
Укажите в правильной последовательности действия процессора по выполнению программы
Функционирование процессора в основном состоит из повторяющихся рабочих циклов, каждый из которых соответствует выполнению одной команды программы. Завершив рабочий цикл для текущей команды, процессор переходит к выполнению рабочего цикла для следующей команды программы.
На рис. 9.34 представлена схема рабочего цикла процессора. Эта схема имеет достаточно общий характер.
Рис. 9.34. Рабочий цикл процессора
На схеме показаны варианты рабочего цикла для четырех групп команд: 1) основных (осуществляющих арифметические, логические и пересылочные операции), 2) передачи управления, 3) ввода-вывода и 4) системных (устанавливающих состояние процессора, маску прерывания, слово состояния программы и др.).
Рабочий цикл начинается с распознавания состояния процессора. Устанавливается, какое из альтернативных состояний — Счет или Ожидание — имеет место. Далее проверяется наличие незамаскированных прерываний.
В состоянии Ожидание никакие программы не выполняются. Процессор ждет прихода запроса прерывания, после чего управление переходит к соответствующей прерывающей программе, переводящей процессор в состояние Счет.
В состоянии Счет при наличии незамаскированных прерываний происходят выход из нормального рабочего цикла н переход к процедуре обработки запросов прерывания.
При отсутствии в состоянии Счет запросов прерывания последовательно выполняются этапы рабочего цикла: выборка очередной команды и определение по коду операции команды ее группы, подготовка операндов (формирование исполнительных адресов и выборка операндов из памяти), обработка операндов в АЛУ и запоминание результата.
На этапе выборки очередной команды образуется согласно естественному порядку адрес следующей за ней команды (продвинутый адрес), при этом содержимое счетчика команд (соответствующего поля ССП) увеличивается на число, равное числу байт в очередной команде. В некоторых ЭВМ формирование адреса следующей команды составляет отдельный этап, завершающий рабочий цикл.
В процессе выполнения заданной командой операции формируется признак результата операции, используемый командами условного перехода при организации ветвлений в программах.
Указанная выше последовательность этапов составляет основной вариант рабочего цикла, реализуемый при выполнении основных команд.
При выполнении команд передачи управления проверяется заданное командой (например, ее полем маски) условие. Если условие не выполняется, то следующую команду указывает продвинутый адрес, ранее установленный в СчК (регистре ССП). Если условие выполняется или имеется один из вариантов команды безусловного перехода, то адрес, задаваемый командой передачи управления, передается в СчК.
Команды ввода-вывода инициируют в канале операцию обмена информацией между ядром ЭВМ (основной памятью) и периферийным устройством. Сама эта операция выполняется каналом под управлением его собственной. программы. Поэтому на долю процессора остается только процедура опроса состояний канала и периферийного устройства — свободны ли они для операции ввода-вывода. Если свободны, процессор выдает в канал информацию, необходимую для начала операции ввода-вывода. В противном случае процессор переключается в состоянии Ожидание и ждет сигнала прерывания от этого канала.
Системные команды осуществляют переключение состояния процессора (программы) путем загрузки нового ССП или его части. В частности, эти команды изменяют маски прерывания, устанавливают ключи памяти и ключи защиты в ССП, реализуют операции прямого управления.
9.20. Принцип совмещения операций академика С. А. Лебедева. Конвейер операций
Вернемся к схеме рабочего цикла (рис. 9.34) и рассмотрим совокупность этапов цикла для основных команд (основной вариант цикла). Если эти этапы выполняются последовательно во времени, то, суммируя обозначенные на рисунке продолжительности отдельных этапов, получаем время цикла
и производительность процессора, операций (команд)/с,
Во многих случаях последовательная процедура выполнения этапов цикла не обеспечивает требуемую производительность процессора.
Академик С. А. Лебедев в 1956 г. предложил повышать производительность, используя принцип совмещения во времени отдельных операций (этапов) рабочего цикла, и реализовал этот принцип в ЭВМ М-20 в форме параллельного выполнения во времени операции в АЛУ и выборки из памяти следующей команды.
Пусть рабочий цикл процессора состоит из k этапов, причем 1-й этап имеет продолжительность ti, тогда при последовательном выполнении этапов продолжительность процедуры
и общая производительность процессора, операций/с,
Скорость работы машины может быть увеличена, если для выполнения каждого этапа иметь отдельный аппаратурный блок и соединить эти блоки в обрабатывающую линию — конвейер операций (в данном случае конвейер команд) так, чтобы результат выполнения в данном блоке некоторого этапа передавался для реализации очередного этапа на следующий блок, и т. д. (рис. 9.35).
Синхронный конвейер операций. Если конвейер работает в принудительном темпе и для выполнения любого этапа выделено одно и то же время tT, (такт конвейера), то такой конвейер называется синхронным.
Разбиение процедуры на этапы и выбор длительности такта производятся согласно условиям
причем в силу цикличности рабочего процесса в последнем неравенстве принимаем tk+ 1 = t1.
Если для каких-либо смежных этапов второе условие не выполняется, то их следует объединить в один этап либо наиболее длинный этап разбить на несколько этапов. В последнем случае заново выбирается tT и вновь проверяется условие (**).
На рис. 9.36 показана временная диаграмма выполнения команд на 5-позиционном синхронном конвейере. Одинаковыми символами помечены разные этапы рабочего цикла одной и той же команды.
После того как все позиции конвейера окажутся заполненными, параллельно во времени обрабатывается столько команд, сколько в конвейере обрабатывающих блоков (позиций).
Конвейер характеризуется коэффициентом совмещения операций, равным числу одновременно выполняемых этапов обработки информации.
Номинальная производительность синхронного конвейера при его полной загрузке
Найдем соотношение производительностей процессора при конвейерной обработке и при последовательном выполнении этапов рабочего цикла.
а из (*) и (***) получаем (*****)
В действительности рост реальной производительности процессора окажется ниже из-за простоев (задержек) конвейера. В процедурах выполнения некоторых команд (например, команд пересылки данных) отдельные этапы общего рабочего цикла отсутствуют, и, следовательно, простаивают отдельные блоки конвейера. Для команды условного перехода по результату предыдущей операции выборка следующей команды должна быть задержана (конвейер простаивает несколько тактов), пока не будет сформирован признак результата (формируется на более позднем этапе) предыдущей операции.
Если pm — вероятность выборки команды, вызывающей задержку конвейера на m тактов (m = 1, 2, . k), то действительная производительность конвейера
| Рис. 9.37. Структура управляющего устройства процессора: БВК. — блок выборки команд; БМП — блок местной памяти; БВД — блок выборки данных; БЦУ — блок центрального управления; БСА — блок , сумматора адреса; БАР — блок адреса результата: АЛБ — арифметико-логический блок; ПУ — пульт управления; УП — управляющие сигналы |
Асинхронный конвейер команд. При большой зависимости продолжительности выполнения процедур отдельных этапов от типа команды и вида операндов целесообразно применение асинхронного конвейера, в котором отсутствует единый такт работы его блоков, а информация с одного блока конвейера передается на следующий, когда данный блок закончит свою процедуру, а следующий полностью освободится от обработки предыдущей команды.
Управление передачей информации между соседними блоками в асинхронном конвейере осуществляется с помощью двух триггеров — готовности блока (сигнализирует о завершении операции в блоке) и освобождения последующего блока.
В качестве примера применения асинхронного конвейера команд может служить процессор ЭВМ ЕС-1050, в котором реализован конвейер, выполняющий одновременно три команды. Рабочий цикл выполнения команды разбит на три этапа: I — выборка очередной команды, II — формирование исполнительных адресов и выборка операндов, III — операция в АЛУ, формирование признака результата и запись результата в память.
Для каждого из указанных этапов выполнения команды имеется соответствующая аппаратура. Например, кроме сумматора АЛУ есть отдельный сумматор для формирования исполнительного адреса на этапе II. На рис. 9.37 представлена структура управляющего устройства с «жесткой» логикой процессора ЭВМ ЕС-1050, на которой показаны блоки, управляющие процедурами отдельных этапов выполнения команды.
На рис. 9.38 показана временная диаграмма совмещения выполнения трех команд в ЭВМ ЕС-1050 Временная диаграмма построена для случая, когда выбираемый за одно обращение к памяти «участок программы» содержит четыре команды формата «регистр-регистр».
Этап I содержит две процедуры, выборку из ОП участка программы (8 байт) и распаковку участка — выделение из него очередной команды и размещение ее в регистре команды.
Этап II в общем случае включает в себя формирование исполнительных адресов (при выполнении команд формата “регистр-регистр” отсутствует) и выборку операндов.
Этап III состоит также из двух процедур: выполнения операций в АЛУ и записи результата в память.
Из диаграммы видно, что, начиная с момента времени t4выполняются одновременно три этапа цикла соответственно для трех команд. В приведенном примере с момента t7 из-за большой длительности в команде N+1 операции в АЛУ приостанавливается работа блоков аппаратуры, соответствующих этапам I и II.
Арифметический конвейер. Выше был рассмотрен конвейер команд. Однако в целях повышения производительности машины принцип конвейерной обработки широко используется и в самих выполняющих содержательную обработку информации устройствах (АЛУ), которые строятся в виде арифметического конвейера, причем таких арифметических конвейерных линий может быть в процессоре несколько, в том числе и специализированных для определенных операций с данными Подобные операционные (арифметические) устройства часто называют магистральными.
Пусть операционное устройство должно вычислять некоторую функцию Ф от входных данных (выполнять некоторую операцию над входными данными). Можно функцию Ф представить в виде последовательности более простых подфункций
причем такой, что результаты преобразования, выполняемые подфункцией ji, используются в качестве входных данных при вычислении подфункции ji+1, и если при этом для каждой подфункции иметь реализующую ее схемный блок, то получим арифметический конвейер, который может быть выполнен как синхронный или как асинхронный.
Приведенные выше элементы теории синхронного конвейера команд остаются в силе и для синхронного арифметического конвейера. Если tT — такт конвейера, то после полной загрузки он станет выдавать значения функции Ф через интервалы времени tT. Увеличение производительности процессора за счет использования арифметического конвейера можно оценить по (******).
Если арифметический конвейер используется для выполнения разных операций, то осложняется определение состава рабочих позиций (блоков) конвейера и может потребоваться настройка (диспетчеризация) с соответствующей коммутацией блоков конвейера на операцию, задаваемую текущей командой.
Рассмотрим в качестве примера использование арифметического конвейера для сложения двух векторовX+Y=Z, компонентами» которых являются числа, представленные в форме с плавающей точкой и в нормализованном виде.
Выделим в операции сложения чисел с плавающей точкой четыре этапа: 1) сравнение и определение разности порядков, 2) выравнивание порядков - сдвиг мантиссы числа с меньшим порядком на число разрядов, равное разности порядков; 3) сложение мантисс; 4) нормализация результата.
В арифметическом конвейере эти этапы выполняются отдельными блоками, образующими конвейер, по которому перемещаются операнды или промежуточные результаты операции По мере их перемещения в конвейер вводятся новые компоненты векторов.
Пусть времена, необходимые для выполнения этапов сложения чисел с плавающей точкой, есть t1, t2, t3, t4.
Рис.9.39 Пример настройки арифметического конвейера на выполнение различных операций
Следовательно, если не организовать конвейер и выполнять все этапы операции последовательно, то для получения компонента zi = xi + yi потребуется время T = t1 + t2 + t3 + t4.
В синхронном конвейере, как указывалось выше, продолжительность каждого этапа устанавливается по самому длинному из них, пусть в данном случае это t3. Тогда, если конвейер заполнен, результаты сложения элементов векторов будут выдаваться через каждые промежутки времени t3, т. е. значительно быстрее, чем в случае отсутствия конвейерной обработки.
На рис. 9.39 в качестве примера представлена структура конвейерного (магистрального) АЛУ, соответствующего АЛУ известной в свое время ЭВМ ASC фирмы Texas Instruments, и показаны варианты коммутации блоков конвейера для выполнения разных операций, в данном случае сложения чисел с плавающей точкой и умножения чисел с фиксированной точкой.
Особенно эффективно использование операционных (арифметических) конвейеров в специализированных вычислительных устройствах с ограниченным набором алгоритмов обработки входных потоков данных, так как в этом случае возможно разбиение АЛУ на большое число простейших быстродействующих конвейерных блоков при небольших схемных и временных потерях на их коммутацию.
В ряде микропроцессоров одновременно присутствуют конвейер команд и арифметический конвейер, при этом часто в процессоре (микропроцессоре) выделяют I-часть — аппаратуру, относящуюся к обработке собственно команд и E-часть — аппаратуру, связанную с операциями над данными 1 .
I — от Instruction (инструкция, команда) и Е — от Execution (выполнение).
Контрольные вопросы
Что относится к элементам архитектуры ЭВМ.
Что определяет остроту проблемы при выборе структуры и формата команд современных ЭВМ. Каковы пути решения этой проблемы.
Что такое самоопределяемые данные? Почему при использовании тегов сокращается количество различных команд в системе команд машины.
Почему в малоразрядных ЭВМ и микропроцессорах широко используется косвенная адресация? Приведите пример совместного использования регистровой и косвенной адресации. |
Поясните, почему стековая память позволяет использовать безадресные команды? 1
Каковы назначение и особенности реализации команды безусловного перехода с возвратом?
Как с помощью индексации организуется обработка упорядоченных массивов данных?
Каковы назначение и процедуры автоинкрементной и автодекрементной адресаций?
Что общего между вектором состояния программы (процессора) и вектором прерывания?
Каковы назначение и процедура прерывания программ ЭВМ?
Что такое векторное прерывание? Опишите процедуру векторного прерывания с использованием стековой памяти.
В чем различие синхронного и асинхронного конвейеров?
Каким образом особенности RISC-архитектуры способствуют повышению ее быстродействия? Какова при этом роль «перекрывающихся регистровых окон»?
Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций.



Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰).

В состав вычислительной машины обязательно должны входить:
- блок управления
- блок памяти
- блоки ввода/вывода информации
- блок обработки данных
- блок защиты от перепадов электричества
- блок защиты от взлома
Вопрос 2
Как называется программа, которая переводит в машинный код сразу всю программу и строит исполняемый файл?
- Компилятор
- Отладчик
- Транслятор
- Интерпретатор
Вопрос 3
Укажите операционные системы для мобильных устройств.
- iOS
- Google Android
- Windows Phone
- MS DOS
- QNX
Вопрос 4
Отметьте все программы, которые относятся к системному программному обеспечению.
- Операционные системы
- Драйверы
- Утилиты
- Редакторы текста
- Игры
Вопрос 5
Выберите правильное имя файла:
- LES.BMP
- INFO\RMATIKA:TXT
- 1DOCUM.
- LIST.3.EXE
Вопрос 6
Первым в мире программистом считается .
- А. Лавлейс
- С. Лебедев
- Г. Лейбниц
- Б. Паскаль
Вопрос 7
Пользователь, перемещаясь из одного каталога в другой, последовательно посетил каталоги LESSONS, CLASS, SCHOOL, D:\, MYDOC, LETTERS. При каждом перемещении пользователь либо спускался в каталог на уровень ниже, либо поднимался на уровень выше. Каково полное имя каталога, из которого начал перемещение пользователь?
- D:\SCHOOL\CLASS\LESSONS
- D:\LESSONS
- D:\MYDOC\LETTERS
- D:\LESSONS\CLASS\SCHOOL
Вопрос 8
Что из предложенного можно считать полным именем файла?
- c:\log\ljfgh.txt
- kdftg.txt
- B:GG\NUL.DOC
- a:\d:\ghjuk.kc
Вопрос 9
Как называлось первое механическое устройство для выполнения четырех арифметических действий?
- арифмометр
- суан-пан
- соробан
- абак
Вопрос 10
Специальный микропроцессор, предназначенный для управления внешними устройствами, называется:
- контроллер
- драйвер
- транзистор
- концентратор
Вопрос 11
В каком веке появились механические арифмометры?
- в XVII в.
- в XIV в.
- в XIX в.
- в XVI в.
Вопрос 12
Элементарная база компьютеров второго поколения - это:
- транзистор
- электронная лампа
- интегральная схема
- большая интегральная схема
Вопрос 13
Отметьте принципы, которые можно отнести к основополагающим принципам построения компьютеров.
- принцип двоичного кодирования
- принцип программного управления
- принцип иерархической организации памяти
- принцип отсутствия умения принимать самостоятельные решения
- принцип доступной стоимости
Вопрос 14
Отметьте все прикладные программы.
- Электронные таблицы
- Графические редакторы
- Системы управления базами данных
- Утилиты
- Операционная система
Вопрос 15
В каталоге находятся файлы со следующими именами:
file.mdb file.mp3
ilona.mpg pile.mpg
miles.mp3 nil.mpeg
Определите, по какой из масок будет выбрана указанная группа файлов:
file.mp3
pile.mpg
miles.mp3
nil.mpeg
- ?il*.mp?
- *il?.mp*
- ?il*.mp
- ?il*.m*
Вопрос 16
Расставьте по порядку действия, выполняемые процессором при работе с программой:
- чтение команды из памяти и её расшифровка
- формирование адреса очередной команды
- выполнение команды
Вопрос 17
Заполните пропуски в предложении.
Команды программ и … хранятся в одной и той же памяти, и внешне в памяти они … . Распознать команды и данные можно только по способу … .
- данные, неразличимы, использования
- информация, неразличимы, кодирования
- информация, отличны друг от друга, кодирования
- данные, отличны друг от друга, использования
Вопрос 18
Установите соответствие между категориями людей, использующих компьютеры, и типами программного обеспечения:
- прикладные программы
- системы программирования
- системные программы
Вопрос 19
Что понимается под термином "поколение ЭВМ"?
- Совокупность машин, предназначенных для обработки, хранения и передачи информации
- Все типы моделей процессора Pentium
- Все счётные машины
- Все типы и модели ЭВМ, построенные на одних и тех же научных и технических принципах
Вопрос 20
Определите, какое из указанных имен файлов удовлетворяет маске: F??tb*.d?*.
Для улучшения понимания вопросов взаимодействия узлов и устройств ЭВМ рассмотрим автоматическое выполнение команды в трехадресной ЭВМ с классической архитектурой. Структурная схема такой ЭВМ показана на рис. 12.1
Обработку команды можно разбить на ряд функционально завершенных действий (этапов), составляющих ее цикл ( рис. 12.2).
Изучение цикла команды проведем при следующих начальных условиях и предположениях:
- программа и операнды находятся в оперативном запоминающем устройстве ( ОЗУ );
- адрес ячейки ОЗУ , в которой находится выполняемая команда ( k ), зафиксирован на счетчике команд ( СК );
- команда считывается за одно обращение к ОЗУ ;
- команда, операнды и приемник результата используют прямую адресацию памяти.
Определим взаимодействие узлов и устройств ЭВМ на каждом этапе.
Первый этап – выборка исполняемой команды из ОЗУ . Для реализации этого этапа необходимо код со счетчика команд (СК) = k передать в ОЗУ , обратиться в ячейку ОЗУ с адресом k и содержимое этой ячейки, являющееся кодом этой команды, передать на регистр команд . Соответствующие передачи отмечены на рис. 12.1 цифрой 1: передача кода СК на РА ( регистр адреса ) ОЗУ , дешифрация адреса на дешифраторе адреса ( ДшА ), считывание команды из ячейки ( k ) ОЗУ и передача ее в РК .
Регистр адреса служит для хранения адреса, по которому происходит обращение к ОЗУ , на время этого обращения. Дешифратор преобразует поступающий на него адрес в унитарный код, который непосредственно воспринимается физическими элементами схем памяти. На его выходах всегда имеется одна и только одна возбужденная шина , соответствующая адресу выбираемой ячейки. Регистр команд предназначен для хранения в процессоре считанной из ОЗУ команды на время ее выполнения. На этом этапе после приема команды на РК дешифратор кода операции ( ДшКОп ) по операционной части выполняемой команды определяет тип команды . Сигнал с ДшКОп таким образом настраивает блок управления операциями ( БУОп ), что на его выходах формируются управляющие сигналы ( УСi ), которые необходимы для автоматического выполнения всего цикла команды вплоть до занесения в РК новой команды. Формирование УСi проходит на основе сигналов с датчика сигналов ( ДС ), который вырабатывает импульсы, равномерно распределенные по своим выходам. Регистр команд , дешифратор кода операции , блок управления операциями, датчик сигналов , счетчик команд составляют устройство управления .
Если данная команда не является командой перехода, то реализуется следующая последовательность этапов как продолжение первого.
Второй этап – выборка первого операнда ( a ). Необходимо код из поля адреса первого операнда – a из РК передать в ОЗУ , обратиться к ячейке с адресом a в оперативной памяти и код этой ячейки передать в АЛУ . Соответствующие передачи обозначены на рис. 12.1 цифрой 2.
Третий этап – выборка второго операнда ( b ). Производится по аналогии со вторым этапом. Соответствующие передачи на рис. 12.1 отмечены цифрой 3.
Четвертый этап – выполнение операции в соответствии с полем кода операции команды. Еще в конце первого этапа коммутатор операций определил тип выполняемой команды. Операнды переданы в АЛУ на втором и третьем этапах. Блок управления операциями формирует управляющие сигналы , необходимые для выполнения данной операции в АЛУ . Результат выполненной в АЛУ операции сохраняется в его внутреннем регистре результата ( РР ), а признаки результата – в регистре признаков АЛУ . Соответствующие передачи и взаимодействия блоков обозначены на рис. 12.1 цифрой 4.
Пятый этап – обращение к ОЗУ и запись по адресу c результата операции . Здесь код поля c регистра команд передается в ОЗУ на РА . Затем в ячейку ОЗУ с адресом c записывается результат операции , находящийся в регистре результата АЛУ . Признаки результата записываются из регистра признаков АЛУ в регистр флагов компьютера, из которого они передаются в БУОп , если очередная считанная в РК команда окажется командой условного перехода. Соответствующие передачи обозначены на рис. 12.1 цифрой 5.
Шестой этап – формирование адреса ячейки ОЗУ , где находится следующая команда программы, то есть замена старого кода в счетчике команд на новый. Так как в ЭВМ предполагается естественный порядок выполнения программы, то следующая команда находится в ячейках ОЗУ , располагающихся сразу же вслед за ячейками, занятыми выполненной командой. Считая, что выполненная команда занимает в памяти ячеек, получим, что суть этого этапа заключается в следующем изменении счетчика команд : . На этом заканчивается цикл выполнения команды : в СК сформирован адрес следующей команды . Выполнение этого этапа может совмещаться с выполнением предшествующих этапов, что и реализовано в большинстве ЭВМ.
Приведенная последовательность этапов повторяется и в дальнейшем для каждой из последующих команд программы, что обеспечивает автоматическое выполнение программы.
При выполнении команды перехода вышеизложенная последовательность этапов меняется. Допустим, в конце выполнения первого этапа дешифратор кода операции зафиксировал выполнение команды безусловного перехода. Эту ситуацию можно представить так: (k) = БП j , то есть код выполняемой команды выбран из ячейки с адресом k , это – команда безусловного перехода ( БП ), которая должна передать управление на выполнение команды, имеющей смещение j относительно текущей команды. В данном случае выполнение этапов со второго по четвертый блокируется, и выполнение команды безусловного перехода заключается в прибавлении значения j к счетчику команд .
В команде условного перехода нарушение естественного порядка выполнения программы (то есть передача кода k + j в СК ) происходит только при выполнении определенного условия. Это условие характеризует результат, полученный командой, предшествующей команде условного перехода.
Таким условием может быть, например, отрицательный результат или результат, равный нулю.

Что CPU / ЦЕНТРАЛЬНЫЙ ПРОЦЕССОР выполняет инструкции программы, находящейся в памяти. Но знаете ли вы, что все они следуют одним и тем же общим правилам? Все они следуют одному и тому же командному циклу, который разделен на три отдельных этапа, называемых «выборка», «декодирование» и «выполнение», которые переводятся как выборка, декодирование и выполнение. Мы объясняем, как работают эти этапы и как они организованы.
Визуализация цикла обучения
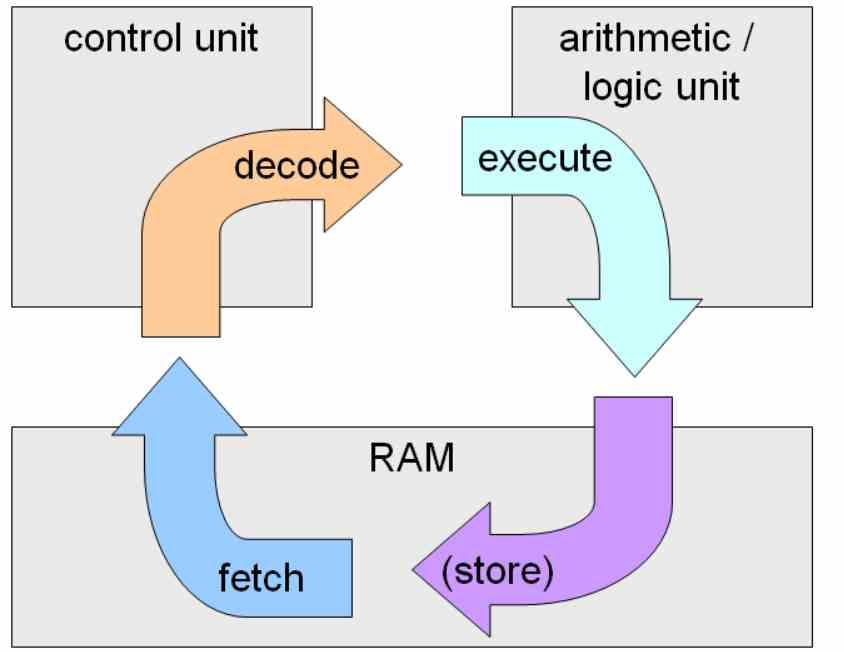
- Получить или захватить: В котором инструкция захватывается из ОЗУ и копируется в процессор.
- Декодирование или декодирование: В котором ранее захваченная инструкция декодируется и отправляется исполнительным блокам.
- Выполнили: Если инструкция разрешена, а результат записан во внутренние регистры процессора или в адрес памяти RAM
Эти три этапа выполняются в каждом процессоре. Существует четвертый этап, который является обратной записью, когда исполнительные блоки записывают результат, но это обычно учитывается на этапе выполнения цикла команд.
Первый этап цикла обучения: выборка
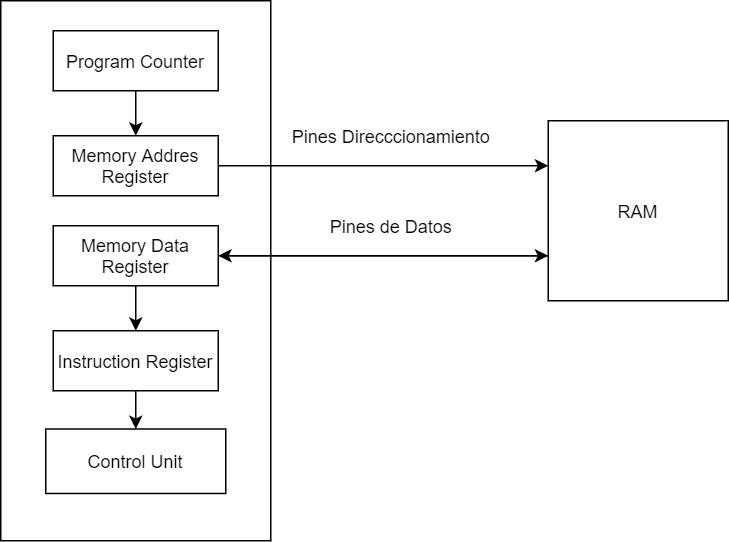
- Программный счетчик или Программный счетчик: Что указывает на следующую строку памяти, где находится следующая инструкция процессора. Его значение увеличивается на 1 каждый раз, когда завершается полный цикл команд или когда команда перехода изменяет значение программного счетчика.
- Регистр адреса памяти: MAR копирует содержимое ПК и отправляет его в ОЗУ через адресационные контакты ЦП, которые соединены с адресными контактами самого ОЗУ.
- Регистр данных памяти или регистр данных памяти : В случае, если ЦП должен выполнить чтение памяти, MDR копирует содержимое этого адреса памяти во внутренний регистр ЦП, который является временным регистром передачи, прежде чем его содержимое будет скопировано в регистр команд. MDR, в отличие от MAR, подключается к выводам данных RAM, а не к контактам адресации, и в случае инструкции записи содержимое того, что вы хотите записать в RAM, также записывается в MDR.
- Реестр инструкций: Заключительной частью этапа выборки является запись инструкции в регистр инструкций, из которого блок управления процессором копирует ее содержимое для второго этапа цикла инструкций.
Эти 4 подэтапа происходят во всех процессорах, независимо от их полезности, архитектуры и двоичной совместимости или того, что мы называем ISA.
устройство управления
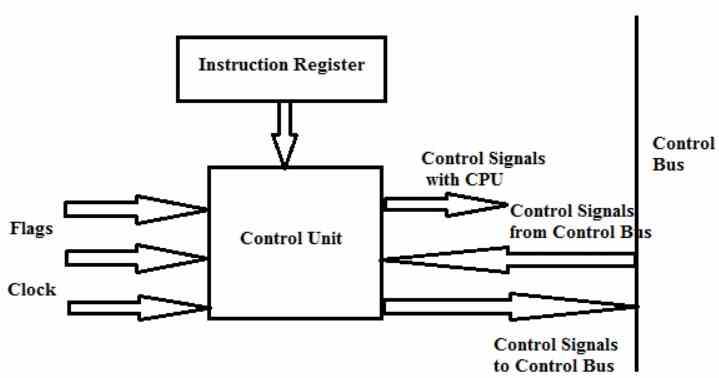
- Они отвечают за координацию движения и порядок, в котором данные перемещаются внутри и вне процессора, а также за различные подблоки, которые за это отвечают.
- В общем, считается, что блоки этапа захвата или Fetch являются частью оборудования, которое мы называем блоком управления, и это оборудование также называется Front-End процессора.
- Он интерпретирует инструкции и отправляет их различным исполнительным устройствам, к которым он подключен.
- Он передается различным ALU и исполнительным блокам процессора, которые действуют
- Он отвечает за захват и декодирование инструкций, а также за запись результатов в регистры, кеши или в соответствующий адрес ОЗУ.

Блок управления декодирует инструкции, и он делает это, потому что каждая инструкция на самом деле является своего рода предложением, в котором сначала идет глагол, а затем прямой объект или объект, на котором выполняется действие. Субъект в конечном итоге исключается на этом внутреннем языке компьютеров, поскольку понимается, что это сам компьютер выполняет его, поэтому каждое число битов представляет собой предложение, в котором первые 1 и 0 соответствуют действию, а единицы Далее идут данные или расположение данных, которыми нужно управлять.
Второй этап: декодирование
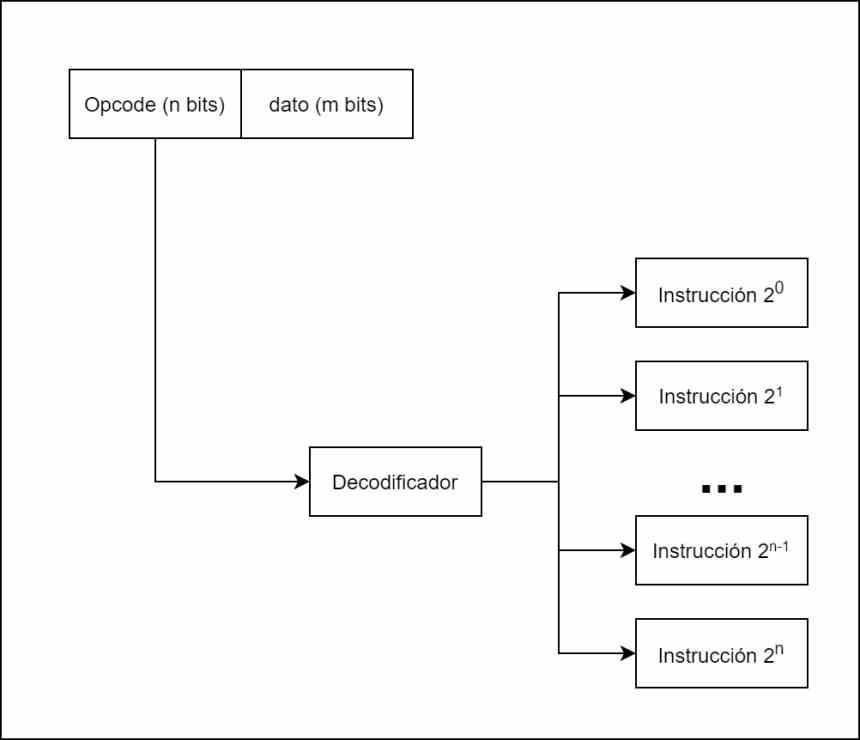
Существуют разные типы инструкций, и не все они делают одно и то же, поэтому в зависимости от типа инструкции нам нужно знать, в какие исполнительные единицы будут отправляться, и самый классический способ сделать это - использовать то, что мы называем декодером. , который принимает каждую инструкцию, делит ее внутри в соответствии с кодом операции или инструкцией и данными или адресом памяти, где она расположена.
Например, на диаграмме выше у нас есть диаграмма процессора всего с 8 инструкциями, которые могут быть закодированы только 3 битами. Каждая из инструкций после декодирования отправляется различным исполнительным блокам, которые их разрешат.
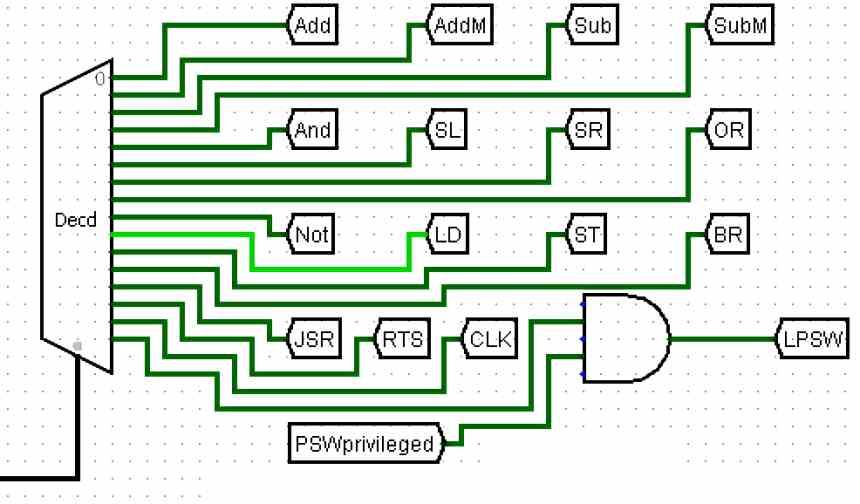

Этот цикл команд является самым сложным из всех и определяет тип архитектуры. В зависимости от того, есть ли у нас сокращенный или сложный набор инструкций, это повлияет на характер блока управления, в зависимости от формата инструкции или от того, сколько одновременно обрабатывается на этапе декодирования, и, следовательно, блок управления будет иметь разная природа. Другой.
Самый простой способ визуализировать происходящее - представить инструкции как поезда, движущиеся по сложной железнодорожной сети, и блок управления, направляющий их к конечной станции, которая является исполнительным блоком, который будет отвечать за выполнение инструкции.
Третий этап: Выполнить
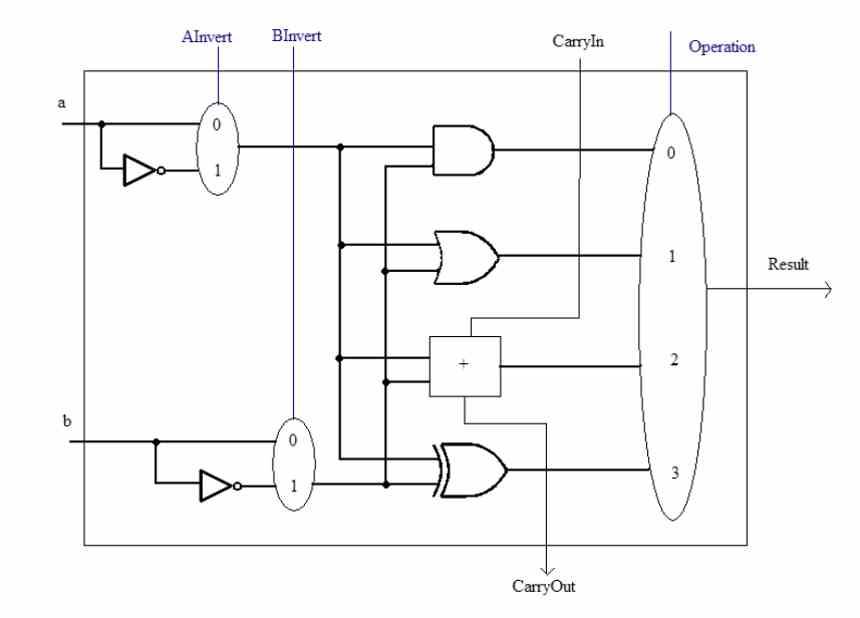
- Инструкции по перемещению долота: В котором осуществляется управление порядком битов, содержащих данные.
- Арифметические инструкции: Там, где выполняются математические и логические операции, они решаются в так называемых ALU или арифметико-логических устройствах.
- Инструкции по прыжкам: В котором изменяется следующее значение программного счетчика, что позволяет использовать код рекурсивно.
- Инструкция к памяти: Они используются процессором для чтения и записи информации из системной памяти.
Другой момент - это форматы инструкций, поскольку инструкция может применяться к данным, скаляру или нескольким данным одновременно, что мы знаем как SIMD. В заключение и в зависимости от формата данных существуют разные типы ALU для выполнения арифметических инструкций, например, сегодня у нас есть целые числа и блоки с плавающей запятой как дифференцированные блоки.
После того, как инструкция завершена, результат записывается в определенный адрес памяти, и выполняется следующий. Некоторые инструкции управляют не значениями памяти, а определенными регистрами. Таким образом, регистр программного счетчика модифицируется инструкциями перехода, если мы хотим читать или записывать данные, то управляются регистры MAR и MDR.
Читайте также: