
Ячейки памяти внутри процессора используемые для размещения команд программы и обрабатываемых данных
Основная функция любого процессора, ради которой он и создается, — это выполнение команд. Система команд , выполняемых процессором, представляет собой нечто подобное таблице истинности логических элементов или таблице режимов работы более сложных логических микросхем. То есть она определяет логику работы процессора и его реакцию на те или иные комбинации внешних событий.
Написание программ для микропроцессорной системы — важнейший и часто наиболее трудоемкий этап разработки такой системы. А для создания эффективных программ необходимо иметь хотя бы самое общее представление о системе команд используемого процессора. Самые компактные и быстрые программы и подпрограммы создаются на языке Ассемблер , использование которого без знания системы команд абсолютно невозможно, ведь язык Ассемблер представляет собой символьную запись цифровых кодов машинного языка , кодов команд процессора. Конечно, для разработки программного обеспечения существуют всевозможные программные средства . Пользоваться ими обычно можно и без знания системы команд процессора. Чаще всего применяются языки программирования высокого уровня, такие как Паскаль и Си . Однако знание системы команд и языка Ассемблер позволяет в несколько раз повысить эффективность некоторых наиболее важных частей программного обеспечения любой микропроцессорной системы — от микроконтроллера до персонального компьютера.
Именно поэтому в данной главе мы рассмотрим основные типы команд , имеющиеся у большинства процессоров, и особенности их применения.
Каждая команда , выбираемая (читаемая) из памяти процессором, определяет алгоритм поведения процессора на ближайшие несколько тактов. Код команды говорит о том, какую операцию предстоит выполнить процессору и с какими операндами (то есть кодами данных), где взять исходную информацию для выполнения команды и куда поместить результат (если необходимо). Код команды может занимать от одного до нескольких байт , причем процессор узнает о том, сколько байт команды ему надо читать, из первого прочитанного им байта или слова. В процессоре код команды расшифровывается и преобразуется в набор микроопераций , выполняемых отдельными узлами процессора. Но разработчику микропроцессорных систем это знание не слишком важно, ему важен только результат выполнения той или иной команды.
3.1. Адресация операндов
3.1.1. Методы адресации
Количество методов адресации в различных процессорах может быть от 4 до 16. Рассмотрим несколько типичных методов адресации операндов , используемых сейчас в большинстве микропроцессоров.
Непосредственная адресация (рис. 3.1) предполагает, что операнд (входной) находится в памяти непосредственно за кодом команды. Операнд обычно представляет собой константу, которую надо куда-то переслать, к чему-то прибавить и т.д. Например, команда может состоять в том, чтобы прибавить число 6 к содержимому какого-то внутреннего регистра процессора. Это число 6 будет располагаться в памяти, внутри программы в адресе, следующем за кодом данной команды сложения.
Прямая (она же абсолютная) адресация (рис. 3.2) предполагает, что операнд (входной или выходной) находится в памяти по адресу, код которого находится внутри программы сразу же за кодом команды. Например, команда может состоять в том, чтобы очистить (сделать нулевым) содержимое ячейки памяти с адресом 1000000. Код этого адреса 1000000 будет располагаться в памяти, внутри программы в следующем адресе за кодом данной команды очистки.
Регистровая адресация (рис. 3.3) предполагает, что операнд (входной или выходной) находится во внутреннем регистре процессора. Например, команда может состоять в том, чтобы переслать число из нулевого регистра в первый. Номера обоих регистров (0 и 1) будут определяться кодом команды пересылки .
Косвенно-регистровая (она же косвенная) адресация предполагает, что во внутреннем регистре процессора находится не сам операнд , а его адрес в памяти (рис. 3.4). Например, команда может состоять в том, чтобы очистить ячейку памяти с адресом, находящимся в нулевом регистре. Номер этого регистра (0) будет определяться кодом команды очистки.
Реже встречаются еще два метода адресации .
Автоинкрементная адресация очень близка к косвенной адресации, но отличается от нее тем, что после выполнения команды содержимое используемого регистра увеличивается на единицу или на два. Этот метод адресации очень удобен, например, при последовательной обработке кодов из массива данных, находящегося в памяти. После обработки какого-то кода адрес в регистре будет указывать уже на следующий код из массива. При использовании косвенной адресации в данном случае пришлось бы увеличивать содержимое этого регистра отдельной командой.
Автодекрементная адресация работает похоже на автоинкрементную, но только содержимое выбранного регистра уменьшается на единицу или на два перед выполнением команды. Эта адресация также удобна при обработке массивов данных. Совместное использование автоинкрементной и автодекрементной адресаций позволяет организовать память стекового типа (см. раздел 2.4.2).
Из других распространенных методов адресации можно упомянуть об индексных методах, которые предполагают для вычисления адреса операнда прибавление к содержимому регистра заданной константы (индекса). Код этой константы располагается в памяти непосредственно за кодом команды.
Отметим, что выбор того или иного метода адресации в значительной степени определяет время выполнения команды. Самая быстрая адресация — это регистровая, так как она не требует дополнительных циклов обмена по магистрали. Если же адресация требует обращения к памяти, то время выполнения команды будет увеличиваться за счет длительности необходимых циклов обращения к памяти. Понятно, что чем больше внутренних регистров у процессора, тем чаще и свободнее можно применять регистровую адресацию, и тем быстрее будет работать система в целом.
3.1.2. Сегментирование памяти
Говоря об адресации, нельзя обойти вопрос о сегментировании памяти, применяемой в некоторых процессорах, например в процессорах IBM PC-совместимых персональных компьютеров.
В процессоре Intel 8086 сегментирование памяти организовано следующим образом.
Вся память системы представляется не в виде непрерывного пространства, а в виде нескольких кусков — сегментов заданного размера (по 64 Кбайта), положение которых в пространстве памяти можно изменять программным путем.
Для хранения кодов адресов памяти используются не отдельные регистры, а пары регистров:
- сегментный регистр определяет адрес начала сегмента (то есть положение сегмента в памяти);
- регистр указателя (регистр смещения) определяет положение рабочего адреса внутри сегмента.
При этом физический 20-разрядный адрес памяти, выставляемый на внешнюю шину адреса , образуется так, как показано на рис. 3.5, то есть путем сложения смещения и адреса сегмента со сдвигом на 4 бита. Положение этого адреса в памяти показано на рис. 3.6.
Сегмент может начинаться только на 16-байтной границе памяти (так как адрес начала сегмента, по сути, имеет четыре младших нулевых разряда, как видно из рис. 3.5), то есть с адреса, кратного 16. Эти допустимые границы сегментов называются границами параграфов.
Отметим, что введение сегментирования , прежде всего, связано с тем, что внутренние регистры процессора 16-разрядные, а физический адрес памяти 20-разрядный (16-разрядный адрес позволяет использовать память только в 64 Кбайт, что явно недостаточно). В появившемся в то же время процессоре MC68000 фирмы Motorola внутренние регистры 32-разрядные, поэтому там проблемы сегментирования памяти не возникает.
Рис. 3.5. Формирование физического адреса памяти из адреса сегмента и смещения.
Рис. 3.6. Физический адрес в сегменте (все коды — шестнадцатеричные).
Применяются и более сложные методы сегментирования памяти. Например, в процессоре Intel 80286 в так называемом защищенном режиме адрес памяти вычисляется в соответствии с рис. 3.7.
В сегментном регистре в данном случае хранится не базовый (начальный) адрес сегментов, а коды селекторов, определяющие адреса в памяти, по которым хранятся дескрипторы (то есть описатели) сегментов. Область памяти с дескрипторами называется таблицей дескрипторов. Каждый дескриптор сегмента содержит базовый адрес сегмента, размер сегмента (от 1 до 64 Кбайт) и его атрибуты. Базовый адрес сегмента имеет разрядность 24 бит, что обеспечивает адресацию 16 Мбайт физической памяти.
Рис. 3.7. Адресация памяти в защищенном режиме процессора Intel 80286.
Таким образом, на сумматор , вычисляющий физический адрес памяти, подается не содержимое сегментного регистра, как в предыдущем случае, а базовый адрес сегмента из таблицы дескрипторов.
Еще более сложный метод адресации памяти с сегментированием использован в процессоре Intel 80386 и в более поздних моделях процессоров фирмы Intel. Этот метод иллюстрируется рис. 3.8.
Адрес памяти (физический адрес) вычисляется в три этапа. Сначала вычисляется так называемый эффективный адрес (32-разрядный) путем суммирования трех компонентов: базы, индекса и смещения (Base, Index, Displacement ), причем возможно умножение индекса на масштаб (Scale). Эти компоненты имеют следующий смысл:
Рис. 3.8. Формирование физического адреса памяти процессора 80386 в защищенном режиме.
Затем специальный блок сегментации вычисляет 32-разрядный линейный адрес, который представляет собой сумму базового адреса сегмента из сегментного регистра с эффективным адресом. Наконец, физический 32-битный адрес памяти образуется путем преобразования линейного адреса блоком страничной переадресации, который осуществляет перевод линейного адреса в физический страницами по 4 Кбайта.
В любом случае сегментирование позволяет выделить в памяти один или несколько сегментов для данных и один или несколько сегментов для программ. Переход от одного сегмента к другому сводится всего лишь к изменению содержимого сегментного регистра. Иногда это бывает очень удобно. Но для программиста работать с сегментированной памятью обычно сложнее, чем с непрерывной, несегментированной памятью, так как приходится следить за границами сегментов, за их описанием, переключением и т.д.
3.1.3. Адресация байтов и слов
Многие процессоры, имеющие разрядность 16 или 32, способны адресовать не только целое слово в памяти (16-разрядное или 32-разрядное), но и отдельные байты. Каждому байту в каждом слове при этом отводится свой адрес.
Так, в случае 16-разрядных процессоров все слова в памяти (16-разрядные) имеют четные адреса. А байты, входящие в эти слова, могут иметь как четные адреса, так и нечетные.
Например, пусть 16-разрядная ячейка памяти имеет адрес 23420 , и в ней хранится код 2А5Е (рис. 3.9).
При обращении к целому слову (с содержимым 2А5Е ) процессор выставляет адрес 23420 . При обращении к младшему байту этой ячейки (с содержимым 5Е ) процессор выставляет тот же самый адрес 23420 , но использует команду, адресующую байт, а не слово. При обращении к старшему байту этой же ячейки (с содержимым 2А ) процессор выставляет адрес 23421 и использует команду, адресующую байт. Следующая по порядку 16-разрядная ячейка памяти с содержимым 487F будет иметь адрес 23422 , то есть опять же четный. Ее байты будут иметь адреса 23422 и 23423 .
Для различия байтовых и словных циклов обмена на магистрали в шине управления предусматривается специальный сигнал байтового обмена. Для работы с байтами в систему команд процессора вводятся специальные команды или предусматриваются методы байтовой адресации.
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес --> Линейный (виртуальный)--> Физический

Все линейное адресное пространство разбито на сегменты. Адресное пространство каждого процесса имеет по крайней мере три сегмента:
Сегмент кода. (содержит команды из нашей программы, которые будут исполнятся.)
Сегмент данных. (Содержит данные, то бишь переменные)
Сегмент стека, про который я писал выше.
Линейный адрес вычисляется по формуле:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Базовый адрес сегмента кода берется из регистра CS. Значение смещения для сегмента кода берется из регистра EIP, в котором хранится адрес инструкции, после исполнения которой, значение EIP увеличивается на размер этой команды. Если команда занимает 4 байта, то значение EIP увеличивается на 4 байта и будет указывать уже на следующую инструкцию. Все это делается автоматически без участия программиста.
Сегментов кода может быть несколько в нашей памяти. В нашем случае он один.
Сегмент данных
Данные загружаются в регистры DS, ES, FS, GS
Это значит что сегментов данных может быть до 4х. На нашей картинке он один.
Смещение внутри сегмента данных задается как операнд команды. По дефолту используется сегмент на который указывает регистр DS. Для того чтобы войти в другой сегмент надо это непосредственно указать в команде префикса замены сегмента.
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес.
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке:
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
В зависимости от 55 G-бита(гранулярити), предел может измеряться в байтах при нулевом значении бита и тогда максимальный предел составит 1 мб, или в значении 1, предел измеряется страницами, каждая из которых равна 4кб. и максимальный размер такого сегмента будет 4Гб.
Для сегмента стека предел будет в интервале:
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.

Можно выделить три основных вида памяти, используемой в микроконтроллерах:
● память программ, которая представляет собой постоянную память, предназначенную для хранения программного кода и констант. Эта память не изменяет своего содержимого в процессе выполнения программы;
● память данных, предназначенная для хранения переменных (результатов) в ходе выполнения программы;
● регистровая память, состоящая из внутренних регистров микроконтроллера. Рассмотрим особенности каждого из перечисленных видов памяти.
Память программ.
Необходимость такой памяти вызвана тем, что микроконтроллер не содержит таких устройств памяти, как винчестер в компьютере, с которого загружается исполняемая программа. Поэтому код программы должен постоянно храниться в микроконтроллере.
Все типы памяти программ относятся к энергонезависимой памяти, или постоянной памяти (ПЗУ), содержимое которой сохраняется после выключения питания микроконтроллера.
В процессе выполнения программа считывается из этой памяти, а блок управления (дешифратор команд) обеспечивает ее декодирование и выполнение необходимых операций. Содержимое памяти программ не может меняться (перепрограммироваться) во время выполнения программы. Поэтому функциональное назначение микроконтроллера не может измениться, пока содержимое его памяти программ не будет стерто (если это возможно) и перепрограммировано (заполнено новыми командами).
Следует обратить внимание, что разрядность микроконтроллера (8, 16 или 32 бит) указывается в соответствии с разрядностью его шины данных.
Когда говорится, что устройство является 8–разрядным, это означает разрядность данных, которые способен обрабатывать микроконтроллер.
В Гарвардской архитектуре команды могут иметь большую разрядность, чем данные, чтобы дать возможность считывать за один такт целую команду. Например, микроконтроллеры PIC в зависимости от модели используют команды с разрядностью 12, 14 или 16 бит. В микроконтроллерах AVR команда всегда имеет разрядность 16 бит. Однако все эти микроконтроллеры имеют шину данных разрядностью 8 бит.
В устройствах с Принстонской архитектурой разрядность данных обычно определяет разрядность (число линий) используемой шины. В микроконтроллерах Motorola 68НС05 24–разрядная команда размешается в трех 8–разрядных ячейках памяти программ. Для полной выборки такой команды необходимо произвести три цикла считывания этой памяти.
Выделим и рассмотрим пять типов энергонезависимой резидентной памяти, или постоянных запоминающих устройств (ПЗУ), используемых для хранения программ.
Масочная память.
Масочные ПЗУ (Mask–ROMили просто ROM) изготавливаются на этапе производства микроконтроллеров для полностью отлаженной программы. На стеклянном фотошаблоне при использовании программы создается рисунок маски. Полученный фотошаблон с маской используется для формирования соединений между элементами, из которых состоит память программ.
Первые масочные ПЗУ появились в начале 1960–х годов и находят применение до настоящего времени благодаря таким достоинствам как низкая стоимость при массовом производстве изделий и высокая надежность хранения программ.
Недостатки масочных ПЗУ — любое изменение прикладной программы связано со значительными затратами средств и времени на создание нового комплекта фотошаблонов и их внедрение в производство.
Однократно программируемая память.
Эта память (One–Time Program mable ROM — OTPROM ) программируется пользователем и в исходном состоянии содержит ячейки с единичными битами. Программированию подлежат только те ячейки памяти, содержимое которых должно принять значение 0. Для этого на ячейку памяти подают последовательность импульсов повышенного напряжения.
Уровень напряжения, число импульсов и их временные параметры должны строго соответствовать техническим условиям. После записи нуля восстановить единичное значение невозможно. По этой причине память получила название однократно программируемых ПЗУ. Однако следует указать на возможность допрограммирования (не тронутых) ячеек с единичными битами.
Микроконтроллеры с однократно программируемым ПЗУ используются в изделиях, выпускаемых небольшими партиями.
Репрограммируемая память с ультрафиолетовым стиранием.
Ячейка памяти с ультрафиолетовым стиранием (Erasable Programmable ROM — EPROM) представляет собой ЛИПЗМОП (лавинно–инжекционный с плавающим затвором) транзистор. В исходном состоянии (до записи) при обращении к ячейке считывается логическая единица. Программирование памяти сводится к записи в соответствующие ячейки логических нулей. Память ЕР ROM допускают многократное программирование, технология которого подобна технологии однократно программируемых ПЗУ.
Перед каждым сеансом программирования выполняется операция стирания для восстановления исходного состояния ячеек памяти. Для этого в корпусе микроконтроллера предусмотрено специальное окно, которое облучается ультрафиолетовыми лучами. Число сеансов стирания/программирования ПЗУ составляет 25–100 раз при соблюдении технологии программирования (заданные значения питающих напряжений, число и длительность импульсов) и технологии стирания (волновой диапазон источника ультрафиолетового излучения).
Микроконтроллеры с памятью EPROM из–за высокой стоимости применяются в опытных образцах разрабатываемых приложений.
Для уменьшения цены микросхемы EPROM заключают в корпус без окошка (версия EPROM с однократным программированием). Благодаря снижению стоимости версии EPROM часто используются вместо масочно–программируемых ROM.
Репрограммируемая память с электрическим стиранием.
В качестве элемента памяти с электрическим стиранием (Electrically Erasable Pro grammable ROM — EEPROM или E2 PROM) используется транзистор со структурой МНОП (Металл, Нитрид кремния, Окисел кремния, Полупроводник), благодаря чему ПЗУ имеет сравнительно низкую стоимость (по отношению к EPROM) и допускает максимальное число циклов стирания/программирования 10 4 –10 6 . Кроме того, технология программирования памяти EEPROM позволяет реализовать побайтное стирание и побайтное программирование, не снимая контроллер с платы, что позволяет периодически обновлять его программное обеспечение.
Несмотря на указанные достоинства, этот тип памяти не получил широкого распространения для хранения программ по двум причинам:
● ПЗУ типа EEPROM имеют ограниченную емкость;
● появились ПЗУ типа FLASH , которые имеют близкие пользовательские характеристики, но более низкую стоимость.
Память типа FLASH.
Электрически программируемая и электрически стираемая память типа FLASH (FLASH ROM) создавалась как альтернатива между дешевыми однократно программируемыми ПЗУ большой емкости и дорогими EEPROM ПЗУ малой емкости. Память FLASH (как и EEPROM) сохранила возможность многократного стирания и программирования.
Из схемы ПЗУ изъят транзистор адресации каждой ячейки, что, с одной стороны, лишило возможности программировать каждый бит памяти отдельно, с другой стороны, позволило увеличить объем памяти. Поэтому память типа FLASH стирается и программируется страницами или блоками.
Таким образом, функционально FLASH –память мало отличается от EEPROM. Основное отличие состоит в способе стирания записанной информации: если в EEPROM–памяти стирание производится отдельно для каждой ячейки, то во FLASH –памяти — целыми блоками. В микроконтроллерах с памятью EEPROM приходится изменять отдельные участки программы без необходимости перепрограммирования всего устройство.
В настоящее время МК с FLASH начинают вытеснять МК с однократно программируемым (и даже масочным) ПЗУ.
Программирование ПЗУ.
Отметим, что Mask ROM –память программируется только в заводских условиях при изготовлении МК. Память типа OTPROM и EPROM предоставляет разработчику возможности программирования с использованием программатора и источника повышенного напряжения, которые подключаются к соответствующим выводам МК.
Память EEPROM и FLASH относится к многократно программируемой, или репрограммируемой, памяти. Необходимое для стирания/программирования повышенное напряжение питания создается в модулях EEPROM и FLASH –памяти современных контроллеров с помощью встроенных схем усиления напряжения, называемых генераторами накачки. Благодаря реализации программного управления включением и отключением генератора накачки появилась принципиальная возможность осуществить программирование или стирание ячеек памяти FLASH и EEPROM в составе разрабатываемой системы. Такая технология программирования получила название программирования в системе (In System Programming — ISP).
Она не требует специального оборудования (программаторов), благодаря чему сокращаются расходы на программирование. Микроконтроллеры с ISP–памятью могут быть запрограммированы после их установки на плату конечного изделия.
Рассмотрим, как реализуется (и используется) возможность программирования EEPROM–памяти под управлением прикладной программы. Если программу с алгоритмом программирования хранить в отдельном модуле памяти с номинальным питающим напряжением, а EEPROM–память снабдить генераторами накачки, то можно произвести ISP–программирование EEPROM –памяти. Данное обстоятельство делает EEPROM –память идеальным энергонезависимым запоминающим устройством для хранения изменяемых в процессе эксплуатации изделия настроек пользователя. В качестве примера можно привести современный телевизор, настройки каналов которого сохраняются при отключении питания.
Поэтому одной из тенденций совершенствования резидентной памяти 8–разрядных МК стала интеграция на кристалл МК двух модулей энергонезависимой памяти: FLASH (или OTP ) — для хранения программ и EEPROM — для хранения перепрограммируемых констант.
Рассмотрим технологию (ре)программирования FLASH –памяти с встроенным генератором накачки под управлением прикладной программы. Прежде всего, отметим два обстоятельства:
● если для хранения перепрограммируемых констант в МК встроена память EEPROM, то попрограммирование нескольких бит FLASH –памяти при эксплуатации готового изделия не имеет смысла. При необходимости лучше сразу использовать режим репрограммирования;
● не следует программу программирования FLASH –памяти хранить в самой FLASH –памяти, так как переход в режим программирования приведет к невозможности дальнейшего ее считывания. Программа программирования должна располагаться в другом модуле памяти.
Для реализации технологии программирования в системе выбирается один из оследовательных портов МК, обслуживание которого осуществляет специальная программа монитора связи, расположенная в резидентном масочном ПЗУ МК. Через последовательный порт персональный компьютер загружает в ОЗУ МК программу программирования и прикладную программу, которая затем заносится в память FLASH. Так как резидентное ОЗУ МК имеет незначительный объем, то прикладная программа загружается отдельными блоками (порциями). Если в МК установлен модуль масочной памяти с программой программирования, в ОЗУ загружается только прикладная программа.
Микроконтроллеры, реализующие технологию программирования в системе, часто имеют в своем составе четыре типа памяти:
FLASH –память программ, Mask ROM –память монитора связи, EEPROM –память для хранения изменяемых констант и ОЗУ промежуточных данных.
Технология программирования в системе в настоящее время все шире используется для занесения прикладных программ в микроконтроллеры, расположенные на плате конечного изделия. Ее достоинство — отсутствие программатора и высокая надежность программирования, обусловленная стабильностью заданных внутренних режимов МК.
В качестве примера приведем показатели резидентной FLASH –памяти МК семейства НС08 фирмы Motorola:
● гарантированное число циклов стирания/программирования — 10 5 ;
● гарантированное время хранения записанной информации — 10 лет, что практически составляет жизненный цикл изделия; модули FLASH –памяти работают и программируются при напряжении питания МК от 1,8 до 2,7 В;
● эквивалентное время программирования 1 байта памяти — 60 мкс.
Память данных.
В качестве резидентной памяти данных используется статическое оперативное запоминающее устройство (ОЗУ), позволяющие уменьшать частоту тактирования до сколь угодно малых значений. Содержимое ячеек ОЗУ (в отличие от динамической памяти) сохраняется вплоть до нулевой частоты. Еще одной особенностью статического ОЗУ является возможность уменьшения напряжения питания до некоторого минимально допустимого уровня, при котором программа управления микроконтроллером не выполняться, но содержимое в ОЗУ сохраняется.
Уровень напряжения хранения имеет значение порядка одного вольта, что позволяет для сохранения данных при необходимости перевести МК на питание от автономного источника (батарейки или аккумулятора). Некоторые МК (например, DS5000 фирмы Dallas Semiconductor) имеют в корпусе автономный источник питания, гарантирующий сохранение данных в ОЗУ на протяжении 10 лет.
Характерной особенностью микроконтроллеров является сравнительной небольшой объем (сотни байт) оперативной памяти (ОЗУ), используемой для хранения переменных. Это можно объяснить несколькими факторами:
● стремлением к упрощению аппаратных средств МК;
● использованием при написании программ некоторых правил, направленных на сокращение объема памяти ОЗУ (например, константы не хранятся как переменные);
● распределением ресурсов памяти таким образом, чтобы вместо размещения данных в ОЗУ максимально использовать аппаратные средства (таймеры, индексные регистры и др.);
● ориентацией прикладных программы на работу без использования больших массивов данных.
Особенности стека.
В микроконтроллерах для организации вызова подпрограмм и обработки прерываний выделяется часть памяти ОЗУ, именуемая стеком. При этих операциях содержимое программного счетчика и основных регистров (аккумулятора, регистра состояния, индексных и других регистров) сохраняется, а при возврате к основной программе восстанавливается. Напомним, что стек работает по принципу: последний пришел — первый ушел (Last In , First Out—LIFO).
В Принстонской архитектуре ОЗУ используется для реализации многих аппаратных функций, включая функции стека. В адресном пространстве памяти выделены отдельные области для команд, регистров общего назначения, регистров специальных функций и др. Это снижает производительность контроллера, так как обращения к различным областям памяти не могут выполняться одновременно.
Микропроцессоры с Гарвардской архитектурой могут параллельно (одновременно) адресовать память программ, память данных (включающую пространство ввода–вывода) и стек.
Например, при активизации команды вызова подпрограммы CALL выполняется несколько действий одновременно.
В Принстонской архитектуре при выполнении команды CALL следующая команда выбирается только после того, как в стек будет помещено содержимое программного счетчика.
Из–за небольшой емкости ОЗУ в микроконтроллерах обеих архитектур могут возникнуть проблемы при выполнении программы:
● если выделен отдельный стек, то после его заполнения происходит циклическое изменение содержимого указателя стека, в результате чего указатель стека начинает ссылаться на ранее заполненную ячейку стека. Поэтому после слишком большого количества команд CALL в стеке окажется неправильный адрес возврата, который был записан вместо правильного адреса;
● если микропроцессор использует общую область памяти для размещения данных и стека, то при переполнении стека произойдет затирание данных. Рассмотрим особенности сохранения в стеке содержимого регистров, обусловленные отсутствием команд загрузки в стек (PUSH) и извлечения из стека (POP). В таких микроконтроллерах вместо команды PUSH и POP используются две команды и индексный регистр, который явно указывает на область стека. Последовательность команд должна быть такой, чтобы прерывание между первой и второй командой не привело к потере данных. Ниже приведена имитация команд PUSH и POP с учетом указанного требования.
PUSH ; Загрузить данные в стек decrement index; Перейти к следующей ячейке стека move [ index], асе ; Сохранить содержимое аккумулятора в стеке POP ; Извлечь данные из стека move асе, [index]; Поместить значение стека в аккумулятор increment index ; Перейти к предыдущей ячейке стека
Если после первой команды программа будет прервана, то после выполнения обработки прерывания содержимое стека не будет потеряно.
Регистровая память.
Микроконтроллеры (как и компьютерные системы) имеют множество регистров, которые используются для управления различными внутренними узлами и внешними устройствами. К ним относятся:
● регистры процессорного ядра (аккумулятор, регистры состояния, индексные регистры);
● регистры управления (регистры управления прерываниями, регистры управления таймером);
● регистры ввода/вывода данных (регистры данных и регистры управления параллельным, последовательным или аналоговым вводом/выводом).
По способу размещения регистров в адресном пространстве можно выделить:
● микроконтроллеры, в которых все регистры и память данных располагаются в одном адресном пространстве, т. е. регистры совмещены с памятью данных. В этом случае устройства ввода–вывода отображаются на память;
● микроконтроллеры, в которых устройства ввода/вывода отделены от общего адресного пространства памяти. Основное достоинство способа размещения регистров ввода–вывода в отдельном пространстве адресов — упрощается схема подключения памяти программ и данных к общей шине. Отдельное пространство ввода–вывода дает дополнительное преимущество процессорам с Гарвардской архитектурой, обеспечивая возможность считывать команду во время обращения к регистру ввода–вывода.
Способы обращения к регистрам оказывают существенное влияние на их производительность. В процессорах с RISC–архитектурой все регистры (часто и аккумулятор) располагаются по явно задаваемым адресам, что обеспечивает более высокую гибкость при организации работы процессора.
О внешней памяти.
В тех случаях, когда для разрабатываемых приложений не хватает резидентной памяти программ и памяти данных, к микроконтроллеру подключается дополнительная внешняя память. Известны два основных способа:
● подключение внешней памяти с использованием шинного интерфейса (как в микропроцессорных системах). Для такого подключения многие микроконтроллеры имеют специальные аппаратные средства;
● подключение памяти к устройствам ввода–вывода, При этом обращение к памяти осуществляется через эти устройства программными средствами. Такой способ позволяет использовать простые устройства ввода/вывода без реализации сложных шинных интерфейсов. Выбор способа зависит от конкретного приложения.

Именно от типа процессора и его характеристик в первую очередь зависит производительность компьютерной системы в целом .
Центральный процессор — это устройство компьютера, предназначенное для выполнения арифметических и логических операций над данными, а также координации работы всех устройств компьютера.
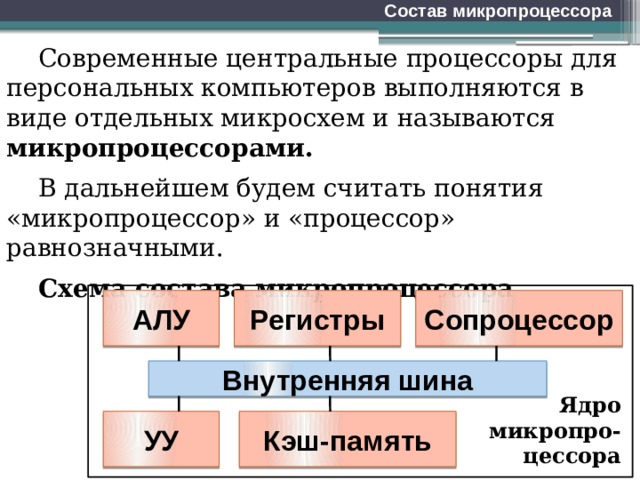
Состав микропроцессора
Современные центральные процессоры для персональных компьютеров выполняются в виде отдельных микросхем и называются микропроцессорами.
В дальнейшем будем считать понятия «микропроцессор» и «процессор» равнозначными.
Схема состава микропроцессора
Сопроцессор
Внутренняя шина
Ядро микропро-цессора

Состав микропроцессора
Основным элементом микропроцессора является ЯДРО, от которого зависит большинство характеристик самого процессора.
Современные процессоры могут иметь более одного ядра , т. е. могут быть многоядерными .
Многоядерные процессоры способны выполнять одновременно несколько потоков команд
Основная причина перехода к многоядерным процессорам была вызвана тем, что повышение производительности микропроцессоров путем дальнейшего наращивания тактовой частоты достигло физического предела в связи с очень высоким уровнем тепловыделения и энергопотребления.

Состав микропроцессора
Ядро процессора помещается в корпус (пластмассовый или керамический) и соединяется проводками с металлическими ножками (выводами), с помощью которых процессор присоединяется к системной плате компьютера.
Количество выводов и их расположение определяют тип процессорного интерфейса (разъема, Socket).
Каждая системная плата ориентирована на один определенный тип разъема .

Состав микропроцессора
1. Арифметико-логическое устройство (АЛУ) выполняет все математике и логические операции.
2. Управляющее устройство (УУ) обеспечивает выполнение процессором последовательности команд программы.
3. Набор регистров — ячейки памяти внутри процессора, используемые для размещения команд программы и обрабатываемых данных.

Состав микропроцессора
4. Кэш-память (кэш) — сверхбыстрая память, хранящая содержимое наиболее часто используемых ячеек оперативной памяти, а также части программы, к которым процессор обратится с наибольшей долей вероятности.
5. Сопроцессор — элемент процессора, выполняющий действия над числами с плавающей запятой.

Характеристики микропроцессора
Тактовая частота . Для каждой выполняемой процессором команды требуется строго определенное количество единиц времени (тактов). Тактовые импульсы формируются генератором тактовой частоты, установленным на системной плате.
Чем чаще они генерируются , тем больше команд процессор выполняет за единицу времени , т.е. тем выше его быстродействие .
Тактовая частота обычно выражается в мегагерцах - 1 МГц равен 1 миллиону тактов в секунду.
Первые модели процессоров Intel (i8008x) работали с тактовыми частотами, меньшими 5 МГц.

Характеристики микропроцессора
Различают внутреннюю и внешнюю тактовую частоту.
Внешняя тактовая частота — это частота, с которой процессор обменивается данными с оперативной памятью компьютера.
Как уже было сказано выше, она формируется генератором тактовых импульсов (кварцевым резонатором).
Внутренняя тактовая частота — это частота, с которой происходит работа внутри процессора .
Именно это значение указывается в прайс-листах фирм, продающих процессоры .

Характеристики микропроцессора
Первые процессоры имели одинаковую внутреннюю и внешнюю частоту , но, начиная с процессора i80486 , для определения внутренней частоты стал применяться коэффициент умножения .
Этот коэффициент определяется подачей напряжения на определенные контакты центрального процессора. Таким образом, для современных процессоров справедлива формула:
Внутренняя тактовая частота (ТЧ) =
= внешняя ТЧ × коэффициент умножения
Характеристики микропроцессора
Разрядность процессора определяет количество битов данных, которые он может принять и обработать одновременно .
Объем кэш-памяти . Как уже было сказано, при поиске нужной информации процессор в первую очередь обращается к кэш-памяти . Поэтому чем выше ее объем, тем больше вероятность, что необходимые данные будут найдены именно там.

Характеристики микропроцессора
Технологические нормы . Технологические нормы определяют расстояние между соседними транзисторами . Чем меньше расстояние , тем короче каналы транзисторов и тем больше их быстродействие .
Кроме того, уменьшение расстояния понижает уровень мощности тепловыделения .
В настоящее время все процессоры производятся с технологическими нормами 0,09 микрона, 0,065 микрона и 0,045 микрона (1 микрон = 10 -6 метров). Иногда технологические нормы указывают в нанометрах (1 нм = 10 -9 м).

Характеристики микропроцессора
Количество ядер . Большинство современных процессоров выпускаются с несколькими ядрами (обычно их два или четыре).
Благодаря наличию нескольких ядер процессор может одновременно обрабатывать несколько потоков программных команд , т.е. решать параллельно несколько задач в режиме реального времени .
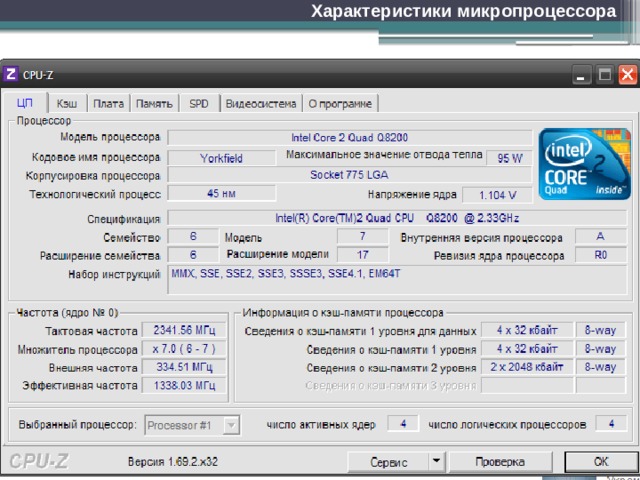
Характеристики микропроцессора
Для определения основных характеристик процессора можно воспользоваться специальными сервисными программами. Примером такой программы является CPU-Z (рис.).
Читайте также: