
Локальный компьютер не входит в отказоустойчивый кластер windows
Настраиваем отказоустойчивый кластер Hyper-V на базе Windows Server 2012
Уже на этапе планирования будущей виртуальной инфраструктуры следует задуматься об обеспечении высокой доступности ваших виртуальных машин. Если в обычной ситуации временная недоступность одного из серверов еще может быть приемлема, то в случае остановки хоста Hyper-V недоступной окажется значительная часть инфраструктуры. В связи с чем резко вырастает сложность администрирования - остановить или перезагрузить хост в рабочее время практически невозможно, а в случае отказа оборудования или программного сбоя получим ЧП уровня предприятия.
Все это способно серьезно охладить энтузиазм по поводу преимуществ виртуализации, но выход есть и заключается он в создании кластера высокой доступности. Мы уже упоминали о том, что термин "отказоустойчивый" не совсем корректен и поэтому сегодня все чаще используется другая характеристика, более точно отражающая положение дел - "высокодоступный".
Для создания полноценной отказоустойчивой системы требуется исключить любые точки отказа, что в большинстве случаев требует серьезных финансовых вложений. В тоже время большинство ситуаций допускает наличие некоторых точек отказа, если устранение последствий их отказа обойдется дешевле, чем вложение в инфраструктуру. Например, можно отказаться от недешевого отказоустойчивого хранилища в пользу двух недорогих серверов с достаточным числом корзин, один из которых настроен на холодный резерв, в случае отказа первого сервера просто переставляем диски и включаем второй.
В данном материале мы будем рассматривать наиболее простую конфигурацию отказоустойчивого кластера, состоящего из двух узлов (нод) SRV12R2-NODE1 и SRV12R2-NODE2, каждый из которых работает под управлением Windows Server 2012 R2. Обязательным условием для этих серверов является применение процессоров одного производителя, только Intel или только AMD, в противном случае миграция виртуальных машин между узлами будет невозможна. Каждый узел должен быть подключен к двум сетям: сети предприятия LAN и сети хранения данных SAN.
Вторым обязательным условием для создания кластера является наличие развернутой Active Directory, в нашей схеме она представлена контроллером домена SRV12R2-DC1.
Хранилище выполнено по технологии iSCSI и может быть реализовано на любой подходящей платформе, в данном случае это еще один сервер на Windows Server 2012 R2 - SRV12R2-STOR. Сервер хранилища может быть подключен к сети предприятия и являться членом домена, но это необязательное условие. Пропускная способность сети хранения данных должна быть не ниже 1 Гбит/с.
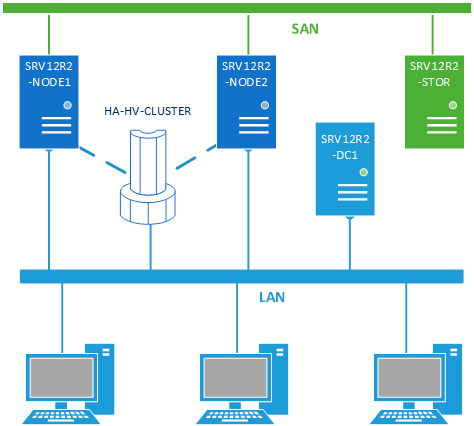
Будем считать, что на оба узла уже установлена операционная система, они введены в домен и сетевые подключения настроены. Откроем Мастер добавления ролей и компонентов и добавим роль Hyper-V.
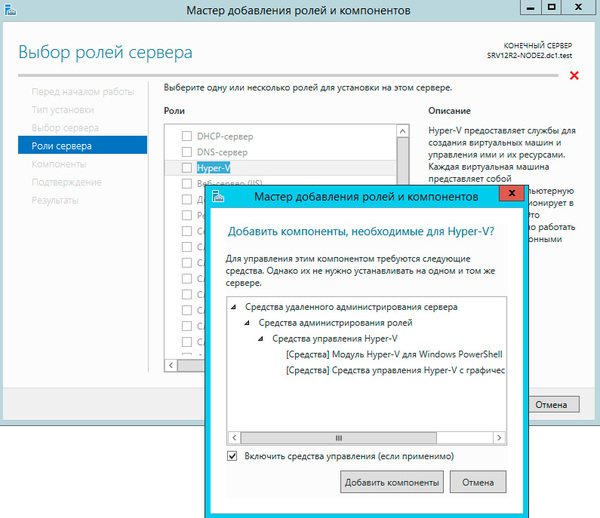
Следующим шагом добавим компоненту Отказоустойчивая кластеризация.
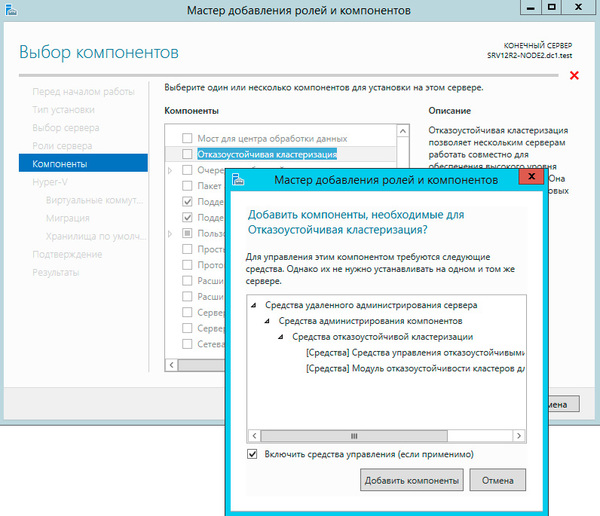
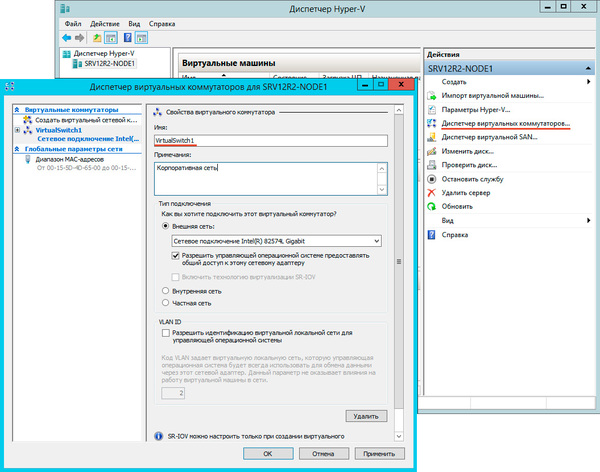
На странице настройки виртуальных коммутаторов выбираем тот сетевой адаптер, который подключен к сети предприятия.

Миграцию виртуальных машин оставляем выключенной.
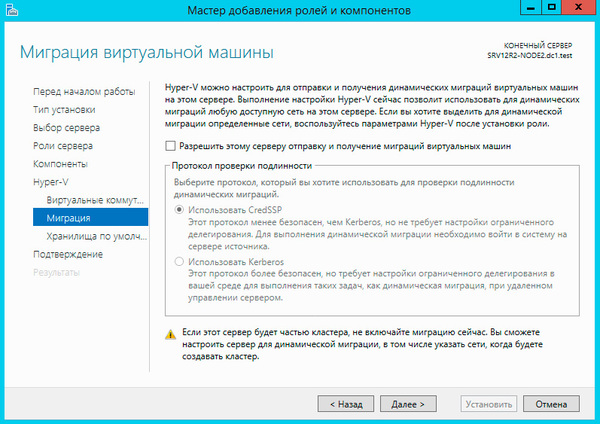
Остальные параметры оставляем без изменения. Установка роли Hyper-V потребует перезагрузку, после чего аналогичным образом настраиваем второй узел.
Затем перейдем к серверу хранилища, как настроить iSCSI-хранилище на базе Windows Server 2012 мы рассказывали в данной статье, но это непринципиально, вы можете использовать любой сервер цели iSCSI. Для нормальной работы кластера нам потребуется создать минимум два виртуальных диска: диск свидетеля кворума и диск для хранения виртуальных машин. Диск-свидетель - это служебный ресурс кластера, в рамках данной статьи мы не будем касаться его роли и механизма работы, для него достаточно выделить минимальный размер, в нашем случае 1ГБ.
Создайте новую цель iSCSI и разрешите доступ к ней двум инициаторам, в качестве которых будут выступать узлы кластера.
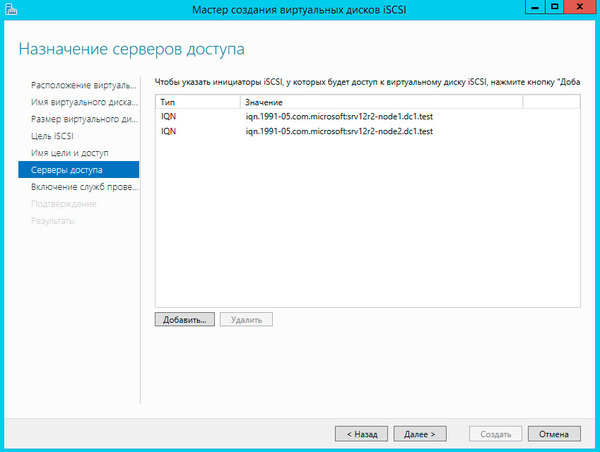
И сопоставьте данной цели созданные виртуальные диски.
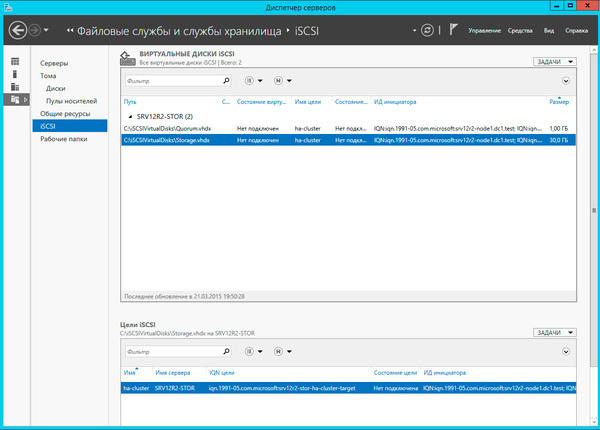
Настроив хранилище, вернемся на один из узлов и подключим диски из хранилища. Помните, что если сервер хранилища подключен также к локальной сети, то при подключении к цели iSCSI укажите для доступа сеть хранения данных.
Подключенные диски инициализируем и форматируем.
После чего откроем Диспетчер Hyper-V и перейдем к настройке виртуальных коммутаторов. Их название на обоих узлах должно полностью совпадать.
Теперь у нас все готово к созданию кластера. Запустим оснастку Диспетчер отказоустойчивых кластеров и выберем действие Проверить конфигурацию.
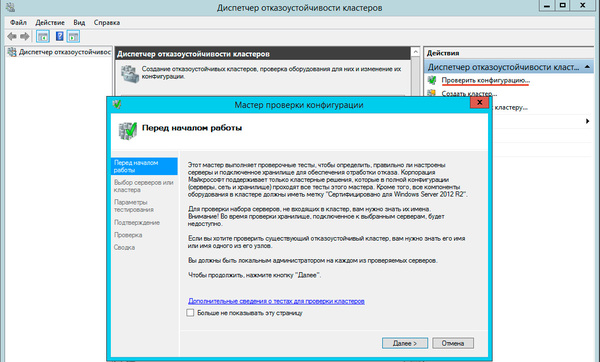
В настройках мастера добавим настроенные нами узлы и выберем выполнение всех тестов.
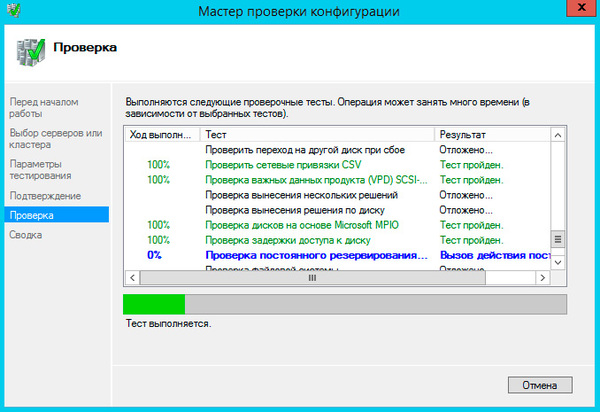
Если существенных ошибок не обнаружено работа мастера завершится и он предложит вам создать на выбранных узлах кластер.
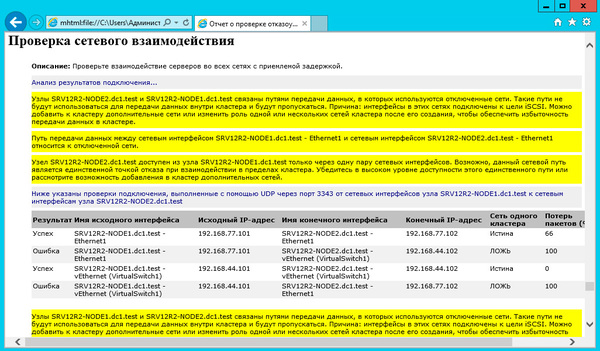
При создании кластера для него создается виртуальный объект, обладающий сетевым именем и адресом. Укажем их в открывшемся Мастере создания кластеров.
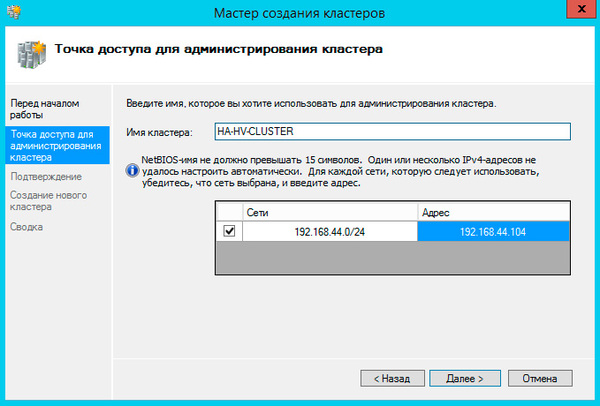
На следующем шаге советуем снять флажок Добавление всех допустимых хранилищ в кластер, так как мастер не всегда правильно назначает роли дискам и все равно придется проверять и, при необходимости исправлять, вручную.
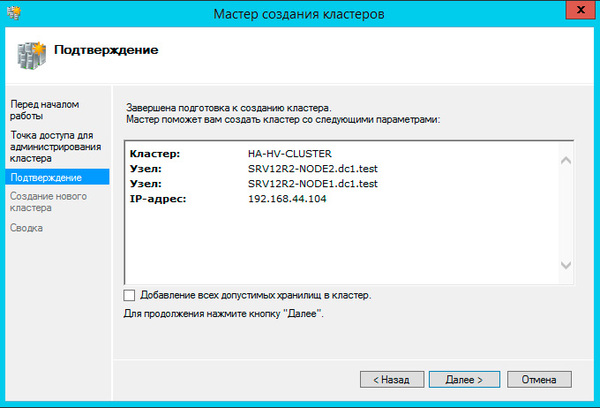
Больше вопросов не последует и мастер сообщит нам, что кластер создан, выдав при этом предупреждение об отсутствии диска-свидетеля.
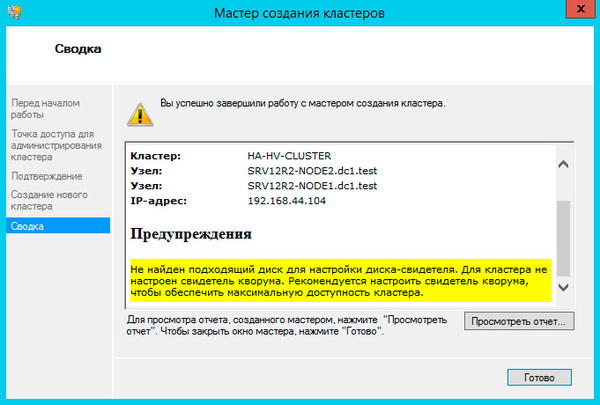
Закроем мастер и развернем дерево слева до уровня Хранилище - Диски, в доступных действиях справа выберем Добавить диск и укажем подключаемые диски в открывшемся окне, в нашем случае их два.
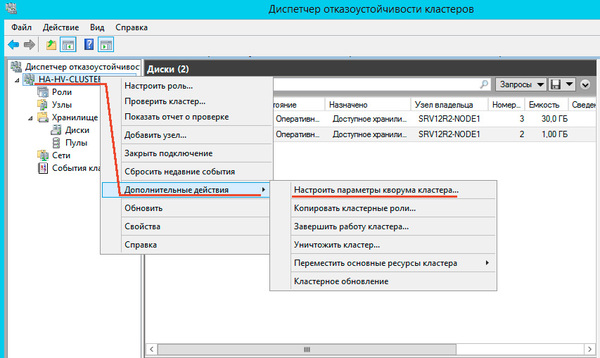
Далее последовательно выбираем: Выбрать свидетель кворума - Настроить диск-свидетель и указываем созданный для этих целей диск.
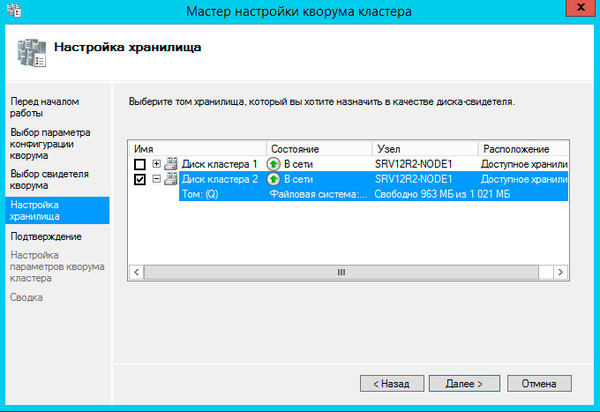
Теперь настроим диск хранилища, с ним все гораздо проще, просто щелкаем на диске правой кнопкой и указываем: Добавить в общие хранилища кластера.
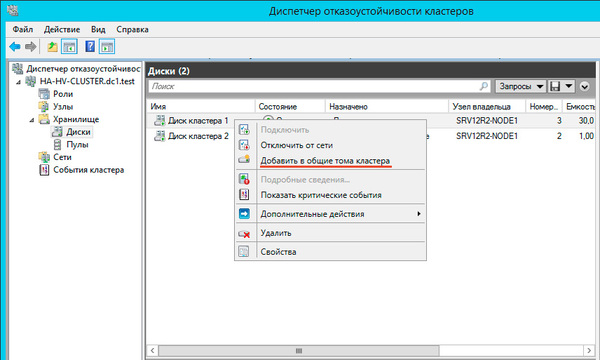
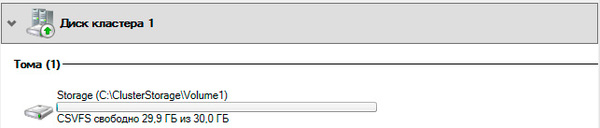
Для того, чтобы диск мог использоваться сразу несколькими участниками кластера на нем создается CSVFS - реализуемая поверх NTFS кластерная файловая система, впервые появившаяся в Windows Server 2008 R2 и позволяющая использовать такие функции как Динамическая (Живая) миграция, т.е. передачу виртуальной машины между узлами кластера без остановки ее работы.
Общие хранилища становятся доступны на всех узлах кластера в расположении C:\ClusterStorage\VolumeN. Обратите внимание, что это не просто папки на системном диске, а точки монтирования общих томов кластера.
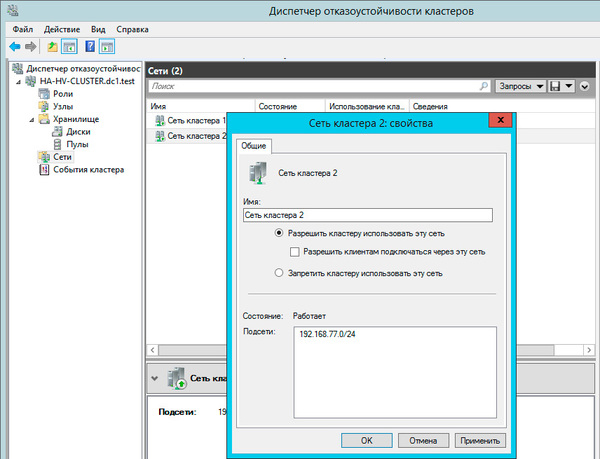
Закончив с дисками, перейдем к настройкам сети, для этого перейдем в раздел Сети. Для сети, которая подключена к сети предприятия указываем Разрешить кластеру использовать эту сеть и Разрешить клиентам подключаться через эту сеть. Для сети хранения данных просто оставим Разрешить кластеру использовать эту сеть, таким образом обеспечив необходимую избыточность сетевых соединений.
На этом настройка кластера закончена. Для работы с кластеризованными виртуальными машинами следует использовать Диспетчер отказоустойчивости кластеров, а не Диспетчер Hyper-V, который предназначен для управления виртуалками расположенными локально.
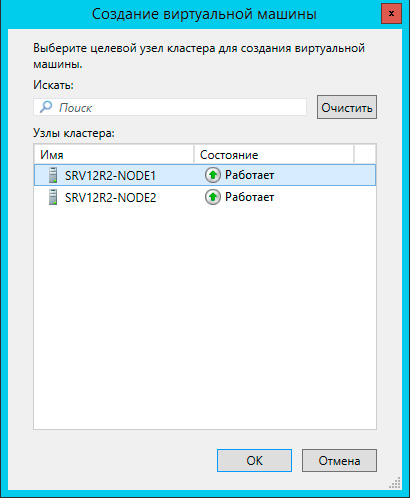
Чтобы создать виртуальную машину перейдите в раздел Роли в меню правой кнопки мыши выберите Виртуальные машины - Создать виртуальную машину, это же можно сделать и через панель Действия справа.

Прежде всего выберите узел, на котором будет создана виртуальная машина. Каждая виртуалка работает на определенном узле кластера, мигрируя на другие узлы при остановке или отказе своей ноды.
После выбора узла откроется стандартный Мастер создания виртуальной машины, работа с ним не представляет сложности, поэтому остановимся только на значимых моментах. В качестве расположения виртуальной машины обязательно укажите один из общих томов кластера C:\ClusterStorage\VolumeN.
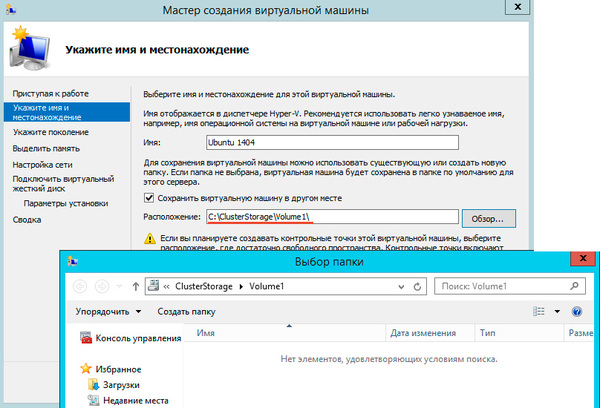
Здесь же должен располагаться и виртуальный жесткий диск, вы также можете использовать уже существующие виртуальные жесткие диски, предварительно скопировав их в общее хранилище.
После создания виртуальной машины перейдите в ее Параметры и в пункте Процессоры - Совместимость установите флажок Выполнить перенос на физический компьютер с другой версией процессора, это позволит выполнять миграцию между узлами с разными моделями процессоров одного производителя. Миграция с Intel на AMD или наоборот невозможна.
Не забудьте настроить автоматические действия при запуске и завершении работы узла, при большом количестве виртуальных машин не забывайте устанавливать задержку запуска, чтобы избежать чрезмерной нагрузки на систему.
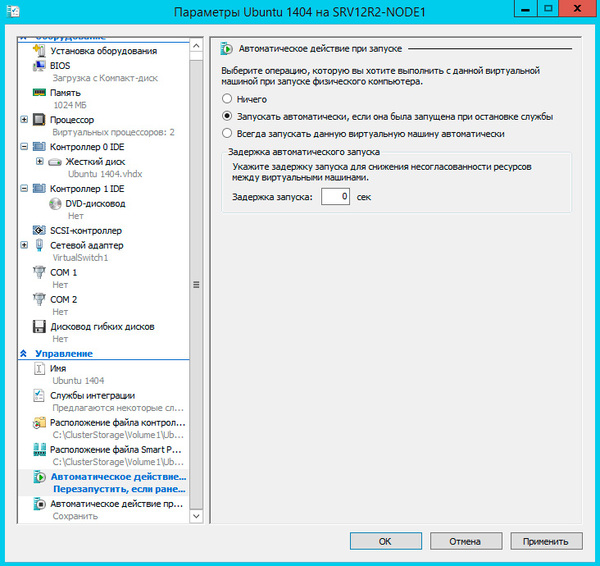
Закончив с Параметрами перейдите в Свойства виртуальной машины и укажите предпочтительные узлы владельцев данной роли в порядке убывания и приоритет, машины имеющие более высокий приоритет мигрируют первыми.
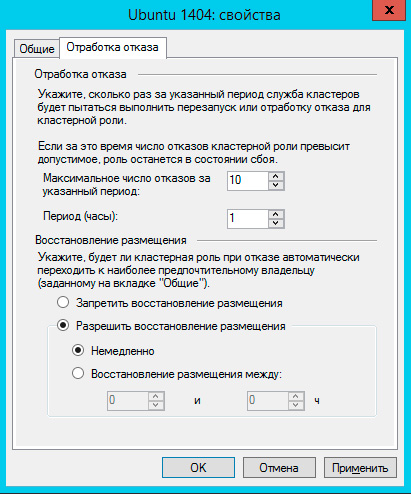
На закладке Обработка отказа задайте количество допустимых отказов для виртуальной машины за единицу времени, помните, что отказом считается не только отказ узла, но и потеря пульса виртуальной машины, например, ее зависание. На время настройки и тестов есть смысл указать значения побольше.
Также настройте Восстановление размещения, эта опция позволяет передавать виртуальные машины обратно наиболее предпочтительному владельцу при восстановлении его нормальной работы. Чтобы избежать чрезмерных нагрузок воспользуйтесь опцией задержки восстановления.
На этом настройка виртуальной машины закончена, можем запускать и работать с ней.
Теперь самое время проверить миграцию, для этого щелкните на машине правой кнопкой мыши и выберите Переместить - Динамическая миграция - Выбрать узел. Виртуалка должна переместиться на выбранную ноду не завершая работы.
Каким образом происходит миграция в рабочей обстановке? Допустим нам надо выключить или перезагрузить первый узел, на котором в данный момент выполняется виртуальная машина. Получив команду на завершение работы узел инициирует передачу виртуальных машин:

Завершение работы приостанавливается до тех пор, пока не будут переданы все виртуальные машины.

Когда работа узла будет восстановлена, кластер, если включено восстановление размещения, инициирует обратный процесс, передавая виртуальную машину назад предпочтительному владельцу.

Что произойдет если узел, на котором размещены виртуальные машины аварийно выключится или перезагрузится? Все виртуалки также аварийно завершат свою работу, но тут-же будут перезапущены на исправных узлах согласно списка предпочтительных владельцев.
Как мы уже говорили, прижившийся в отечественной технической литературе термин "отказоустойчивый" неверен и более правильно его было бы переводить как "с обработкой отказа", либо использовать понятие "высокая доступность", которое отражает положение дел наиболее верно.
Кластер Hyper-V не обеспечивает отказоустойчивости виртуальным машинам, отказ узла приводит к отказу всех размещенных на нем машин, но он позволяет обеспечить вашим службам высокую доступность, автоматически восстанавливая их работу и обеспечивая минимально возможное время простоя. Также он позволяет значительно облегчить администрирование виртуальной инфраструктуры позволяя перемещать виртуальные машины между узлами без прерывания их работы.
Я работаю в группе, которая занимается поддержкой отказоустойчивых кластеров, поэтому мне часто приходится выявлять и устранять неисправности. В этой статье будут описаны типичные проблемы, с которыми я сталкивался, с пояснением причин их возникновения и рекомендациями по их устранению
Проблема 1
Служба кластеров при запуске обнаруживает сети, в которые входит узел, и для каждой сети определяет сетевые адаптеры. Одна из типичных неполадок связана с тем, что отказоустойчивая кластеризация Windows Server (WSFC) допускает использование для одной сети только одного сетевого адаптера. Все прочие адаптеры этой сети игнорируются.
Предположим, что администратор настроил узел с двумя сетевыми адаптерами для одной сети:
Сетевой драйвер кластера (Netft.sys) для каждой сети будет использовать только один сетевой адаптер (или группу). Поэтому при данной конфигурации сеть кластера Cluster Network 1 (10.10.10.0/16) будет задействовать только сетевой адаптер Card1, тогда как сетевой адаптер Card2 будет игнорироваться, то есть не будет применяться для связи между узлами. Поскольку работает только одна сеть, при выходе Card1 из строя или утрате сетевого соединения узел не сможет взаимодействовать с другими узлами. Это единственная точка отказа. Чтобы избежать подобной ситуации, кластер следует настраивать так, чтобы между узлами существовало, как минимум, два сетевых пути. В этом случае при отказе одного из сетевых адаптеров связь между узлами будет осуществляться через другой сетевой адаптер.
Проблема 2
Вторую типичную проблему проще всего раскрыть с помощью сценариев. Опишем ее на примере двух различных конфигураций кластера: односайтовой и многосайтовой.
Односайтовый кластер. Предположим, что администратор решил изменить конфигурацию кластера, установив две сети между узлами Node1 и Node2. На узле Node1 он поменял IP-адреса и маски подсети сетевых адаптеров:
Кроме того, администратор поменял IP-адреса узла Node2 (192.168.0.2 и 10.10.10.2). При этом на узле Node1 в кластере он добавил группу файлового сервера, назначив ей IP-адрес 192.168.0.15.
Затем администратор протестировал кластер, чтобы убедиться в успешном переходе группы файлового сервера на узел Node2 при отработке отказа. Однако IP-адрес группы файлового сервера не виден в сети, то есть группа находится в автономном состоянии. В журнале событий системы регистрируется событие 1069, описание которого указывает на отказ ресурса с этим IP-адресом.
Причина отказа становится очевидной, если воспользоваться командой PowerShell Get-ClusterLog для вывода журнала кластера. Для этого достаточно ввести следующий набор символов:
Команда инициирует создание журнала кластера на каждом узле. Для построения журнала кластера только на одном узле можно добавить параметр -Node и указать имя узла. Можно также добавить параметр -TimeSpan для создания журнала только за последние x минут. Например, приведенная ниже команда предписывает построить журнал кластера на узле Node2 за последние 15 минут:
В результатах, представленных на экране 1, указано состояние «status 5035.».
.jpg) |
| Экран 1. Информация о состоянии 5035 в файле журнала кластера |
Создавая ресурс с IP-адресом, можно указать сеть, которая будет использоваться для него. Если эта сеть не будет существовать на узле, куда данный ресурс перейдет при отработке отказа, то WSFC не поменяет сеть, используемую ресурсом. В данном примере, при том IP-адресе, который указал администратор, и маске подсети, применяемой этим IP-адресом, группа файлового сервера сможет работать только по сети Cluster Network 1 (192.168.0.0/24).
Многосайтовый кластер. В случае многосайтового кластера каждый узел обычно имеет собственную сеть со своим IP-адресом. При первоначальном создании кластера и его ролей с помощью мастера создания ресурсов вам предлагается указать IP-адрес для сетей каждого из узлов, настроенных для клиентского доступа (см. экран 2).
.jpg) |
| Экран 2. Создание многосайтового кластера |
Мастер создания ресурсов, создавая IP-адреса и назначая имя сети, автоматически присваивает параметру зависимости этого имени сети значение «или». Это означает, что если один из IP-адресов в сети, имя также видно в сети. Создавая группы или ресурсы перед добавлением узлов из других сетей, необходимо вручную создавать эти вторичные IP-адреса и добавлять зависимость «или».
Проблема 3
Для формирования кластера необязательно быть администратором домена, но создание объектов в Active Directory (AD) требует наличия соответствующих прав. Как минимум, необходимо обладать правами на просмотр и создание объектов (Read and Create) в том подразделении (OU), где создается данный объект имени кластера (CNO). CNO – это объект-компьютер, связанный с ресурсом-кластером «Имя кластера». При создании кластера служба WSFC использует учетную запись, с которой вы регистрировались в системе, чтобы создать объект CNO в том же OU, которому принадлежат узлы. Если вы не обладаете достаточными правами в отношении данного OU, кластер не будет создан, и система выдаст ошибку, как показано на экране 3.
.jpg) |
| Экран 3. Ошибка процесса создания кластера |
В статье «Диагностика проблем отказоустойчивых кластеров Windows Server 2012» (№ 10 за 2013 г.) я рассказывал об использовании мастера проверки конфигурации в диспетчере отказоустойчивости кластеров для выявления причин возникающих проблем. Мастер позволяет выполнять различные тесты, включая проверку настроек Active Directory. В ответ на попытку запуска этого теста без достаточных прав в отношении данного OU будет выдана ошибка, как показано на экране 4. Соответствующая настройка прав позволит вам создать кластер.
.jpg) |
| Экран 4. Ошибка проверки настроек Active Directory |
Все другие ресурсы с сетевыми именами в кластере ассоциированы с объектами виртуальных компьютеров (VCO), создаваемыми в том же OU, что и CNO. Следовательно, при назначении ролей в кластере необходимо указать CNO с соответствующими правами (просмотр и создание) в отношении OU, поскольку CNO формирует все VCO в кластере. В противном случае новая роль будет находиться в состоянии сбоя. Тогда в журнале появится событие 1194 (см. экран 5).
.jpg) |
| Экран 5. Событие 1194 в журнале событий системы |
Есть и другие установки локального компьютера, способные вызвать ошибки (включая ошибки отказа в доступе) при создании VCO в AD.
1. В составе локальной группы «Пользователи» больше нет группы «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
2. В локальной политике безопасности разрешение Access this computer from the network («Доступ к этому компьютеру по сети») или Add workstations to the domain («Добавление рабочих станций к домену») больше не включает группу «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
3. Включены следующие права доступа:
- сетевой доступ (не разрешать перечисление учетных записей SAM анонимными пользователями);
- сетевой доступ (не разрешать перечисление учетных записей SAM и общих ресурсов анонимными пользователями).
4. Ресурс имени кластера в состоянии сбоя.
Проблема 4
CNO и VCO – учетные записи компьютера и, подобно учетным записям пользователей, они имеют пароли, генерируемые AD случайным образом. По умолчанию политика домена предусматривает сброс пароля учетной записи компьютера каждые 60 дней.
СNO используется для таких операций, как добавление новых узлов к кластеру, создание новых объектов в домене и выполнение динамической миграции виртуальных машин с узла на узел. Для выполнения этих операций пароль CNO в домене должен быть актуальным. Для верности служба кластера делает попытку сброса паролей этих объектов по истечении половины срока (через 30 дней). Если пароль не сброшен на 60-дневной отметке, имя кластера не видно в сети.
Для сброса пароля необходимо выполнить восстановление в диспетчере отказоустойчивости кластеров. Как показано на экране 6, щелкните правой кнопкой имя проблемного ресурса и выберите «Дополнительные действия» и «Восстановить».
.jpg) |
| Экран 6. Сброс пароля вручную в диспетчере отказоустойчивости кластеров |
При обращении к AD для сброса пароля диспетчер отказоустойчивости кластеров задействует учетную запись пользователя, под которой вы зарегистрировались в системе, поэтому вашей учетной записи должно быть предоставлено право на изменение пароля CNO; в противном случае восстановление не будет выполнено. Необходимо также убедиться, что включено разрешение на сброс пароля CNO и VCO, чтобы служба WSFC могла выполнять сброс при необходимости.
Проблема 5
Чтобы узел был осведомлен о том, какие узлы являются активными участниками кластера (то есть о текущем членстве), применяется ряд периодических контрольных сигналов, передаваемых между узлами по сети. Эти пакеты сигналов представляют собой UDP-датаграммы, следующие через порт 3343.
Каждый пакет включает регистрационный номер, по которому отслеживается факт приема пакета. Это работает следующим образом: узел Node1, отправляющий регистрационный номер 1111, ожидает ответного пакета, включающего 1111. Эти действия совершаются между всеми узлами каждую секунду. Если узел Node1 не получает ответного пакета, он отправляет следующий по порядку регистрационный номер (1112), и т.д.
По умолчанию, если узел не получает пять контрольных сигналов в течение пяти секунд, WSFC устанавливает факт отказа узла. Активный узел в кластере отправляет пакет на узел, где установлен отказ, чтобы завершить работу службы кластера, и регистрирует событие 1135 в журнале событий системы (см. экран 7).
.jpg) |
| Экран 7. Событие 1135 в журнале событий системы |
Такое событие может быть вызвано несколькими причинами, многие из которых связаны с блокировкой связи через порт 3343:
1. Отказ сетевого оборудования.
2. Устаревший драйвер или устаревшая прошивка сетевого адаптера.
3. Сетевая задержка.
4. Протокол IPv6 разрешен на серверах, но параметры брандмауэра Windows выключают следующие разрешения для входящего и исходящего трафика:
- основы сетей – объявление поиска соседей;
- основы сетей – запрос поиска соседей.
5. Настройка коммутаторов, брандмауэров или маршрутизаторов не допускает прохождения трафика данных UDP-датаграмм.
6. Проблемы производительности (зависания, задержки и прочее).
7. Неправильно настроенные параметры буфера приема у драйвера сетевого адаптера.
Первым делом я всегда проверяю счетчик отброшенных принятых пакетов в составе объекта производительности сетевого интерфейса в окне системного монитора. Этот счетчик отслеживает число входящих пакетов, которые были отброшены, хотя и не было зафиксировано каких-либо ошибок, препятствующих их передаче протоколу верхнего уровня. Одна из возможных причин – необходимость освободить место в буфере.
Для добавления счетчика отброшенных принятых пакетов в окне системного монитора щелкните правой кнопкой на дисплее и выберите «Добавить счетчики». В открывшемся окне добавления счетчиков укажите нужный компьютер, выполните прокрутку и выберите счетчик «Отброшено принятых пакетов». В выпадающем списке «Экземпляры выбранного объекта» выберите нужный сетевой адаптер и нажмите «Добавить» (см. экран 8).
Добавив счетчик, проверьте его среднее, минимальное и максимальное значения. Если есть значения больше нуля, это указывает на необходимость настройки буфера приема для сетевого адаптера. Проконсультируйтесь с производителем сетевого адаптера по поводу рекомендуемых параметров. Может потребоваться перезагрузка.
В отказоустойчивом кластере Windows Server 2012 R2 можно воспользоваться мастером проверки конфигурации для выполнения проверки сетевого взаимодействия. Этот тест позволяет проверить возможность информационного обмена между узлами через порт 3343. Если есть проблемы связи, то будет выдана соответствующая ошибка с указанием возможной причины.
Проблема 6
В листинге приведен сценарий Windows PowerShell, позволяющий выявить узел, утративший экземпляр Cluster WMI.
Установив проблемный узел, можно ввести команду
Наиболее распространенной причиной утраты Cluswmi.mof узлом является устаревший способ решения проблем WMI. Для устранения неполадок WMI администраторы обычно используют команду Mofcomp.exe *.mof, позволяющую скомпилировать все файлы Managed Object Format (MOF) в репозиторий WMI. Однако дело в том, что существует довольно много файлов удаления для различных ролей и компонентов Windows, включая Cluster WMI. Поэтому файл Cluswmi.mof, устанавливаемый с помощью этой команды, впоследствии удаляется. Правильный способ восстановления репозитория WMI – с использованием команды Winmgmt.exe.
Ошибку легче предупредить
Как известно, предупредить ошибку легче, чем исправлять ее последствия. Поэтому в заключение повторю простое правило: регулярно актуализируйте состояние своих систем, применяя все обновления и исправления, касающиеся безопасности. Команда разработчиков отказоустойчивой кластеризации в Microsoft опубликовала материалы с перечнями исправлений, которые рекомендуется применить на всех кластерах. Каждой версии Windows посвящена отдельная публикация:
Материалы обновляются по мере необходимости, поэтому всегда актуальны. Замечу, что в них перечислены не все исправления, а лишь самые критичные для обеспечения стабильной работы и наиболее востребованные, исходя из числа обращений в службу поддержки Microsoft.
Листинг. Сценарий PowerShell для определения узлов с отсутствующим экземпляром Cluster WMI
Опыта построения и настройки отказоустойчивых кластеров не было. Сервер уже настроен был. Построен на Windows Server 2012. 2 узла.
Сегодня в разгар рабочего дня с одного нода на другой переехал основной рабочий сервер 1С. При этом не совсем удачно (серве (виртуальная машина) потух - пришлось его включать).
Узел "n1" лишен членства в активном отказоустойчивом кластере. Возможно, служба кластеров на этом узле была остановлена. Это также могло произойти из-за потери связи между данным узлом и другими активными узлами в отказоустойчивом кластере. Чтобы проверить параметры сети, запустите мастер проверки конфигурации. Если это не поможет, проверьте оборудование или программное обеспечение на наличие ошибок, связанных с сетевыми адаптерами на данном узле. Также проверьте работу других сетевых устройств, к которым подключен этот узел, таких как концентраторы, коммутаторы и мосты. Сетевой интерфейс кластера "n2 - Claster" для узла "n2" недоступен по сети "Сеть кластера" по крайней мере одному другому узлу кластера, подключенному к этой сети. Отказоустойчивому кластеру не удалось определить источник ошибки. Для проверки сети запустите мастер проверки конфигурации. Если это не поможет, проверьте оборудование или программное обеспечение на наличие ошибок, связанных с сетевым адаптером. Кроме того, проверьте работу других сетевых устройств, к которым подключен этот узел, таких как концентраторы, коммутаторы и мосты. Сеть кластера "Сеть кластера" разделена. Некоторые подключенные узлы отказоустойчивого кластера не смогут взаимодействовать с другими через сеть. Отказоустойчивому кластеру не удалось определить источник ошибки. Для проверки сети запустите мастер проверки конфигурации. Если это не поможет, проверьте оборудование или программное обеспечение на наличие ошибок, связанных с сетевым адаптером. Кроме того, проверьте работу других сетевых устройств, к которым подключен этот узел, таких как концентраторы, коммутаторы и мосты.Пока ничего не предпринималось, работу останавливать нельзя. Может кто сталкивался с подобным - подскажите с чего начать?
Сетевой интерфейс "n2 - Claster" непосредственно соединяется шнурком напрямую через высокоскоростной порт.
Сейчас в центре управления сетями стоит у него тип сети "Неопознанная сеть / Общедоступная сеть". Может ли с этим быть связано? Брэндмауэр включен.
В прошлом месяце я рассмотрел некоторые наиболее популярные сложности с отказоустойчивыми кластерами в Windows Server 2008 R2 и рассказал о способах корректного устранения этих неполадок.
Вспомните, что текущая политика поддержки предполагает, что решение отказоустойчивой кластеризации в Windows Server 2008 и Windows Server 2008 R2 может считаться официально поддерживаемым службой поддержки потребителей Microsoft (Customer Support Services, CSS), только если удовлетворяет следующим критериям:
- Все компоненты, включая оборудование и программное обеспечение, должны удовлетворять требованиям для получения логотипа "Certified for Windows Server 2008 R2".
- Окончательно настроенное решение должно пройти проверочный тест в оснастке "Failover Cluster Management" (Управление отказоустойчивыми кластерами).
Есть несколько сценариев устранения неполадок. Они представляют самые популярные неполадки отказоустойчивых кластеров Windows Server 2008 R2 и шаги по их устранению.
Сценарий 1. В процессе ежемесячной очистки объектов Active Directory по неосторожности был удален Cluster Name Object. Вновь созданный объект не переходит в интерактивный режим.
Объект CNO (Cluster Name Object) это общий идентификатор кластера, и поэтому он очень важен. Он создается автоматически мастером создания кластера (Create cluster) и носит то же имя, что и кластер. По мере настройки новых служб и приложений в этой учетной записи, CNO создает другие виртуальные объекты. При удалении CNO или его разрешений он не может создавать другие необходимые кластеру объекты до тех пор, пока не будет восстановлен или ему не будут назначены соответствующие разрешения.
Как и в случае с другими объектами Active Directory, у CNO есть связанный идентификатор objectGUID. По нему отказоустойчивый кластер узнает, что имеет дело с правильным объектом. Если просто создать новый объект, то у него будет новый objectGUID. Нужно восстановить правильный объект, чтобы отказоустойчивый кластер мог продолжить нормальную работу.
При устранении этой неполадки нужно найти две вещи, относящиеся к ресурсу кластера. В Windows PowerShell выполните команду:
Get-ClusterResource "Cluster Name" | Get-ClusterParameterCreatingDC,objectGUID
Эта команда сообщает необходимые значения. Первый параметр — CreatingDC. Когда отказоустойчивый кластер создает CNO, отмечается контроллер домена, в котором он был создан. При любой выполняемой с кластером операции (создание виртуального объекта, перевод в интерактивное состояние и т.п.) к этому контроллеру обращаются за объектом CNO и информацией безопасности. Если контроллер домена найти не удается или он недоступен, тогда уже выполняется поиск любого другого ответственного контроллера.
Второй параметр – objectGUID – отвечает за то, чтобы можно было быть уверенным, что получен правильный объект. В нашем случае имя кластера —CLUSTER1, контроллер, на котором он был создан, — DC1, а значение objectGUID — 1a3cf049cf79614ebd94670560da6f04:
Надо войти в систему DC1 и открыть консоль Active Directory Users and Computers (Active Directory — пользователи и компьютеры). Если в ней есть текущий объект CLUSTER1, можно проверить наличие в нем правильных атрибутов. Редактор атрибутов Active Directory не показывает GUID, поскольку он не отражается в шестнадцатеричном формате.
В противном случае мы увидели бы такое значение 49f03c1a-79cf-4e61-bd94-670560da6f04. Шестнадцатеричный формат преобразуется и работает в парах, что немного смущает. Если взять первые восемь пар и выполнить преобразование, то 49f03c1a станет 1a3cf049. В следующих двух парах 79cf станет cf79, а 4e61 — 614e. Оставшиеся пары останутся такими же.
Чтобы увидеть в шестнадцатеричном формате то, что видит отказоустойчивый кластер, свойства объекта objectGUID нужно передать в редактор атрибутов. Поскольку это неправильный объект, сначала надо удалить объект, чтобы было возможно восстановить правильный объект.
Восстановить объект можно несколькими способами. Можно воспользоваться Active Directory Restore, утилитой, подобной ADRESTORE, или новой корзиной Active Directory (если это контроллер домена Windows 2008 R2 с обновленной схемой). Новая корзина значительно упрощает процесс и делает его самым удобным для восстановления объектов Active Directory.
С помощью корзины Active Directory можно найти объект восстановления, выполнив команду Windows PowerShell:
Эта команда выполняет поиск всех удаленных объектов с именем CLUSTER1 в корзине Active Directory. В результате получаем имя учетной записи и objectGUID. Если найдены несколько элементов, все они будут показаны. При просмотре нужного элемента мы увидим:
Теперь его надо восстановить. После удаления неправильного объекта для восстановления следует использовать такую команду Windows PowerShell:
Restore-ADObject –identity 49f03c1a-79cf-4e61-bd94-670560da6f04
В результате объект будет восстановлен в том же месте (подразделении) с теми же разрешениями и паролем, известным Active Directory.
Это одно из преимуществ корзины Active Directory по сравнению с аналогами утилиты ADRESTORE. При восстановлении эти утилиты сбрасывают пароль, перемещают объект в соответствующий контейнер, восстанавливают объект в отказоустойчивом кластере и т.д.
Используя корзину, мы просто переводим ресурс в интерактивный режим. Это более удачный вариант, чем восстановление Active Directory, особенно если позже были созданы новые объекты пользователя или компьютера, удалены старые объекты и т. п.
Во-первых, уточним определение общих томов кластера. Они упрощают настройку и управление виртуальными машинами Hyper-V в отказоустойчивых кластерах. Благодаря наличию общих томов в отказоустойчивом кластере, работающие под управлением Hyper-V, множество виртуальных машин могут использовать один LUN и при этом перемещаться между узлами независимо друг от друга. Общий том кластера обеспечивает повышение гибкости томов в кластерном хранилище. Например, для оптимизации дисковой производительности можно хранить системные файлы отдельно от данных, даже если системные файлы и данные размещены в файлах виртуального жесткого диска.
Надо позаботиться, чтобы в параметрах всех сетевых адаптеров, обеспечивающих связь кластеров, были установлены компоненты Client for Microsoft Networks (Клиент для сетей Microsoft) и File and Printer Sharing for Microsoft Networks (Общий доступ к файлам и принтерам в сетях Microsoft), для поддержки протокола SMB (Server Message Block). Это необходимо для общего тома. Сервер работает под управлением Windows Server 2008 R2, что автоматически обеспечивает версию SMB, необходимую для общего тома, а именно SMB2.Используется только одна предпочтительная коммуникационная сеть для общего тома, но включение этих параметров во множестве сетей поможет кластеру противостоять отказам.
Перенаправление доступа подразумевает, что все операции ввода-вывода «перенаправляются» по сети на другой узел, имеющий доступ к диску. Могут быть три причины для перехода в режим перенаправления доступа:
- Режим настроен вручную.
- Идет процесс резервного копирования.
- Имеются неполадки с оборудованием, и узел не может напрямую получить доступ к диску.
В нашем сценарии мы исключили первые два варианта. Остается третий. Если заглянуть в журнал системных событий System Event Log, можно увидеть событие отказоустойчивой кластеризации "Event ID: 5121".
Определение этой записи журнала: Общий том кластера CSV «Cluster Disk x» более не доступен напрямую с этого узла кластера. Ввод-вывод будет перенаправлен на устройство хранения по сети через узел-владелец, которому принадлежит этот том. Это может привести к снижению производительности. Если перенаправление доступа к этому тому включено, отключите его. Если перенаправление доступа отключено, устраните неполадки связи этого узла с устройством хранения; после восстановления связи с устройством хранения работоспособность ввода-вывода будет также восстановлена.
В такой ситуации надо тщательно изучить все предшествующие этому события, связанные с оборудованием. Это значит, что надо искать такие события, как 9, 11, 15, которые указывают на неполадки оборудования или связи. Стоит провести физическую проверку диску в панели Disk Management (Управление диском). В большинстве случаев так удается обнаружить другие ошибки. Решив проблему, можно вывести диск из этого режима.
Следует помнить, что общий том остается включенным на протяжении всего времени, пока есть хотя бы один узел, подключенный с сети хранения. Именно поэтому будет установлен режим перенаправления. Все операции записи на диск отправляются в узел, который поддерживает связь, и виртуальные машины Hyper-V будут продолжать работу. Это может повлиять на их производительность, но они останутся работоспособными. В результате производственные серверы никогда не отключаются, а это уже хорошо.
Сценарий 3. Я только что создал новый отказоустойчивый кластер Windows 2008 R2 для виртуальных машин с высоким уровнем доступности. Диски настроены для работы с общим томом, но при попытке доступа к ним с помощью проводника или панели «Управление диском» происходит зависание. Я не могу скопировать на том файлы виртуального диска.
Существует только один «истинный» владелец диска и он называется узел-координатор (Coordinator Node). Запись любого типа метаданных выполняется только этим узлом.
Проводник или панель управления диском открывает диск с возможностью записи любых метаданных (если такое предполагается). По этой причине любой диск, не находящийся в собственности, перенаправляется по сети на узел-координатор. Это не совсем то же, что «перенаправление доступа».
В процессе устранения этой неполадки в оснастке «Управление отказоустойчивым кластером» можно увидеть, что диск находится в интерактивном режиме. Поэтому сначала надо изучить события в журнале. В журнале системных событий можно увидеть события отказоустойчивой кластеризации:
Событие ID: 5120
Общий том кластера «Cluster Disk x» больше не доступен на этом узле из-за «STATUS_BAD_NETWORK_PATH(c00000be)». Все операции ввода-вывода будут временно поставлены в очередь, пока путь к тому не будет восстановлен. (Cluster Shared Volume ‘Cluster Disk x’ is no longer available on this node because of ‘STATUS_BAD_NETWORK_PATH(c00000be).’ All I/O will temporarily be queued until a path to the volume is reestablished.)
Событие ID: 5142
Эти события говорят о попытках подключения к узлу-координатору, которые завершаются таймаутом. Поэтому загляните в журнал системных событий и проверьте, нет ли там других ошибок, указывающих на связь узлов по сети. При наличии таковых необходимо устранить их. Ошибки могут быть вызваны поломкой или отключением сетевой карты.
Далее надо проверить возможность связь узлов по сети. Первым делом нужно проверить сеть, по которой передается трафик общего тома. В отказоустойчивом кластере сеть для общего тома выбирается, исходя из максимального значения метрики. Это отличается от того, как Windows идентифицирует сети.
Сетевой отказоустойчивый адаптер для отказоустойчивого кластера (Failover Cluster Network Fault Tolerance, NETFT) имеет свою собственную внутреннюю систему метрик. Все выявленные им сети имеют шлюз по умолчанию и получают метрики 10000, 10100 и т. д. Метрики всех сетей без шлюза по умолчанию начинаются с 1000, 1100 и т. д. Чтобы узнать, как адаптер NETFT определил их, можно использовать команду Windows PowerShell:
Вы увидите примерно следующее:
Name Metric
-------------------
Management 10100
CSV Traffic 1000
LAN-WAN 10000
Private 1100
Среди этих сетей сеть, которую я определил как сеть общего тома, — CSV Traffic. Для узла Node1 я использовал IP-адрес 1.1.1.1 и 1.1.1.2 для узла Node2, поэтому я проверяю сетевое соединение с помощью команды PING.
Следующим шагом будет попытка соединения по протоколу SMB к указанным IP-адресам. Это то, что делает служба кластеризации. Чтобы получить ответ, достаточно выполнить простую команду:
Для работы с общим томом необходимы компоненты "Client for Microsoft Networks" и "File and Printer Sharing for Microsoft Networks". Если они отсутствуют, то возникает проблема с зависанием Проводника.
В Windows 2003 Server Cluster и ниже рекомендовалось отключать эти компоненты. Сейчас в этом нет необходимости.
Другие факторы
Есть несколько факторов, которые следует принять во внимание. Если узлы кластера вызывают отказ подсистемы размещения ресурсов (Resource Host Subsystem, RHS), первым делом нужно вспомнить о природе RHS и ее функциях. RHS — это компонент отказоустойчивого кластера, выполняющий проверку работоспособности множества ресурсов для обеспечения работоспособности. Что касается IP-адресов, то этот компонент проверяет, находится ли адрес в сетевом стеке и реагирует ли на запросы. Проверяя диски, он пытается соединиться и выполнить команду DIR.
Если сбоит RHS, проверьте журнал системных событий на наличие записей с идентификаторами 1230 и 1146. В событии 1230 фактически указывается ресурс и используемые библиотеки DLL. Если произошел сбой, это означает, что ресурс не отвечает должным образом и возможна взаимная блокировка. Если сбой произошел на дисковом ресурсе, следует просмотреть наличие ошибок, связанных с диском или слишком большим временем отклика диска. Неплохо начать с использования монитора производительности (Performance Monitor). Также приветствуется обновление драйверов и микропрограммы карт или компонентов сети.
Помимо этого следует сделать некоторые наблюдения. Служба кластеризации проводит проверку работоспособности пользовательских процессов из режима ядра, чтобы выявить, когда пользовательский режим перестает отвечать или происходит зависание. Для вывода из этого состояния служба кластеризации проводит проверку ошибкой. Если это происходит, будет получена ошибка Stop 0x0000009E. Чтобы устранить неполадку, надо изучить файл дампа, созданный для поиска причин зависания. Также можно запустить монитор производительности и посмотреть, будут ли возникать зависания, утечки памяти и т. п.
Служба кластеризации зависит от инструментария управления Windows (Windows Management Instrumentation, WMI). Если возникают проблемы с WMI, это ведет к проблемам с кластеризацией (с созданием и добавлением узлов, миграцией и т. п.). Проверьте WMI, например, WBEMTEST.EXE или даже удаленные сценарии WMI.
Один сценарий можно попытаться выполнить в консоли Windows PowerShell (здесь NODE1 — имя узла):
Он создает соединение WMI с кластером и предоставляет информацию о группах.
Неудачное завершение сценария указывает на проблемы с WMI. Перезапустите службу WMI, если она остановлена. Может быть повреждена база данных WMI (для проверки целостности воспользуйтесь командой Windows PowerShell: winmgmt /salvagerepository) и т. д.
Помните о ряде правил устранения неполадок:
- Проверяйте, проверяйте и еще раз проверяйте. При устранении неполадок используйте тесты для проверки кластера. Используйте их при изменении системы.
- Все больше систем переводятся на Windows PowerShell, поэтому начните изучать эту технологию, если вы ее еще не освоили.
- Если вы зависите от объектов Active Directory, защитите их. Разрешите использование корзины Active Directory и защитите объекты от случайного удаления.
- При устранении неполадок общего тома не забывайте, что проблема может быть не только в неполадках оборудования.
- При устранении неполадки сделайте шаг назад и внимательно проанализируйте все, на что она может оказывать влияние, и постепенно сужайте поле поиска.
Служба отказоустойчивой кластеризации создана для выявления, восстановления и предоставления отчетов об ошибках. Когда кластер «говорит», что есть или была неполадка, это не значит, что он вызвал ее. Как говорится, "не убивайте гонца, принесшего дурную весть".
Читайте также: