Тип идентификации в 1с 8
Данная статья является анонсом новой функциональности.
Не рекомендуется использовать содержание данной статьи для освоения новой функциональности.
Полное описание новой функциональности будет приведено в документации к соответствующей версии.
Полный список изменений в новой версии приводится в файле v8Update.htm.
Реализовано в версии 8.3.15.1489.
Мы реализовали механизм, с помощью которого вы можете выполнять двухфакторную аутентификацию пользователей информационной базы. Он позволяет запрашивать у пользователя аутентификационные данные двух разных типов. Это обеспечивает более эффективную защиту от несанкционированного проникновения в информационную базу.
Аутентификация
Применительно к системе 1С:Предприятие аутентификация – это процедура проверки логина и пароля, которые ввёл пользователь, на корректность. Эту операцию платформа может выполнять самостоятельно, либо может воспользоваться результатами аутентификации, которую выполнил другой ресурс, которому она доверяет (операционная система или аутентификация OpenID). В любом случае либо там, либо там пользователь выбирает некоторый логин и вводит пароль. Если логин и пароль корректные, платформа считает, что пользователь идентифицирован и предоставляет ему доступ к данным.
Эта привычная парадигма (логин / пароль) проста и удобна, но обладает одним концептуальным недостатком. Пароль надо помнить, для этого он должен быть коротким и простым. Но такие пароли легко взломать. Чтобы пароль было трудно взломать, он должен быть длинным и сложным. Но такие пароли запомнить непросто. По этой причине в реальности всё сводится к тому, что люди используют простые пароли, причём в разных местах одни и те же.
Двухфакторная аутентификация - это способ, позволяющий, с одной стороны, значительно усложнить злоумышленникам доступ к чужим данным, а с другой стороны - это решение, которое позволяет в какой-то степени нивелировать недостатки классической парольной защиты.
Двухфакторная аутентификация требует, чтобы пользователь имел два из трех возможных типов аутентификационных данных:
- Нечто ему известное, то, что он помнит (например, логин / пароль),
- Нечто, чем он владеет (например, мобильный телефон),
- Нечто ему присущее (например, отпечаток пальца).
Смысл двухфакторной аутентификации заключается в том, что для того, чтобы куда-то попасть, пользователь должен дважды подтвердить тот факт, что он – это он, причём, разными способами. Например, ввести логин / пароль (первый фактор), а затем ввести код, присланный на его мобильный телефон (второй фактор).
Проверку первого фактора аутентификации выполняет платформа 1С:Предприятия, а для работы со вторым фактором аутентификации используется некоторый сторонний сервис, который мы будем называть провайдером.
Провайдер второго фактора аутентификации
Сценарии аутентификации
Чтобы дальнейший рассказ был более понятным, рассмотрим сразу два сценария аутентификации, которые позволяет реализовывать новый механизм.
Итак, стандартная аутентификация 1С:Предприятия (первый фактор) выглядит следующим образом:
- Пользователь запускает клиентское приложение. Оно запрашивает у него первый фактор аутентификации – логин и пароль. Пользователь вводит их, клиентское приложение отправляет их на сервер.
- Сервер проверяет логин и пароль на корректность. Если они верные, сервер проверяет, нужно ли для этого пользователя использовать второй фактор аутентификации.
Если второй фактор использовать не нужно, то считается, что пользователь полностью идентифицирован и может начинать работу. Это привычный сценарий аутентификации, который существует в платформе сейчас.
А вот если для этого пользователя нужно использовать второй фактор, то дальше возможны два новых сценария использования второго фактора аутентификации.
Простой провайдер

«Умный» провайдер

Пользователи и провайдеры
То, у какого провайдера и каким образом выполнять аутентификацию второго фактора, определяется для каждого пользователя отдельно.
В результате, например, шаблон для простого провайдера, отправляющего СМС, вы можете сформировать, задав только один запрос – запрос для аутентификации. В этом запросе будут использованы два параметра – host (адрес провайдера) и secret (код второго фактора, который сформирует платформа):

Шаблон «умного» провайдера будет содержать уже два запроса (просьба выполнить аутентификацию и запрос результатов аутентификации):

После того, как вы сохранили один или несколько шаблонов для провайдеров, вы можете каждому пользователю назначить определенный шаблон и набор значений для параметров, которые должны подставляться в этот шаблон.

А для пользователя, который будет использовать «умного» провайдера, параметров понадобится больше:

Журнал регистрации
Для всех новых сценариев аутентификации мы добавили в журнал регистрации новые события и новые поля некоторым старым событиям. Поэтому вы сможете контролировать не только сами процессы аутентификации, но и связанные с ними действия: изменение шаблонов второго фактора аутентификации, а также изменение настроек пользователей, связанных с двухфакторной аутентификацией.

Для отправки заявления на выпуск сертификата КЭП, составленного по новой форме, фирма «1С» рекомендует обновить прикладные конфигурации.
Что изменилось в форме заявления
С 1 сентября этого года вступил в силу приказ ФСБ № 795, в котором утверждены новые требования к форме квалифицированного сертификата ключа проверки электронной подписи.
В частности, в форме заявки на получение сертификата в составе дополнительных атрибутов имени появились новые обязательные атрибуты:
- INNLE для указания ИНН юридических лиц. Значение атрибута INNLE представляет собой строку, состоящую из 10 цифр
- OGRNIP для указания ОГРНИП владельца квалифицированного сертификата – физического лица, являющегося индивидуальным предпринимателем. Значением атрибута OGRNIP станет строка, состоящая из 15 цифр.
- IdentificationKind, определяющий метод идентификации заявителя при получении сертификата ключа проверки ЭП. Может иметь значения:
- 0 – сертификат выдавался при личном присутствии;
- 1 – без личного присутствия с использованием имеющейся квалифицированной ЭП;
- 2 – без личного присутствия, по данным паспорта и биометрическим персональным данным;
- 3 – без личного присутствия с применением единой биометрической системы.
Подробное описание всех изменений есть в приложении к приказу об утверждении требований к форме квалифицированного сертификата ключа проверки электронной подписи.
Фирма «1С» рекомендует обновиться
При этом сертификаты, выпущенные по заявлениям, отправленные до 1 сентября, останутся действительными до окончания их срока действия и не потребуют перевыпуска.
Поддержка новой формы заявления уже реализована в большинстве тиражных продуктов или запланирована на первую половину сентября. График выпуска обновлений опубликован в разделе «Монитор законодательства» на сайте «1С».
Тем, кто не читал первые, можно перейти по ссылкам ниже:
- Первая, вводная статья (для тех, кто не знаком механизмом обмена данными через ED ).
- Вторая статья – процесс выгрузки данных.
Чтобы облегчить восприятие информации, я сделал схемы с кратким пояснением. Под схемами идет более подробное описание. Схемы можно скачать в формате PowerPoint в комментарии к статье.
ИБ – информационная база, участвующая в обмене данными,
КД31 – информационная базы для создания правил конвертации (Конвертация данных 3.1),
ED – EnterpriseData (Универсальный формат обмена данными),
ПОД – правило обработки данных,
ПКО – правило конвертации объекта,
ПКС – правило конвертации свойства,
УИД – уникальный идентификатор объекта
Инструкция – структура, содержащая два элемента: имя правила конвертации и значение самого объекта, которое необходимо конвертировать. Боле подробно инструкция описана во второй статье.
Общая последовательность операций при загрузке данных
Ниже приведена общая схема процессов загрузки данных:
![Процесс загрузки данных]()
Первое, что происходит во время загрузки данных, это инициализация структуры «Компоненты обмена» и выполнение обработчика «Перед конвертацией». Как правило, данный обработчик используется для инициализации параметров обмена, как и в случае выгрузки данных.
Дальше происходит чтение файла данных. Последовательно считывается каждый объект XDTO и преобразуется в структуру, поля которой соответствуют самому объекту.
Для каждого объекта выполняется поиск ПОД по типа объекта, и его выполнение.
Дальше выполняется обработчик «При обработке». В обработчике доступен параметр «Данные XDTO », в который передается подготовленная структура с данными из XDTO объекта. Также в обработчике доступен параметр «ИспользуемыеПКО», который также является структурой. Ключи структуры, это имена ПКО, выбранные для данного ПОД. Значения элементов структуры имеют тип «булево». Выполняться будут только те ПКО, для которых значения в структуре равны «Истина». Обработчик в основном используется для отключения лишних ПКО для объекта на основании полученных данных и параметров обмена.
Дальше выполняется конвертация объекта по всем не отключенным ПКО. Именно на этом этапе происходит конвертация свойств первого и второго этапов, идентификация и запись объекта в ИБ. Запись выполняется в режиме «ОбменДанными.Загрузка = Истина», минуя все платформенные проверки и обработчики при записи. Этап конвертации объекта рассмотрен в отдельном разделе.
Дальше, после выборки и обработки всех объектов из файла обмена, выполняется обработчик «Перед отложенным заполнением». В нем можно реализовать какие-либо действия, необходимые перед отложенным заполнением. Например, можно выполнить сортировку данных в таблице для отложенного заполнения «КомпонентыОбмена.ЗагруженныеОбъекты». В таблицу записываются все выгруженные объекты, для которых указан алгоритм в КД31, на закладке «После загрузки всех данных». Объекты записываются в той же последовательности, в которой они были загружены. Можно их отсортировать по типу объекта.
Дальше выполняется само отложенное заполнение объектов. Отрабатываются алгоритмы для каждого объекта из таблицы «КомпонентыОбмена.ЗагруженныеОбъекты».
Последним обработчиком на этапе загрузки данных является обработчик «После конвертации». В нем можно выполнить какие-либо заключительные действия.
Самым последним действием на этапе загрузки является отложенная запись и отложенное проведение объектов, с выполнением всех необходимых проверок и обработчиков при загрузки. По своей сути, это обычная запись или проведение объекта.
Самым интересным элементом загрузке данных, является конвертация объекта по правилу. Но прежде чем перейти к подробному описанию этого процесса, введем новый термин – Идентификация.
Идентификация объектов при загрузке
Идентификация – это наиважнейшая операция при загрузке данных в ИБ. Она позволяет сопоставить загружаемые объекты с уже существующими в базе.
В КД31 доступны три варианта идентификации:
![Идентификация объектов при загрузке]()
По уникальному идентификатору (УИД) , используется по умолчанию – поиск выполняется по значению уникального идентификатора. Данный способ применяется, когда не нужно сопоставлять объекты одной ИБ с объектами в другой. Когда все объекты создаются только в одной ИБ, а затем переносятся в другую. После переноса объекта в ИБ приемнике у него создается УИД, аналогичный УИД этого объекта в ИБ источнике. После этого можно выполнять произвольное изменение реквизитов этого объекта в ИБ приемнике, на дальнейшую синхронизацию это не повлияет.
По полям поиска – поиск выполняется по набору полей объекта. Объект считается найденным, если совпадают все поля, указанные в качестве полей поиска. Данный способ используется для сопоставления объектов одной ИБ с объектами другой, когда объекты одного вида создаются как в ИБ источнике так и в ИБ приемнике. Существенный недостаток данного способа идентификации заключается в том, что если поля, указанные в качестве полей поиска будут изменены в ИБ приемнике, при последующей загрузки этого объекта из ИБ источника, объект не будет найден и будет загружен повторно. Из-за этого недостатка, данный способ идентификации обычно используется только в том случае, если отсутствует УИД у выгружаемых данных.
По уникальному идентификатору и полям поиска – поиск выполняется по УИД, если объект не найден, продолжается по указанным полям поиска. Если объект был найден по полям поиска, его УИД будет записан в специальный регистр сведений «ПубличныеИдентификаторыСинхронизируемыхОбъектов». При последующей синхронизации, поиск будет выполняться по УИД в данном регистре сведений, а не по полям. Таким образом можно выполнять сопоставление объектов, созданных в двух ИБ, и решается проблема поиска только по полям.
Примечание. Если загрузка данных выполняется в режиме «С дополнительными параметрами», и сопоставление объектов выполняется вручную, данные о сопоставленных объектах также записываются в регистр «ПубличныеИдентификаторыСинхронизируемыхОбъектов», и последующий поиск выполняется именно в данном регистре. Это справедливо только для объектов с идентификацией «По уникальному идентификатору» или «По уникальному идентификатору и полям поиска».
КД31 позволяет указать несколько разных комбинаций для поиска объектов по полям. Поиск в ИБ приемнике будет выполнен по всем комбинациям. Объект будет считаться найденным, если поиск успешен хотя бы по одной из этих комбинаций.
Конвертация объектов по правилам конвертации (ПКО)
Рассмотрим более подробно алгоритм основного этапа загрузки данных, в процессе которого происходит идентификация и запись новых или найденных объектов в ИБ.
Данный алгоритм можно разделить на два разных процесса:
- Конвертация объекта, загружаемого по ПОД – объект выгружен целиком из базы источника.
- Конвертация объекта по ссылке – загружается ссылка на объект из другого объекта.
Конвертация объекта, выгруженного целиком
Общая схема конвертации полного объекта:
![Конвертация полного объекта]()
Первым действием происходит поиск объекта по УИД, если данный вид идентификации доступен для объекта.
Дальше выполняется конвертация свойств (ПКС) первого этапа. На первом этапе происходит конвертация тех свойств, для которых задано свойство формата.
Дальше выполняется обработчик «При конвертации данных XDTO ». В обработчике доступны параметры:
- ДанныеXDTO – структура с полученными данными.
- ПолученныеДанные - новый, созданный объект данного типа, с частично заполненными свойствами (на первом этапе конвертации).
В обработчике можно реализовать произвольный механизм конвертации для тех свойств, для которых установлен флаг «Используется алгоритм конвертации». Значения всех таких свойств нужно поместить в структуру «Дополнительные свойства» параметра «ПолученныеДанные». Свойства можно помещать непосредственно, в виде значений или в виде инструкций (см. описание используемых терминов в начале статьи). Свойства – коллекции помещаются в виде массива структур.
После выполнения обработчика выполняется конвертация свойств второго этапа. Конвертируются все свойства и коллекции, добавленные в структуру «ДополнительныСвойства» параметра «ПолученныеДанные».
Дальше, если объект был найден по УИД, выполняется обработчик «Перед записью полученных данных». В обработчике доступны параметры: «ПолученныеДанные» и «ДанныеИБ».
Если объект найден, параметр «ДанныеИБ» содержит ссылку на этот объект.
Если объект не найден по УИД, и для него доступен поиск по полям, происходит поиск по этим полям. Если объект найден по полям, также вызывается обработчик «Перед записью полученных данных» с заполненным параметром «ДанныеИБ».
Если объект не найден ни по УИД ни по полям, в обработчике «Перед записью полученных данных», параметр «ДанныеИБ» будет иметь значение «Неопределено».
В данном обработчике, можно реализовать собственный поиск объекта, и присвоить параметру «ДанныеИБ» найденный объект самостоятельно. Если же параметр «ДанныеИБ» останется не заполненным, в ИБ будет создан новый объект, который находится в параметре «ПолученныеДанные».
Если объект был найден (по УИД, полям поиска или произвольным образом), его данные будут замещены значениями из параметра «ПолученныеДанные». Причем замещаться будут только те свойства объекта для которых были определены ПКС в настройках КД31.
Если в обработчике «Перед записью полученных данных» присвоить параметру «Полученные данные» значение «Неопределено», данные найденного объекта замещаться не будут.
Объект (новый или найденный) будет записан в режиме «ОбменДанными.Загрузка = Истина». Это значит, что не будут выполнены многие платформенные проверки и обработчики при записи объекта, и он запишется в любом случае.
Конвертация объекта, выгруженного по ссылке
Общая схема конвертации по ссылке:
![Конвертация объекта по ссылке]()
Так же, как и в случае с загрузкой полного объекта, сначала происходит поиск по УИД (если он доступен). Если объект найден, возвращается ссылка на него, и больше никаких действий не происходит.
Если объект не найден по УИД, и поиск по полям для объекта не доступен, возвращается пустая ссылка. В этом случае, если объект в дальнейшем не будет загружен по ПОД полностью, будет ссылка на несуществующий объект.
Если же для объекта доступен поиск по полям, происходит конвертация свойств первого и второго этапов с выполнением обработчика «При конвертации данных XDTO ». Все происходит аналогично конвертации полного объекта, за исключением того, что конвертируются только те свойства, которые указаны в полях поиска. Обратите внимание, что это могут быть не все ключевые данные, которые присутствуют в файле данных.
Дальше происходит поиск объекта по полям поиска. В случае, если объект найден, возвращается ссылка на него. А если же он не найден, выполняется обработчик «Перед записью полученных данных». В этом обработчике можно реализовать собственный поиск объекта. Но, обратите внимание, поиск будет выполняться только в том случае, если объект не был найден ни по УИД ни по полям поиска.
Дальше происходит запись частично заполненного объекта (заполнены только поля поиска), и возвращается ссылка не него. Поскольку запись происходит в режиме «ОбменДанными.Загрузка = Истина», объект будет записан на данном этапе.
Дальше проверяется, используется ли ПКО выгружаемого по ссылке объекта в каком-нибудь ПОД. Если ПКО негде не используется, в ИБ так и остается частично записанный объект. Если ПКО используется, объект помещается в специальную таблицу значений «КомпонентыОбмена.ТаблицаОбъектовСозданныхПоСсылкам». Если при дальнейшей загрузки объектов, этот объект не будет загружен полностью, он будет удален из ИБ. Ссылка на него из других записанных объектов будет «битой» (указывать на не существующий объект).
Полезные процедуры общего модуля «ОбменДаннымиXDTOСервер»Данные процедуры участвуют в алгоритмах загрузки данных. Некоторые из них могут быть использованы в обработчиках загрузки, а также при реализации собственных алгоритмов.
ИнициализироватьКомпонентыОбмена – выполняет инициализацию компонентов обмена данными, создание и первоначальное заполнение структуры «КомпонентыОбмена».
ПроизвестиЧтениеДанных – выполняет чтение данных, загруженных в параметр «КомпонентыОбмена.ФайлДанных». Выполняются все действия по обработке и загрузке полученных данных.
СсылкаОбъектаПоУИДОбъектаXDTO – выполняет поиск ссылки на объект по УИД из полученных данных XDTO . Сначала поиск выполняется в регистре «ПубличныеИдентификаторыСинхронизируемыхОбъектов».
ПОДПоТипуОбъектаXDTO – выполняет поиск правил обработки данных по типу объекта XDTO .
ПКОПоИмени – выполняет поиск правила конвертации объекта по имени в таблице «ПравилаКонвертацииОбъектов» структуры «КомпонентыОбмена»
СтруктураОбъектаXDTOВДанныеИБ – выполняет преобразование данных из структуры XDTO в объект ИБ. В зависимости от переданного параметра «Действие», может быть либо получена ссылка на объект (только идентификация), либо полноценная загрузка объекта.
ОбъектXDTOВСтруктуру – выполняет создание структуры «ДанныеXDTO» по данным прочитанного из файла загрузки объекта XDTO .
ЗаписатьОбъектВИБ – выполняет запись объекта в ИБ в режиме «ОбменДанными.Загрузка = Истина».
ВыполнитьОтложенноеПроведениеДокументов – выполняет отложенное проведение документов после загрузки всех данных. Проведение выполняется со всеми необходимыми проверками.
ЗаписьЖурналаРегистрацииОбменДанными – выполняет запись произвольных данных в журнал регистрации.
Основные элементы структуры «КомпонентыОбмена»Структура, содержащая всю информацию по текущему обмену данными. Передается в качестве параметра во все обработчики при загрузке данных.
Общие элементы структуры рассмотрены во второй статье, посвященной выгрузки данных.
Элементы, используемые при загрузке данных
РежимЗагрузкиДанныхВИнформационнуюБазу – флаг, указывающий на то, что происходит загрузка данных в ИБ
СчетчикЗагруженныхОбъектов – позиция текущего загружаемого объекты.
КоличествоОбъектовНаТранзакцию – параметр определяет, нужно ли использовать транзакции при загрузке данных (значение > 0), и сколько объектов необходимо включать в одну транзакцию.
КоличествоОбъектовКЗагрузке – общее количество загружаемых объектов.
ДокументыДляОтложенногоПроведения – список документов для отложенного проведения (с выполнением всех платформенных проверок и обработчиков при записи).
ТаблицаОбъектовСозданныхПоСсылкам – список объектов созданных по ссылке по ПКО, которые используются в ПОД. Все объекты из данного списка, которые не будут загружены полностью, будут удалены из ИБ.
ОбъектыДляОтложеннойЗаписи – список объектов для отложенной записи (с выполнением всех платформенных проверок и обработчиков при записи).
На этом все, спасибо за внимание. Напишите, пожалуйста, в комментариях, какие еще темы по ED могут быть интересны. Ну и ставьте плюс, если статья Вам понравилась.
Другие мои статьи из серии «Новый подход к обмену данными»
Для нужд своих клиентов я внедрил биометрию на базе сканера ANVIZ OA 99 .
![]()
Выбор оборудования был обусловлен :
1. Отсутствие платы за SDK . Т.е. можно разрабатывать любые программы, взаимодействующие со сканером бесплатно. В среднем SDK других производителей стоит 1000$.
2. Отсутствие платы за лицензию на сканер при использовании собственных программ, разработанных на SDK . В среднем лицензия стоит 20$ на сканер.
3. Известность бренда Anviz.
4. Принцип работы аналогичен сканерам ULINK , особо популярным в России.
Мой поставщик поставляет ANVIZ OA 99 по цене 4400 при поставке от 10 штук. Оборудование надо заказывать заранее, в запасе обычно не более 5 устройств, поставка – 1,5-2 месяца, но можно поискать и у других поставщиков.
Для сопряжения 1С со сканером было разработано приложение-коннектор на VB 6, управляемое из командной строки.
Оно понимает команды :
1. Получения отпечатка пальца
2. Верификации отпечатка с ключом отпечатка.
3. Идентификации пользователя по базе ключей отпечатков
SDK Anviz содержит функции для получения и распознавания отпечатков. Поэтому приложение просто интерпретирует переданные команды и вызывает функции SDK . Функции расположены в DLL , но напрямую DLL из 1С вызывать нельзя, поэтому используется программа-посредник с управлением через командную строку.
Как вариант, можно было бы написать внешнюю компоненту, но есть недостатки :
1. Компонента требует регистрации на компьютере под администраторскими правами.
2. COM -объекты более глючные и чаще зависают (проверено на практике).
Для идентификации формируется файл базы отпечатков, который считывает коннектор в режиме идентификации и по нему распознает пользователя. Файл формируется через компоненту ADODB , которая есть по умолчанию в любой Windows .
Программа-коннектор имеет форму, где все указания и команды сделаны на русском языке, текстом, понятным простому сотруднику.
На данный момент в базе 75 пользователей, каждый сдал по 2 отпечатка левого и правого указательных пальцев, но можно сдавать отпечатки любых пальцев. Постепенно база растет. Ошибок распознавания и жалоб на работу оборудования замечено не было.
Существующие недостатки решения :
1. После ввода отпечатка пальца окно программы-коннектора закрывается, но фокус отдается не в 1с, а в следующее в Z -последовательности окон приложение. Решаемо, но пока не занимался.
2. Драйвер ANVIZ работает только под администраторскими правами, производитель драйвера менять это поведение не собирается. Мы выкрутились через использование CPAU , которая позволяет запускать программу под правами администратора. Возможно, можно найти, какое именно право нужно, но у нас не получилось. Это какое-то из прав работы со съемными дисками, навскидку.
3. COM -компонента – более защищенное решение, хотя и в приложение, управляемое через командную строку, сложно вмешаться. Но, в принципе, если изменить базу отпечатков пальцев, то можно теоретически совершить манипуляцию. Но это не недостаток решения, просто, если требуется, нужно уделить больше внимания правам доступа.
4. Неизвестно, можно ли сделать mapping драйвера устройства в терминальном режиме.
Само решение состоит из следующих модулей :
1. Программа-коннектор на VB 6, использует SDK в виде DLL -файлов. Вызывается и управляется через командную строку.
2. Модуль в 1С для подготовки данных для коннектора и вызова коннектора.
3. Обработка в 1С для снятия отпечатков сотрудников, их тестовой верификации и идентификации.
В 1С в форму выбора физических лиц добавляется кнопка, по нажатию на которую физическое лицо выбирается через сканер.
Соответственно, 1С получает подтверждение о том, что физлицо выбрано через сканер и можно это контролировать.
Существует функция для выбора физлица, которая может вызываться из нужных мест программы. В ней контролируется, что физлицо было выбрано через сканер (биометрически). Для некоторых физлиц допускается возможность работы без отпечатков (исключения), если, например, их отпечатки не снимаются. Но такого у нас не было, т.к. можно снимать любой палец, а не только указательный.
По сути, все что требуется – это добавить модули в программу, в нужных местах вашего сценария расставить вызов функции выбора сотрудника через биометрию, дать права ответственному сотруднику на снятие отпечатков пользователей.
Если в программе используется не справочник ФизическиеЛица, а другой, нужно адаптировать программу под соответствующий справочник, что делается в 1С достаточно тривиально.
Демонстрационные данные
Для проверки работоспособности программы с вашим сканером выложена демонстрационная версия программы.
Для начала работы с программой нужно:
- Создать папку anviz в корне диска C : и скопировать в нее содержимое каталога anviz .
- Файл 1Cv8.1CD – это файл базы данных 1С81. Пропишите его в список баз и откройте, зайдите под пользователем Администратор с пустым паролем.
- Подключите сканер в USB порт.
Для того, чтобы программа работала нужно, чтобы у пользователя были права администратора.
![]()
В справочнике Физические лица заведено трое сотрудников:
![]()
Пункт меню «Ввод отпечатков anviz » открывает обработку, которой пользуется администратор базы данных отпечатков для сбора, удаления и изменения отпечатков пальцев. Для проверки можно выполнить добавление отпечатков, верификацию, идентификацию, смотрите раздел «Работа администратора базы данных отпечатков».
Работа администратора базы данных отпечатков
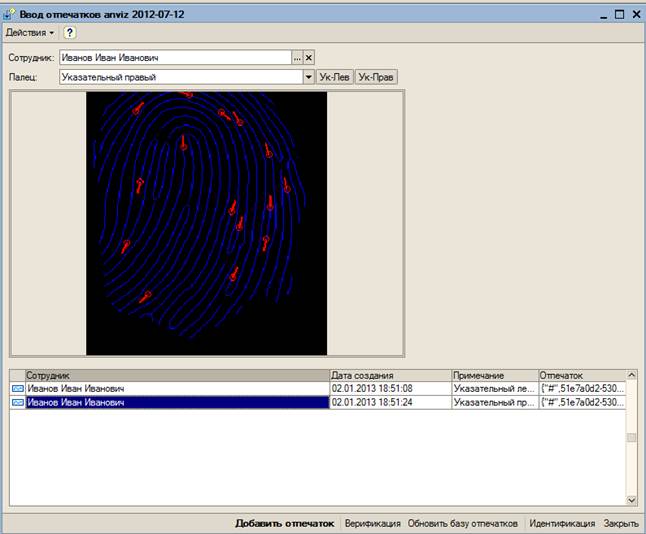
Обработка, с которой работает администратора базы данных отпечатков, имеет вид:
![]()
Добавление отпечатка пальца:
- Нужно выбрать сотрудника в поле «Сотрудник»
- Выбрать палец, который сканируется. Можно выбрать из списка или использовать кнопки быстрого выбора «Ук-лев» или «Ук-прав».
- Попросить сотрудника положить палец на устройство и не отпускать.
- Нажать кнопку «Добавить отпечаток». Откроется окно программы-коннектора. При этом отпечаток сразу считается, т.к. сотрудник приложил палец. Будет отображена картинка отпечатка и добавлена строчка в список отпечатков сотрудника.
- Нажать кнопку «Верификация». Будет еще раз получен отпечаток пальца и произведено сопоставление полученного отпечатка со слепком в базе данных. Если верификация прошла неуспешно несколько раз, удалить отпечаток и снять повторно.
- Нажать кнопку «Обновить базу отпечатков». При этом все отпечатки, хранимые в базе, будут собраны в файл, используемый для идентификации.
- Нажать кнопку «Идентификация». Будет еще раз получен отпечаток пальца и произведено его сопоставление с базой всех отпечатков.
- В результате идентификации сотрудник должен быть опознан и выдана фамилия сотрудника в поле «Сотрудник».
- Установить курсор в списке на удаляемый отпечаток.
- Нажать кнопку « Delete » на клавиатуре. Подтвердить удаление.
Особенности подключения сканера в Windows
Устройство распознается как USB -флешка:
![]()
Особенности реализации в 1С
В 1С используются следующие объекты :
- Модуль _ Anviz - основные функции для работы с биометрией Anviz .
- Модуль _ AnvizLocal - локальные для клиента особенности реализации биометрии.
- Регистр _БиометрияAnviz - хранит отпечатки сотрудников
- Константы ДанныеБиометрии Anviz и ДанныеБиометрии Anviz 2 - используются для хранения уже готовой базы данных отпечатков для идентификации.
Для того, чтобы клиент мог по-своему написать некоторые нюансы реализации, в модуле _AnvizLocal реализованы вызовы событий, которые можно реализовать по-своему, не затрагивая основной модуль _Anviz :
Механизм сопоставления данных при обмене через универсальный формат
Логично ожидать, что при синхронизации данных, как начальной, так и основанной на регулярной основе, одинаковые данные в приложениях будут сопоставлены между собой.
Для решения этой задачи как раз и предназначен механизм сопоставления данных.
В идеальном случае данные синхронизируемых приложений могли бы сопоставляться по уникальным внутренним идентификаторам объектов (GUID). Но для этого необходимо, чтобы добавление данных, подлежащих синхронизации, осуществлялся только в одном приложении, а в другом эти данные появлялись исключительно в результате синхронизации. В этом случае GUID в двух приложениях у одинаковых объектов будут одинаковыми, и по ним можно будет однозначно сопоставить объекты.
На практике соблюдать данное требование не всегда возможно, особенно в случае настройки синхронизации между приложениями, работа в которых велась независимо. Это связано с тем, что у двух одинаковых объектов, созданных параллельно в каждом приложении, будет два разных GUID.
В некоторых случаях данные не могут быть сопоставлены по GUID по причине его отсутствия (особые случаи, которые не рассматриваются в данной статье).
Для успешного сопоставления объектов с разными GUID должно быть место для хранения информация об их соответствии. Таким местом является регистр сведений Публичные идентификаторы синхронизируемых объектов (далее РПИ ). Структура регистра представлена в таблице:
Узел информационной базы ПланОбменаСсылка Ссылка на узел плана обмена (настройку обмена), для которой хранится соответствие. Ссылка СправочникСсылка,
ПланВидовХарактеристикСсылка,
ДокументСсылкаСсылка на объект текущего приложения. Идентификатор Строка (36) GUID объекта, полученного от приложения-корреспондента. При получении данных записи в регистре могут появляться на нескольких этапах (см. рисунок 1). Подробное описание самих алгоритмов сопоставления см. далее.
![]()
Рисунок 1. Этапы, на которых могут быть сделаны записи в РПИ
Этапы, помеченные пунктиром, опциональные: при выполнении сеанса обмена в автоматическом режиме отсутствуют этапы 1 и 2, при выполнении в интерактивном режиме этап 2 может быть пропущен пользователем.
В процессе обмена данные РПИ обеспечивают следующую функциональность:
- Сопоставление объектов при получении данных (см. рисунок 2-а).
- Обработка получаемых данных (замена ссылок) с целью обеспечения ссылочной целостности (см. рисунок 2-b).
- Обработка отправляемых данных (замена ссылок) для исключения повторного сопоставления на стороне приложения-корреспондента уже сопоставленных данных (см. рисунок 2-b).
![]()
Рисунок 2. Использование данных РПИ при получении и при отправке данных.
Прикладная логика, определяющая порядок автоматического сопоставления объектов при получении, содержится в правилах конвертации объектов (ПКО), предназначенных для получения данных.
Все компоненты (правила обработки данных, правила конвертации объектов и т.д.), определяющие прикладную логику обработки данных в процессе их получения, либо отправки (подробнее в статье Методика работы с конфигурацией "Конвертация данных 3.0" ) формируют так называемый менеджер обмена . Код менеджера обмена разрабатывается в общем модуле (подробное описание см. в документации по БСП , в разделе Обмен через универсальный формат ). Модуль создается автоматически с помощью КД3.0 на основе настроенных правил обмена либо вручную в конфигураторе (см. пример - общий модуль _ДемоМенеджерОбменаЧерезУниверсальныйФормат демо-конфигурации БСП ).
Вариант автоматического сопоставления (идентификации) объектов при получении задается с помощью свойства ВариантИдентификации ПКО и может принимать одно из трех значений:
- ПоУникальномуИдентификатору - идентификация по GUID,
- СначалаПоУникальномуИдентификаторуПотомПоПолямПоиска - идентификация по GUID и полям поиска,
- ПоПолямПоиска - идентификация по полям поиска,
Еще одним свойством, определяющим логику сопоставления, является массив полей поиска, определяемый в свойстве ПоляПоиска ПКО.
![]()
Рисунок 3. Настройки идентификации в модуле менеджера и в КД3.0.
В таблице 1 представлено описание использования данных настроек при автоматическом сопоставлении на разных этапах получения данных:
Этап анализа данных (при загрузке через помощник синхронизации данных)
Ручное сопоставление (при загрузке через помощник синхронизации данных)
Идентификация по РПИ .
Идентификация по GUID.
Запись соответствий в РПИ: делается, если соответствие нашлось при выполнении п.3.
Сопоставлять можно со всеми объектами соответствующего типа, для которых нет соответствий в РПИ .
Запись соответствий в РПИ: делается по результатам сопоставления.
Идентификация по РПИ .
Идентификация по GUID среди объектов, отсутствующих в РПИ .
Запись соответствий в РПИ: делается для либо с исходным GUID, либо с вновь сгенерированным, п. 1 не дал результата но объект с таким GUID уже есть в РПИ .
По GUID и полям поиска Аналогично варианту "По GUID".
Идентификация по РПИ .
Идентификация по GUID.
Запись соответствий в РПИ: см. выше.
См. колонку "Загрузка данных"
Запись соответствий в РПИ: не делаются.
Таблица 1. Правила работы настроек идентификации.
Происходит последовательное применение вариантов поиска, заданных в свойстве ПоляПоиска ПКО, используемого при загрузке объекта.
Ограничение.
При сопоставлении на этапе анализа данных применяется только 1-й вариант поиска.Переход к следующему варианту осуществляется в двух случаях:
- У загружаемого объекта не заполнено какое-либо из полей, которое указано в варианте поиска.
- Вариант поиска не дал результата.
Если в загружаемом объекте есть информация об исходном GUID и вариант идентификации для объекта "По GUID" или "По GUID и полям поиска", то поиск выполняется среди всех объектов заданного типа, кроме тех, для которых в РПИ уже установлены соответствия.
В остальных случаях поиск осуществляется среди всех объектов информационной базы соответствующего типа.
Особенность.
При сопоставлении на этапе анализа данных у загружаемых объектов не проверяется заполнение полей, участвующих в поиске.Особенность.
На этапе анализа данных соответствие будет установлено только в том случае, когда для одного объекта отправителя был найден один объект получателя.
На этапе загрузки данных соответствие будет установлено и в том случае, когда для одного объекта отправителя нашлось несколько объектов получателя. В такой ситуации соответствие будет установлено с одним из них.Особенность.
На этапе загрузки данных вариант поиска Номер + Дата для документов работает следующим образом: номер искомого документа проверяется на точное соответствие, дата определяет интервал, в котором проводится поиск по номеру. Сам интервал определяется как период уникальности номеров документа, в который входит указанная дата. Например, если номера документов уникальны в пределах месяца и задана дата 10 декабря 2001 года, то поиск будет проводиться в интервале с 01 по 31 декабря 2001 года.
На этапе анализа данных этот вариант поиска будет работать как обычно: оба поля будут проверяться на точное соответствие.Читайте также:
- Как назначить звонок в outlook
- Microsoft office ubit menu что это
- Как удалить дубликаты в excel libreoffice
- Как удалить папки на планшете
- Сбросить состояние датчика вскрытия корпуса в bios