
Tmpfs linux что это
Файловая система tmpfs может найти повседневное применение в вашей деятельности, поскольку она невероятно быстрая и может помочь снизить нагрузку на ваше постоянное хранилище (особенно актуально тем, у кого Linux установлен на флешку или карту памяти).
tmpfs — это виртуальная файловая система, располагающаяся в оперативной памяти.
Средство tmpfs позволяет создавать файловые системы, содержимое которых находится в виртуальной памяти. Поскольку файлы в таких файловых системах обычно находятся в ОЗУ, доступ к файлам осуществляется очень быстро.
Файловая система создаётся автоматически при монтировании файловой системы с типом tmpfs с помощью следующей команды:
Файловая система tmpfs имеет следующие свойства:
- Файловая система может использовать пространство подкачки, когда этого требует физическая нагрузка на память.
- Файловая система потребляет столько физической памяти и пространства подкачки, сколько требуется для хранения текущего содержимого файловой системы.
- Во время операции повторного монтирования (mount -o remount) размер файловой системы может быть изменён (без потери существующего содержимого файловой системы).
Если файловая система tmpfs размонтирована, её содержимое теряется (удаляется).
Вы можете скопировать в tmpfs файлы для максимально быстрого доступа. Это могут быть файлы баз данных или веб-сервера.
Ещё одна цель использования — снизить износ постоянного хранилища. Это не особенно актуально для жёсткого диска или твердотельного диска — современные модели при любом типе домашнего использования переживут нас. Но это может быть актуально, если система установлена на карту памяти. Вы можете разместить в оперативную память приложение, которое постоянно использует хранилище (часто обращается к файлам или непрерывно сохраняет файлы), тем самым ускорится работа этого приложения, а также всей системы за счёт снижения нагрузки на карту памяти.
Ещё одна возможная причина использование — незаметность, при работе в tmpfs всё будет происходить в оперативной памяти, а на постоянных хранилищах не останется никаких следов.
Рассмотрим пример копирования файлов — насколько быстрее это будет происходить в tmpfs по сравнению с дисками.
Создадим точку монтирования:
Создадим виртуальную файловую систему размером 20 Гигабайт в оперативной памяти:
Скопируем туда файл размером в несколько Гигабайт:
Проверим, сколько времени понадобится для создания копии этого файла в оперативной памяти:

Понадобилось совсем немного времени — примерно полторы секунды.
А теперь сделаем копию этого же файла на жёстком диске:

Понадобилось 14 секунд — в 10 раз больше времени.
Итак, используя tmpfs можно добиться максимальной скорости доступа к файлам.
Так сложилось, что уже пять лет мой раздел ntfs с операционной системой Windows располагается на рамдиске. Решено это не аппаратным, а чисто программным способом, доступным на любом ПК с достаточным количеством оперативной памяти: рамдиск создается средствами загрузчика grub4dos, а Windows распознаёт его при помощи драйвера firadisk.
Однако до недавнего времени мне не был известен способ, как реализовать подобное для Linux. Нет, безусловно, существует огромное количество линуксовых LiveCD, загружающихся в память при помощи опций ядра toram, copy2ram и т. д., однако это не совсем то. Во-первых, это сжатые файловые системы, обычно squashfs, поэтому любое чтение с них сопровождается накладными расходами на распаковку, что вредит производительности. Во-вторых, это достаточно сложная каскадная система монтирования (так как squashfs — рид-онли система, а для функционирования ОС нужна запись), а мне хотелось по возможности простого способа, которым можно «вот так взять и превратить» любой установленный на жесткий диск Linux в загружаемый целиком в RAM.
Но поскольку установка Debian не является предметом этой статьи, подробно ее описывать не буду.
Такой выбор в общем продиктован тем, что оперативной памяти никогда не бывает много и держать в ней что-то огромное вроде KDE не предполагалось. После установки необходимых для работы программ на жестком диске оказалось занято полтора гигабайта. Установка производилась в один раздел, без раздела swap. Оперативной памяти на компьютере установлено 16 гигабайт.
Собственно, способ
1. В файле /usr/share/initramfs-tools/scripts/local закомментируем строку:
checkfs $ root
и строку:
mount $ -t $ $ $ $
и сразу после нее вставим такой текст:
mkdir /ramboottmp
mount $ -t $ $ $ /ramboottmp
mount -t tmpfs -o size=100% none $
cd $
tar -zxf /ramboottmp/ram.tar.gz
umount /ramboottmp
2. Выполним команду mkinitramfs -o /initrd-ram.img
и после того, как она отработает, вернем файл /usr/share/initramfs-tools/scripts/local в исходное состояние.
3. В файле /etc/fstab закомментируем строку, описывающую монтирование корневого раздела / и вставим такую строку:
none / tmpfs defaults 0 0
4. Загрузим какой-нибудь другой линукс с LiveCD, чтобы полностью отвязаться от испытуемой операционной системы,
и заархивируем весь раздел с ее файловой системой:
cd /mnt/first && busybox tar -czf /mnt/work/ram.tar.gz *
после окончания вернем файл /etc/fstab в исходное состояние.
5. В итоге у нас получился линукс, состоящий всего из трех файлов:
кернела, initrd-ram.img и ram.tar.gz. Местонахождение ram.tar.gz указываем в параметре root= ядра в меню загрузчика grub:
title Linux in RAM
kernel /vmlinuz root=/dev/sdb1
initrd /initrd-ram.img
Это вся инструкция. Необходимые комментарии:
— checkfs закомментируем потому, что нет такого fsck для проверки tmpfs, не написали его;
— busybox tar используем для создания архива вместо простого tar из-за того, что в initrd нет простого tar, распаковывать наш архив будет именно busybox, и существует такой баг, что не сможет распаковать;
— звездочка в командной строке не страшна, так как в корне, обычно, нет скрытых файлов и папок, а в директориях они архивируются.
— /mnt/first — это примонтированный раздел с испытуемой ОС, а /mnt/work/ — это раздел для помещения архива.
Как это работает?
Мы изготовили специальный initrd, который при загрузке создает корневую файловую систему типа tmpfs (в этом вся соль, так как располагается она в оперативной памяти), затем смотрит на указанный в опции root= раздел, берет там файл архива, имя которого захардкожено (ram.tar.gz), и распаковывает из него все дерево ФС на эту tmpfs.
Так ФС оказывается в памяти.
Причем tmpfs обладает выгодными отличиями от рамдисков (в том числе от используемого мной для Windows) — она не блочное устройство, а файловая система, она занимает места в памяти ровно столько, сколько занимают файлы, и динамически увеличиватся, если что-то устанавливать, записывать новые файлы, и уменьшается, если деинсталлировать софт, удалять файлы. Остальная память доступна для работы ОС, программ. А еще Linux понимает, что это УЖЕ память и ее не надо кэшировать. Замечательная вещь!
Преимущества
Да, конечно, кэширование в современных ОС частично решает проблему низкой производительности дисковых устройств, но все равно необходимо время для первого прочтения файла с диска, а также он может быть выгружен из кэша в любое время и тогда понадобится время для его повторного чтения. Размещение же всей ОС в памяти является бескомпромиссным решением, гарантирующим максимально возможную скорость чтения и записи ее файлов. Простейший тест с помощью dd демонстрирует 3 гигабайта в секунду на последовательное чтение и 2 гигабайта в секунду на последовательную запись:
dd if=/dev/zero of=/test bs=1M count=500
524288000 bytes (524 MB) copied, 0.268589 s, 2.0 GB/s
dd if=/test of=/dev/null bs=1M count=500
524288000 bytes (524 MB) copied, 0.167294 s, 3.1 GB/s
Это примерно в 30 раз быстрее, чем HDD, и в 8 раз быстрее, чем SSD.
Продвинутый тест с помощью fio демонстрирует iops 349059 при случайном чтении и complete latency 0.29 микросекунд (латентность на два-три (десятичных) ПОРЯДКА меньше, чем у SSD):
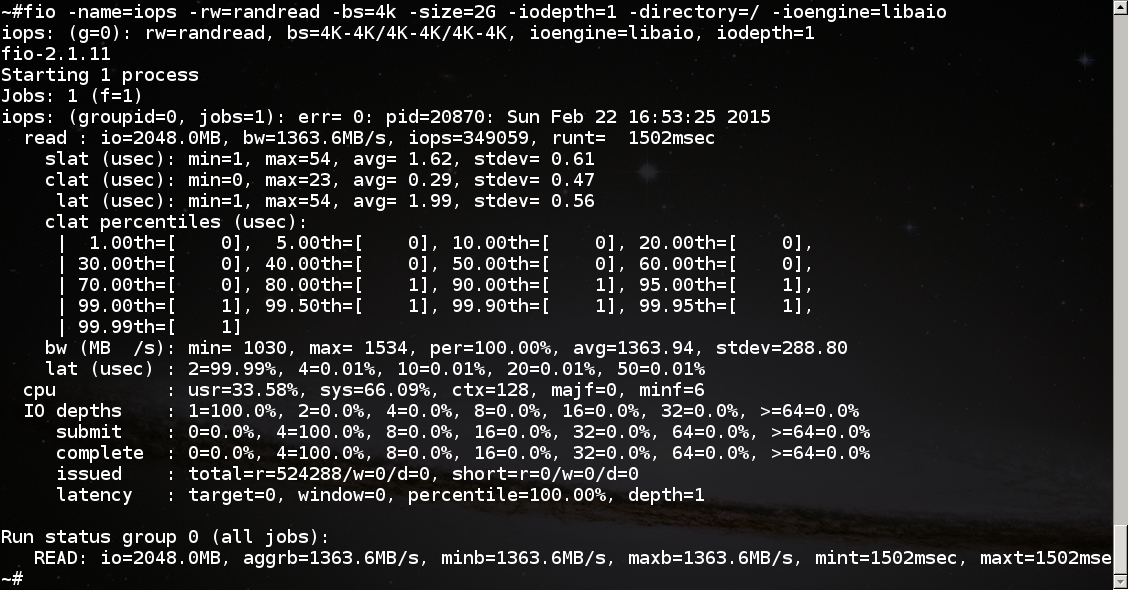
В работе
Вывод команды free в типовой рабочей ситуации:
total used free shared buffers cached
Mem: 16469572 3236968 13232604 2075372 65552 2687436
Сразу после загрузки используется около 2 гигабайт памяти, из которых 1.5 занимает файловая система. При наличии 16 гигабайт ОЗУ имеется большой простор для установки даже больших приложений, как LibreOffice или Blender. Размер файла ram.tar.gz примерно полгига, что позволяет хранить его, кернел и initrd на любой небольшой флешке или на CD. Жесткого диска может вообще не быть. Такая система неубиваема. Но главное — это, конечно, скорость работы.
В заключении тридцатисекундный скринкаст о фактической скорости запуска приложений в такой системе. Нет, это не открытие приложений из трея, это запуск программ с носителя, которым в данном случае является tmpfs:

До недавнего времени в Одноклассниках в качестве основного Linux-дистрибутива использовался частично обновлённый OpenSuSE 10.2. Однако, поддерживать его становилось всё труднее, поэтому с прошлого года мы перешли к активной миграции на CentOS 7. На подготовительном этапе перехода для CentOS были отработаны все внутренние процедуры, подготовлены конфиги и политики настройки (мы используем CFEngine). Поэтому сейчас во многих случаях миграция с одного дистрибутива на другой заключается в установке ОС через kickstart и развёртывании приложения с помощью системы деплоя нашей разработки — всё остальное осуществляется без участия человека. Так происходит во многих случаях, хотя и не во всех.
- 4 x 10 Гбит к пользователям
- 2 x 10 Гбит к хранилищу
- 256 Гбайт RAM — кэш в памяти
- 22 х 480 Гбайт SSD — кэша на SSD
- 2 х E5-2690 v2
Проблема 1 — сильный рост CPU system time

- увеличение sched_migration_cost
- отключение transparent_hugepage
- увеличение vfs_cache_pressure
- отключение NUMA
Фрагментация памяти — нередкая проблема (и характерна не только для Linux), и в ядро регулярно вносятся изменения для борьбы с ней. Одним из виновников фрагментации является само ядро, точнее дисковый кеш, который нельзя ни отключить, ни ограничить в объёме. Это не значит, что фрагментация в нашем случае была вызвана именно дисковым кешем, но точные причины были не так важны. Важнее было решение — дефрагментация. Такой механизм есть в ядре, но очевидно, что он не справлялся (либо вместо него запускалось высвобождение памяти — global reclaim). Дефрагментация запускается только тогда, когда свободная память опускается ниже определённой отметки (zone watermark), и в нашем случае это происходило слишком поздно. Единственный способ заставить её запускаться раньше — это повысить min_free_kbytes через sysctl. Данный параметр говорит ядру стараться держать часть памяти свободной, а чтобы удовлетворить это требование, ему приходится запускать дефрагментацию раньше. В нашем случае хватило значения в 1 Гбайт.
Проблема 2 — уход в swap
- Память делится на ноды: один физический процессор — одна нода.
- Каждая нода делится на зоны (представление для 64-битных систем) — ZONE_DMA (0-16 Мбайт), ZONE_DMA32 (0-4 Гбайт), ZONE_NORMAL (4+ Гбайт).
- Каждая зона делится на области памяти размером степеней двойки (order of 2), т.е. 2 0 *PAGE_SIZE, 2 1 *PAGE_SIZE. 2 10 *PAGE_SIZE (текущее распределение можно посмотреть в /proc/buddyinfo). Отсутствие свободных областей большого размера — это и есть фрагментация, о которой мы говорили в предыдущем разделе.
Сначала мы опять винили фрагментацию, но дальнейшее увеличение min_free_kbytes, а также увеличение vfs_cache_pressure нам не помогло. Пришлось познакомиться с утилитой numastat ( numastat -m ).
Но сначала ещё одно отступление про работу приложения раздачи видео. На сервере замонтирован tmpfs (занимает почти всю память), на котором приложение создаёт 1 файл и использует его в качестве кеша.
Что же мы увидели в выводе numastat? А то, что различные типы памяти распределены между нодами крайне неравномерно:
| Per-node process memory usage (in MBs) for PID 7781 (java) | |||
|---|---|---|---|
| Node 0 | Node 1 | Total | |
| Huge | 0 | 0 | 0 |
| Heap | 0.20 | 0.14 | 0.34 |
| Stack | 118.82 | 137.87 | 256.70 |
| Private | 80200.73 | 123323.81 | 203524.55 |
| Total | 80319.76 | 123461.82 | 203781.58 |
| Per-node system memory usage (in MBs): | |||
| Node 0 | Node 1 | Total | |
| MemTotal | 131032.75 | 131072.00 | 262104.75 |
| MemFree | 1228.93 | 639.84 | 1868.78 |
| MemUsed | 129803.82 | 130432.16 | 260235.98 |
| Active | 23224.13 | 121073.42 | 144297.55 |
| Inactive | 101138.88 | 3753.98 | 104892.85 |
| Active(anon) | 1690.50 | 120997.86 | 122688.36 |
| Inactive(anon) | 79528.66 | 3560.95 | 83089.61 |
| Active(file) | 21533.63 | 75.57 | 21609.20 |
| Inactive(file) | 21610.21 | 193.03 | 21803.24 |
| Unevictable | 0 | 0 | 0 |
| Mlocked | 0 | 0 | 0 |
| Dirty | 0.11 | 0.02 | 0.13 |
| Writeback | 0 | 0 | 0 |
| FilePages | 122397.46 | 124295.47 | 246692.93 |
| Mapped | 78436.03 | 122947.26 | 201383.29 |
| AnonPages | 1966.62 | 532.02 | 2498.64 |
| Shmem | 79251.21 | 123964.70 | 203215.90 |
| KernelStack | 2.44 | 2.57 | 5.01 |
| PageTables | 158.62 | 252.29 | 410.91 |
| NFS_Unstable | 0 | 0 | 0 |
| Bounce | 0 | 0 | 0 |
| WritebackTmp | 0 | 0 | 0 |
| Slab | 1801.95 | 1932.29 | 3734.23 |
| SReclaimable | 1653.13 | 1818.79 | 3471.92 |
| SUnreclaim | 148.82 | 113.49 | 262.31 |
| AnonHugePages | 1856.00 | 498.00 | 2354.00 |
| HugePages_Total | 0 | 0 | 0 |
| HugePages_Free | 0 | 0 | 0 |
| HugePages_Surp | 0 | 0 | 0 |
За распределение памяти между нодами отвечает технология NUMA, и она не может равномерно распределить 1 файл в tmpfs между нодами. Запуск приложения в режиме interleave (numactl —interleave=all, равномерное распределение памяти приложения между нодами) решило нашу проблему.
Проблема 3 — неравномерное распределение нагрузки по ядрам
Пожалуй, все, кто работал с большим трафиком, сталкивались с проблемой распределения прерываний между ядрами процессоров. Чаще всего проблема исследуется и решается так (здесь приведены все шаги, но не обязательно, что вы столкнётесь с каждым):
Волшебная цифра 16 — это максимальное количество очередей, на которое может распределить трафик RSS. Длина хеша RSS-индекса нормальная, но используются только последние 4 бита, поэтому максимальное количество очередей, которое он может выдать — 16. Это ограничение самой технологии и с ним ничего сделать нельзя.
Что касается конкретно карт Intel, то тут всё несколько интереснее. Во-первых, у карт есть возможность статически привязывать трафик на основе классификаторов к определённым очередям (причём классификация работает на стороне карты, без задействования ресурсов процессора). Мы не тестировали эту технологию, т.к. статическая конфигурация нам, в данном случае, не подходит.
Во-вторых, у карт есть Flow director.
Сразу оговорюсь, что в коде драйверов, в документации драйверов, в документации карт и в документации утилит часто используются разные термины для одних и тех же вещей, что порождает много путаницы. Надеюсь, нам удалось распутать этот клубок правильно.
Flow director
Flow director, судя по доке Intel, работает в 2 режимах — Signature Filter (он же ATR — Application Targeted Receive) и Perfect filter. Flow director не воспринимает не-IP пакеты, туннелированные пакеты и фрагментированные пакеты. Можно посмотреть статистику попавших/не попавших пакетов в flow director: ethtool -S ethN|grep fdir
Perfect filter (ntuple)
Может содержать не более 8 000 правил. Классификатор пакетов Perfect filter просматривается/настраивается через ethtool -u/U flow-type .
Signature Filter
Может содержать не более 32 000 правил. Согласно интернетам, ATR запоминает, в какую очередь (и на каком процессоре) _ушёл_ SYN пакет и направляет приходящие пакеты этого потока через ту же очередь.
During transmission of a packet (every 20 packets by default), a hash is calculated based on the 5-tuple. The (up to) 15-bit hash result is used as an index in a hash lookup table to store the TX queue. When a packet is received, a similar hash is calculated and used to look up an associated Receive Queue. For uni-directional incoming flows, the hash lookup tables will not be initialized and Flow Director will not work. For bidirectional flows, the core handling the interrupt will be the same as the core running the process handling the network flow.
Раз оно нам не помогает, то лучше отключить совсем — для этого делаем ethtool -k ethN ntuple on . Эта команда не только выключает ATR, но и включает Perfect filter, который, однако, без правил совсем никак не помогает, но и не мешает.
RPS (receive packet steering)
Чисто софтверный механизм. Технология номер 2 (после RSS) в уже упомянутом документе от разработчиков ядра — scaling.txt.
Прерывания не трогает вообще (можно распределить статически или через irq_balancer).
Изначально этот механизм был создан для распределения нагрузки по ядрам на картах с одной очередью. Однако, как мы теперь понимаем, он также хорош, когда количество очередей и ядер больше 16. Суть этого механизма в том, что независимо от того, в какую очередь пришёл пакет, обрабатываться он будет на ядре, выбранном по хешу. Хеш RPS, в отличие от RSS, может выдать результат больше 16 (т.к. использует его целиком), поэтому задействуются все ядра (если быть точнее, то в файле rps_cpus можно указать, какие конкретно ядра разрешено использовать).
Т.к. эта технология использует ресурсы процессора, то, конечно, есть некоторый оверхед, но он незначительный, т.к. самую тяжёлую операцию — расчёт хеша — всё равно делает карта. Не останавливаясь на достигнутом, продолжаем читать уже полюбившийся scaling.txt и находим там RFS.
RFS (receive flow steering)
Что же нам даёт замена одного слова в названии? При использовании этого механизма пакеты распределяются между ядрами не только на основе хеша, но и на основе того, на каком ядре висит тред приложения, ожидающий эти пакеты. Т.е. пакет отправляется не на фиксированное ядро, а туда, где его ждут, что ускоряет его обработку.
Разница хорошо видна на диаграммах[2]:
| RPS | RFS |
|---|---|
 |  |
Accelerated RFS
Чтобы закончить разбор технологий из scaling.txt, стоит также рассказать и про Accelerated RFS. Кто и что тут ускоряет? В случае с RFS работу по распределению пакетов по нужным ядрам в зависимости от хеша пакета выполняет центральный процессор. А в случае с Accelerated RFS этим занимается сетевая карта, снимая нагрузку с процессора. Но из известных нам сетевых адаптеров эту технологию на сегодняшний день поддерживает только Mellanox.
По счастливому совпадению, часть раздачи видео работает как раз на картах этого производителя. По несчастливому совпадению, каждая попытка включить этот режим заканчивается kernel panic.
В последних версиях драйвера проблема с падениями решена, но в этом режиме пропускная способность в нашей конфигурации оказалась значительно ниже. Похоже, что драйверы или firmware карт ещё не готовы к таким нагрузкам и режимам.
Проблема 4 — большое количество broken pipe
Регулярно появление ошибок broken pipe наблюдалось в приложении ещё на OpenSuSE, но с переходом на CentOS было принято решение положить этому конец. Тогда мы ещё не знали, сколько времени это займёт, ведь “пощупать” эти ошибки очень сложно.
Broken pipe — это ошибка, которая возникает, когда приложение не может записать данные в pipe. На одном конце pipe находится приложение, на другом — файл или соединение. Если пропадёт диск, на котором находится файл, или компьютер, с которым установлено соединение, то попытка записи в pipe завершится ошибкой broken pipe. В ходе изучения дампов трафика было замечено, что клиенты не просто пропадают, а закрывают соединения в ускоренном режиме (half-duplex tcp close sequence), что само по себе не является чем-то некорректным. Так почему же некоторые наши клиенты закрывают соединения не получив все данные и даже не пытаясь нормально закрыть соединение? Откуда такое безразличие к запрошенным данным и спешка? Дальнейшее расследование происходило исключительно эмпирическим путём, т.к. поймать такие эти ошибки на стороне клиентов и понять, что у них происходит, было бы слишком трудоёмким занятием. Поэтому поиск решения занял много времени.
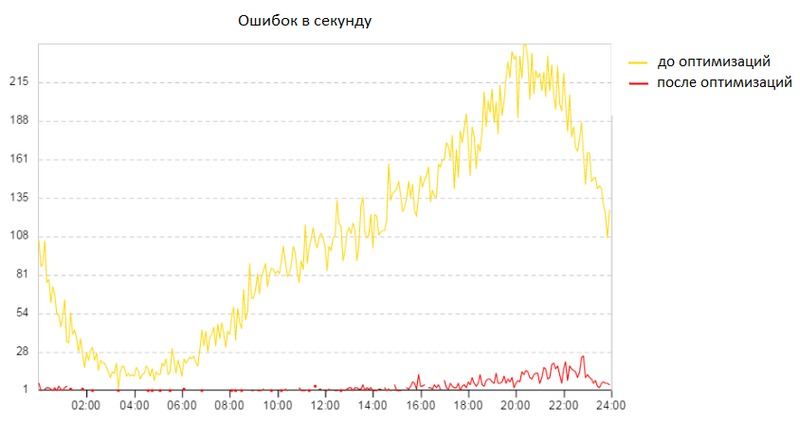
Второй фактор, который повлиял на снижение количества ошибок — это interrupt coalescing. Что это за зверь, рассказывается в следующей главе.
Проблема 5 — большое количество прерываний
Трафик бывает разный, и если фанаты Counter Strike крайне болезненно относятся к высокому latency, то для любителей торрентов (и любых других приложений, работающих с большим количеством трафика) куда важнее пропускная способность. Что касается раздачи видео, то это очень много трафика (десятки гигабит с сервера) и очень много пакетов (миллионы), а значит очень много процессорной нагрузки типа softirq. Во время тестов при пиковой нагрузке на сервер softirq мог достигать 50% от всей нагрузки на процессор.
Настройка, которая уменьшает нагрузку на CPU, — мечта любого админа. В данном случае нам помог interrupt coalescing, который настраивается через ethtool -c/-C . При увеличении параметров interrupt coalescing прерывания генерируются реже — не на каждый пакет, а сразу на пачку.
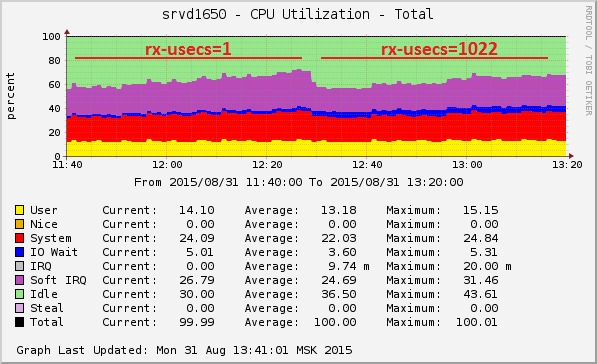
- [rx|tx]-usecs — максимальное время в микросекундах между получением пакета и генерированием прерывания
- [rx|tx]-frames — количество пакетов, после получения которого генерируется прерывание
- *-irq — то же самое для обновления статуса при отключенных прерываниях
- *-[low|high] — то же самое для адаптивного режима
Итоги
- дистрибутив, поддерживаемый до 2024 года [3]
- снижение количества ошибок broken pipe в 40 раз
- повышение производительности серверов (один сервер способен обработать 50 Гбит в секунду)
- опыт работы с различными новыми технологиями (а также политики CFEngine для их автоматического конфигурирования)
Постскриптум
В заключение хочется сказать спасибо нашим разработчикам, которые помогали в работе и оптимизировали приложение, а также коллегам-администраторам, благодаря которым у меня было время на все эти изыскания. Самые сложные задачи дают больше всего знаний, опыта и удовлетворения. Хотя и треплют нервы.
tmpfs is a temporary filesystem that resides in memory and/or swap partition(s). Mounting directories as tmpfs can be an effective way of speeding up accesses to their files, or to ensure that their contents are automatically cleared upon reboot.
Tip: Temporary files in tmpfs directories can be recreated at boot by using systemd-tmpfiles.Contents
Usage
Some directories where tmpfs(5) is commonly used are /tmp, /var/lock and /var/run. Do not use it on /var/tmp, because that folder is meant for temporary files that are preserved across reboots.
Arch uses a tmpfs /run directory, with /var/run and /var/lock simply existing as symlinks for compatibility. It is also used for /tmp by the default systemd setup and does not require an entry in fstab unless a specific configuration is needed.
glibc 2.2 and above expects tmpfs to be mounted at /dev/shm for POSIX shared memory. Mounting tmpfs at /dev/shm is handled automatically by systemd and manual configuration in fstab is not necessary.
Generally, tasks and programs that run frequent read/write operations can benefit from using a tmpfs folder. Some applications can even receive a substantial gain by offloading some (or all) of their data onto the shared memory. For example, relocating the Firefox profile into RAM shows a significant improvement in performance.
Examples
Note: The actual memory/swap consumption depends on how much is used, as tmpfs partitions do not consume any memory until it is actually needed.By default, a tmpfs partition has its maximum size set to half of the available RAM, however it is possible to overrule this value. To explicitly set a maximum size, in this example to override the default /tmp mount, use the size mount option:
To specify a more secure mounting, specify the following mount option:
Reboot for the changes to take effect. Note that although it may be tempting to simply run mount -a to make the changes effective immediately, this will make any files currently residing in these directories inaccessible (this is especially problematic for running programs with lockfiles, for example). However, if all of them are empty, it should be safe to run mount -a instead of rebooting (or mount them individually).
After applying changes, verify that they took effect by looking at /proc/mounts and using findmnt :
The tmpfs can also be temporarily resized without the need to reboot, for example when a large compile job needs to run soon. In this case, run:
Disable automatic mount
Under systemd, /tmp is automatically mounted as a tmpfs, if it is not already a dedicated mountpoint (either tmpfs or on-disk) in /etc/fstab . To disable the automatic mount, mask the tmp.mount systemd unit.
Files will no longer be stored in a tmpfs, but on the block device instead. The /tmp contents will now be preserved between reboots, which might not be the desired behavior. To regain the previous behavior and clean the /tmp folder automatically when restarting, consider using tmpfiles.d(5) :
Troubleshooting
Opening symlinks in tmpfs as root fails
Considering /tmp is using tmpfs, change the current directory to /tmp , then create a file and create a symlink to that file in the same /tmp directory. Permission denied errors are to be expected when attempting to read the symlink due to /tmp having the sticky bit set.
Читайте также: