
Программы управления памятью переводов
В современном бюро переводов используется множество средств автоматизации процессов. Применяются программы для управления памятью переводов, контроля качества, координации проектов, учета платежей, коммуникаций с клиентами и исполнителями. Каждая из этих программ позволяет управлять каким-либо процессом — другими словами, выполняет какую-либо отдельную функцию в общем процессе управления переводами.
Большинство таких программ относят к категории «системы управления переводами» (TMS). Но ни одна из них не охватывает все процессы в компании. Термин «TMS» стал настолько размытым, что под ним понимают совершенно разные системы. Попробуем разобраться, на какие категории делятся TMS-системы.
Пример путаницы
Введите в строке поиска Google запрос «translation management software» — скорее всего, в первой десятке результатов окажутся страницы с перечнем этих программ на сервисах Capterra и G2Crowd. Просмотрите эти списки: оба каталога не имеют отношения к отрасли перевода и локализации. В них свалены в кучу системы, предназначенные для совершенно разных целей. Одни позволяют извлекать текст для перевода из веб-страницы, другие — раздавать задания переводчикам, третьи — фиксировать заказы и вести финансовый учет и т. п.
Мы попытаемся обозначить основные категории систем управления переводами.
CAT-инструменты
CAT-инструмент на жаргоне технических переводчиков — «кошка». Это ключевой инструмент переводчика — программа, предназначенная для выполнения собственно перевода. По сути, это текстовый редактор, в котором предусмотрены специальные возможности — использование памяти переводов, терминологических словарей и т. п.
Такие программы упрощают работу переводчика, предлагая уже применявшиеся ранее и подсказывая возможные варианты перевода. Они особенно эффективны для работы с техническими текстами, в которых многие фрагменты текста повторяются.
Менеджер проектов ведет с помощью таких программ память переводов (translation memory), готовит задания для переводчиков из исходных файлов, определяет объемы работ, конвертирует файлы в исходный формат, комплектует пакеты для сдачи клиенту. Если проект выполняется в онлайновом CAT-инструменте, у менеджера есть возможность отслеживать выполнение отдельных работ в режиме реального времени: он в любой момент знает, какую часть работы успел выполнить каждый переводчик. Все переводчики пользуются одной серверной памятью переводов, и каждый из них может использовать перевод, выполненный другими, благодаря чему уменьшается общий объем работ.
Примеры CAT-инструментов: Trados Studio, memoQ, MemSource, Smartcat, MateCat, Wordfast, Transit, Deja Vu и т. д.
Парсеры и конвертеры
Перевод — это только часть проекта. Прежде чем переводить, текст нужно извлечь из файла, сайта или интерфейса программы и перенести в CAT-инструмент, а после перевода — вернуть его обратно, вставив вместо исходного текста. Такие операции не имеют отношения к переводу, но порой требуют немалых усилий.
На этапе переноса текста в «кошку» следует выполнить множество условий.
— Необходимо извлечь именно ту часть текста, которая подлежит переводу, без лишних и отсутствующих фрагментов.
— В тексте должно сохраниться форматирование (шрифты, цвет, выделение полужирным шрифтом, курсивом, подчеркиванием и т. п.).
— Текст должен корректно разбиться на сегменты (обычно один сегмент — это одно предложение).
— Должны корректно сохраниться все специальные символы — надстрочные элементы, буквы «посторонних» языков, знаки градуса и т. д.
— Таблицы, подписи к рисункам, математические формулы и другие специальные элементы не должны превратиться в «обычный» текст.
В идеале переводчик в процессе перевода должен видеть текст в уже сверстанном виде.
Когда перевод готов, возникает обратная задача: корректно перенести текст туда, где изначально был текст оригинала. Если речь идет о веб-сайте, в его локализованной версии должны правильно работать гиперссылки, если о руководстве в формате PDF — в оглавлении должны быть указаны правильные номера страниц, если о программе — перевод должен не выходить за границы кнопок и заголовков диалоговых окон, и т. д., и т. п. Подводных камней и неожиданных проблем на этом этапе масса.
Обычно операции, не связанные непосредственно с переводом, возложены на плечи менеджера проектов, и программы, выполняющие их, значительно упрощают ему жизнь. В их отсутствие ему приходится изобретать хитроумные методы.
Примеры программ и систем для конвертации и извлечения текста: Easyling, Infix, Transifex, Poedit. Существует также масса расширений (add-on) для «обычных» программ, позволяющих извлекать текст из документов «неудобных» программ, например чертежей AutoCAD, векторной графики Corel, макетов QuarkXpress и т. д.
В большинстве современных CAT-инструментов предусмотрены конвертеры для основных форматов файлов.
Краудсорсинговые платформы и отраслевые биржи заказов
Еще один аспект работы переводческой компании — поиск и отбор переводчиков для своих проектов. Для этого тоже существуют специальные сервисы, наиболее известным из которых является ProZ. На таких сайтах можно подать объявление о работе, на которое откликнутся желающие ее выполнить. Останется только выбрать наиболее подходящего кандидата и предоставить ему нужные материалы.
Некоторые системы позволяют раздать проект «вслепую» большому количеству переводчиков и получить готовый перевод через некоторое время. При этом, конечно, возникает масса нюансов с контролем качества и сроков, но многих заказчиков — особенно тех, для которых скорость или количество предпочтительнее качества, — такой подход устраивает.
Системы машинного перевода
Этот пункт, думаем, понятен всем. Системы машинного перевода — это системы, которые «переводят сами», без участия человека. Несмотря на то, что они существуют уже несколько десятков лет, результат их работы, как мы уже знаем, вообще-то нельзя считать переводом.
В последнее время бурно развивается новая технология, так называемый NMT — машинный перевод с использованием нейросетей. Такая система анализирует огромные массивы уже существующих переводов, выполненных человеком, и сама выводит правила и закономерности, по которым переводился текст. Чем больше объем входящих данных, тем более близким к «человеческому» оказывается результат их работы.
Примеры таких систем: Globalese, Lilt, Google Translate.
Системы управления бизнесом
В отличие от перечисленного выше, системы этой категории не предназначены для выполнения собственно перевода. Их задача — ведение баз клиентов и исполнителей с ценами и контактами, прием заказов от клиентов и выдача заказов исполнителям, контроль сроков, финансовый учет, создание счетов-фактур, мониторинг оплаты и составление финансовых отчетов о деятельности компании.
Такие системы позволяют контролировать деятельность переводческой компании в режиме реального времени и быстро действовать в нестандартных ситуациях. Без них работа организации превращается в хаос: данные хранятся в разрозненных и несвязанных таблицах, дедлайны записываются в календари, контактная информация хранится в недрах почтового клиента, задания отправляются вложениями по электронной почте, счета-фактуры создаются в текстовом редакторе вручную, а на финансовые отчеты просто нет времени.
Примеры таких систем: Plunet, Protemos, XTRF, Projetex.
Гибридизация и интеграция
Такая классификация весьма условна, поскольку в каждой из программ предусмотрены функции, относящиеся к различным категориям TMS-систем. Например, Smartcat — это в первую очередь CAT-инструмент, но при этом в нем есть собственная биржа переводчиков и встроенная платежная система.
Кроме того, многие TMS-системы разных категорий взаимоинтегрируются, предоставляя друг другу недостающие функции. Благодаря такой интеграции пользователю не нужно вносить одни и те же данные в несколько разных баз: они автоматически копируются из одной системы в другую. Например, внеся заказ от клиента в Protemos, можно автоматически перенести его в Smartcat для выполнения перевода, и т. п.
Заключение
Как видим, сложно отнести какую-либо TMS-систему лишь к одной категории. Классификация скорее указывает на центральную функцию TMS. Функции, являющиеся для одних систем основными, для других — вспомогательные.
Важно просто знать обо всем многообразии существующих TMS-инструментов и понимать, какие задачи компании они способны решать.
Использование программного обеспечения позволяет автоматизировать рутинные операции и снизить риск ошибки из-за человеческого фактора. В нашей работе мы используем следующие виды специализированного программного обеспечения:
1. Системы переводческой памяти (CAT-программы)
Переводческая память (англ. translation memory, TM) – база данных, содержащая ранее переведенные командой переводчиков сегменты текста. Одна запись в такой базе данных соответствует сегменту или «единице перевода» (англ. translation unit), за которую обычно принимается одно предложение, ячейка таблицы. При использовании системы переводческой памяти сегмент исходного текста сравнивается с записями в базе данных. Найденные точные совпадения или похожие сегменты предлагаются переводчику для их оценки и включения в текст перевода. Современные системы переводческой памяти позволяют решить следующие задачи:
А. Снизить трудозатраты на перевод текстов с повторяющимися фрагментами и сократить сроки выполнения таких проектов.
Б. Обеспечить единообразие используемой терминологии при работе нескольких переводчиков над проектом. Практически все современные системы переводческой памяти позволяют реализовать одновременное подключение нескольких переводчиков к расположенной на сервере или в облаке памяти переводов.
В. Автоматизация работы с файлами, имеющими сложное форматирование. При использовании систем переводческой памяти происходит конвертация файла в двуязычный формат (в большинстве случаев на основе стандарта XLIFF), а параметры форматирования выносятся в параметры сегмента или расположенные внутри сегмента теги. Контроль соблюдения форматирования выполняется программными средствами. Это гарантирует, что переведенный файл будет выглядеть так же аккуратно, как и оригинал.
| SDL Trados Studio 2017 | Memsource | ||
| MemoQ | Transit | ||
| Across | Deja Vu | ||
| SDLX | Wordfast | ||
| MateCAT | SmartCAT |
2. Программы формально-логического контроля качества перевода (QA)
Сегментация переводимых файлов и их конвертирование в двуязычный формат открывает дополнительные возможности для автоматизации процесса контроля качества. Сравнение сегментов с оригиналом и переводом позволяет выявить и полностью исключить следующие типы ошибок:
А. Ошибки в цифровых данных.
Б. Несоблюдение глоссария.
В. Пропуски в переводе.
Г. Расхождение пунктуации в конце сегментов оригинала и перевода.
Д. Несогласованный перевод, когда для одного сегмента существует несколько альтернативных вариантов перевода.
Е. Различия в форматировании между оригиналом и переводом.
и т.д.
| ApSIC Xbench | Verifika |
3. Программное обеспечение для верстки и работы со специализированными форматами файлов
В процессе перевода нам приходится работать с разными форматами файлов. В большинстве случаев речь идет о программах для верстки (Adobe InDesign, Corel Draw, Adobe Photoshop), разработки программного обеспечения (Shockwave, PHP, HTML, XML, MS Help workshop) или инженерных программах (AutoCAD). Вот неполный перечень форматов, с которыми мы работаем:
Сегодня я расскажу о средствах, помогающих в работе переводчику. А именно - о системах памяти переводов (они же TM (Translation Memory), CAT-Tools (Computer-Assisted Translation Tools) или просто "кошки"))).
Их существует великое множество, самая известная из которых - смею предположить, Традос. Также есть MemoQ, Memsource и множество иных. В данном посте я расскажу о принципе их работы на примере ТМ Memsource, с которой мне лично довелось работать. В остальных системах принцип аналогичный, судя по прочитанным материалам во ВсеПротянутой Паутине (WorldWideWeb дословно можно перевести именно так)).
Итак, приступим:
1. Открываем браузер и вводим адрес www.memsource.com.
2. Регимся. Тут есть нюанс: так как полная версия стоит достаточно приличных денег (100/130/180 евро в месяц, в стоимость включены аккаунты для одного/трех/пяти менеджеров проектов и 10 лингвистов. Соответственно каждая версия рассчитана на бюро переводов (100 евро), средние и большие переводческие компании (130/180 евро) , и разработчики это понимают, они предложили пользователям выбор: либо купить полную версию, либо воспользоваться бесплатной (рассчитана на индивидуальных переводчиков). Ограничений бесплатной версии всего два: можно загружать файлы весом не более 10 Мб, и не более двух в одном проекте. Я не Рокфеллер и даже не Ротшильд, посему пользовался бесплатной онлайн-версией.
3. После регистрации и подтверждения мыла логинимся и видим слева менюшку и три вкладки посередине окна: проекты, базы терминов и базы памяти переводов. Нажимаем кнопку "создать проект", загружаем файл с оригиналом, указываем срок выполнения (чтобы не забыть потом), обзываем проект как-нибудь, создаем базу терминов и базу памяти переводов (чтобы не запутаться потом, лучше всего назвать их также как проект) и сохраняем. Базы памяти переводов и базы терминов пока не касаемся, ибо в свежесозданном аккаунте их еще нет.
ВАЖНОЕ ПРИМЕЧАНИЕ: система криво работает с PDF, посему если оригинал в этом формате, идем на convert standard.com, выбираем опцию "PDF в Word", грузим наш оригинал и нажимает кнопочку CONVERT. По окончании конвертации автоматически загрузится вордовский файл, для приличия спросив куда емусохраниться (или, если не спросит, автоматически сохранится в стандартной папке загрузок (Мои документы - Загрузки). Его и нужно после загрузить в систему для начала перевода.
4. Во вкладке "Проекты" видим только что созданный проект, входим в него и открываем загруженный исходник - в новой вкладке автоматически открывается web me source editor, имеющий вид фрейма, вверху которого - панель инструментов, внизу - две колонки, соответственно для оригинала и перевода, а сбоку справа - панелька MT (Machine translation), автоматически выдающая варианты перевода каждого сегмента (предложения), на которые система автоматически разбила оригинал.
5. Ставим курсор в первую строчку перевода - автоматически подставляется машинный перевод. Если он Вас устраивает, то в панели инструментов нажмите символ - он появится чуть справа от перевода, означая что перевод фрагмента подтвержден, он правильный и занесен в базу памяти переводов. Если машинный перевод не нравится, впишите свой перевод и опять же нажмите кнопку в панели инструментов. Курсор автоматически перескочит на следующую строчку и подставит машинный перевод, с которым Вы уже знаете как поступить.
6. В процессе перевода можно переключиться на вкладку с проектами и, обновив страницу, увидеть какой объем (в процентах) уже переведен. В системе используется облачное хранение данных, потому даже если Вы случайно закрыли вкладку с переводом не сохранив (к слову, там и кнопки "сохранить" нет, я проверял), все что Вы сделали, сохранится при повторном открытии. Посему при окончании перевода просто закрываем вкладку и обновляем страницу с проектами.
7. Выделяем готовый перевод на вкладке проектов - активируются неактивные до того кнопки меню, среди которых выбираем "скачать - готовый файл". Начнется загрузка вордовского документа с переводом. И вот здесь нас ждет бонус. Помните, мы делали вордовский документ из pdf? Естественно в нем было какое-то оформление - шрифты, картинки, схемы и так далее. Так вот, ВСЁ оформление сохраняется в готовом файле с переводом. Да-да, со всеми картинками, схемами, таблицами и прочим.
8. Отправляем готовый перевод заказчику.
9. Профит!
На этом все на сегодня. Успехова в переводах, коллеги, и да пребудет с Вами Контекст!)))
Говоря об автоматизированном переводе, обычно подразумевают программы, осуществляющие перевод на основе технологии машинного перевода (Machine Translation). Однако существует и другая технология — Translation Memory, которая хотя и не столь широко известна российским пользователям, но, тем не менее, имеет ряд преимуществ.
Бурное развитие технического прогресса привело к увеличению числа технических устройств, машин и другой сложной техники, без которых жизнь современного человека практически немыслима. Например, объем документации для европейского самолета Airbus исчисляется десятками тысяч страниц. Как показывают данные исследования, проведенного в конце 2004 года ассоциацией LISA 1 (LISA 2004 Translation Memory Survey), 42% опрошенных переводят около 1 млн. слов в год, у 24% компаний — участников опроса ежегодный объем переводов составляет 1-5 млн., 12% переводят от 5 до 10 млн., объем переводов остальных компаний — от 10 до 500 и более миллионов слов в год. В частности, большинство производителей сегодня не ограничиваются своим локальным рынком и активно осваивают региональные рынки. При этом локализация продукции, в том числе перевод описания продукта на местный язык, является одним из обязательных условий для выхода на новый рынок.
В то же время, хотя производители регулярно выпускают новые версии своих продуктов — автомобилей, экскаваторов, компьютеров и мобильных телефонов, программного обеспечения, — далеко не все из них принципиально отличаются от предыдущих моделей. Подчас новая модель телефона представляет собой слегка измененную (или рестайлинговую) предыдущую модель. Новые версии продаются лучше, поэтому производителям приходится регулярно обновлять свои продукты. В результате документация по каждому из таких продуктов зачастую на 70-90% совпадает с той, что была у предыдущей версии.
Два фактора — большой объем требующих перевода документов и их высокая повторяемость — послужили стимулом к созданию технологии Translation Memory (сокращенно именуется TM, общепринятый русский перевод этого термина отсутствует). Суть технологии TM можно образно передать одной фразой: «Не переводить один и тот же текст дважды». Иначе говоря, Translation Memory используется для повторного использования ранее сделанных переводов. Это позволяет серьезно сократить время на подготовку перевода, особенно при работе с текстами, имеющими высокую степень повторяемости.
Технологию Translation Memory часто путают с машинным переводом (Machine Translation), которая, безусловно, тоже полезна и интересна, но ее описание не является целью настоящей статьи. Использование технологии ТМ повышает скорость перевода за счет уменьшения объема механической работы. Однако важно отметить, что TM не выполняет перевод за переводчика, а является мощным инструментом для сокращения затрат при переводе повторяющихся текстов.
Технология ТМ работает по принципу накопления результатов перевода: в процессе перевода в базе ТМ сохраняются исходный текст и его перевод. Для облегчения обработки информации и сравнения различных документов система Translation Memory разбивает весь текст на отдельные кусочки, которые называются сегментами. Такими сегментами чаще всего являются предложения, но могут быть приняты и другие правила сегментации. При загрузке нового текста система TM осуществляет сегментирование и сравнивает сегменты исходного текста с уже имеющимися в подключенной базе переводов. Если системе удается найти полностью или частично совпадающий сегмент, то его перевод отображается с указанием совпадения в процентах. Сегменты, которые отличаются от сохраненного текста, выделяются подсветкой. Таким образом, переводчику остается только перевести новые сегменты и отредактировать частично совпадающие.
Как правило, задается порог совпадений на уровне не ниже 75%, так как если установить меньший процент совпадений, то увеличатся затраты на редактирование текста. Каждое изменение или новый перевод сохраняются в ТМ, так что нет необходимости переводить одно и то же дважды!
Важно также постоянно пополнять базу Translation Memory, сохраняя в базе (или в базах, если перевод выполняется по различным тематикам) пары сегментов «исходный текст — правильный перевод». Это позволит значительно сократить время, необходимое для перевода сходных текстов. Помимо снижения трудоемкости перевода система TМ позволяет выдержать единство терминологии и стиля во всей документации.
Использование технологии ТМ обеспечивает переводчику следующие преимущества:
Отдельно отметим, что в западных странах, где технология Translation Memory давно уже стала де-факто обязательным инструментом переводчика, средства, потраченные на создание базы переводов, рассматриваются не как затраты, а, скорее, как инвестиции в стабильную и качественную работу, что увеличивает не только прибыль, но и стоимость самой компании.
Рынок систем Тranslation Мemory
Бесспорным лидером на рынке систем Translation Memory являются программы SDL-TRADOS. Летом 2005 года произошло объединение двух крупнейших разработчиков систем ТМ — компаний SDL и TRADOS (программные продукты под торговой маркой TRADOS хорошо известны многим пользователям), и теперь они выпускают совместный продукт, который является законодателем стандартов в области Translation Memory.
Новая система SDL-TRADOS имеет расширенные (настраиваемые пользователем) функциональные возможности нечеткого соответствия (поиск по совпадениям в базе переводов), а также инструментарий для проверки качества переводимых документов. Программа осуществляет проверку орфографии и защищает содержимое блоков памяти с помощью технологии шифрования.
Система поддерживает такие форматы, как Word DOC и RTF, online help RTF, PowerPoint, FrameMaker, FrameMaker +SGML, FrameBuilder, Interleaf, QuickSilver, Ventura, QuarkXPress, PageMaker, SGML/HTML/XML, включая HTML Help, RC (Windows Resource), Bookmaster (DCF) и Troff. Помимо системы SDL-TRADOS, на IT-рынке имеются и другие системы ТМ. Особенно широко представлены французские производители.
— это самостоятельное приложение с систематизированным меню. Система может создавать базы ТМ, а также базы данных терминологии и подключать словари. Процесс перевода осуществляется в специальной оболочке Project, куда при ее создании прикрепляется файл, который необходимо перевести, и подключаются дополнительные настройки: база ТМ, словари и др. Текст переводится в специальной таблице, где напротив каждой графы его оригинала нужно заполнить вариант перевода. К преимуществам также относится дополнительная функция для перевода файлов различных форматов, которая позволяет сохранить исходное форматирование файла.
Помимо поддержки форматов Word, система может переводить документы Excel и PowerPoint. При переводе можно использовать и базы ТМ других программ: Trados версий 2, 3 и 5, документы формата TMX и базы программы IBM Translation Manager. Кроме того, система может работать без лицензии с базами перевода объемом до 110 Кбайт.
ТМ в России
Помимо иностранных компаний, разработкой систем класса Тranslation Мemory занимается российская компания ПРОМТ — всемирно известный разработчик систем машинного перевода (Machine Translation).
Разработка продукта PROMT Translation Suite 7.0 — это дебют компании ПРОМТ в области применения технологии Translation Memory. Уникальность продукта заключается в интеграции сразу двух технологий перевода: Translation Memory и Machine Translation. Помимо работы с базой ТМ в виде самостоятельного приложения путем создания специального документа «Проект», система PROMT Translation Suite 7.0 самостоятельно переводит те сегменты текста, которые отсутствуют в базе ТМ.
Для облегчения работы с незнакомым текстом в продукте также имеется интегрированный электронный словарь, который позволяет оперативно просмотреть варианты перевода слова (рис. 1).
Рис. 1. Окно программы PROMT Translation Suite с развернутой панелью справки по словарной статье
Основные достоинства PROMT Translation Suite:
- Интеграция двух технологий — интеграция машинного перевода с технологией Translation Memory позволяет значительно снизить расходы на перевод текстов. Как правило, даже наличие обширной базы Translation Memory не гарантирует 100%-ного совпадения сегментов оригинального текста с базой переводов. Как показывает практика, даже при высокой степени совпадения, не менее 30-40% текста переводчикам приходится переводить вручную. Наличие функции машинного перевода позволяет ускорить процесс перевода. По ряду оценок, использование МТ повышает производительность труда переводчика на 40-60% в зависимости от сложности текста.
- Дружественный интерфейс — в отличие от большинства систем TM, продукт PROMT Translation Suite предлагает удобный и интуитивно понятный интерфейс. Фактически пользователь может начать переводить сразу же после инсталляции, не нуждаясь в дорогостоящем тренинге по обучению работе с продуктом.
- Наличие русской локализации — данный продукт имеет русский интерфейс и документацию на русском языке.
- Привлекательная цена — PROMT Translation Suite в комплектации с системой машинного перевода с английского на русский и обратно стоит 400 долл.
Как настроить систему Тranslation Memory
Процесс перевода с помощью системы Translation Memory можно условно разделить на следующие этапы:
- Сегментирование исходного текста в соответствии с заданными правилами сегментации.
- Поиск совпадений между сегментами исходного текста и сегментами, хранящимися в базе переводов. Найденные совпадения программа подставляет в текст перевода с указанием процента совпадения.
- Перевод ненайденных сегментов и редактирование частично совпадающих сегментов.
- Сохранение корректных переводов в базе TM для последующего использования.
Для упрощения изложения в рамках данной статьи мы сознательно не рассматриваем этапы извлечения текста из исходного документа и последующей верстки переведенного текста в случае перевода документов в таких форматах, как XML, PDF и др.
Рассмотрим возможности настройки системы Translation Memory на примере уже упоминавшейся нами программы PROMT Translation Suite.
Правила сегментации текста
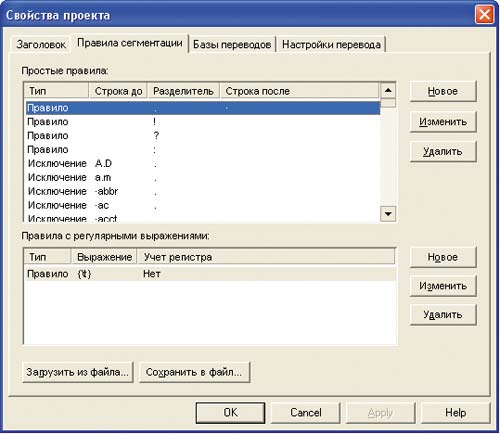
Одна из основных задач во время настройки системы — правильное сегментирование текста. Успех поиска совпадающих сегментов в базе зависит от того, насколько правильно заданы правила сегментации текста (рис. 2).
Существует два типа условий сегментации:
- правило — задает условия, при которых определенные символы (точка, запятая и т.д.) являются границами сегментов;
- исключение — задает условия, при которых определенные символы не являются границами сегментов.
Базовый набор правил сегментации автоматически добавляется в каждый проект перевода при его создании. Для того чтобы получить возможность редактирования этих правил, необходимо выбрать команду Свойства в контекстном меню искомого проекта (второй способ: меню Проект -> Все проекты -> Свойства -> Правила сегментации).
В системе можно задать две группы правил сегментации: простые правила и правила с регулярными выражениями.
Простые правила задают условия, определяющие последовательность символов, которые надо или не надо считать границей сегмента. К простым правилам относится строка до разделителя (возможна пустая или определенная последовательность символов), символ разделителя (всегда один!) и строка после разделителя.
Правила с регулярными выражениями существуют для создания более гибких условий сегментации, что также отнюдь не лишне. Если должным образом не задать такие условия, то, например, предложение «Команда выиграла матч со счетом 3:1» может быть неправильно сегментировано. В данном случае необходимо задать исключение (то есть символ, который система не будет считать границей сегмента) в виде строки до разделителя с помощью регулярного выражения « \d+ » (обозначает любое количество цифр), символа разделителя «:» и строки после разделителя с помощью регулярного выражения « \d+ » (любое количество цифр). В этом случае система не обратит внимание на двоеточие между цифрами.
Работа с непереведенными сегментами
В процессе перевода система анализирует текст, находит полностью или частично совпадающие предложения в базе ТМ и подставляет их в текст перевода. В каждом сегменте сбоку указывается процент совпадений, нижний предел которого можно устанавливать самостоятельно, задавая настройки перед переводом.
Нельзя также забывать о необходимости постоянного пополнения баз ТМ для сокращения затрат на перевод в дальнейшем. Для того чтобы добавить корректно переведенные сегменты в базу, щелкните правой клавишей мыши по выделенному сегменту и выберите команду Добавить выделенные сегменты в базу (или нажмите соответствующую кнопку на панели инструментов). Сохранение новых сегментов перевода в базе не только повышает эффективность работы с системой, но и экономит время при переводе последующих текстов.
Кроме того, следует пользоваться командой контекстного меню Завершить перевод сегментов после окончания редактирования сегментов. В этом случае можно избежать случайного внесения изменений в уже отредактированный сегмент.
Импорт баз переводов
Одна из наиболее полезных опций системы PROMT Translation Suite — возможность импорта баз переводов (во внутреннем формате программы (*.pts) и баз переводов ассоциированной памяти PROMT (*.apd)), а также сегментов из файлов (во внутреннем формате *.pts и в формате TMX Level 1 (*.tmx)). Используя эту возможность системы, можно избавить себя от составления базы переводов с нуля в том случае, если база ТМ по необходимой тематике уже создана, например, другими сотрудниками компании.
Процесс импорта баз переводов PROMT Translation Suite сравнительно прост. Необходимо открыть меню База -> Импортировать и выбрать команду База переводов, а затем найти нужный файл базы и обязательно указать тип файла *.pts.
Особое внимание следует уделить возможности импорта сегментов файлов TMX.
Файлы TMX — это универсальный формат обмена данными для систем Translation Memory, поэтому с их помощью вы можете переносить содержимое баз данных, даже если раньше работали с другой системой ТМ. Чтобы импортировать сегменты из файла ТМХ, нужно выбрать в том же меню База -> Импортировать команду Сегменты и необходимый ТМХ-файл. После этого следует выбрать ту базу переводов, в которую необходимо добавить сегменты из ТМХ-файла, и нажать кнопку Выбрать.
В заключение отметим, что технология Translation Memory является мощным инструментом для решения проблемы эффективного перевода повторяющихся текстов. В этом обзоре мы не только рассказали о сути технологии TM, но и описали представленные на рынке системы. В частности, российским пользователям можно порекомендовать обратить внимание на систему PROMT Translation Suite, разработанную российской компанией ПРОМТ.
Важным преимуществом системы PROMT Translation Suite, по сравнению с зарубежными аналогами, является наличие интегрированной технологии машинного перевода. Это позволяет значительно ускорить создание собственных баз Translation Memory и повысить эффективность работы с системой.
Постоянное пополнение баз переводов новыми сегментами сведет к минимуму работу переводчика вручную при переводе текстов схожей тематики.

Па́мять переводо́в (ПП, англ. translation memory, TM иногда называемая «Накопитель переводов») — база данных, содержащая набор ранее переведенных текстов. Одна запись в такой базе данных соответствует «единице перевода» (англ. translation unit), за которую обычно принимается одно предложение (реже — часть сложносочинённого предложения, либо абзац). Если очередное предложение исходного текста в точности совпадает с предложением, хранящимся в базе (точное соответствие, англ. exact match), оно может быть автоматически подставлено в перевод. Новое предложение может также слегка отличаться от хранящегося в базе (неточное соответствие, англ. fuzzy match). Такое предложение может быть также подставлено в перевод, но переводчик будет должен внести необходимые изменения.
Помимо ускорения процесса перевода повторяющихся фрагментов и изменений, внесенных в уже переведенные тексты (например, новых версий программных продуктов или изменений в законодательстве), системы Translation Memory также обеспечивают единообразие перевода терминологии в одинаковых фрагментах, что особенно важно при техническом переводе. С другой стороны, если переводчик регулярно подставляет в свой перевод точные соответствия, извлеченные из баз переводов, без контроля их использования в новом контексте, качество переведенного текста может ухудшиться.
В каждой конкретной системе Translation Memory данные хранятся в своем собственном формате (текстовый формат в Wordfast, база данных Access в Deja Vu), но существует международный стандарт TMX (англ. Translation Memory eXchange format), который основан на XML и который могут порождать практически все системы ПП. Благодаря этому результаты работы переводчиков можно обменивать между приложениями, то есть переводчик работающий с OmegaT может использовать память переводов, созданную в ТРАДОСе (Trados) и наоборот.
Большинство систем Translation Memory как минимум поддерживают создание и использование словарей пользователя, создание новых баз данных на основе параллельных текстов (англ. alignment), а также полуавтоматическое извлечение терминологии из оригинальных и параллельных текстов.
Гигабайты словарей и программ для перевода[1]
Список программных систем Translation Memory (памяти переводов)
В соответствии с недавними обзорами использования систем памяти переводов (translation memory) к наиболее популярным системам относятся:
| Deja Vu | одна из популярных систем, поддерживающих память переводов (Translation Memory/TM). Разрабатывается со второй половины 1990-х годов испанской компанией ATRIL |
| OmegaT | система автоматизированного перевода, поддерживающая память переводов, написана на языке Java. Возможности продукта включают сегментацию исходного текста на основе регулярных выражений, использование точных (англ. exact) и неточных (англ. fuzzy) соответствий с уже переведенными фрагментами, использование словарей, поиск контекстов в базах данных переводов и работу с ключевыми словами |
| SDLX | |
| Trados (Традос) | система автоматизированного перевода, первоначально (с 1992 года) разработанная немецкой компанией Trados GmbH. Является одним из мировых лидеров в классе систем Translation Memory (TM, накопитель переводов) |
| Metatexis (Метатексис) | программа автоматизации перевода CAT (Computer Aided Translation) для Microsoft Office. Программа встравивается в Microsoft Word и позволяет создавать свою базу параллельных переводов. Метатексис поддерживает все форматы Microsoft Office (Word, Exсel, Power Point), импорт и экспорт базы переводов в популярные форматы TMX, TM TRADOS, TM Wordfast и другие |
| Star Transit | |
| Wordfast | реализована как набор макросов для MS Word; встраивается в MS Word (как и Metatexis) |
![]()
Гигабайты словарей и программ для перевода[2]
Автоматизированный перевод
Автоматизированный перевод (АП, англ. Computer-Aided Translation) — перевод текстов на компьютере с использованием компьютерных технологий. От машинного перевода (МП) он отличается тем, что весь процесс перевода осуществляется человеком, компьютер лишь помогает ему произвести готовый текст либо за меньшее время, либо с лучшим качеством.
Идея Автоматизированного перевода появилась с момента появления компьютеров: переводчики всегда выступали против стандартной в те годы концепции МП, на которую было направлено большинство исследований в области компьютерной лингвистики, но поддерживали использование компьютеров для помощи переводчикам. В 1960-е годы Европейское объединение угля и стали (предшественник современного Евросоюза) стало создавать терминологические базы данных под общим названием Eurodicautom. В Советском Союзе для создания баз такого рода был создан ВИНИТИ.
В современной форме идея АП была развита в статье Мартина Кея 1980 года, который выдвинул следующий тезис: "by taking over what is mechanical and routine, it (computer) frees human beings for what is essentially human" (компьютер берет на себя рутинные операции и освобождает человека для операций, требующих человеческого мышления).
В настоящее время наиболее распространенными способами использования компьютеров при письменном переводе является работа со словарями и глоссариями, памятью переводов (англ. Translation Memory, TM), содержащей примеры ранее переведенных текстов, а также использование так называемых корпусов, больших коллекций текстов на одном или нескольких языках, что дает сжатое описание того, как слова и выражения реально используются в языке в целом или в конкретной предметной области.
При синхронном переводе использование средств автоматизированного перевода по необходимости ограничено. Одним из примеров является использование словарей, загружаемых на КПК. Другим примеров может служить полуавтоматическое извлечение списков терминов при подготовке к синхронному переводу в узкой предметной области.
В узких предметных областях при большом количестве исходных текстов и устоявшейся терминологии переводчики могут использовать и машинный перевод, который может обеспечить хорошее качество перевода терминологии и устойчивых выражений в узкой области. Переводчик в этом случае осуществляет пост-редактирование полученного текста. Более половины текстов внутри Еврокомиссии (главным образом юридические тесты и текущая корреспонденция) переводится с использованием Машинного Перевода (МП).
Гигабайты словарей и программ для перевода[3]
Отказ от использования программ памяти переводов
Каждый раз, когда мы рассматриваем кандидатуру внештатного переводчика с целью сотрудничества с ним, первое, что мы хотим знать, есть ли у кандидата опыт работы с какой-либо программой, основанной на использовании памяти переводов. Несмотря на то что большое значение при выборе переводчика также играют такие факторы, как опыт и специализация, этот вопрос для нас является первостепенным, поскольку принятый в нашем бюро процесс перевода всегда включает его проверку вторым специалистом и автоматизированный контроль качества, поэтому получение готового перевода в двуязычном формате является для нас совершенной необходимостью. Если бы мы искали переводчика для разовой работы, то нам было бы не так важно, использует он или нет переводческую программу, но мы стремимся к налаживанию долгосрочных отношений, которые требуют более осмысленного и последовательного подхода к управлению переводом. Дополнительным преимуществом наличия такого опыта является то, что переводчик, повседневно использующий в работе такую программу, зачастую более профессионален и дисциплинирован и в других аспектах своей деятельности.
Несмотря на то что системы автоматизированного перевода (CAT) в основном и созданы для того, чтобы повышать эффективность и качество перевода, сегодняшний наш опыт свидетельствует о том, что далеко не все переводчики-фрилансеры спешат применять эту технологию. Одни просто не используют эти средства, тогда как другие — вероятно, под давлением требований к их использованию со стороны заказчиков — указывают переводческие программы в своем резюме, но когда доходит до дела, выясняется, что опыта работы с такими программами у них нет или он слишком небольшой.
По правде говоря, я этого просто не понимаю. Я допускаю, что существуют некоторые объективные причины для такого отказа, но не понимаю, зачем зацикливаться на проблемах? Разве доводов «за» не гораздо больше, чем «против»? Лично я считаю, что одно то преимущество, что с применением программы памяти переводов процесс перевода становится более безопасным, уже является достаточной причиной для того, чтобы использовать ее в работе, так как она может защитить переводчика от каких-то случайных или непродуманных действий. Например, когда я только начинал свой путь в качестве переводчика, мне понадобился всего лишь месяц, чтобы понять, что работа без использования памяти переводов крайне небезопасна, — к сожалению, мне пришлось убедиться в этом на собственном горьком опыте. Вдвоем с коллегой мы взялись за перевод срочного проекта объемом 5000 слов и, работая без передышек, перевели его за 12 часов, при этом перевод выполнялся из файла PDF непосредственно в документе Word. И когда конец работы был уже почти близок, я случайно удалил весь текст в файле, закрыл файл и сохранил его, фактически уничтожив итоги работы целого дня. После того как мы связались с заказчиком, чтобы извиниться и попросить продлить срок сдачи проекта, я дал себе обещание никогда больше ничего не переводить без программы CAT, ну может, за исключением нескольких предложений.
Но давайте рассмотрим сначала аргументы, с которыми я отчасти согласен, чтобы, являясь ярым сторонником использования технологии памяти переводов, не казаться слишком критически настроенным с самого начала.
Статья Романа Миронова[4]
Возможные аргументы против использования памяти переводов
«Я не пользуюсь памятью переводов, потому что деление текста по сегментам разрушает естественный поток речи».
Думаю, что это самое существенное и убедительное возражение. В программе памяти переводов вы имеете дело с текстом, сегментированным, как правило, по отдельным предложениям, а не со всем текстом сразу. В одной весьма интересной записи блога переводчик с немецкого на английский язык Джон Банч проводит различие между хорошими переводчиками, для которых исходный текст служит отправной точкой для создания нового текста, и неопытными переводчиками, которых можно было бы назвать просто «преобразователями», передающими текст оригинала словами другого языка. Сегментация по предложениям может препятствовать творческому подходу, так как переводчик вынужден сосредотачиваться на переводе отдельных частей и не получает представления о тексте в целом, превращаясь, таким образом, в простого «преобразователя» текста. В результате перевод может выглядеть не как целостный текст, созданный искусным автором, а скорее как набор отдельных предложений, мало или вовсе не связанных между собой по смыслу или грамматически.
Я полностью согласен с этим возражением и, вместо того чтобы спорить, хочу предложить несколько способов сгладить эту проблему. Прежде всего переводчик должен знать об этой проблеме и быть достаточно компетентен, чтобы соответствующим образом ее решать. То есть в том случае, если вы переводчик, вы должны развивать свои навыки в этой области, а если заказчик перевода — искать высококвалифицированного поставщика. Мысль вполне здравая, но, как всем известно, здравый смысл иногда расходится с общепринятой практикой, поэтому еще раз хочу подчеркнуть, что переводчик должен быть профессионалом своего дела и ответственным человеком, о чем я не устаю повторять в этом блоге.
Во-вторых, программа памяти переводов, как правило, также имеет одну или несколько собственных функций для решения этой проблемы. Например, вы всегда можете произвести сегментацию по абзацам, а не по предложениям. Если в сегменте будет представлен целый абзац, то это поможет переводчику придать тексту большую связность. Еще один проверенный способ — это переключение на другой вид отображения текста, при котором можно видеть только переведенный текст. В этом случае перевод будет представлять собой единый текст и оригинал не будет вас отвлекать. Это позволит вам проверить весь текст на предмет отсутствия логических связей между предложениями. Мы сами регулярно пользуемся этим методом — он действительно работает.
Конечно, мое мнение является предвзятым, поскольку я использую эти программы все время своей работы в качестве профессионального переводчика. Поэтому не стесняйтесь и поправьте меня, если я ошибаюсь в каких-то своих предположениях.
Читайте также: