
Сколько ресурсов браузер может одновременно загружать с одного домена
Примечание: ниже расположен перевод заметки "Browser Page Load Performance" от John Resig, в которой он рассматривает тестовое окружение от Steve Souders для анализа клиентской производительности браузеров. Мои комментарии далее курсивом.
Steve Souders много внес в улучшение производительности браузеров при загрузке страницы и клиентской оптимизации более, чем кто-либо. Во время своей работы в Yahoo! он отвечал за YSlow (великолепный инструмент для измерения производительности вашего сайта) и написал книгу, посвященной улучшению производительности веб-страниц — High Performance Web Sites. Сейчас он работает в Google, но по-прежнему занимается тем же самым: делает загрузку веб-страниц чуточку быстрее.
Я был восхищен выходом одного из его новых проектов — UA Profiler (проект стартовал достаточно давно, но хороших обзоров его работы пока не было). Этот инструмент можно запустить в вашем браузере, чтобы выяснить его текущие возможности касательно клиентской производительности, которые так или иначе ограничивают в нем скорость загрузки страниц.
Давайте взглянем на следующую таблицу:

на ней хорошо видно, что лидирует Firefox 3.1, имея 9 из 11 потенциальных возможностей для ускорения загрузки страницы. В Firefox 3, Chrome и Safari 4 присутствует всего 8 из этого списка. Firefox 2, Safari 3.1 и IE 8 являются следующими по списку с 7 выполненными тестами. Эти цифры могут помочь оценить общую производительность браузеров при загрузке страницы. Естественно, что все эти тесты не затрагивают особенностей рендеринга страницы или JavaScript-производительность: их козырной картой является производительность сетевого соединения (CSS-производительность была подробно рассмотрена ранее в соответствующем цикле статей, который привел к некоторым практическим аспектам ее применения).
Информация о качестве использования сетевого соединения важна по двум причинам:
- Она позволяет производителям браузеров узнать качество их продукта в этом аспекте. Если производители улучшат какие-либо из заявленных показателей, это выльется в более быструю загрузку страниц в их браузере.
- Она позволяет веб-разработчикам верно выставить приоритеты и обозначить те проблемы, с которыми они столкнутся при создании сайтов. Например, если они поддерживают браузер, который не поддерживает (каламбур просто получается) параллельную загрузку файлов стилей, то, возможно, их сайт нужно видоизменить для улучшения производительности.
Тесты могут быть разбиты на несколько категорий (Steve подробно объясняет такую классификацию в FAQ):
Сетевые соединения
В основном, тестируются две вещи: число одновременных соединений к одному хосту (поддомены расцениваются как отдельные хосты) и сколько соединений можно открыть ко всем хостам одновременно. Эти числа являются хорошим индикатором, каково возможное число параллельных соединений (это обычно влияет на число одновременно загружаемых картинок).
Дополнительно проверяется, поддерживает ли браузер gzip -сжатие. Результаты не слишком впечатляют: все современные браузеры на данный момент поддерживают сжатие.
Параллельные загрузки
Все браузеры способны загружать изображения в параллельном режиме (несколько изображения загружаются одновременно) но что насчет других ресурсов (таких как стили и скрипты)?
К несчастью, добиться параллельной загрузки файлов скриптом и стилей гораздо сложнее, потому они могут очень сильно изменить содержание (и внешний вид) всей остальной страницы. Появление этих компонентов на странице происходит в несколько в этапов:
- Загрузка (может быть параллельной)
- Анализ
- Исполнение
Поэтому загрузки этих файлов блокирует друг друга (напоминая игру в «камень-ножницы-бумага»): скрипты блокируют анализ и исполнение других скриптов, стили блокируют анализ и исполнение скриптов.
Для браузеров тяжело добиться параллельной загрузки скриптов, поскольку скрипты могут изменять содержание страницы и удалить или добавлять новые скрипты или таблицы стилей. Исходя из этих соображений, браузеры пытаются добиться лучшей производительности, предвосхищая ситуацию, анализируя документ и предварительно загружая стили и скрипты — даже если их реальное использование будет отложено.
Изменения в этой области позволят значительно улучшить клиентскую производительность. Можно смело сказать, что это по-прежнему самая нетронутая область для оптимизации (и именно она больше всего беспокоит сейчас фронт-енд архитекторов).
Кэширование
Абсолютно то же самое происходит в случае кэширования статических файлов, например, таблиц стилей, картинок или скриптов. Поскольку такие редиректы происходят гораздо чаще (и один из аспектов оптимизации как раз связан с устранением таких редиректов), то со стороны браузеров кэширование любого производимого действия выглядит гораздо критичнее для производительности.
Пред-вызов (prefetching)
Пред-вызов является частью спецификации HTML 5 и позволяет определить ресурсы на странице, которые нужно загрузить «на будущее», поскольку они могут потребоваться при дальнейших действиях пользователя (распространенным примером будет динамическая смена изображений).
Хотя существует целая страниц, посвященная использованию данного подхода на сайте разработчиков Mozilla, но его применение гораздо проще, чем может сперва показаться. Это так же просто, как добавление новой ссылки наверх вашего сайта:
И все необходимые ресурсы будут предварительно загружены (без использования JavaScript)!
Встроенные изображения
Заключение
Можно совершенно точно утверждать, что наличие таких публичных проектов, как UA Profiler будет поощрять создателей браузеров быстрее реагировать на изменения в клиентских технологиях и внедрять критический с точки зрения производительности функционал.
Как было замечено дальше в комментариях, Steve является автором еще Cuzilion — моделирования загрузки страницы при использовании различного количества различных файлов — и дополнения к Firefox Hammerhead — позволяющего замерять и запоминать время загрузки для выбранных сайтов.
Большинство разработчиков сайтов уже знают, что число соединений к серверу у браузеров лимитированно. Старые версии браузеров используют только два соединения на сервер, более свежие побольше (например, «Опера» 11.10 — аж 16).
В общем случае алгоритм использования этих соединений достаточно сложен и отличается от браузера к браузеру (имеется ввиду будут ли параллельно загружаются стилевые таблицы, скрипты и прочее), но общее правило неизменно — больше своего лимита браузер соединений к серверу не плодит.
Между тем, это не всегда хорошо, ведь если все соединения заняты, то браузер ждёт данных по ним, не инициируя новые, даже если канал до сервера позволяет загрузить что-то ещё.
Если сайт и канал вполне выдержат и большее количество соединений от одного пользователя (с учётом посещаемости), то есть хитрость, которую часто используют — загружать статику (картинки, файлы стилей и прочее) с других доменов. Их не обязательно располагать на других серверах, достаточно дать одному серверу несколько имён и использовать их для загрузки.
Хорошо, когда есть возможность завести любое количество доменов какого-нибудь уровня на своём хостинге. Далеко не все хостеры предоставят такую возможность бесплатно, а простому блогеру платить за ещё одно имя только ради ускорения загрузки вряд ли захочется.
Мои эксперименты (проверял на сервисе BrowserShots, операционные системы Linux, Windows XP, Mac OS X) говорят о том, что браузеры умеют с ними работать, то есть картинки с URL, где имя домена кончалось на точку, грузились нормально.
Для того, чтобы проверить считают ли браузеры домены с точкой в конце и без различными, я создал небольшой скрипт, который отдаёт картинку без кеширования с секундной задержкой.
В эксперименте я выставил максимальное количество соединений к серверу в единицу («Опера» и «FireFox» позволяют это сделать, где это делается в браузерах на WebKit я не знаю, подскажите, если знаете) и создал две HTML-страницы: одну, где две картинки из моего скрипта грузятся с одного домена, вторую, где одна из них грузится с домена с точкой.
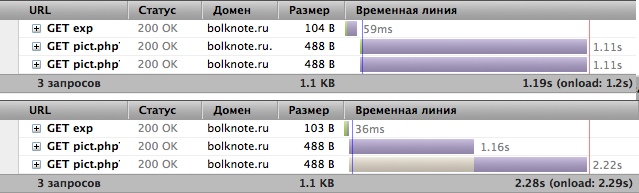 |
На скриншоте хорошо заметен результат и видно где какой эксперимент (по колонке «Домен»). По скриншоту видно, что я использовал хорошо всем знакомый FireBug, но на Dragonfly из «Оперы» картина такая же.
Скорость загрузки сайта – важный пункт технической оптимизации сайта.
Ранее мы уже рассказывали о 12 способах, как увеличить этот показатель в данной статье. В случае если все рекомендации выполнены, а скорость сайта желает лучшего, можно воспользоваться специальными директивами и ресурсными подсказками для браузеров (Resource Hints), чтобы увеличить показатели скорости вашего сайта.
В этой статье будут рассмотрены следующие директивы и ресурсные подсказки для браузеров:
- Preload
- Prefetch
- dns-prefetch
- Preconnect
- Prerender
С помощью этих подсказок мы сообщаем браузеру о ресурсах, которые посетитель сайта может использовать в ближайшее время. Браузер можно обучить обрабатывать указанные ресурсы и сохранять их в локальный кеш. В случае, если это произойдет, процесс загрузки на стороне пользователя будет намного быстрее.
Сразу обозначу, что это не является для браузера прямой инструкцией, а имеет рекомендательный характер.
В случае, если все ресурсы браузера заняты более важным процессом, он спокойно проигнорирует такие подсказки.
Второй важный момент: стоит понимать, что благодаря этим подсказкам скорость по Google PageSpeed не увеличится в разы.
Эти подсказки помогут скорее посетителю сайта и практически не повлияют на оценочные баллы PageSpeed.
Данные директивы относительно недавно появились, поэтому на старых версиях браузеров они не поддерживаются. Если вы хотите их использовать, следует обновить свой браузер.
Версии браузеров, поддерживающие те или иные ресурсные подсказки, можно посмотреть по ссылкам:
Разберемся с директивами по очереди. Предлагаю начать с dns-prefetch.
Dns-prefetch
Сейчас почти на всех сайтах используются сторонние ресурсы, такие как системы аналитики, онлайн-консультанты и прочие. Обработка и поиск нужного Dns браузером занимает какое-то время. Браузер начинает обрабатывать эту информацию в момент обнаружения внешнего ресурса в html-коде страницы.
В такой ситуации нам и поможет подсказка dns-prefetch, с ее помощью мы заранее сообщим браузеру о том, что в дальнейшем будет использоваться внешний ресурс, и вот его адрес. То есть браузер заранее будет знать, к какому dns необходимо обратиться во время загрузки нужного скрипта, что ускорит весь процесс.
Обработка dns-prefetch происходит в фоновом режиме во время просмотра пользователем страницы сайта.
Например, так мы сообщим о том, что надо проверить связь с dns Яндекса.
<link rel="dns-prefetch" href="https://mc.yandex.ru">
Следующая директива preconnect.
Preconnect
Отличается от dns-prefetch тем, что не только ищет указанный днс, но и выполняет обмен пакетами с сервером (клиент -> сервер -> клиент), и тем самым инициирует TCP-соединение с сервером.
TCP (Transmission Control Protocol, протокол управления передачей) – один из основных протоколов передачи данных интернета. Представляет собой поток данных с предварительной установкой соединения. Осуществляет повторный запрос данных в случае их потери, а также устраняет дублирование при получении двух копий одного пакета, гарантируя тем самым целостность передаваемых данных.
TLS (англ. transport layer security – протокол защиты транспортного уровня) – протокол, обеспечивающий защищённую передачу данных между узлами в сети Интернет.
Рассмотрим пример использования preconnect для Яндекс.Метрики:
<link rel="preconnect" href="https://mc.yandex.ru">
Практическое сравнение preconnect и dns-prefetch
Скорость сайта без использования подсказок, TLS-соединение:

Скорость сайта без использования подсказок, TCP-соединение:

Добавим к TLS-соединению подсказки и получим вот такую картину.
TLS-соединение с использованием preconnect:

TLS-соединение с использованием dns-prefetch:

Теперь можно наглядно увидеть различие между dns-prefetch и preconnect: для второго вместе с обращением к dns сразу выполняется обмен пакетами для установки TCP- или TLS-соединения. И в дальнейшем, когда происходит непосредственно обработка скрипта в коде, из цепочки загрузки исключаются эти этапы, что сокращает скорость загрузки.
Как видно из графиков, с помощью подсказок мы заранее сообщаем браузеру о том, что в дальнейшем мы будем использовать внешний ресурс Яндекса, и нужно сразу получить информацию о его dns.
Стоит учесть, что это усредненное значение из выборки тестов, были единичные случаи, когда загрузка происходит быстрее, а также наоборот.
Prefetch
Эта подсказка сообщает браузеру о том, что указанный ресурс может понадобиться пользователю в будущем при перемещении по сайту. Браузер начнет загружать этот ресурс во время простоя, то есть тогда, когда страница уже полностью загрузилась – после загрузки ресурс сохранится в кеше браузера.
Prefetch имеет низкий приоритет среди остальных подсказок, его стоит использовать для ресурсов, которые понадобятся в будущем.
Однако в режиме простоя браузер не будет находиться вечно. Из этого вытекает вопрос, что будет с ресурсами, для которых указана директива prefetch, после того как пользователь перейдет на другую страницу и прервет режим простоя?
Ответ прост: браузер сохранит в кэше загруженную часть и вернется к дальнейшей загрузке снова, используя заголовок Content-Range, когда страница будет полностью загружена.
<link rel="prefetch" as="style" href="/style.css">
С помощью атрибута as указывается тип ресурса. Это помогает браузеру выбрать приоритет загрузки для предварительной выборки.
Также позволяет браузеру понять, совместим ли запрос с политикой безопасности контента в соответствии с атрибутом as. С помощью этого атрибута браузер может посылать подходящие заголовки accept, основываясь на типе ресурса.
Атрибут as может иметь следующие значения:
- audio: аудио файлы <audio>
- document: HTML документ, встраиваемый с помощью <frame> или <iframe>
- embed: Ресурс для встраивания в <embed>
- fetch: ресурс, к которому должен обращаться запрос на выборку или XHR, например, файл ArrayBuffer или JSON
- font: Шрифты
- image: Изображения
- object: Ресурс встроенный в <object>
- script: Скрипты
- style: Стили
- track: WebVTT файлы
- worker: JavaScript код для Web Workers (средство для запуска скриптов в фоновом потоке)
- video: Видео файлы <video>
Нужно иметь в виду, что данная директива во время простоя браузера потребляет трафик. И если пользователь в итоге не обратится к данному ресурсу, этот трафик будет потрачен зря.
Пример из практики использования Prefetch
Допустим, мы знаем, что логотип сайта точно будет использоваться при дальнейшем просмотре. Давайте добавим в код подсказу браузеру о том, что нужно сохранить в кэш это изображение.
Добавим в код страницы:
<link rel="prefetch" as="image" href="https://*sitename*/images/logo.jpg">
Проверим в браузере Google Chrome. Нужно открыть вкладку сеть (network) и найти там соответствующее изображение.
В строке Status Code увидим надпись (from prefetch cache), это означает что изображение закэшировалось и, соответственно, загрузилось из специального Prefetch-кеша.

Preload
Эта подсказка так же, как и Prefetch, служит для предварительной загрузки ресурсов, но имеет более высокий приоритет и используется для текущей навигации пользователя. То есть эта подсказка работает не для будущих страниц, а для страницы, на которой находится пользователь.
Ресурсы, для которых прописана директива Preload, имеют средний приоритет для браузера, и будут загружаться раньше, чем к ним обратится пользователь.
Это полезно для загрузки скриптов и таблиц стилей.
Если необходима предварительная загрузка связей с разрешенными CORS-ресурсами, необходимо добавить атрибут crossorigin.
Cross-origin resource sharing (CORS; с англ. – «совместное использование ресурсов между разными источниками») – технология современных браузеров, которая позволяет предоставить веб-странице доступ к ресурсам другого домена.
<link rel="preload" href="style.css" as="style">
Так же, как и Prefetch, имеет атрибут As, используется для тех же целей.
По истечении 3 секунд после загрузки ресурса, если он не используется, Google Chrome выведет соответствующее предупреждение:

Не стоит использовать Preload для большого количества ресурсов, я бы рекомендовал применять его для предварительной загрузки шрифтов, и не более четырех раз. Чрезмерное использование этой подсказки может негативно влиять на загруженность сервера и соответственно скорость.
Prerender
И в завершении подсказка Prerender. С ее помощью можно предварительно загрузить в кэш браузера целую страницу. Нужно быть уверенным в том, что пользователь точно посетит указанную страницу, так как Prerender является одной из наиболее ресурсопотребляемых директив и может послужить причиной падения пропускной способности, особенно при использовании мобильных устройств.
Происходит следующее: строится полноценная html-страница, затем строится структура DOM-элементов с загрузкой всех скриптов и таблицами стилей. В связи с этим страница при открытии загружается очень быстро.
DOM (от англ. Document Object Model – «объектная модель документа») – это не зависящий от платформы и языка программный интерфейс, позволяющий программам и скриптам получить доступ к содержимому HTML-, XHTML- и XML-документов, а также изменять содержимое, структуру и оформление таких документов.
К сожалению, эту подсказку пока поддерживает наименьшее количество браузеров – Google Chrome и Microsoft Edge последних версий.
Добавление такой подсказки может быть полезно, например, в случае разбиения статей на несколько частей.
Также можно использовать для страниц акций, скидок.
Заключение
С помощью использования ресурсных подсказок и директив можно повысить скорость загрузки сайта на стороне пользователя.
Эти подсказки не создадут существенного прироста по параметрам Google PageSpeed, однако могут быть полезны для пользователей.
Важно понимать, что нет нужды добавлять все подряд в предзагрузку, так как есть вероятность, что предзагруженный ресурс не будет использован, и тем самым вы только усложните код. Нужно иметь четкое представление о том, как пользователь будет себя вести на определенной странице, это поможет правильно использовать подсказку.

Эта статья предназначена для тех, кто любит докапываться до сути всех своих рабочих инструментов. И веб-браузер не исключение. Знаете ли вы, что в процессе загрузки веб-страницы от момента, когда пользователь ввел адрес до фактической загрузки страницы, находящейся по этому адресу, происходит множество процессов. Давайте разберёмся подробнее, как работает веб-браузер, и какие технологии он использует.
Обо всех этих процессах мы поговорим подробнее в нашей статье. Но начать стоит не с этого.
Сетевые модели передачи данных и архитектура браузера
Для объяснения процесса передачи данных по сети используются различные модели. Одной из самых распространённых таких моделей, которая понятна даже людям, далеким от хакерства и IT, считается модель OSI – модель взаимосвязанных открытых систем.

Модель OSI описывает семь слоёв взаимодействия компьютерных систем в сети. Каждый уровень открывает новый уровень абстракции, выше, чем предыдущий, и все они ведут к уровню приложения (браузера), о котором мы будем говорить дальше.
Есть и более старая модель взаимодействия – так называемая TCP/IP. Она точнее описывает процессы, о которых мы говорим в нашей статье. Такая модель используется как для моделирования интернет-архитектуры, так и для установки правил для всех форм передачи данных в сети. Именно к ней мы и будем обращаться в этой статье.
Как мы уже упоминали ранее, все данные, передаваемые приложением, пройдут путь между всеми уровнями модели, нередко не по одному разу (в зависимости от количества посредников в сети). Сегодня это, конечно же, происходит невероятно быстро, но всё же не моментально. Поэтому понимать процесс передачи стоит каждому разработчику.
Ниже мы приводим общую схему такого взаимодействия.

Еще одно понятие, которое поможет вам дальше разбираться в работе веб-браузера – это высокоуровневая архитектура самого браузера. Если описывать кратко, то она состоит из:
Завершая нашу вступительную часть, помните, что описанные здесь модели и архитектура – это очень общая концепция. Не все браузеры следуют моделям OSI/TCP-IP, не у всех архитектура отвечает нашему описанию. А теперь перейдём непосредственно к путешествию нашей веб-страницы.
Шаг 1: Навигация
Итак, далее происходит разрешение веб-адреса - процесс DNS (O RTT). Как это работает?
- Проверяется кэш браузера и ОС.
- Браузер отправляет запрос на распознавание DNS.
- DNS-преобразователь проверяет свой кэш, возвращает ответ, если IP-адрес найден.
- Преобразователь DNS отправляет запрос корневым серверам имен.
- Корневой сервер имен отвечает преобразователю DNS IP-адресом сервера имен TLD.
- Преобразователь DNS отправляет ещё один запрос, теперь на сервер имён TLD, спрашивая, знают ли они, что это за IP.
- Сервер имён TLD отвечает преобразователю DNS IP-адресом полномочного сервера имен.
- DNS-преобразователь отправляет последний запрос авторитетному серверу имен, запрашивая IP.
- Полномочный сервер имен просканирует файлы зон, чтобы найти сопоставление имя домена: ipaddress, и вернёт, существует оно или нет, на преобразователь DNS.
- Наконец, преобразователь DNS теперь ответит браузеру IP-адресом сервера, с которым браузер пытается связаться.
Далее следует установка соединения с сервером (1 RTT). Производится она по принципу «тройного рукопожатия» TCP. Это позволяет установить надёжное соединение, в котором обе стороны синхронизированы (SYN) и опознаны друг другом (ACK). Соответственно соединение производится в три шага: SYN, SYN-ACK, ACK.

Как только соединение установлено, ACK обычно следуют для каждого сегмента. В конечном итоге соединение завершится RST (сбросить или разорвать соединение) или FIN (корректно завершить соединение).
В итоге для сайтов, на которые вы заходите впервые, процесс DNS может занимать целых 4 RTT, в то время, как для уже знакомых страниц он сокращается до 2 RTT.
Шаг 2: Получение
GET - запрашивает информацию с заданного сервера, используя унифицированный идентификатор ресурса (URI). Спецификация правильных реализаций метода GET только извлекает данные и не вызывает изменений в исходном состоянии. Независимо от того, сколько раз вы запрашиваете один и тот же ресурс, вы никогда не вызовете изменения состояния. Есть и другие методы, но нас интересует непосредственно GET.
Шаг 3: Парсинг
Как только браузер получил ответ сервера, он начинает парсить полученную информацию. Этот процесс необходим для преобразования данных в деревья DOM и CCOM, на основании которых рендерный движок затем создаст изображение сайта на экране.
Объектная модель документа (DOM) - это внутреннее представление объектов, которые составляют структуру и содержимое документа разметки (в данном случае HTML), только что полученного браузером. Он представляет собой страницу, поэтому программы могут изменять структуру, стиль и содержимое документа.
Объектная модель CSS (CSSOM) - это набор API-интерфейсов, позволяющих манипулировать CSS из JavaScript. Вкратце: это тот же DOM, но для CSS, а не для HTML. Он позволяет пользователям динамически читать и изменять стиль CSS. Он представлен очень похоже на DOM в виде дерева и будет использоваться вместе с DOM для формирования дерева рендеринга, чтобы браузер мог начать процесс рендеринга.
Что же происходит дальше? А дальше браузер начинает строить дерево DOM. Анализ HTML включает токенизацию и построение дерева.
Токенизация - это лексический анализ, разбивающий элементы на токены.
Постройка дерева - это, по сути, создание дерева на основе проанализированных токенов и того, на чем мы будем сосредоточены - дерева DOM.
Дерево DOM описывает содержимое документа. В нём также указываются взаимосвязи и иерархия различных тегов. Теги, которые расположены внутри других тегов называются «дочерними» узлами. Чем больше узлов DOM, тем дольше происходит построение дерева.

Следующий этап в этом шаге – обработка CSS и построение дерева CSSOM. Браузер строит «узловую» модель дерева точно так же, как в случае с DOM: формирует родительские, дочерние, сиблинговые узлы. Тут дело идёт проще, ведь в отличие от HTML, CSS имеет контекстно-свободную грамматику и анализируется с помощью стандартных методов синтаксического анализа CFG. Как и с HTML, браузеру нужно преобразовать полученные правила во что-то, с чем он сможет работать. И тут он снова обращается к процессу преобразования HTML в объект, но уже для CSS.
Когда оба дерева сформированы, их нужно объединить в единое дерево рендеринга. Такое дерево нужно для вычисления макета каждого видимого элемента. Оно выступает источником данных для отрисовки пикселей на экране. Чтобы построить дерево рендеринга, браузер:
- Начиная с корня DOM-дерева, проходит по каждому видимому узлу. Некоторые узлы могут быть не видны (например, теги сценария, метатеги и т. д.) И опускаются, поскольку они не отражаются в визуализированном выводе. Некоторые узлы скрыты с помощью CSS и также не отображаются в дереве рендеринга; например, узел span - в приведённом выше примере - отсутствует в дереве визуализации, потому что у нас есть явное правило, которое устанавливает для него свойство «display: none».
- Для каждого видимого узла находит соответствующие правила CSSOM и применяет их.
- Выпускает видимые узлы с содержимым и их вычисленными стилями.
Конечный результат - это визуализация, в которой есть как содержимое, так и информация о стиле всего видимого на экране. Установив дерево рендеринга, мы можем перейти к этапу «разметки».
Одновременно с построением дерева рендеринга браузер использует ещё одного незаменимого помощника – сканер предзагрузки, который подготовит запрос на выборку с высоким приоритетом для таких ресурсов, как CSS, JavaScript и веб-шрифты. Это оптимизация, добавленная на этапе синтаксического анализа, поскольку выполнение этих запросов займёт слишком много времени, поскольку синтаксический анализатор находит на них ссылки.
Браузер также строит дерево доступности, которое вспомогательные устройства используют для анализа и интерпретации контента. Объектная модель доступности (AOM) похожа на семантическую версию DOM. Браузер обновляет дерево доступности при обновлении DOM. Дерево доступности не может быть изменено самими вспомогательными технологиями. Пока модель AOM не построена, контент не будет отображен на экране.
Шаг 4: Рендеринг
Теперь, когда информация проанализирована, браузер может начать её отображать. Для этого браузер теперь будет использовать дерево рендеринга для визуального представления документа. Этапы рендеринга включают в себя макет, раскраску и, в некоторых случаях, композицию.
Теперь самое время познакомить вас с понятием критического пути рендеринга. Лучше всего это визуализировать с помощью инфографики:

Оптимизация критического пути рендеринга позволяет ускорить начало рендеринга. Мы не будем вдаваться в подробности того, как оптимизировать CRP, но в целом суть заключается в повышении скорости загрузки страницы за счёт определения приоритетов загружаемых ресурсов, контроля порядка их загрузки и уменьшения размеров файлов этих ресурсов.
И, наконец, мы переходим к самому рендерингу.
- Макет - это первый этап рендеринга, на котором определяется геометрия и расположение узлов. Макет рекурсивно строится через часть или всю иерархию кадров, вычисляя геометрическую информацию для каждого средства визуализации, которому она требуется. Чтобы не делать полный макет для каждого небольшого изменения, браузеры используют систему «грязных битов». Изменённый или добавленный рендерер помечает себя и его дочерние элементы как «грязные».
- Рисование – следующий этап рендеринга. Браузер преобразует каждый блок, вычисленный на этапе макета, в фактические пиксели на экране. Рисование включает в себя визуализацию всех элементов на экране. Браузеру нужно обрабатывать всё это очень быстро. Этот этап может разбивать элементы в дереве компоновки на слои. Размещение содержимого в слоях на графическом процессоре (вместо основного потока на центральном процессоре) улучшает производительность рисования и перерисовки. Слои действительно повышают производительность, но являются дорогостоящими, когда дело доходит до управления памятью, поэтому не следует злоупотреблять ими в рамках стратегий оптимизации веб-производительности.
- В ряде случаев при рендеринге страницы потребуется компоновка или выстраивание композиции. Когда разделы документа отрисовываются на разных слоях, перекрывая друг друга, наложение необходимо для обеспечения того, чтобы они отображались на экране в правильном порядке и содержимое отображалось правильно.
Шаг 5: Финальный
Если вы думаете, что после полной отрисовки всё уже готово, можем вас разочаровать: в случае, когда загрузка JS была отложена, потребуется ещё время на её завершение. Нередко в таких случаях оценивается TTI – время до ответа пользователю. Если браузер занят построением деревьев, загрузкой JavaScript и отрисовкой, он просто не сможет в это же время отвечать на клики пользователя. Чаще всего TTI составляет около 50 мс.
Но зато сразу после их истечения пользователь может полностью увидеть загруженную страницу и работать с ней.
Данная статья является переводом с англоязычной статьи.
Читайте также: