
Где хранятся таблицы oracle
При решении задачи хранения и обеспечения доступа к историческим данным очень часто возникает задача выгрузки архивных данных на резервный носитель (например, на магнитную ленту) с возможностью оперативного восстановления этой информации и обеспечения доступа к ней пользователей. Эта проблема наиболее актуальна для хранилищ данных, хотя может применяться и для обработки архивных данных OLTP-систем.
В данной статье описывается способ решения этой проблемы с помощью опции Partitioning базы данных Oracle Database.
Ниже представлена иллюстрация данного подхода, который включает в себя: идентификацию исторических данных, их перемещение во временную таблицу, экспорт и копирование на резервный носитель.
Иллюстрация подхода перемещения исторических данных
Первым шагом является определение секций, содержащих исторические данные. Исторические данные – это данные за прошлые периоды, над которыми в будущем не будут проводиться операции изменения. Затем секции, содержащие исторические данные, перемещаются в заранее подготовленную временную таблицу. Следующим шагом производится экспорт метаданных для Transport Table Space (TTS). В заключении производится перенос файла с метаданными и файла табличного пространства на резервный носитель.
Далее будет детально рассматриваться процесс экспорта и импорта табличного пространства для одного раздела секционированной таблицы CALLS (информация о телефонных звонках клиентов) схемы DWH.
Описанный подход был принят как основной для задач перемещение и восстановление исторических данных хранилища корпоративной информации компании “ОАО Ростелеком”.
2. Определение исторических данных
Для выявления исторических данных, то есть тех данных которые не будут больше изменяться, администратор должен ежемесячно проводить мониторинг их появления. Перечень данных, которые следует признавать историческими, определяют бизнес-требования. Часто правило определения исторических данных сводится к такому условию: историческими признаются те данные, срок хранения которых превышает определенный лимит, например, 5 лет от текущего момента.
Для автоматизации выявления исторических данных в конкретной таблице фактов, возможно выполнение следующего запроса (обращение к словарю Oracle Database):
Данный запрос вернет перечень разделов (см. поле PARTITION_NAME) по таблицам, данные в которых являются историческими (срок хранения превышает 5 лет). Эти данные необходимо архивировать и перенести на резервный носитель.
3. Перемещение исторических данных
Для перемещения раздела таблицы с историческими данными будет использована технология перемещаемых табличных пространств (Transportable Tablespace). Для перемещения табличных пространств необходимо провести следующие действия:
- Создать временную таблицу, в которую будут перемещены исторические данные.
- Переместить во временную таблицуисторические данные путем смены разделов (exchange partition).
- Убрать все логические и физические связи табличного пространства и раздела таблицы со всеми объектами кроме временной таблицы.
- Сделать табличное пространство доступным только для чтения (read only).
- Сделать экспорт метаданных табличного пространства раздела с историческими данными (для успешного выполнения экспорта и импорта необходимо, чтобы пользователь, из-под которого выполняются данные операции, обладал правами exp_full_database и imp_full_database соответственно).
- Скопировать файл с метаданными и файлы данных табличного пространства с историческими данными в папку для переноса на резервный носитель.
- Сделать архив, включив в него: файл с метаданными, файлы табличного пространства, дополнительный файл с описанием.
- Удалить табличное пространство с историческими данными из БД.
Ниже приведена последовательность действий по перемещению исторических данных из раздела P_0106 таблицы CALLS.
Данные раздела P_0106 хранятся в табличном пространстве TBS_CALLS_0106_1, которое в свою очередь, состоит из двух файлов: TBS_CALLS_0106_1_001.dbf и TBS_CALLS_0106_1_002.dbf.
Ниже все скрипты будут выполняться из-под пользователя system.
4. Создание временной таблицы
Создадим временную таблицу, в которую в последствии переместим раздел с историческими данными.
5. Перемещение данных во временную таблицу
Выполняем команду смены раздела (exchange paertition) P_0106 (раздел с историческими данными) между таблицей CALLS и временной таблицей CALLS$EXP$P_0106.
6. Удаление связей
Сделать экспорт метаданных табличного пространства можно только тогда, когда оно не связано с другими объектами базы данных.
Для проверки наличия связей необходимо выполнить следующие процедуру и запрос (их необходимо выполнять из-под пользователя SYS):
Если запрос к представлению TRANSPORT_SET_VIOLATIONS возвращает записи, то это значит, что взаимосвязи раздела с другими объектами базы данных существуют. Необходимо, чтобы запрос к данному представлению НЕ возвращал строк. Для этого необходимо изменить табличные пространства для раздела P_0106 таблицы CALLS – переместить раздел в табличное пространство TBS_CALLS_0106_HIST и переместить метаданные о таблице CALLS$EXP$P_0106 в табличное пространство TBS_CALLS_0106_1:
Выполним проверку наличия взаимосвязей повторно.
В представлении TRANSPORT_SET_VIOLATIONS записи отсутствуют – взаимосвязей нет.
7. Атрибут "только для чтения"
Сделать экспорт метаданных табличного пространства можно только тогда, когда оно находится в режиме "только для чтения". Сделать табличное пространство доступным только для чтения можно, выполнив следующую команду:
8. Экспорт табличного пространства
Произведем экспорт метаданных табличного пространства. Для этого будет использована технология DataPump и, соответственно, утилита expdp.
В командной строке необходимы выполнить команду экспорта (см. скрипт – export.sh) в директорию определенною в переменной DATA_PUMP_DIR базы данных.
Перейдем в директорию, которую определяет переменная DATA_PUMP_DIR.
Просмотрим ее содержимое.
9. Копирование файлов
Скопируем файл с метаданными TBS_CALLS_0106_1.DMP и файлы данных БД TBS_CALLS_0106_1_001.dbf, TBS_CALLS_0106_1_002.dbf в директорию /backup/DWH/TBS_CALLS_0106_1_HIST, предназначенную для временного хранения архивов, перед переносом на резервный носитель. Предварительно директорию TBS_CALLS_0106_1_HIST необходимо создать в /backup/DWH/.
Рекомендуется создать текстовый файл /backup/DWH/TBS_CALLS_0106_1.txt, в котором описать месторасположение файлов с данными экспортируемого табличного пространства. И затем включить данный текстовый файл в архив.
Для создания файла с описанием можно выполнить следующие действия (в операционной системе Unix):
- Создать файл: touch TBS_CALLS_0106_1.txt.
- Открыть файл на редактирование: cat > TBS_CALLS_0306_1.txt.
- Внести в файл текст.
- По окончанию редактирования файла нажать Cntr+D.
10. Создание архива
Создадим архив с содержимым директории TBS_CDR_0306_1_HIST, используя утилиту tar. Этот архив, впоследствии, и будет перемещен на резервный носитель.
Архив создан. Теперь можно удалить исторические данные из таблицы БД.
11. Удаление табличного пространства
Удалим табличное пространство TBS_CALLS_0106_1
Вместе с табличным TBS_CALLS_0106_1 пространством удалится и временная таблица CALLS$EXP$P_0106.
Для облегчения в дальнейшем процесса восстановления в таблице с данными (в нашем примере это таблица CALLS) раздел, в котором были исторические данные, лучше оставить.
12. Восстановление исторических данных
Для восстановления исторических данных из архива необходимо провести следующие действия:
- Скопировать архив с историческими данными с резервного носителя в директорию для восстановления.
- Распаковать архив.
- Скопировать файл с метаданными в папку для восстановления и файлов с данными в папку (или папку) сервера базы данных, где они находились до проведения экспорта.
- Импорт исторических данных во временную таблицу.
- Смена табличных пространств.
13. Копирование и распаковка архива
Скопируем архив с историческими данными с резервного носителя в директорию для восстановления. В нашем примере это будет директория /backup/Restore. Обычно эту функцию выполняет администратор системы резервного копирования.
Подключимся к серверу, на котором работает наша СУБД, под пользователем операционной системы oracle, используя командную строку.
Извлечём файлы из архива.
14. Копирование файлов
Скопирем файл с метаданными TBS_CALLS_0106_1.DMP в директорию /u01/app/oracle/product/10.2.0/db_1/admin/DWH/dpdump/,
файл данных TBS_CALLS_0106_1_001.dbf в директорию /wh/oracle/disk1/DWH/;
файл данных TBS_CALLS_0106_1_002.dbf в директорию /wh/oracle/disk0/DWH/.
15. Импорт исторических данных
Выполним команду экспорта метаданных табличного пространства (см. скрипт – import.sh) в директорию, определенную в переменной DATA_PUMP_DIR базы данных.
После окончания импорта метаданных табличного пространства в схеме DWH появится таблица CALLS$EXP$P_0106.
16. Смена табличных пространств
Осуществим смену (partitio6 exchange) между таблицей CALLS$EXP$P_0106 и таблице CALLS.
17. Заключение
База данных Oracle Database предоставляет гибкий механизм управления табличными пространствами секционированных таблиц, что позволяет достаточно просто организовать управление архивными данными, как в OLTP-системах, так и в хранилищах данных.
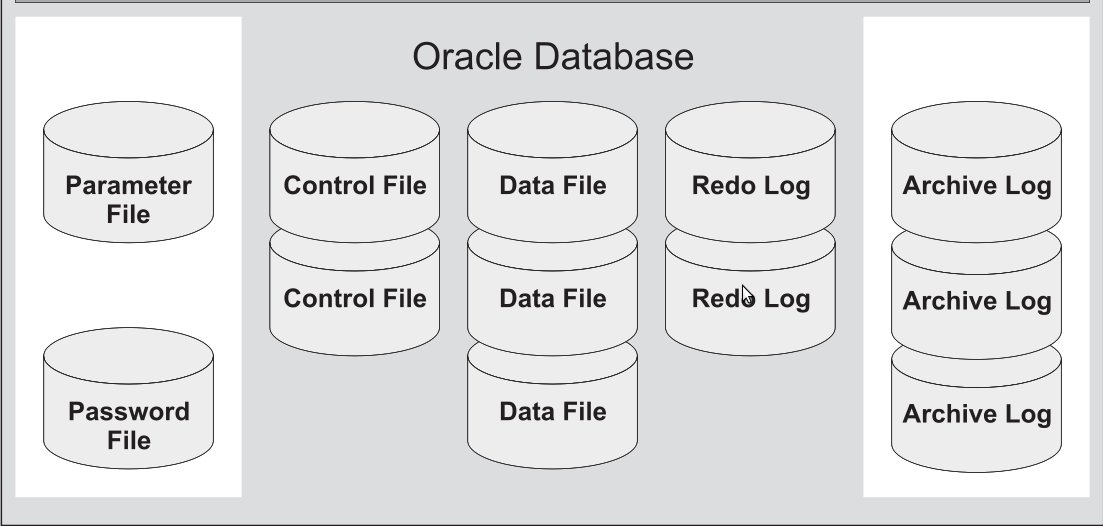
Предполагается, что вы инсталлировали базу данных, согласно документа.
Обязательные файлы:
Необязательные файлы:
-
(необязательные в том смысле, что база может быть настроена для работы без данных файлов) (Alertlog - если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить) (По умолчанию не используются. Нужно специально создавать специальными командами.)
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления - все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора - предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно - означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile - бинарный файл, который используется сервером Oracle при старте.
- pfile - текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных - наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
Tags: Oracle Database, Файлы базы данных Oracle,
Oracle DBA
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.
Oracle Database — это объектно-реляционная СУБД (система управления базами данных), созданная компанией Oracle. В настоящее время она имеет множество разных версий и типов. Однако в этой статье мы поговорим не о видах баз данных Oracle, а о структуре и основных концепциях, которые относятся к СУБД Oracle Database. Поняв архитектуру СУБД Oracle, вы заложите фундамент, необходимый для понимания прочих средств (а они весьма обширны), предоставляемых базой данных Oracle.
Базы данных Oracle: экземпляры и сущности
СУБД Oracle Database включает в себя физические и логические компоненты. Особого упоминания заслуживает понятие экземпляра. Замечено, что некоторые используют термины «база данных» и «экземпляр» в качестве синонимов. Да, это взаимосвязанные, но всё же разные вещи. База данных в терминологии Oracle — это физическое хранилище информации, а экземпляр — это программное обеспечение, которое работает на сервере и предоставляет доступ к информации, содержащейся в базе данных Oracle. Экземпляр исполняется на конкретном сервере либо компьютере, в то самое время как база данных хранится на дисках, подключённых к этому серверу:
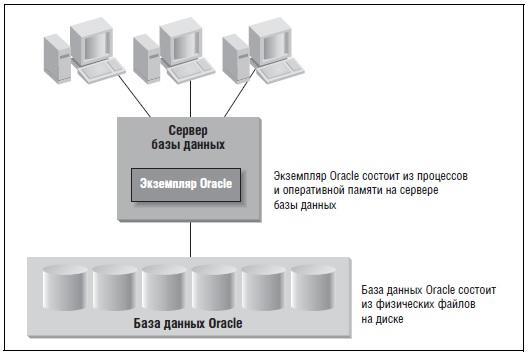
При этом база данных Oracle является физической сущностью, состоящей из файлов, которые хранятся на дисках. В то же самое время, экземпляр – это сущность логическая, состоящая из структур в оперативной памяти и процессов, которые работают на сервере. Экземпляр может являться частью только одной базы данных. При этом с одной базой данных бывает ассоциировано несколько экземпляров. Экземпляр ограничен по времени жизни, тогда как БД, условно говоря, может существовать вечно.
Также стоит заметить, что у пользователей нет прямого доступа к информации, которая хранится в базе данных Oracle — они должны запрашивать эту информацию у экземпляра Oracle.
Если упрощённо, то экземпляр — это мост к базе данных, а сама БД – это остров. Когда экземпляр запущен, мост работает, а данные способны попадать в базу данных Oracle и покидать её. Если мост перекрыт (экземпляр остановлен), пользователи не могут обращаться к базе данных, несмотря на то, что физически она никуда не исчезла.
Структура базы данных Oracle
База данных Oracle включает в себя: — табличные пространства; — управляющие файлы; — журналы; — архивные журналы; — файлы трассировки изменения блоков; — ретроспективные журналы; — файлы резервных копий (RMAN).
Табличные пространства Oracle
Любые данные, которые хранятся в базе данных Oracle, просто обязаны существовать в каком-либо табличном пространстве. Под табличным пространством (tablespace) понимают логическую структуру, то есть вы не сможете попросить ОС показать вам табличное пространство Oracle.
При этом каждое табличное пространство включает в себя физические структуры, называемые файлами данных (data files). Одно табличное пространство Oracle способно содержать один либо несколько файлов данных, в то время как каждый файл данных может принадлежать лишь одному tablespace. Создавая таблицу, мы можем указать, в какое именно табличное пространство мы её поместим — Oracle находит для неё место в каком-нибудь из файлов данных, которые составляют указанное табличное пространство.
На рисунке ниже вы можете посмотреть на соотношение между файлами данных и табличными пространствами в базе данных Oracle.
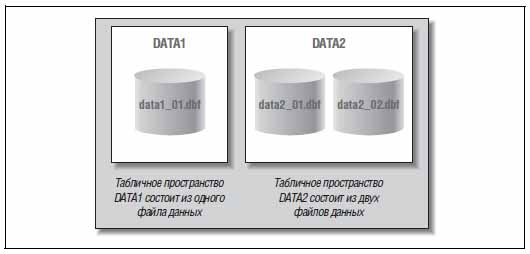
Создавая новую таблицу, мы можем поместить её в табличное пространство DATA1 либо DATA2. Таким образом, физически наша таблица окажется в одном из файлов данных, которые составляют указанное табличное пространство.
Файлы базы данных Oracle
База данных Oracle может включать в себя физические файлы 3-х основных типов: • control files — управляющие файлы; • data files — файлы данных; • redo log files — журнальные файлы либо журналы.
Посмотрим на отношения между ними:
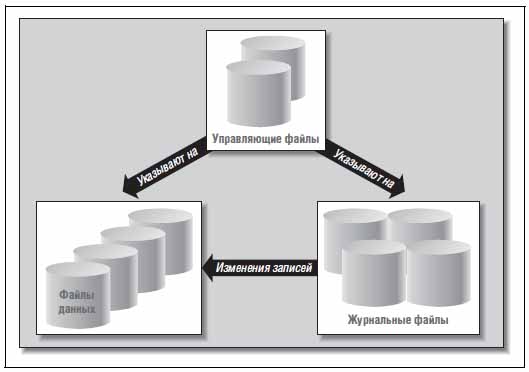
В управляющих файлах содержится информация о местонахождении других физических файлов, которые составляют базу данных Oracle, — речь идёт о файлах данных и журналов. Также там хранится важная информация о содержимом и состоянии БД Oracle. Что это за информация: • имя базы данных Oracle; • время создания БД; • имена и местонахождение журнальных файлов и файлов данных; • информация о табличных пространствах; • информация об архивных журналах; • история журналов, порядковый номер текущего журнала; • информация о файлах данных в автономном режиме; • информация о резервных копиях, контрольных точках, копиях файлов данных.
При этом функция управляющих файлов не ограничивается хранением важной информации, нужной при запуске экземпляра, — полезны они и в процессе удалении БД Oracle. К примеру, уже с версии Oracle Database 10g можно посредством команды DROP DATABASE удалить все файлы, которые перечислены в управляющем файле БД, включая сам управляющий файл.
Инициализация СУБД Oracle
Когда вы запускаете экземпляр Oracle, происходит считывание параметров инициализации. Параметры определяют, каким образом базе данных Oracle следует использовать физическую инфраструктуру и прочую конфигурационную информацию об экземпляре.
Как правило, инициализационные параметры хранятся в файле параметров инициализации экземпляра (обычно это INIT.ORA) либо, начиная с Oracle9i, в репозитории, называемом файлом параметров сервера (SPFILE). С выходом каждой новой версии Oracle число обязательных параметров инициализации уменьшается.
Кстати, в дистрибутиве Oracle можно найти пример файла инициализации, который пригоден для запуска базы данных. Также можно воспользоваться специальной программой Database Configuration Assistant (DCA) — она подскажет обязательные значения.
Более подробную информацию смотрите в официальной документации для СУБД Oracle Database.
Управление и обслуживание табличного пространства ORACLE
1: Концепция табличного пространства
В базе данных ORACLE все данные хранятся в табличном пространстве из логической структуры, конечно же, есть логические структуры, такие как сегменты, области, блоки под табличным пространством. Из физической структуры он помещается в файл данных. Табличное пространство может состоять из нескольких файлов данных.
Как показано на следующем рисунке, база данных состоит из одного или нескольких табличных пространств, которые логически состоят из одного или нескольких сегментов и физически состоят из одного или нескольких файлов os.

![clip_image002[4]](https://russianblogs.com/images/867/e843b35e8839efdd8a981e21c455539b.JPEG)
1.1 базовое табличное пространство
Несколько табличных пространств, созданных по умолчанию в системе:
Сколько табличных пространств необходимо в системе?
Ответ: SYSTEM, SYSAUX, TEMP, UNDO, как USERS, ПРИМЕР Ожидание табличного пространства необязательно.
1.2 Классификация табличных пространств
Постоянное табличное пространство Храните постоянные данные, такие как таблицы, индексы и т. Д.
Временное табличное пространство Невозможно хранить постоянные объекты, используемые для сохранения временных данных, сгенерированных при сортировке и группировке базы данных.
UNDO табличное пространство Сохраните зеркальное отображение перед изменением данных.
1.3 Управление табличным пространством
Метод управления табличным пространством:
Управление словарем: все пространство, выделенное для всей библиотеки, помещается в словарь данных. Легко вызвать конфликт по словарю и вызвать проблемы с производительностью.
2: создать табличное пространство
3: Управление табличным пространством
3.1 Информация табличного пространства
Как проверить, какие табличные пространства находятся в базе данных? Как просмотреть файл данных, соответствующий табличному пространству?
Просмотр табличного пространства:
Просмотр табличного пространства позволяет просматривать основную информацию через следующие системные представления
-Содержит описательную информацию для всех табличных пространств в базе данных
SELECT * FROM DBA_TABLESPACES
-Содержит информацию описания табличного пространства текущего пользователя
SELECT * FROM USER_TABLESPACES
-Содержит имя табличного пространства и информацию о номере, полученную из контрольного файла
SELECT * FROM V$TABLESPACE;
Просмотр файлов данных
-Содержит информацию описания файла данных и табличного пространства, к которому он принадлежит
SELECT * FROM DBA_DATA_FILES
-Содержит информацию описания временного файла данных и табличного пространства, к которому он принадлежит
SELECT * FROM DBA_TEMP_FILES
- Содержит основную информацию о файле данных, полученном из контрольного файла, включая имя и номер табличного пространства, к которому он принадлежит
SELECT * FROM V$DATAFILE
- Содержит основную информацию обо всех временных файлах данных
SELECT * FROM V$TEMPFILE
3.1.1. Просмотр табличного пространства TEMP по умолчанию
Уровень базы данных
уровень пользователя
3.1.2. Просмотр постоянного табличного пространства по умолчанию
Если вы создаете пользователя без указания его постоянного табличного пространства, будет использоваться табличное пространство по умолчанию.
3.1.3. Просмотр табличного типа по умолчанию
Если вы не укажете тип табличного пространства, по умолчанию будет использован тип табличного пространства, указанный параметром DEFAULT_TBS_TYPE.
3.1.4. Просмотр табличного пространства
SELECT * FROM DBA_TABLESPACES
3.1.5. Просмотр файла данных табличного пространства
Постоянное табличное пространство / UNDO табличное пространство
SELECT * FROM DBA_DATA_FILES;
Временное табличное пространство
SELECT * FROM V$TEMPFILE;
3.1.6. Просмотр использования табличного пространства
Рассчитать использование табличного пространства (с учетом автоматического роста файлов данных)
3.2 табличное пространство по умолчанию
В базе данных ORACLE 9i, когда создается пользователь базы данных, если не указано постоянное табличное пространство по умолчанию, система использует табличные пространства SYSTME в качестве постоянного табличного пространства пользователя по умолчанию, а временное табличное пространство по умолчанию - TEMP. В ORACLE 10 / 11g, если вы не укажете постоянное табличное пространство по умолчанию, это ПОЛЬЗОВАТЕЛИ. Временное табличное пространство по умолчанию - TEMP, конечно, при условии, что вы не изменили значение постоянного табличного пространства по умолчанию или не указали постоянное табличное пространство пользователя по умолчанию. ORACLE позволяет использовать настраиваемые табличные пространства в качестве постоянного табличного пространства по умолчанию, вы можете использовать следующий SQL для просмотра постоянного табличного пространства по умолчанию и временного табличного пространства по умолчанию в базе данных.
SQL>SELECT * FROM database_properties
WHERE PROPERTY_NAME = 'DEFAULT_PERMANENT_TABLESPACE';
SQL>SELECT * FROM database_properties
WHERE PROPERTY_NAME ='DEFAULT_PERMANENT_TABLESPACE'
Вы можете использовать инструкцию ALTER DATABASE DEFAULT TABLESPACE, чтобы установить постоянное табличное пространство по умолчанию для базы данных, чтобы при создании пользователя указанное табличное пространство использовалось по умолчанию.
Уровень базы данных:
Постоянное табличное пространство
SQL>ALTER DATABASE DEFAULT TABLESPACE USER;
Временное табличное пространство
SQL>ALTER DATABASE DEFAULT TEMPORARY TABLESPACE TEMP;
SQL>ALTER USER USERNAM DEFAULT TABLESPACE NEW_TABLESPACE_NAME
Просмотр табличного пространства по умолчанию, соответствующего пользователю
SELECTUSERNAME, DEFAULT_TABLESPACEFROMDBA_USERS
1: Если мы указали табличное пространство по умолчанию в качестве значения DEFAULT_PERMANENT_TABLESPACE при создании пользователя, то после изменения табличного пространства по умолчанию табличное пространство пользователя также изменится.
2: Если мы не указали табличное пространство пользователя при создании пользователя, то табличное пространство по умолчанию БД также будет использоваться по умолчанию. В это время, если мы изменим табличное пространство по умолчанию БД, табличное пространство пользователя также изменится.
Переключите табличное пространство по умолчанию для базы данных на USERS
3: Если мы создаем пользовательское табличное пространство пользователя, являющееся другим табличным пространством, то мы изменяем табличное пространство БД по умолчанию, которое не повлияет на табличное пространство пользователя.
4: табличное пространство по умолчанию БД не может быть удалено, если табличное пространство по умолчанию не указано на другие табличные пространства, прежде чем его можно будет удалить.
SQL> DROP TABLESPACE USERS;
DROP TABLESPACE USERS
ORA-12919: невозможно удалить постоянное табличное пространство по умолчанию
5: если табличное пространство пользователя по умолчанию указывает на другие табличные пространства, при удалении этого табличного пространства табличное пространство пользователя по умолчанию автоматически указывает на табличное пространство по умолчанию в БД.
SQL> DROP TABLESPACE TEST2;
3.3 удалить табличное пространство
В дополнение к табличному пространству SYSTEM любое табличное пространство в базе данных может быть удалено. При удалении табличного пространства ORACLE просто удаляет информацию, связанную с табличным пространством и файлом данных, в управляющем файле и словаре данных. По умолчанию ORACLE не удаляет соответствующий файл данных в операционной системе, поэтому после успешного выполнения операции удаления табличного пространства необходимо вручную удалить соответствующий файл данных табличного пространства в операционной системе. Если вы удаляете соответствующий файл данных при удалении табличного пространства, вы должны отобразить указанное предложение INCLUDING CONTENTS AND DATAFILES. Примечание: Текущее табличное пространство по умолчанию на уровне базы данных не может быть удалено, а пользовательское табличное пространство может быть удалено. В противном случае будет сообщено об ошибке: ORA-12919: Невозможно удалить постоянное табличное пространство по умолчанию.
DROP TABLESPACE имя табличного пространства [ВКЛЮЧАЯ СОДЕРЖАНИЕ [И ДАННЫЕ ФАЙЛЫ] [КАСКАДНЫЕ СООТВЕТСТВИЯ]]
SQL> DROP TABLESPACE URER01 INCLUDING CONTENTS;
Если объект базы данных включен в табличное пространство, указанный оператор INCLUDING CONTENTS должен отображаться в операторе DROP TABLESPACE. Если вы хотите удалить табличное пространство USER при удалении соответствующего файла данных, вы можете использовать следующий оператор
SQL>DROP TABLESPACE USER01 INCLUDING CONTENTS AND DATAFILES;
Примечание. При удалении табличного пространства параметры CONTENTS и DATAFILES не выровнены, и будет показана следующая ошибка:
SQL>DROP TABLESPACE TBS_STAGE_DAT INCLUDING DATAFILES AND CONTENTS
ORA-01911:contents keyword expected
SQL>DROP TABLESPACE TBS_STAGE_DAT INCLUDING CONTENTS AND DATAFILES
3.4 Настройте табличное пространство
3.4.1 Добавить файл данных
Если вы обнаружите, что в табличном пространстве недостаточно места для хранения, вы можете добавить новый файл данных в табличное пространство, чтобы увеличить размер табличного пространства. Однако, как правило, рекомендуется заранее оценить объем памяти, необходимый для табличного пространства, а затем создать для него несколько файлов данных соответствующего размера.
При добавлении нового файла данных, если операционная система с таким именем уже существует, инструкция ALTER TABLESPACE завершится ошибкой. Если вы хотите перезаписать файл операционной системы с тем же именем, вы должны указать предложение REUSE, показанное ниже.
SQL> ALTER TABLESPACE TBS_EDS_DAT
2 ADD DATAFILE 'G:\datafile\TBS_EDS_DAT01.DBF'
4 AUTOEXTEND ON
6 MAXSIZE 51200M;
ALTER TABLESPACE TBS_EDS_DAT
Произошла ошибка в строке 1:
ORA-03206: максимальный размер файла (6553600) блока в предложении AUTOEXTEND вне диапазона
Размер файла данных, поддерживаемый ORACLE, определяется числом db_block_size и db_block. Число db_block (блок ORACLE) является фиксированным значением 2 ** 22-1 (4194303). Емкость файла данных = количество блоков * размер блока. В следующем списке показан максимальный размер физического файла, который могут поддерживать разные базы данных блоков данных:
Размер блока данных Максимальный физический файлMМаксимальный физический файл G
16KB 65535M 64G
32KB 131072M 128G
64KB 262144M 256G
3.4.2 Настройка размера файла данных
Сбросить размер файла данных
ALTER DATABASE DATAFILE '/database/oracle/oradata/gsp/tbs_dm_data_002.dbf'
3.4.3 Удалить файлы данных
ALTER TABLESPACE TEST
DROP DATAFILE '/database/oracle/oradata/gsp/tbs_dm_data_002.dbf'
3.4.4 Мобильные файлы данных
Теперь есть такой случай: в прошлом на сервере базы данных был только один диск с относительно небольшой емкостью, и все файлы данных были помещены на диск D. Позже я подал заявку на диск 1T и мне нужно было освободить место для диска D (диск D заполнен). Переместите несколько больших файлов данных на диск 1T:
Под Linux / Unix
3.4.5 Файлы автономных данных
ALTER DATABASE DATAFILE '/database/oracle/oradata/gsp/tbs_dm_data_002.dbf' OFFLINE;
3.4.6 Файл данных онлайн
ALTER DATABASE DATAFILE '/database/oracle/oradata/gsp/tbs_dm_data_002.dbf' ONLINE;
4: поддерживать табличное пространство
4.1 Изменение состояния табличного пространства
Состояние табличного пространства имеет следующие состояния: онлайн, оффлайн, только чтение, чтение и запись.
Чтобы просмотреть состояние табличного пространства, вы можете просмотреть его с помощью следующего оператора SQL.
4.1.1 Табличное пространство не в сети
SQL>ALTER TABLESPACE TBS_DM_DAT OFFLINE IMMEDIATE;
Чтобы установить автономный статус, вы можете использовать следующие 4 параметра для управления автономным режимом
НОРМАЛЬНЫЙ Этот параметр указывает, что табличное пространство переключается в автономное состояние обычным способом. Затем закройте все файлы данных табличного пространства. Если во время этого процесса не возникает ошибок, вы можете использовать параметр NORMAL, который также используется по умолчанию.
TEMPORARY Этот параметр временно переводит табличное пространство в автономный режим. В настоящее время ORACLE не будет проверять состояние каждого файла данных при выполнении контрольной точки. Даже если некоторые файлы данных недоступны, ORACLE будет игнорировать эти ошибки. Таким образом, когда табличное пространство установлено в оперативное состояние, может потребоваться восстановление данных.
IMMEDIATE Этот параметр немедленно переводит табличное пространство в автономный режим, при котором ORACLE не будет выполнять контрольную точку или проверять, доступен ли файл данных. Вместо этого файлы данных, принадлежащие табличному пространству, переводятся в автономный режим. База данных должна быть восстановлена при следующем включении табличного пространства в оперативный режим.
FOR RECOVER Этот параметр переводит табличное пространство в автономное состояние для восстановления. Если вы хотите выполнить восстановление табличного пространства на основе времени, вы можете использовать этот параметр, чтобы переключить табличное пространство в автономное состояние.
Если база данных работает в неархивном режиме (NOARCHIVELOG), поскольку данные для восстановления, необходимые для восстановления табличного пространства, не могут быть сохранены, табличное пространство нельзя немедленно переключить в автономное состояние. Если табличное пространство находится в автономном режиме, запросите таблицы в табличном пространстве и сообщите об ошибке: в данный момент ORA-00376 не может прочитать файл, а ORA-01110: файл данных x .
Примечание. Автономный режим (автономный режим) обычно используется для оперативного резервного копирования базы данных, восстановления данных и других операций обслуживания. Некоторые табличные пространства не могут быть в автономном режиме, такие как: SYTEM, UNDO и т. Д.
1. SYTEM не может быть в автономном режиме или только для чтения
2. Пустое пространство текущей таблицы UNDO не может быть отключено или доступно только для чтения.
3. Текущее временное табличное пространство не может быть отключено или доступно только для чтения.
4. SYSAUX может быть в автономном режиме, но не только для чтения
SQL> ALTER TABLESPACE SYSTEM OFFLINE;
ALTER TABLESPACE SYSTEM OFFLINE
ORA-01541: system tablespace cannot be brought offline; shut down if necessary
SQL> ALTER TABLESPACE SYSTEM OFFLINE;
ALTER TABLESPACE SYSTEM OFFLINE
ORA-01541: system tablespace cannot be brought offline; shut down if necessary
4.1.2 Табличное пространство онлайн
SQL> ALTER TABLESPACE TBS_DM_DAT ONLINE;
4.1.3 Табличное пространство только для чтения
SQL>ALTER TABLESPACE TBS_DM_DAT READY ONLY;
Когда табличное пространство доступно только для чтения, никакие операции DML не могут быть выполнены с таблицами в нем, в противном случае будет сообщено об ошибке: ORA-00372: файл xxx не может быть изменен в данный момент
ORA-01110: файл данных xx: ********. Но таблицу можно удалить.
4.1.4 Табличное пространство для чтения и записи
SQL>ALTER TABLESPACE TBS_DM_DAT READ WRITE;
4.1.5 Переименование табличного пространства
До ORACLE 10g имя табличного пространства нельзя изменить. В ORACLE 11G, используя предложение RENAME в операторе ALTER TABLESPACE, администратор базы данных может изменить имя табличного пространства.
4.1.6 Включить автоматическое расширение
ALTER DATABASE DATAFILE '/database/oracle/oradata/gsp/tbs_dm_data_002.dbf' AUTOEXTEND ON;
4.1.7 Отключить автоматическое расширение
ALTER DATABASE DATAFILE '/database/oracle/oradata/gsp/tbs_dm_data_002.dbf' AUTOEXTEND OFF;
5 Квота табличного пространства
Недостаточное табличное пространство и недостаточная квота пользователя - это две разные концепции. Размер табличного пространства относится к размеру фактического пользовательского табличного пространства, а размер квоты относится к размеру табличного пространства, указанного пользователем. Два решения не совпадают
3.5.1 Просмотр квоты табличного пространства пользователя
MAX_BYTES = -1 означает, что квота не установлена,
3.5.2 Управление квотой табличного пространства пользователя
Создание и изменение квоты пользовательского табличного пространства:
1. При создании пользователя укажите лимит
CREATE USER TEST IDENTIFIED BY TEST
DEFAULT TABLESPACE TS_TEST
TEMPORARY TABLESPACE TEMP
QUOTA 3M ON TS_TEST
2. Измените ограничение табличного пространства пользователя:
A: Не контролируйте ограничение табличного пространства для пользователей:
Проверьте, нет ли ограничения табличного пространства
B: отменить квоту
Этот подход является глобальным.
SQL> GRANT UNLIMITED TABLESPACE TO SCOTT;
Или для конкретного табличного пространства.
SQL>ALTER USER SCOTT QUOTA UNIMITED ON TBS_EDS_DAT;
SELECT * FROM SESSION_PRIVS WHERE PRIVILEGE='UNLIMITED TABLESPACE'
SQL> REVOKE UNLIMITED TABLESPACE FROM SCOTT;
C: установить квоты
3. Может распространяться естественным путем или переработано:
revoke unlimited tablespace from TEST;
alter user skate quota 0 on TB;
Чтобы решить проблему недостаточного размера табличного пространства: используйте команду «ALTER TABLESPACE tablespace_name ADD DATAFILE filename SIZE size_of_file», чтобы увеличить табличное пространство до указанных данных, в зависимости от конкретной ситуации можно увеличить одно или несколько табличных пространств.

Высоконагруженные сайты, доступность «5 nines». На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle. Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g – означает «grid», распределенные вычисления. В основе распределенных вычислений «как ни крути» лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster (RAC).
Статья не претендует на полноту и всеобъемлемость, также в ней исключены настройки (дабы не увеличивать в объеме). Смысл – просто дать представление о технологии RAC.
Статью хотелось написать как можно доступнее, чтобы прочесть ее было интересно даже человеку, мало знакомому с СУБД Oracle. Поэтому рискну начать описание с аспектов наиболее часто встречаемой конфигурации БД – single-instance, когда на одном физическом сервере располагается одна база данных (RDBMS) Oracle. Это не имеет непосредственного отношения к кластеру, но основные требования и принципы работы будут одинаковы.
Введение. Single-instance.
- область хранения данных, т.е. физические файлы на диске (datastorage) (сама БД)
- экземпляр БД (получающая и обрабатывающая эти данные в оперативной памяти) (СУБД)

Во всех современных реляционных БД данные хранятся в таблицах. Таблицы, индексы и другие объекты в Oracle хранятся в логических контейнерах – табличных пространствах (tablespace). Физически же tablespace располагаются в одном или нескольких файлах на диске. Хранятся они следующим образом:
Каждый объект БД (таблицы, индексы, сегменты отката и.т.п.) хранится в отдельном сегменте – области диска, которая может занимать пространство в одном или нескольких файлах. Сегменты в свою очередь, состоят из одного или нескольких экстентов. Экстент – это непрерывный фрагмента пространства в файле. Экстенты состоят из блоков. Блок – наименьшая единица выделения пространства в Oracle, по умолчанию равная 8K. В блоках хранятся строки данных, индексов или промежуточные результаты блокировок. Именно блоками сервер Oracle обычно выполняет чтение и запись на диск. Блоки имеют адрес, так называемый DBA (Database Block Address).

При любом обращении DML (Data Manipulation Language) к базе данных, Oracle подгружает соответствующие блоки с диска в оперативную память, а именно в буферный кэш. Хотя возможно, что они уже там присутствуют, и тогда к диску обращаться не нужно. Если запрос изменял данные (update, insert, delete), то изменения блоков происходят непосредственно в буферном кэше, и они помечаются как dirty (грязные). Но блоки не сразу сбрасываются на диск. Ведь диск – самое узкое место любой базы данных, поэтому Oracle старается как можно меньше к нему обращаться. Грязные блоки будут сброшены на диск автоматически фоновым процессом DBWn при прохождении контрольной точки (checkpoint) или при переключении журнала.

- Что будет, если Oracle упадет где-то на середине длинной транзакции (если бы она вносила изменения)?
- Какие же данные прочтет первая транзакция, когда в кэше у нее «под носом» другая транзакция изменила блок?
- журнал повтора (redo log)
- сегмент отмены (undo)

Когда в базу данных поступает запрос на изменение, то Oracle применяет его в буферном кэше, параллельно внося информацию, достаточную для повторения этого действия, в буфер повторного изменения (redo log buffer), находящийся в оперативной памяти. Как только транзакция завершается, происходит ее подтверждение (commit), и сервер сбрасывает содержимое redo buffer log на диск в redo log в режиме append-write и фиксирует транзакцию. Такой подход гораздо менее затратен, чем запись на диск непосредственно измененного блока. При сбое сервера кэш и все изменения в нем потеряются, но файлы redo log останутся. При включении Oracle начнет с того, что заглянет в них и повторно выполнит изменения таблиц (транзакции), которые не были отражены в datafiles. Это называется «накатить» изменения из redo, roll-forward. Online redo log сбрасывается на диск (LGWR) при подтверждении транзакции, при прохождении checkpoint или каждые 3 секунды (default).
С undo немного посложнее. С каждой таблицей в соседнем сегменте хранится ассоциированный с ней сегмент отмены. При запросе DML вместе с блоками таблицы обязательно подгружаются данные из сегмента отката и хранятся также в буферном кэше. Когда данные в таблице изменяются в кэше, в кэше так же происходит изменение данных undo, туда вносятся «противодействия». То есть, если в таблицу был внесен insert, то в сегмент отката вносится delete, delete – insert, update – вносится предыдущее значение строки. Блоки (и соответствующие данные undo) помечаются как грязные и переходят в redo log buffer. Да-да, в redo журнал записываются не только инструкции, какие изменения стоит внести (redo), но и какие у них противодействия (undo). Так как LGWR сбрасывает redo log buffer каждые 3 секунды, то при неудачном выполнении длительной транзакции (на пару минут), когда после минуты сервер упал, в redo будут записи не завершенные commit. Oracle, как проснется, накатит их (roll-forward), и по восстановленным (из redo log) в памяти сегментам отката данных отменит (roll-back) все незафиксированные транзакции. Справедливость восстановлена.
Кратко стоит упомянуть еще одно неоспоримое преимущество undo сегмента. По второму сценарию (из схемы) когда select дойдет до чтения блока (DBA) 500, он вдруг обнаружит что этот блок в кэше уже был изменен (пометка грязный), и поэтому обратится к сегменту отката, для того чтобы получить соответствующее предыдущее состояние блока. Если такого предыдущего состояния (flashback) в кэше не присутствовало, он прочитает его с диска, и продолжит выполнение select. Таким образом, даже при длительном «select count(money) from bookkeeping» дебет с кредитом сойдется. Согласованно по чтению (CR).
Отвлеклись. Пора искать подступы к кластерной конфигурации. =)
Уровень доступа к данным. ASM.

Хранилищем (datastorage) в больших БД почти всегда выступает SAN (Storage Area Network), который предоставляет прозрачный интерфейс серверам к дисковым массивам.
Сторонние производители (Hitachi, HP, Sun, Veritas) предлагают комплексные решения по организации таких SAN на базе ряда протоколов (самым распространенным является Fibre Channel), с дополнительными функциональными возможностями: зеркалирование, распределение нагрузки, подключение дисков на лету, распределение пространства между разделами и.т.п.
Позиция корпорации Oracle в вопросе построения базы данных любого масштаба сводится к тому, что Вам нужно только соответствующее ПО от Oracle (с соответствующими лицензиями), а выбранное оборудование – по возможности (если средства останутся после покупки Oracle :). Таким образом, для построения высоконагруженной БД можно обойтись без дорогостоящих SPARC серверов и фаршированных SAN, используя сервера на бесплатном Linux и дешевые RAID-массивы.
На уровне доступа к данным и дискам Oracle предлагает свое решение – ASM (Automatic Storage Management). Это отдельно устанавливаемый на каждый узел кластера мини-экземпляр Oracle (INSTANCE_TYPE = ASM), предоставляющий сервисы работы с дисками.
Oracle старается избегать обращений к диску, т.к. это является, пожалуй, основным bottleneck любой БД. Oracle выполняет функции кэширования данных, но ведь и файловые системы так же буферизуют запись на диск. А зачем дважды буферизировать данные? Причем, если Oracle подтвердил транзакцию и получил уведомления том, что изменения в файлы внесены, желательно, чтобы они уже находились там, а не в кэше, на случай «падения» БД. Поэтому рекомендуется использовать RAW devices (диски без файловой системы), что делает ASM.
- отсутствие необходимости в отдельном ПО для управления разделами дисков
- нет необходимости в файловой системе
- Зеркалирование данных:
как правило, 2-х или 3-х ступенчатое, т.е. данные одновременно записываются на 2 или 3 диска. Для зеркалирования диску указываются не более 8 дисков-партнеров, на которые будут распределяться копии данных. - Автоматическая балансировка нагрузки на диски (обеспечение высокой доступности):
если данные tablespace разместить на 10 дисках и, в некоторый момент времени, чтение данных из определенных дисков будет «зашкаливать», ASM сам обратится к таким же экстентам, но находящимся на зеркалированных дисках. - Автоматическая ребалансировка:
При удалении диска, ASM на лету продублирует экстенты, которые он содержал, на другие оставшиеся в группе диски. При добавлении в группу диска, переместит экстенты в группе так, что на каждом диске окажется приблизительно равное число экстентов.
Таким образом, кластер теперь может хранить и читать данные с общего файлового хранилища.
Пора на уровень повыше.
Clusterware. CRS.
На данном уровне необходимо обеспечить координацию и совместную работу узлов кластера, т.е. clusterware слой: где-то между самим экземпляром базы данных и дисковым хранилищем:
CRS (Cluster-Ready Services) – набор сервисов, обеспечивающий совместную работу узлов, отказоустойчивость, высокую доступность системы, восстановление системы после сбоя. CRS выглядит как «мини-экземпляр» БД (ПО) устанавливаемый на каждый узел кластера. Устанавливать CRS – в обязательном порядке для построения Oracle RAC. Кроме того, CRS можно интегрировать с решениями clusterware от сторонних производителей, таких как HP или Sun.
Опять немного «терминологии»…
- CSSD – Cluster Synchronization Service Daemon
- CRSD – Cluster Ready Services Daemon
- EVMD – Event Monitor Daemon
Как уже стало ясно из таблички, самым главным процессом, «самым могущественным демоном», является CRSD (Cluster Ready Services Daemon). В его обязанности входит: запуск, остановка узла, генерация failure logs, реконфигурация кластера в случае падения узла, он также отвечает за восстановление после сбоев и поддержку файла профилей OCR. Если демон падает, то узел целиком перезагружается. CRS управляет ресурсами OCR: Global Service Daemon (GSD), ONS Daemon, Virtual Internet Protocol (VIP), listeners, databases, instances, and services.
- Node Membership (NM).Каждую секунду проверяет heartbeat между узлами. NM также показывает остальным узлам, что он имеет доступ к так называемому voting disk (если их несколько, то хотя бы к большинству), делая регулярно туда записи. Если узел не отвечает на heartbeat или не оставляет запись на voting disk в течение нескольких секунд (10 для Linux, 12 для Solaris), то master узел исключает его из кластера.
- Group Membership (GM). Функция отвечает за своевременное оповещение при добавлении / удалении / выпадении узла из кластера, для последующей реконфигурации кластера.
Информатором в кластере выступает EVMD (Event Manager Daemon), который оповещает узлы о событиях: о том, что узел запущен, потерял связь, восстанавливается. Он выступает связующим звеном между CRSD и CSSD. Оповещения также направляются в ONS (Oracle Notification Services), универсальный шлюз Oracle, через который оповещения можно рассылать, например, в виде SMS или e-mail.
Стартует кластер примерно по следующей схеме: CSSD читает из общего хранилища OCR, откуда считывает кластерную конфигурацию, чтобы опознать, где расположен voting disk, читает voting disk, чтобы узнать сколько узлов (поднялось) в кластере и их имена, устанавливает соединения с соседними узлами по протоколу IPC. Обмениваясь heartbeat, проверяет, все ли соседние узлы поднялись, и выясняет, кто в текущей конфигурации определился как master. Ведущим (master) узлом становится первый запустившийся узел. После старта, все запущенные узлы регистрируются у master, и впоследствии будут предоставлять ему информацию о своих ресурсах.
Уровнем выше CRS на узлах установлены экземпляры базы данных.
Друг с другом узлы общаются по private сети – Cluster Interconnect, по протоколу IPC (Interprocess Communication). К ней предъявляются требования: высокая ширина пропускной способности и малые задержки. Она может строиться на основе высокоскоростных версий Ethernet, решений сторонних поставщиков (HP, Veritas, Sun), или же набирающего популярность InfiniBand. Последний кроме высокой пропускной способности пишет и читает непосредственно из буфера приложения, без необходимости в осуществлении вызовов уровня ядра. Поверх IP Oracle рекомендует использовать UDP для Linux, и TCP для среды Windows. Также при передаче пакетов по interconnect Oracle рекомендует укладываться в рамки 6-15 ms для задержек.
Читайте также: