
Хинты в oracle это
В этом могут помочь методы, появившиеся в Oracle, начиная с Oracle 9i и развитые в Oracle 11g, позволяющие подставлять хинты (подсказки оптимизатору) в запрос, не меняя текст работающего запроса и не компилируя заново хранимую процедуру (функция, процедур, пакет), в которой он находится.
Практика показала, что эти методы особенно эффективны в период перехода от одной версии Oracle к другой. Так, например, при переходе с версии с Oracle 11.2.0.3 на 11.2.0.4 или на Oracle 12c планы выполнения запросов, которые были оптимальны в предыдущей версии, порой становятся далеко не оптимальными.
В этом случае вернуться к оптимальному плану выполнения позволяют разные приемы, например модификация структуры запроса или добавление хинта (например, хинта index) в запрос с последующей перекомпиляцией хранимой процедуры, в которой он находится. Может быть также применен хинт в запросе, возвращающий работу оптимизатора к предыдущим версиям Oracle, в которых планы выполнения были оптимальными. Как показала практика, в Oracle 11g вэтом могут помочь хинты:
При наличии проблем с планами выполнения в запросах с bind-переменными (связанными переменными) оптимизировать план выполнения запроса может помочь (помимо хинта, такого как index) еще хинт:
/*+ opt_param ('_optim_peek_user_binds' 'false') */
Данный хинт изменяет значение недокументированного параметра инициализации _optim_peek_user_binds, влияющего на планы выполнения с bind-переменными, с true (устанавливаемый по умолчанию) на значение false.
В то же время на операцию добавления хинтов в запрос с последующей перекомпиляцией хранимой процедуры порой просто нет времени, поскольку задачу оптимизации плана выполнения запроса нужно решать оперативно. Может быть также вариант, когда запрос находится в хранимой процедуре (например, в пакете), который после подстановки хинта в запрос следует перекомпилировать, в то время как пакет постоянно находится в работе или в настоящий момент нет автора пакета и т.д.
В этом случае можно воспользоваться методами оперативной подстановки хинта в запрос без перекомпиляции хранимой процедуры. Применение данных методов, кроме того, позволяет осуществлять быструю отмену действия применения хинтов и оперативно пробовать другие варианты хинтов для улучшения плана.
Важным достоинством применения методов подстановки хинта является то, что перед тем, как вставить хинт в запрос (с последующей перекомпиляцией хранимой процедуры, в которой находится этот запрос), можно убедиться, что этот хинт действительно улучшает план выполнения запроса.
В то же время подстановка хинта в запросе может быть обоснована, как правило, в случае, когда прежде всего важна стабильность планов выполнения. Подставка хинта может привести к искусственному ограничению свободы действий оптимизатора, потенциально ведущему к невозможности использования других, быть может, более оптимальных планов (например, в зависимости от значений bind-переменных).
Начиная с Oracle 9i появился метод замены или добавления хинтов в запрос, к которому нет доступа на редактирование, известный как метод использования хранимых шаблонов (Stored Outlines). Данный метод позволяет не только подставлять, но и заменять существующий хинт на другой, причем как в основном запросе, так и в подзапросах у запроса.
Вместе с тем данный метод не нашел у нас широкого применения, в силу того, что столкнулись с проблемой использования этого метода в запросах, в которых имеются bind-переменные (т.е. в запросах типа SELECT * FROM agreement WHERE isn=:b ), в то время как большинство запросов у нас базируется на bind-переменных.
Существуют другие методы подстановки хинта в запрос, например SQL profiles, вместе с тем у нас более востребованными оказались методы, появившиеся в Oracle 11g, такие как SQL plan baseline и SQL patch. Это обусловлено удобством работы с ними и возможностью работы с запросами, которые содержат bind-переменные.
Данные рекомендации взяты мной из руководства Oracle по настройке базы данных, со временем они практически не меняются, посмотреть их можно здесь, это глава 11.5. Ссылка может не работать, все зависит от того, как долго Oracle решит хранить этот фрагмент документации в интернете.
Не используйте SQL-функции в предикатах. Любое выражение в котором используется колонка (expression), например функция, использующая колонку, как аргумент, приведет к тому, что индекс для данной колонки (если он есть) использоваться не будет, даже если это уникальный индекс. Хотя, если для колонки имеется составной индекс (function-based) на основе применяемой в предикате функции, то он может быть использован.
где numexpr выражение числового типа, то Oracle преобразует ваше условие в:
и индекс использован не будет.
Где по числовой колонке numcol построен индекс.
План запроса.
Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами, т.е. написать несколько разных запросов, которые дадут один и тот же результат. Это, однако не означает, что база данных эти запросы будет выполнять по-разному. Также неверно мнение о том, что структура запроса может повлиять на то, как Oracle будет его выполнять, это касается порядка временных таблиц, JOINS и условий отбора в WHERE. Решение о том, как построить запрос принимает оптимизатор Oracle. Алгоритм получения сервером данных для конкретного запроса называют планом запроса.
Практически все продукты для работы с базой данных Oracle позволяют просмотреть план конкретного запроса. Так как слушатели этих лекций используют PL/SQL Developer, то для получения плана запроса в нем необходимо сделать следующее:
Существует стандартный механизм получения плана запроса. Для этого используется конструкция (команда) EXPLAIN PLAN FOR:
План запроса будет выведен в виде таблицы с одним полем, выглядит он так:
Важно ! Во всех планах запросов, первостепенное значение имеют колонки операций и названия объектов над которыми эти операции производятся. Все остальные колонки имеют оценочный характер, часть из них формируется на основе статистики, которая может устареть или вообще отсутствовать. При анализе плана запроса вы должны представлять объемы записей в таблицах, а также примерный алгоритм соединения таблиц.
В приведенном выше примере показан план запроса, полученный с помощью EXPLAIN PLAN FOR, более наглядную картину дает окно плана запроса в PL/SQL Developer:
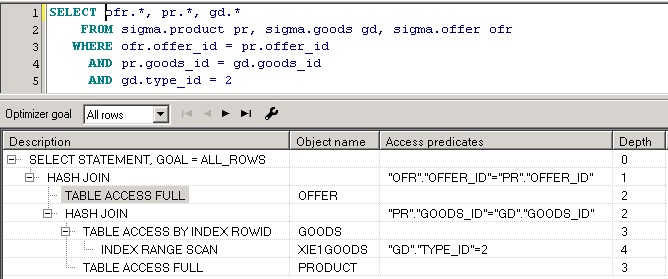
План всегда имеет иерархическую структуру. Операция соединения результирующих наборов оперирует парами дочерних операций. Операция получения данных может использовать вспомогательную операцию, такую, например, как сканирование индекса.
Данные результирующих наборов получаются в порядке следования этих наборов в плане запроса. Операция получения данных результирующего набора может состоять из нескольких шагов, которые характеризуются глубиной операции (колонка Depth).
При анализе плана в первую очередь необходимо обращать внимание на способы, с помощью которых получены данные результирующих наборов.
Некоторые термины в плане запроса.
План запроса имеет форму таблицы, один из столбцов которой описывает тип производимых сервером операций. Вот некоторые из них, которые встречаются наиболее часто:
Анализ плана запроса.
При анализе плана запроса вам необходимо примерно представлять объемы записей в таблицах и наличие у них индексов, которые могут пригодиться при фильтрации записей. Для доступа к данным Oracle использует несколько стратегий, какие из них выбраны для каждой из таблиц можно понять из плана запроса. При просмотре плана, вам необходимо решить, правильная ли выбрана стратегия в том или ином случае. Ниже приведены краткие описания способов доступа и механизмов отбора записей при соединениях результирующих наборов.
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным таблицы быстрее осуществлять через индекс, но это не так. Иногда дешевле прочитать всю таблицу целиком, чем прочитать, например, 80% записей таблицы через индекс, так как чтение индекса тоже требует ресурсов. Очень не желательна ситуация, когда эта операция стоит первой в объединении наборов записей и таблица, которая читается полностью, большая. Еще хуже ситуация с большой таблицей на второй позиции в объединении, это означает, что она также будет прочитана полностью, как минимум, один раз, а если объединение производится через NESTED LOOPS, то таблица будет читаться несколько раз, поэтому запрос будет работать очень долго.
Nested Loops.
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане запроса) объединяется с помощью условия, позволяющего эффективно выбрать записи из второго набора. Важным условием успешного использования такого соединения является наличие связи между основным и второстепенным набором записей. Если такой связи нет, то для каждой записи в первом наборе, из второго набора будут извлекаться одни и те же записи, что может привести к значительному увеличению времени запроса. Если вы видите, что в плане запроса применен NESTED LOOPS, а соединяемые наборы не удовлетворяют этому условию, то налицо ошибка.
Hash Joins.
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения в памяти хэш-таблицы по ключу соединения. Затем он сканирует большую таблицу, используя хэш-таблицу для нахождения записей, которые удовлетворяют условию объединения.
Оптимизатор использует HASH JOIN, если наборы данных соединяются с помощью операторов и ключевых слов эквивалентности (=, AND) и если присутствует одно из условий:
■ Необходимо соединить наборы данных большого объема.
■ Большая часть небольшого набора данных должна быть использована в соединении.
Sort Merge Join.
Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую стратегию, если наборы данных уже отсортированы ранее, и если дальнейшая сортировка результата соединения не требуется. Обычно это имеет место для наборов, которые соединяются с помощью операторов , >=. Для этого типа соединения нет понятия главного и вспомогательного набора данных, сначала оба набора сортируются по общему ключу, а затем сливаются в одно целое. Если какой-то из наборов уже отсортирован, то повторная сортировка для него не производится.
Cartesian Joins.
Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с какой-либо другой таблицей в запросе. В этом случае произойдет объединение каждой записи из одного набора данных с каждой записью в другом. Такое соединение может быть выбрано между двумя небольшими таблицами, а в дальнейшем этот набор данных будет соединен с другой большой таблицей. Наличие такого соединения может обозначать присутствие серьезных проблем в запросе, особенно, если соединяемые таблицы по MERGE JOIN CARTESIAN. В этом случае, возможно, упущены дополнительные условия соединения наборов данных.
Хинты.
Использование хинтов.
Хинт ставится после ключевого слова, которое определяет некую цельную конструкцию запроса, в данном разделе речь пойдет о хинтах в запросах к данным, т.е. тех, которые оформляются оператором SELECT и ключевых словах, используемых в сочетании с ним. Хинт указывается в закрытом комментарии после оператора:
В данном примере используется хинт RULE.
FIRST_ROWS.
Данный хинт дает указание оптимизатору выбрать такой план запроса при котором первые записи результатов будут получены максиально быстрым способом. Хорош при отладке запроса, чтобы убедиться, что выдается то, что необходимо. Если предполагается, что запрос вернет много записей, то при использовании такого хинта он может работать дольше.
ORDERED / LEADING.
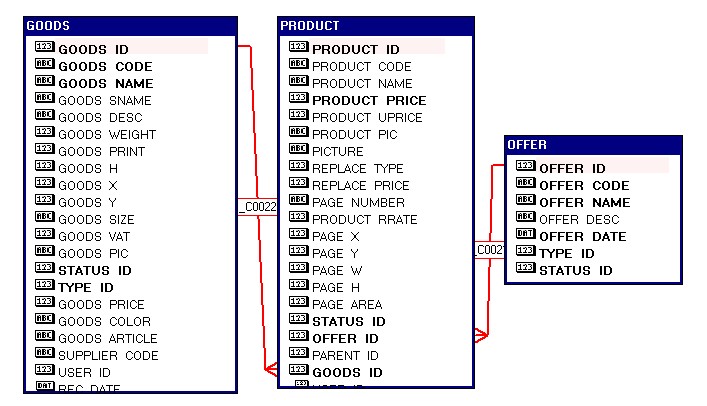
При использовании этого хинта оптимизатор соединяет наборы данных в том порядке, в каком они следуют после оператора FROM. Вот пример разных последовательностей:
Порядок наборов данных необходимо выбирать аккуратно, чтобы соединяемые объекты имели какое-то условие связи в WHERE или после ключевого слова ON. Например в приведенном выше примере 4 версия списка во FROM приведет к перемножению таблиц GOODS и OFFER, так как они не связаны друг с другом условиями.
Данный хинт часто бывает полезен, если статистика по таблицам не собрана, план запроса не верный, и вам точно известно, как должны соединяться таблицы. При использовании данного хинта старайтесь выстроить порядок соединения так, чтобы тяжесть обработки данных следовала в сторону увеличения, т.е. сначала соедините наборы поменьше или с хорошими условиями отбора, чтобы результат их соединения был наименьшим по количеству записей, затем подключайте наборы данных большего размера.
Более удобен в использовании хинт LEADING. Он позволяет соединить наборы данных в порядке перечисления их (или их алиасов) в списке аргументов хинта:
Порядок связи в этом примере будет такой: product -> offer -> goods. Использование этого хинта предпочтительнее при отладке, если список наборов данных большой.
MATERIALIZE.
Дает указание оптимизатору построить временную таблицу (материализовать результаты) для запроса, к которому этот хинт применяется, работает только в конструкции WITH. Очень полезен при обработке больших объемов данных, так как позволяет разбить запрос на части, в этом случае улучшается читабельность запроса, а также может быть получен правильный план. Пример использования:
План запроса выглядит так:
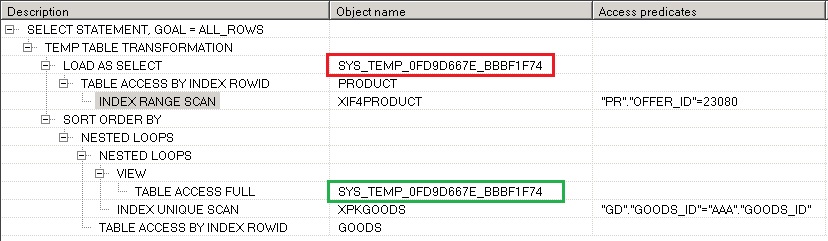
Красным цветом помечена таблица при ее создании, зеленым ее использование в соединении.
INDEX.
Дает указание оптимизатору использовать индекс при чтении данных из таблицы. Полезен тем, что может предотвратить чтение всего содержимого таблицы, если вы считаете, что этого делать не нужно. Пример использования:
Этот хинт сработает в том случае, если у таблицы есть указываемый индекс, и его можно использовать на основе одного или нескольких условий при получении данных таблицы. В приведенном примере в составе индекса есть поле OFFER_ID на второй позиции и он может быть использован, план запроса выглядит в этом случае так:

Комбинации хинтов.
Использование комбинации хинтов допустимо. Нужный эффект можно получить, если хинты в одном запросе не протеворечат друг другу. При записи хинты разделяются пробелами:
В данном примере используется хинт для установки порядка соединения наборов данных и способа доступа к таблице, противоречия в их использовании нет.

В этой статье изложен многолетний опыт оптимизации SQL-запросов в процессе работы с базами данных Oracle 9i, 10g и 11g. В качестве рабочего инструмента для получения планов запросов мною используется всем известные программные продукты Toad и PLSQL Developer.
Нередко возникают ситуации, когда запрос работает долго, потребляя значительные ресурсы памяти и дисков. Назовем такие запросы неэффективными или ресурсоемкими.
Причины ресурсоемкости запроса могут быть следующие:
- плохая статистика по таблицам и индексам запроса;
- проблемы с индексами в запросе;
- проблемы с хинтами в запросе;
- неэффективно построенный запрос;
- неправильно настроены параметры инициализации базы данных, отвечающие за производительность запросов.
Программные средства, позволяющие получить планы выполнения запросов, можно разделить на 2 группы:
- средства, позволяющие получить предполагаемый план выполнения запроса;
- средства, позволяющие получить реальный план выполнения запроса;
К средствам, позволяющим получить предполагаемый план выполнения запроса, относятся Toad, SQL Navigator, PL/SQL Developer и др. Это важный момент, поскольку надо учитывать, что реальный план выполнения может отличаться от того, что показывают эти программные средства. Они выдают ряд показателей ресурсоемкости запроса, среди которых основными являются:
Чем больше значение этих показателей, тем менее эффективен запрос.
Ниже приводиться пример плана выполнения запроса:
полученного в Toad
Из плана видно, что наибольшие значения Cost и Cardinality содержатся во 2-й строке, в которой и надо искать основные проблемы производительности запроса.
Вместе с тем, многолетний опыт оптимизации показывает, что качественный анализ эффективности запроса требует, помимо Cost и Cardinality, рассмотрения других дополнительных показателей:
- CPU Cost — процессорная стоимость выполнения;
- IO Cost — стоимость ввода-вывода;
- Temp Space – показатель использования дискового пространства.
Если дисковое пространство используется (при нехватке оперативной памяти для выполнения запроса, как правило, для проведения сортировок, группировок и т.д.), то с большой вероятностью можно говорить о неэффективности запроса. Указанные дополнительные параметры с соответствующей настройкой можно увидеть в PL/SQL Developer и Toad при их соответствующей настройке. Для PL/SQL Developer в окне с планом выполнения надо выбрать изображение гаечного ключа, войти в окно Preferensec добавить дополнительные параметры в Select Column, после чего и нажать OK. В Toad в плане выполнения по правой кнопке мыши выбирается директива Display Mode, а далее Graphic, после чего появляется дерево, в котором по каждому листу нажатием мышки можно увидеть дополнительные параметры: CPU Cost, IO Cost, Cardinality. Структура плана запроса, указанного выше, в виде дерева приведена ниже.
Предполагаемый план выполнения запроса с Cost и Cardinality можно также получить, выполнив после анализируемого запроса другой запрос, формирующий план выполнения:
Дополнительно в плане выполнения запроса выдается значение SQL_ID запроса, который можно использовать для получения реального плана выполнения запроса с набором как основных (Cost, Cardinality), так и дополнительных показателей через запрос:
Реальный план выполнения запроса и указанный выше перечень характеристик для анализа ресурсоемкого запроса дают динамические представления Oracle: V$SQL_PLAN и V$SQL_PLAN_MONITOR (последнее представление появилось в Oracle 11g).
План выполнения запроса получается из представления Oracle по запросу:
где SQL_ID – это уникальный идентификатор запроса, который может быть получен из разных источников, например, из представления V$SQL:
Трассировочный файл — это еще одно средство получение реального плана выполнения. Это довольно сильное средство диагностики и оптимизации запроса. Для получения трассировочного файла ( в Toad или PL/SQL Developer) запускается PL/SQL блок:
где первая, третья и последняя строки являются стандартными, а во второй строке пишется идентификатор (любые символы), который включается в имя трассировочного файла. Так, если в качестве идентификатора напишем M_2013, то имя трассировочного файла будет включать этот идентификатор и будет иметь вид: oraxxx_xxxxxx_ M_2013.trc. Результат пишется в соответствующую директорию сервера, которая находиться из запроса
Трассировочный файл для удобства чтения расшифровывается утилитой Tkprof (при определенном навыке анализировать можно без расшифровки, в этом случае имеем более детальную информацию).
Ещё одним из средств получения реального плана выполнения запроса с получением рекомендаций по его оптимизации является средство Oracle SQLTUNE.
Для анализа запроса запускается PL/SQL блок (например, в Toad или PL/SQL Developer) , в котором имеются стандартные строки и анализируемый запрос. Для рассматриваемого выше запроса блок PL/SQL примет вид:
Все строки (кроме текста запроса) являются стандартными.
Далее запуск запрос, который выдает на экран текст рекомендаций:
Для работы SQLTUNE необходимо как минимум из под SYSTEM выдать права на работу с SQLTUNE схеме, в которой запускается PL/SQL блок. Например, для выдачи прав на схему HIST выдается GRANT ADVISOR TO HIST;
В результате работы SQLTUNE выдает рекомендации (если Oracle посчитает, что есть что рекомендовать). Рекомендациями могут быть: собрать статистику, построить индекс, запустить команду создания нового эффективного плана и т.д.
Анализ плана выполнения запроса.
Анализ плана выполнения запроса имеет определенную последовательность действий. Рассмотрим на примере плана выполнения запроса из представление V$SQL_PLAN для ранее приведенного запроса
- При анализе план просматриваетcя снизу вверх. В процессе просмотра в первую очередь обращается внимание на строки с большими Cost, CPU Cost.
- Как видно из плана, резкий скачек этих значений имеется в 4-ой строке. Причиной такого скачка является 5-я строка с INDEX FULL SCAN, указывающая на наличие полного сканирование индекса X_DICTI_NAME таблицы DICTI. С этих строк и надо начинать поиск причины ресурсоемкости запроса. После нахождения строки с большим Cost и CPU Cost продолжается просмотр плана снизу вверх до следующего большого CPU Cost и т.д. При этом, если CPU Cost в строке близок к CPU Cost первой строки (максимальное значение), то найденная строка является определяющей в ресурсоемкости запроса и с ней в первую очередь надо искать причину ресурсоемкости запроса.
- Помимо поиска больших Cost и CPU Cost в строках плана следует просматривать первый столбец Operation плана на предмет наличия в нем HASH JOIN. Соединение по HASH JOIN приводит к соединению таблиц в памяти и, казалось бы, более эффективным, чем вложенные соединения NESTED LOOPS. Вместе с тем, HASH JOIN эффективно при наличии таблиц, хотя бы одна из которых помещаются в память БД или при наличии соединения таблиц с низкоселективными индексами. Недостатком этого соединения является то, что при нехватке памяти для таблицы (таблиц) будут задействованы диски, которые существенно затормозят работу запроса. В связи с чем, при наличии высокоселективных индексов, целесообразно посмотреть, а не улучшит ли план выполнения хинт USE_NL, приводящий к соединению по вложенным циклам NESTED LOOPS. Если план будет лучше, то оставить этот хинт. При этом в хинте USE_NL в скобках обязательно должны перечисляться все алиасы таблиц, входящих во фразу FROM, в противном случае может возникнуть дефектный план соединения. Этот хинт может быть усилен хинтами ORDERED и INDEX. Следует обратить так же внимание на MERGE JOIN. При большом CPU Cost в строке с MERGE JOIN стоит проверить действие хинта USE_NL для улучшения эффективности запроса.
- Особое внимание в плане следует так же уделить строкам в плане с операциями полного сканирования таблиц и индексов в столбец Operation: FULL — для таблиц и FULL SCAN, FAST FULL SCAN , SKIP SCAN — для индексов. Причинами полного сканирования могут быть проблемы с индексами: отсутствие индексов, неэффективность индексов, неправильное их применение. При небольшом количестве строк в таблице полное сканировании таблицы FULL может быть нормальным явлением и эффективнее использования индексов.
- Наличие в столбце Operation операции MERGE JOIN CARTESIAN говорит, что между какими-то таблицами нет полной связки. Эта операция возникает при наличии во фразе From трех и более таблиц, когда отсутствуют связи между какой-то из пар таблиц.
Решением проблемы может быть добавление недостающей связки, иногда помогает использование хинта Ordered.
Оптимизация запроса
После анализа плана выполнения запроса осуществляется его оптимизация.
Оптимизация запроса предполагает удаление причин неэффективности запроса, среди которых наиболее весомыми являются:
- плохая статистика таблиц и индексов, участвующих в запросе (наиболее важный фактор, на который в первую очередь надо обратить внимание);
- проблемы с индексами: отсутствие нужных индексов, неэффективно построенные индексы, неэффективно используемые индексы, большое значение фактора кластеризации;
- проблемы с хинтами: отсутствие хинтов или они неэффективны;
- неэффективная структура запроса (запрос построен не корректно).
Неэффективная статистика.
Прежде чем оптимизировать запрос, целесообразно посмотреть статистику таблиц и индексов, участвующих в запросе. Порой достаточно обновить статистику, чтобы запрос стал работать эффективно. Возможные варианты не эффективной статистики, приводящие к ресурсоемкости запроса:
- Устаревшая статистика. Время последнего сбора статистики определяется значением поля Last_Analyzed для таблиц и индексов, которое находиться из Oracle таблиц ALL_TABLES (DBA_TABLES) и ALL_INDEXES (DBA_INDEXES) соответственно. Oracle ежедневно в определенные часы в рабочие дни и в определенные часы в выходные сам собирает статистику по таблицам. Но для этого DML операции с таблицей должны привести к изменению не менее 10% строк таблицы. Однако, мне приходилось сталкиваться с ситуацией, когда в течение дня таблица неоднократно и существенно меняет число строк или таблица столь большая, что 10% изменений наступает через длительное время. В этом случае приходилось обновлять статистику, используя процедуры сбора статистики внутри пакетов, а ряде случае использовать JOB, запускающийся в определенные часы для анализа и обновления статистики.
Статистика по таблице и индексу (на примере таблицы AGREEMENT и индекса X_AGREEMENT в схеме HIST) обновляется соответственно процедурами: - для таблицы:
- для индекса:
где число 10 в процедуре указывает на процент сбора статистики. С учетом времени сбора статистики и числа строк в таблице (индексе) были выработаны рекомендации для таблиц (индексов) по проценту сбора статистики: если число строк более 100 млн. процент сбора устанавливать 2 -5, при числе строк с 10 млн. до 100 млн. процент сбора устанавливать 5-10, менее 10 млн. процент сбора устанавливать 20 -100. При этом, чем выше процент сбора, тем лучше, однако, при этом растет и может быть существенным время сбора статистики.
Для таблиц процент сбора статистики (на примере таблицы AGREEMENT в схеме HIST) вычисляется запросом:
Процент сбора статистики по индексу находиться по запросу
Необходимо пересобрать статистику по таблице или индексу с плохой статистикой.
Замечание. При хорошем значении статистики по таблице может быть неблагополучная статистика по какому-то индексу таблицы, в силу чего целесообразно отслеживать статистику не только таблицы, но и индексов таблицы.
Проблемы с индексами
Проблемы с индексами в плане выполнения проявляются при наличии в столбце Options значений FULL, FULL SCAN, FAST FULL SCAN и SKIP SCAN в силу следующих причин:
- Отсутствие нужного индекса. Требуемое действие — создать новый индекс;
- Индекс имеется, но он неэффективно построен. Причинами неэффективности индекса могут быть:
— Малая селективность столбца, на котором построен индекс, т.е. в столбце много одинаковых значений, мало уникальных значений. Решение в данной ситуации — убрать индекс из таблицы или столбец, на основе которого построен индекс, ввести в составной индекс.
— Столбец селективный, но он входит в составной индекс, в котором этом столбец не является первым (ведущим) в индексе. Решение – сделать этот столбец ведущим или создать новый индекс, где столбец будет ведущим; - Построен эффективный индекс, но он работает не эффективно в силу следующих причин:
— Индекс заблокирован от использования. Блокируют использование индекса следующие операции над столбцом, по которому используется индекс: SUBSTR, NVL, DECODE, TO_CHAR,TRUNC,TRIM, ||конкатенация, + цифра к цифровому полю и т.д.
Решение – модифицировать запрос, освободиться от блокирующих операций или создать индекс по функции, блокирующей индекс.
— Не собрана или неактуальная статистика по индексу. Решение – собрать статистику по индексу запуском процедуры, указанной выше.
— Имеется хинт, блокирующий работу индекса, например NO_INDEX.
— Неэффективно настроены параметры инициализации базы данных БД (особенно отвечающие за эффективную работу индексов, например, optimizer_index_caching и optimizer_index_cost_adj). По моему опыту использования Oracle 10g и 11g эффективность работы индексов повышалась, если optimizer_index_caching=95 и optimizer_index_cost_adj=1. - Имеются сильные индексы, но они соперничают между собой.
Это происходит тогда, когда в условии where имеется строка, в которой столбец одной таблицы равен столбцу другой таблицы. При этом на обоих столбцах построены сильные или уникальные индексы. Например, в условии Where имеется строка AND A.ISN=B.ISN. При этом оба столбца ISN разных таблиц имеют уникальные индексы. Однако, эффективно может работать индекс только одного столбца (левого или правого в равенстве). Индекс другого столбца, в лучшем случае, даст FAST FULL SCAN. В этой ситуации, чтобы эффективно заработали оба индекса, потребуется вести дополнительное условие для одного из столбцов. - Индекс имеет большой фактор кластеризации CLUSTERING_FACTOR.
По каждому индексу Oracle вычисляет фактор кластеризации (ФК), определяющий число перемещений от одного блока к другому в таблице при выборе индексом строк из таблицы. Минимальное значение ФК равно числу блоков таблицы, максимальное — числу строк в таблице. CLUSTERING_FACTOR определяется по запросу:
Фактор кластеризации для индекса считает во время сбора статистики. Он используется оптимизатором при расчете стоимости индексного доступа к данным таблицы. Большой ФК (особенно близкий к числу строк в таблице) говорит о неэффективном индексе. Таким образом, ФК является характеристикой индекса, а не таблицы. Первое решение при большом ФК является убрать существующий индекс как не эффективный. Второе решение, если данный индекс наиболее часто применяется в запросах и он нужен, то перестроить структуру таблицы таким образом, чтобы строки в блоках таблицы были упорядочены в том же порядке, в котором расположена информация по данным строкам в индексе, т.е. сделать кластерными блоки таблицы, уменьшив таким образом число перемещений от одного блока к другому при работе индекса.
Проблемы с хинтами в запросе
Проблемы с хинтами могут быть следующие:
- Неэффективный хинт. Он может привести к существенному снижению производительности. Причины возникновения не эффективности хинтов:
— хинт был написан, когда БД работала на 9-ом Oracle, при переходе на Oracle 10g и выше хинт стал тормозом (это могут быть хинты Rule, Leading и др.). Leading –мощный хинт, но при переходе на другую версию Oracle в некоторых случаях приводит в резкому снижению производительности и перед применение этих хинтов необходимо учитывать вероятность изменения со временем статистики системы и ее объектов (таблиц и индексов), используемых в запросе;
— в хинте USE_NL содержится не полный перечень алиасов;
— в составном хинте используется неправильный порядок следования хинтов, в результате чего хинты блокирую эффективную работу друг. Например, хинт Leading полностью игнорируются при использовании двух или более конфликтующих подсказок Leading или при указании в нем более одной таблицы.
— хинт написан давно, после чего была модификация запроса (например, отсутствует или изменился индекс, указанный в хинте). - В запросе отсутствует хинт, который бы повысил эффективность работы запроса. В ряде случаем наличие хинта повышает эффективность запроса и обеспечивает стабилизацию планов выполнения (например, при изменении статистики).
- При создании хинта в запросе есть ряд рекомендаций:
— В хинте INDEX могут быть перечислены несколько индексов. Оптимизатор сам выберет соответствующий индекс. Можно поставить хинт NO_INDEX, если надо заблокировать использование какого-то индекса.
— При наличии Distinct в запросе Distinct ставиться после хинта (т.е. хинт всегда идет после Select).
— Наиболее эффективные и часто используемыми являются хинты: Ordered, Leading, Index , No_Index, Index_FFS, Index_Join, Use_NL, Use_Hash, Use_Merge, First_Rows(n), Parallel, Use_Concat, And_Equal, Hash_Aj и другие. При этом, например, индекс Index_FFS кроме быстрого полного сканирования индекса позволяет ему выполняться параллельно, в силу чего можно получить существенный выигрыш в производительности. Пример такого использования для секционированной таблицы где T-алиас таблицы.
— Изменение параметров инициализации базы данных в пределах запроса позволяет сделать хинт /*+ opt_param('Параметр инициализацци' N) */ , например, /*+ opt_param('optimizer_index_caching' 10) */. Данный хинт используется для проверки производительности работы запроса в случае, когда запрос разрабатывается или тестируется на базе с одним значением параметров инициализации, а работает на базе с другими значениями.
Замечание. В некоторых случаях, когда хинт неэффективный, но заменить его оперативно в запросе не представляется возможным (например, чужая разработка), имеется возможность, не меняя рабочий запрос в программном модуле, заменить хинт (хинты) в запросе, а также в его подзапросах, на эффективный хинт (хинты). Это прием — подмена хинтов (который известен, как использование хранимых шаблонов Stored Outlines). Но такая подмена должна быть временным решением до момента корректировки запроса, поскольку постоянная подмена хинта может привести к некоторому снижению производительности запроса.
Хинты - это инструкции, а не команды и оптимизатор им не всегда следует
(это для него только советы). Избегайте лишних подсказок.
На уровне init.ora можно задать директивы использования:
CHOOSE
RULE
FIRST_ROWS
ALL_ROWS
В OLTP изменение на уровне init.ora с CHOOSE на FIRST_ROWS настраивает оптимизатор
на возвращение первых нескольких строк быстрее. (наилучшее время отклика)
Он делает это разными способами, но основной из них - выполнение соединений в режиме nested loops.
В хранилищах изменение на уровне init.ora с CHOOSE на ALL_ROWS настраивает оптимизатор
на возвращение всех строк быстрее. (лучшая производительность).
Нужно всегда стремиться к директивам использования на уровне всей системы,
а не к директивам на уровне подсказок и советов для отдельных запросов.
При переходе к новой версии СУБД это позволяет избежать хлопот,
поскольку хинты могут работать по другому.
Если вы обнаружите, что при оптимизации системы используете чаще всего одни и те же хинты,
то это возможно симптом более существенной проблемы.
- отсутствие индекса
- нехватка памяти
то решайте эти проблемы на уровне системы.
Хинты должны использоваться лишь изредка.
Например, при отсутствии правильных индексов, оптимизатор может объединять
таблицы в неправильном порядке.
Если вы часто используете хинты:
для объединений, посмотрите на индексы, для объединяемых таблиц.
Многие проблемы можно решить без использования инструкций, например перезаписав запрос так,
чтобы он правильно использовал индексы.
/*+ HINT1 HINT2 HINT3 */
отступы в один пробел имеют важное значение
подсказки всегда форсируют использование стоимостной оптимизации, кроме подсказки RULE.
Если в запросах используются псевдонимы (table alias), в подсказках также должны
использоваться псевдонимы вместо названий таблиц.
select /*+ FULL (my_alias) */ empno
from emp my_alias
where empno > 10;
В подсказках не должно быть указания названия схемы:
select /*+ index (scott.emp emp1) */ .
Некорректные подсказки игнорируются без предупреждений.
Некорректность подсказки может быть неочевидна.
Например указание подсказки FIRST_ROWS (для получения первых строк) для запроса с ORDER BY.
Поскольку данные должны быть отсортированы преде, чем будут возвращены первые строки запроса.
Использование FIRST_ROWS может не дать желаемого результата.
Общие цели оптимизатора:
RULE
ALL_ROWS
FIRST_ROWS
FIRST_ROWS(n)
CHOOSE
Метоы доступа
AND_EQUAL
HASH
INDEX_COMBINE
INDEX_JOIN
CLUSTER
INDEX
INDEX_DESC
NO_INDEX
FULL
INDEX_ASC
INDEX_FFS
ROWID
Преобразование запроса
FACT
NO_FACT
REWRITE
USE_CONCAT
MERGE
NO_MERGE
STAR
NO_EXPAND
NOREWRITE
STAR_TRANSFORMATION
Параллельное исполнение
NOPARALLEL
PARALLEL_INDEX
NOPARALLEL_INDEX
PARALLEL
PQ_DISTRIBUTE
Операции объединения:
DRIVING_SITE
LEADING
NL_AJ
PUSH_SUBQ
USE_NL
HASH_AJ
MERGE_AJ
NL_SJ
USE_HASH
HASH_SJ
MERGE_SJ
ORDERED
USE_MERGE
Другие инструкции
APPEND
NOAPPEND
NOCACHE
UNNEST
CACHE
NO_UNNEST
ORDERED_PREDICATES
CURSOR_SHARING_EXACT
NO_PUSH_PRED
PUSH_PRED
Примеры использования:
Общие цели оптимизатора:
ALTER SYSTEM SET optimizer_mode=RULE SCOPE=MEMORY;
ALTER SYSTEM SET optimizer_mode=ALL_ROWS SCOPE=MEMORY;
ALTER SYSTEM SET optimizer_mode=FIRST_ROWS SCOPE=MEMORY;
ALTER SYSTEM SET optimizer_mode=CHOOSE SCOPE=MEMORY;
SELECT /*+ RULE */ table_name
FROM dba_tables
WHERE owner = 'SYS'
AND table_name LIKE '%$'
ORDER BY 1;
SELECT /*+ ALL_ROWS */ table_name
FROM dba_tables
WHERE owner = 'SYS'
AND table_name LIKE '%$'
ORDER BY 1;
SELECT /*+ FIRST_ROWS */ table_name
FROM dba_tables
WHERE owner = 'SYS'
AND table_name LIKE '%$';
SELECT /*+ FIRST_ROWS(10) */ table_name
FROM dba_tables
WHERE owner = 'SYS'
AND table_name LIKE '%$';
SELECT /*+ CHOOSE */ table_name
FROM dba_tables
WHERE owner = 'SYS'
AND table_name LIKE '%$'
ORDER BY 1;
Читайте также: