка. При этом в нижней части окна можно видеть, как будет отображаться текст.
![выбрать кодировку в Akelpad]()
Для того чтобы изменить текущую кодировку текста нужно воспользоваться меню « Файл – Сохранить как » и сохранить документ с указанием новой схемы кодирования.
![изменить кодировку в Akelpad]()
В отличие от Notepad++, текстовый редактор Akelpad позволяет сохранить файл в практически любой кодировке. В частности, доступны Windows 1251, DOS 886, UTF-8 и многие другие.
БлогNot. Перекодируем много файлов из Windows-1251 в Unicode (UTF-8)
Перекодируем много файлов из Windows-1251 в Unicode (UTF-8)
Проблема, конечно, не в самом перекодировании, а в том, что файлов может быть много и они могут быть разбросаны по множеству вложенных папок. Мне кажется, отдельного программного обеспечения для этой задачи не нужно - достаточно удобного плагина для Far Manager с названием FarTrans (он же Transcod). Плагину уже 13 лет, но он успешно работает и с новыми версиями Far 2/3.
- Создайте папку FarTrans в C:\Program Files\Far\Plugins
- Скопируйте скачанные файлы из архива в новую папку FarTrans
- Перезапустите Far Manager
- Выделяйте файлы и, выбирая в меню плагинов (клавиша F11) пункт "Перекодировка файлов", указывайте нужный вариант кодировки (у нас - UTF-8).
Почему нет опции "Обрабатывать вложенные папки", со слов автора:
Что не сделано и сделано не будет:
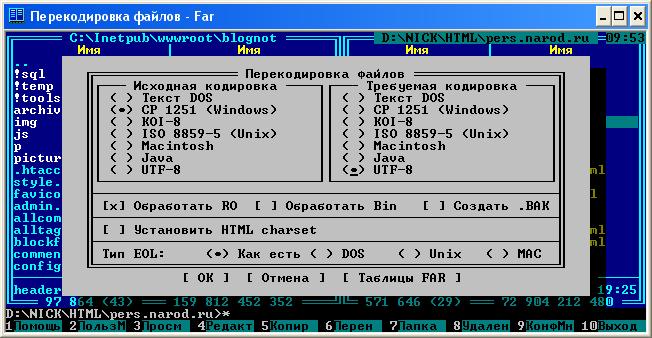
- Обработка подкаталогов. В FARе есть замечательная фича - временная панель. Выведите на нее все необходимые файлы (проще всего с помощью поиска файлов Alt+F7), а затем выделите действительно нужные и обработайте их в FarTrans. Это наглядно, соответствует общей концепции обработки выделенных на панели файлов и, главное, более безопасно, поскольку вслепую можно и все системные файлы "перекодировать" :-)Напомню, что выделить все файлы панели можно нажатием серой "звёздочки" на дополнительной цифровой клавиатуре. Вот окно плагина, настроенного на перекодировку из Windows-1251 в Юникод:
![Окно плагина FarTrans]()
Окно плагина FarTransПерекодировать один файл удобнее всего во встроенном редакторе Far Manager 3.0. Просто откройте файл во встроенном редакторе (встать на него курсором и нажать F4), выделите весь текст комбинацией клавиш Ctrl+A, спрячьте его в буфер обмена нажатием Ctrl+X, нажмите Shift+F8, чтобы выбрать кодировку из списка (65001 UTF-8), после выбора кодировки, которая, кстати, видна в верхней строке редактора, вставьте весь текст назад нажатием комбинации клавиш Ctrl+V.
Если при импорте контактов вы видите нечитаемые символы, как на скриншоте, это значит, что кодировка файла не подходит для импорта в Unisender. Файл нужно перекодировать в UTF-8. Далее мы расскажем, как это сделать в Excel.
![нечитаемые числа.]()
Переходим на вкладку «Данные», выбираем «Получение внешних данных», а далее — «Из текста».
![получение данных из текста.]()
Открывается мастер импорта текста.
С текущей кодировкой содержимое файла нечитабельное.![текущая кодировка.]()
В поле «Формат файла» перебираем кодировки, пока не найдём ту, в которой текст отображается правильно. Вариантов много, поэтому можно начать с форматов, которые начинаются со слова «Кириллица». Находим нужный формат, нажимаем «Далее».
Выбираем символы-разделители. В нашем случае это запятая.
Нажимаем «Далее» → «Готово» → «OK».
![выбираем символы-разделители.]()
Так выглядит импортированный текст в Excel.
![как выглядит документ в ексель.]()
Теперь нажимаем «Файл» → «Сохранить как».
Вводим название файла, тип файла выбираем CSV, ниже нажимаем «Сервис» → «Параметры веб-документа».
![сохраняем файл.]()
Переходим на вкладку «Кодировка», выбираем «Юникод UTF-8» и нажимаем «OK».
![]()
В этой статье мы поговорим о UTF-8, кодировке символов и рассмотрим примеры преобразования файлов из одной кодировки в другую с помощью инструмента командной строки. Затем, мы рассмотрим, как конвертировать несколько файлов из любой кодировки в кодировку UTF-8 в Linux.
Как вы, знаете, компьютер не понимает и не хранит буквы, цифры или что-либо еще. Он все запоминает и воспринимает через биты информации. Бит имеет только два возможных значения, то есть 0 или 1, true или false. Все остальное: буквы, цифры, изображения, должны быть представлены в битах для того чтобы компьютер мог их обрабатывать.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
Инструмент командной строки iconv используется для преобразования текста из одной формы кодирования в другую.
Вы можете проверить кодировку файла с помощью команды file, используя опцию -i или -mime, которая позволяет выводить строку типа mime, как в приведенных ниже примерах:
![file -i]()
![]()
Синтаксис использования iconv выглядит следующим образом:
Чтобы перечислить все известные кодировки символов, выполните следующую команду:
![iconv -l]()
Преобразование файлов из UTF-8 в кодировку ASCII
Теперь перейдем к тому, как конвертировать из одной системы кодирования в другую. Приведенная ниже команда преобразуется из ISO-8859-1 в кодировку UTF-8.
Рассмотрим файл с именем input.file, который содержит символы:
![]()
Начнем с проверки кодировки символов в файле, а затем просмотра содержимого файла. Вкратце, мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы проверяем содержимое выходного файла и новую кодировку символов, как показано ниже.
Примечание. Если в кодировку добавлена строка //IGNORE, после преобразования отображаются символы, которые не могут быть преобразованы, и ошибка.
Опять же, предположим, что строка //TRANSLIT добавляется в кодировку, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы транслитерируются по мере необходимости. Это подразумевает, что символ не может быть представлен в целевом наборе символов, его можно аппроксимировать одним или несколькими похожими символами.
Следовательно, любой символ, который не может быть транслитерирован и не находится в целевом наборе символов, заменяется знаком вопроса (?) на выходе.
Преобразование нескольких файлов в кодировку UTF-8
Возвращаясь к нашей основной теме, чтобы преобразовать несколько или все файлы каталога в кодировку UTF-8, вы можете написать небольшой скрипт оболочки под названием encoding.sh следующим образом:
Сохраните файл, затем сделайте его исполняемым файлом скрипта. Запустите этот скрипт из каталога, в котором находятся ваши файлы (*.txt).
Важно. Вы также можете использовать этот скрипт для общего преобразования нескольких файлов из одной кодировки в другую, просто поэкспериментируйте со значениями переменной FROM_ENCODING и TO_ENCODING, не забывая имя выходного файла «$.utf8.converted».
Для получения дополнительной информации просмотрите страницу iconv man.
Спасибо за уделенное время на прочтение статьи!
Если возникли вопросы, задавайте их в комментариях.
Подписывайтесь на обновления нашего блога и оставайтесь в курсе новостей мира инфокоммуникаций!
Чтобы знать больше и выделяться знаниями среди толпы IT-шников, записывайтесь на курсы Cisco от Академии Cisco, курсы Linux от Linux Professional Institute на платформе SEDICOMM University.
Читайте также: