
Схема работы браузера и веб сервера
Интернет - глобальная информационная сеть, части которой логически взаимосвязаны друг с другом посредством единого адресного пространства , основанного на протоколе TCP /IP. Интернет состоит из множества взаимосвязанных компьютерных сетей и обеспечивает удаленный доступ к сервисам сети Интернет.
Сервисы Интернет - сервисы, предоставляемые в сети Интернет пользователям, программам, системам, уровням, функциональным блокам. В сети Интернет сервисы реализованы в виде сетевых служб , доступ к которым реализуется как из локальной, так и из глобальной сети .
Наиболее распространенными Интернет-сервисами являются:
Служба WWW
Служба WWW (World Wide Web) - основная служба в сети Интернет, позволяющая получать доступ к информации на любых серверах, подключенных к сети. Служба WWW представляет собой множество независимых, но взаимосвязанных серверов и предназначена для обмена текстовой, графической, аудио и видео-информацией. Работая с Web, пользователь последовательно соединяется с Web-серверами и получает информацию. WWW построена по схеме "клиент-сервер". В качестве клиента выступает браузер, который является также и интерпретатором HTML. Как интерпретатор, браузер в зависимости от команд (тегов) выполняет различные функции: размещение текста на экране, обмен информацией с сервером по мере анализа полученного HTML-текста и др.
Служба WWW организована на принципах гиперсреды. Гиперсреда - технология представления информации в виде относительно небольших блоков, ассоциативно связанных друг с другом.
Web-сервер
Web-браузер
Для доступа к информации, расположенной на web-серверах, пользователи применяют специальные клиентские программы — браузеры.
Web-браузер - это программное обеспечение для просмотра web-сайтов, то есть для запроса web-страниц из WWW, для их обработки и вывода, и для реализации перехода от одной страницы к другой. Браузер — комплексное приложение для обработки и вывода разных составляющих web-страницы, и для предоставления интерфейса между web-сайтом и его посетителем. Браузер способен предварительно обрабатывать данные, отправляемые на сервер, а также обрабатывать и представлять результаты, полученные от сервера, в удобном для пользователя виде.
В настоящее время существует четыре наиболее популярных web-браузера. К ним относятся Internet Explorer (IE), Netscape , Opera и Firefox. Большинство браузеров основано на одном ядре. Например, Netscape и Firefox основаны на ядре, которое называется Gecko. Между браузерами существует ряд отличий, например:
Web-браузер является источником ряда угроз безопасности для компьютера пользователя. Некоторые web-страницы могут содержать вредоносный код . Для обеспечения большей устойчивости браузера к подобным страницам рекомендуется проделать следующие операции:
Это лишь краткий перечень настроек, которые можно произвести для того, чтобы сделать браузер безопасным. Проблемой является то, что это приведет к значительным ограничениям функций браузера, вплоть до полной невозможности его использования, как злоумышленником, так и пользователем.
Запросы и ответы выглядят следующим образом:
Формат начальной строки (start-line) клиента и сервера различаются. Заголовки бывают четырех видов:
Каждый заголовок состоит из названия, символа двоеточия ":" и значения. Наиболее важные заголовки приведены в 1.1.
Простыми словами объясняем, как браузер подключается и общается с сервером.
Поэтому первым делом браузеру нужно понять, какой IP-адрес у сервера, на котором находится сайт.
Такая информация хранится в распределенной системе серверов — DNS (Domain Name System). Система работает как общая «контактная книга», хранящаяся на распределенных серверах и устройствах в интернете.
Однако перед тем, как обращаться к DNS, браузер пытается найти запись об IP-адресе сайта в ближайших местах, чтобы сэкономить время:
- Сначала в своей истории подключений . Если пользователь уже посещал сайт, то в браузере могла сохраниться информация c IP-адресом сервера.
- В операционной системе . Не обнаружив информации у себя, браузер обращается к операционной системе, которая также могла сохранить у себя DNS-запись. Например, если подключение с сайтом устанавливалось через одно из установленных на компьютере приложений.
- В кэше роутера , который сохраняет информацию о последних соединениях, совершенных из локальной сети.
Не обнаружив подходящих записей в кэше, браузер формирует запрос к DNS-серверам, расположенным в интернете.
Как только браузер узнал IP-адрес нужного сервера, он пытается установить с ним соединение. В большинстве случаев для этого используется специальный протокол — TCP.
TCP — это набор правил, который описывает способы соединения между устройствами, форматы отправки запросов, действия в случае потери данных и так далее.
Например, для установки соединения между браузером и сервером в стандарте TCP используется система «трёх рукопожатий». Работает она так:
- Устройство пользователя отправляет специальный запрос на установку соединения с сервером — называется SYN -пакет.
- Сервер в ответ отправляет запрос с подтверждением получения SYN-пакета — называется SYN/ACK -пакет.
- В конце устройство пользователя при получении SYN/ACK-пакета отправляет пакет с подтверждением — ACK -пакет. В этот момент соединение считается установленным.
Задача браузера — как можно подробнее объяснить серверу, какая именно информация ему нужна .
Сервер получил запрос от браузера с подробным описанием того, что ему требуется. Теперь ему нужно обработать этот запрос. Этой задачей занимается специальное серверное программное обеспечение — например, nginx или Apache. Чаще всего такие программы принято называть веб-серверами.
Когда ответ сформирован, он отправляется веб-сервером обратно браузеру. В ответе как правило содержится контент для отображения веб-страницы, информация о типе сжатия данных, способах кэширования, файлы cookie, которые нужно записать и так далее.
👉 Чтобы обмен данными был быстрым, браузер и сервер обмениваются сразу множеством небольших пакетов данных — как правило, в пределах 8 КБ. Все пакеты имеют специальные номера, которые помогают отслеживать последовательность отправки и получения данных. 8. Браузер обрабатывает полученный ответ и «рисует» веб-страницуБраузер распаковывает полученный ответ и постепенно начинает отображать полученный контент на экране пользователя — этот процесс называется рендерингом .
Сначала браузер загружает только основную структуру HTML-страницы. Затем последовательно проверяет все теги и отправляет дополнительные GET-запросы для получения с сервера различных элементов — картинки, файлы, скрипты, таблицы стилей и так далее. Поэтому по мере загрузки страницы браузер и сервер продолжают обмениваться между собой информацией.
Параллельно с этим на компьютер как правило сохраняются статичные файлы пользователя — чтобы при следующем посещении не загружать их заново и быстрее отобразить пользователю содержимое страницы.
Как только рендеринг завершен — пользователю отобразится полностью загруженная страница сайта.
Цель: изучить общий принцип организации работы пользователей с Интернет-приложениями.
Задачи:
- разобраться в схеме взаимодействия клиента и сервера при работе пользователей в среде Интернет;
- изучить основные методы отправки запросов Web-серверу;
- познакомиться с организацией CGI-протокола и возможностями его использования для разработки Интернет-приложений;
- познакомиться с основными функциями Web-серверов и современным состоянием их использования в среде Интернет.
Оглавление
1.1. Схема взаимодействия клиента и Web-сервера. Принципы передачи информации
1.1.1. Организация взаимодействия клиента и сервера в сети Интернет
Кто же является клиентом, и кто его обслуживает при работе в Интернете?
Internet построен по многоуровневому принципу, от физического уровня, связанного с физическими аспектами передачи двоичной информации, и до прикладного уровня, обеспечивающего интерфейс между пользователем и сетью.
Ответ сервера содержит:
В протоколе не указывается, кто должен открывать и закрывать соединение между клиентом и сервером. На практике соединение, как правило, открывает клиент, а сервер после отправки ответа инициирует его разрыв.
Давайте рассмотрим более подробно, в какой форме отправляются запросы на сервер.
Форма запроса клиента
Простой запрос содержит метод доступа и адрес ресурса. Формально это можно записать так:
<Простой-Запрос>:= <Метод> <символ пробел><Запрашиваемый-URI> <символ новой строки>
Пример простого запроса:
Полный запрос содержит строку состояния, несколько заголовков (заголовок запроса, общий заголовок или заголовок содержания) и, возможно, тело запроса. Формально общий вид полного запроса можно записать так:
<Полный запрос>:= <Строка состояния>
(<Общий заголовок>|<Заголовок запроса>|
<символ новой строки> [<содержание запроса>]
Полная форма содержит тип протокола доступа, адрес сервера ресурса и адрес ресурса на сервере (см. рис. 1.2).
В сокращенной форме опускают протокол и адрес сервера, указывая только местоположение ресурса от корня сервера. Полную форму используют, если возможна пересылка запроса другому серверу. Если же работа происходит только с одним сервером, то чаще применяют сокращенную форму.
1.1.2. Методы отправки запросов Web-серверу
Метод HEAD аналогичен методу GET, только не возвращает тело ресурса и не имеет условного аналога. Метод HEAD используют для получения информации о ресурсе. Это может пригодиться, например, при решении задачи тестирования гипертекстовых ссылок.
1.2. Общий интерфейс шлюза CGI (Common Gateway Interface)
Шлюз предусматривает единое окружение и набор протоколов для внешних приложений, взаимодействующих с Web-сервером. Таким образом, любое приложение может использовать CGI для обеспечения интерфейса между приложением и Web-сервером. Это значительно расширяет диапазон возможностей Web-сервера, включая те свойства, которыми обладает потенциально неограниченное число внешних приложений. То есть теперь некоторое CGI-приложение может генерировать бесчисленное количество различных HTML-страниц и передавать их Web-серверу, а тот в свою очередь может возвращать их клиенту, который как раз и запросил данную страницу.
С помощью CGI можно создавать CGI-программы, называемые шлюзами, которые во взаимодействии с такими прикладными системами, как система управления базой данных, электронная таблица, деловая графика и др., смогут выдать на экран пользователя динамическую информацию.
Программа-шлюз запускается WWW-сервером в реальном масштабе времени. WWW-сервер обеспечивает передачу запроса пользователя шлюзу, а она в свою очередь, используя средства прикладной системы, возвращает результат обработки запроса на экран пользователя. Программа-шлюз может быть закодирована на языках C/C++, Fortran, Perl, TCL, Unix Schell, Visual Basic, Apple Script, PHP. Как выполнимый модуль, она записывается в поддиректорий с именем cgi-bin WWW-сервера. На рис.1.3 показан принцип взаимодействия Web-сервера с клиентами с использованием CGI-протокола.
Рис. 1.3. Взаимодействие Web-сервера с клиентами с использованием CGI–протоколаДля передачи данных об информационном запросе от сервера к шлюзу сервер использует командную строку и переменные окружения. Эти переменные окружения устанавливаются в тот момент, когда сервер выполняет программу шлюза (cм. рис. 1.4).
Рис. 1.4. Информационные потоки при взаимодействии Web-сервера с CGI-приложениемПри отправке данных на сервер любым методом передаются не только сами данные, введенные пользователем, но и ряд переменных, называемых переменными окружения, характеризующими клиента, историю его работы, пути к файлам и т. п. Вот некоторые из переменных окружения:
Как правило, программа CGI анализирует содержимое некоторых переменных среды, получает данные от удаленного пользователя через стандартный поток ввода, а результат обработки этих данных записывает в стандартный поток вывода.
Метод GET обеспечивает получение данных от браузера с помощью переменной среды с именем QUERY_STRING. Значение этой переменной равно param1. Это значение соответствует строке параметров, передаваемой программе после знака?
Метод передачи данных GET прост в использовании, однако он подходит только для передачи относительно коротких текстовых строк. Причина этого лежит в ограничении, которое накладывается операционной системой на размер строки переменной среды (не более 255 символов). Если необходимо передать текстовые данные большого объема (например, содержимое полей диалоговых панелей), более предпочтителен метод POST: тогда программа GCI получает данные от браузера, выполняя чтение из стандартного потока ввода.
Если данные передаются методом POST (о чем программа CGI может узнать, анализируя переменную среды REQUEST_METHOD), то объем передаваемых данных записывается в переменную среды с именем CONTENT_LENGTH. Заметим, при использовании метода GET содержимое переменной среды CONTENT_LENGTH анализировать не нужно.
Каждый раз, когда удаленный пользователь обращается к расширению CGI, на сервере Web запускается программа, которая выполняется как отдельный процесс, причем в собственном адресном пространстве. На запуск процесса требуется время, и если ваш сервер пользуется популярностью, то программы CGI могут полностью его загрузить. В результате увеличится время реакции сервера, что может оттолкнуть от него пользователей.
1.3. Основные функции Web-серверов
Web была создана для распространения гипертекстовых документов в привлекательном графическом формате, но теперь всеобщей заботой стало расширение ее функциональных возможностей. Пользователи стремятся персонифицировать содержимое страниц. Многие компании хотят, чтобы страницы Web могли извлекать информацию из баз данных и составлять отчеты в задаваемой пользователем форме.
Что собой представляют Web-серверы?
Функции, выполняемые Web-серверами, в сущности очень просты:
В качестве примеров Web-серверов можно привести сервер Apache группы Apache, Internet Information Server (IIS) компании Microsoft, SunOne фирмы Sun Microsystems,WebLogic фирмы BEA Systems, IAS (Inprise Application Server) фирмы Borland, WebSphere фирмы IBM, OAS (Oracle Application Server).

Неопытные разработчики вряд ли поймут, что изображено на диаграмме ниже. Но без понимания концептуальных основ работы современного веба тяжело назвать себя хорошим веб-программистом. В материале будет приведено краткое объяснение, которое поможет разобраться в происходящем, а после каждый элемент будет разобран в деталях.
Пользователь ищет в Google «Strong Beautiful Fog And Sunbeams In The Forest». Первый результат отправляет его на Storyblocks. Пользователь нажимает на ссылку, которая перенаправляет его браузер на страницу с изображением. Тем временем браузер отправляет запрос на DNS-сервер, чтобы установить соединение со Storyblock, и, получив ответ, отправляет запрос на сайт.
Запрос попадает на балансировщик нагрузки, который случайным образом выбирает для обработки запроса один из десяти (или около того) веб-серверов, на которых запущен сайт. Веб-сервер достаёт некоторую часть информации об изображении из службы кэширования, а остальное — из основной базы данных. Если цветовой профиль для изображения ещё не был вычислен, задача «определить цветовой профиль» будет добавлена в очередь заданий. Эти задания серверы обрабатывают асинхронно и соответствующим образом обновляют базу данных с результатами.
Затем происходит поиск похожих фотографий: в службу полнотекстового поиска отправляется запрос с заголовком фотографии в качестве входных данных. Если пользователь авторизовался в Storyblocks, информация о его учётной записи загружается из базы данных учётных записей. Наконец, данные о просмотре страницы отправляются в firehose-хранилище для последующей записи в облачную систему хранения. В конечном счёте, эти данные будут загружены в хранилище данных, которое аналитики используют для обработки.
25–27 ноября, Онлайн, Беcплатно
Далее будет рассказано про каждый элемент в деталях. Конечно, каждую тему можно рассмотреть гораздо подробнее, но в рамках этой статьи будут разобраны только основы. Этого должно хватить для понимания архитектуры современного веб-проекта.
1. DNS
2. Балансировщик нагрузки
Прежде чем начать обсуждение балансировки нагрузки, нужно сделать шаг назад, чтобы обсудить горизонтальное и вертикальное масштабирование приложений. Что это и в чём разница? Эта тема хорошо объяснена в посте на StackOverflow: «горизонтальное» масштабирование характеризуется добавлением новых машин в пул ресурсов, тогда как «вертикальное» подразумевает, что наращивается мощность (например, увеличивается CPU или RAM) существующей машины.
В веб-разработке проект масштабируется горизонтально как минимум потому, что всё ломается. Серверы падают по непонятным причинам. Сети деградируют. В некоторых ЦОД-ах время от времени отключается свет. Несколько серверов позволит переживать незапланированные отключения без нарушения работы приложения. Другими словами, приложение становится «отказоустойчивым». Горизонтальное масштабирование позволяет минимально связывать разные части проекта (веб-сервер, базу данных и т. д.), потому что каждая из них запускается на разных серверах. Наконец, может наступить такой момент, когда вертикальное масштабирование более невозможно, так как в мире нет достаточно мощного компьютера для выполнения всех вычислений приложения. Поисковая платформа Google является типичным примером, хотя это относится и к компаниям с гораздо меньшими масштабами. Например, Storyblocks обычно использует от 150 до 400 AWS-машин EC2 в любой момент времени. Было бы сложно получить всю эту вычислительную мощность с помощью вертикального масштабирования.
Давайте вернёмся к балансировщикам нагрузки. Благодаря им возможно горизонтальное масштабирование. Они направляют входящие запросы на один из множества серверов приложения, которые обычно являются зеркальными копиями друг друга, и отправляют ответ обратно пользователю. Любой сервер обрабатывает запросы одинаково, так что балансировщик занимается распределением заданий, чтобы никакой из них не был перегружен.
Вот и всё. Концептуально балансировщики нагрузки довольно просты и понятны.
3. Серверы веб-приложений
Если смотреть издалека, серверы веб-приложений относительно просты. Они выполняют основную бизнес-логику, которая обрабатывает запрос пользователя и отправляет HTML обратно браузеру. Чтобы выполнять свою работу, они обычно общаются с различными бэкэнд-инфраструктурами, такими как базы данных, серверы кэширования, очереди заданий, службы поиска и т. д. Как упоминалось выше, обычно есть как минимум два, а то и больше, сервера, подключённых к балансировщику нагрузки для обработки пользовательских запросов.
4. Сервер баз данных
Каждое современное веб-приложение использует одну или несколько баз данных для хранения информации. Базы данных предоставляют инструменты для организации, добавления, поиска, обновления, удаления и выполнения вычислений над данными. В большинстве случаев серверы веб-приложений напрямую общаются с серверами заданий. Кроме того, у каждой серверной службы может быть соответствующая база данных, изолированная от остальной части приложения.
Здесь стоит упомянуть SQL и NoSQL.
SQL расшифровывается как «Structured Query Language» (язык структурированных запросов). Он был изобретён в 1970-х годах, чтобы создать стандартный способ запросов к реляционным наборам данных, доступных широкой аудитории. SQL-базы данных хранят данные в таблицах, которые связаны между собой общими ключами. Такие ключи обычно представлены целыми числами.
Рассмотрим типичный пример хранения информации об истории адресов пользователей. Получатся две таблицы — user и user_addresses, — связанные друг с другом идентификатором пользователя (id в таблице user). Их можно увидеть на изображении ниже. Таблицы связаны, потому что столбец user_id в user_addresses является «внешним ключом» в столбце id в таблице users.

Если вы мало что знаете о SQL, настоятельно рекомендуем ознакомиться с нашим курсом по этой теме. Эта технология используется в веб-разработке почти везде, поэтому стоит хотя бы понимать основы для правильного построения приложений.
NoSQL расшифровывается как «не-SQL» и представляет собой более новый набор технологий баз данных. Он был разработан для обработки очень больших объёмов информации, которые могут генерироваться крупномасштабными веб-приложениями. Большинство вариантов SQL плохо масштабируются горизонтально, а масштабироваться вертикально могут только до определённого момента. Если вы ничего не знаете о NoSQL, рекомендуем начать знакомство со следующих статей:
Также хочется отметить, что индустрия повсеместно полагается на SQL даже как на интерфейс для баз данных NoSQL, поэтому нужно изучать SQL, даже если он не требуется в вашей работе. В современных реалиях почти невозможно этого избежать.
5. Кэширование
Служба кэширования предоставляет простое хранилище данных в формате ключ-значение, которое позволяет хранить и искать информацию за время, близкое к линейному (O(1)). Обычно приложения используют функции кэширования, чтобы сохранять результаты дорогостоящих вычислений и воспользоваться ими позже из кэша, а не пересчитывать их еще раз. Приложение может кэшировать результаты запроса в базы данных, результаты обращения к внешним службам, HTML для заданного URL-адреса и многое другое. Вот некоторые примеры из реального мира:
- Google кэширует результаты поиска для популярных поисковых запросов, таких как «собака» или «Тейлор Свифт», а не ищет их каждый раз заново;
- Facebook кэширует большую часть данных, которые вы видите при входе в систему, например, списки постов или друзей. Подробнее, о технологии кэширования используемого в Facebook, можно почитать в этой статье на Medium;
- Storyblocks кэширует HTML-страницы от React, результаты поиска и другое.
Двумя наиболее распространёнными технологиями кэширования являются Redis и Memcache.
6. Очереди задач
Большинству веб-приложений требуется выполнять некоторую работу, напрямую не связанную с ответом на запросы пользователей, асинхронно, в фоновом режиме. Например, Google должен сканировать и индексировать весь интернет, чтобы возвращать релевантные результаты поиска. Он не делает это при каждом запросе, а сканирует сеть асинхронно, обновляя поисковые индексы «по пути».
Выполнять асинхронную работу позволяют разные архитектуры, но наиболее распространённой является архитектура «очередь задач». Она состоит из двух компонентов: очереди «заданий», которые необходимо выполнить, и одного или нескольких рабочих серверов (часто называемых «работниками»), которые обрабатывают задания из очереди.
В очередях задач хранятся списки заданий, которые нужно выполнить асинхронно. Всякий раз, когда приложению нужно выполнить какую-то задачу, которая должна выполняться по расписанию или в соответствии с действием пользователя, оно добавляет её в очередь. Проще всего организованы очереди FIFO — «первым пришёл — первым ушёл», но большинство приложений в конечном итоге нуждаются в какой-то системе балансировки очередей.
Например, в Storyblocks очередь заданий используется для выполнения многих скрытых работ, необходимых для поддержания проекта: кодирование видео и фотографий, обработка CSV-файлов для тегов метаданных, агрегирование статистики пользователей, отправка писем с паролями для сброса и т. д. Со временем проект отказался от простой очереди FIFO в пользу приоритетной очереди, чтобы операции с фиксированным временем выполнения, такие как отправка писем о сбросе пароля, были завершены как можно скорее.
Сервера заданий выполняют задания из очереди. Они запрашивают её, чтобы определить, есть ли работа, и если есть, — приступают к выполнению.
7. Полнотекстовый поиск
Многие, если не большинство, веб-приложений поддерживают функцию поиска по текстовому вводу (часто называемого «запрос»), в котором приложение возвращает наиболее «релевантные» результаты. Технология, использующая эту функцию, обычно называется «полнотекстовым поиском» и использует инвертированный индекс для быстрого поиска документов, содержащих ключевые слова запроса.

В этом примере три заголовка документов преобразуются в инвертированные индексы, что облегчает поиск по определённому ключевому слову среди документов с этим ключевым словом в заголовке. Обратите внимание, что обычные слова, также называемые стоп-словами («in», «the», «with» и т. д.), обычно не включаются в инвертированный индекс.
В действительности можно выполнять полнотекстовый поиск непосредственно из некоторых баз данных (например, его поддерживает MySQL), но обычно принято запускать отдельную службу, которая вычисляет и сохраняет инвертированные индексы и предоставляет интерфейс для запросов. Самая популярная полнотекстовая поисковая платформа сегодня — Elasticsearch, хотя есть и другие варианты, такие как Sphinx или Apache Solr.
8. Службы
Когда приложение достигает определённого масштаба, как правило, появляются определённые «службы», созданные специально для запуска в виде отдельных приложений. Они не выставлены на всеобщее обозрение, но приложение и другие службы взаимодействуют с ними. Например, в Storyblocks имеются несколько операционных и плановых служб:
- служба учётных записей хранит пользовательские данные для всех сайтов компании, что позволяет работать перекрёстно и создаёт более унифицированный опыт использования;
- служба контента хранит метаданные для видео, аудио и изображений, а также предоставляет интерфейсы для загрузки содержимого и просмотра истории загрузок;
- служба оплаты предоставляет интерфейс для оплаты кредитными картами;
- HTML → PDF сервис предоставляет простой интерфейс, который принимает HTML-код и возвращает соответствующий PDF-документ.
9. Хранилище данных
Будет компания жить или нет во многом определяется тем, как она работает с данными. Почти каждое современное приложение, достигая определённого масштаба, переходит к одной и той же организации сбора, хранения и анализа данных. Работа с данными проходит в три основных этапа:
- Приложение отправляет данные в «firehose»-хранилище, которое обеспечивает потоковый интерфейс для поглощения и обработки данных. Как правило, это информация о действиях пользователей. Часто необработанные данные преобразуются или дополняются и передаются в другие «firehose»-хранилища. Наиболее распространённые технологии для этого процесса — AWS Kinesis и Kafka.
- Исходные, а также окончательно преобразованные и дополненные данные сохраняются в облачном хранилище. AWS Kinesis предлагает сервис под названием Firehose, который позволяет сохранять необработанные данные в облачном хранилище (S3), которое чрезвычайно просто в настройке.
- Преобразованные и дополненные данные загружаются в хранилище данных для анализа. Типичным примером является AWS Redshift, им пользуется большинство стартапов, хотя крупные компании предпочитают решения от Oracle или другие проприетарные технологии хранения. Если наборы данных достаточно велики, то для анализа может потребоваться технология NoSQL MapReduce, например, Hadoop.
На диаграмме не изображён ещё один шаг: загрузка данных из приложения и баз данных различных служб в хранилище. Например, Storyblocks каждую ночь загружает VideoBlocks, AudioBlocks, Storyblocks, службу учётных записей и базы данных портала разработчиков в Redshift. Это даёт аналитикам целостное представление, так как основные бизнес-данные и данные действий пользователей хранятся в одном и том же месте.
10. Облачное хранилище
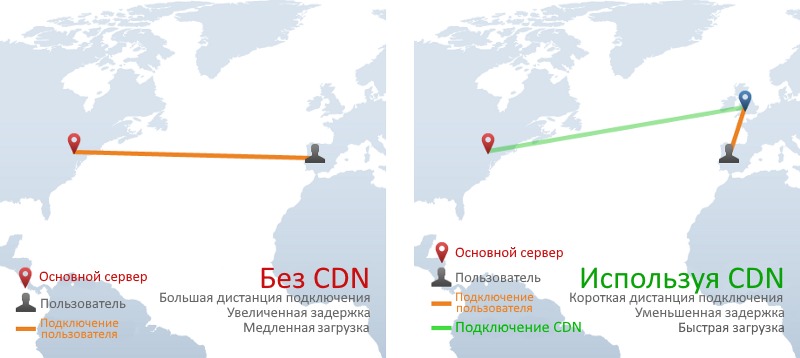
11. CDN
Для более полного понимания принципов работы современного веба вы можете также ознакомиться с другими нашими материалами:
Читайте также: