
Что делать если поврежден кэш
Вот и мне пришлось сталкнуться с этой злосчастной ошибкой. Естественно первым делом курение темы в гугле. Вариантов решения масса, но практически все под SQL версию. с файловой версией подходящего решения не нашел.
Итак приступим к описанию.
Первым делом решил очистить кеш тут C:\Users\Администратор\AppData\Roaming\1C\1Cv82 и тут C:\Users\Администратор\AppData\Local\1C\1Cv82 (Win7x64). После очистки кеша удалось запуститься в режиме конфигуратора. Попытки открыть конфигурацию приводили к падению. Выгрузить в ДТ удалось. Тестирование и исправление не помогает. Утилита проверки файловой базы говорит, что ошибок нет. Пункты меню загрузки, выгрузки конфигурации, поддержки и т.п. без открытой конфигурации не активны.
Так же из конфигуратора удалоь запуститья в пользовательский режим в режиме отладки. Просмотр данных показал, что данные живы.
Попытка загрузить DT файл в SQL приводила к падению.
Светлую мысль подсказал гугл - создать узел подчиненной базы и выгрузить все туда. не помогло - при выгрузке узла имеем такую же ошибку.
Все, в принципе, на этом можно было бы поставить крест на базе. подняться из древнего бекапа. и напрягаться с восстановление данных вручную (3 месяца работы бухгалтерии). НО!
Как оказалось эту ошибку можно обойти и уничтожить. Итак вот оно - решение:
1. Необходима чистая конфа той же версии, что и работающая база (в моем случае Бухгалтерия для Украины 1.2.5.3 ).
2. Очиста кеша полная.
3. Запускаем чистую базу в режиме конфигуратора и открываем конфигурацию. При этом 1Ска создает ее кеш в C:\Users\Администратор\AppData\Local\1C\1Cv82 (набор файлов и папок в папке с ID конфигурации.) так же нам нужен кеш C:\Users\Администратор\AppData\Roaming\1C\1Cv82.
4. Запускаем наш "трупп" в режиме конфигуратора и смотрим кеш. Имеем две папки с ID конфигурации (Живой и Мертвой).
5. Закрываем все и подменяем кеш мертвой конфы на живую полностью.
6. Запускаем мертвую конфу в режиме конфигуратора и. ап, дерево конфигурации открыто, разделы меню управления конфигурацией активны.
7. Идем в управление поддержкой, и снимаем с поддержки полностью. сохраняем, обновляем.
8. Удалем кеш полностью.
9. Запускаем Битую базу в режиме конфигуратора, пытаемся открыть конфигурацию - все открывается, ошибки нет.
10. Берем CFку текущей версии конфигурации и делаем полную загрузку, сохраняем, обновляем, в результате получаем конфу снова на поддержке.
11. Для верности очистим кеш и попробуем запустить все сначала и открыть конфигурацию. все должно работать, по карйней мере у меня все получилось.
Вывод из всего этого - нет ничего не выполнимого, и непоправимого, главное не паниковать и включать мозги и фанатазию :)
Меня зовут Виктор Пряжников, я работаю в SRV-команде Badoo. Наша команда занимается разработкой и поддержкой внутреннего API для наших клиентов со стороны сервера, и кэширование данных — это то, с чем мы сталкиваемся каждый день.
Существует мнение, что в программировании есть только две по-настоящему сложные задачи: придумывание названий и инвалидация кэша. Я не буду спорить с тем, что инвалидация — это сложно, но мне кажется, что кэширование — довольно хитрая вещь даже без учёта инвалидации. Есть много вещей, о которых следует подумать, прежде чем начинать использовать кэш. В этой статье я попробую сформулировать некоторые проблемы, с которыми можно столкнуться при работе с кэшем в большой системе.

Я расскажу о проблемах разделения кэшируемых данных между серверами, параллельных обновлениях данных, «холодном старте» и работе системы со сбоями. Также я опишу возможные способы решения этих проблем и приведу ссылки на материалы, где эти темы освещены более подробно. Я не буду рассказывать, что такое кэш в принципе и касаться деталей реализации конкретных систем.
При работе я исхожу из того, что рассматриваемая система состоит из приложения, базы данных и кэша для данных. Вместо базы данных может использоваться любой другой источник (например, какой-то микросервис или внешний API).
Деление данных между кэширующими серверами
Если вы хотите использовать кэширование в достаточно большой системе, нужно позаботиться о том, чтобы можно было поделить кэшируемые данные между доступными серверами. Это необходимо по нескольким причинам:
- данных может быть очень много, и они физически не поместятся в память одного сервера;
- данные могут запрашиваться очень часто, и один сервер не в состоянии обработать все эти запросы;
- вы хотите сделать кэширование более надёжным. Если у вас только один кэширующий сервер, то при его падении вся система останется без кэша, что может резко увеличить нагрузку на базу данных.
Есть разные алгоритмы для реализации этого. Самый простой — вычисление номера сервера как остатка от целочисленного деления численного представления ключа (например, CRC32) на количество кэширующих серверов:
Такой алгоритм называется хешированием по модулю (англ. modulo hashing). CRC32 здесь использован в качестве примера. Вместо него можно взять любую другую хеширующую функцию, из результатов которой можно получить число, большее или равное количеству серверов, с более-менее равномерно распределённым результатом.
Этот способ легко понять и реализовать, он достаточно равномерно распределяет данные между серверами, но у него есть серьёзный недостаток: при изменении количества серверов (из-за технических проблем или при добавлении новых) значительная часть кэша теряется, поскольку для ключей меняется остаток от деления.
Я написал небольшой скрипт, который продемонстрирует эту проблему.
В нём генерируется 1 млн уникальных ключей, распределённых по пяти серверам с помощью хеширования по модулю и CRC32. Я эмулирую выход из строя одного из серверов и перераспределение данных по четырём оставшимся.
В результате этого «сбоя» примерно 80% ключей изменят своё местоположение, то есть окажутся недоступными для последующего чтения:
Total keys count: 1000000
Shards count range: 4, 5
| ShardsBefore | ShardsAfter | LostKeysPercent | LostKeys |
|---|---|---|---|
| 5 | 4 | 80.03% | 800345 |
Самое неприятное тут то, что 80% — это далеко не предел. С увеличением количества серверов процент потери кэша будет расти и дальше. Единственное исключение — это кратные изменения (с двух до четырёх, с девяти до трёх и т. п.), при которых потери будут меньше обычного, но в любом случае не менее половины от имеющегося кэша:

Я выложил на GitHub скрипт, с помощью которого я собрал данные, а также ipynb-файл, рисующий данную таблицу, и файлы с данными.
Для решения этой проблемы есть другой алгоритм разбивки — согласованное хеширование (англ. consistent hashing). Основная идея этого механизма очень простая: здесь добавляется дополнительное отображение ключей на слоты, количество которых заметно превышает количество серверов (их могут быть тысячи и даже больше). Сами слоты, в свою очередь, каким-то образом распределяются по серверам.
При изменении количества серверов количество слотов не меняется, но меняется распределение слотов между этими серверами:
- если один из серверов выходит из строя, то все слоты, которые к нему относились, распределяются между оставшимися;
- если добавляется новый сервер, то ему передаётся часть слотов от уже имеющихся серверов.

На картинке начального разбиения все слоты одного сервера расположены подряд, но в реальности это не обязательное условие — они могут быть расположены как угодно.
Основное преимущество этого способа перед предыдущим заключается в том, что здесь каждому серверу соответствует не одно значение, а целый диапазон, и при изменении количества серверов между ними перераспределяется гораздо меньшая часть ключей ( k / N , где k — общее количество ключей, а N — количество серверов).
Если вернуться к сценарию, который я использовал для демонстрации недостатка хеширования по модулю, то при той же ситуации с падением одного из пяти серверов (с одинаковым весом) и перераспределением ключей с него между оставшимися мы потерям не 80% кэша, а только 20%. Если считать, что изначально все данные находятся в кэше и все они будут запрошены, то эта разница означает, что при согласованном хешировании мы получим в четыре раза меньше запросов к базе данных.
Код, реализующий этот алгоритм, будет сложнее, чем код предыдущего, поэтому я не буду его приводить в статье. При желании его легко можно найти — на GitHub есть rendezvous hashing), но они гораздо менее распространены.
Вне зависимости от выбранного алгоритма выбор сервера на основе хеша ключа может работать плохо. Обычно в кэше находится не набор однотипных данных, а большое количество разнородных: кэшированные значения занимают разное место в памяти, запрашиваются с разной частотой, имеют разное время генерации, разную частоту обновлений и разное время жизни. При использовании хеширования вы не можете управлять тем, куда именно попадёт ключ, и в результате может получиться «перекос» как в объёме хранимых данных, так и в количестве запросов к ним, из-за чего поведение разных кэширующих серверов будет сильно различаться.
Чтобы решить эту проблему, необходимо «размазать» ключи так, чтобы разнородные данные были распределены между серверами более-менее однородно. Для этого для выбора сервера нужно использовать не ключ, а какой-то другой параметр, к которому нужно будет применить один из описанных подходов. Нельзя сказать, что это будет за параметр, поскольку это зависит от вашей модели данных.
В нашем случае почти все кэшируемые данные относятся к одному пользователю, поэтому мы используем User ID в качестве параметра шардирования данных в кэше. Благодаря этому у нас получается распределить данные более-менее равномерно. Кроме того, мы получаем бонус — возможность использования multi_get для загрузки сразу нескольких разных ключей с информацией о юзере (что мы используем в предзагрузке часто используемых данных для текущего пользователя). Если бы положение каждого ключа определялось динамически, то невозможно было бы использовать multi_get при таком сценарии, так как не было бы гарантии, что все запрашиваемые ключи относятся к одному серверу.
Параллельные запросы на обновление данных
Посмотрите на такой простой кусочек кода:
Что произойдёт при отсутствии запрашиваемых данных в кэше? Судя по коду, должен запуститься механизм, который достанет эти данные. Если код выполняется только в один поток, то всё будет хорошо: данные будут загружены, помещены в кэш и при следующем запросе взяты уже оттуда. А вот при работе в несколько параллельных потоков всё будет иначе: загрузка данных будет происходить не один раз, а несколько.
Выглядеть это будет примерно так:

На момент начала обработки запроса в процессе №2 данных в кэше ещё нет, но они уже читаются из базы данных в процессе №1. В этом примере проблема не такая существенная, ведь запроса всего два, но их может быть гораздо больше.
Количество параллельных загрузок зависит от количества параллельных пользователей и времени, которое требуется на загрузку необходимых данных.
Предположим, у вас есть какой-то функционал, использующий кэш с нагрузкой 200 запросов в секунду. Если на на загрузку данных нужно 50 мс, то за это время вы получите 50 / (1000 / 200) = 10 запросов.
То есть при отсутствии кэша один процесс начнёт загружать данные, и за время загрузки придут ещё девять запросов, которые не увидят данные в кэше и тоже станут их загружать.
Эта проблема называется cache stampede (русского аналога этого термина я не нашёл, дословно это можно перевести как «паническое бегство кэша», и картинка в начале статьи показывает пример этого действия в дикой природе), hit miss storm («шторм непопаданий в кэш») или dog-pile effect («эффект собачьей стаи»). Есть несколько способов её решения:
Блокировка перед началом выполнения операции пересчёта/ загрузки данных
Суть этого метода состоит в том, что при отсутствии данных в кэше процесс, который хочет их загрузить, должен захватить лок, который не даст сделать то же самое другим параллельно выполняющимся процессам. В случае memcached простейший способ блокировки — добавление ключа в тот же кэширующий сервер, в котором должны храниться сами закэшированные данные.
При этом варианте данные обновляются только в одном процессе, но нужно решить, что делать с процессами, которые попали в ситуацию с отсутствующим кэшем, но не смогли получить блокировку. Они могут отдавать ошибку или какое-то значение по умолчанию, ждать какое-то время, после чего пытаться получить данные ещё раз.
Кроме того, нужно тщательно выбирать время самой блокировки — его гарантированно должно хватить на то, чтобы загрузить данные из источника и положить в кэш. Если не хватит, то повторную загрузку данных может начать другой параллельный процесс. С другой стороны, если этот временной промежуток будет слишком большим и процесс, получивший блокировку, умрёт, не записав данные в кэш и не освободив блокировку, то другие процессы также не смогут получить эти данные до окончания времени блокировки.
Вынос обновлений в фон
Основная идея этого способа — разделение по разным процессам чтения данных из кэша и записи в него. В онлайн-процессах происходит только чтение данных из кэша, но не их загрузка, которая идёт только в отдельном фоновом процессе. Данный вариант делает невозможными параллельные обновления данных.
Этот способ требует дополнительных «расходов» на создание и мониторинг отдельного скрипта, пишущего данные в кэш, и синхронизации времени жизни записанного кэша и времени следующего запуска обновляющего его скрипта.
Этот вариант мы в Badoo используем, например, для счётчика общего количества пользователей, про который ещё пойдёт речь дальше.
Вероятностные методы обновления
Суть этих методов заключается в том, что данные в кэше обновляются не только при отсутствии, но и с какой-то вероятностью при их наличии. Это позволит обновлять их до того, как закэшированные данные «протухнут» и потребуются сразу всем процессам.
Для корректной работы такого механизма нужно, чтобы в начале срока жизни закэшированных данных вероятность пересчёта была небольшой, но постепенно увеличивалась. Добиться этого можно с помощью алгоритма XFetch, который использует экспоненциальное распределение. Его реализация выглядит примерно так:
В данном примере $ttl — это время жизни значения в кэше, $delta — время, которое потребовалось для генерации кэшируемого значения, $expiry — время, до которого значение в кэше будет валидным, $beta — параметр настройки алгоритма, изменяя который, можно влиять на вероятность пересчёта (чем он больше, тем более вероятен пересчёт при каждом запросе). Подробное описание этого алгоритма можно прочитать в white paper «Optimal Probabilistic Cache Stampede Prevention», ссылку на который вы найдёте в конце этого раздела.
Нужно понимать, что при использовании подобных вероятностных механизмов вы не исключаете параллельные обновления, а только снижаете их вероятность. Чтобы исключить их, можно «скрестить» несколько способов сразу (например, добавив блокировку перед обновлением).
«Холодный» старт и «прогревание» кэша
Нужно отметить, что проблема массового обновления данных из-за их отсутствия в кэше может быть вызвана не только большим количеством обновлений одного и того же ключа, но и большим количеством одновременных обновлений разных ключей. Например, такое может произойти, когда вы выкатываете новый «популярный» функционал с применением кэширования и фиксированным сроком жизни кэша.
В этом случае сразу после выкатки данные начнут загружаться (первое проявление проблемы), после чего попадут в кэш — и какое-то время всё будет хорошо, а после истечения срока жизни кэша все данные снова начнут загружаться и создавать повышенную нагрузку на базу данных.
От такой проблемы нельзя полностью избавиться, но можно «размазать» загрузки данных по времени, исключив тем самым резкое количество параллельных запросов к базе. Добиться этого можно несколькими способами:
- плавным включением нового функционала. Для этого необходим механизм, который позволит это сделать. Простейший вариант реализации — выкатывать новый функционал включённым на небольшую часть пользователей и постепенно её увеличивать. При таком сценарии не должно быть сразу большого вала обновлений, так как сначала функционал будет доступен только части пользователей, а по мере её увеличения кэш уже будет «прогрет».
- разным временем жизни разных элементов набора данных. Данный механизм можно использовать, только если система в состоянии выдержать пик, который наступит при выкатке всего функционала. Его особенность заключается в том, что при записи данных в кэш у каждого элемента будет своё время жизни, и благодаря этому вал обновлений сгладится гораздо быстрее за счёт распределения последующих обновления во времени. Простейший способ реализовать такой механизм — умножить время жизни кэша на какой-то случайный множитель:
Если по какой-то причине не хочется использовать случайное число, можно заменить его псевдослучайным значением, полученным с помощью хеш-функции на базе каких-нибудь данных (например, User ID).
Пример
Я написал небольшой скрипт, который эмулирует ситуацию «непрогретого» кэша.
В нём я воспроизвожу ситуацию, при которой пользователь при запросе загружает данные о себе (если их нет в кэше). Конечно, пример синтетический, но даже на нём можно увидеть разницу в поведении системы.
Вот как выглядит график количества hit miss-ов в ситуации с фиксированным (fixed_cache_misses_count) и различным (random_cache_misses_count) сроками жизни кэша:

Видно, что в начале работы в обоих случаях пики нагрузки очень заметны, но при использовании псевдослучайного времени жизни они сглаживаются гораздо быстрее.
«Горячие» ключи
Данные в кэше разнородные, некоторые из них могут запрашиваться очень часто. В этом случае проблемы могут создавать даже не параллельные обновления, а само количество чтений. Примером подобного ключа у нас является счётчик общего количества пользователей:

Этот счётчик — один из самых популярных ключей, и при использовании обычного подхода все запросы к нему будут идти на один сервер (поскольку это всего один ключ, а не множество однотипных), поведение которого может измениться и замедлить работу с другими ключами, хранящимися там же.

Чтобы решить эту проблему, нужно писать данные не в один кэширующий сервер, а сразу в несколько. В этом случае мы кратно снизим количество чтений этого ключа, но усложним его обновления и код выбора сервера — ведь нам нужно будет использовать отдельный механизм.
Мы в Badoo решаем эту проблему тем, что пишем данные во все кэширующие серверы сразу. Благодаря этому при чтении мы можем использовать общий механизм выбора сервера — в коде можно использовать обычный механизм шардирования по User ID, и при чтении не нужно ничего знать про специфику этого «горячего» ключа. В нашем случае это работает, поскольку у нас сравнительно немного серверов (примерно десять на площадку).
Если бы кэширующих серверов было намного больше, то этот способ мог бы быть не самым удобным — просто нет смысла дублировать сотни раз одни и те же данные. В таком случае можно было бы дублировать ключ не на все серверы, а только на их часть, но такой вариант требует чуть больше усилий.
Если вы используете определение сервера по ключу кэша, то можно добавить к нему ограниченное количество псевдослучайных значений (сделав из total_users_count что-то вроде t otal_users_count_1 , total_users_count_2 и т. д.). Подобный подход используется, например, в Etsy.
Если вы используете явные указания параметра шардирования, то просто передавайте туда разные псевдослучайные значения.
Главная проблема с обоими способами — убедиться, что разные значения действительно попадают на разные кэширующие серверы.
Сбои в работе
Система не может быть надёжной на 100%, поэтому нужно предусмотреть, как она будет вести себя при сбоях. Сбои могут быть как в работе самого кэша, так и в работе базы данных.
При сбоях в работе базы данных и отсутствии кэша мы можем попасть в ситуацию cache stampede, про которую я тоже уже рассказывал раньше. Выйти из неё можно уже описанными способами, а можно записать в кэш заведомо некорректное значение с небольшим сроком жизни. В этом случае система сможет определить, что источник недоступен, и на какое-то время перестанет пытаться запрашивать данные.

![]()
skype: live:di-sem

@programmist_1C
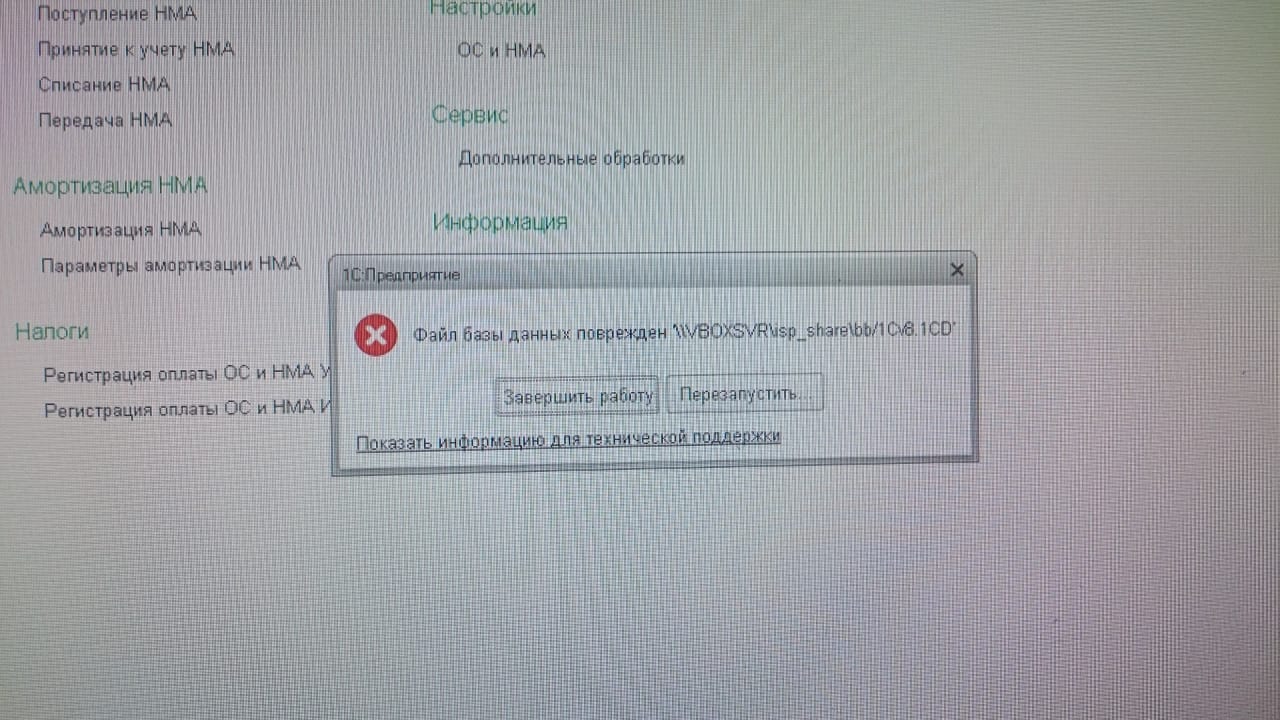
Перед тем как начать исправлять базу обязательно сделайте резервную копию!
1. Через конфигуратор
Тестирование и исправление информационной базы в 1С 8.2 и 8.3.
Нужно войти в конфигуратор администрирование - тестирование и исправление.
2. Утилита chdbfl.exe
Если в конфигуратор войти нет возможности можно воспользоваться утилитой chdbfl.exe. Ее скачивать не нужно, она находится в папке, где установлена 1С.
Например в C:\Program Files (x86)\1cv8\8.3.10.2561\bin\chdbfl.exe , где 8.3.10.2561 - номер релиза платформы.
У меня утилита chdbfl.exe находится тут
Нужно ее запустить, выбрать файл 1Cv8.1CD в папке базы 1с, поставить галочку "Исправлять обнаруженные ошибки" и запустить.
3. Очистить кэш (более подробно смотреть тут) .
Бывают такие глюки\сбои которые очень хорошо исправляются очисткой кэша.
Например один пользователь входит в базу 1с и работает без проблем, а другой или войти не может или при входе у него куча ошибок и т.п.
Способ очень простой.
Нужно подключиться к компьютеру этого пользователя, запустить 1с чтобы появился список баз.
И сделать так:
1 Выбрать в списке нужную базу
2 Удалить ее из списка, сама база не удалится. Главное запомните или запишите где она лежит.
3 Заново ее пропишите.
Сейчас у одного из моих клиентов ситуация в которой не помог ни один из этих способов.
Клиент новый, поэтому я еще не до конца разобрался как у него все устроено.
База файловая, находится на вирт машине, 1с без сервера запускается с другой вирт. машины.
Возможно 1с просто не хватает ресурсов.
Базу скачал себе, запущу и попробую поработать в ней, если ошибка не появится, то проблема точно не в 1с, а в системном администрировании.
Тогда буду перенастраивать.
Скачал базу себе, тестировал ее весь день - ни одной ошибки.
Узнал что ресурсов на компьютере клиента достаточно.
Решено. Проблема была в платформе.
Переустановка платформы и удаление старых версий полностью решило проблему. :)

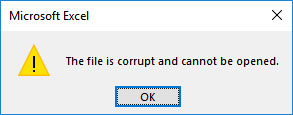
Иногда вы можете столкнуться с ошибками при открытии некоторых файлов, таких как «The file». .docx "не удается открыть из-за проблемы с содержимым. Файл поврежден и не может быть открыт". Эта ошибка означает, что в файле есть нечитаемое содержимое, поэтому файл нельзя открыть.

1. Что такое испорченный файл?
Как следует из названия, поврежденные файлы - это компьютерные файлы, которые внезапно перестают работать или становятся непригодными для использования.
Фактически, каждый файл в вашей системе имеет определенную структуру и содержание. Таким образом, если нужная информация находится в правой части файлов, она будет работать хорошо. Но если в файл записана неверная информация или в неправильном месте записана правильная информация, данные будут искажены и зашифрованы, что приведет к повреждению файла.
2. Причины испорченного файла
Независимо от того, что не так, есть причина для этого. Смотрите ниже и узнайте причины поврежденного файла.
- Ваши файлы повреждены при сохранении. Например, ваш компьютер теряет питание или падает при сохранении файлов, файлы могут быть повреждены.
- Плохие сектора на жестком диске или других устройствах хранения.
- Вирус и вредоносное ПО на жестком диске или других устройствах хранения.
- Неожиданное завершение работы или плохое обновление на вашем компьютере
3. Как открыть и восстановить поврежденные файлы
Метод 1: изменить формат файла
Иногда это может помочь изменить формат файла. Возможно, файл не удастся открыть в исходной форме, но вы, по крайней мере, должны иметь доступ к содержимому файла. Например, вы можете конвертировать документы Microsoft Word в формат PDF или изображения из формата PNG в JPG.
Метод 2: использовать другую программу
Один формат файла может быть открыт многими программами, как встроенными, так и сторонними. Кроме того, каждая программа имеет собственный алгоритм и требования для открытия файла. Ваша текущая программа не может открыть файл, но альтернативная программа может открыть его. Например, документ Word также можно открыть с помощью альтернативных программ, таких как WPS и даже Google Docs.
Метод 3: использовать опцию открытия и восстановления
Возможно, не все знают, что у офисного программного обеспечения Microsoft есть полезная функция, когда мы хотим открыть новый документ. Функция открытия и восстановления может помочь нам восстановить поврежденные файлы при открытии
Поэтому, когда мы открываем поврежденный файл, мы можем использовать функцию открытия и восстановления, когда открываем его.
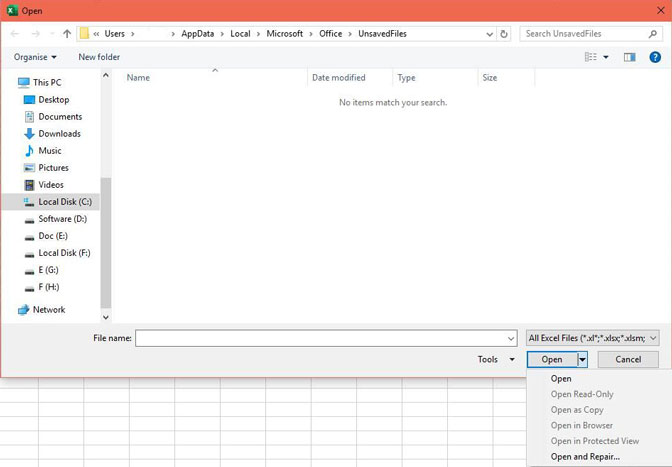
Использовать эту функцию очень просто, просто нужно выбрать опцию раскрывающегося списка при открытии файла. Ниже я открою испорченный файл Excel в качестве примера, чтобы показать вам, как использовать эту функцию.
Шаг 1 Откройте Microsoft Excel, затем щелкните файл и выберите «Открыть».
Шаг 2 В открывшемся окне выберите файл, который хотите открыть.
Шаг 3 Нажмите на кнопку Открыть в правом нижнем углу окна, и появится раскрывающееся окно. Выберите опцию открытия и восстановления в раскрывающемся списке.
4. Как восстановить поврежденные файлы
Чтобы восстановить удаленный или потерянный поврежденный файл, FoneLab Data Retriever лучший выбор
Причины, по которым мы выбираем FoneLab
- Восстановить все типы данных, такие как документ, e-mail, аудио, видео, И т.д.
- Очень совместим с вашим компьютер, карты памяти, Флэш-накопитель, цифровой фотоаппарат, жесткий диски другие съемные диски.
- Применить ко всем ситуациям потери данных, таким как вирусная атака, неожиданно вылетает, образование, удаление и т.д.
- Scan, search и предварительный просмотр любой тип данных и жесткий диск с подробной информацией.
- Гарантия безопасности данных, Когда вы восстанавливаете потерянные данные, он не сохраняет эти данные на своем сервере.
- Легко использовать, С помощью нескольких щелчков мыши вы можете легко восстановить потерянные данные.
- Просто нажмите на ссылку ниже, вы можете бесплатно загрузить это программное обеспечение и получить бесплатную пробную версию 30.
FoneLab Data Retriever - восстанавливайте потерянные / удаленные данные с компьютера, жесткого диска, флэш-накопителя, карты памяти, цифровой камеры и многого другого.
- Восстановление фотографий, видео, документов и других данных с легкостью.
- Предварительный просмотр данных перед восстановлением.
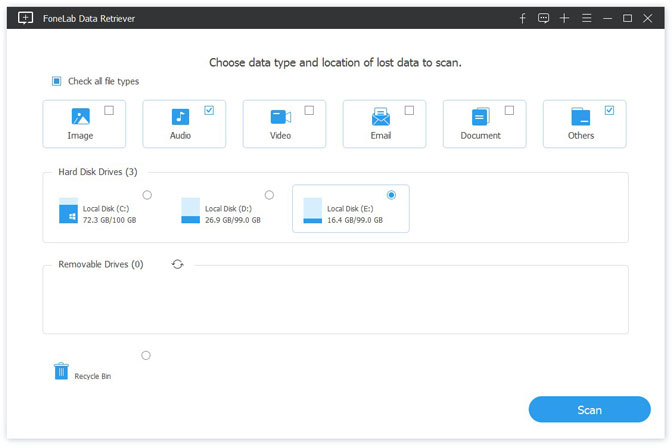
Шаг 2 В главном интерфейсе выберите типы файлов, которые вы хотите восстановить, и жесткий диск, на котором хранятся удаленные поврежденные файлы. Затем нажмите Scan Кнопка, чтобы начать быстрое сканирование на выбранном диске.
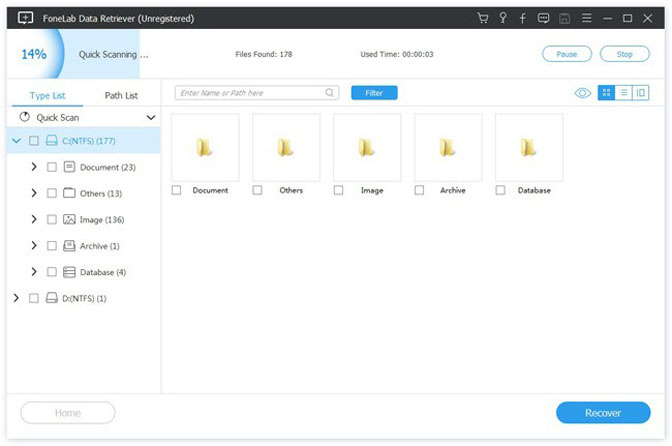
Шаг 3 Просмотрите файлы, отображаемые в окне, и найдите файлы, которые вы собираетесь восстановить. Отметьте файлы, которые вы хотите получить, а затем нажмите Recover Кнопка, чтобы сохранить выбранные файлы на ваш компьютер.
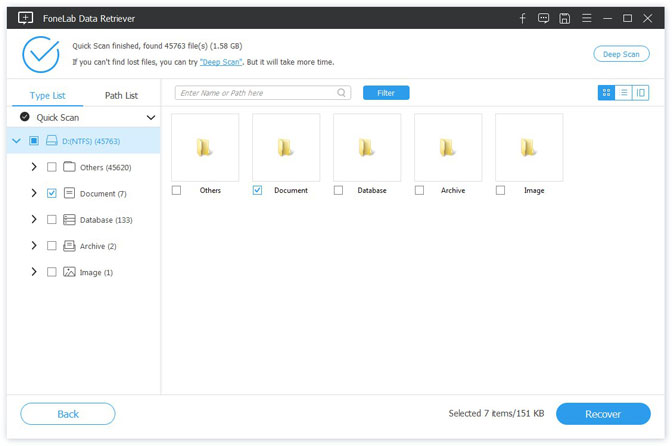
- Если быстрое сканирование не может дать желаемых результатов, вы можете нажать Deep Scan, чтобы повторить попытку. Глубокий анализ требуется больше времени для завершения всего процесса, но это приносит больше результатов.
- Вы также можете использовать Фильтр функция, чтобы быстро найти нужные файлы.
Заключение
Если у вас есть предложения или комментарии по поводу восстановления поврежденного файла, сообщите нам об этом в комментариях ниже.
FoneLab Data Retriever - восстанавливайте потерянные / удаленные данные с компьютера, жесткого диска, флэш-накопителя, карты памяти, цифровой камеры и многого другого.
Читайте также: