
Из json файла отображается бинарное дерево qt
Дерево является графом у которого есть единственный узел, называемый корнем. Рёбрами он связан с другими узлами (непосредственными потомками корня). Эти потомки, в свою очередь, имеют собственных потомков и т.д. Перемещаясь от корня по узлам дерева, можно попасть в любой узел, причём единственным образом. Деревья широко используются в различных задачах поиска решений. В этом документе обсуждаются способы визуального представления деревьев. К алгоритмам обработки деревьев мы вернёмся в дальнейшем.
Дерево будем задавать объектом: , где nm - имя узла, а ar - массив ветвей (ближайших потомков). Так, следующий объект tree описывает бинарное дерево глубины 2, изображенное справа на рисунке:
Это дерево имеет 7 узлов, 4 из которых - терминальные. Такие узлы также называются листьями. Далее предполагается, что дерево имеет хотя бы один (корневой) узел: . Как это часто бывает в компьютерной графике (с осью y, направленной вниз), ветви деревьев на картинках растут вниз. Поэтому, говоря о спуске по дереву вниз, мы будем подразумевать продвижение от корня к листьям. Внутреннее представление структуры любого объекта в виде строки, можно получить при помощи вызова функции JSON.stringify(tree) объекта JSON. Однако она даёт кавычки в названии свойств: , поэтому, для большей читабельности, обернём её регулярным выражением, удаляющим эти кавычки: У функции replace первым аргументом внутри слешей находится шаблон поиска. Запись \w+ означает символы из латинского алфавита, цифр или подчёркивания: [A-Za-z0-9_], которые идут подряд один или более раз (плюс после \w). Круглые скобки: (\w+) означают, что найденная подстрока запоминается в "переменной" $1, которая используется во втором аргументе функции replace. Там определяется замена, которую необходимо провести в найденном шаблоне (буква g после слеша означает глобальный поиск по всей строке).Функция getJSON является статической и не требует создания экземпляра класса Tree при помощи new. Можно просто написать: document.write( Tree.getJSON(tree) ), что даст строку:
В классе Tree все статические функции продублированы как "динамические", при помощи указателя prototype: Таким образом, класс Tree может в статическом варианте обрабатывать структуры подобные tree, а в динамическом - хранить дерево "внутри себя". Например, дерево в JSON-формате можно вставить в документ также так: var t = new Tree(tree); document.write( t.getJSON() ).
Вывод дерева
При работе с деревьями естественно использовать рекурсивные методы. Напишем, например, функцию вывода дерева в "функциональном" виде, которая для структуры tree, приведенной выше, выдаст строку: :
Небольшие изменения этой функции, позволяют вывести дерево в виде списка html (функция Tree.getUL(tr), выше, справа). Ещё две функции Tree.getGIF(tr) (в виде папочек) и Tree.getSVG(tr) (традиционное преставление) будут рассмотрены позднее.Копирование деревьев
Присвоение деревьев, как и любых объектов, проводится по ссылке. Чтобы получить независимую копию дерева, напишем незамысловатую функцию: Теперь для следующего кода получим: .
В функции copy снова использован объект JSON, функция parse которого позволяет преобразовать строку в объект, произведя её синтаксический анализ. Поэтому сначала, при помощи JSON.stringify, дерево превращается в строку, затем эта строка функцией parse преобразуется опять в дерево, но уже в новой памяти. Заметим, что в JavaScript объекты можно копировать (клонировать), как и массивы, следующим образом: copy_obj = Object.assign( <> , obj); Однако метод assign копирует только простые типы и не работает рекурсивно. Так как с узлом в дальнейшем могут быть связаны различные данные, ограничимся таким, не самым эффективным, однако простым способом копирования.Генерация деревьев
Для тестирования различных алгоритмов, необходимо создавать деревья "на лету". Напишем функцию, генерящую случайные деревья: Рисовать ящики:
Функция Tree.rand принимает на вход 3 параметра: depth - максимальная глубина, branches - максимальное число ветвей и cut - вероятность обрыва ветки (0 < cut < 1). При каждом рекурсивном вызове depth уменьшается, пока не станет равным нулю:
Получить максимальную глубину дерева tr и количество узлов можно при помощи следующих рекурсивных функций:
В качестве забавы, найдём среднюю глубину случайного дерева и среднее число узлов на нём (нажмите кнопку start):
depth: 2.64 nodes: 19.65 leaves: 12.18
Стоит попробовать вычислить эти параметры теоретически.
Деревья как функции
В ряде случаев удобнее задавать дерево не структурой, а строкой, подобной . Имена таких вложенных функций являются узлами дерева, а их аргументы - потомками этих узлов. При этом справедлива следующая грамматика: Грамматика является набором правил порождения синтаксически верных выражений. Она может выдать выражение f(x,g(h(a),z)), но не приведёт к синтаксически неверной записи типа f(,),(g(h,(a,z). В первой строке утверждается, что узлом дерева NODE может быть имя NAME (для терминальных узлов) или функция NAME(LIST) для нетеминальных. Эти две возможности перечисляются через вертикальную черту. Вторая строка - определение списка аргументов функции. При этом правило LIST :- NODE,LIST содержит в себе рекурсию (список - это узел NODE, после которого через запятую снова идёт список).
Функция Tree.parse(st) парсит строку st, выдавая на входе дерево в виде структуры. В ней введена статическая переменная pos указателя на текущее положение в анализируемой строке и вызывается первое грамматическое правило: Напишем функции для каждого элемента грамматики. Функция Tree.parseNODE возвращает дерево . Функция Tree.parseNAME даёт строку имени (узла или листа), которым будем считать что угодно, кроме скобок и запятых "(,)":
Последняя функция парсинга вычитывает список переменных в "функции": Теперь в html-документе можно написать следующий код: что приведёт к:
Вместо функции Tree.getSVG (вывод дерева как svg-картинки), можно воспользоваться любой другой функцией: Tree.getFun (в функциональном виде), Tree.getJSON (в JSON-формат), Tree.getUL (html-список) и Tree.getGIF ("файловая" система).
Дерево, как файловая система
Разберём подробнее функцию Tree.getGIF, выводящую дерево, подобно списку файлов и папок на компьютере, с возможностью сворачивания веток дерева и иерархической пометкой узлов (покликайте на папках, листиках и плюсиках):
Прежде чем описывать её устройство, приведём пример использования. Если от дерева не требуется итерактивности, вставка его в html-страницу делается так: Если же нужна динамичность, то необходимо создать экземпляр класса Tree при помощи оператора new. Его имя, как строку, необходимо передать в функцию и задать функцию рисования show, которая вызывается деревом при его изменении. Кроме стандартных сворачиваний и разворачиваний узлов (папок), реализована рекурсивная пометка узлов и листьев (необходимо кликнуть на папку или лист). Соответствующие пометки добавляются в каждый узел дерева свойством chk, равным 1 или 0. Статической функцией Tree.arrProp(tr,"chk",1) можно получить массив всех выбранных листьев. Кроме этого, непомеченный узел-папки имеет значение chk=2, если хотя бы один его потомок помечен. Если папка помечается (chk=1), то автоматически помечаются все её потомки. Если с папки снята пометка, то она снимается и с потомков. При изменении пометки вызывается функция select, а при клике на имя узла - функция click:
Реализация getANSII
Чтобы не погрязнуть в дизайнерских изысках, нарисуем сначала дерево при помощи псевдографики (ниже первый результат):
При стартовом запуске статическая функция Tree.getANSII вызывается без второго праметра calc и возвращает строку, разбитую на линии символами возврата каретки ("\n"). Если параметр clac=true (при рекурсивных вызовах), то функция возвращает массив строк отображения данного узла:Реализация getGIF
Теперь можно модифицировать функцию getANSII для рисования красивого дерева. Оределим классы стилей: При наличии квадратных картинок (18px):
p111.jpg: , p110.jpg: , l101.jpg: , l111.jpg: l110.jpg: flop.jpg: , page.jpg: .
следующий html-код: приведёт к вполне себе симпатичному дереву:
Именно эти div-ки и img-ы необходимо вставить в функции Tree.getANSII для получения функции Tree.getGIF рисования дерева при помощи gif-ок.Чтобы придать динамичности дереву из gif-ок, добавляются ссылки на картинки и назавания узлов. Так для картинок с плюсиками надо написать: Дальнейшие детали можно найти в исходниках.
Графическое svg-представление
"Традиционное" рисование дерева в виде куста, растущего вниз, реализовано в функции getSVG. Она выводит дерево в виде текста - описания svg-файла. Его можно просто вствить в html-документ. Для настройки отображения дерева в svg-формате служит следующая структура: Если узел дерева имеет пометку vis==false, то он не рисуется вместе со всеми потомками. При пометке hide==true узел не рисуется, но пространство под него выделяется (не сжимается, как это происходит при vis==false). В зависимости от значения пометки chk=0,1. и наличия массива Tree.svg.colors, можно раскрашивать узлы дерева в различные цвета.
С деталями реализации функции getSVG можно разобраться по исходникам, которые достаточно хорошо задокументированы.
БлогNot. QT: строим дерево строк на основе QTreeWidget
QT: строим дерево строк на основе QTreeWidget
Примеров для новичков на работу с деревьями почти нет, а хочется, для начала, что-нибудь элементарное, скажем, чтобы мы могли добавлять в произвольное дерево и удалять из него строковые элементы. Ввод строк пользователем или их чтение из файла, заботу об "украшении" приложения и тому подобные типовые вещи опустим, а сосредоточимся лишь на главном.
- в режиме дизайна добавим на форму 2 кнопки, выделим обе при зажатой клавише Ctrl, нажмём комбинацию Ctrl+H, получили горизонтальное "обрамление" QHBoxLayout ;
- выше кнопок добавим на форму компоненту QTreeWidget , выделим её и красную рамку вокруг кнопок при зажатой клавише Ctrl, нажмём комбинацию Ctrl+L, получили вертикальный QVBoxLayout ;
- щёлкнули по форме вне всех компонент, нажали Ctrl+H - растянули компоненты на всю форму.
На рисунке видно, что должно выйти, а также подписи на кнопках.
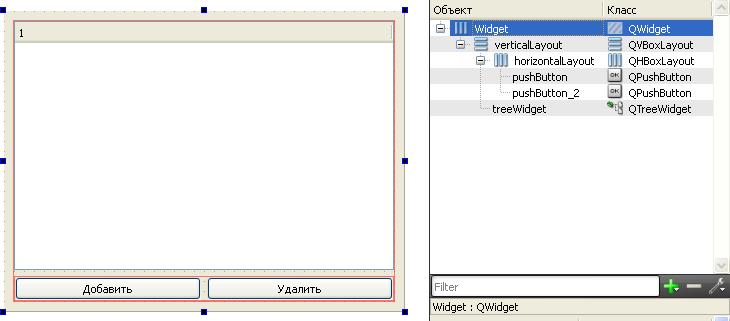
форма приложения QTree
Выбирать элементы дерева мы будем кликом по ним, так что нажмём правую кнопку мыши на пустом treeWidget и создадим единственный слот (команды Перейти к слоту - itemClicked(QTreeWidgetItem *, int) ).
А для кнопок аналогично выберем самый простой слот clicked() и создадим ещё 2 пустые функции.
В приватной секции файла widget.h допишем имена своих методов и свойств, которые мы добавляем в класс, вот что получится:
Не забудем также подключить библиотеку QtWidgets:
Теперь напишем код файла widget.cpp . В конструктор добавим инициализацию наших данных:
Метод подсчёта количества узлов в QTreeWidget нам придётся сделать довольно громоздким, так как готового свойства нет и не может быть (нужно с видом использовать модель, и тогда всё будет, но для начинающих сразу начать это делать сложновато):
Удаление элемента учтёт случаи, когда элемент имеет родителя и когда является корневым:
Вставка будет предполагать, что родитель есть, иначе придётся писать 2 разных метода вставки с различными параметрами:
По кнопке "Добавить" будет выполняться следующее:
Как видно, здесь мы учли, что можно добавлять элементы в корень дерева (так в нашей программе будет всегда, если перед добавлением не щёлкнуть по элементу, который станет родителем нового элемента).
Кнопка "Удалить", по сути, только вызовет написанный выше метод:
Если никакой элемент не выделен, то удалять она тоже ничего не будет.
Служебная функция showAll позаботится об отображении вычисленного количества узлов в заголовке окна виджета.
Ну и наш единственный слот "дерева" просто будет запоминать в дополнительных свойствах класса, по какому именно элементу мы щёлкнули:
Это всё, проект можно запускать и выйдет вот что:

окно виджета QTree, на рисунке выделен элемент
Почему наше решение вышло довольно неуклюжим? А потому что правильно было бы использовать MVC. Но об этом в другой раз, возможно, на таком же простом "списочном" или "древовидном" примере :)
Qt читает и записывает JSON и использует QTreeView для отображения и редактирования данных JSON.
JSON (объектная нотация JavaScript) - это облегченный формат структурированных данных, более лаконичный, чем синтаксис XML. Он имеет 6 основных типов данных: bool (истинное или ложное строковое представление), double (соответствует числу в JS), строка, массив (список значений), объект (набор пар ключ-значение) и null.
Хотя cJSON и JsonCpp также широко используются в синтаксических анализаторах C / C ++ JSON, классы синтаксического анализа, предоставляемые Qt, обычно используются в структуре Qt. Эта статья в основном знакомит с использованием QJson и использованием QTreeView для отображения и редактирования документов JSON (ссылка на код в конце).
оглавление
«Случайный» - Сюй Чжимо
Я облако в небе,
иногда проецируется на ваше сердце волны──
Не удивляйтесь,
Не надо радоваться──
исчез в одно мгновение.
Мы с тобой встречаемся в ночном море,
У вас есть свое, у меня свое направление;
как вы помните,
лучше забыть
Свет, который сияет на этом рандеву!
Qt предоставляет несколько классов для представления документов, узлов и итераторов JSON, которые неявно разделяются.
QJsonDocument:Используется для чтения и записи документов JSON. Он упаковывает полный документ JSON и может читать и записывать этот документ из текстового представления на основе кодировки UTF-8 и собственного двоичного формата Qt. Вы можете использовать QJsonDocument :: fromJson () для преобразования документа JSON из его текстового представления в QJsonDocument.toJson (), чтобы преобразовать его обратно в текст.
QJsonParseError:Используется для обозначения ошибки во время синтаксического анализа JSON.
QJsonObject:Представляет список пар ключ-значение, где ключ является уникальной строкой, а значение представлено QJsonValue. QJson также предоставляет итератор и const_iterator для итерации по QJsonObject. Следует отметить, что в общей структуре JSON список пар «ключ-значение» объекта неупорядочен, а массив упорядочен.Реализация QJSON не обеспечивает упорядоченную настройку объекта.
QJsonArray:Представляет список значений, значение представлено QJsonValue.
QJsonValue:Значение хранимых данных имеет шесть основных типов, и перечисление типов можно получить с помощью метода type (): Bool, Double, String, Array, Object, Null, а также Undefined для указания неопределенного значения.
При использовании этих классов сначала добавьте соответствующие файлы заголовков.
Операции генерации и синтаксического анализа также очень просты.
Интерфейс toJson () QJsonDocument имеет два параметра форматирования. QJsonDocument :: Compact более компактен без отступов разрыва строки и т. Д .:

QJsonDocument :: Indented - это более простой для просмотра формат с разрывами строк:

QTreeView довольно часто используется для отображения данных JSON. Я написал простую демонстрацию для отображения и редактирования данных JSON (часть добавления и удаления связана с делегатом, поэтому мне лень писать, но общая структура есть).

На самом деле идея очень проста, синтаксический анализ и генерация дерева похожи на генерацию двоичного дерева:
Экспорт отредактированного дерева похож на обход двоичного дерева:
В отношении работы TreeView я в основном ссылаюсь на официальный пример:

Каждый узел состоит из класса TreeItem, который эквивалентен узлу связанного списка, и каждый узел имеет родительский узел и несколько дочерних узлов. Что необходимо спроектировать, так это то, что для каждого узла вам нужно пометить его тип, будь то массив, объект или значение, чтобы его можно было легко преобразовать с помощью документов JSON.
Область, которую необходимо улучшить: помимо улучшения функции добавления и удаления узлов, вам также необходимо использовать делегат для делегирования ComboBox, чтобы изменить тип узла: массив, объект или значение.
В процессе написания программы EColor появилась задача, в которой было необходимо каким-то образом уведомлять пользователя о том, что вышла новая версия программы. Решением этой задачи стало наличие JSON файла на сайте. С помощью QNetworkAccessManager получаем JSON файл и производим его разбор, благодаря классам библиотеки Qt : QJsonDocument, QJsonObject, QJsonArray. В случае с программой EColor на сайте содержится JSON файл с названием программы, полной версией в строковом варианте и тремя объектами с Мажорной частью версии, Минорной и Патч-версией. При разборе файла производится сравнение текущей версии программы с той, которая находится на сайте. В случае, если на сайте выложена более свежая версия, то программа сообщает об этом пользователю.
В корневом объекте файла располагается три объекта, второй из которых является массивом. Первый объект - это строковое свойство "departament" , которое содержит название отдела. Второй объект - это массив с именами и фамилиями сотрудников. А третий объект - это число сотрудников типа Integer .
Структура проекта для разбора JSON
- JSONParser.pro - профайл проекта;
- main.cpp - основной файл исходных кодов проекта;
- widget.h - заголовочный файл окна приложения, в котором содержится поле QTextEdit, в которое будет помещен результат парсинга файла;
- widget.cpp - файл исходных кодов с QNetworkAccessManager.
- widget.ui - файл интерфейса программы.
JSONParser.pro
Не забываем подключить в профайле проекта модуль network , чтобы была возможность работать с классом QNetworkAccessManager.
widget.h
Подключаем класс QNetworkAccessManager , также в заголовочном файле объявлен СЛОТ onResult(QNetworkReply *reply) , в котором будет разбираться JSON файл при получении ответа от сайта с содержимым файла.
widget.cpp
Процесс заключается в том, чтобы создать объект QJsonDocument и записать в него содержимое ответа QNetworkReply. После чего забираем из документа корневой объект root , который будет содержать все три свойства. После этого забираем по названиям свойств их значения. Из второго свойства "employes" забираем массив с именами и фамилиями сотрудников отдела. Все данные помещаем в поле ui->textEdit.
В результате работы данного программного кода получится следующий результат, который показан на ниже следующем изображении. Также работу приложения Вы можете увидеть на в видеоуроке.
Видеоурок
А дело было так: мне для нужен простой способ сохранять некую информацию в своей проге, эта информация имеет подкатегории тк кк записывается несколько раз в день. Тк вот было бы удобно если бы дата записывалась в категорию, а вся инфа в подкатегории этой даты.
Ну например так (инфа абсолютно рандомна и не имеет смысла):
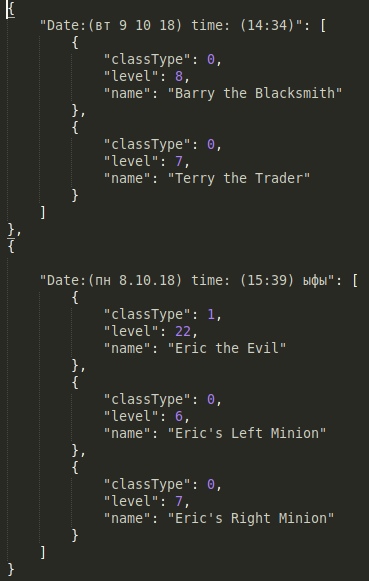
Итак при первом взгляде на это безобразие становиться абсолютно не понятно что тут и для чего.

Для работы с JSON в Qt сделано целых 7 классов, когда мне всего лишь нужно сделать удобно читаемый список с подкатегориями.
Для этой цели неплохо бы подошел ini который использовать на порядок проще тк кк ini как раз содержит [Категорию] и значение в ней. Но по необъяснимым причинам ini в Qt не умеет в кирилицу, и чтобы я не делал я получаю кракозябры(в гугле выясняется что это действительно существующая проблема и тролтеч забили на все кроме латиницы)
Итак начнем с QJsonValue.
QJsonValue это просто одно значение json которое может быть следующих форматов

Далее уже что-то полезное QJsonObject.
QJsonObject это одна или несколько пар ключ::значение в одном из вышеупомянутых форматов.
Вот пример использования
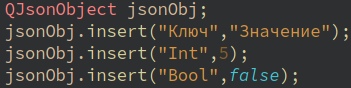
jsonObj будет выглядеть так

Также добавлять значения можно так
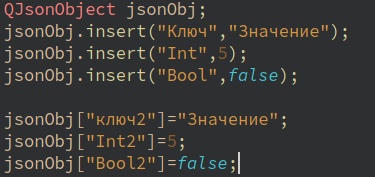
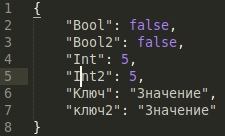
Идем по нарастающей теперь QJsonArray.
QJsonArray это как нетрудно догадаться массив из QJsonObject
Добавим в него по отдельности 2 предыдущих примера.

И тадаам теперь они оба тут
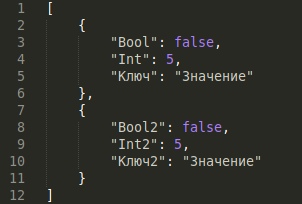
Все это до сих пор не то, мне то нужны подкатегории, а не безымянные блоки данных. И тут в игру вступает немного магии, также как QJsonArray может содержать в себе несколько QJsonObject, так и QJsonObject может содержать в себе несколько QJsonObject. То есть с логической точки зрения мы будем по ключю хранить не значение, а другой объект со значениями.
Попробуем дать обоим блокам названия:

Итак получается мы создаем глобальный объект GBjsonObj и помещаем в него 2 других объекта по ключам name и age и получаем то что и требовалось

Для скорости работы функций парсинга json автоматически сортируется по алфавиту.
Ну и пожалуй самое основное — сохранение и загрузка
Для этого нам потребуется уже четвертый Qt класс QJsonDocument.
QJsonDocument как бы хранит в себе всю структуру нашего JSON, редактировать его напрямую нельзя, мы только можем поместить в него массив или объект:
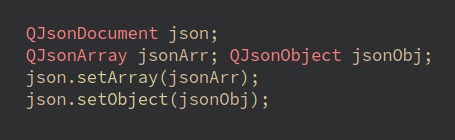
Или обратно достать из документа объект:

Напишем 2 простейшие функции для работы с файлами load и save.
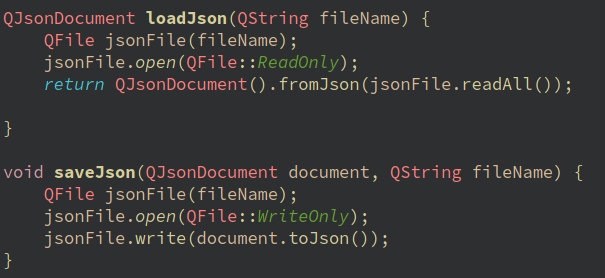
load() будет принимать название или путь к файлу, и возвращать json документ, Ну а save разумеется принимать документ и название/путь.
Ну и теперь как это выглядит на практике:

Ну пожалуй все. Может быть когда-нибудь напишу статью как все это дело парсить, но помойму это очевидно прямо из последнего примера.
У всех этих четырех объектов есть также куча классных методов и свойст типа
is(Любой типа данных) для проверки типа данных
isEmpty для проверки на пустоту
toVariantHash() toVariantMap() size() length() find(const QString &key)
contains(QLatin1String key) swap(QJsonObject &other) toBinaryData() toJson()
Читайте также: