
Чем pci отличается от isa
В «войне шин» участвовали стандарты ISA, MCA, EISA, VLB и PCI. Она началась в тот момент, когда стало ясно, что возможности ISA вот-вот будут исчерпаны, и вылилась в противоборство IBM, с одной стороны, и производителей клонов ПК — с другой. Корпорация IBM предлагала шину MCA, стремясь к восстановлению утерянной монополии на архитектуру ПК, а в противовес ей производители клонов и чипсетов продвигали свой проект EISA. Однако вмешательство Microsoft и Intel привело к выбору нейтрального варианта — шины PCI; с ней мы и живем последние годы.
№ 30, 1997: PCI приходит на смену ISA
«Поставщики полупроводников представили шлюзовые микропроцессоры типа PCI-PCI, позволяющие производителям ПК обеспечивать столько же гнезд расширения PCI, сколько сейчас предусмотрено для шины ISA. Корпорации Microsoft и Intel настаивают на поэтапном прекращении использования доживающей свой век в персональных компьютерах, производство которых запланировано на 1998 год, шины ISA. Представитель Microsoft сообщил, что при сертификации для Windows 98 с 1 января 1998 года компания будет настаивать на том, чтобы каждый ПК соответствовал этим стандартам».
Конкурирующая с MCA шина Extended Industry Standard Architecture (EISA) была разработана оппозиционными IBM производителями клонов ПК в 1988 году. Это была 32-разрядная шина, в отличие от MCA она поддерживала старые платы стандартов XT и ISA. Шина получилась удачной, и в некоторых своих моделях IBM использовала ее. Еще одна шина, VESA Local Bus (VLB), оказалась не столь популярной из-за ее слишком сильной привязки к процессору 80486. С появлением процессоров Pentium ее применение сошло на нет.
Peripheral Component Interconnect (PCI) — детище Intel. Ее разработка началась в 1990 году. Спустя два года была опубликована спецификация PCI 1.0, а еще через год появилась PCI 2.0. Новый стандарт очень быстро распространился на серверы, заменив собой и MCA, и EISA. Напротив, в производстве персональных компьютеров процесс замены шин развивался не столь стремительно, к моменту появления PCI в персональных компьютерах уже нашли применение VLB и EISA, поэтому он затянулся вплоть до 2000 года. На общем фоне компания Apple действовала энергичнее других, в 1995 году переведя на PCI компьютеры Power Macintosh (ранее в них использовалась собственная шина NuBus), а потом и все остальные модели.
Успеху PCI способствовал реализованный в этой шине принцип самонастраиваемости (plug-and-play). Упрощенно его можно представить так: при подключении нового устройства системное программное обеспечение анализирует его конфигурационную область и без вмешательства пользователя резервирует необходимые ресурсы. Благодаря этому прерыванию необходимые для работы устройства настраиваются автоматически, без установки перемычек, как того требовала шина ISA.
В конечном итоге война шин закончилась «вничью». PCI была принята в качестве всеобщего стандарта. Но ничто не вечно, все развивается, в своем оригинальном виде PCI не осталась. Сначала частота шины была повышена с 33 до 66 МГц, а затем появилась версия PCI-X, работающая на частоте 133 МГц. Дальнейшим шагом на пути эволюционного развития стандарта PCI стали версии PCI-X 2.0 (266 и 533 МГц). Революционный скачок произошел в 2004 году, когда был разработан стандарт PCI Express. В нем параллельные соединения 32- и 64-разрядной шины, принятые в предшествующих версиях, были заменены последовательными соединениями (например, Serial ATA и Serial Attached SCSI). И, похоже, по своему потенциалу новая технология шины обеспечивает запас скорости передачи, достаточный еще на одно десятилетие. Скорее всего, через несколько лет она окончательно заменит PCI и PCI-X, как те в свое время заменили собственных предшественников.
Из подшивок Computerworld
Российские Internet-провайдеры
Павел Храмцов, № 30, 1996
В конце прошлого года число фирм, предоставляющих услуги доступа к информационным ресурсам Internet, в нашей стране едва превышало десяток.
При этом спектр услуг был достаточно однотипным (электронная почта, терминал и, как исключение, IP). Объявленный SovamTeleport проект «Россия-Он-Лайн» вызвал широкий резонанс — по сути, впервые было заявлено о создании настоящей информационной службы, построенной на основе технологии IP. Прошло всего полгода, и ситуация в корне изменилась.
FTC отказалась проверять Microsoft
Боб Тротт, № 30, 1997
Федеральная торговая комиссия США направила в конгресс письмо за подписью руководителя FTC Роберта Питовски, в котором говорится, что просьба конгрессменов о расследовании деятельности Microsoft на предмет нарушения антимонопольного законодательства отклонена.
Четверо сенаторов потребовали вмешательства FTC, поскольку их не устраивают темпы расследования, проводимого Министерством юстиции.
СОРМ в избе
Валерий Коржов, № 30, 1998
Как вы отреагируете, если к вам придут люди в черном и установят у вас в спальне видеокамеру, причем попросят вас же и заплатить за установку? Ответ очевиден. А если вы провайдер и от навязанного вам «черного ящика» зависит возможность получить лицензию? . Обсуждаются «Общие технические требования к системе технических средств по обеспечению оперативно-розыскных мероприятий при предоставлении услуг передачи данных и телематических служб», сокращенно — СТС СОРМ ПД и ТС. Этот документ необходим функционерам ФСБ для разработки частных технических требований по конкретным провайдерам. Однако, получив широкую огласку, он вызвал у общественности Сети много вопросов — юридических, технических и финансовых.
Как разорвать порочный круг?
Пол Страссман, №30, 1999
Минувшие 50 лет компьютерной эры характеризуются не только фантастическим взрывом новых возможностей, но и увеличением объема дорогостоящего программного «мусора».
Вся история ВТ — это история непрерывной эволюции, которая требует постоянно растущих капиталовложений и состоит из повторяющихся циклов рождения нового и отмирания старого.
Первые PDA: надежды и разочарования
Мэри Брандел, №30, 2000
Компьютерная отрасль не всегда благосклонна к первопроходцам. Устройства, которые по-английски называются персональными цифровыми помощниками, были встречены более чем прохладно, и неизвестно, какая судьба ожидала бы эти теперь столь популярные машинки, и не превратились бы они в электронные органайзеры типа продуктов компании Psion.
По иронии судьбы компании-прародительнице PDA собственная инновация не принесла тех баснословных прибылей, которые получают сейчас производители этих устройств. Apple Computer, первой в 1993 году предложившая устройство такого типа, потерпела сокрушительное фиаско с его «потомком» — Newton MessagePad.
В период между 1993 и 1996 годами многие компании с переменным успехом выходили на рынок со своими карманными компьютерами. В конце концов определился и почти единоличный лидер — компания Palm Computing, образованная на базе корпорации 3Com.
Borland собирает профессионалов
Леонид Черняк, № 30, 2001
Жидкий свет
Группа испанских ученых провела методом компьютерного моделирования исследование, показавшее, что при определенных условиях свет можно расщепить на частички, которые ведут себя во многом подобно каплям воды. Исследователи уверены, что обнаруженный эффект даст ключ к созданию средств управления потоком фотонов в оптическом контуре, а следовательно, будет использоваться в вычислительных системах новых поколений. При этом «капли» могут стать кандидатами на роль бит информации.
«Apple следовало выбрать нас»
Старший вице-президент и директор по технологиям Intel Пат Гелсингер в интервью Edmonton Journal заявил, что, по его мнению, Apple Computer для своей новой системы G5 следовало выбрать процессоры производства Intel, а не IBM. «Мне кажется, Стив Джобс на протяжении всех 20 лет ошибался в выборе процессора, а теперь вот добавил к ним еще несколько лет, — сказал Гелсингер. — Процессоры Intel помогли бы Apple найти способы открыть для себя новые приложения, расширить ассортимент продуктов».
Дмитрий Желвицкий, № 30, 2004
В мае Intel заключила соглашение с компаниями «Эльбрус МЦСТ» и «Уни Про», по которому их сотрудники будут зачислены в штат корпорации.
Как теперь сложится сотрудничество МЦСТ и Sun, которое планировалось активно развивать, непонятно; в компаниях комментариев не дают.
С момента появления домашних компьютеров существует возможность расширять их функционал путём установки большего количества RAM, более ёмких накопителей, дополнительных комплектующих. Но только с появлением IBM PC привычной стала идея о полностью открытой модульной компьютерной системе. А именно, концепция карт расширения позволила пользователям компьютеров не зависеть от конфигураций систем, предлагаемых производителями. Подобные конфигурации можно было, в ограниченных пределах, расширять комплектующими, рассчитанными исключительно на эти системы. Благодаря универсальным картам расширения появились целые отрасли промышленности, они стали и причиной возникновения большого рынка любительских устройств, которые можно было подключать к компьютерам.

Такая открытость ISA означала то, что можно было достаточно легко и дёшево создавать собственные ISA-карты. То же касалось и шины PCI, которая появилась после ISA и была такой же открытой. В результате до сих пор существует полная жизни экосистема, в которой есть место и любительским звуковым картам, рассчитанным на слоты PCI или ISA, и картам расширения, позволяющим оснастить IBM PC 1981-го года поддержкой USB, и много чему ещё.
С чего начать тому, кто в наши дни хочет заняться работой с ISA- и PCI-картами?
Цена простоты

По мере того, как разработчики клонов PC использовали в своих моделях компьютеров всё более быстрые процессоры, частота шины AT, в итоге, пришла к значениям, находящимся где-то между 10 и 16 МГц. Это, понятно, привело к тому, что многие существующие AT-карты (ISA) работали в подобных системах неправильно. Через некоторое время большинство производителей оборудования сделало так, чтобы частота шины не была бы напрямую связана с частотой процессора. Но несмотря на то, что в названии шины ISA есть намёк на нечто стандартизированное, настоящего стандарта этой шины не существовало.
Правда, была попытка стандартизировать замену ISA, получившую название Extended ISA (EISA). Эта 32-битная шина, работавшая на частоте 8,33 МГц, была создана в 1988 году. Хотя на рынке домашних компьютеров она и не «взлетела», некоторым вниманием она пользовалась среди пользователей серверного оборудования, особенно — как более дешёвая альтернатива собственной шине IBM Micro Channel architecture (MCA). Компания IBM задумывала эту шину в качестве замены ISA.
В итоге же шина ISA дожила до наших дней, сохранившись, в основном, в промышленном оборудовании и во встраиваемых системах (например, в виде шины LPC), в то время как в других сферах был сначала осуществлён переход на PCI, а позже — на PCIe. А вот интерфейсы для подключения видеокарт к компьютерам шли своим путём. Речь идёт о шинах VESA Local Bus (VLB) и Accelerated Graphics Port (AGP), которые представляют собой специализированные интерфейсы, нацеленные на нужды GPU.
Начало работы с новыми старыми технологиями
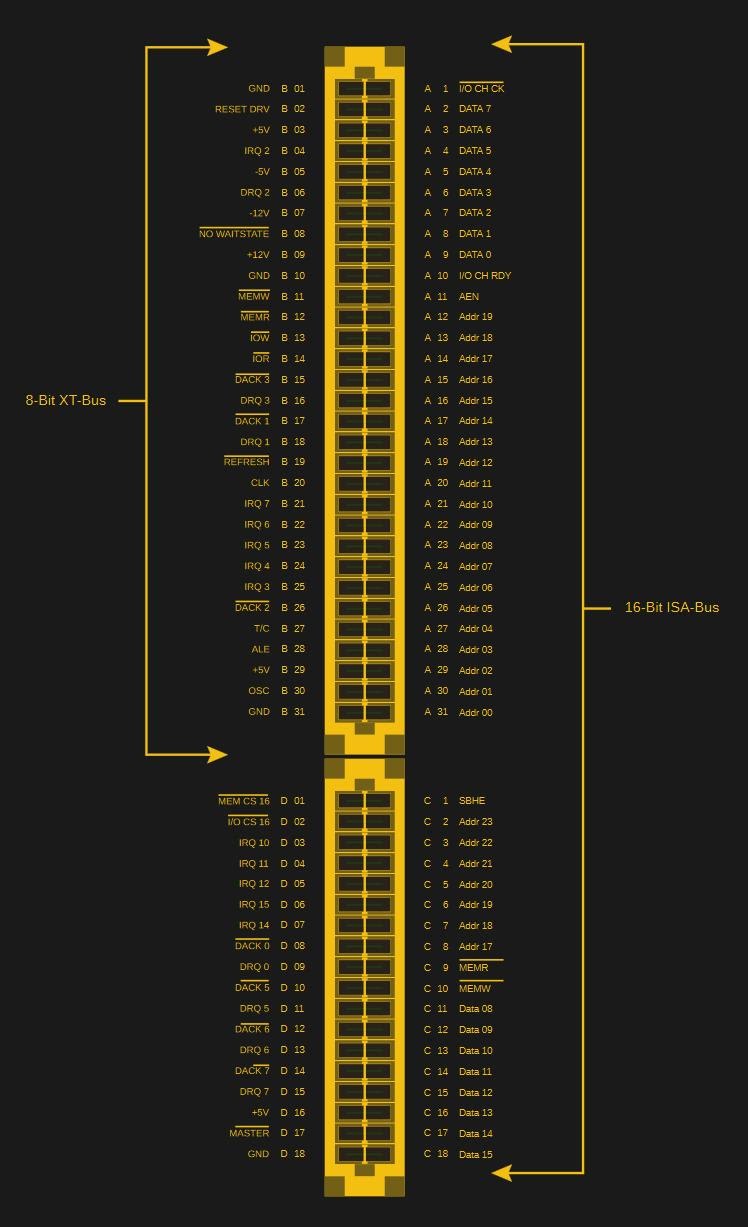
При разработке устройств для ISA и PCI физический интерфейс тоже особых проблем не доставляет, так как и в том и в другом случаях используются контакты, расположенные на ребре платы. Именно такой вариант расположения контактов на платах, актуальный до наших дней, был выбран, преимущественно, из-за его дешевизны и надёжности. На плате расширения нет какого-то физического коннектора. Там, на краю, находятся лишь контактные площадки, которые позволяют подключить плату к слоту. При проектировании подобных плат, правда, надо обращать внимание на их толщину, так как от неё зависит надёжность контакта. Обычно хорошо показывает себя толщина платы в 1,6 мм.
Если кто-то хочет самостоятельно создать ISA или PCI-плату — в интернете можно найти параметры контактов для таких плат. Например — этот отличный обзор. Тут, в частности, есть сведения о расстоянии между контактными площадками, о форме платы в том месте, где находятся контакты, о размерах контактных площадок и о других параметрах плат и контактов.
При проектировании электрических цепей плат стоит знать о том, что ISA использует напряжение в 5 В, а PCI может использовать 5 В, 3,3 В, или и то и другое. В случае с PCI платы различают, используя выступы в PCI-слотах и выемки на картах (ключи). Так, если в слоте имеется один выступ, расположенный на расстоянии 56,21 мм от той его стороны, на котором находятся разъёмы подключаемой к нему карты, то это будет слот, рассчитанный на карты, поддерживающие напряжение 3,3 В. Выступ, расположенный на расстоянии 104,77 мм от края слота, указывает на слот для 5 В-карт. На краях карт есть соответствующие выемки. Если карта поддерживает и 5, и 3,3 В — то на ней будет две выемки (это — так называемые универсальные карты).
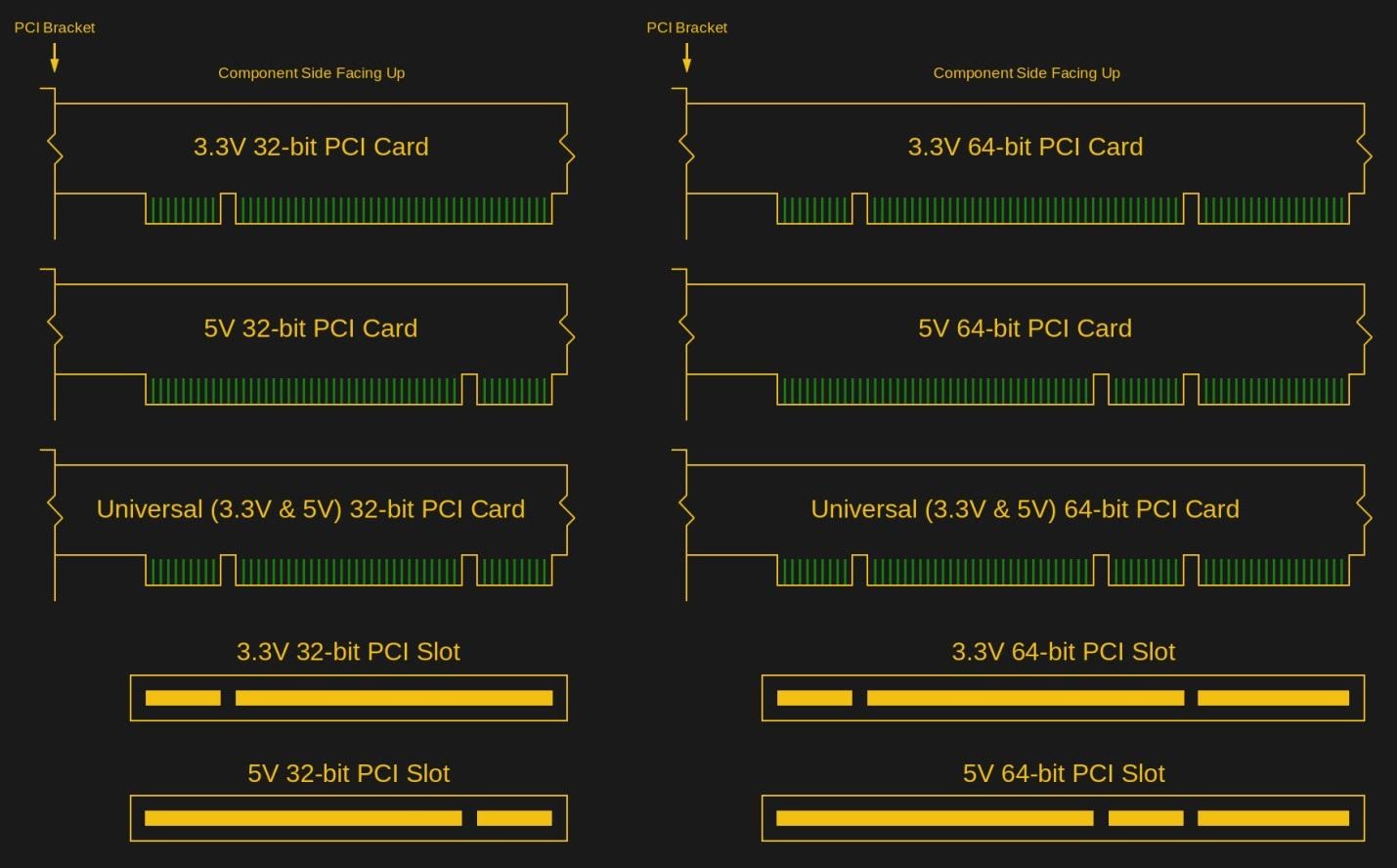
Ключи на PCI-картах и разъёмах
Существуют 32-битные и 64-битные варианты PCI. Причём, всеобщий интерес на рынке домашних компьютеров вызвал именно первый вариант шины. Если говорить о развитии PCI, то можно отметить интерфейс PCI-X. Эта шина, в 64-битном варианте, в основном, применялась в серверных системах. В PCI-X удвоена максимальная частота шины (с 66 до 133 МГц) и убрана поддержка 5 В. Поэтому PCI-X-карты часто работают при их установке в слоты PCI, рассчитанные на 3,3 В (то же самое справедливо и для PCI-карт, устанавливаемых в слоты PCI-X). 64-битная карта, и PCI, и PCI-X, может перейти в 32-битный режим в том случае, если она установлена в более короткий, 32-битный слот.
Работа с шинами
Каждое устройство, подключённое к шине, увеличивает нагрузку на неё. Кроме того, если речь идёт о шинах с общими линиями связи, важно, чтобы отдельные устройства могли бы отключаться от этих линий в то время, когда они эти линии не используют. Обычно для реализации такой схемы работы используется буферный элемент с тремя состояниями. Например — такой, как распространённый 74LS244.
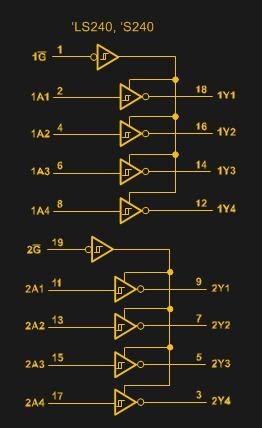
Логическая схема 74LS244
74LS244 может не только обеспечивать изоляцию, что умеют и стандартные цифровые буферы. Этот элемент может переключаться в высокоимпедансное состояние (Hi-Z), что равносильно отключению устройства.
В случае с ISA-картами нам, для организации правильного взаимодействия с шиной, нужно нечто вроде 74LS244 или его двунаправленного варианта 74LS245. У каждой сигнальной линии должен быть буфер или «защёлка». Подробнее об этом можно почитать здесь. А тут описан хороший пример современной ISA-карты, называемой Snark Barker и представляющей собой клон SoundBlaster.
PCI-карты, по идее, тоже можно создавать, используя подобный подход, но обычно в коммерческих PCI-картах используют специализированные интегральные схемы для ускорения ввода-вывода, которые предоставляют компонентам карт простой интерфейс, похожий на ISA. Подобные решения в наши дни, правда, нельзя назвать дешёвыми (если только не рисковать, связываясь с чем-то вроде WCH CH365). Поэтому хорошей альтернативой подобным решениям является реализация PCI-контроллера на базе FPGA. MCA-версия вышеупомянутой карты Snark Barker использует для взаимодействия с шиной MCA CPLD. На сайтах вроде OpenCores имеются проекты, ориентированные на PCI, которые можно использовать в качестве отправной точки для собственных разработок.
Обмен данными с шинами ISA и PCI
После создания новенькой платы с золотыми контактами, и после того, как на ней распаяны буферные элементы или FPGA, нужно ещё и иметь возможность обмениваться данными с шиной ISA или PCI, пользуясь соответствующим протоколом. К счастью, существует множество материалов по ISA, например — этот. А вот протокол PCI, вроде протокола PCIe, это — «коммерческая тайна». В результате соответствующие данные можно официально (и небесплатно) достать лишь на сайте PCI-SIG. Правда, спецификации, всё же, «утекли» в общий доступ.
Как и в случае с любой другой общей шиной, схема взаимодействия с шиной при записи или чтении данных предусматривает запрос доступа к шине у «хозяина шины» или, в случае с шиной PCI с несколькими «хозяевами», использование процедуры арбитража. К карте расширения, кроме того, можно обращаться напрямую (вот материал об этом, в котором речь идёт об ISA). В Linux это подразумевает использование программ ядра ( sys/io.h ). Сначала получают соответствующие разрешения, а потом уже можно отправлять данные в конкретный IO-порт, соответствующий карте. В целом это выглядит так:
В случае с ISA адрес IO-порта задаётся в самой плате, а для распознавания адреса используется декодер, находящийся на линиях адресного сигнала. Часто на платах для выбора адреса, а так же — линий IRQ и DMA использовались переключатели или перемычки. Технология ISA PnP была призвана улучшить этот процесс, но по факту принесла больше вреда, чем пользы. В случае с PCI технология PnP является частью стандарта. Шина PCI осуществляет поиск устройств при загрузке, а встроенная ROM (BIOS) запрашивает у карт сведения об их нуждах, после чего адреса и другие параметры задаются автоматически.
Итоги
Правда, шины ISA и PCI хороши тем, что они доступны даже любителям. Скорости этих шин, если нужно отлаживать или анализировать платы, вполне укладываются в возможности любительского аппаратного обеспечения и соответствующих осциллографов. Использование достаточно медленных параллельных шин данных означает, что дифференциальные сигналы тут не применяются, а это облегчает трассировку плат.
Хотя те старые шины, о которых мы говорили, не являются игроками той же лиги, что и шина PCIe, их возможности и их широкая доступность означают, что они могут дать старым компьютерам второй шанс. Даже если речь идёт о чём-то очень простом, вроде накопителя, основанного на флэш-памяти, предназначенного для первого IBM PC.
Среди наиболее динамично развивающихся областей компьютерной техники стоит отметить сферу технологий передачи данных: в отличие от сферы вычислений, где наблюдается продолжительное и устойчивое развитие параллельных архитектур, в «шинной» 1 сфере, как среди внутренних, так и среди периферийных шин, наблюдается тенденция перехода от синхронных параллельных шин к высокочастотным последовательным. (Заметьте, «последовательные» – не обязательно значит «однобитные», здесь возможны и 2, и 8, и 32 бит ширины при сохранении присущей последовательным шинам пакетной передачи данных, то есть в пакете импульсов данные, адрес, CRC и другая служебная информация разделены на логическом уровне 2 ).
1 Компьютерная шина (магистраль передачи данных между отдельными функциональными блоками компьютера) – совокупность сигнальных линий, объединённых по их назначению (данные, адреса, управление), которые имеют определённые электрические характеристики и протоколы передачи информации. Шины отличаются разрядностью, способом передачи сигнала (последовательные или параллельные), пропускной способностью, количеством и типами поддерживаемых устройств, протоколом работы, назначением (внутренняя, интерфейсная).
Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени), а также могут использовать мультиплексирование (передачу адреса и данных по одним и тем же линиям) и различные схемы арбитража (то есть способа совместного использования шины несколькими устройствами).
2 Основным отличием параллельных шин от последовательных является сам способ передачи данных. В параллельных шинах понятие «ширина шины» соответствует её разрядности – количеству сигнальных линий, или, другими словами, количеству одновременно передаваемых («выставляемых на шину») битов информации. Сигналом для старта и завершения цикла приёма/передачи данных служит внешний синхросигнал. В последовательных же каналах передачи используется одна сигнальная линия (возможно использование двух отдельных каналов для разделения потоков приёма-передачи). Соответственно, информационные биты здесь передаются последовательно. Данные для передачи через последовательную шину облекаются в пакеты (пакет – единица информации, передаваемая как целое между двумя устройствами), в которые, помимо собственно полезных данных, включается некоторое количество служебной информации: старт-биты, заголовки пакетов, синхросигналы, биты чётности или контрольные суммы, стоп-биты и т. п. Но в свете последних достижений в «железной» сфере компьютерной индустрии малое количество сигнальных линий и логически более сложный механизм передачи данных последовательных шин оборачиваются для них существенным преимуществом – возможностью практически безболезненного наращивания рабочих частот в таких пределах, каких никогда не достичь громоздким параллельным шинам с их высокочастотными проблемами ожидания доставки каждого бита к месту назначения. Проблема в том, что каждая линия такой шины имеет свою длину, свою паразитную ёмкость и индуктивность и, соответственно, своё время прохождения сигнала от источника к приёмнику, который вынужден выжидать дополнительное время для гарантии получения данных по всем линиям. Так, к примеру, каждый байт, передаваемый через линк шины PCIExpress, для увеличения помехозащищённости «раздувается» до 10 бит, что, однако, не мешает шине передавать до 0,25 ГБ за секунду по одной паре проводов. Да, ширина последовательной шины на самом деле является количеством одновременно задействованных отдельных последовательных каналов передачи.
Все эти нововведения и смена приоритетов преследуют в конечном итоге одну цель – повышение суммарного быстродействия системы, ибо не все существующие архитектурные решения способны эффективно масштабироваться. Несоответствие пропускной способности шин потребностям обслуживаемых ими устройств приводит к эффекту «бутылочного горлышка» и препятствует росту быстродействия даже при дальнейшем увеличении производительности вычислительных компонентов – процессора, оперативной памяти, видеосистемы и так далее.
Процессорная шина
Любой процессор архитектуры x86CPU обязательно оснащён процессорной шиной. Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жёстким диском и так далее. Так, классическая схема организации внешнего интерфейса процессора (используемая, к примеру, компанией Intel в своих процессорах архитектуры х86) предполагает, что параллельная мультиплексированная процессорная шина, которую принято называть FSB (Front Side Bus), соединяет процессор (иногда два процессора или даже больше) и контроллер, обеспечивающий доступ к оперативной памяти и внешним устройствам. Этот контроллер обычно называют северным мостом , он входит в состав набора системной логики ( чипсета ).
Используемая Intel в настоящее время эволюция FSB – QPB , или Quad-Pumped Bus, способна передавать четыре блока данных за такт и два адреса за такт! То есть за каждый такт синхронизации шины по ней может быть передана команда либо четыре порции данных (напомним, что шина FSB–QPB имеет ширину 64 бит, то есть за такт может быть передано до 4х64=256 бит, или 32 байт данных). Итого, скажем, для частоты FSB, равной 200 МГц, эффективная частота передачи адреса для выборки данных будет эквивалентна 400 МГц (2х200 МГц), а самих данных – 800 МГц (4х200 МГц) 3 .
3 Кстати, именно результирующей «учетверённой» частотой передачи данных (как и в случае с «удвоенной» передачей DDR-шины, где данные передаются дважды за такт) хвастаются производители и продавцы, умалчивая тот факт, что для многочисленных мелких запросов, где данные в большинстве своём умещаются в одну 64-байтную порцию (и, соответственно, не используются возможности DDR или QDR/QPB), на чтение/запись важнее именно частота тактирования.
Различия реализации классической архитектуры и АМD-K8
Различия реализации классической архитектуры и АМD-K8
Ещё одним довольно заметным отличием архитектуры К8 является отказ от асинхронности, то есть обеспечение синхронной работы процессорного ядра, ОЗУ и шины HyperTransport, частоты которых привязаны к «шине» тактового генератора (НТТ), которая в этом случае является опорной. Таким образом, для процессора архитектуры К8 частоты ядра и шины HyperTransport задаются множителями по отношению к НТТ, а частота шины памяти выставляется делителем от частоты ядра процессора 4
4 Пример: для системы на базе процессора Athlon 64-3000+ (1,8 ГГц) с установленной памятью DDR-333 стандартная частота ядра (1,8 ГГц) достигается умножением на 9 частоты НТТ, равной 200 МГц, стандартная частота шины HyperTransport (1 ГГц) – умножением НТТ на 5, а частота шины памяти (166 МГц) – делением частоты ядра на 11.
В классической же схеме с шиной FSB и контроллером памяти, вынесенным в северный мост, возможна (и используется) асинхронность шин FSB и ОЗУ, а опорной частотой для процессора выступает частота тактирования 5 (а не передачи данных) шины FSB, частота же тактирования шины памяти может задаваться отдельно. Из наиболее свежих чипсетов возможностью раздельного задания частот FSB и памяти обладает NVIDIA nForce 680i SLI, что делает его отличным выбором для тонкой настройки системы (разгона).
К распространенным типам архитектуры шины данных относятся ISA, EISA, Micro Channel" и PCI. Каждая из них физически отличается от остальных.
ISA (Industry Standard Architecture).
EISA (Extended Industry Standard Architecture).
Этот стандарт шины был представлен в 1988 году консорциумом из девяти компьютерных компаний: AST" Research, Inc., Compaq, Epson, Hewlett-Packard, NEC, Olivetti, Tandy, Wyse Technology и Zenith. EISA предлагает 32-разрядную шину, совместимую с ISA. Кроме того, она поддерживает дополнительные возможности, которыми обладает шина Micro Channel Architecture (MCA), разработанная IBM.
MCA (Micro Channel Architecture).
IBM представила этот стандарт в 1988 году как часть своего проекта PS/2. Эта архитектура электрически и физически несовместима с шиной ISA. В отличие от ISA, Micro Channel работает и как 16-разрядная, и как 32-разрядная шина. Особенностью данной шины является возможность параллельной и независимой работы нескольких активных процессорных устройств, таких как несколько ЦПУ, видеопроцессор и пр. Эта шина может использоваться как центральный элемент вычислительной системы, объединяющий процессоры, видеопроцессоры, процессоры управления доступом к данным и каналам ввода/вывода.
PCI (Peripheral Component Interconnect).
Это 32-разрядная локальная шина, которая используется в настоящее время в большинстве компьютеров с процессором Pentium и в компьютерах Apple Power Macintosh. В отличие от MCI PCI имеет существенные ограничения как на число устройств, взаимодействующих на шине, так и на их функциональность. Распространилась данная шина не благодаря своим качествам, а вследствие агрессивного маркетинга со стороны крупных корпораций.
Считается, что архитектура PCI удовлетворяет большинству требований технологии Plug and Play, целью которой является возможность изменять конфигурацию персонального компьютера без вмешательства пользователя, т.е. максимально упростить подключение любого устройства.
Читайте также: