
Как классифицируются файлы и файловые структуры в базах данных
В деловой и личной сфере часто приходится работать с данными из разных источников, каждый из которых связан с определенным видом деятельности. Для координации всех этих данных необходимы определенные знания и организационные навыки.
В общем смысле термин база данных — это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области или разделе предметной области.
Увеличение объема и структурной сложности хранимых данных, расширение круга пользователей информационных систем выдвинуло требование создания удобных средств интеграции хранимых данных и управления ими.
Применение «ИС Поликлиника» необходимо при организации деятельности таких учреждений, как поликлиника. В связи с большим количеством пациентов, необходимость их учета требует автоматизации, путем применения данной информационной системы поликлиникой, что обусловливает актуальность базы данных «Поликлиника»
Объект данной работы — «ИС Поликлиника»
Предмет — проблема организации и хранения данных в данной ИС.
Цель работы — разработать эффективную и удобную базу данных.
Для достижения поставленной цели необходимо решить следующие задачи:
1. Разработать и заполнить таблицы соответствующими данными.
2. Установить тип связей в таблице.
3. Создать запросы для вывода необходимых полей.
4. Создать формы, отчеты и макросы.
ОСНОВНАЯ ЧАСТЬ
Физические модели таблиц базы данных.
Физическая модели таблицы базы данных предполагает описание свойств каждого поля таблицы. Для описания свойств полей необходимо составить проект таблицы по форме, показанной на рис. 1.
Таким образом, разработка физической модели проекта таблицы базы данных сводится к описанию характеристик каждого поля. Приведем обязательные характеристики полей таблиц базы данных.
Имя поля — некоторый минимальный набор символов, предназначенный для поиска данных в таблице. В каждой прикладной программной системе для разработки баз данных существуют свои грамматические правила для формирования имен полей. В общем случае не допускается начинать имя поля с символа пробела, выбирать в качестве символов знаки препинания.
Подпись поля идентифицируется с названием признака объекта, значения которого будут храниться в ячейках поля. Подпись поля будет находиться в заголовке таблицы. В современных СУБД не существует каких-либо ограничений на формирование подписи поля.
Тип данных — обозначение типа данных в соответствии с конкретной программной системой.
Количество символов – предполагаемое количество символов, которые будут, храниться в ячейках поля.
Точность — число знаков после запятой в числовых полях.
Ключ — указание, что данное поле является ключевым.
Данный состав свойств является минимально необходимым для описания данных, хранимых в таблице.
Физические модели хранения данных.
Физические модели хранения данных определяют методы размещения данных в памяти компьютера или на соответствующих носителях информации, а также способы хранения и доступа к этим данным. Исторически первыми системами хранения и доступа были файловые структуры и системы управления файлами (СУФ). Фактически файловые структуры хранения информации являлись и являются основой операционных систем. В системах управления базами данных использование файловых систем хранения информации оказалось не эффективным потому, что пользователю требовалась информация в виде отдельных данных, а не содержание всего файла. Поэтому в современных СУБД перешли от файловых структур к непосредственному размещению данных на внешних носителях – устройствах внешней памяти. Однако механизмы управления, применяемые в файловых системах, во многом перешли и в новые системы организации данных во внешней памяти, называемые чаще страничными системами хранения информации.
Файловые структуры организации базы данных.
В каждой СУБД по-разному организованы хранение и доступ к данным, однако существуют некоторые файловые структуры, которые применяются практически во всех СУБД.
В системах баз данных файлы и файловые структуры, которые используются для хранения информации во внешней памяти, можно классифицировать.
С точки зрения пользователя, файл представляет собой поименованную область дискового пространства, в которой хранится некоторая последовательность записей. В таком файле всегда можно определить первую и последнюю запись; текущую запись; запись, предшествующую текущей и следующую за ней.
В соответствии с методами управления доступом к информации в файлах различают устройства внешней памяти (накопители информации) с произвольной адресацией, или прямым доступом (магнитные и оптические диски), и устройства с последовательной адресацией, или последовательным доступом (магнитофоны, стриммеры).
На устройствах с произвольной адресацией возможна установка головок для чтения записи в любую область накопителя практически мгновенно.
На устройствах с последовательной адресацией вся память рассматривается как линейная последовательность информационных элементов. Поэтому в таких накопителях для получения информации требуется пройти некоторый путь от исходного состояния считывающего устройства до нужной записи.
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа.
В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи (NZ).
Каждая файловая система — система управления файлами — поддерживает некоторую иерархическую файловую структуру, включающую чаще всего ограниченное число уровней иерархии в представлении внешней памяти (рис. 9).
Для каждого файла в системе хранится следующая информация:
· тип файла (например, расширение или другие характеристики);
· число занятых физических блоков; - базовый начальный адрес;
· ссылка на сегмент расширения;
· способ доступа (код защиты).
Для файлов с постоянной длиной записи адрес размещения записи с номером К может быть вычислен по формуле
ВА+(К – 1) • LZ + 1, где ВА – базовый адрес; LZ – длина записи.
Если можно определить адрес, на который необходимо позиционировать механизм считывания записи, то устройства прямого доступа делают это практически мгновенно, поэтому для таких файлов чтение произвольной записи практически не зависит от ее номера.
На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа.
Они могут быть организованы двумя способами:
1. конец записи отмечается специальным маркером;
2. в начале каждой записи записывается ее длина.
Файлы с прямым доступом обеспечивают достаточно надежный способ доступа к записи. Основным недостатком файлов прямого доступа является то, что поиск записи производится по ее номеру, что при большом числе записей занимает существенное время.
Суть методов хеширования состоит в том, что выбираются значения ключа (или некоторые его характеристики), которые используются для начала поиска, т.е. вычисляется так называемая хеш-функция h(k), где k – значение ключевого поля. В этом случае число шагов поиска значительно уменьшается. Однако при таком подходе возможны ситуации, когда нескольким разным ключам может соответствовать одно значение хеш-функции, т.е. один адрес. Подобные ситуации называются коллизиями. Значения ключей, которые имеют одно и то же значение хеш-функции, называются синонимами.
Поэтому при использовании хеширования как метода доступа необходимо принять два независимых решения:
· выбрать метод разрешения коллизий.
Существует множество различных стратегий разрешения коллизий, наиболее распространенными из которых являются:
Физические модели баз данных определяют способы размещения данных в среде хранения и способы доступа к этим данным, которые поддерживаются на физическом уровне. Исторически первыми системами хранения и доступа были файловые структуры и системы управления файлами (СУФ), которые фактически являлись частью операционных систем. СУБД создавала над этими файловыми моделями свою надстройку, которая позволяла организовать всю совокупность файлов таким образом, чтобы она работала как единое целое и получала централизованное управление от СУБД . Однако непосредственный доступ осуществлялся на уровне файловых команд, которые СУБД использовала при манипулировании всеми файлами, составляющими хранимые данные одной или нескольких баз данных.
Однако механизмы буферизации и управления файловыми структурами не приспособлены для решения задач собственно СУБД , эти механизмы разрабатывались просто для традиционной обработки файлов, и с ростом объемов хранимых данных они стали неэффективными для использования СУБД . Тогда постепенно произошел переход от базовых файловых структур к непосредственному управлению размещением данных на внешних носителях самой СУБД . И пространство внешней памяти уже выходило из-под владения СУФ и управлялось непосредственно СУБД . При этом механизмы , применяемые в файловых системах, перешли во многом и в новые системы организации данных во внешней памяти, называемые чаще страничными системами хранения информации. Поэтому наш раздел, посвященный физическим моделям данных , мы начнем с обзора файлов и файловых структур, используемых для организации физических моделей, применяемых в базах данных, а в конце ознакомимся с механизмами организации данных во внешней памяти, использующими страничный принцип организации.
Файловые структуры, используемые для хранения информации в базах данных
В каждой СУБД по -разному организованы хранение и доступ к данным, однако существуют некоторые файловые структуры, которые имеют общепринятые способы организации и широко применяются практически во всех СУБД .
В системах баз данных файлы и файловые структуры, которые используются для хранения информации во внешней памяти, можно классифицировать следующим образом (см. рис. 9.1).
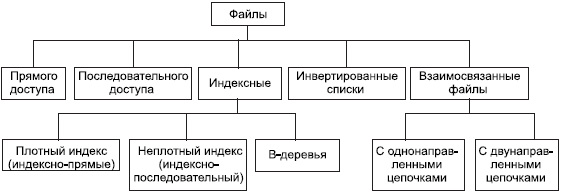
Рис. 9.1. Классификация файлов, используемых в системах баз данных
С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на внешних носителях. На рис. 9.2 представлена такая условная последовательность записей.
Так как файл — это линейная последовательность записей, то всегда в файле можно определить текущую запись , предшествующую ей и следующую за ней. Всегда существует понятие первой и последней записи файла. Не будем вдаваться в особенности физической организации внешней памяти, выделим в ней те черты, которые существенны для рассмотрения нашей темы.
В соответствии с методами управления доступом различают устройства внешней памяти с произвольной адресацией (магнитные и оптические диски) и устройства с последовательной адресацией (магнитофоны, стримеры ).
На устройствах с произвольной адресацией теоретически возможна установка головок чтения-записи в произвольное место мгновенно. Практически существует время позиционирования головки, которое весьма мало по сравнению со временем считывания-записи.
В устройствах с последовательным доступом для получения доступа к некоторому элементу требуется "перемотать (пройти)" все предшествующие ему элементы информации. На устройствах с последовательным доступом вся память рассматривается как линейная последовательность информационных элементов (см. рис. 9.3).
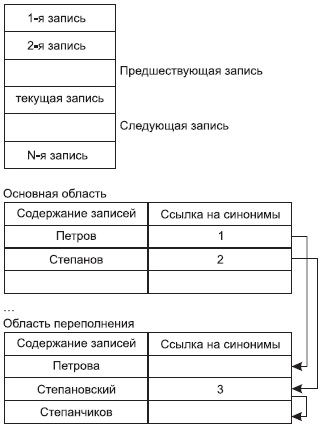
Рис. 9.2. Файл как линейная последовательность записей

Рис. 9.3. Модель хранения информации на устройстве последовательного доступа
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа.
В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи (NZ).
Каждая файловая система СУФ — система управления файлами поддерживает некоторую иерархическую файловую структуру, включающую чаще всего неограниченное количество уровней иерархии в представлении внешней памяти (см. рис. 9.4).
В данном посте база SQLite будет рассмотрена в разрезе, вы можете найти информацию о строении файла базы данных, о представлении данных в памяти, а также информацию о структуре и файловом представлении В – дерева.
Формат файла базы данных
Вся база данных хранится в одном файле на диске под названием «main database file». Во время транзакций, SQLite хранит дополнительную информацию во втором файле: журнал отката (rollback journal), либо, если база работает в режиме WAL, лог-файл с информацией о записях. Если приложение или компьютер отключился до окончания транзакции, то данные файлы называются «hot journal» или «hot WAL file» и содержат необходимую информацию для восстановления базы в согласованное состояние.
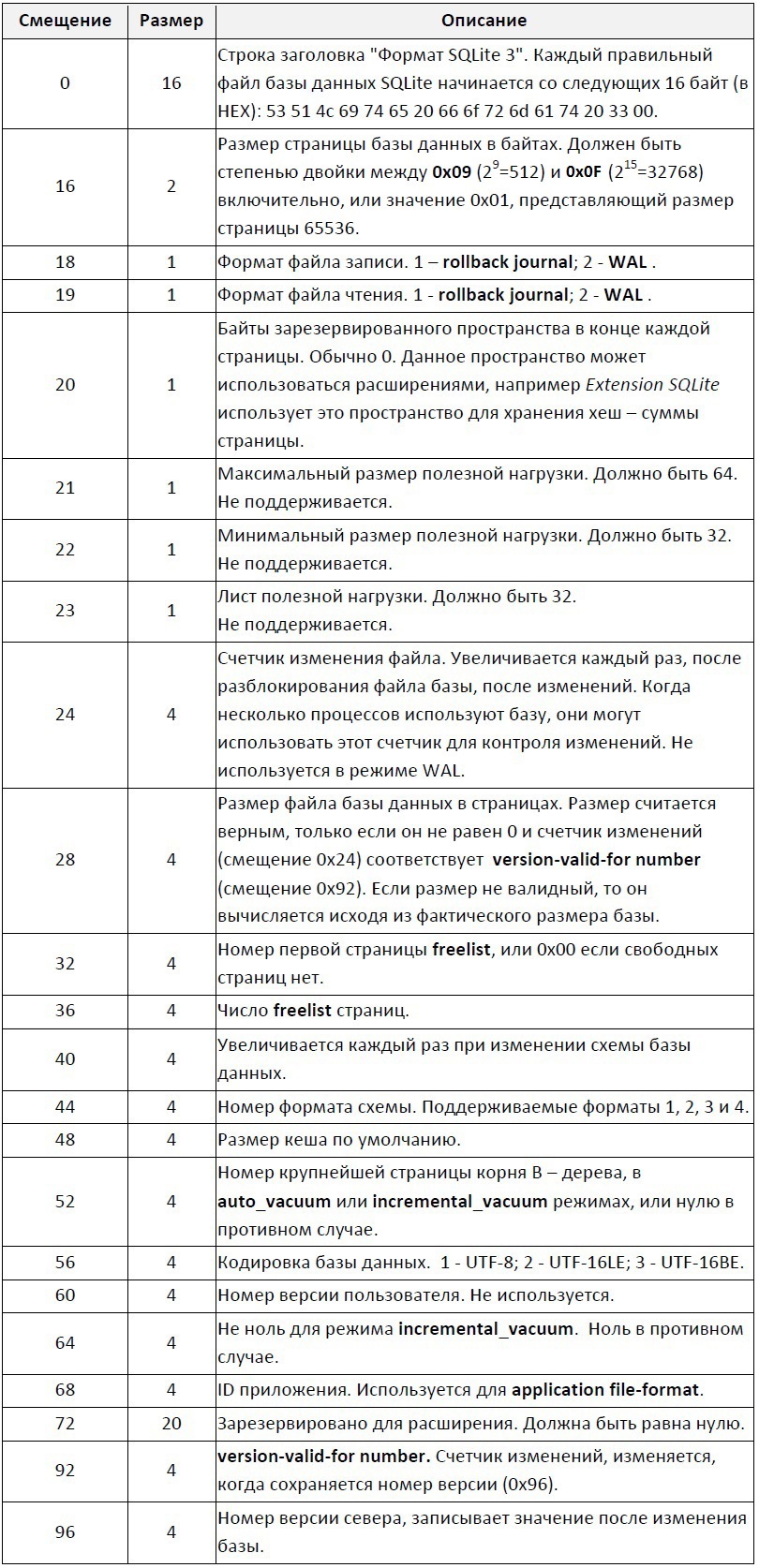
Основной файл базы состоит из одной или нескольких страниц. Все страницы в одной базе имеют одинаковый размер, который может быть от 512 до 65536 байт. Размер страницы для файла базы определяется целым 2-ух байтовым числом со смещением 16 байт от начала файла базы данных.
Все страницы пронумерованы от 1 до 2147483646 (2^31 – 2). Минимальный размер базы: одна страница размеров 512 байт, максимальный размер базы: 2147483646 страниц по 65536 байт (
Заголовок
Первый 100 байт файла базы данных содержат заголовок базы, в таблице 1 представлена схема заголовка.
Lock-byte страница
Freelist
Список пустых страниц организован как связный список. Каждый элемент списка состоит из двух чисел по 4 байта. Первое число определяет номер следующего элемента freelist (trunk pointer), либо равняется нулю, если список кончился. Второе число, это указатель на страницу данных (Leaf page numbers). На рисунке ниже показана схема данной структуры.

B — tree
SQLite использует две вида деревьев: «table B – tree» (на листьях хранятся данные) и «index B – tree» (на листьях хранятся ключи).
Каждая запись в «table B – tree» состоит из 64-битового целое ключа и до 2147483647 байт произвольных данных. Ключ «table B – tree» соответствует ROWID таблицы SQL.
Каждая запись в «index B – tree» состоит из произвольного ключа до 2147483647 байт в длину.
- Заголовок файла базы данных (100 байт)
- Заголовок страницы B-дерева (8 или 12 байт)
- Массив указателей ячеек
- Незанятое пространство
- Содержимое ячейки
- Зарезервированное место
Заголовок файла базы данных встречается только на первой странице, которая всегда является старицей «table B – tree». Все остальные страницы B-дерева в базе не имеют этого заголовка.
Заголовок страницы B-дерева имеет размер 8 байт для страниц листьев и 12 байт для внутренних страниц. В таблице 2 представлена структура заголовка страницы.

Freeblock — это структура, используемая для определения незанятого пространства внутри страницы B-дерева. Freeblock организованы в виде цепочки. Первые 2 байта в freeblock (от старшего к младшему), это смещением до следующего freeblock, или ноль, если freeblock является последним в цепочке. Третий и четвертый байты – целое число, размер freeblock в байтах, включая заголовок в 4 байта. Freeblocks всегда связаны в порядке возрастания смещения.
Число фрагментированных байт – это общее число неиспользуемых байт в области содержимого ячейки.
Массив указателей ячеек состоит из K 2-байтовых целочисленных смещений содержимого ячеек (при K ячейках в B-дереве). Массив отсортирован по возрастанию (от наименьших ключей к наибольшим).
Незанятое пространство — это область между последней ячейкой массива указателей и началом первой ячейки.
Зарезервированное место в конце каждой страницы используется расширениями для хранения информации о странице. Размер зарезервированной области определяется в заголовке базы (по умолчанию равен нулю).
Representation
TABLE
TABLEWITHOUT ROWID
Каждая таблица (без ROWID) представляется в базе в виде index b — tree. Отличие от таблиц с rowid, заключается в том, что ключ каждой записи SQL таблицы хранится в виде record format, при чем столбцы ключа хранятся как указаны в PRIMARY KEY, а остальные в порядке указанном в объявлении таблицы.
Таким образом записи в index b — tree представляются также как и в table b — tree, кроме порядка столбцов и того, что содержание строки хранится в ключе дерева, а не в качестве данных на листьях как в table b — tree.
INDEX
Каждый индекс (объявленный CREATE INDEX, PRIMARY KEY или UNIQUE) представляется в базе в виду index b — tree. Каждая запись в таком дереве соответствует строки в SQL таблице. Ключ индексного дерева представляет собой последовательность значений столбцов указанных в индексе и завершается значением ключа строки (rowid или primary key) в record format.
UPD 13:44: переработан раздел Representation, спасибо за критику mayorovp (можно было конечно и пошевелиться, ну да ладно).
Файлы и файловые структуры, широко применяемые практически во всех СУБД для хранения информации во внешней памяти, можно классифицировать следующим образом (рис. 6).
Так как файл — это линейная последовательность записей, то всегда в файле можно определить текущую запись, предшествующую ей и следующую за ней.

Рис. 6. Классификация файлов, используемых в системах баз данных
Для каждого файла в системе хранится следующая информация:
тип файла (например, расширение или другие характеристики);
количество занятых физических блоков;
базовый начальный адрес;
ссылка на сегмент расширения;
Известно, что в соответствии с методами управления доступом различают устройства внешней памяти произвольного и последовательного доступа.
На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа.
Вообще файлы могут иметь постоянную или переменную длину записи. Файлы с переменной длиной записи всегда являются файлами последовательного доступа. Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа, являются файлами прямого доступа.
Наиболее перспективным в системах баз данных считается использование файлов прямого доступа, поскольку посредством их обеспечивается наиболее быстрый доступ к произвольным записям. Для файлов с постоянной длиной записи физический адрес расположения нужной записи может быть вычислен по номеру записи. Но доступ по номеру записи в базах данных весьма неэффективен. Чаще всего в базах данных необходим поиск по ключу, для которого необходимо определить соответствующий ему номер записи, а следовательно, предпочтительнее связывать между собой не номер записи и физический адрес, а значение ключа записи и номер записи файла.
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение линейной обеспечивающей однозначное соответствие функции, которая по значению ключа однозначно вычисляет номер записи файла. Однако чаще всего такой подход оказывается неприемлемым и тогда приходится искать выход в привлечении других технологий.
Читайте также: