
Тестовый контур 1с это

В предыдущей статье я описал проблемы, с которыми мы столкнулись в самом начале становления QA-процессов в нашем хранилище, а также первые шаги по их исправлению. В этой статье расскажу, как мы справлялись с оставшимися проблемами, какие инструменты использовали и какие у нас планы.
Проблемы прошлого
Для начала вспомним, какие же проблемы остались актуальными:
Ручной сбор пакета разработчиками.
Ручное ревью пакета.
Необходимость в синхронизации продуктового и тестового контуров.
Недоступность операций над метаинформацией при возникновении очереди.
Отдельный контур для тестирования интеграции.
Кроме того, из последней проблемы вытекает тот факт, что целых три тестовых контура используются в текущем flow.
Три тестовых контура (vial, live и test)
Я уже писал про vial и live — серверы для проведения модульного и регрессионного тестирования ETL-процессов. Они позволили отделить эти виды тестов, но старый test-контур при этом никуда не делся и использовался для интеграционного тестирования пакета, уже прошедшего модульное тестирование на vial. Кроме того, ряд задач невозможно было протестировать на vial в силу различных обстоятельств, и с ними по-прежнему работали на test.
Было: все тестирование на одном контуре.
Стало: модульное и интеграционное тестирование, а также регресс разнесены по разным контурам.

Распределение этапов тестирования между контурами
тестовых контуров стало больше;
test по-прежнему использовался.
Зачем нужен test?
Во-вторых, ряд задач просто нельзя было на тот момент тестировать на vial по разным причинам. Например, бэкапы для некоторых таблиц нельзя (или очень проблематично) было перенести на vial с prod. Поэтому их тестировали на test.
Хорошо, с важностью и необходимостью test’а разобрались.
А в чем были проблемы с test при текущем flow с тремя тестовыми контурами?
Оказывается, проблем было несколько:
необходимость синхронизаций с продом;
О синхронизации уже говорили, поэтому рассмотрим две оставшиеся проблемы.
При совместном использовании теста многими QA-инженерами время от времени возникали конфликты метаинформации и/или физических данных из-за одновременного использования в разных задачах одинаковых объектов. В этом случае нужен был откат задач и согласование порядка работы с объектами (порядка наката и тестирования).
Давайте рассмотрим решения проблем при помощи наших разработок, и начнем с проблемы ручного сбора пакетов.
Текущие реалии

Мы шаг за шагом улучшали наши процессы и создавали новые инструменты, развивая их. Постепенно переходили к автоматизации. Остановимся на этом подробнее.

Составляющие автоматизации
Про авторелиз уже рассказали в предыдущей статье, поэтому рассмотрим остальные составляющие.
Портал автоматизации
Консольная утилита автонаката задач на разные контуры была очень полезной, но мы не зацикливались на ней, да и, что называется, аппетит приходит во время еды.
Через некоторое время в работу был введен портал автоматизации — это наше внутреннее веб-приложение, которое помогает разработчикам, QA-инженерам, ревьюверам и ребятам, выполняющим релизы задач, вести свою работу с пакетами в одном месте.

Отображение пакета на портале автоматизации
Какие функции предоставляет портал автоматизации?
Автоматический сбор пакета.
Накаты задач на все контуры.
Большой пул работ с метаинформацией.
На портале автоматизации у разработчика появилась возможность собрать свой пакет автоматически. Причем, если задача не содержит специфических объектов и действий, на лету создается пакет с типовым содержимым и сценарием. А если сценарий по данной задаче содержит специфические действия, то на портале есть функционал создания сложного сценария работы с объектами хранилища данных и наката.
А еще у нас появилась загадочная сущность — автотестер, решающая задачи автоматического создания тестовых окружений.
Автотестер
Итак, автотестер — это совокупность нескольких демонов, создающих готовые vial-окружения без каких-либо ручных действий со стороны сотрудников.
Автотестер запускает накаты задач ежедневно в 20:30, поскольку в это время нагрузка на тестовый контур резко снижается и работы автотестера никак не будут блокировать работу сотрудников. Он берет все задачи, которые успешно прошли ревью и по которым в Jira указан уровень тестирования «автоматическое». Такой уровень тестирования проставляется у всех задач, для которых не предполагаются ручные действия во время наката. А далее запускает процесс создания пробирок.
Автотестер создает чат с разработчиком и QA и в случае возникновения ошибок окружения (моргнула база, кончилось место или же в самом пакете вылезли ошибки, которые не были выявлены на ревью) отправляет туда лог ошибки.
После успешного переноса задачи на vial запускаются автотесты и сравнения текущих и предыдущих версий целевых таблиц, а также чекеры целостности данных. Результаты всех этих проверок автотестер отправляет в тот же slack-канал.

Результаты автопроверок в slack-канале
С появлением авторелиза, а затем и портала автоматизации перенакаты задач перестали требовать множества ручных действий! Это стало огромным стимулом для дальнейшего развития наших процессов и инфраструктуры.
Авторевью
Давайте вспомним, какие проблемы были при проведении ревью вручную:
занимает много времени;
невозможно отследить глазами выполнение абсолютно всех требований.
Большое количество проверок было просто вынесено в отдельный сервис, который запускается для проверки созданного пакета и выдает свой вердикт о его качестве. Далее ревьюверу остается проверить логи с результатами авторевью и самые критичные требования к объектам из задачи. То есть ревью стало двухфакторным и проходит гораздо быстрее.
Например, на этапе авторевью можно быстро отловить использование в ETL-процессах хардкода вместо макропеременных или же увидеть, что ETL-процесс работает очень долго, поэтому необходимо его оптимизировать.
Рассмотрим основные категории проверок в рамках ревью.
Meta-review
Работа с метаданными объектов хранилища осуществляется в SAS Data Integration Studio. Метаданные физически хранятся на SAS-сервере и представляют собой таблицы атрибутов и таблицу связей — их используем для автоматизации. После внесения разработчиком изменений в метаданные, происходит запрос на SAS-сервер по объектам, которые были затронуты доработкой.
По названию объектов выстраиваются связи и находятся необходимые для анализа атрибуты в виде таблиц, которые, в свою очередь, подвергаются проверкам на предмет соответствия стандартам разработки. Под стандартами разработки в данном случае можно понимать соответствие объектов внутренним соглашениям по разработке, особенности работы с GP, особенности работы связанных систем. В результате работы авторевью пользователь получает отчет со списком выявленных проблем.
Package-review
Результат разработки — опубликованный в VCS релиз-пакет, который содержит в себе все файлы, необходимые для установки задачи, а также файлы, свидетельствующие о корректности разработки.
Package-review запускается для проверки наполнения релиз-пакета. Проверяется наличие всех необходимых файлов, соответствие конфига и содержания пакета, корректность создания или изменения физической структуры объектов, производится парсинг скриптов, сопоставление объектов, дорабатываемых в скриптах, с объектами метаданных. В результате работы package-review пользователь получает отчет со списком объектов релиз-пакета, не прошедших проверки, и рекомендации по устранению проблем.
Diff-review
Запускает python-скрипт, выполняющий сравнение деплоев джобов до и после разработки и создающий diff-файлы.
Log-review
Выполняет проверку логов в пакете.
Автотесты
На крупных проектах в целях автоматизации тестирования пишутся собственные тестовые фреймворки, и наш проект не исключение. На связке python + pytest создан наш тестовый фреймворк, позволяющий:
Запускать автотесты на всех объектах по задаче.
Выполнять часть тестовых проверок на лету, запуская самописные тестовые функции.
Формировать итоговый отчет с результатами тестирования в Allure.
У запуска автотестов есть особенность: их перечень зависит от объектов тестовой задачи. Например, при создании нескольких абсолютно новых ETL-процессов интеграционные проверки запускаться не будут, поскольку в хранилище еще нет никаких зависимостей от этих процессов. И наоборот: при доработке существующих процессов будут запускаться интеграционные проверки.
Какие виды тестов во фреймворке существуют?
Static — включают проверки хардкода, корректности метаинформации и настроек инкрементальной загрузки ETL-процесса.
BI — проверяют зависимости в SAP BO юниверсах.
Интеграционные тесты — проверяют возможные ошибки в зависимых ETL-процессах хранилища и в важных отчетах.
Work — проверяют что корректно отработала инкрементальная загрузка новых/измененных данных из источников, обновились данные и так далее.
Интеграционное тестирование
В этом направлении мы совершили огромный прорыв и очень им гордимся.
Итак, интеграционное тестирование прошло следующие этапы:
Ручной запуск всех зависимых процессов на тестовом контуре.
Вынесение части проверок в авточекер и выполнение их автоматически.
Расширение перечня автопроверок и переход к накату на тест только метаинформации.
Апогеем этой эволюционной лестницы стал полный отказ от интеграционного контура. Почему это удалось?
Вместо инстанса тестового контура для подтягивания всех зависимостей стали использовать специальную платформу MG (наша внутренняя разработка), содержащую метаданные хранилища, а также описывающую логическую и концептуальную модели хранилища.
Интеграционные тесты стали отрабатывать уже во время наката задачи на vial, то есть на более раннем этапе мы можем посмотреть на итоги интеграционных проверок и обнаружить ошибки.
Так мы победили ненавистные синхронизации и избавились от теста, тем самым чуть разгрузили тестовый контур (привет нашим DB-админам и спасибо им за терпение), сделали тестовое окружение более доступным — нет больше потерянных дней тестирования из-за проблем с синхронизацией.
Попутно были достигнуты следующие результаты:
Влияние человеческого фактора на итоги интеграционного тестирования уменьшилось в разы.
Время интеграционного тестирования сократилось на 80—90%.
Качество самих интеграционных проверок улучшилось за счет максимально актуальных данных.
Качество проверок улучшилось, потому что на тесте не всегда были актуальные данные, да и зависимости в BI и важных стратегических отчетах ранее мы не могли проверить, а с приходом автоматизации это стало реальным.
Выполнение проверок на лету
Кроме автотестов, написанных на python, мы также используем набор самописных SQL-функций, позволяющих быстро и эффективно проводить самые важные проверки качества данных.
Какие функции у нас есть?
ddl(‘имя_таблицы’) — возвращает DDL-скрипт создания таблицы, используемый для проверки корректности метаинформации и соответствия ее ТЗ.
profile(‘имя_таблицы’) — сводный отчет наполняемости таблицы (насколько заполнено каждое поле таблицы, какие уникальные значения есть в различных полях и т. д.).
dq_check(‘имя_таблицы’, ‘ключ’) — позволяет определить, сколько дублей и NULL есть в ключевых полях таблицы, а также выявить проблемы версионности.
compare_(‘таблица1’, ‘таблица2’, ‘ключ’) — самый основной инструмент, выдающий результаты сравнения двух таблиц.
Compare() показывает, сколько столбцов и строк в каждой таблице, сколько строк сджойнилось и в каких столбцах были обнаружены расхождения для сджойненных записей.
Ниже показано, что все записи из первой и второй таблицы (12 987 767 234 строки) сджойнились, но по полю order_id были обнаружены расхождения в 9 458 234 строках.

Пример результата функции compare()
Если такое расхождение и предполагалось получить в результате доработки ETL-процесса — все хорошо, если же оно неожиданно — это повод для обсуждения с аналитиком и разработчиком.
При помощи функций compare() выполняются сравнения с прототипом и бэкапом. Они позволяют сравнить: полностью все таблицы, только актуальные версии записей или же отдельные партиции (для больших партицированных таблиц).
Тест-кейсы в Allure
В Allure тест-кейсы создаются автоматически и динамически, отталкиваясь от особенностей проверяемых объектов, так же, как тесты, о которых я писал выше. Кроме того, ряд проверок выполняется на лету в процессе наката задачи на vial, а их результаты сразу записываются в тест-кейсы.
Пополнение базы автотестов
Наша база автотестов постоянно расширяется, в том числе за счет обнаруженных при тестировании дефектов. У нас выстроен процесс заведения и анализа багов с дальнейшим созданием задач как на написание автотестов, так и на добавление проверок в авторевью. Дефекты для удобства анализа и получения статистики делятся на несколько категорий: на каком этапе процесс дал сбой, какие объекты были с дефектом и т. д.
Разработка собственных допсервисов
Помимо написания самих автотестов наша команда разрабатывает различные сервисы на python, поддерживающие общую QA-инфраструктуру и позволяющие сделать процесс автоматизации более гибким, удобным и прозрачным.
Разработка
Ранее в статье я упомянул проблему блокировки всех пользователей при выполнении операций с метаинформацией. Все такие операции выстраивались в очередь, и пока очередь не опустеет — пользователи с метой работать не смогут.
Эта проблема затрагивала не только QA-инженеров, но и самих разработчиков. И для ее решения было предложено использовать отдельные метасерверы. На них с помощью плейбуков разработчики готовят окружение, разрабатывают свои задачи и проводят первичную проверку результата.
Далее задача отправляется согласно установленному flow.
Проблемы на данном этапе
Из оставшихся проблем были решены:
Необходимость в синхронизации продуктового и тестового контуров — отпала после перехода на vial и автоматизацию интеграционного тестирования.
Ручное ревью пакета — решено после введения авторевью. Полностью избавиться от ручного ревью не получится, но механизм авторевью значительно разгрузил сотрудников.
Имеется целых три тестовых контура — теперь для тестирования используется только связка vial/live, причем live — лишь для некоторых задач.
Для тестирования интеграции требуется отдельный контур — контур больше не используется.
Недоступность операций с метаинформацией при возникновении очереди (изначально выделена не была, но по ходу статьи упоминалась) — к сожалению, пока не решена.
Таким образом, из списка проблем, которые упоминались в самом начале статьи и добавлялись по ходу, осталась нерешенной только одна — блокировка меты при одновременной работе.
Но разработчики уже решили эту проблему в своем окружении, а в планах — решить ее и применительно к QA.
Дорога к светлому будущему
Мы уже многое сделали для улучшения нашей работы, но нам еще многое предстоит.

Будущее — прекрасное далеко
Какие же наши основные задачи?
Переход авторевью в разработку и поддержку на стороне QA.
Тестовые контуры переходят в зону ответственности QA — в команду QA нанимается SRE.
Тестирование на отдельных метасерверах.
Разработка новых сервисов автоматизации.
Тестирование на отдельных метасерверах позволит избавить от зависаний меты на vial, но не все сразу. Впрочем, мы обязательно это сделаем.
А что касается новых сервисов автоматизации, то сейчас мы занимаемся написанием статистического анализатора результата регресса, анализатора корректности эталонного SQL-кода (этот код поддерживает в актуальном состоянии системный аналитик), на основе которого разработчики создают ETL-процессы, а также автоматизацией тестирования инкрементальной загрузки.
Заключение
Непрерывное улучшение качества продуктов, данных и процессов очень важно для нашей группы компаний. И на примере управления хранилища данных была показана эволюция QA в срезе автоматизации процессов и инструментов.
Шаг за шагом мы двигались в сторону автоматизации, целью было уменьшение количества ручных действий в процессах и фокусирование внимания сотрудников на анализе ошибок, сложных кейсах тестирования и повышении собственной экспертизы.
В самом начале своего пути мы делали вручную практически все: от разворачивания тестового окружения и до интеграционного тестирования. Но со временем на каждом этапе процесса появлялась возможность ускорить работу и повысить ее эффективность за счет использования новых инструментов.
Слаженная работа команд разработки и тестирования в DWH позволила уверенно двигаться в сторону автоматизации, и со временем процессы внутри управления кардинально поменялись.
Вот что было сделано:
Автоматизировано большое количество действий, выполняющихся ранее вручную: сбор пакетов, накат/откат задач, ревью, большая часть тестов и т. д.
Разработаны внутренние сервисы для ускорения и повышения эффективности работы с хранилищем: портал автоматизации, авторевью, автотесты и т. д.
Процессы непрерывно улучшаются за счет пополнения базы тестов, повышения стабильность автотестов.
Результаты показывают, что наша экспертиза позволяет нам и дальше двигаться в сторону повышения эффективности рабочих процессов.
Кроме того, QA наращивают техническую экспертизу за счет расширения обязанностей, взятия на себя все большего числа сервисов в поддержку и разработку. У нас много планов, и мы их обязательно реализуем. А о результатах расскажем в новых статьях.
Для настройки создадим репозиторий на gitlab. Добавим файл .gitlab-ci.yml с текстом:
Файл .gitlab-ci.yml содержит набор инструкций для исполнения экземпляром gitlab-runner
Далее необходимо будет указать секретные переменные (те что начинаются с %secret) и зарегистрировать runner на машине с доступом к продуктовой базе
Настраиваем секретные переменные
ключ - secret_ib_file, значение d:\bases\trade\1cv8.1cd
ключ - secret_ya_path, значение /stages/trade/
Имена ключей в Secret variables указываются без %

Так же есть переменная secret_ya_token значение которой необходимо получить из
далее указываем какие права будут у нашего приложения

Рекомендую создать еще одно приложение, со всеми правами только без Запись в любом месте на диске и использовать его токен для развертывания.
Регистрируем runner
В разделе Runners settings
1. Отключаем общие раннеры, они нам не нужны. Нажимаем кнопку Disable shared Runners

2. Копируем токен для раннера, он будет нужен при регистрации

Наконец то регистрируем раннер
1. Создаем папку на диске, например C:\GitLab-Runner. Рекомендую для использования нескольких раннеров сделать основную папку GitLab-Runners и в ней подпапки с именами раннеров C:\GitLab-Runner\TradePrepareStage например
2. Загрузите двоичный файл для amd64 и поместите его в созданную вами папку. Переименуйте двоичный файл в gitlab-runner.exe.
3. Запустите командную строку с правами Администратора
По умолчанию, служба регистрируется как gitlab-runner. Лучше дополнительно указать имя службы, за место верхней инструкции выполнить:

После запуска можно зайти в задание и следить за результатом выполнения

После успешного выполнения, в каталоге Диска должна появиться выгрузка базы.
При выполнении команды putyadisk выводится ошибка о том что каталог уже создан, так же при повторном выполнении задания выводится ошибка, что и закачиваемый файл имеется на Яднекс.Диске.
Для повторной выгрузки файла пока что необходимо предварительно удалить ранее созданную выгрузку на сегодняшний день.
Заключение
В итоге мы получаем возможность забрать копию рабочей базы через веб-интерфейс gitlab, когда нам это необходимо. Почему gitlab?
Трудности, с которым сталкивается бизнес в процессе адаптации ПО под себя
И прежде чем мы приступим непосредственно к теме нашей беседы, давайте вспомним о том, с чем сталкиваются практически все пользователи, практически любой бизнес, когда речь заходит о внесении изменений в рабочую конфигурацию.
История становления командной разработки в нашей компании. Как мы жили, когда были маленькие, и с чем сталкивались в процессе роста?
Какие виды групповой разработки могут быть, через что прошли мы.
- Это – ручная сборка конфигурации, чем занимаются практически все, кто сталкивается не только с групповой, но и вообще с разработкой в 1С.
- Это – использование хранилища конфигурации в различных его модификациях.
- И, поскольку мы не стоим на месте, движемся вперед, хотим развиваться, задействовать новые инструменты, то следующий этап, который мы планируем внедрять – это применение в разработке ПО системы контроля версийGIT.
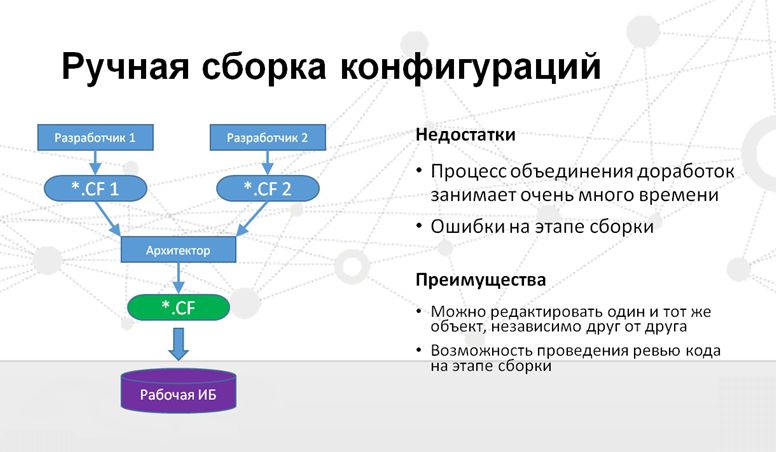
Когда пять лет назад я пришел в компанию, не было департамента ИТ, был только небольшой ИТ-отдел из 5 человек. Это был просто отдел разработки. Никакого хранилища тогда не было, конфигурации собирались вручную – один или два разработчика конфигурационных единиц выполняли какие-то доработки, и вносили в конфигурацию новую функциональность. Потом либо эти доработки переносились в рабочую конфигурацию, либо изменения различных специалистов сверялись и объединялись, и уже результат объединения с помощью файла конфигурации натягивался на рабочую базу. Всё вручную!
Конечно же, у такого подхода были существенные недостатки:
- Во-первых, это время, которое должен затратить исполняющий обязанности архитектора на сверку всех изменений, и их консолидацию.
- И это – высокая вероятность внесения ошибки самим архитектором, даже если каждый разработчик выполнил свою часть работы идеально.
Но у такого подхода есть и свои преимущества.
- Это, во-первых, возможность редактирования одного объекта конфигурации одновременно несколькими разработчиками (то, чего мы лишены при использовании хранилища).
- И это – возможность проведения рефакторинга, ревью кода, его инспекции на этапе сборкирезультата разработки самим архитектором.
Но такая схема у нас просуществовала недолго. Как только на одной конфигурации появился третий разработчик, времени на консолидацию этих разработок стало затрачиваться неимоверно много, процент ошибок резко пополз вверх. Естественно, нужно было что-то менять. И мы приступили к использованию хранилища конфигурации в групповой разработке.
Роль хранилища конфигурации 1С в групповой разработке. Его плюсы и минусы.

Я думаю, не стоит повторяться и подробно объяснять, что такое хранилище – это и так все знают. Хранилище – это полезный инструмент для групповой разработки от фирмы 1С.
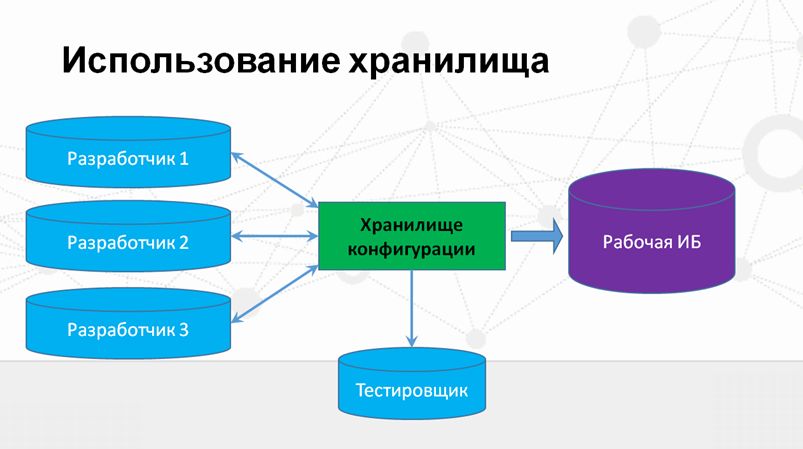
Схема использования хранилища выглядит примерно так, как показано на слайде. Это – классический подход, когда:
- К одному хранилищу подключено несколько информационных баз разработчиков.
- Также к этому же хранилищу подключается тестировщик, который в определенный момент времени забирает изменения из хранилища и тестирует разработанную функциональность.
- Затем файл конфигурации выгружается из хранилища, и архитектору остается только загрузить эти изменения, эту готовую разработку уже в рабочую базу.
Но и эта схема просуществовала недолго. Потому что очень быстро выявились ее существенные недостатки.
- Один из главных – это невозможность синхронизировать работу разработчика и тестировщика. Даже если разработчик с тестировщиком договорятся, в какой момент времени нужно забрать конфигурацию из хранилища на тестирование, то к тому времени, когда тестировщик спохватится это сделать, кто-то из разработчиков может уже успеть поместить туда изменения, относящиеся уже к последующим задачам.
- И в результате может возникнуть ситуация, что непротестированные изменения, а уж тем более изменения с ошибками попадут в рабочую информационную базу и нарушат работу бизнеса.
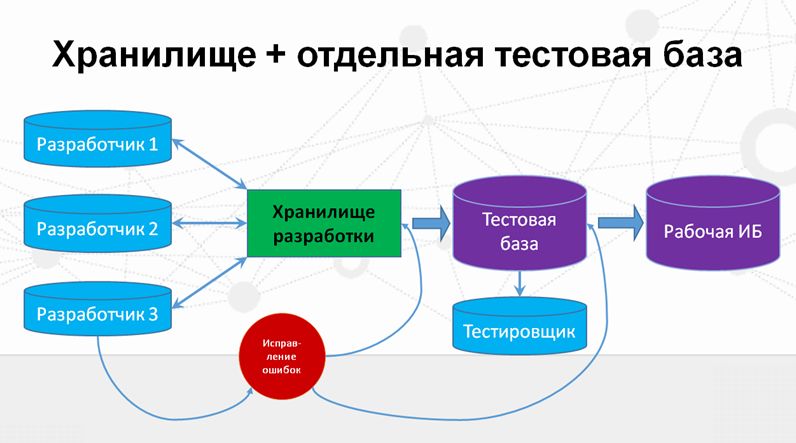
Поэтому следующим шагом было решено вынести тестовую базу из цикла разработки.
Такая схема оказалась достаточно успешной, мы на ней проработали достаточно долго (больше двух лет). Свои слабые стороны она начала показывать, когда разработчиков стало достаточно много, и тестировщиков на одной конфигурационной единице стало больше одного.
Долго так продолжаться не могло, поэтому было принято решение что-то поменять.
Ну и прежде, чем перейти к тому, к чему мы пришли на сегодняшний день, давайте подытожим те преимущества и недостатки, которые предоставляет нам использование классической схемы хранилища конфигурации.
Итак, преимущества:
- Первое – это то, для чего собственно и разрабатывался такой полезный механизм, как хранилище конфигурации, это – обеспечение целостности структуры конфигурации в любой момент времени.
- Также в хранилище есть очень полезная возможность в любой момент времени откатиться к предыдущей версии в случае ошибки.
- Полное отсутствие необходимости сверки, консолидации трудов различных специалистов. Хранилище конфигурации само прекрасно справляется с этой задачей, на это время уже тратить не нужно.
Ну и недостатки, с которыми мы столкнулись:
- Это невозможность одновременной работы с одним объектом конфигурации двум программистам. Это ограничение, которое накладывает само использование хранилища конфигурации – ради повышения качества разработки приходится идти на такую жертву.
- Это – трудность синхронизации работы разработчика и тестировщика.
- И отсутствие ревью и инспекции кода. Этот процесс при использовании хранилища уже нужно организовывать какими-то отдельными инструментами, какими-то дополнительными процессами в команде.
Организация цикла разработки ПО, взаимодействие специалистов различных сфер деятельности.
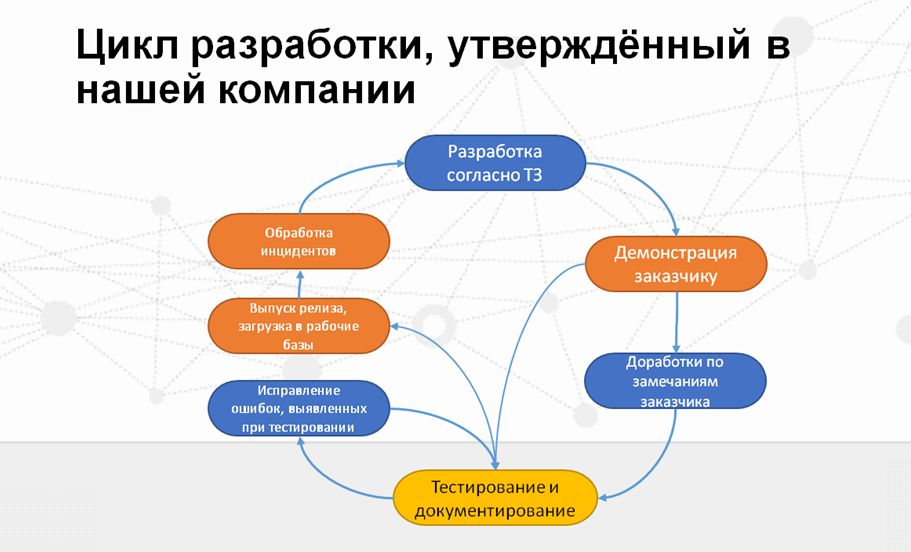
Говоря о каких-то технических моментах, мы неизбежно опираемся на то, как взаимодействуют люди, потому что техническая сторона дела отражает то, как налажен этот процесс в команде.
- Процесс разработки у нас циклический, где цикл разработки и релизного планирования занимаетодну неделю. В течение этого периода выполняется доработка ПО согласно техническим заданиям, согласованным с заказчиком.
- После того, как разработка выполнена, программист в своей конфигурации, еще не помещая изменения в хранилище, демонстрирует результаты заказчику. И заказчик либо принимает эти изменения, либо вносит какие-то свои замечания, коррективы.
- Разработчик учитывает эти замечания, исправляет их, и эта результирующая функциональность передается на тестирование.
- Параллельно с этим запускается процесс технического документирования результатов доработки – в работу включается технический писатель.
- В это же время осуществляется циклическое взаимодействие разработчика и тестировщика по отлаживанию переданного на тестирование релиза, по выявлению и исправлению ошибок.
- И после того, как все доработки успешно протестированы, готовый релиз помещается в рабочую конфигурацию.
- Конечно, от всех «жучков» избавиться невозможно, поэтому также существует отдельный цикл по обработке инцидентов и избавлению от тех багов, которые не были выявлены ни во время разработки, ни на этапе демонстрации, ни в процессе тестирования.
Что если использовать несколько хранилищ? Как это помогает и вредит?
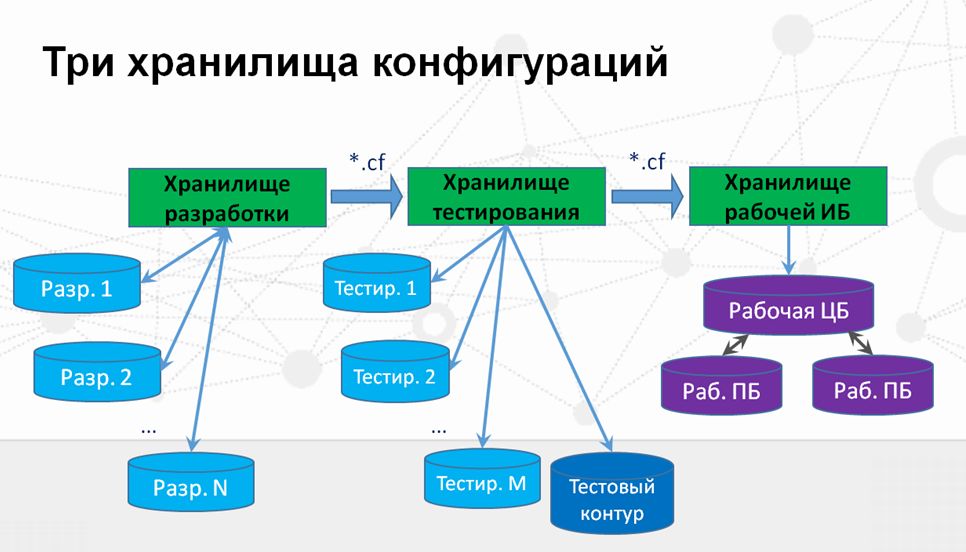
Наконец о том, как технически реализован цикл групповой разработки в нашей компании на сегодняшний день.
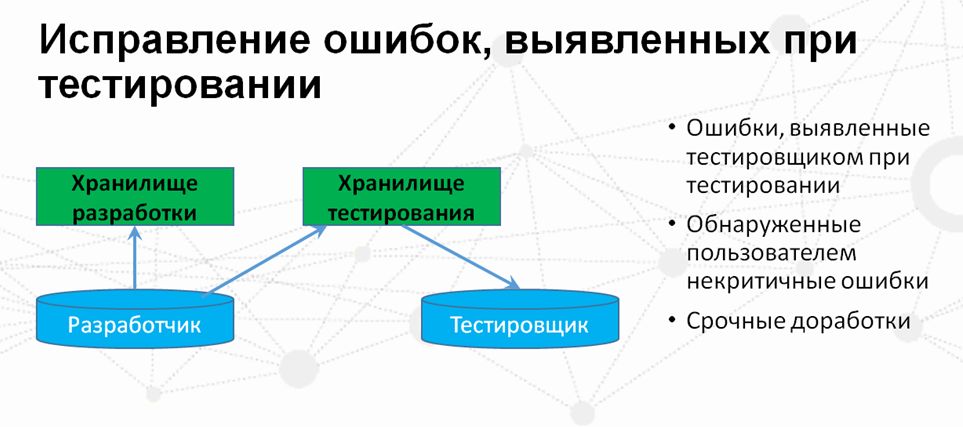
Немного слов о том, как решаются различные коллизионные ситуации.
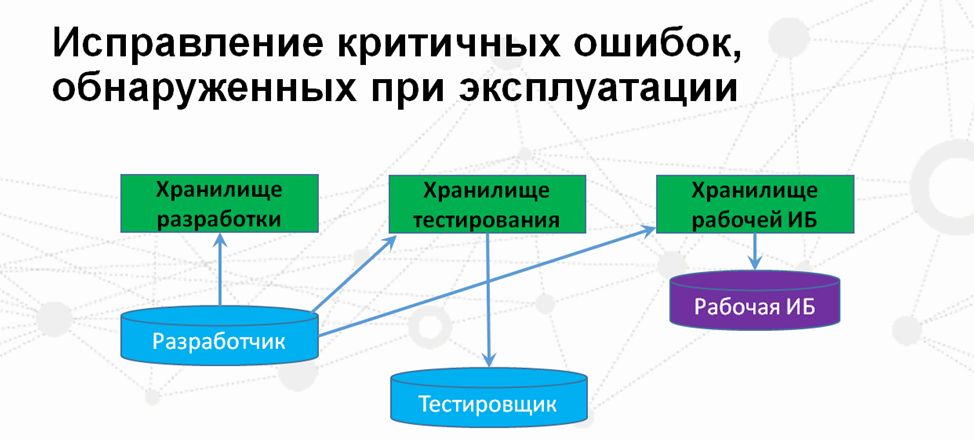
- Когда у нас появляются срочные заявки, когда заказчик не готов ждать две недели, ему эти изменения надо получить срочно – их исправления вне очереди передаются на тестирование и после тестирования сразузагружаются в хранилище рабочей базы.
Какие очевидные недостатки есть у этой схемы:
- Как видите, если у нас в рабочей базе появляются какие-то критичные ошибки, ситуация немного осложняется тем, что разработчику приходится помещать изменения сразу в три хранилища конфигурации. Почему я говорю «приходится»? Потому что существенным недостатком такой схемы является то количество времени, которое тратится на работу с несколькими хранилищами.
- И еще один минус – это возможность внесения ошибок, даже на этом этапе, когда разработчика что-то или кто-то отвлекает, он поместил изменения в одно хранилище, но забыл поместить в другое. В рабочей базе либо на следующей неделе, либо через две недели может не оказаться исправления данной ошибки.
В чем плюсы такой организации работы?
- Существенный плюс заключается в том, что благодаря хранилища у нас есть контроль истории изменения конфигурации (кто, что и когда менял) для любой базы, в любой момент времени.
- Также преимуществом является возможность тестировщикам и разработчикам иметь свои собственные конфигурации, свои собственные тестовые данные, не мешая друг другу работать в отдельной базе.
А если говорить про недостатки:
Организация тестового контура информационных баз для тестировщика и заказчика.

Вернемся к тому «Тестовому контуру», который у нас подключен к тестовому хранилищу наряду с базами тестировщиков. Что это такое?
Тестовый контур – это полная имитация (я бы даже сказал клон) той среды, которая развернута для реальной работы – на таких же серверах, с такими же операционными системами, службами и т. д. Ну и, естественно, туда подключены точно такие же базы 1С, более того, это – копии реальных рабочих баз, которые периодически обновляются.
Тестовый контур полностью изолирован от рабочей среды, чтобы тестовые базы не стали обмениваться своими данными с рабочими базами, а задействованы могут быть самые различные обменные процессы, не только "конвертация".
Каковы цели организации тестового контура?
- Во-первых, это – возможность протестировать любую задачу, провести любое нагрузочное тестирование любым пользователем – будь то аналитик или заказчик.
- Поскольку тестовый контур подключен к тестовому хранилищу, заказчик может посмотреть уже на этом этапе, что он получит в результате, когда новая функциональность будет загружена в его рабочую базу. Причем, на своих же реальных рабочих данных, которые он хорошо знает, с которыми он работает.
- Также существенный плюс тестового контура – это безопасность рабочих данных. Полностью оценив масштаб трагедии какой-то тестовой задачи, которую мы крутим на тестовом контуре, мы можем оценить, насколько она ресурсоемка, затратна по времени, может ли она заблокировать работу пользователя. Все это мы можем проверить в тестовом контуре, абсолютно не мешая при этом работе пользователей и не нарушая целостности их рабочих данных.
- Пользователем тестового контура может быть кто угодно, не только программисты и тестировщики, но также аналитики, заказчики, системные администраторы. Ведь настройки сети, имена компьютеров также в точности повторяют рабочую среду.
Дальнейшие планы по улучшению качества продукта. Какие еще инструменты и технологии можно задействовать?
Мы двигаемся дальше и не собираемся останавливаться на достигнутом, продолжаем бороться с теми трудностями, с которыми сейчас сталкиваемся, и продолжаем повышать качество результатов разработки.
- Во-первых, мы планируем внедрение системы контроля версий;
- А еще, спасибо фирме 1С, мы собираемся использовать в разработке новый полезный механизм расширений конфигурации. Он особенно интересен после выхода платформы 8.3.9, когда в расширениях нам стало доступно изменение уже абсолютно любых модулей. Использование этого механизма нам видится очень перспективным, потому что оно хорошо подходит к специфике организации нашего бизнеса.
Как происходит тестирование, исправление ошибок, разработка внешних отчетов/обработок и правил обмена в крупной компании при интенсивном использовании ПО?

В заключение расскажу о некоторых фишках, которые мы также используем в своей работе.
Желаю всем качественного результата и довольного заказчика!
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2016 DEVELOPER. Больше статей можно прочитать здесь.
В 2020 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2020 в Москве.

в появившемся окне контроля учетных записей
Как этим пользоваться?
- Нажмите на кнопку Начать диагностику.
- После завершения диагностики выберите Выполнить рекомендуемые действия. Откроется окно автоматической установки и настройки компонентов.
- Рекомендуем поставить флажок Выбрать все.
- Нажмите на кнопку Начать установку и настройку.
может привести к неработоспособности системы. В соответствии с эксплуатационной документацией
сертифицированное СКЗИ КриптоПро CSP 4.0
не предназначено для функционирования в среде Windows XP . Для стабильной работы КриптоПро CSP необходимо удалить ViPNet CSP,
после чего перезагрузить компьютер и вновь пройти диагностику. В соответствии с эксплуатационной документацией
сертифицированное СКЗИ КриптоПро CSP 5.0 не предназначено
для функционирования в среде macOS 10.15 Catalina .
С 1 января 2020 года возможно использование только КриптоПро CSP 4.0 и выше.
Для работы этих версий КриптоПро CSP на серверных версиях Windows
необходимо приобрести и активировать серверную лицензию
в течение 90 дней , для этого обратитесь в сервисный центр .
Согласно уведомлению Минкомсвязи России использование сертификатов
по ГОСТ Р 34.10-2001 после 31 декабря 2019 года не допускается.
Работа с сертификатами по новому ГОСТ Р 34.10-2012 возможна
только в КриптоПро CSP версии 4.0 и выше.
Для работы с сертификатами без встроенной лицензии на серверных
версиях Windows необходимо приобрести и активировать серверную
лицензию для КриптоПро CSP.
Сертификаты без встроенной лицензии
| Установить КриптоПро CSP 4.0 R4 | Отложить установку |
1. Настоящие условия предназначены для обязательного ознакомления пользователями Контур.Веб-диска и иными лицами, ссылающимися или иным образом использующими страницу, на которой размещены настоящие условия.
4. Контур.Веб-диск может использоваться клиентами группы компания СКБ Контур согласно условиям заключенных ими договоров, а также иными пользователями исключительно для проверки и настройки своего рабочего места.
5. Не допускается использовать Контур.Веб-диск путем распространения информации о Контур.Веб-диске третьим лицам с целью извлечения любой коммерческой выгоды, в том числе с целью снижения собственных расходов вследствие отсутствия необходимости разрабатывать и поддерживать решение, аналогичное или схожее по функциональности с Контур.Веб-диском. Использование Контур.Веб-диска, если такое использование осуществляется без согласия правообладателя, является незаконным и влечет ответственность, установленную действующим законодательством (п. 1 ст. 1229 Гражданского кодекса РФ).
Читайте также: