Linux native partition что это
Помните те времена, когда BIOS был 16-битным с адресным пространством в 1 Мб, а вся информация о загрузчиках писалась в MBR? На смену уже давно пришли более гибкие технологии: UEFI (замена BIOS), и GPT (замена MBR).
Предыстория: Понадобилось мне недавно на свой домашний десктоп поставить 2 системы, чтобы разграничить окружение. Kubuntu для разработки на Ruby on Rails (ибо работаю удаленно), и Windows для всяких игрушек в свободное время. Хочу заметить, что несколько лет назад это было достаточно просто: один раздел для винды и один раздел для линукса, загрузчик записывался в MBR. Однако, технологии не стоят на месте, и оказалось, что настройка dual boot'а теперь несколько изменилась.
Итак, начнем.
Терминология
UEFI (Unified Extensible Firmware Interface, Единый расширяемый интерфейс прошивки) разрабатывался компанией Intel как замена BIOS (Basic Input Output System). В отличие от 16-битного BIOS'а UEFI работает в 32- или 64-битном режиме, что позволяет использовать намного больше памяти для сложных процессов. Кроме того, UEFI приятно выглядит и там есть поддержка мышки.
- Количество разделов: MBR поддерживает только 4 раздела. Можно и больше, но только через extended partition, что является просто хаком ограничений. GPT поддерживает до 128 разделов.
- Размер диска: MBR поддерживает диски до 2Тб, в то время как GPT — до 9.4 Зеттабайт (=9.4 × 10^21 байт, или условно 1000 Тб)
- Порядок загрузки: раньше BIOS загружал MBR, и в нем содержались адреса загрузчиков для каждого раздела диска. Теперь UEFI считывает GPT, находит в таблице все разделы типа efi (на них содержатся загрузчики), и подгружает их в память. Разберем это на примере немного позже.
Что делаем:
- Windows 8.1 x64. Windows поддерживает загрузку с GPT начиная с Windows 8 для 32 битной архитектуры и с Windows Server 2003 и Windows Vista для 64 бит (Источник).
- Kubuntu 15.04. По идее подойдет любой дистрибутив, который поддерживает Grub2, лично я предпочитаю Kubuntu.
Разбивка диска
Сначала устанавливаем Windows 8, т.к. она автоматически будет использовать GPT.
Разбивка будет выглядеть так (пардон за кривой снимок):
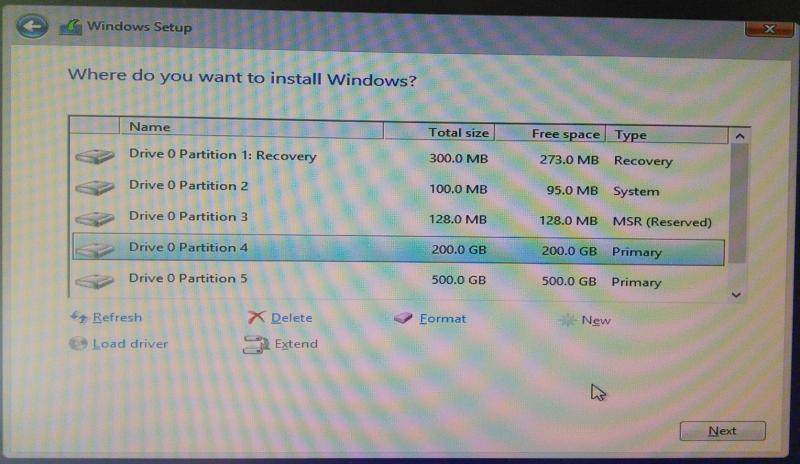
- Recovery (300Мб). Очевидно, что он используется для восстановления системы. Оставим как есть.
- EFI partition (100Мб). Помечается как system type (не любят в Майкрософте называть вещи своими техническими именами). Собственно сюда и пишутся загрузчики.
- MSR (128Мб, Microsoft Reserved Partition). Для меня остается загадкой, зачем он нужен. Данных там никаких нет, просто пустое место, зарезервированное для каких-то непонятных целей в будущем.
- Основной раздел. Мы его поделим на 3: 200 гигов под винду, 500 гигов для раздела под данные и остальное пространство пока оставим неразмеченным (отформатируем потом при установке Kubuntu).
Пропустим саму установку Windows, т.к. в ней все стандартно и понятно.
Теперь загрузимся с USB в Kubuntu Live.
Проверим EFI раздел:
Boot0000 — виндовый загрузчик
Boot0001 — дефолтный загрузчик
Boot0003 — флешка с Kubuntu Live
Обратите внимание, что список загрузчиков не привязан к одному физическому диску как в MBR. Он хранится в NVRAM.
Можем также сразу посмотреть, что же в этом разделе, подмонтировав его:
Там окажутся следующие файлы:
Убедились, что все хорошо. Теперь продолжаем разбивку диска (через KDE Partition Manager).

- sda2 определился как FAT32. Это практически верно, т.к. файловая система типа EFI основана на FAT, только с жесткими спецификациями.
- sda3 (MSR) не определился, т.к. файловой системы там так таковой нет.
Нам осталось только отформатировать раздел для Kubuntu в ext4, и выделить раздел под swap.
Несколько слов про swap. Рекомендуют на swap выделять от SQRT(RAM) до 2xRAM. Т.к. у меня 16 Гб RAM, то по минимуму мне надо 4 Гб свопа. Хотя я с трудом могу представить ситуации, при которых он будет использоваться: десктоп в hibernate я не перевожу, и сильно тяжелых программ, которые жрут больше 16 гигов, не использую.
P.S. При форматировании раздела в swap Partition Manager может выдать ошибки, которые связаны с тем, что Kubuntu автоматически монтирует в себя любой swap раздел, однако на результат эти ошибки не влияют.
Итак, финальная разбивка:

Теперь самое главное для правильного dual boot'а. При установке Kubuntu важно выбрать, куда установить загрузчик:

Указываем, конечно же на раздел EFI.
После завершения установки Kubuntu, заходим в систему и проверяем, какие файлы появились на efi разделе (монтировать уже не нужно):
Смотрим, как теперь выглядит список загрузчиков:
Вот как это выглядит при загрузке:

А еще эти загрузчики доступны сразу из UEFI (в старом BIOS'е такое было бы невозможно — там был выбор только диска, он просто не знал, что такое загрузчики):
Ну и напоследок: чтобы dual boot правильно работал, в Windows надо обязательно отключить fast boot. Это такая нехорошая фича, которая может привести к потере данных.

При выключении компьютера Windows сохраняет файловую структуру NTFS разделов в файл (видимо, потому что один файл прочитать быстрее, чем сканировать много разных файлов). Если записать файл на NTFS раздел через линукс, и потом загрузиться в Windows, то Windows просто не увидит файл. Источник
Если выключить комп через Windows, и потом попытаться загрузить Linux, то он просто не запустится из-за «ошибки» NTFS. Источник
Глава 2 Инсталляция вашего Linux сервера (Часть1)
| В этой главе Определите ваше аппаратное обеспечение Создайте загрузочный и корневой диски Классы и методы инсталляции Разбиение диска (Disk Druid) Компоненты инсталляции (Выбор пакетов для инсталляции) Выбор индивидуальных пакетов Описания программ, которые должны быть деинсталлированы из соображений безопасности Как использовать команды RPM Запуск и остановка демонов Описание программы, которые должны быть удалены после инсталляции сервера Программы, которые должны быть установлены после инсталляции сервера Программы установленные на вашем сервере Добавьте цветов на ваш терминал Обновление программ до их последних версий |  |
Мы подготовили эту главу следуя за процедурой инсталляции. Каждый раздел ниже будет проводить вас через различные экраны, которые будут возникать в процессе установки сервера.
Время от времени Red Hat обновляет свою операционную систему на новые версии и добавляет, удаляет и модифицирует некоторые пакеты, изменяет их месторасположения, содержимое и возможности. Недавно Red Hat выпустила версию 6.2 своей операционной системы, которая представляет собой незначительное обновление 6.1. В этой главе мы пытаемся рассмотреть вопросы инсталляции как версии 6.1 так и 6.2. Все разделы в этой секции которые относятся к Red Hat 6.1 будут обозначаться (6.1), разделы относящиеся к Red Hat 6.2 (6.2), а общие для обеих версиях - (All).
Определите ваше аппаратное обеспечение.
- Сколько у вас установлено жестких дисков?
- Каков объем каждого из них?
- Если у вас несколько жестких дисков, то какой из них первичный?
- Какого типа диски у вас установлены (IDE, SCSI)?
- Сколько оперативной памяти установлено у вас?
- Имеете ли вы SCSI адаптеры? Если есть, то кто их производитель и какой они модели?
- Есть ли у вас RAID система? Если есть, то кто ее производитель и какой она модели?
- Мышь какого типа у вас установлена (Microsoft, Logitech, PS/2)?
- Как много в ней кнопок (2/3)?
- Если у вас "серийная" мышь, то к какому порту она подключена (COM1)?
- Кто производитель и какая модель у вашего видеоадаптера? Как много в нем видеопамяти?
- Какой у вас монитор (производитель и модель)?
- Будете ли вы подключены к сети. Если да, то выясните следующее:
- Ваш IP
- Какова сетевая маска.
- Адрес "шлюза по умолчанию"
- IP адрес DNS сервера
- Ваше доменное имя
- Имя вашего компьютера
- Какие сетевые карты у вас установлены (производитель и модель)
Перед тем как сделать загрузочный диск вставьте Official Red Hat Linux CD- ROM часть1 в ваш дисковод. Когда программа спросит имя файла - ответьте boot.img. Чтобы сделать загрузочный диск под MSDOS вам нужно ввести следующие команды (принимаем, что CDROM это диск D:, и в него вставлен Official Red Hat Linux CD-ROM).
C:\> d:
D:\> cd \dosutils
D:\dosutils> rawrite
Enter disk image source file name: ..\images\boot.img
Enter target diskette drive: a:
Please insert a formatted diskette into drive A: and press --ENTER-- :
D:\dosutils>Программа rawrite.exe запрашивает имя образа. Введите boot.img и вставьте дискету в дисковод. Затем программа спрашивает на какой диск записать образ. Ответьте a:. После завершения процедуры подпишите дискету, например "Red Hat boot disk".
Шаг 2.- Выберите язык
- Выберите тип клавиатуры
- Выберите тип мыши
- рабочая станция с GNOME
- рабочая станция с KDE
- Сервер
- Пользовательская
Идея состоит в том, чтобы проинсталлировать минимальное количество пакетов. Меньшее количество программного обеспечение, уменьшает количество потенциальных проблем с безопасностью. Выберите "Custom" и нажмите Next.
Разбиение диска (Disk Druid)(All) Мы принимаем, что вы устанавливаете Linux на новый диск, на котором нет никаких файловых или операционных систем. Хорошая стратегия разбития диска, это разделение его на отдельные разделы для каждой важной файловой системы.
- Защита от DoS (Denial of Service) атак
- Защита от SUID программ
- Более быстрая загрузка
- Облегчение процедуры резервного копирования и обновления
- Улучшенный контроль над смонтированными файловыми системами
- Ограничение для каждой файловой системы возможности роста
Исходя из соображений стабильности и безопасности мы рекомендуем разбить диск согласно принципам описанным ниже. Мы исходили из того, что у вас есть SCSI диск объемом 3.2 GB. Конечно, вы можете изменить размеры разделов, исходя из размеров вашего диска и личных нужд.
Разделы которые необходимо создать на вашем диске.
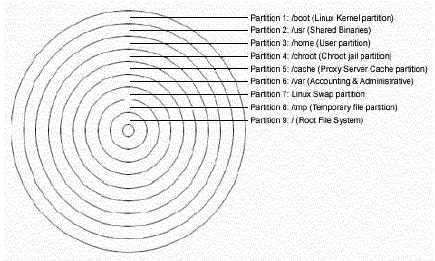
/boot 5MB Образы ядер находятся здесь. /usr 512MB Должен быть большим. Все двоичные файлы Linux хранятся здесь. /home 1146MB Пропорционально числу пользователей (например, 10MB на пользователя * число пользователей 114 = 1140MB). /chroot 256MB Если вы будете использовать программы с CHROOT (например DNS). /cache 256MB Кэш раздел для прокси сервера (например, Squid). /var 256MB Содержит файлы которые изменяются при нормальной работе системы (например, логфайлы). <Swap> 128MB swap раздел. Виртуальная память Linux. /tmp 256MB Раздел для временных файлов. / 256MB Корневой раздел. ![]()
Все основные файловые системы на отдельных раздела.Мы создаем два специальных раздела /chroot и /cache. /chroot - для программ умеющий менять корневую файловую систему (chroot). К ним относятся DNS- сервер, Apache веб-сервер и ряд других программ. Раздел /cache предназначен для кэширующего прокси сервера Squid. Если вы не хотите использовать Squid, то вы можете не создавать его.
Расположите /tmp и /home на отдельных разделах, особенно если пользователи вашего сервера имеют shell-доступ к нему. Также хорошей идеей будет разместить на независимых разделах /var и /usr. Отделение /var защитит ваш корневой раздел от переполнения.
В нашей конфигурации мы зарезервировали 256 MB под /chroot. Это связано с тем, что на нем будут располагаться файлы из Apache DocumentRoot и другие исполняемые файлы, связанные с Apache. Заметим, что размер каталога Apache на /chroot зависит от общего объема занимаемого файлами из "DocumentRoot". Если вы не планируете использовать Apache, то можете уменьшить размер этого раздела до 10 MB. Этого должно хватить для DNS-сервера.
Минимальные размеры разделов.Ниже приведены минимальные размеры разделов при которых система корректно функционирует. Это действительно самые минимальные цифры. Они взяты исходя из размеров старых жестких дисков - 512 MB.
/ 35MB /boot 5MB /chroot 10MB /home 100MB /tmp 30MB /usr 232MB /var 25MB Disk Druid - это утилита, которая облегчает процедуру разбиения диска на разделы. Выберите "Add" для создания нового раздела, "Edit" для редактирования раздела, "Delete" для удаления раздела и "Reset" сбросить последние изменения в исходное состояние. Когда вы создаете новый раздел перед вами появляется новый экран, в котором вы должны определить ряд параметров.
Точка монтирования (Mount Point): место в файловой системе куда будет монтироваться данный раздел.
Size (Megs): размер нового раздела в мегабайтах.
Partition Type: Тип раздела: Linux native для файловой системы Linux и Swap для Linux Swap раздела.
Если у вас SCSI диск, то устройство называется "/dev/sda", а если IDE диск, то "/dev/hda". Если вы стремитесь к высокой производительности и стабильности, то используйте SCSI диски.
Для описания дисков в Linux используется комбинация из букв и цифр.
Первые две буквы - первые две буквы из названия устройства. Например, "hd" (для IDE дисков) или "sd" (для SCSI дисков).
Следующая буква - Эта буква показывает порядок подключения устройств к интерфейсу.Например, "/dev/hda" (первый IDE диск) и "/dev/hdb" (второй IDE диск).
A swap partitionSwap раздел используется для поддержки виртуальной памяти. Если ваш компьютер имеет 16 MB памяти или меньше, то swap раздел вам просто необходим. Если памяти у вас много больше, то его все равно рекомендуется создавать. Минимальный размер swap-раздела должен быть равен объему RAM, но не меньше 16 MB. Наибольший его размер 1 GB (столько поддерживает ядра серии 2.2). Вы можете создать и использовать более одного swap-раздела. Swap-раздел лучше располагать в начале диска. Физически начало диска находится на внешней части цилиндра, поэтому головка за один оборот охватывает большую поверхность.
Ниже приведен пример разбиения диска при помощи утилиты Disk Druid:
Add
Mount Point: /boot - ваш /boot каталог.
Size (Megs): 5
Partition Type: Linux Native
Ok
Add
Mount Point: /usr - ваш /usr каталог.
Size (Megs): 512
Partition Type: Linux Native
Ok
Add
Mount Point: /home - ваш /home каталог.
Size (Megs): 1146
Partition Type: Linux Native
Ok
Add
Mount Point: /chroot - ваш /chroot каталог.
Size (Megs): 256
Partition Type: Linux Native
Ok
Add
Mount Point: /cache - ваш /cache каталог.
Size (Megs): 256
Partition Type: Linux Native
Ok
Add
Mount Point: /var - ваш /var каталог.
Size (Megs): 256
Partition Type: Linux Native
Ok
Add
Mount Point: - ваш /Swap раздел (не имеет точки монтирования на вашей файловой системе).
Size (Megs): 128
Partition Type: Linux Swap
Ok
Add
Mount Point: /tmp - ваш /tmp каталог.
Size (Megs): 256
Partition Type: Linux Native
Ok
Add
Mount Point: - ваш корневой каталог.
Size (Megs): 256
Partition Type: Linux Native
OkПо окончании процедуры разбиения диска у вас должна получиться следующее:
Точка монтирования Устройство Объем требуемый Объем выделенный Тип файловой системы /boot Sda1 5M 5M Linux Native /usr Sda5 512M 512M Linux Native /home Sda6 1146M 1146M Linux Native /chroot Sda7 256M 256M Linux Native /cache Sda8 256M 256M Linux Native /var Sda9 256M 256M Linux Native <Swap> Sda10 128M 128M Linux Swap /tmp Sda11 256M 256M Linux Native / Sda12 256M 256M Linux Native Drive Geom [C/H/S] Total (M) Free (M) Used (M) Used (%) sda [3079/64/32] 3079M 1M 3078M 99% Сейчас, когда вы разбили диск и определили точки монтирования для разделов, нажмите Next для продолжения. После того, как новые разделы созданы, вам будет предложено отформатировать их. Выберите раздел для инициализации, поставьте "галочку" напротив "проверить диски на плохие блоки" и нажмите Next. Раздел будет отформатирован и станет доступен для использования под Linux.
- В Master Boot Record (MBR)
- В первый сектор загрузочного раздела.
- Включить MD5 пароли
- Включить теневые пароли
Замечание: Выбрать эту опцию (Select individual packages) очень важно до продолжения процедуры инсталляции.
Выбор индивидуальных пакетовИнсталляционная программа представит список доступных групп с пакетами, выберите необходимую группу для проверки. Пакеты перечисленные ниже должны быть удалены из соображений безопасности, оптимизации и ряда других причин.
Для того, чтобы продолжить установку нам надо иметь разделы под Linux. Для разбиения диска можно запустить программы fdisk или cfdisk. Программа cfdisk с более дружелюбным пользовательским интерфейсом, поэтому при желании можете запустить ее. Я же запущу fdisk:
Для того, чтобы вызвать помощь нужно набрать букву m и нажать Enter:
Нам надо создать как минимум два новых раздела на диске. Первый раздел типа swap, который является неким подобием памяти на диске. Этот раздел используется системой, когда не хватает основной памяти. Давайте его создадим, нажмем "n" - создать новый раздел. Программа предложит выбрать тип раздела:
Для своп-раздела лучше выбрать тип primary. Нажимаем p. Далее вводим номер раздела, у нас он самый первый, поэтому:
Далее требуется ввести начальный цилиндр для этого раздела, не будем особо демать над этим, у нас это самый первый раздел значит введем 1 или просто нажмем Enter.
Теперь требуется ввести размер раздела. Про размер своп-раздела можно говорить долго. Если у Вас памяти много, то размер этого раздела может быть не большим, но с другой стороны Linux это не Windows, он не может динамически менять размер "файла подкачки", поэтому если ему не будет хватать основной памяти, то лучше сделать этот раздел побольше. В конце концов лучше посмотреть на размер жесткого диска, и если он больше нескольких гигабайт, то зачем экономить на мегабайтах ? Лучше сделать этот раздел больше 64 Мб, например, 256 или 300. Сейчас я устанавливаю систему на небольшой винчестер, поэтому место на нем лучше чуток экономить, поэтому сделаю раздел в 64 Мб.
Теперь если вывести список разделов командой p, то получим следующую картинку:
Видим что появился раздел, но не чуть не того типа. Тип Linux native будет нужен для других разделов, а для своп-раздела надо поменять Id. Выбираем команду смены типа t:
Чтобы узнать нужный нам код ID введем L для просмотра листинга. Приводить весь листинг из более чем 40 кодов не буду, посмотрите сами, а я Вам просто скажу, что нужен тип 82 - Linux swap.
Теперь создадим второй раздел, для корневого каталога. В данный раздел будет производиться установка нашей системы.
Теперь количество разделов увеличилось:
По идее можно было бы создать еще несколько разделов, для разных нужд, но для обучения хватит и этих. Однако помните что если вы потеряете по какой-то причине один раздел, то возможно другие останутся целыми. Поэтому я не рекомендую создавать разделы по 20 Гб. У меня уже было два раза, когда такие разделы "залечивались" какими-нибудь Norton DiskDoctor, поверьте ощущения от потери 20 Гб информации рамые мерзопакостные. А еще лучше, если у Вас будет несколько отдельных винчестеров %)
Думаю остался один штрих, но незнаю нужен ли он. По идее бы надо установить признак Boot на раздел /dev/hda2, но возможно и не обязательно. Ладно, не буду ставить, а там посмотрим :)
Для выхода нам надо записать таблицу разбиения на диск командой w.
Прим перев.: Автор оригинальной статьи — испанский Open Source-энтузиаст nachoparker, развивающий проект NextCloudPlus (ранее известен как NextCloudPi), — делится своими знаниями об устройстве дисковой подсистемы в Linux, делая важные уточнения в ответах на простые, казалось бы, вопросы…
Сколько пространства занимает этот файл на жёстком диске? Сколько свободного места у меня есть? Сколько ещё файлов я смогу вместить в оставшееся пространство?
![]()
Ответы на эти вопросы кажутся очевидными. У всех нас есть инстинктивное понимание работы файловых систем и зачастую мы представляем хранение файлов на диске аналогично заполнению корзины яблоками.
Однако в современных Linux-системах такая интуиция может вводить в заблуждение. Давайте разберёмся, почему.
Размер файла
Что такое размер файла? Ответ вроде бы прост: совокупность всех байтов его содержимого, от начала до конца файла.
Зачастую всё содержимое файла представляется как расположенное байт за байтом:
![]()
Так же мы воспринимаем и понятие размер файла. Чтобы его узнать, выполняем ls -l file.c или команду stat (т.е. stat file.c ), которая делает системный вызов stat() .
В ядре Linux структурой памяти, представляющей файл, является inode. И метаданные, к которым мы обращаемся с помощью команды stat , находятся именно в inode.
Здесь можно увидеть знакомые атрибуты, такие как время доступа и модификации, а также i_size — это и есть размер файла, как он был определён выше.Размышлять в терминах размера файла интуитивно понятно, но больше нас интересует, как в действительности используется пространство.
Блоки и размер блока
Для внутреннего хранения файла файловая система разбивает хранилище на блоки. Традиционным размером блока были 512 байт, но более актуальное значение — 4 килобайта. Вообще же при выборе этого значения руководствуются поддерживаемым размером страницы на типовом оборудовании MMU (memory management unit, «устройство управления памятью» — прим. перев.).
Файловая система вставляет порезанный на части (chunks) файл в эти блоки и следит за ними в метаданных. В идеале всё выглядит так:
![]()
… но в действительности файлы постоянно создаются, изменяются в размере, удаляются, поэтому реальная картина такова:
![]()
Это называется внешней фрагментацией (external fragmentation) и обычно приводит к падению производительности. Причина — вращающейся головке жёсткого диска приходится переходить с места на место, чтобы собрать все фрагменты, а это медленная операция. Решением данной проблемы занимаются классические инструменты дефрагментации.
Что происходит с файлами меньше 4 КБ? Что происходит с содержимым последнего блока после того, как файл был порезан на части? Естественным образом будет возникать неиспользуемое пространство — это называется внутренней фрагментацией (internal fragmentation). Очевидно, этот побочный эффект нежелателен и может привести к тому, что многое свободное пространство не будет использоваться, особенно если у нас большое количество очень маленьких файлов.
Итак, реальное использование диска файлом можно увидеть с помощью stat , ls -ls file.c или du file.c . Например, содержимое 1-байтового файла всё равно занимает 4 КБ дискового пространства:
Таким образом, мы смотрим на две величины: размер файла и использованные блоки. Мы привыкли думать в терминах первого, однако должны — в терминах последнего.Специфичные для файловой системы возможности
Помимо актуального содержимого файла ядру также необходимо хранить все виды метаданных. Метаданные inode'а мы уже видели, но есть и другие данные, с которыми знаком каждый пользователь UNIX: права доступа, владелец, uid, gid, флаги, ACL.
Наконец, существуют ещё и другие структуры — вроде суперблока (superblock) с представлением самой файловой системы, vfsmount с представлением точки монтирования, а также информация об избыточности, именные пространства и т.п. Как мы увидим далее, некоторые из этих метаданных также могут занимать значительное место.Метаданные размещения блоков
Эти данные сильно зависят от используемой файловой системы — в каждой из них по-своему реализовано сопоставление блоков с файлами. Традиционный подход ext2 — таблица i_block с прямыми и непрямыми блоками (direct/indirect blocks).
![]()
Эту же таблицу можно увидеть в структуре памяти (фрагмент из fs/ext2/ext2.h ):
Для больших файлов такая схема приводит к большим накладным расходам, поскольку единственный (большой) файл требует сопоставления тысяч блоков. Кроме того, есть ограничение на размер файла: используя такой метод, 32-битная файловая система ext3 поддерживает файлы не более 8 ТБ. Разработчики ext3 спасали ситуацию поддержкой 48 бит и добавлением extents:
Идея по-настоящему проста: занимать соседние блоки на диске и просто объявлять, где extent начинается и каков его размер. Таким образом мы можем выделять файлу большие группы блоков, минимизируя количество метаданных и заодно используя более быстрый последовательный доступ.Примечание для любопытных: у ext4 предусмотрена обратная совместимость, то есть в ней поддерживаются оба метода: непрямой (indirect) и extents. Увидеть, как распределено пространство, можно на примере операции записи. Запись не идёт напрямую в хранилище — из соображений производительности данные сначала попадают в файловый кэш. После этого в определённый момент кэш записывает информацию на постоянное хранилище.
Кэш файловой системы представлен структурой address_space , в которой вызывается операция writepages. Вся последовательность выглядит так:
… где ext4_map_blocks() вызовет функцию ext4_ext_map_blocks() или ext4_ind_map_blocks() в зависимости от того, используются ли extents. Если взглянуть на первую в extents.c , можно увидеть упоминания дыр (holes), о которых будет рассказано ниже.Контрольные суммы
Файловые системы последнего поколения хранят также контрольные суммы (checksums) для блоков данных во избежание незаметного повреждения данных. Эта возможность позволяет обнаруживать и корректировать случайные ошибки и, конечно, ведёт к дополнительным накладным расходам в использовании диска пропорционально размеру файлов.
Более современные системы вроде BTRFS и ZFS поддерживают контрольные суммы для данных, а у более старых, таких как ext4, реализованы контрольные суммы для метаданных.
Журналирование
Возможности журналирования для ext2 появились в ext3. Журнал — циклический лог, записывающий обрабатываемые транзакции с целью улучшить устойчивость к сбоям питания. По умолчанию он применяется только к метаданным, однако можно его активировать и для данных с помощью опции data=journal , что повлияет на производительность.
Это специальный скрытый файл, обычно с номером inode 8 и размером 128 МБ, объяснение про который можно найти в официальной документации:
Журнал, представленный в файловой системе ext3, используется в ext4 для защиты ФС от повреждений в случае системных сбоев. Небольшой последовательный фрагмент диска (по умолчанию это 128 МБ) зарезервирован внутри ФС как место для сбрасывания «важных» операций записи на диск настолько быстро, насколько это возможно. Когда транзакция с важными данными полностью записана на диск и сброшена с кэша (disk write cache), запись о данных также записывается в журнал. Позже код журнала запишет транзакции в их конечные позиции на диске (операция может приводить к продолжительному поиску или большому числу операций чтения-удаления-стирания) перед тем, как запись об этих данных будет стёрта. В случае системного сбоя во время второй медленной операции записи журнал позволяет воспроизвести все операции вплоть до последней записи, гарантируя атомарность всего, что пишется на диск через журнал. Результатом является гарантия, что файловая система не застрянет на полпути обновления метаданных.
«Упаковка хвостов»
Возможность tail packing, ещё называемая блочным перераспределением (block suballocation), позволяет файловым системам использовать пустое пространство в конце последнего блока («хвосты») и распределять его среди различных файлов, эффективно упаковывая «хвосты» в единый блок.
![]()
Замечательно иметь такую возможность, что позволяет сохранить много пространства, особенно если у вас большое количество маленьких файлов… Однако она приводит к тому, что существующие инструменты неточно сообщают об используемом пространстве. Потому что с ней мы не можем просто добавить все занятые блоки всех файлов для получения реальных данных по использованию диска. Эту фичу поддерживают файловые системы BTRFS и ReiserFS.
Разрежённые файлы
Большинство современных файловых систем поддерживают разрежённые файлы (sparse files). У таких файлов могут быть дыры, которые в действительности не записаны на диск (не занимают дисковое пространство). На этот раз реальный размер файла будет больше, чем используемые блоки.
![]()
Такая особенность может оказаться очень полезной, например, для быстрой генерации больших файлов или для предоставления свободного пространства виртуальному жёсткому диску виртуальной машины по запросу.
Чтобы медленно создать 10-гигабайтный файл, который занимает около 10 ГБ дискового пространства, можно выполнить:
Чтобы создать такой же большой файл мгновенно, достаточно лишь записать последний байт… или даже сделать:
Или же воспользоваться командой truncate :
Дисковое пространство, выделенное файлу, можно изменить командой fallocate , которая делает системный вызов fallocate() . С этим вызовом доступны и более продвинутые операции — например:- Предварительно выделить пространство для файла вставкой нулей. Такая операция увеличивает и использование дискового пространства, и размер файла.
- Освободить пространство. Операция создаст дыру в файле, делая его разрежённым и уменьшая использование пространства без влияния на размер файла.
- Оптимизировать пространство, уменьшив размер файла и использование диска.
- Увеличить пространство файла, вставив дыру в его конец. Размер файла увеличивается, а использование диска не меняется.
- Обнулить дыры. Дыры станут не записанными на диск extents, которые будут читаться как нули, не влияя на дисковое пространство и его использование.
Команда cp поддерживает работу с разрежёнными файлами. С помощью простой эвристики она пытается определить, является ли исходный файл разрежённым: если это так, то результирующий файл тоже будет разрежённым. Скопировать же неразрежённый файл в разрежённый можно так:
… а обратное действие (сделать «плотную» копию разрежённого файла) выглядит так:
Таким образом, если вам нравится работать с разрежёнными файлами, можете добавить следующий алиас в окружение своего терминала (
Когда процессы читают байты в секциях дыр файловая система предоставляет им страницы с нулями. Например, можно посмотреть, что происходит, когда файловый кэш читает из файловой системы в области дыр в ext4. В этом случае последовательность в readpage.c будет выглядеть примерно так:(cache read miss) ext4_aops-> ext4_readpages() -> . -> zero_user_segment()
После этого сегмент памяти, к которому процесс пытается обратиться с помощью системного вызова read() , получит нули напрямую из быстрой памяти.
Файловые системы COW (copy-on-write)
Следующее (после семейства ext) поколение файловых систем принесло очень интересные возможности. Пожалуй, наибольшего внимания среди фич файловых систем вроде ZFS и BTRFS заслуживает их COW (copy-on-write, «копирование при записи»).
Когда мы выполняем операцию copy-on-write или клонирования, или копии reflink, или поверхностной (shallow) копии, на самом деле никакого дублирования extent'ов не происходит. Просто создаётся аннотация в метаданных для нового файла, которая отсылает к тем же самым extents оригинального файла, а сам extent помечается как разделяемый (shared). При этом в пользовательском пространстве создаётся иллюзия, что существуют два отдельных файла, которые можно отдельно модифицировать. Когда какой-то процесс захочет написать в разделяемый extent, ядро сначала создаст его копию и аннотацию, что этот extent принадлежит единственному файлу (по крайней мере, на данный момент). После этого у двух файлов появляется больше отличий, однако они все ещё могут разделять многие extents. Другими словами, extents в файловых системах с поддержкой COW можно делить между файлами, а ФС обеспечит создание новых extents только в случае необходимости.
![]()
Как видно, клонирование — очень быстрая операция, не требующая удваивания пространства, которое используется в случае обычной копии. Именно эта технология и стоит за возможностью создания мгновенных снапшотов в BTRFS и ZFS. Вы можете буквально клонировать (или сделать снапшот) всей корневой файловой системы меньше чем за секунду. Очень полезно, например, перед обновлением пакетов на случай, если что-то сломается.
BTRFS поддерживает два метода создания shallow-копий. Первый относится к подтомам (subvolumes) и использует команду btrfs subvolume snapshot . Второй — к отдельным файлам и использует cp --reflink . Такой алиас (опять же, для
/.bashrc ) может пригодиться, если вы хотите по умолчанию делать быстрые shallow-копии:
cp='cp --reflink=auto --sparse=always'
Следующий шаг — если есть не-shallow-копии или файл, или даже файлы, с дублирующимися extents, можно дедуплицировать их, чтобы они использовали (через reflink) общие extents и освободили пространство. Один из инструментов для этого — duperemove, однако учтите, что это естественным образом приводит к более высокой фрагментации файлов.
Если мы попытаемся теперь разобраться, как дисковое пространство используется файлами, всё будет не так просто. Утилиты вроде du или dutree всего лишь считают используемые блоки, не учитывая, что некоторые из них могут быть разделяемыми, поэтому они покажут больше занятого места, чем на самом деле используется.
Аналогичным образом, в случае BTRFS стоит избегать команды df , поскольку пространство, занятое файловой системой BTRFS, она покажет как свободное. Лучше пользоваться btrfs filesystem usage :
К сожалению, я не знаю простых способов отслеживания занятого пространства отдельными файлами в файловых системах с COW. На уровне подтома с помощью утилит вроде btrfs-du мы можем получить приблизительное представление о количестве данных, которые уникальны для снапшота и которые разделяются между снапшотами.Читайте также: