
Linux объединить две подсети
Так вот вопрос: как настроить iptables на серваках, чтобы все компы пинговали друг друга и на виндовом клиенте был доступ в интернет?
А iptables тут ни при чём. Вам надо настроить маршрутизацию, чтобы для виндовой машины 192.168.2.1 был шлюзом по умолчанию, и все машины сети 192.168.0.0/маска знали, что в сеть 192.168.2.0/маска надо ходить через 192.168.0.10. Ну и форвардинг в CentOS разрешить, разумеется.| в консоли вку́пе (с чем-либо) в общем вообще | в течение (часа) новичок нюанс по умолчанию | приемлемо проблема пробовать трафик |
Я пробовал командой route. Все работало. А если у меня в каждой подсети будет по 200 компов, не буду же я каждой машине присваивать шлюз и тд. В обоих сервах включен форвардинг
| в консоли вку́пе (с чем-либо) в общем вообще | в течение (часа) новичок нюанс по умолчанию | приемлемо проблема пробовать трафик |
Я конечно знаю для чего нужен dhcp, но как в нем, например, прописать чтоб все машины сети 192.168.0.0/маска знали, что в сеть 192.168.2.0/маска надо ходить через 192.168.0.10)
Я конечно знаю для чего нужен dhcp, но как в нем, например, прописать чтоб все машины сети 192.168.0.0/маска знали, что в сеть 192.168.2.0/маска надо ходить через 192.168.0.10)
Почитайте что такое "шлюз по умолчанию" и зачем он нужен.
| в консоли вку́пе (с чем-либо) в общем вообще | в течение (часа) новичок нюанс по умолчанию | приемлемо проблема пробовать трафик |
Вся подсеть 192.168.0.0/24 ходит через debian server(192.168.0.1) в инет.
CentOS(файловый сервер) входит в эту же подсеть(192.168.0.10) вторым интерфейсом смотрит в другую подсеть 192.168.2.0/24.
Написал в centos server в iptables правило "iptables -t nat -A POSTROUTING -s 192.168.2.0/24 -d 192.168.0.0/24 -j MASQUERADE", после этого пинги с подсети 192.168.2.0 идут в 192.168.0.0. Обратные пинги не идут, что логично, так как надо каким то образом настроить перекидывание пакетов с Дебиан Сервера на CentOS! У меня не получается. И нужно чтоб подсеть 192.168.2.0 имела выход в инет?
| в консоли вку́пе (с чем-либо) в общем вообще | в течение (часа) новичок нюанс по умолчанию | приемлемо проблема пробовать трафик |
Не знал, что в dhcp такое можно настроить. Буду читать этот пост на "буржуйском". Спасибо за подсказку Не знал, что в dhcp такое можно настроить. Буду читать этот пост на "буржуйском". Спасибо за подсказку
А такое через DHCP лучше не реализовывать. Не его это дело. Там стандартная опция - только шлюз по умолчанию, остальное - расширения (к тому же убогие), которое клиенты могут легко проигнорировать.
Для анонсирования маршрутов и их динамического обновления существуют отдельные сервисы и протоколы. Для малых сетей - RIPv2 (RIPng для IPv6) Его и используйте. Сервер называется quagga. Правда, он требует конфигурирования.
Здравствуйте, я так понимаю что условно говоря, все компьютеры находятся в 1 свиче. В данном случаи клиенту достаточно иметь шлюз по умолчанию, а все маршруты следует указывать на шлюзе, приведу пример:
Допустим есть маршрутизатор(в вашем случаи linux), а что если у вас корпоративная сеть, и в ней 9 VLAN'ов? Вы задолбаетесь статические маршруты через DHCP конфигурировать, да и не правильно это. У вас имеются такие подсети:
192.168.0.0 / 24 допустим такая маска
192.168.2.0 / 23 допустим такая маска
Каждая из этих подсетей должна иметь свой шлюз по умолчанию. Говоря другими словами, на вашем linux (вы писали 192.168.0.1), должно быть 2 vlan (это делается саб интерфейсами, если я правильно помню), и все маршруты вы указываете на своем шлюзе.
Так будет правильно.
| в консоли вку́пе (с чем-либо) в общем вообще | в течение (часа) новичок нюанс по умолчанию | приемлемо проблема пробовать трафик |
А это потому что я не внимательный Я говорил про топологию:
Да, а человеку достаточно указать статические маршруты на шлюзах до нужных ему сетей.
P.S:Кроме того, ситуации когда нет других варинтов, кроме как оставить два шлюза, довольно редки, почти всегда можно развести сетку по VLAN, и оставить один физический шлюз.
Здравствуйте, я так понимаю что условно говоря, все компьютеры находятся в 1 свиче. В данном случаи клиенту достаточно иметь шлюз по умолчанию, а все маршруты следует указывать на шлюзе, приведу пример:
Допустим есть маршрутизатор(в вашем случаи linux), а что если у вас корпоративная сеть, и в ней 9 VLAN'ов? Вы задолбаетесь статические маршруты через DHCP конфигурировать, да и не правильно это. У вас имеются такие подсети:
192.168.0.0 / 24 допустим такая маска
192.168.2.0 / 23 допустим такая маска
Каждая из этих подсетей должна иметь свой шлюз по умолчанию. Говоря другими словами, на вашем linux (вы писали 192.168.0.1), должно быть 2 vlan (это делается саб интерфейсами, если я правильно помню), и все маршруты вы указываете на своем шлюзе.
При создании локальной сети не каждый администратор подходит с ответственностью к выбору диапазона адресов. А может и не каждый догадывается о наличии частных диапазонов кроме 192.168.0.0/24. И со временем такая бомба замедленного действия может дать о себе знать. Локальные сети объединяются, возникает потребность в коммуникации между хостами разных сетей. И тут выясняется, что номера сетей совпадают. И менять их по каким либо причинам проблематично или невозможно.
В таком случае, серверу, маршрутизирующему пакеты между сетями, остается сделать вид, что номера сетей различны и выдавать желаемое за действительное. В богатом арсенале Linux есть средства для таких манипуляций: iptables с NETMAP и утилита ip.
Из сети LAN1 мы хотим послать пакет в сеть LAN2. Но мы не можем послать его в сеть, номер которой одинаков с нашим. В самом частом случае 192.168.0.0/24. Если такой пакет появится в LAN1, он не будет знать, что есть LAN2, он будет искать такую машину в LAN1. Таковы правила маршрутизации по умолчанию.
Значит, надо посылать пакеты с другими адресами, которые уйдут в роутер.
Как это должно вглядеть для наблюдателя из LAN1
Например, пользователь сети LAN1 будет видеть сеть LAN2 как 10.8.1.0/24. Тут уже никакого пересечения адресов. LAN1 доволен.

Как это выглядит с обеих сторон
Из LAN1 приходит пакет с адресом отправителя 192.168.0.100 и адресом назначения 10.8.1.200. Из роутера с интерфейса LAN2 выходит тот же пакет с адресом отправителя 10.8.1.100 и с адресом назначения 192.168.0.200. Пакет проходит до адреса назначения и тот шлет в ответ на адрес отправителя со своим адресом. Пакет уходит в роутер. В нем происходит обратное преобразование и пользователь LAN1 получает ответ с того адреса, на который отправил пакет.
Теория. Путь пакета в ядре роутера: netfilter

Здесь я попытаюсь рассказать о путешествии транзитного трафика через наш Linux-роутер. Для полного понимания процесса путешествия пакета лучше видеть схему его прохождения из Википедии по цепочкам netfilter.
Наш пакет с [источником|назначением] [192.168.0.100|10.8.1.200] попадает на сетевой интерфейс роутера и первой его цепочкой будет PREROUTING.
PREROUTING
Проходя по цепочке он попадает в таблицу PREROUTING mangle. В которой посредством iptables мы определяем интерфейс, с которого он пришел, и адрес источника. Если это наш пациент, мы его помечаем действием MARK.
После чего пакет [192.168.0.100|10.8.1.200|(marked)] попадает в таблицу nat. Эта таблица предназначена для трансляции адресов. Поскольку не существует реального адреса 10.8.1.200, то на последующем этапе маршрутизации пакет будет отброшен или уйдет в неизвестном направлении. Поэтому заменяем ему адрес назначения на тот, на который он действительно должен пойти именно тут: [192.168.0.100|192.168.0.200|(marked)]. Делается это действием NETMAP, которое заменяет номер сети по маске.
ROUTING
Пакет успешно проходит цепочку FORWARDING. Попадает опять на этап маршрутизации. Если в FORWARDING с ним ничего не случилось, а по идее не должно было. Он идет тем же путем. После чего попадает в POSTROUTING.
POSTROUTING
Без изменений доходя до таблицы nat. Мы должны изменить адрес источника. Ведь ответ на пакет [192.168.0.100|192.168.0.200] будет отправлен в локальную сеть, а не в роутер. Чтоб он попал обратно в роутер, меняем адрес источника на несуществующий [10.8.1.100|192.168.0.200]. Опять же NETMAP. После этого пакет выходит в LAN2.
С ответным пакетом проделываем обратную процедуру, чтоб он дошел до изначального источника.
Реализация
Узнаем пакет по метке и действием NETMAP в таблице PREROUTING подменяет номер сети.
В POSTROUTING NETMAP подменяет адрес источника.
После этого все обращения на подсеть 10.8.1.0/24 будут выглядеть внутри LAN2, как обращения из подсети 10.8.2.0/24.
ROUTING
Чтобы маршрутизировать пакеты по метке необходимо создать свою таблицу маршрутизации.Редактируем /etc/iproute2/rt_tables, добавляя уникальное число и название новой таблицы.
256 netmap
Далее надо добавить правило, по которому в эту таблицу будут направляться пакеты на маршрутизацию.
Теперь помеченные пакеты будут уходить на маршрутизацию в таблицу netmap.
И последним шагом нужно определить маршруты в таблице netmap.
Или можно указать в особом случае отдельный шлюз, если в эту сеть трафик от роутера идет через него. Что-то в духе:
Пока рано радоваться, к нам придет ответ из LAN2 [192.168.0.100|10.8.2.200].
Надо сделать все тоже самое, но только преобразовать обратно. Увы, netfilter сам этого не делает. Все действия уже описаны, приведу только последовательность команд для преобразования адресов в одну и в обратную сторону. (В первой таблице маршрутизации необходимости в данном случае нет, но при иных обстоятельствах может понадобиться.)
Результаты
Вот что пишет tcpdump (первый пример с vnc, второй с пингом):
12:46:46.358969 IP 192.168.0.100.41930 > 10.8.1.200.5900: Flags [P.], seq 647:657, ack 261127, win 1213, options [nop,nop,TS val 460624 ecr 171318], length 10
12:46:46.358978 IP 10.8.2.100.41930 > 192.168.0.200.5900: Flags [P.], seq 647:657, ack 261127, win 1213, options [nop,nop,TS val 460624 ecr 171318], length 10
12:46:46.505847 IP 192.168.0.200.5900 > 10.8.2.100.41930: Flags [.], ack 657, win 64879, options [nop,nop,TS val 171320 ecr 460624], length 0
12:46:46.505861 IP 10.8.1.200.5900 > 192.168.0.100.41930: Flags [.], ack 657, win 64879, options [nop,nop,TS val 171320 ecr 460624], length 0
12:47:46.363905 IP 192.168.0.100 > 10.8.1.200: ICMP echo request, id 2111, seq 1, length 64
12:47:46.363922 IP 10.8.2.100 > 192.168.0.200: ICMP echo request, id 2111, seq 1, length 64
12:47:46.364049 IP 192.168.0.200 > 10.8.2.100: ICMP echo reply, id 2111, seq 1, length 64
12:47:46.364054 IP 10.8.1.200 > 192.168.0.100: ICMP echo reply, id 2111, seq 1, length 64
Tcpdump отлично демонстрирует, как происходит преобразование адресов на входе в один интерфейс и на выходе в другой и в обратную сторону.
Так же отлично работают остальные сервисы, типа Samba и ее аналог на Windows.
Если соединение между сетями организовано посредством туннеля OpenVPN, то для правильной маршрутизации со стороны клиента в конфиг сервера необходимо добавить дополнительный маршрут через туннель.
push "route 10.8.1.0 255.255.255.0"
Объединение сетевых интерфейсов(Bonding) – это механизм, используемый Linux-серверами и предполагающий связь нескольких физических интерфейсов в один виртуальный, что позволяет обеспечить большую пропускную способность или отказоустойчивость в случае повреждения кабеля. В данном руководстве мы разберем реализацию объединения интерфейсов в Linux для Ubuntu/Debian и CentOS/RHEL/Fedora.
Агрегация сетевых интерфейсов в Ubuntu и Debian
Важно! Если у вас используется Ubuntu версии 17.10 и выше, то необходимо установить пакет ifupdown или настраивать агрегацию каналов нужно через netplan
Прежде всего нужно установить модуль ядра для поддержки объединения и при помощи команды modprobe проверить, загружен ли драйвер.
В более старых версиях Debian или Ubuntu может потребоваться установка пакета ifenslave:
Для создания связанного интерфейса из двух физических сетевых карт вашей системы выполните следующую команду. К сожалению, при использовании такого метода объединение интерфейсов не сохраняется после перезагрузки системы:
Для создания постоянного связанного интерфейса типа mode 0 (ниже мы разберем эти типы более подробно), нужно отредактировать файлы конфигурации сетевых интерфейсов. Откройте с помощью любого текстового редактора, например nano, файл /etc/network/interfaces , как показано в следующем фрагменте (замените IP-адрес, маску подсети, шлюз и DNS-серверы на используемые в вашей сети).
Чтобы активировать объединенный интерфейс, перезапустите сетевую службу, отключите физические интерфейсы и включите объединенный интерфейс, либо перезагрузите машину, чтобы ядро определило новый объединенный интерфейс.
Настройки связанного интерфейса можно проверить при помощи следующих команд:
Подробную информацию об объединенном интерфейсе можно получить, просмотрев содержимое следующего файла ядра командой cat:
Для отладки ошибок можно использовать команду tail
Проверку параметров сетевой карты можно выполнить при помощи инструмента mii-tool:
Режимы работы
mode=1 (active-backup)
Когда используется этот метод, активен только один физический интерфейс, а остальные работают как резервные на случай отказа основного.
mode=3 (broadcast) Широковещательный режим, все пакеты отправляются через каждый интерфейс. Имеет ограниченное применение, но обеспечивает значительную отказоустойчивость.
mode=4 (802.3ad)
Особый режим объединения. Для него требуется специально настраивать коммутатор, к которому подключен объединенный интерфейс. Реализует стандарты объединения каналов IEEE и обеспечивает как увеличение пропускной способности, так и отказоустойчивость.
mode=6 (balance-alb)
Адаптивное распределение нагрузки. Аналогично предыдущему режиму, но с возможностью балансировать также входящую нагрузку.
Объединение сетевых интерфейсов в CentOS, RHEL и Fedora
Создайте новый файл bonding.conf в директории /etc/modprobe.d/ . Имя может быть любым, но расширение должно быть .conf. Вставьте в этот файл следующую строку:
Такая строка в файле /etc/modprobe.d/bonding.conf требуется для каждого bond интерфейса.
Для агрегации интерфейсов создайте в директории /etc/sysconfig/network-scripts/ файл конфигурации с именем ifcfg-bond0. Вот пример содержимого файла конфигурации (IP-адреса в вашей системе могут отличаться):
После создания объединённого интерфейса нужно настроить его и связанные с ним сетевые карты, добавив в файлы конфигурации директивы MASTER и SLAVE. Для всех связанных интерфейсов эти файлы могут быть почти одинаковыми. Например, у двух интерфейсов eth0 и eth1, связанных в один, они могут иметь следующий вид. Отредактируйте их, как показано ниже.
Для eth0
Значение этих директив следующее:
DEVICE: определяет имя устройства
USERCTL: определяет, может ли пользователь управлять интерфейсом (в данном случае нет)
ONBOOT: определяет, включать ли интерфейс при загрузке
MASTER: есть ли у этого устройства ведущий интерфейс (здесь это bond0)
SLAVE: работает ли это устройство каки ведомое
BOOTPROTO: Определяет получение IP-адреса по DHCP. При статическом IP-адресе устанавливается значение none
Перезагрузите сетевую службу и проверьте конфигурацию командой ifconfig.
Заключение
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
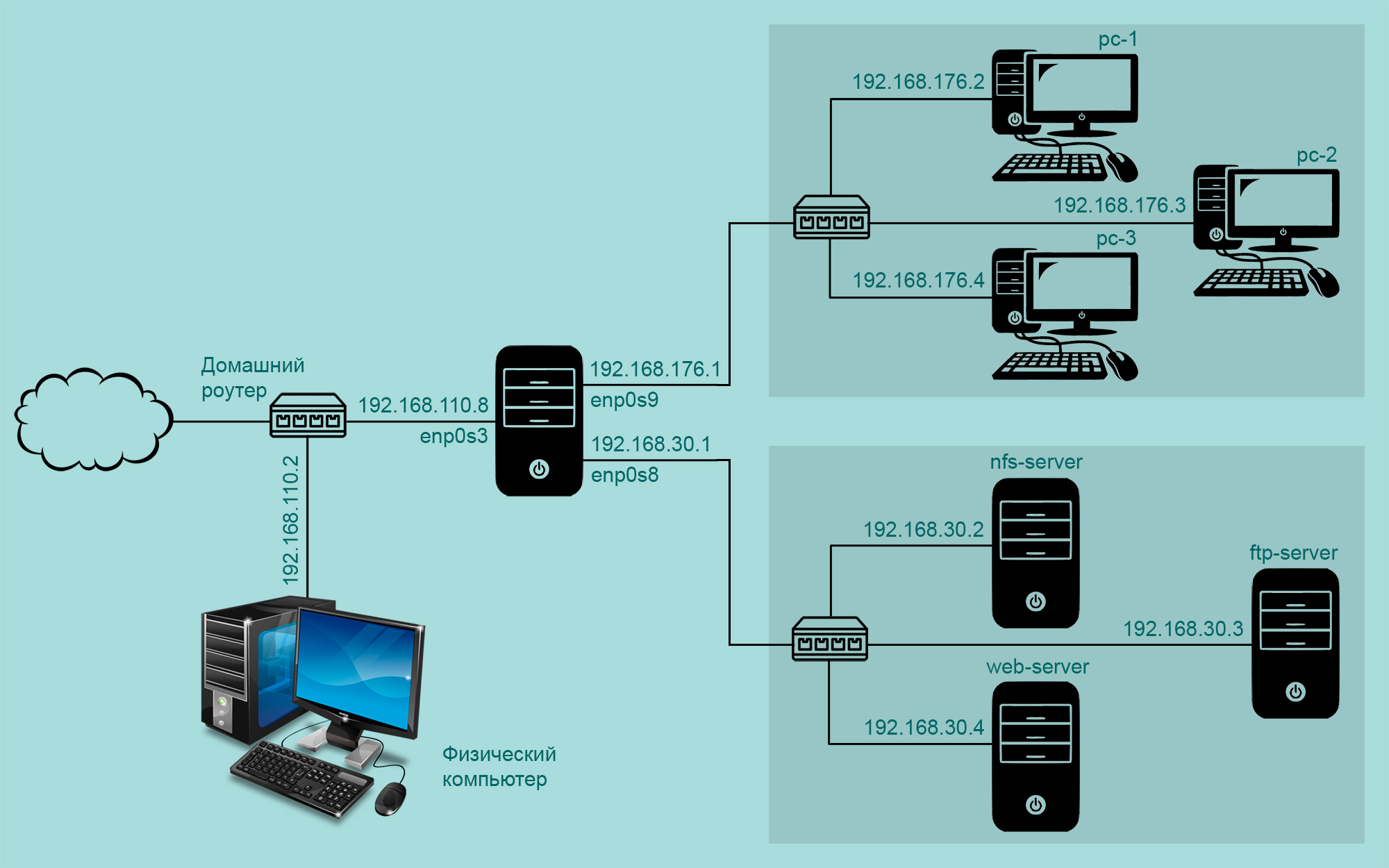
Небольшой эксперимент создания интернет-шлюза для двух подсетей на базе на Ubuntu Server. У меня дома компьютер с установленной Windows 10 и VirtualBox. Давайте создадим семь виртуальных машин: router , pc-1 , pc-2 , pc-3 , nfs-server , ftp-server , web-server :
- Виртуальные машины pc-1 , pc-2 , pc-3 объединены в сеть 192.168.176.0/24
- Виртуальные машины nfs-server , ftp-server , web-server объединены в сеть 192.168.30.0/24
Виртуальная машина router будет обеспечивать выход в интернет для компьютеров подсетей 192.168.176.0/24 и 192.168.30.0/24 , у нее три сетевых интерфейса:
- enp0s3 (сетевой мост) — смотрит в домашнюю сеть, получает ip-адрес 192.168.110.8 от роутера Keenetic Air
- enp0s9 (внутреняя сеть) — смотрит в одну сеть с виртуальными машинами pc-1 , pc-2 , pc-3
- enp0s8 (внутреняя сеть) — смотрит в одну сеть с виртуальными машинами nfs-server , ftp-server , web-server
Тут надо сказать несколько слов о настройке сети в VirtualBox. Существует несколько способов, рассмотрим два из них:
- Сетевой мост — при таком подключении виртуальная машина становится полноценным членом локальной сети, к которой подключена основная система. Виртуальная машина получает адрес у роутера и становится доступна для других устройств, как и основной компьютер, по своему ip-адресу.
- Внутренняя сеть — тип подключения симулирует закрытую сеть, доступную только для входящих в ее состав машин. Поскольку виртуальные машины не имеет прямого доступа к физическому сетевому адаптеру основной системы, то сеть получается полностью закрытой, снаружи и изнутри.
Настройка сети для router
Сначала нужно посмотреть, как называются сетевые интерфейсы в системе:
Теперь редактируем файл /etc/netplan/01-netcfg.yaml
Применяем настройки и смотрим сетевые интерфейсы:
Первый сетевой интерфейс enp0s3 получил ip-адрес 192.168.110.8 от роутера Keenetic Air, этот ip-адрес закреплен постоянно. Второму сетевому интерфейсу enp0s8 мы назначили ip-адрес 192.168.30.1 . Третьему сетевому интерфейсу enp0s8 мы назначили ip-адрес 192.168.176.1 .
Настройка сети для pc-1, pc-2 и pc-3
Сначала для виртуальной машины pc-1 . Смотрим, как называются сетевые интерфейсы в системе:
Открываем на редактирование файл /etc/netplan/01-netcfg.yaml :
Применяем настройки и смотрим сетевые интерфейсы:
Для виртуальных машин pc-2 и pc-3 все будет аналогично, назначаем им ip-адреса 192.168.176.3 и 192.168.176.4 .
Настройка сети для nfs-server, ftp-server, web-server
Сначала для виртуальной машины nfs-server . Смотрим, как называются сетевые интерфейсы в системе:
Открываем на редактирование файл /etc/netplan/01-netcfg.yaml :
Применяем настройки и смотрим сетевые интерфейсы:
Для виртуальных машин ftp-server и web-server все будет аналогично, назначаем им ip-адреса 192.168.30.3 и 192.168.30.4 .
Настройка интернет-шлюза
Виртуальная машина router должна обеспечивать выход в интернет для компьютеров из двух подсетей 192.168.176.0/24 и 192.168.30.0/24 . По умолчанию транзитный трафик отключен, так что редактируем файл /etc/sysctl.conf :

И перезагружаем виртуальную машину router . После этого настраиваем netfilter с помощью утилиты iptables :
И вот что у нас получилось в итоге:
Теперь настроим SNAT (подмена адреса источника), что позволит всем компьютерам двух подсетей выходить в интернет, используя единственный ip-адрес 192.168.110.8 :
И смотрим, что получилось:
Доступ к NFS-серверу за NAT
Наш NFS-сервер расположен во внутренней сети 192.168.30.0/24 и имеет ip-адрес 192.168.30.2 . Чтобы обеспечить доступ к нему из подсети 192.168.110.0/24 , выполняем на виртуальной машине router команды (подробнее можно прочитать здесь):
И смотрим, что получилось:
Доступ к FTP-серверу за NAT
Наш FTP-сервер расположен во внутренней сети 192.168.30.0/24 и имеет ip-адрес 192.168.30.3 . Чтобы обеспечить доступ к нему из подсети 192.168.110.0/24 , выполняем на виртуальной машине router команды (подробнее можно прочитать здесь):
И смотрим, что получилось:
Доступ к WEB-серверу за NAT
Наш WEB-сервер расположен во внутренней сети 192.168.30.0/24 и имеет ip-адрес 192.168.30.4 . Чтобы обеспечить доступ к нему из подсети 192.168.110.0/24 , выполняем на виртуальной машине router команду:
И смотрим, что получилось:
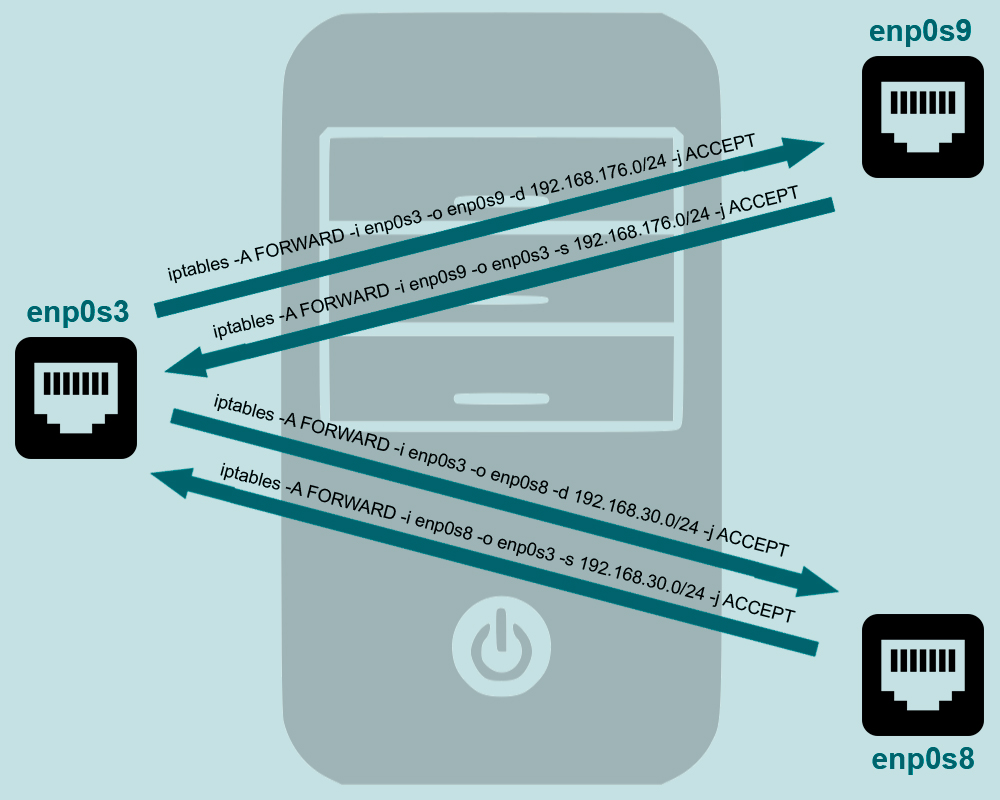
Связь между подсетями
Чтобы обеспечить связь между подсетями 192.168.176.0/24 и 192.168.30.0/24 , добавим на маршрутизаторе еще два правила:
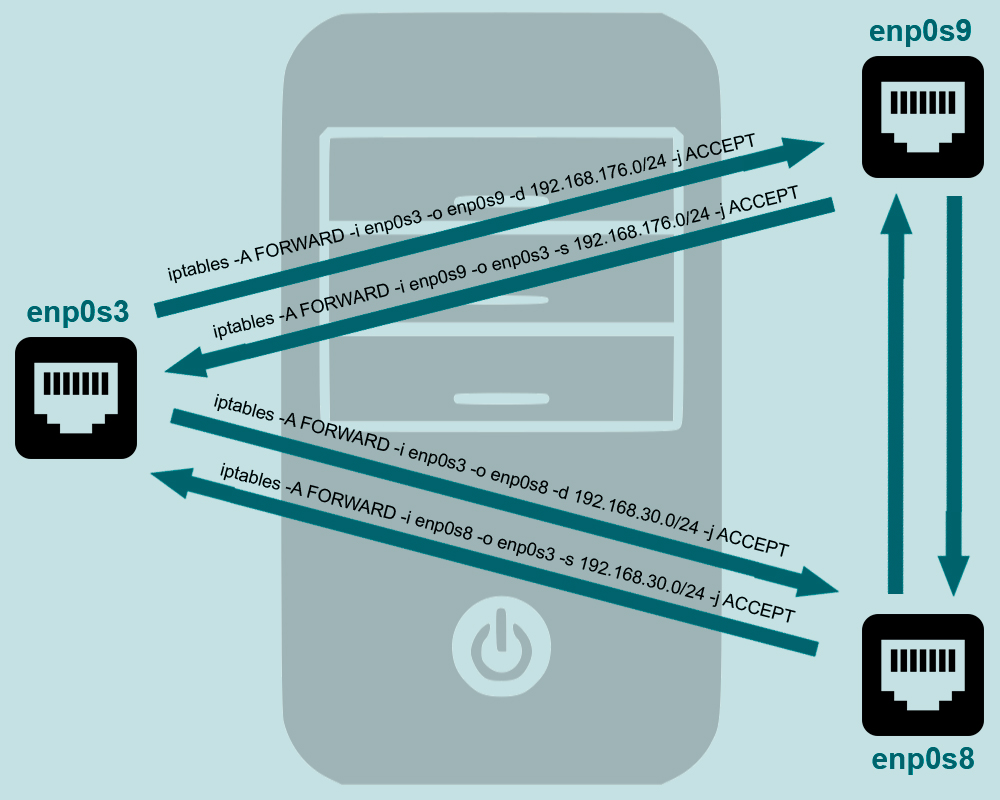
Проверим, что с виртуальной машины pc-1 можно достучаться до nfs-server :
И наоборот, что с виртуальной машины nfs-server можно достучаться до pc-1 :
Доступ к серверам за NAT по SSH
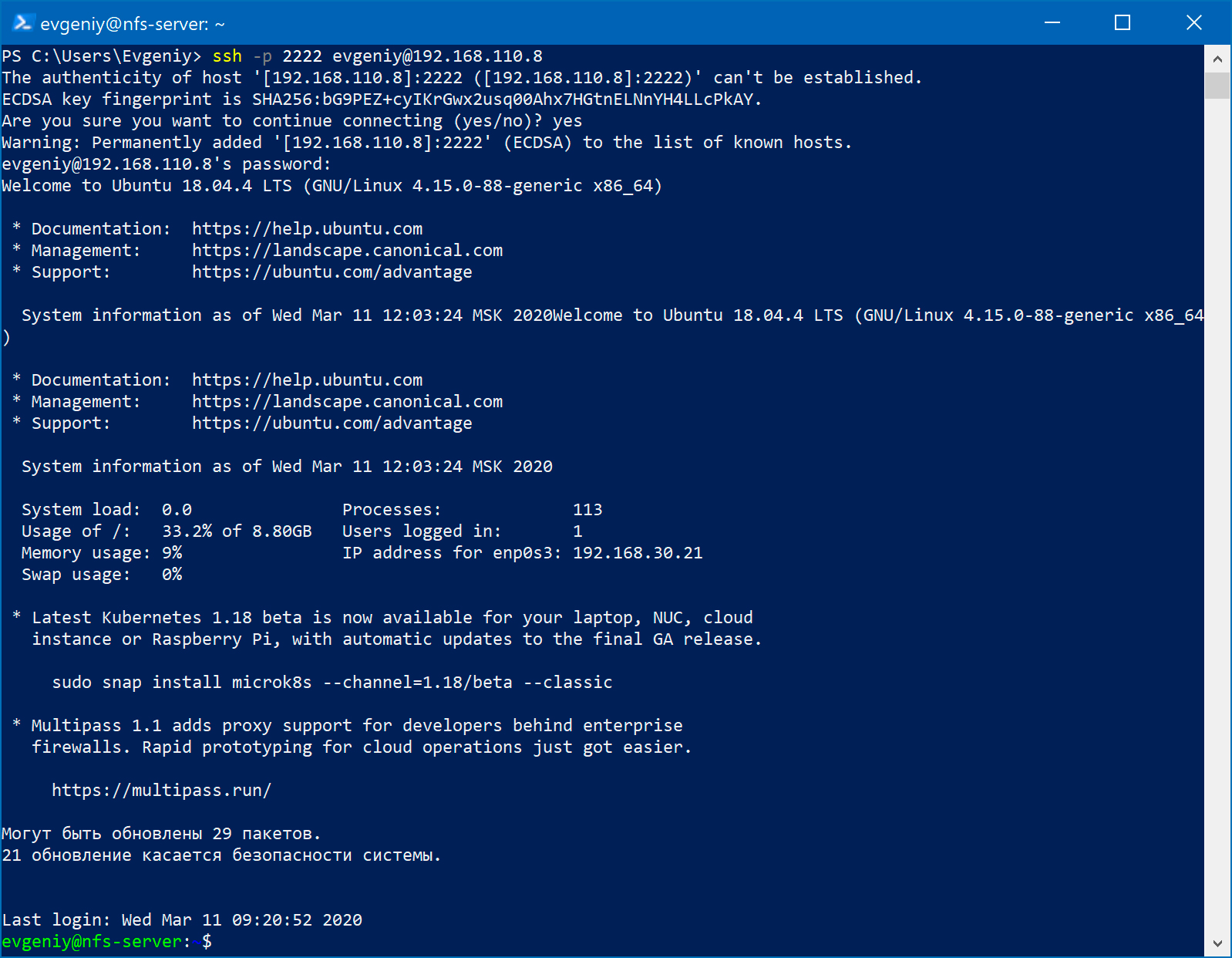
Чтобы иметь возможность управлять серверами, на каждый из них установлен SSH-сервер. И нужно обеспечить доступ к ним из внешней подсети 192.168.110.0/24 . Для этого выполняем на маршрутизаторе три команды:
Первая комнанда — мы отбираем tcp-пакеты, которые приходят на интерфейс enp0s3 на порт 2222 и отправляем эти пакеты виртуальной машине nfs-server на порт 22 , заменяя в пакетах пункт назначения на 192.168.30.2 . Вторая и третья команды позволяют получить доступ к ftp-server и web-server .
Открываем на физическом компьютере окно PowerShell и выполняем команду:
Сохранение правил netfilter
Созданные с помощью утилиты iptables правила пропадут при перезагрузке виртуальной машины router . Так что их нужно сохранить и восстанавливать при перезагрузке. В этом нам поможет пакет iptables-persistent :
При установке пакета будет предложено сохранить текущие правила iptables :
- в файл /etc/iptables/rules.v4 для протокола IPv4
- в файл /etc/iptables/rules.v6 для протокола IPv6

После установки пакета будет добавлена новая служба netfilter-persistent.service , которая при загрузке системы будет восстанавливать созданные нами правила:
При добавлении новых правил, надо сохранить конфигурацию с помощью команды
Читайте также: