
Как используют модели файла устройства
Файловая система позволяет программам обходиться набором достаточно простых операций для выполнения действий над некоторым абстрактным объектом, представляющим файл . При этом программистам не нужно иметь дело с деталями действительного расположения данных на диске, буферизацией данных и другими низкоуровневыми проблемами передачи данных с запоминающего устройства. Все эти функции файловая система берет на себя. Файловая система распределяет дисковую память , поддерживает именование файлов, отображает имена файлов в соответствующие адреса во внешней памяти, обеспечивает доступ к данным, поддерживает разделение, защиту и восстановление данных.
Таким образом, файловая система играет роль промежуточного слоя, экранизирующего все сложности физической организации долговременного хранилища данных и создающего для программ более простую логическую модель этого хранилища, а затем предоставляет им набор удобных в использовании команд для манипулирования файлами.
Классическая схема организации программного обеспечения файловой системы представлена на рис. 7.6.
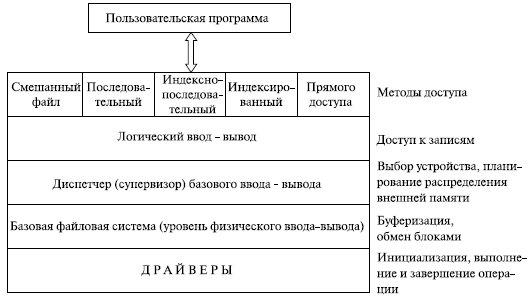
Рис. 7.6. Организация программного обеспечения файловой системы
На нижнем уровне драйверы устройств непосредственно связаны с периферийными устройствами или их котроллерами либо каналами. Драйвер устройства отвечает за начальные операции ввода-вывода устройства и за обработку завершения запроса ввода-вывода. При файловых операциях контролируемыми устройствами являются дисководы и стримеры (накопители на МЛ). Драйверы устройств рассматриваются как часть операционной системы.
Следующий уровень называется базовой файловой системой, или уровнем физического ввода-вывода. Это первичный интерфейс с окружением (периферией) компьютерной системы. Он оперирует блоками данных, которыми обменивается с дисками, магнитной лентой и другими устройствами. Поэтому он связан с размещением и буферизацией блоков в оперативной памяти. На этом уровне не выполняется работа с содержимым блоков данных или структурой файлов. Базовая файловая система обычно рассматривается как часть операционной системы (в MS- DOS эти функции выполняет BIOS , не относящийся к ОС).
Диспетчер базового ввода-вывода отвечает за начало и завершение файлового ввода-вывода. На этом уровне поддерживаются управляющие структуры, связанные с устройством ввода-вывода, планированием и статусом файлов. Диспетчер осуществляет выбор устройства, на котором будет выполняться операция файлового ввода-вывода, планирование обращения к устройству (дискам, лентам), назначение буферов ввода-вывода и распределение внешней памяти. Диспетчер базового ввода-вывода является частью ОС.
Логический ввод- вывод предоставляет приложениям и пользователям доступ к записям. Он обеспечивает возможности общего назначения по вводу-выводу записей и поддерживает информацию о файлах. Наиболее близкий к пользователю уровень ФС часто называется методом доступа. Он обеспечивает стандартный интерфейс между приложениями и файловыми системами и устройствами, содержащими данные. Различные методы доступа отражают различные структуры файлов и различные пути доступа и обработки данных.
7.13. Организация файлов и доступ к ним
Типы, именование и атрибуты файлов
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых входят обычные файлы, содержащие информацию произвольного характера (текст, графика , звук и др.), файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и др.
Обычные файлы, или просто файлы, или регулярные файлы, содержат информацию, которую в них заносит пользователь или которая образуется в результате работы системных и пользовательских программ. Большинство ОС не контролируют содержимое и структуру регулярных файлов , которые в основном являются ASCII-файлами либо двоичными файлами. ASCII-фалы состоят из текстовых строк. Они могут отображаться на экране и выводиться на печать без какого-либо преобразования, и могут редактироваться практически любым текстовым редактором. Двоичные файлы имеют определенную внутреннюю структуру, которая известна программе, использующей данный файл . При выводе двоичного файла на принтер получается случайный набор символов.
Каталоги – это системные файлы, обеспечивающие поддержку структуры файловой системы. Они содержат системную справочную информацию о наборе файлов, сгруппированных пользователем по какому-либо неформальному признаку (договоры, рефераты, курсовые проекты и т.п.). Во многих ОС в каталог могут входить другие файлы, в том числе другие каталоги, за счет чего образуется древовидная структура, удобная для поиска требуемого файла. Каталоги устанавливают соответствие между именами файлов и их характеристиками, используемыми файловой системой для управления файлами. В число таких характеристик входят тип файла , права доступа к файлу, его распоряжение на диске, размер, дата и время создания и др.
Специальные файлы – это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к последовательным устройствам ввода-вывода, таким как терминалы, принтеры и др. (например, MS- DOS рассматривает монитор и клавиатуру как файлы со стандартным именем con – консоль , а принтер – как файл prn ). Блочные специальные файлы используются для моделирования дисков.
Именованные конвейеры (каналы) представляют собой циклические буферы, позволяющие выходной файл одной программы соединить со входным файлом другой программы.
Наконец, отображаемые файлы – это обычные файлы, отображенные на адресное пространство процесса по указанному виртуальному адресу.
Файлы относятся к абстрактному механизму. Они предоставляют способ сохранять информацию на запоминающем устройстве и считывать ее позднее снова. При этом от пользователя должны скрываться такие детали, как способ и место хранения информации, а также детали работы устройства.
Во многих операционных системах имя файла состоит из двух частей, разделенных точкой. Часть имени после точки называется расширением файла и обычно означает его тип. Так, в MS- DOS имя файла может содержать от 1 до 8 символов, а расширение от 0 (отсутствует) до 3.
В некоторых ОС, например, Windows , расширение указывает на программу, создавшую файл . Другие ОС, например, UNIX , не принуждают пользователя строго придерживаться расширений. Некоторые типичные расширения файлов приведены ниже.
В иерархически организованных файловых системах обычно используются три типа имен файлов: простые, составные и относительные.
Простое (короткое) символьное имя идентифицирует файл в пределах одного каталога. Несколько файлов могут иметь одно и то же простое имя , если они принадлежат разным каталогам.
Составное (полное) символьное имя представляет собой цепочку, содержащую имя диска и имена всех каталогов, через которые проходит путь от корневого каталога до данного файла.
Относительное имя файла определяется через текущий каталог , т.е. каталог, в котором в данный момент времени работает пользователь . Таким образом, относительных имен у файла может быть достаточно много, и все они являются частью полного имени.
Понятие файла включает не только хранимые им данные и имя, но и информацию, описывающую свойства файла. Эта информация составляет атрибуты файла. Список атрибутов может быть различным в различных ОС. Пример возможных атрибутов приведен ниже.
Пользователь может получить доступ к атрибутам, используя средства, предоставляемые для этой цели файловой системой. Обычно разрешается читать значение любых атрибутов, а изменять – только некоторые.
Значения атрибутов файлов могут содержаться в каталогах, как это сделано, например, в MS- DOS (рис. 7.7). Другим вариантом является размещение атрибутов в специальных таблицах, в этом случае в каталогах содержатся ссылки на эти таблицы.
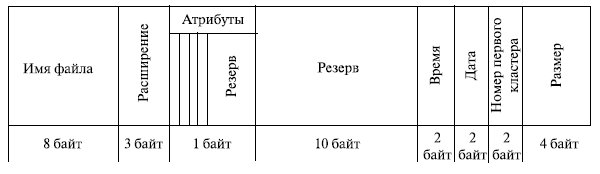
Логическая организация файла
В общем случае данные, содержащиеся в файле, имеют некоторую логическую структуру. Эта структура (организация) файла является базой при разработке программы, предназначенной для обработки этих данных. Поддержание структуры данных может быть целиком возложено на приложение либо в той или иной степени эту работу может взять на себя файловая система .
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла, целиком относятся к ведению приложения, файл представляется файловой системе неструктурированной последовательностью данных. Приложение формирует запросы к файловой системе на ввод- вывод , используя общие для всех приложений системные средства, например, указывая смещение от начала файла и количество байт , которые необходимо считать или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой. Следует подчеркнуть, что интерпретация данных никак не связана с действительным способом их хранения в файловой системе.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью байт , стала популярной вместе с ОС UNIX , и теперь широко используется в современных ОС. Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями, поскольку разные приложения могут по -своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла – структурированный файл . В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением!
Известно пять фундаментальных способов организации файлов [10]:
- смешанный файл,
- последовательный файл ,
- индексно- последовательный файл ,
- индексируемый файл,
- файл прямого доступа.
При выборе способа организации файла нужно учитывать несколько критериев:
- быстрота доступа,
- легкость обновления,
- экономность хранения,
- простота обслуживания,
- надежность.
Смешанный файл . Это наименее сложная форма организации файла. Данные накапливаются в порядке поступления. Запись состоит из одного пакета данных. Записи могут иметь различные или одинаковые поля, расположенные в различном порядке (рис. 7.8). Каждое поле описывает само себя, включая как имя, так и значение . Длина каждого поля должна быть указана явно либо посредством применения разделителя.

Поскольку смешанный файл не имеет никакой структуры, доступ к записи осуществляется полным перебором всех записей файла. Смешанные файлы применяются в том случае, когда данные накапливаются и сохраняются перед обработкой, или если данные неудобны для организации. Файлы этого типа рационально используют дисковое пространство , хорошо подходят для полного набора. Обновление записей достаточно сложно, так же как и вставка записи.
Последовательный файл . Для записей используется фиксированный формат. Все записи имеют одинаковую длину (но иногда и не одинаковую) и состоят из одинакового количества полей фиксированной длины, организованных в определенном порядке (рис. 7.9). Поскольку длина и позиция каждого поля известны, сохранению подлежат только значения полей. Атрибутами файловой структуры является имя и длина каждого поля.
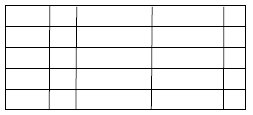
Одно определенное поле (или несколько полей) называется ключевым. Оно однозначно идентифицирует запись , так как это поле различно для каждой записи. Более того, записи сохраняются в "ключевой" последовательности: в алфавитном порядке для текстового ключа и в числовом – для числового. Последовательные файлы часто используются пакетными приложениями и обычно являются оптимальным вариантом, если эти приложения выполняют обработку всех записей. Удобно и то, что такой файл можно хранить как на ленте, так и на магнитном диске.
Для диалоговых приложений последовательный файл малоэффективен, поскольку для нахождения нужной записи требуется последовательный перебор записи файла. Правда, если в оперативную память загрузить весь файл , возможен более эффективный метод поиска. Дополнения к файлу или изменения в записях создают проблемы.
Обычно последовательный файл сохраняется с последовательной организацией записей внутри блока, т.е. физическая организация файла в точности соответствует логической. Новые записи размещаются в отдельном смешанном файле, называемом журнальным файлом, или файлом транзакции. Периодически в пакетном режиме выполняется слияние основного и журнального файлов в новый файл с корректной последовательностью ключей.
Альтернативной организацией может быть физическая организация в виде списка с использованием указателей. В каждом физическом блоке сохраняется одна или несколько записей, и каждый блок содержит указатель на следующий блок. Для вставки новых записей достаточно изменить указатели, и нет необходимости в том, чтобы новые записи занимали определенную физическую позицию. Это удобство достигается за счет определенных накладных расходов и дополнительной работы. Если в последовательном файле записи имеют одну и ту же длину, то можно вычислить адрес требуемой записи по ее номеру, номеру текущей записи и длине записи. Если записи имеют переменную длину, такой подход невозможен.
Индексно- последовательный файл . Одним из методов преодоления недостатков последовательного файла является индексно-последовательная организация файла. В этом случае файл состоит из трех частей (файлов): главный файл , содержащий записи с последовательно идущими ключами, индексный файл , содержащий индексное поле , и указатель в главный с ключами, файл переполнения (рис. 7.10).
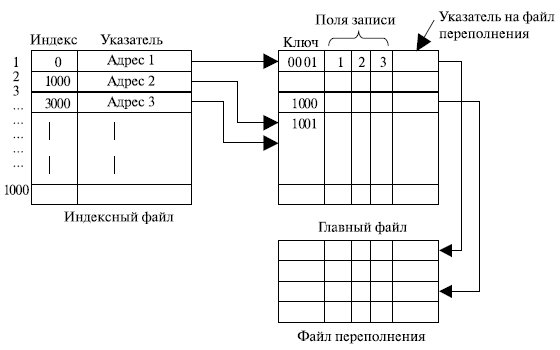
Для поиска нужной записи по ее ключу сначала выполняется поиск в индексном файле. После того как в нем найдено наибольшее значение ключа, которое не превышает искомое, продолжается поиск в главном файле. Например, пусть последовательный файл (главный) содержит 1 млн записей. Для поиска определенного ключевого значения необходимо в среднем 0,5 млн операций доступа к записям. Если создать индексный файл , содержащий 1000 элементов, то потребуется в среднем 500 операций доступа к индексному файлу, после чего еще нужно в среднем 500 операций доступа к главному файлу. В результате средняя длина поиска уменьшилась с 0,5 млн до 1000. Еще лучшего результата можно достичь, используя многоуровневую индексацию. При этом нижний уровень индексного файла рассматривается как последовательный файл , для которого создается индексный файл верхнего уровня.
Дополнения к файлу обрабатываются следующим образом. В каждой записи главного файла содержится дополнительное поле , невидимое для приложения и являющееся указателем на файл переполнения. Если в файле производится вставка новой записи, она добавляется в файл переполнения. Запись в главном файле, непосредственно предшествующая новой записи в логической последовательности, обновляется и указывает на новую запись в файле переполнения. Время от времени выполняется слияние индексно- последовательного файла с файлом переполнения.
Индексированный файл . Индексно- последовательный файл сохраняет одно ограничение последовательного файла : эффективная работа с файлом ограничена работой с ключевым полем. Если необходимо производить поиск записи по какой-либо иной характеристике, отличной от ключевого поля, то оказываются непригодными обе организации последовательного файла , в то время как в некоторых приложениях эта гибкость крайне желательна.
Для достижения гибкости необходимо применение большого количества индексов, по одному для каждого типа поля, которое может быть объектом поиска. В обобщенном индексированном файле доступ к записям осуществляется только по их индексам. В результате в размещении записей нет никаких ограничений до тех пор, пока указатель по крайней мере в одном индексе ссылается на эту запись . Кроме того, в таком файле легко реализуются записи переменной длины.
Используется два типа индексов. Полный индекс содержит по одному элементу для каждого типа записей главного файла. Сам по себе индекс организовывается в виде последовательного файла для облегчения поиска. Частный индекс содержит элементы для записей, в которых имеется интересующее пользователя поле . При добавлении новой записи в главный файл необходимо обновлять все индексные файлы.
Индексированные файлы применяются теми приложениями, в которых время доступа к информации является критической характеристикой и редко требуется обработка всех записей в файле.
Файл прямого доступа. Такой файл использует возможность прямого доступа к блоку с известным адресом при хранении файлов на диске. В каждой записи в этом случае также имеется ключевое поле .
Файлы устройств ( англ. Device file ) - это специальные файлы, которые используются почти во всех производных Unix и многих других операционных системах . Они дают возможность простой связи между пользовательским пространством , например , обычные пользовательские программы , а ядро и , таким образом , в конечном счете, аппаратное обеспечение в компьютере . Эта связь прозрачна, поскольку файлы устройств используются как обычные файлы.
Содержание
Файлы устройств под Unix
Типы файлов устройств
В файловых системах из Unix и подобных операционные систем , различие между «нормальными» файлами (двоичным / ASCII), каталоги , названные трубы (также называемый FIFOs ), символическими ссылками , розетками и блоками данных . В то время как «обычные» файлы и каталоги являются частью стандартных функций обычных файловых систем, именованные каналы уже играют особую роль, но не являются частью файлов устройства. Только последние три типа являются файлами устройств. Поэтому различают три типа файлов устройств:
- символьные устройства : символьные устройства
- блочные устройства : блочно-ориентированные устройства
- сокетные устройства : устройства, ориентированные насокеты
Команды, такие как ls или , подходят для вывода типа файла (устройства) file .

Поскольку обычно для каждого устройства существует отдельный файл устройства, эти файлы уже были собраны в каталоге в ранних версиях Unix /dev . В Стандарте иерархии файловой системы эта процедура была стандартизирована для Linux ( Solaris хранит файлы устройств в виртуальной файловой системе /devices и автоматически генерирует символические ссылки, указывающие /dev на фактические файлы /devices ); также предписывается, какие файлы устройств должны находиться в этом каталоге под каким именем (см. списки ниже). Современные производные Unix часто используют специальные (виртуальные) файловые системы, чтобы поддерживать этот каталог в актуальном состоянии. Долгое время devfs была популярна под Linux , но теперь udev берет на себя администрирование файлов устройства.
Файлы устройств используются в качестве интерфейса между драйверами устройств или компонентами системы и прикладными программами, которые выполняются в пространстве пользователя . Например, вы можете печатать на LPT- принтере, который подключен к компьютеру через параллельный интерфейс, путем записи текста непосредственно в файл устройства /dev/lp0 . Концепция файлов устройств означает, что программы в принципе отделены от драйверов устройств, работающих в ядре. Кроме того, использование устройства выглядит совершенно прозрачным - вам не нужно предварительно использовать специальную программу, но вы можете записывать в файл, соответствующий принтеру. Это обеспечивает интуитивно понятное использование оборудования.
Концепция файлов устройств является одной из основ принципа Unix. Все является файлом и была расширена, например, такими подходами, как производный Plan 9 .
Блочно-ориентированные устройства
Блочные устройства (также блочное запоминающее устройство, блочное устройство или англ. Block device ) передают данные в виде блоков данных и поэтому часто используются для параллельной передачи данных . Все эти устройства используют собственный буфер операционной системы .
Устройства, ориентированные на персонажей
Символьно-ориентированные устройства передают только один символ (обычно один байт ) за раз, поэтому они должны быть назначены для последовательной передачи данных . Обычно, но не всегда, данные передаются без буферизации, т.е. немедленно.
В сетевых картах ( например , Ethernet , , ISDN ) не рассмотрены под Linux с помощью файлов устройства, но через стек TCP / IP , хотя файлы устройства часто существуют также для специальных применений , таких как прямой контроль аппаратных средств ( Нетлинк устройство, D-канал, и т.д.) .
Розеточные устройства
Для устройств на основе сокетов это не файлы устройств, а форма межпроцессного взаимодействия . Как и FIFO , они не являются файлами устройств, но их также можно использовать для связи с ядром и выполнения той же задачи, что и для символьных устройств.
| Имя файла | важность |
|---|---|
| /dev/log | Разъем для системного журнала - Демон |
| /dev/gpmdata | Разъем для мультиплексора мыши GPM |
| /dev/printer | Розетка для lpd |
Поддельные устройства
Файл устройства не соответствует реальному устройству, но также может быть так называемым виртуальным устройством ( виртуальное устройство ) или псевдоустройством ( доступно псевдоустройство ). Это рабочий инструмент, за функционирование которого отвечает операционная система (ядро, расширение ядра, драйвер).
Вопреки тому, что предполагает термин виртуальное устройство , здесь не обязательно воспроизводить физическое устройство (см. Виртуализацию ).
Ниже приводится список наиболее распространенных псевдоустройств (все символьные) в Unix и подобных системах :
| /dev/null | отбрасывает любой ввод, не производя вывода |
| /dev/zero | создает поток символов, состоящий только из нулевых символов (в нотации C :), '\0' состоит |
| /dev/full | создает поток символов, который состоит только из нулевых символов (в нотации C :) во время доступа для чтения . Во время доступа для записи возникает ошибка ENOSPC ("диск заполнен"). '\0' |
| /dev/random | производит реальные случайные числа или , по крайней мере , криптографически сильные псевдо - случайных чисел ( в основном на основе аппаратных ресурсов) |
| /dev/urandom | производит псевдослучайные числа (в основном в отличие от /dev/random без блокировки, когда не генерируются аппаратные данные) |
Управление файлами устройства на примере Linux
Специфичная для Linux команда mknod используется для создания файлов устройств и требует соответствующих старшего и младшего номеров для создания файла устройства.
Если пользователь установил новый драйвер в ранних версиях Linux, один или несколько файлов устройств должны были быть созданы с помощью этой mknod команды с помощью документации по драйверу и указания необходимого старшего / младшего номера для создания требуемого интерфейса. Поэтому многие дистрибутивы Linux /dev уже предоставили тысячи файлов устройств в дереве каталогов, независимо от того, понадобятся ли они когда-либо. С одной стороны, это сбивало с толку, с другой стороны, было сложно автоматически загружать новые драйверы для нового оборудования, поскольку файлы устройств всегда приходилось поддерживать вручную.
За несколько лет и выпусков ядра были разработаны две новые концепции:
devfs
В DEVFS была введена в дереве Linux ядра 2.2 . Основная идея заключалась в том, что сами модули ядра несут информацию об именах файлов устройств, которые они генерируют, вместе с младшими и старшими номерами и типом. Это позволило ядру впервые сгенерировать файлы устройств.
Требуемые или предоставляемые ядром и его модулями файлы устройств автоматически попадают в ядро в файловой системе devfs с помощью созданных devfsd - демонов . Файловая система обычно /dev монтировалась в каталог .
После внимательного рассмотрения система с devfs показалась слишком негибкой. Требовалась система, которая реагирует на подключение нового оборудования ( горячее подключение ), загружает соответствующие модули ядра, создает файлы устройств и удаляет их снова, когда устройства отключаются. Кроме того, должна быть возможность определить с помощью набора правил, какую схему именования вы хотите использовать для файлов вашего устройства, как они должны быть структурированы в подкаталогах и т. Д.
С появлением ядра 2.6 udev стал новой концепцией управления устройствами. Подобно devfs, есть также демон, который работает в пользовательском пространстве и выполняет реальную работу. Однако udev не использует свою собственную файловую систему, а необходимый компонент ядра намного компактнее, то есть меньше и проще.
Файлы устройства под Windows
В Windows также есть файлы устройств: вы можете получить к ним доступ как программист с помощью подпрограммы CreateFile() . Имя файла устройства имеет формат \\.\NAME . Файлы устройств нельзя найти в обычных каталогах, как в Unix, и связь, соответственно, не прозрачна (для пользователя). Как пользователь, оболочка Windows обычно не имеет доступа к файлам устройства.
Моделирование в информатике — это процесс, при котором создается цифровой образ какого-то реально существующего объекта. Модель в информатике — это цифровой объект-прообраз объекта из реальной жизни. В информатике термин «модель» характеризуется несколькими определениями, например, модель — это:
- упрощенная копия реального объекта;
- уменьшенное копия реального объекта;
- схематичное представление явления или процесса;
- графическое представление явления или процесса;
- текстовое представление явления или процесса;
- аналогичное представление физического объекта;
- информационное представление реального объекта;
- цифровой объект-аналог реального объекта;
- и т. д.
То есть модель в информатике — это обширное понятие, определение которого может быть различным и зависит от конкретной ситуации.
Моделирование и модель в информатике, что это
- Материальная группа. К этой группе относят модели, которые основываются на реально существующих объектах, например, на каком-либо реальном предмете или процессе.
- Идеальная группа. К этой группе относятся модели, которые основываются не на реальных объектах, например, на произведениях искусства или литературе. То есть такие модели поддаются влиянию индивидуальным человеческим свойствам, например: мышлению, воображению или восприятию. Такие модели могут быть созданы разными людьми по-разному, даже если за основу будет взят один какой-то пример для моделирования.
Виды и цели моделирования в информатике
- учебное моделирование — это процесс, который необходим для обучения студентов, учеников и других обучающихся людей;
- моделирование для опытов — это процесс, при котором необходимо выяснить влияние на реальный объект каких-либо изменений в его сущность;
- имитационное моделирование — это процесс, при котором происходит имитация реального объекта с максимальным количеством его свойств для предугадывания исхода какого-либо события с объектом;
- игровое моделирование — это моделирование объектов для их использования в игровой индустрии;
- научно-техническое моделирование — это процесс, который применяется в различных научных исследованиях.
- проектировать новые реальные объекты, на основе уже имеющихся моделей (проектировать новые автомобили);
- проводить расчеты последствий после внесения изменений в реальные объекты (что будет, если пересадить автомобиль на атомное топливо);
- обеспечить подтверждение эффективности принятых решений (электромобили лучше дизельных автомобилей);
- представлять материальные предметы (проект жилого дома);
- и др.
Моделирование в информатике не происходит просто так, оно всегда преследует цель решить какую-то поставленную задачу. Задачи, которые решает моделирование, делятся на 2 большие группы:
- Прямые задачи. Это задачи, в которых задаются точные исходные данные и условия, и они требуют конкретного ответа. Например, такой задачей будет поиск ответа на вопрос: «Что будет, если мы сделаем так-то и так-то?». Результатом такой задачи будет один ответ или одно решение.
- Обратные задачи. Это задачи без конкретных исходных данных и условий. Такими задачами будет поиск ответа на вопрос: «Как можно улучшить что-либо?». Результатом таких задач может быть множество решений.
Модель в информатике — это разнообразие видов
- Образные модели. Эта группа включает в себя модели, где важна их внешняя составляющая, например рисунки и фотографии.
- Смешанные модели. Эта группа включает в себя модели, где внешняя составляющая моделей имеет второстепенное значение. Сюда входят: таблицы, графики, диаграммы, схемы (карты, графы, блок-схемы, чертежи).
- Знаковые модели. Эта группа включает в себя модели, где важна их символьная составляющая. Сюда входят: словесное описание, формулы, языки программирования.
Моделирование в информатике: этапы
- манекен — это модель человеческой фигуры;
- глобус — это модель нашей планеты;
- и т. д.
О физическом моделировании мы поговорим в другой раз, а сегодня нас интересуют этапы, через которые проходит моделирование в информатике с применением электронно-вычислительных машин.
Моделирование – метод познания окружающего мира, состоящий в создании и исследовании моделей реальных объектов.
Модель отражает только часть свойств, отношений и особенностей поведения оригинала.
Информационные модели - описание объекта-оригинала на языках кодирования информации.
Информационная модель - набор признаков, содержащий всю необходимую информацию об исследуемом объекте.
Знаковые информационные модели строятся с использованием различных языков (знаковых систем).
С точки зрения информатики, решение любой производственной или научной задачи описывается следующей технологической цепочкой: «реальный объект - модель - алгоритм - программа - результаты - реальный объект». В этой цепочке очень важную роль играет звено «модель», как необходимый, обязательный этап решения этой задачи. Под моделью при этом понимается некоторый мысленный образ реального объекта (системы), отражающий существенные свойства объекта и заменяющий его в процессе решения задачи.
Виды моделей.
Различают четыре основных вида модельных представлений:
1. Графические представления.
2. Словесные описания.
3. Информационно-логические модели.
4. Математические (количественные) модели.
Моделирование в информатике – это составление образа какого-либо реально существующего объекта, который отражает все существенные признаки и свойства. Модель для решения задачи необходима, так как она, собственно, и используется в процессе решения.
В школьном курсе информатики тема моделирования начинает изучаться еще в шестом классе. В самом начале детей необходимо познакомить с понятием модели. Что это такое?
- Упрощенное подобие объекта;
- Уменьшенная копия реального объекта;
- Схема явления или процесса;
- Изображение явления или процесса;
- Описание явления или процесса;
- Физический аналог объекта;
- Информационный аналог;
- Объект-заменитель, отражающий свойства реального объекта и так далее.
Модель – это очень широкое понятие, как это уже стало ясно из вышеперечисленного. Важно отметить, что все модели принято делить на группы:
Читайте также: