
Centos 7 backup системы со всеми настройками
Данное руководство научит создавать резервные копии удаленного хоста CentOS 7 с помощью Bacula. Вы узнаете, как установить Bacula Client на удаленный хост и откорректировать настройки существующего хоста Bacula Server.
Требования
- Компоненты Bacula Server, установленные согласно этому руководству.
- Частная сеть для взаимодействия клиента и сервера Bacula.
- FQDN серверов должен указывать на внутренний IP-адрес. Если у вас нет соответствующих настроек DNS, вместо этого можно использовать IP-адреса серверов.
- В руководстве используются условные данные: сервер Bacula будет называться BaculaServer, или сервер бэкапа; удаленные хосты называются ClientHost, или клиенты бэкапа.
Настройка Bacula Director
Перейдите на BaculaServer.
При настройке сервера Bacula вы, возможно, заметили, что файлы конфигурации слишком длинные. Попытаемся немного систематизировать конфигурацию Bacula Director. Создайте отдельные файлы для добавления новой конфигурации, например заданий, наборов файлов и пулов.
Создайте каталог для конфигурационных файлов Bacula:
sudo mkdir /etc/bacula/conf.d
Откройте конфигурационный файл Bacula Director:
sudo vi /etc/bacula/bacula-dir.conf
В конец файла вставьте строку:
@|"find /etc/bacula/conf.d -name '*.conf' -type f -exec echo @<> \;"
Сохраните и закройте файл. Теперь Director сможет искать дополнительные настройки в других файлах каталога /etc/bacula/conf.d. Любой файл с расширением .conf будет восприниматься как часть конфигурации.
Пул RemoteFile
Добавьте в настройку Bacula Director новый пул для резервного копирования удаленных серверов.
sudo vi /etc/bacula/conf.d/pools.conf
Добавьте ресурс Pool:
Сохраните и закройте файл. Эти строки определяют пул RemoteFile, который будет использоваться для резервного копирования клиентов. Все параметры можно отладить согласно вашим требованиям.
Пока что перезапускать Bacula Director не нужно. Просто убедитесь, что в файле нет ошибок.
sudo bacula-dir -tc /etc/bacula/bacula-dir.conf
Установка и настройка Bacula Client
Примечание: Этот раздел нужно выполнить на всех клиентах бэкапа.
Установите пакет bacula-client.
sudo yum install bacula-client
Эта команда установит File Daemon (FD).
Настройка клиента
Перед настройкой File Daemon нужно иметь в виду следующую условную информацию, которая будет использоваться в течение оставшейся части этого руководства:
Эти условные данные нужно заменять своими данными.
Далее нужно будет добавить в настройки File Daemon пароль, который позволит Bacula Director подключиться нему. Сгенерируйте случайный пароль (можно пропустить этот шаг и создать свой собственный пароль):
date +%s | sha256sum | base64 | head -c 33 ; echo
Скопируйте полученный пароль, чтобы использовать его в дальнейшем.
Откройте конфигурационный файл File Daemon:
sudo vi /etc/bacula/bacula-fd.conf
В нем нужно изменить несколько элементов и найти информацию, которая понадобится для дальнейшей конфигурации сервера.
Найдите ресурс Director с именем вашего клиентского хоста (например, ClientHost-dir). Измените значение параметра Name и укажите в нем имя хоста сервера бэкапа с суффиксом –dir. Например:
Director Name = BackupServer-dir
Password = "Y2Q5ODUyMWM0YTFhYjA3NTcwYmU5OTA4Y"
>
Затем нам нужно откорректировать один параметр в ресурсе FileDaemon. Измените параметр FDAddress, укажите в нем FQDN клиентской машины. Параметр Name уже должен содержать правильное имя демона FD клиента. Ресурс должен выглядеть примерно так (замените условные данные):
Messages Name = Standard
director = BackupServer-dir = all, !skipped, !restored
>
Сохраните и закройте файл. Клиент и File Daemon настроены.
Проверьте ошибки в файле:
sudo bacula-fd -tc /etc/bacula/bacula-fd.conf
Если команда не сообщила вам об ошибках, значит, в файле их нет.
Перезапустите демон, чтобы обновить настройки.
sudo systemctl restart bacula-fd
Теперь настройте каталог, в котором Bacula Server сможет хранить восстановленные файлы. Создайте структуру каталогов и заблокируйте доступ к ней:
sudo mkdir -p /bacula/restore
sudo chown -R bacula:bacula /bacula
sudo chmod -R 700 /bacula
Добавление файлов FileSet
Примечание: Данный раздел нужно выполнить на сервере.
FileSet определяет список файлов и каталогов, которые нужно включить или исключить из резервного копирования.
Если вы выполнили руководство по установке Bacula Server, у вас уже есть FileSet по имени Full Set. Если вы хотите, чтобы система Bacula копировала почти все файлы системы, можете использовать этот FileSet в задачах. Но обычно для восстановления не нужно иметь бэкап всех файлов, потому этот набор желательно сократить, чтобы сэкономить дисковое пространство.
Тщательный отбор файлов, включенных в FileSet, экономит не только объем дискового пространства, но и время, требуемое для запуска задания резервного копирования. Это также может упростить восстановление, поскольку вам не нужно просматривать весь Full Set, чтобы найти файлы, которые нужно восстановить.
Попробуйте создать новые ресурсы FileSet.
На сервере Bacula откройте файл filesets.conf в конфигурационном каталоге Bacula Director:
sudo vi /etc/bacula/conf.d/filesets.conf
Создайте ресурс FileSet для каждого конкретного набора файлов, который вы хотите использовать в задачах резервного копирования. В этом примере показано, как создать FileSet, который включает только домашний каталог и каталог etc:
FileSet Name = "Home and Etc"
Include Options signature = MD5
compression = GZIP
>
File = /home
File = /etc
>
Exclude File = /home/bacula/not_important
>
>
- Имя FileSet должно быть уникальным.
- В FileSet нужно указать все файлы или разделы, бэкап которых нужно выполнить.
- Чем меньше в FileSet лишних и ненужных файлов, тем продуктивнее резервное копирование.
- Количество FileSet не ограничено.
Добавление задач Client и Backup на сервер Bacula
Чтобы добавить клиентский хост в настройки сервера Bacula, создайте в настройках Bacula Director новые ресурсы – Client и Job.
sudo vi /etc/bacula/conf.d/clients.conf
Добавление ресурса Client
Ресурс Client предоставляет Director информацию, необходимую ему для подключения к хосту клиента. Сюда входят имя, адрес и пароль File Daemon клиента.
Вставьте в файл этот ресурс Client.
Примечание: Замените условные данные.
Создание задачи Backup
Задача Backup определяет клиента и файлы, которые нужно скопировать. Имя задачи должно быть уникальным.
Вставьте задачу в файл conf.d/clients.conf.
Job Name = "BackupClientHost"
JobDefs = "DefaultJob"
Client = ClientHost-fd
Pool = RemoteFile
FileSet="Home and Etc"
>
Сохраните и закройте файл.
Проверка настроек Bacula Director
Убедитесь, что в файле Bacula Director нет ошибок:
sudo bacula-dir /etc/bacula/bacula-dir.conf
Перезапуск Bacula Director
Чтобы обновить настройки, перезапустите Bacula Director.
sudo systemctl restart bacula-dir
Теперь сервер Bacula сможет создавать резервные копии удаленного хоста.
Тестирование подключения клиента
Теперь нужно убедиться, что Bacula Director может подключиться к клиенту Bacula.
На сервере Bacula откройте консоль Bacula:
Команда должна сразу отобразить состояние File Daemon клиента. Если этого не произошло и возникла ошибка, проверьте настройки клиента и сервера Bacula.
Запуск тестовой задачи
Запустите задачу на сервере Bacula.
Команда предложит выбрать задачу, которую нужно запустить. Выберите одну из задач, например 4.
Confirmation prompt:
OK to run? (yes/mod/no): yes
Также вы можете узнать состояние задачи. Для этого нужно запросить состояние Director. Введите в bconsole:
Состояние OK значит, что задача выполнена успешно.
Восстановление данных
Создав резервную копию, важно проверить ее восстановление. Команда restore позволяет восстанавливать скопированные файлы.
Введите в Bacula Console:
На экране появится меню, в котором можно выбрать резервный набор, который необходимо восстановить. Поскольку у вас есть только одна резервная копия, выберите вариант 5, «Select the most recent backup»:
Select item (1-13):
5
Затем будет предложено выбрать клиента. Выберите удаленный хост ClientHost-fd.
Select the Client: ClientHost-fd
Defined Clients:
1: BackupServer-fd
2: ClientHost-fd
Select the Client (1-2): 2
Это переведет вас в виртуальное файловое дерево со всей структурой каталогов, которая находится в резервной копии. Этот интерфейс позволяет добавлять и исключать файлы, которые нужно восстановить.
Поскольку для восстановления использовалась команда restore all, все скопированные файлы уже выбраны. Файлы, которые входят в список восстанавливаемых, отмечены звездочкой *.
Чтобы откорректировать список файлов, вы можете перемещаться и просматривать содержимое с помощью команд cd и ls, а также добавлять и исключать файлы с помощью команд mark и unmark.
Чтобы получить полный список команд, введите help.
Выбрав все необходимые файлы, введите:
OK to run? (yes/mod/no):
yes
Проверьте состояние Director:
Чтобы закрыть Bacula Console, введите:
Если восстановление прошло правильно, вы найдете файлы в каталоге /bacula/restore на клиенте. После тестирования восстановленные файлы можно удалить.
Заключение
Теперь у вас есть сервер и клиент Bacula. Вы можете самостоятельно отладить FileSet, чтобы обеспечить своевременное резервное копирование всех необходимых файлов.
Прежде чем исследовать методы развертывания стандартного плана резервного копирования, специфичные для CentOS, давайте сначала обсудим типичные аспекты политики резервного копирования стандартного уровня. Первое, к чему мы хотим привыкнуть, это правило резервного копирования 3-2-1 .
3-2-1 Стратегия резервного копирования
Во всей отрасли вы часто слышите термин «резервная модель 3-2-1». Это очень хороший подход для реализации плана резервного копирования. 3-2-1 определяется следующим образом: 3 копии данных; например, у нас может быть рабочая копия; копия, помещенная на сервер CentOS, предназначенный для резервирования с использованием rsync; и повернутые резервные копии USB сделаны из данных на сервере резервного копирования. 2 разных резервных носителя. На самом деле в этом случае у нас будет три разных носителя для резервного копирования: рабочая копия на SSD ноутбука или рабочей станции, данные сервера CentOS на массиве RADI6 и внешнее резервное копирование на USB-накопители. 1 копия данных вне офиса; мы вращаем USB-накопители вне площадки каждый вечер. Другим современным подходом может быть поставщик облачного резервного копирования.
Восстановление системы
Полное восстановление данных и восстановление с нуля обычно выполняется с помощью комбинации методов, включая рабочие, настроенные рабочие образы дисков ключевых операционных серверов, избыточные резервные копии пользовательских данных, соблюдая правило 3-2-1. Даже некоторые конфиденциальные файлы, которые могут храниться в безопасном, пожаробезопасном сейфе с ограниченным доступом к персоналу доверенной компании.
План многофазного восстановления и восстановления данных с использованием собственных инструментов CentOS может состоять из:
dd создавать и восстанавливать производственные образы дисков настроенных серверов
rsync для создания инкрементных резервных копий всех пользовательских данных
tar & gzip для хранения зашифрованных резервных копий файлов с паролями и заметками от администраторов. Обычно это можно записать на USB-накопитель, зашифровать и заблокировать в сейфе, к которому имеет доступ старший менеджер. Кроме того, это гарантирует, что кто-то другой будет знать жизненно важные учетные данные безопасности, если текущий администратор выиграет в лотерее и исчезнет на солнечном острове.
dd создавать и восстанавливать производственные образы дисков настроенных серверов
rsync для создания инкрементных резервных копий всех пользовательских данных
tar & gzip для хранения зашифрованных резервных копий файлов с паролями и заметками от администраторов. Обычно это можно записать на USB-накопитель, зашифровать и заблокировать в сейфе, к которому имеет доступ старший менеджер. Кроме того, это гарантирует, что кто-то другой будет знать жизненно важные учетные данные безопасности, если текущий администратор выиграет в лотерее и исчезнет на солнечном острове.
Если система выходит из строя из-за аппаратного сбоя или сбоя, следующие этапы восстановления операций будут следующими:
Создайте рабочий сервер с настроенным голым железным образом
Восстановление данных на рабочий сервер из резервных копий
Иметь физический доступ к учетным данным, необходимым для выполнения первых двух операций
Создайте рабочий сервер с настроенным голым железным образом
Восстановление данных на рабочий сервер из резервных копий
Иметь физический доступ к учетным данным, необходимым для выполнения первых двух операций
Используйте rsync для резервного копирования на уровне файлов
- Исследуйте и поговорите о некоторых распространенных вариантах
- Создать локальные резервные копии
- Создавайте удаленные резервные копии по SSH
- Восстановить локальные резервные копии
rsync назван по назначению: удаленная синхронизация и является мощной и гибкой в использовании.
Ниже приведено базовое удаленное резервное копирование rsync через ssh:
Следующая синхронизация отправила почти 2,3 ГБ данных по нашей локальной сети. Прелесть rsync в том, что он работает постепенно на уровне блоков для каждого файла отдельно. Это означает, что если мы изменим только два символа в текстовом файле размером 1 МБ, только один или два блока будут переданы через сеть при следующей синхронизации!
Кроме того, инкрементная функция может быть отключена в пользу большей пропускной способности сети, используемой для меньшей загрузки ЦП. Это может оказаться целесообразным, если постоянно копировать несколько файлов базы данных по 10 МБ каждые 10 минут на выделенной резервной локальной сети емкостью 1 ГБ. Причина заключается в следующем: они всегда будут меняться и будут передаваться постепенно каждые 10 минут и могут облагаться нагрузкой на удаленный ЦП. Поскольку общая нагрузка передачи не будет превышать 5 минут, мы можем просто синхронизировать файлы базы данных в полном объеме.
Когда использовать rsync
Локальное резервное копирование с rsync
Мы уже видели, как передавать файлы с одного хоста на другой. Тот же метод можно использовать для локальной синхронизации каталогов и файлов.
Давайте сделаем ручное добавочное резервное копирование / etc / в каталоге нашего корневого пользователя.
Во-первых, нам нужно создать каталог с
Затем убедитесь, что на диске достаточно свободного места.
Только наш файл test_incremental.txt был скопирован.
Удаленное дифференциальное резервное копирование с rsync
Давайте сделаем наше первоначальное полное резервное копирование rsync на сервер с развернутым планом резервного копирования. В этом примере фактически выполняется резервное копирование папки на рабочей станции Mac OS X на сервер CentOS. Другим важным аспектом rsync является то, что его можно использовать на любой платформе, на которую был перенесен rsync.
Теперь мы создали резервную копию папки с рабочей станции на сервере с томом RAID6 с повернутым носителем аварийного восстановления, который хранится вне сайта. Использование rsync дало нам стандартное резервное копирование 3-2-1 только с одним сервером, имеющим дорогой избыточный дисковый массив и повернутые дифференциальные резервные копии.
Теперь давайте сделаем еще одну резервную копию этой же папки с помощью rsync после того, как был добавлен новый файл с именем test_file.txt .
Как видите, только новый файл был доставлен на сервер через rsync . Дифференциальное сравнение было сделано для каждого файла отдельно.
Несколько вещей, на которые следует обратить внимание: это только копирует новый файл: test_file.txt, так как это был единственный файл с изменениями. Rsync использует SSH. Нам не нужно было использовать нашу учетную запись root ни на одной машине.
Простой, мощный и эффективный rsync отлично подходит для резервного копирования целых папок и структур каталогов. Однако rsync сам по себе не автоматизирует процесс. Вот где нам нужно покопаться в нашем наборе инструментов и найти лучший, маленький и простой инструмент для работы.
Для автоматизации резервного копирования rsync с помощью cronjobs важно, чтобы пользователи SSH были настроены с использованием ключей SSH для аутентификации. Это в сочетании с cronjobs позволяет выполнять rsync автоматически через определенные промежутки времени.
Используйте DD для блочных изображений восстановления голого металла
Дд в простейшем смысле копирует изображение выбранной области диска. Затем предоставляет возможность копировать выбранные блоки физического диска. Поэтому, если у вас нет резервных копий, когда dd записывает на диск, все блоки заменяются. Потеря предыдущих данных превышает возможности восстановления даже для дорогостоящего восстановления данных профессионального уровня.
Весь процесс создания загрузочного образа системы с помощью dd выглядит следующим образом:
- Загрузка с сервера CentOS с загрузочного дистрибутива Linux
- Найдите обозначение загрузочного диска для образа
- Определите место, где будет храниться образ восстановления
- Найдите размер блока, используемого на вашем диске
- Запустите операцию изображения dd
В этом уроке ради времени и простоты мы будем создавать ISO-образ основной загрузочной записи с виртуальной машины CentOS. Затем мы будем хранить это изображение вне сайта. В случае, если наша MBR повреждена и требует восстановления, тот же процесс может быть применен ко всему загрузочному диску или разделу. Тем не менее, время и дисковое пространство, необходимое для этого урока, немного запредельные.
Администраторам CentOS рекомендуется научиться восстанавливать полностью загрузочный диск / раздел в тестовой среде и выполнять восстановление «с нуля». Это избавит от большого давления, когда в конечном итоге нужно будет завершить практику в реальной ситуации, когда менеджеры и несколько десятков конечных пользователей будут считать время простоя. В таком случае 10 минут на то, чтобы разобраться, могут показаться вечностью и потеть.
Примечание о размере блока. Размер блока по умолчанию для dd составляет 512 байт. Это был стандартный размер блока жестких дисков меньшей плотности. Современные жесткие диски с более высокой плотностью увеличились до 4096 байт (4 КБ), что позволяет использовать диски размером от 1 ТБ и более. Таким образом, мы хотим проверить размер дискового блока перед использованием dd с более новыми жесткими дисками большей емкости.
В этом руководстве вместо работы на рабочем сервере с dd мы будем использовать установку CentOS, работающую в VMWare. Мы также настроим VMWare для загрузки загрузочного ISO-образа Linux вместо того, чтобы работать с загрузочной флешкой USB.
Сначала нам нужно скачать образ CentOS под названием: CentOS Gnome ISO . Это почти 3 ГБ, поэтому рекомендуется всегда сохранять копию для создания загрузочных USB-накопителей и загрузки на виртуальные серверные установки для устранения неполадок и получения изображений с нуля.
Другие загрузочные дистрибутивы Linux будут работать так же хорошо. Linux Mint можно использовать для загрузочных ISO-образов, поскольку он имеет отличную поддержку оборудования и отшлифованные инструменты для графического интерфейса пользователя для обслуживания.
Давайте настроим установку VMWare Workstation для загрузки с нашего загрузочного образа Linux. Шаги предназначены для VMWare в OS X. Однако они одинаковы для VMWare Workstation в Linux, Windows и даже Virtual Box.
Примечание. Использование решения для виртуального рабочего стола, такого как Virtual Box или VMWare Workstation, является отличным способом настройки лабораторных сценариев для изучения задач администрирования CentOS. Он обеспечивает возможность установки нескольких установок CentOS, практически без аппаратной конфигурации, позволяя человеку сосредоточиться на администрировании, и даже сохранить состояние сервера перед внесением изменений.


Теперь при загрузке наша виртуальная машина будет загружаться из загрузочного ISO-образа CentOS и разрешать доступ к файлам на сервере Virtual CentOS, который был предварительно настроен.
Давайте проверим наши диски, чтобы увидеть, куда мы хотим скопировать MBR (сжатый вывод выглядит следующим образом).
Мы нашли оба наших физических диска: sda и sdb . Каждый имеет размер блока 512 байт. Итак, теперь мы запустим команду dd, чтобы скопировать первые 512 байт для нашей MBR на SDA1.
При работе с данными с дисков мы всегда хотим включить: conv = sync, параметр noerror .
Это просто потому, что диски не являются потоками, такими как данные TCP. Они состоят из блоков, выровненных до определенного размера. Например, если у нас есть 512-байтовые блоки, для файла размером всего 300 байт все еще нужны полные 512 байт дискового пространства (возможно, 2 блока для информации inode, такой как разрешения и другая информация файловой системы).
Используйте gzip и tar для безопасного хранения
Использование Gnu Tar в CentOS Linux
В течение многих лет tar является стандартом для хранения архивных файлов в Unix и Linux. Следовательно, использование tar вместе с gzip или bzip считается наилучшей практикой для архивов в каждой системе.
| переключатель | действие |
|---|---|
| -с | Создает новый архив .tar |
| -С | Выдержки в другой каталог |
| -j | Использует сжатие bzip2 |
| -z | Использует сжатие GZIP |
| -v | Подробный прогресс архивирования шоу |
| -t | Содержит список архивов |
| -f | Имя файла архива |
| -Икс | Извлекает архив tar |
Ниже приведен основной синтаксис для создания архива tar .
Замечание о механизмах сжатия с помощью tar. Рекомендуется придерживаться одной из двух распространенных схем сжатия при использовании tar: gzip и bzip2. GZIP-файлы потребляют меньше ресурсов процессора, но обычно имеют больший размер. В то время как bzip2 сжимается дольше, они используют больше ресурсов процессора; но приведет к меньшему конечному размеру файла.
При использовании сжатия файлов мы всегда хотим использовать стандартные расширения файлов, чтобы все, включая нас самих, знали (в отличие от предположения методом проб и ошибок), какая схема сжатия необходима для извлечения архивов.
| bzip2 | .tbz |
| bzip2 | .tar.tbz |
| bzip2 | .tb2 |
| GZIP | .tar.gz |
| GZIP | .tgz |
При необходимости извлечения архивов из коробки Windows или для использования в Windows рекомендуется использовать .tar.tbz или .tar.gz, так как большинство трехсимвольных расширений будут путать Windows и только администраторов Windows (однако это иногда желаемый результат)
Примечание. Вместо того, чтобы добавлять все файлы непосредственно в архив, мы заархивировали всю папку RemoteStuff . Это самый простой способ. Просто потому, что при извлечении весь каталог RemoteStuff извлекается со всеми файлами в текущем рабочем каталоге как ./currentWorkingDirectory/RemoteStuff/
Теперь давайте распакуем архив в каталог / root / home.
Как видно выше, все файлы были просто извлечены в каталог, содержащийся в нашем текущем рабочем каталоге.
Используйте gzip для сжатия резервных копий файлов
Как отмечалось ранее, мы можем использовать bzip2 или gzip из tar с ключами командной строки -j или -z . Мы также можем использовать gzip для сжатия отдельных файлов. Однако использование одних только bzip или gzip не дает столько возможностей, сколько в сочетании с tar .
Некоторые общие параметры командной строки для gzip:
| переключатель | действие |
|---|---|
| -с | Сохраняет файлы после помещения в архив |
| -l | Получить статистику для сжатого архива |
| -р | Рекурсивно сжимает файлы в каталогах |
| -1 до 9 | Определяет уровень сжатия по шкале от 1 до 9 |
gzip более или менее работает на файловой основе, а не на архивной основе, как некоторые утилиты Windows O / S zip. Основной причиной этого является то, что tar уже предоставляет расширенные возможности архивирования. GZIP предназначен для обеспечения только механизма сжатия.
Следовательно, когда вы думаете о gzip , подумайте об одном файле. Когда вы думаете о нескольких файлах, подумайте об архивах tar . Давайте теперь рассмотрим это с нашим предыдущим архивом tar .
Примечание. Опытные специалисты по Linux часто будут ссылаться на архивный архив как на тарбол.
Давайте сделаем еще один архив tar из нашей резервной копии rsync .
В демонстрационных целях давайте распакуем только что созданный tar-архив и скажем gzip сохранить старый файл. По умолчанию без опции -c gzip заменит весь архив tar на файл .gz .
Попробуем проверить ключ -l с помощью gzip .
Чтобы продемонстрировать, чем gzip отличается от Windows Zip Utilities, давайте запустим gzip для папки с текстовыми файлами.
Теперь давайте используем опцию -r для рекурсивного сжатия всех текстовых файлов в каталоге.
Увидеть? Не то, что некоторые могли ожидать. Все исходные текстовые файлы были удалены, и каждый был сжат по отдельности. Из-за этого поведения лучше всего думать о gzip в одиночку, когда нужно работать в отдельных файлах.
Работая с тарболами , давайте распакуем наш rsynced тарбол в новый каталог.
Как показано выше, мы распаковали и распаковали наш tar-архив в каталог / tmp.
Шифровать архивы TarBall
Шифрование архивных архивов для хранения защищенных документов, к которым, возможно, потребуется доступ другим сотрудникам организации, в случае аварийного восстановления может оказаться сложной задачей. Есть в основном три способа сделать это: либо использовать GnuPG, либо использовать openssl, либо использовать утилиту третьей части.
GnuPG в первую очередь предназначен для асимметричного шифрования и имеет в виду связь идентичности, а не парольную фразу. Правда, его можно использовать с симметричным шифрованием, но это не главное преимущество GnuPG. Таким образом, я бы отказался от GnuPG за хранение архивов с физической защитой, когда доступ может понадобиться большему количеству людей, чем первоначальному человеку (например, корпоративному менеджеру, который хочет защититься от администратора, использующего все ключи от королевства в качестве рычага).
Openssl, как и GnuPG, может делать то, что мы хотим, и поставляется с CentOS. Но опять же, он не предназначен специально для того, чтобы делать то, что мы хотим, и шифрование подвергалось сомнению в сообществе безопасности.
Установите 7zip на Centos
Все просто, 7zip установлен и готов к использованию с 256-битным шифрованием AES для наших архивных архивов.
Где : добавить в архив и -p: зашифровать и запросить фразу-пароль
Теперь у нас есть архив .7z, который шифрует сжатый архив с 256-битным AES.
Примечание. 7zip использует 256-битное шифрование AES с хешем пароля и счетчика SHA-256, повторяемое до 512 Кбайт для получения ключа. Это должно быть достаточно безопасно, если используется сложный ключ.
Процесс шифрования и повторного сжатия архива может занять некоторое время с большими архивами.
Допустим, что у нас есть ОС, все данные которой хранятся в одном разделе. Эту ОС необходимо мигрировать на другой сервер.
Гайд предполагает, что / (корень) — ваш загрузочный, если вы используете разметку диска MBR .
Из доступных средств у нас — только LiveCD/ DVD / USB для резервного копирования и развертки системы. Системы резервного копирования отсутствуют.
Резервное копирование
Начнем мы с резервного копирования.
Шаг 0. Загружаемся с Live системы.
Шаг 1. Монтируем накопитель, на который будет производиться резервное копирование системы (директория монтирования ФС накопителя резервных копий в примере будет /media/backupdisk1, система смонтирована в /mnt).
Шаг 2. Создаем архив с резервной копией.
Команда архивации системы
tar cpJvf /media/backupdisk1/our_backup. xz --selinux --exclude /mnt/dev --exclude /mnt/proc --exclude /mnt/sys --exclude /mnt --exclude /media --exclude /mnt/lost+found --exclude /mnt/tmp /mnt/Описание опций tar:
- с — create — создать;
- p — сохраняем владельцев файлов и права к файлам;
- J — используем компрессию xz;
- v — verbose, чтобы видеть, что происходит во время архивации;
- f — указываем файл, куда мы хотим сохранить копию/архив;
- — -exclude — исключить из архивации директории и файлы. Из архива исключаются каталоги, структура которых создается при загрузке операционной системы, в связи с чем нет смысла добавлять их в архив.
- — -selinux — сохраняем контексты SElinux, примененные к файлам. Используйте только при наличии в системе SElinux и его поддержки tar (как правило, присутствует в актуальных системах)!
Шаг 3. Демонтируем раздел накопителя, на который архивировали систему.
Восстановление из резервной копии
Шаг 0. Загружаемся с Live системы.
Шаг 1. Неплохо бы для начала развернуть базовую систему на диске для восстанавливаемой ОС.
Или создаем разметку диска и разделы на нем.
Шаг 2. Монтируем накопитель с резервной копией (в нашем примере — /media/backupdisk1, а корень установленной ОС примонтирован в /mnt).
Шаг 3. Распаковываем копию.
Команда разархивации
tar -xvpfJ --selinux /media/backupdisk1/our-backup. xz -C /mnt/Описание опций tar:
- x — extract, вытащить данные из архива;
- v — verbose, чтобы видеть, что происходит во время разархивации;
- p — сохраняем владельцев файлов и права к файлам;
- f — указываем, из какого файла мы хотим восстановить копию/архив;
- J — указываем при распаковке, что у нас используется компрессия xz;
- -C — create. Восстановить структуру каталогов, воссоздав отсутствующие.
- — -selinux — сохраняем контексты SElinux, примененные к файлам. Использовать только при наличии в системе SElinux и его поддержки tar!
Шаг 4. Если мы выполняем разархивацию не в готовую систему, восстановим директории, которые мы исключили из архивации, а также восстановим правильные права доступа к ним

Примерно год назад у меня возникла «острая» необходимость перевести систему резервного копирования данных в корпоративной сети на бесплатные рельсы. До этого использовался платный продукт от Symantec, по нему, конечно, много нареканий, но он работал, хоть и не всегда справлялся. Как обычно, все надо было сделать «вчера», и я приступил к поиску вариантов.
Для начала начал искать решение для резервного копирования файлов, очевидным решением было простая настройка скриптов на Linux по cron, но это не очень удобное и надежное решение, если серверов более одного(а у меня их около 50-ти) и структура достаточно динамична. Тем более если инфраструктура смешанная, Linux + Windows. Хотелось что-нибудь простое в дальнейшем обслуживании и извлечении самих копий, например, переложить восстановление пользовательских файлов на группу поддержки. Порывшись пару часов в интернете, я наткнулся на интересный проект UrBackup, он удовлетворял всем моим условиям.
Как операционную систему я выбрал CentOS 6 в конфигурации minimal, взять можно тут. Подробно на установке и первичной настройке останавливаться не будут, т.к. манулов по этой процедуре уже достаточно на Хабре. Перейдем к установке виновника топика UrBackup.
Предыдущие версии UrBackup приходилось собирать из исходников, но слава разработчикам, для последних версий появились репозитории для большинства популярных систем. Хотя собрать из исходников проблем не составляло, репозиторий сильно упрощает жизнь, особенно при обновлениях.
Так же для серверов внутри сети отключаем selinux:
Отключаем selinux без перезагрузки:
Устанавливаем сервис в автозагрузку и запускаем:
Готово. Можно подключаться и настраивать.
Заходим по адресу. При желании выбираем язык и идем в настройки:
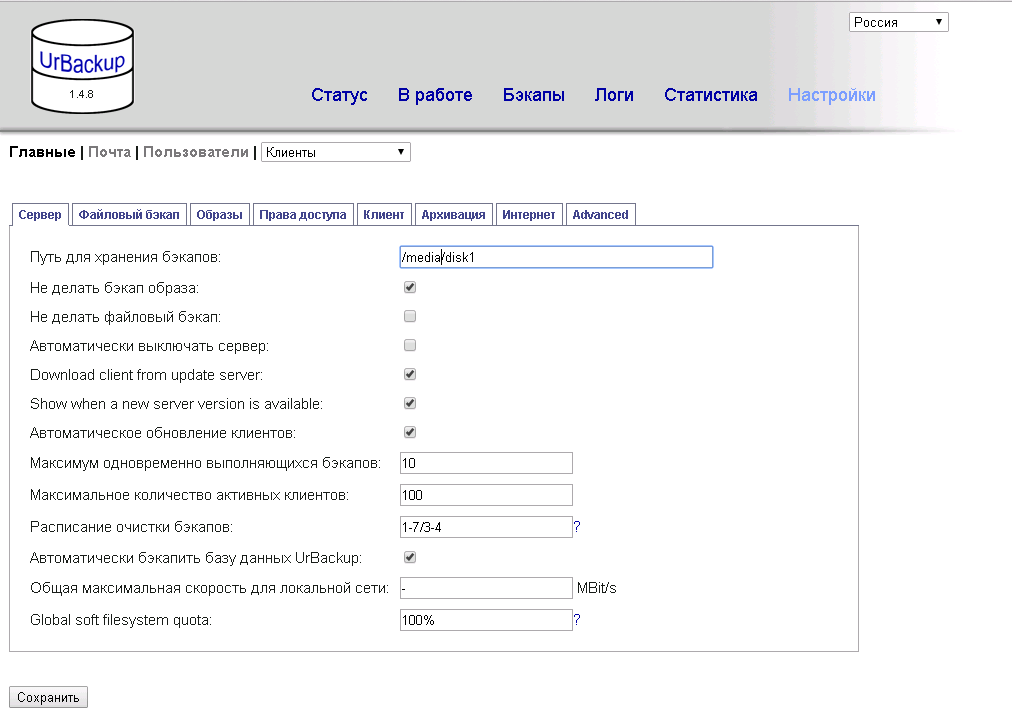
Тут для первичной настройки нам необходимо указать только путь для хранения бекапов. Не забываем нажать кнопку «сохранить» и мы можем переходить к настройке клиентов.
Для начала нам необходимо установить клиент на сервер, который мы хотим копировать. Клиент для Windows систем можно скачать с сайта разработчиков, но так как мы в данный момент рассматриваем linux-системы, рассмотрим установку на тот же CentOS 6:
Добавляем правила в iptables:
Не забываем отключить selinux, если, конечно, в нем нет необходимости. И можно добавлять клиента на сервер. Возвращаемся на сервер. Идем в раздел «статус»:

Вбиваем в поле «Имя/IP» IP-адрес сервера, с которого мы хотим бекапить данные, и нажимаем добавить. Ждем пару минут, пока клиент появится в списке.
Для клиента с GUI этого достаточно, настройки папок для копирования можно сделать прямо на клиенте, резервное копирование начнется по расписанию, но у нас минимальный Linux и мы ставили клиент без GUI, его, как впрочем и полноценного клиента, можно настраивать прямо с сервера.
Идем в настройки:

Выбираем наш сервер из списка и настраиваем «каталоги по умолчанию для бекапа».
Готово. Сервер настроен и работает. Во время работы мы видим нечто подобное:

Сервер работает на удивление быстро и очень компактно использует место на диске, используя подобие дедубликации на основе симлинков.
Это минимальная настройка сервера, при желании можно настроить авторизацию, архивацию, создание образов систем (Windows), резервное копирование через интернет и т.д. В дальнейших статьях планирую рассказать, как на этот же сервер настроить резервное копирование MSSQL и Exchange, если это, конечно, будет интересно читателям.
Читайте также: