
Bitmap raid что это
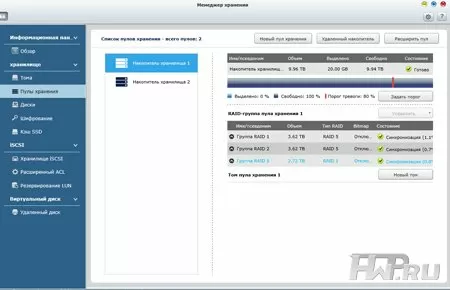
Наконец, фундаментом для дисковых томов и блочных LUN служат пулы хранения. Отметим, что в один пул хранения могут одновременно входить RAID-группы из разных физических устройств, т.е. головного NAS и подключенных полок. К примеру, пул может состоять из двух массивов RAID 5 по три диска в самом NAS (RAID Group 1 и 2 на схеме), а также еще одного RAID 5 из трех дисков в одной из подключенных полок (RAID Group 3 в примере). Кстати, вы вполне можете объединять в один пул массивы разного уровня (например, RAID 6 и RAID 10) и с разным количеством жестких дисков. Правда, система рекомендует всегда использовать в одном пуле массивы одного уровня для более быстрой работы. Разумеется, в Менеджере хранения QNAP предусмотрена возможность расширения пула новыми RAID-группами, как и добавления в них дисков с поддержкой повышения уровня массива.
Вообще, кроме как для объединения дисков из головного устройства и полок расширения, пул может пригодиться для тех случаев, когда у вас имеются диски разного объема. Хранилища QNAP не поддерживает проприетарные технологии эффективного использования места в RAID-массивах при установке дисков разного объема, поэтому если у вас четыре диска имеют объем 3 Тб, а еще четыре других - 1 Тб, лучше будет сделать два RAID-массива типа 5 или 6 из одинаковых дисков и объединить их в пул. В случае добавления в NAS еще восьми дисков разного объема, вы можете часть из них включить в существующие RAID-группы, а часть (например, объемом 2 Тб) - в новую RAID-группу, которая затем войдет в существующий или образует новый пул.
Использование пулов на базе RAID-групп формально усложняет управление системой хранения данных, хотя и позволяет распоряжаться дисковым пространством более гибко. Пользователь может расширить емкость и повысить тип RAID-группы, заменив по отдельности имеющиеся винчестеры и просто добавив к ней новые, в том числе резервный диск (spare drive), увеличить пул новыми группами, а также включить опцию bitmap для более быстрого восстановления массива в случае сбоя. Впрочем, кажущаяся сложность настройки нивелируется мастером создания тома, который позволяет быстро и по шагам создать логический диск.
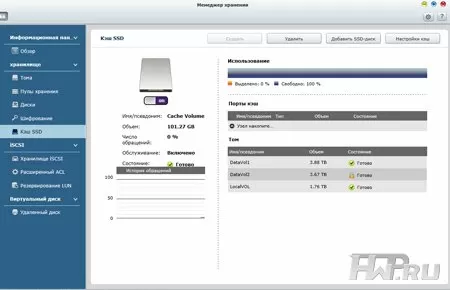
Одной из основных тенденций 2013 года в секторе корпоративных СХД, стала поддержка кеширования на SSD-дисках. Установив в систему пару SSD, можно значительно повысить скорость доступа к наиболее востребованным данным. Для этого в используемом нами устройстве QNAP предназначаются слоты 3 и 4, при этом объем кэша будет равен сумме емкостей установленных SSD-накопителей. В Менеджере хранения включение SSD-кэширования осуществляется на уровне дискового тома. Также в меню настройки вы можете посмотреть статистику использования SSD-кэша - уровень его заполненности, частоту запросов и попаданий, чтобы со временем настроить использование там, где он действительно нужен.
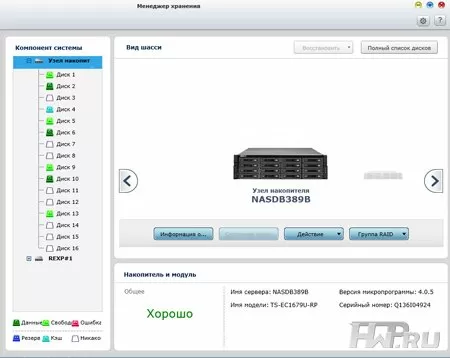
Хочется отдельно сказать, что в Менеджере хранения QNAP доступен максимально понятный и наглядный обзор всей системы в виде диаграмм, показывающих количество и статус каждого тома, пула и отдельного диска. При просмотре отдельных компонентов системы, т.е. головного устройства и полок, можно получить исчерпывающую информацию об их состоянии и установленных дисков. Также здесь вы сможете настроить запуск тестов S.M.A.R.T. для винчестеров по расписанию, что рекомендуется делать хотя бы раз в месяц для того, чтобы заранее определить возможную неисправность.
Подключение дисковых полок
Топовые сетевые хранилища QNAP уровня SMB масштабируются при помощи дисковых полок, или как их еще называют - модулей расширения. Это позволяет использовать одновременно два интерфейса: SATA для внутренних жестких дисков и SAS для подключения полок расширения. В рассматриваемой нами модели TC-EC1679U-RP в качестве последнего интерфейса можно установить 2-портовый адаптер HBA SAS 6 Gbps, приобретаемый отдельно. Эти адаптеры не имеют встроенных процессоров для расчёта XOR, так что даже на подключаемых полках RAID-массивы будут программными. Сами полки расширения QNAP имеют максимально простую конструкцию - одна плата с чипом SAS-множителя, вентиляторы охлаждения и два блока питания. На данный момент есть два варианта по емкости - на 12 или 16 дисков. Ломаться в полке просто нечему, но если вдруг одна из них отключается, модуль управления QNAP тут же блокирует операции ввода-вывода, чтобы предотвратить повреждение данных. При последующем включении полки, система сможет восстановиться в нормальное состояние, оставив данные нетронутыми.
Каждая дисковая полка имеет по два широких порта SAS SFF8088 (один IN и второй OUT) для каскадного подключения к одному головному NAS, обеспечивая скорость для одного соединения с хостом до 24 Гбит/с (один порт включает в себя четыре канала, каждый из которых дает 6 Гбит/c в режиме дуплекса). Этой скорости более чем достаточно даже для прямой передачи данных с дисков в сеть 10G.
Заключение
Менеджер хранения в операционной системе QTS для топовых хранилищ QNAP предоставляет возможность гибко настраивать распределение и резервирование дискового пространства размерами в сотни терабайт. Концепция, примененная разработчиками, значительно отличается от простого создания томов, к которым мы привыкли, работая с NAS-ами для малого бизнеса и SOHO. Сегодня можно говорить, что технологически QNAP стоит на одном уровне с брендами А-класса, такими как IBM, HP, Dell и предлагает более выгодные с финансовой точки зрения продукты. Одно из главных преимуществ конкурентов, которое получила QNAP - это масштабирование своих NAS каскадным подключением дисковых полок. Вполне возможно, что компания QNAP за счет более низких цен будет отбирать часть рынка у более крупных игроков - это покажет время.
В качестве развития системы управления данными, мы видим поддержку резервирования между различными NAS-ами в том числе разных классов для балансировки нагрузки, создание конфигураций N+1 для работы в средах с повышенными требованиями к отказоустойчивости и объединение NAS-ов в кластеры с общей системой управления для создания систем хранения с практически неограниченным объемом. По крайней мере, шаги в этом направлении многими производителями СХД уже делаются.
Чем можно заниматься в 0 часов 0 минут в Москве? Сидеть за праздничным столом и праздновать? Как бы не так. В этот праздничный миг я хочу поделиться с вами моими сегодняшними изысканиями по тюнингу производительности софтрейда в домашнем сервере. Можно пропустить теорию и сразу читать последний абзац где основная соль.
Почему RAID-6?
Как известно, RAID-5 выдерживает смерть одного веника, и после этой самой смерти – до момента когда закончится восстановление рейда с новым винчестером ваши данные под угрозой – восстановление обычно занимало до 70 часов для больших массивов и еще один веник может легко умереть в это время.
RAID-6 выдерживает смерть 2-х любых веников. Из минусов – общепризнанное мнение что тормозит, особенно запись, даже по сравнению с RAID-5. Что-ж, проверим.
Почему софтрейд?
Железный рейд нужен только в одном случае – если у него есть батарейка и набортный кеш. Тогда контроллер сразу отвечает ОС что запись на диск завершена на физическом уровне и всякие ACID базы работают очень быстро и безопасно.
В остальных случаях никаких бонусов по сравнению с софт-рейдом нет, одни минусы:
1) Сгорело железо? Новый сервер? Будьте добры купить тот же контроллер, ну или молитесь о совместимости. Софтрейд из тех-же дисков собирается где угодно.
2) Цена :-) Собственно, из-за этого нормальных рейдов с батарейкой я в руках так ниразу и не держал :-)
Ну а те «рейд-контроллеры» которые стоят на обычных материнских платах – вообще никогда не стоит использовать. Они просто дают грузить ОС с рейда за счет набортного биоса (который выполняется центральным процессором, своего процессора нет), на этом их польза заканчивается, и остаются только минусы.
О паре мифов софтрейда
1) Он жрет много драгоценного процессора
Если мы одним глазком глянем в исходники драйвера RAID в ядре Linux, то увидем, что там давно все оптимизированно под SSE2. А с SSE2 процессор может считать XOR от 16 байт за 1 такт на 1 ядре современного процессора и все упирается в скорость обмена с памятью. Можете прикинуть сколько % загрузки одного ядра сгенерирует поток в 1Гб/сек :-) А ядер то много :-) На практике, с моим Opteron 165 (1.8Ghz 2 ядра) скорость никогда не упиралась в CPU.
2) Он разваливается и потом хрен соберешь.
Если что-то и отваливается – то из-за железа (например обычные винты любят иногда делать всякие фоновые задачи). Добавление вывалившегося веника – простая операция, которая кроме того может проводится автоматически. Впрочем, в среднем это надо делать раз в год.
mdadm /dev/md0 -a /dev/sde1
3) У софтрейда хреновый мониторинг
С мониторингом все отлично и настраиваемо. Достаточно например просто мыло указать в конфиге mdadm и он пришлет вам письмо если что-то случиться с вашим массивом. Очень удобно )
Вот например что приходит если один веник отвалился:
This is an automatically generated mail message from mdadm running on XXXXX
A DegradedArray event had been detected on md device /dev/md0.
Faithfully yours, etc.
P.S. The /proc/mdstat file currently contains the following:
Personalities: [raid6] [raid5] [raid4]
md0: active raid6 sda1[1] sdc1[4] sdd1[3] sde1[2]
2929683456 blocks super 1.2 level 6, 1024k chunk, algorithm 2 [5/4] [_UUUU]
unused devices: none
О роли bitmap
Linux-овый софтрейд поддерживает замечательную фичу: bitmap. Там отмечаются измененные блоки на диске, и если у вас почему-то отвалился один диск из массива, а потом вы его обратно добавили – полная перестройка массива не нужна. Чертовски полезно. Хранить можно на самом рейде – internal, а можно в отдельном файле – но тут есть ограничения (на тип ФС например). Я сделал internal bitmap. И зря. Internal bitmap тормозит безбожно т.к. постоянно дергается головка веников при записи.
Посмотрим на скорость:
time sh -c «dd if=/dev/zero of=ddfile bs=1M count=5000»
time sh -c «dd if=ddfile of=/dev/null bs=1M count=5000»
Результаты для моего RAID-6 из 5xWD 1Тб получились следующие: чтение 268МБ/сек, запись 37МБ/сек. Все разводят руками и говорят: ну а чего же вы хотели? RAID-6 тормозит при записи, ведь ему надо прочитать то что было записано раньше, чтобы посчитать обновленные контрольные суммы для всех дисков. А еще и этот bitmap…
Скорость перестройки массива – около 25МБ/сек – полная перестройка массива до 15 часов. Вот он, ваш ночной кошмар.
Решаются проблемы просто:
-
У драйвера рейда в Linux есть такой полезный параметр: stripe_cache_size
значение по умолчанию которого равно 256. Слишком низкое значение – резко снижает скорость записи (как оказалось). Оптимальное значение для многих – 8192. Это — кол-во блоков памяти на 1 диск. 1 блок это обычно 4kb (зависит от платформы), для 5-и дискового массива кеш займет 8192*4кб*5 = 160МБ.
echo 8192 > /sys/block/md0/md/stripe_cache_size
Действовать начинает моментально. Теперь в большинстве случаев драйверу не приходится читать диск перед записью (особенно при линейной записи), и производительность резко вырастает. После перезагрузки пропадает, чтобы не пропало — добавляем в какой-нибуть /etc/rc.local например.

PS. Внимание! Под рутом ходить только на трезвую голову!
PS. В непростой схватке, первый пост на хабре в 2011 году опубликовал все-таки я
PS. infi
Описание типов массивов RAID см. в приведенной ниже таблице.
Для имеющегося NAS можно настроить одиночную отдельную группу RAID. Однако при этом не будет обеспечено никакой дополнительной защиты. И при повреждении данных на диске или других сбоях все данные на диске будут утеряны.
RAID 0 с чередованием
Чередование данных в группе RAID позволяет объединить два или более дисков в большой логический диск. Это позволяет достичь наибольшей скорости доступа к диску, однако не обеспечивает никакой дополнительной защиты на случай сбоя или повреждения данных. Общий объем диска равен сумме объемов всех дисков. Чередование данных на дисках обычно используется для максимального увеличения их объема или скорости доступа к ним. Учтите, что конфигурация RAID 0 не рекомендуется для хранения важных данных.
RAID 1 с зеркалированием
Зеркалирование диска обеспечивает защиту данных с помощью функции автоматического дублирования содержимого одного диска на втором диске в зеркальной паре. Этим обеспечивается защита на случай одиночного сбоя диска. Объем для хранения данных равен объему наименьшего из дисков, поскольку второй диск используется для резервного хранения данных первого диска. Конфигурация RAID 1 подходит для хранения важных корпоративных и личных данных.
Конфигурации RAID 5 идеально подходят организациям, работающим с базами данных и другими приложениями, использующими транзакции, для которых требуется высокий уровень производительности системы хранения данных и защиты информации. Для создания группы RAID 5 требуется как минимум 3 жестких диска. Общий объем группы RAID 5 равен объему наименьшего диска в массиве, умноженному на общее количество жестких дисков за вычетом 1 диска. Для максимально эффективного использования объема жестких дисков рекомендуется (но не требуется в обязательном порядке) использовать жесткие диски одной и той же марки и одного и того же объема.
Кроме того, если в системе установлено 4 диска, то для массива RAID 5 можно использовать 3 диска, а четвертый настроить в качестве резервного. В такой конфигурации резервный диск автоматически используется системой для перестроения массива в случае сбоя физического диска. Конфигурация RAID 5 может выдержать выход из строя одного диска без потери какой-либо функциональности системы. При сбое диска в RAID 5 дисковый том будет работать в "режиме с ухудшенными характеристиками". С этого момента защита данных больше не обеспечивается, и в случае выхода из строя второго диска все данные будут утеряны. Неисправный диск следует немедленно заменить. Диск можно заменить после отключения сервера или произвести его горячую замену при включенном сервере. После установки нового диска состояние тома изменится на "Восстановление". По завершении процесса восстановления тома дисковый том вернется в нормальное состояние.
Примечание. Прежде чем производить горячую замену диска при включенном сервере убедитесь, что дисковый том находится в режиме "с ухудшенными характеристиками". Или установите вместо неисправного диска новый после двух длинных звуковых сигналов, уведомляющих об отказе диска.
RAID 6 прекрасно подходит для защиты важных данных. Для создания группы RAID 6 требуется минимум 4 жестких диска. Общий объем группы RAID 6 равен объему наименьшего диска в массиве, умноженному на общее количество жестких дисков за вычетом 2 дисков. Для максимально эффективного использования объема жестких дисков рекомендуется (но не требуется в обязательном порядке) использовать одинаковые жесткие диски. Массив RAID 6 может выдержать выход из строя 2 дисков с сохранением работоспособности системы.
Примечание. Прежде чем производить горячую замену диска при включенном сервере убедитесь, что дисковый том находится в режиме "с ухудшенными характеристиками". Или установите вместо неисправного диска новый после двух длинных звуковых сигналов, уведомляющих об отказе диска.
RAID 10 — это комбинация RAID 1 (с зеркалированием) и RAID 0 (с чередованием) без контроля четности. В RAID 10 используется чередование данных по нескольким дискам для обеспечения отказоустойчивости и высокой скорости передачи данных. Объем пространства для хранения группы RAID 10 равен объему наименьшего диска в массиве, умноженному на общее количество жестких дисков и поделенному пополам. Для создания группы RAID 10 рекомендуется использовать жесткие диски одной и той же марки и объема. RAID 10 подходит для приложений с большими объемами транзакций, таких как базы данных, для которых требуется высокий уровень производительности и отказоустойчивости. RAID 10 выдерживает выход из строя 2 дисков в 2 различных парах.
Примечание. Прежде чем производить горячую замену диска при включенном сервере следует убедиться, что дисковый том находится в "режиме с ухудшенными характеристиками". Или установите вместо неисправного диска новый после двух длинных звуковых сигналов, уведомляющих об отказе диска.
Два диска и более можно объединить в один том увеличенного объема. При сохранении файлов данные записываются на физические диски последовательно. Общий объем тома с линейной записью соответствует сумме объемов всех дисков. Данная конфигурация не обеспечивает защиту от выхода диска из строя. Сбой в работе одного из дисков приведет к потере всего массива данных. Группа JBOD обычно используется для хранения больших объемов данных. Она не подходит для хранения важных данных.
Управление поврежденными блоками
Для управления поврежденными блоками используется список (журнал) поврежденных блоков для каждого диска, позволяющий локализовать такие сбои в системе на уровне блоков, а не дисков целиком. Это особенно полезно для массивов RAID. Наличие поврежденных блоков в различных местах на разных дисках не нарушает работоспособность массива RAID, и в нем по-прежнему сохраняется по крайней мере однократное резервирование для всех носителей с чередованием данных. Благодаря этой функции массив RAID может сохранять работоспособность даже при возникновении подобных проблем во время его перестроения.
Примечание. Поддержка управления поврежденными блоками имеется только в массивах RAID 5 и RAID 6.
Увеличение объема группы RAID
Данная функция позволяет увеличить объем группы RAID путем последовательной (один за другим) замены жестких дисков в массиве группы RAID. Функция поддерживается для массивов RAID следующих типов: RAID 1, RAID 5, RAID 6 и RAID 10. Для увеличения объема группы RAID выполните следующие действия.
| 1. | Выберите команды "Менеджер хранения" > "ХРАНИЛИЩЕ" > "Пространство памяти". |
| 2. | Дважды щелкните пул носителей, чтобы открыть страницу управления пулом носителей. |
| 3. | Выберите группу RAID, а затем — команды "Управление" > "Увеличить объем". |
Добавление жестких дисков
Данная функция позволяет добавлять диски в группу RAID. Она поддерживается для конфигураций RAID 5 и RAID 6.
Для добавления одного или нескольких жестких дисков в группу RAID выполните следующие действия.
| 1. | Выберите команды "Менеджер хранения" > "ХРАНИЛИЩЕ" > "Пространство памяти". |
| 2. | Дважды щелкните пул носителей, чтобы открыть страницу управления пулом носителей. |
| 3. | Выберите группу RAID, а затем — команды "Управление" > "Добавить жесткий диск". |
| 4. | Выберите в списке жесткий диск для добавления к выбранной группе RAID и нажмите кнопку "Применить". |
| 5. | Учтите, что все данные на выбранных жестких дисках будут удалены. Если вы уверены, нажмите кнопку "Да". |
| 6. | Выбранные жесткие диски будут добавлены в данную группу RAID. |
Миграция группы RAID
Данная функция позволяет выполнить миграцию одной конфигурации RAID в другую. Она поддерживается для следующих конфигураций дисков: миграция одиночных дисков в RAID 1; миграция RAID 1 в RAID 5; миграция RAID 5 в RAID 6. Для выполнения миграции конфигурации RAID выполните следующие действия.
| 1. | Выберите команды "Менеджер хранения" > "ХРАНИЛИЩЕ" > "Пространство памяти". |
| 2. | Дважды щелкните пул носителей, чтобы открыть страницу управления пулом носителей. |
| 3. | Выберите группу RAID, а затем — команды "Управление" > "Миграция". |
| 4. | Выберите в списке один или несколько жестких дисков и нажмите кнопку "Применить". |
| 5. | Учтите, что все данные на выбранных жестких дисках будут удалены. Если вы уверены, нажмите кнопку "Да". |
| 6. | Будет выполнена миграция выбранной конфигурации RAID в новую. |
Настройка резервных дисков
Данная функция позволяет добавить или удалить резервный диск в конфигурациях RAID 1, RAID, 5, RAID 6 и RAID 10. В отличие от полной замены диска, в этом случае диск будет выделен для группы RAID. Для настройки резервного диска выполните следующие действия.
| 1. | Выберите команды "Менеджер хранения" > "ХРАНИЛИЩЕ" > "Пространство памяти". |
| 2. | Дважды щелкните пул носителей, чтобы открыть страницу управления пулом носителей. |
| 3. | Выберите группу RAID, а затем — команды "Управление" > "Настроить резервный диск". |
| 4. | Выберите в списке один или несколько жестких дисков для настройки и нажмите кнопку "Применить". |
| 5. | Учтите, что все данные на выбранных жестких дисках будут удалены. Если вы уверены, нажмите кнопку "Да". |
| 6. | Выбранные диски будут добавлены в качестве резервных. |
Включение и отключение Bitmap
Данная функция позволяет сократить время на перестроение после сбоя, а также время, требуемое на удаление и добавление жесткого диска. Данная функция не повышает производительность чтения-записи для диска и даже может вызвать некоторое ее снижение. Однако если у массива имеется Bitmap, то допускается удаление и добавление жесткого диска, и требуется произвести только изменения в блоках, поскольку данные при удалении диска (в соответствии с данными, записанными в Bitmap) можно повторно синхронизировать. Для включения Bitmap выполните следующие действия.
| 1. | Выберите команды "Менеджер хранения" > "ХРАНИЛИЩЕ" > "Пространство памяти". |
| 2. | Дважды щелкните пул носителей, чтобы открыть страницу управления пулом носителей. |
Для выключения Bitmap выполните следующие действия.
| 1. | Выберите команды "Менеджер хранения" > "ХРАНИЛИЩЕ" > "Пространство памяти". |
| 2. | Дважды щелкните пул носителей, чтобы открыть страницу управления пулом носителей. |
Примечание. Поддержка функции Bitmap доступна только для массивов RAID 1, RAID 5, RAID 6 и RAID 10.
Восстановление поврежденных дисковых томов RAID
Данная функция позволяет восстановить поврежденные дисковые тома массива RAID из состояния "Неактивен" в нормальное состояние (массивы RAID 1, RAID 5, RAID 6 и RAID 10 будут восстановлены в состояние режима с ухудшенными характеристиками; массивы RAID 0 и JBOD будут восстановлены в нормальный режим). Перед восстановлением дискового тома необходимо убедиться, что все диски тома размещены надлежащим образом в отсеках NAS. По завершении восстановления необходимо незамедлительно выполнить резервное копирование данных на дисках на случай повторного выхода дискового тома из строя.
Восстановление неактивных дисковых томов RAID возможно только в случае, если в NAS имеется минимальное требуемое для конфигурации RAID количество исправных дисков. Например, в конфигурации RAID 5 с массивом из 3 дисков для восстановления тома требуется по крайней мере 2 исправных диска в NAS. В противном случае восстановление тома RAID невозможно. Сведения о минимальном количестве жестких дисков, необходимом для восстановления группы RAID, см. в приведенной ниже таблице.
После создания массива RAID5 из трёх двухтерабайтных дисков, я был неприятно удивлён низкой скорости записи на массив: всего 55 мбайт/сек. Пришлось поизучать, с помощью каких параметров можно добиться от массива нормальной производительности.
Дело оказалось в том, что
во-первых – выставляемое для массива по-умолчанию значение stripe_cache_size слишком мало; во-вторых – массив я создал со внутренним Write Intent Bitmap ( –bitmap=internal ) и маленьким bitmap chunk.После увеличения stripe_cache_size и размера bitmap chunk, скорость записи поднялась до 130-150 мбайт/сек. Подробности об этих и других параметрах читайте ниже.
Параметры, влияющие на производительность
stripe_cache_size
Значение по умолчанию – 256, диапазон от 32 до 32768, при этом увеличение хотя бы до 8192 сильно помогает скорости записи:
Внимание: измеряется в кол-ве страниц * на кол-во устройств , и может быть очень прожорливо в плане потребления ОЗУ. При вышеуказанном значении 8192 , размере страницы памяти в 4096 байт (используемом в ядре Linux на x86 и x86-64) и четырёх дисках в RAID , потребление памяти составит:

Write Intent Bitmap
Эффект можно уменьшить, использовав большее значение параметра mdadm –bitmap-chunk (см. man mdadm ), например я сейчас использую 131072 . Можно также практически полностью исключить его, использовав bitmap во внешнем файле – на диске, не входящем в массив. Для раздела, где будет храниться файл с bitmap, автором mdadm рекомендуется файловая система ext2 или ext3, однако и при размещении его на XFS каких-либо проблем не возникало.
mkfs.ext4 -E stride=,stripe_width=
Важно правильно задать при создании ФС эти параметры, если забыли - ничего страшного, можно и позже их поменять с помощью tune2fs .
XFS пытается определить соответствующие значения автоматически, если у неё не получается – см. man mkfs.xfs на предмет sunit= и swidth= .
Chunk size
Задаётся при создании массива, параметром mdadm –chunk-size . Изменить в уже работающем массиве – крайне долгая, и вероятно не вполне безопасная операция, требующая, к тому же, самой свежей версии mdadm (3.1) и достаточно нового ядра (2.6.31+) 1) .
Дефолтным значением в старых mdadm было 64K, в новых – стало 512K 2) . По мнению автора mdadm , “512K новым дискам подходит лучше”, по моему – не всё так однозначно. Пока что предпочитаю продолжить использование 64K.
Другим автором по результатам тестов рекомендуется размер в 128K:
Read-Ahead
Экспериментов с этим пока не проводил, скорость чтения с массива (на трёхдисковом RAID5, достигающая суммы линейной скорости двух дисков) устраивает и так.
Почему RAID-6?
Как известно, RAID-5 выдерживает смерть одного веника, и после этой самой смерти – до момента когда закончится восстановление рейда с новым винчестером ваши данные под угрозой – восстановление обычно занимало до 70 часов для больших массивов и еще один веник может легко умереть в это время. RAID-6 выдерживает смерть 2-х любых веников. Из минусов – общепризнанное мнение что тормозит, особенно запись, даже по сравнению с RAID-5. Что-ж, проверим.
Почему софтрейд?
Железный рейд нужен только в одном случае – если у него есть батарейка и набортный кеш. Тогда контроллер сразу отвечает ОС что запись на диск завершена на физическом уровне и всякие ACID базы работают очень быстро и безопасно.
В остальных случаях никаких бонусов по сравнению с софт-рейдом нет, одни минусы:
Ну а те «рейд-контроллеры» которые стоят на обычных материнских платах – вообще никогда не стоит использовать. Они просто дают грузить ОС с рейда за счет набортного биоса (который выполняется центральным процессором, своего процессора нет), на этом их польза заканчивается, и остаются только минусы.
О паре мифов софтрейда
Он жрет много драгоценного процессора. Если мы одним глазком глянем в исходники драйвера RAID в ядре Linux, то увидем, что там давно все оптимизированно под SSE2. А с SSE2 процессор может считать XOR от 16 байт за 1 такт на 1 ядре современного процессора и все упирается в скорость обмена с памятью. Можете прикинуть сколько % загрузки одного ядра сгенерирует поток в 1Гб/сек А ядер то много На практике, с моим Opteron 165 (1.8Ghz 2 ядра) скорость никогда не упиралась в CPU. Он разваливается и потом хрен соберешь. Если что-то и отваливается – то из-за железа (например обычные винты любят иногда делать всякие фоновые задачи). Добавление вывалившегося веника – простая операция, которая кроме того может проводится автоматически. Впрочем, в среднем это надо делать раз в год. У софтрейда хреновый мониторинг. С мониторингом все отлично и настраиваемо. Достаточно например просто мыло указать в конфиге mdadm и он пришлет вам письмо если что-то случиться с вашим массивом. Очень удобно. Вот например что приходит если один веник отвалился: Рекоменую протестировать перед использованием: У софтрейда очень низкая скорость перестройки массива. В дефолтной конфигурации – да. А если вы дочитаете до конца статьи – узнаете как сделать так, чтобы все перестраивалось со скоростью самого медленного веника.О роли bitmap
Linux-овый софтрейд поддерживает замечательную фичу: bitmap. Там отмечаются измененные блоки на диске, и если у вас почему-то отвалился один диск из массива, а потом вы его обратно добавили – полная перестройка массива не нужна. Чертовски полезно. Хранить можно на самом рейде – internal, а можно в отдельном файле – но тут есть ограничения (на тип ФС например). Я сделал internal bitmap. И зря. Internal bitmap тормозит безбожно т.к. постоянно дергается головка веников при записи.
Посмотрим на скорость:
Скорость можно тестировать например так:
Результаты для моего RAID-6 из 5xWD 1Тб получились следующие: чтение 268МБ/сек, запись 37МБ/сек. Все разводят руками и говорят: ну а чего же вы хотели? RAID-6 тормозит при записи, ведь ему надо прочитать то что было записано раньше, чтобы посчитать обновленные контрольные суммы для всех дисков. А еще и этот bitmap…
Скорость перестройки массива – около 25МБ/сек – полная перестройка массива до 15 часов. Вот он, ваш ночной кошмар.
Решаются проблемы просто:
У драйвера рейда в Linux есть такой полезный параметр: stripe_cache_size, значение по умолчанию которого равно 256. Слишком низкое значение – резко снижает скорость записи (как оказалось). Оптимальное значение для многих – 8192. Это — кол-во блоков памяти на 1 диск. 1 блок это обычно 4kb (зависит от платформы), для 5-и дискового массива кеш займет 8192*4кб*5 = 160МБ. Действовать начинает моментально. Теперь в большинстве случаев драйверу не приходится читать диск перед записью (особенно при линейной записи), и производительность резко вырастает. После перезагрузки пропадает, чтобы не пропало — добавляем в какой-нибуть /etc/rc.local например. Скорость перестройки массива теперь – 66МБ/сек (это сразу по всем дискам, около 5 часов на весь массив), скорость чтения осталась той-же, а вот скорость записи – выросла до 130МБ/сек (с 37). Переносим bitmap на отдельный диск (в моём случае — системный). Если системный веник сдохнет — ничего страшного, массив восстановится и без bitmap-а. Головка больше не дергается при записи лишний раз, и скорость записи вырастает до 165МБ/сек.Итак, за 10 секунд мы подняли скорость записи с удручающих 37 МБ/сек до вполне приличных 165 МБ/сек (более чем в 4 раза!!). Теперь через Samba по сети файлы и пишутся и читаются 95-100 МБ/сек, и планировавшийся из-за низкой скорости рейда апгрейд сервера придется отложить на неопределенное время – производительности дохленького Opteron 165 теперь с лихвой хватает для всех поставленных задач.
Читайте также: