
Получить индекс строки таблицы значений 1с
Таблица значений часто применяется при программировании на 1С, потому что имеет множество полезных возможностей и работает очень быстро. Таблица значений создается в памяти и не сохраняется в базе данных, т.е. это временный набор данных.
//можно указать тип данных каждой колонки
//если тип данных колонки не указан, то можно хранить данные любого типа
Синтаксис: НоваяКолонка(<Идентификатор>, <Тип>, <Длина>, <Точность>, <Заголовок>, <Ширина>, <Формат>, <Положение>)
Добавление строк в таблицу значений
Перебор строк таблицы значений
Сортировка таблицы значений
Поиск в таблице значений
Синтаксис: НайтиЗначение(<Знач>,<Строка>,<Колонка>)
Возвращает число: 0 - значение не найдено; 1 - значение найдено
Если указан параметр <Строка>, то поиск производится только по заданной строке
Если указан параметр <Колонка>, то поиск производится только по заданной колонке
Итоги и группировка таблицы значений
//часто требуется группировать строки и подсчитывать итоги по группам,
//в этом случае применяется метод Свернуть
Удаление строк и колонок из таблицы значений
ВНИМАНИЕ
Часто требуется удалить строки, удовлетворяющие определенному условию.
Так как при удалении строки из таблицы значений следующая строка становится текущей,
то указанная ниже программа может удалить НЕ ВСЕ необходимые строки.
В этом случае я рекомендую использовать следующий прием:
А вот еще один правильный алгоритм, предложенный Wlad:
Замечание(Туц). Предыдущий вариант не совсем правильный. Случай, когда последняя строка попадает под условие и в условии идёт обращение к строке таблицы, приводит к ошибке. Т.е. происходит попытка чтения для строки 0.
И ещё вариант, предложенный Туц:
Замечание (vligm). А я использую такой алгоритм (это, собственно говоря, шаблон):
Таблица значений как элемент диалога
Таблица значений может использоваться в экранных формах как элемент диалога с пользователем.
Методы УстановитьЗначение и ПолучитьЗначение
Эти методы позволяют обращаться к данным в таблице значений для чтения и записи.
Они могут пригодиться в особых случаях при написании универсальных программ (мастеры отчетов и т.д.).
Синтаксис: УстановитьЗначение(<Строка>,<Колонка>,<Знач>)
Синтаксис: ПолучитьЗначение(<Строка>,<Колонка>)
Таблица значений (далее ТЗ) - универсальная коллекция, наиболее близко моделирующая "классическую" таблицу базы данных. Она имеет колонки различных типов, в т.ч. неопределённого "произвольного" типа, и строки с содержимым; свойства и методы для работы с колонками и строками. Всё это, надеюсь, общеизвестно, изложено в десятках статей и есть в СП. ТЗ можно заполнять произвольным кодом, из наборов регистров, или по результатам работы запроса, построителя запроса, процессора СКД, загружать из табличных частей, заполнять массивами. В ТЗ есть выгрузка журнала регистрации и результатов поиска ссылок. ТЗ можно использовать для заполнения таб.частей, наборов регистров, как источник данных в запросах, построителях запросов, построителях отчётов и наборах данных СКД. ТЗ является входным аргументом и результатом специальных функций СКД, в т.ч. расширяющих возможности встроенного языка 1С.
ТЗ работает в COM-обмене, где поддерживает те же методы (включая и индексацию на стороне базы-провайдера), за малыми исключениями допускается русскоязычная нотация в свойствах и методах.
ТЗ сериализуется в XDTO. Наряду с деревом значений, ТЗ не существует на тонком и веб-клиенте, хотя сериализуется для обмена с сервером; в толстом клиенте может являться реквизитом формы "в естественном виде" и с интерфейсной ипостасью, а также с модальным окном просмотра/выбора, в тонком клиенте существует на сервере, а на клиенте отображается специальной коллекцией. Также может являться реквизитом (в т.ч. явно указанного типа), например, у отчётов и обработок. ТЗ удобно просматривается отладчиком. За уникальными исключениями, чтение и запись ТЗ всегда монопольны, что устраняет все проблемы конкурентного доступа.
Размещение
ТЗ всегда существует в сеансовых данных. Сеансовыми данными рулит менеджер кластера, и если в нём несколько серверов, то сеансовые данные располагаются равномерно по всем серверам (если, конечно, не указаны требования функциональности). ТЗ может быть сформирована одномоментно, некоей выгрузкой, или расти постепенно, но платформа обрабатывает ТЗ всегда одинаково - блоки по 64 МБ (больше бывает только при помещении во временное хранилище согласно мнению rmngr'а о производительности) выделяемые менеджером кластера, пишутся в конец файла сеансовых данных. Как и другие коллекции, ТЗ сначала размещается в памяти rphost, потом бинарным потоком передаётся rmngr'у. В отличие от других сеансовых данных, чей срок жизни считается по открытой форме, или по серверным вызовам, данные ТЗ считаются актуальными до конца сеанса или существования указателя на таблицу (имени переменной, реквизита экземпляра отчёта/обработки). Если ТЗ заняла более четверти объёма файла, то выделение блоков происходит с учётом прочих актуальных сведений в файлах, каждые 5 сек. делается актуализация и сборка мусора. Если ТЗ невелика, то актуальные сеансовые данные копируются в новые файлы, а сборка мусора идёт потом.
Сеансовые данные обычно располагаются в папке \1cv8\srvinfo\reg_1541\snccntx, дописанной специфическим UID, и лежат там в файлах вида snccntx.000057F1.dat (по сути это noSQL key-value storage). Конкурентный доступ к ним в норме невозможен (если только не задвоились процессы rmngr в памяти и не смотрят на одну и ту же папку реестра кластера). Таким образом, для работы с ТЗ не важен сервер СУБД и она сама, а важна скорость дисковой подсистемы ПК, где лежат сеансовые файлы, и мощность процессора, обрабатывающего их. Особенно это стоит учитывать при совмещении серверов СУБД и приложения. Также, очевидно, поведение ТЗ на разных СУБД и в файловом варианте идентично и в логическом, и в физическом чтении. При этом существует несколько ситуаций, определяемых платформой согласно объёму данных, когда индексы ТЗ размещаются в ОЗУ сервера приложений на время их перестроения.
Типизация
ТЗ, как и другие универсальные коллекции, может содержать простые и ссылочные типы, другие коллекции, com-объекты, системные перечисления, указания на экземпляры объектов, модули, служебные переменные и т.д. Для этого достаточно не объявлять тип колонки, а оставить на откуп платформе - описание типов такой колонки пусто, а квалификаторы определены по умолчанию (длина 0, точность 0, любые длина и знак, любые части даты), и это не мешает заносить туда простые типы, вроде бы противоречащие квалификаторам. При явном указании типа ТЗ контролирует это: если знаков дробной части недостаточно для числа, то округляет (причём 0.5 округляет всегда до 1); если не влезает строка - обрезает; если объявлена фиксированная строка и реальная длина меньше, то дописывает пробелами; сообразно обрезает дату/время - словом, всё ожидаемо. Если тип колонки строковый, то возможны дополнительные свободы преобразования (так, ЗаполнитьЗначения, где указано значение другого типа для внесения в строковую колонку, отработает, внеся строковое представление значения; аналогично работает ЗагрузитьКолонку). "Никакое" значение имеет тип "Неопределено", при работе с запросами и внешними источниками может содержаться и Null (как наряду с другими типами, так и в качестве единственного типа, и наполнения, колонки). Изменить тип колонки ТЗ невозможно (даже для произвольного), нельзя изменять и свойства квалификаторов.
При передаче ТЗ в параметр запроса и в конструктор описания источника данных для построителя запроса/отчёта чёткая типизация обязательна. Для источника набора данных СКД это не требуется (поля набора не будут никак типизированы), но по опыту желательно. В ранних релизах 8.3 произвольный тип колонки в коллекции на клиенте не поддерживался, в толстом клиенте при конфигурировании его нельзя сделать и поныне (но можно создать и отобразить программно).
События, касающиеся ТЗ, отслеживаются в технологическом журнале только косвенно - это, конечно, "ALL", а также "MEM" (увеличение объёма памяти под серверные процессы); на 8.2.16-19 иногда наблюдался "LEAKS", связанный с ТЗ. Русскоязычные упоминания ТЗ в logcfg в ряде случаев могут вызывать ошибку и логи тихо перестают писаться.
Строка таблицы значений
Элемент таблицы - строка ТЗ - самостоятельный объект языка, и по сути она же - первичный внешний ключ. Ссылка на строку ТЗ и массив ссылок, найденный поиском, всегда содержит активные ссылки на строки; изменение данных в них сказывается на ТЗ; строка может храниться в той же ТЗ, в переменной и любом соответствующем реквизите формы или объекта. При удалении строки и очистке ТЗ такая переменная по-прежнему имеет тип "СтрокаТаблицыЗначений", но операция со значениями её колонок вызывает ошибку чтения, а с ней самой в рамках ТЗ вызывает ошибки, свидетельствующие об индексовой, "ключевой" сути строки - "индекс за границами диапазона". Тип свой такая переменная (и массив таких переменных) сохранит, даже если сама ТЗ уничтожена, осталась в покинутом контексте или явно очищена, что может стать причиной утечек памяти. Аналогичный эффект наблюдается при свёртке - если некая строка сохранена в переменной, но исчезла в результате свёртки, её тип остаётся, но работа с ней невозможна. Никакую ссылочную целостность 1С для ТЗ не проверяет.
Явные номера строк в ТЗ можно организовать либо добавлением соответствующей колонки и заполнением в цикле, либо запросом, либо использованием служебного поля СКД "НомерПоПорядку". Также, номера образуются при выгрузке из табличной части - при этом появляется колонка с именем "НомерСтроки", заголовком "N", типом "Число" с пустым квалификатором, нумерация в ней идёт не с 0, а с 1. Неявная нумерация строк организована платформой - важно, что это не доступный в языке первичный ключ, а внутреннее служебное поле.
Изменение содержимого
Добавление данных выполняется только построчно. Метод "ЗагрузитьКолонку" заполняет уже имеющиеся строки, начиная с нулевой, столько, сколько есть (если массив больше по размеру, остальное пропадёт), т.е. если строк нет, не добавляет их. Метод "ЗаполнитьЗначения" также оперирует имеющимися строками. Если надо вставлять блоки данных, разумно использовать метод, предложенный Гилёвым: тз.Индексы.Добавить("Кол1,Кол2,Кол3"); // 1-й индекс, покрывающий все колонки тз.Индексы.Добавить("Кол2"); // 2-й индекс, работающий с одной колонкой тз.Индексы.Добавить("Кол3,Кол1"); // 3-й индекс, по 2 колонкам в обратном порядке
Индексы используются при поиске методами "Найти" и "НайтиСтроки", причём для "НайтиСтроки" критически важно точное совпадение порядка колонок в конструкторе структуры отбора с порядком в индексе, поэтому рекомендуется явный конструктор "Структура("Поле1,Поле2",знч1,знч2)". При таком поиске идёт перебор ключей структуры, неприменимые индексы и индексы с лишними элементами отбрасываются, и если платформа находит подходящий индекс, то задействует его. Пример:
У индексов примерно с 8.2.16 нет ограничения на количество полей, длину ключа (900 байтов, 16 колонок), т.к. применяется хэш по ключу полей, что несколько медленнее привычных индексов СУБД. Ни о какой статистике, оценке фрагментированности и прочая для ТЗ речи не идёт, а выбор полей для индексации (согласно их содержимому, селективности итд) целиком на разработчике.
Построение/перестроение индексов выполняется сервером приложения, даёт пик по занятости процессора и активности диска, незначительно по % использования памяти. Файлы подкачки не используются. При индексном поиске идёт обращение к диску (% активности серьёзно колеблется), виртуальная держится стабильно. При безындексном вся нагрузка ложится на процессор. Поиск по индексированным и неиндексированным полям вместе, либо поиск по нескольким полям, порядок и состав которых не имеют точного совпадения ни у одного из индексов, в плане нагрузки на оборудование всегда является безындексным.
Зависимость индексов от изменений ТЗ
Изменение может касаться состава колонок. При удалении колонки индекс по ней остаётся (с пустым значением, неработоспособный), если индекс был по нескольким колонкам и часть их удалена, весь индекс также остаётся и также неработоспособный; при очистке всех колонок индексы остаются; это тоже утечка памяти. При переименовании колонки индекс по ней остаётся работоспособным, его представление меняется автоматически.
Изменение может касаться состава строк. Наиболее ресурсозатратно добавление/вставка строк в индексированную таблицу, это сильно загружает процессор и на 60-70% медленнее добавления в неиндексированную. Чем больше есть индексов, тем больше также загружен диск. Падение скорости при перестроении индексов для каждого добавления строки нелинейно, связь между характером и порядком индексов и содержимым строк не прослеживается. Рекомендуется сначала добавлять строки, потом строить индекс. Пример:
Если индексы уже есть, разумнее их удалить и создать заново, если добавляется более 1/4 от прежнего объёма ТЗ.
Перестроение индексов происходит при изменении содержимого конкретных ячеек, причём присвоение значения - это сразу перестроение, и это ещё одна причина использовать ЗаполнитьЗначенияСвойств - при её применении индексы перестраиваются, когда процедура отработала по всем колонкам строки. Методы ЗаполнитьЗначения и ЗагрузитьКолонку вызывают разовое перестроение индексов по завершении своего выполнения, и тоже выполняются на 30-35% медленнее, чем при работе с неиндексированной ТЗ.
Изменение может касаться сразу и колонок, и строк - это метод Свернуть(). При любой свёртке, даже если колонки индекса остаются в качестве группировочных (а равно и суммируемых), все индексы удаляются автоматически.
Вплоть до 8.3.8 включительно при изменении значения в колонке, не входящей ни в какой индекс, всё равно происходило перестроение индексов; потом это исправили.
При уничтожении, полной перезагрузке или переинициализации ТЗ все индексы удаляются автоматически.
Особенности индексов
Ни индексный, не безындексный поиск не кэшируются, поэтому скорость их повторного выполнения примерно равна скорости первоначального.
Поведение построения индексов и поиска для колонок, имеющих несколько типов, зависит от этих типов (несмотря на хэширование); так, для простых типов отличие от работы с однотипной колонкой минимально, если есть ссылочные типы и системные значения/системные перечисления - в среднем на 5% дольше. Если наполнение состоит из ссылок на формы и модули, скорость даже выше на 2-3%, чем для простых типов. Для наполнения из сложных коллекций прямой зависимости не выявлено.
Строки неограниченной длины индексируются в общем порядке и поиск правильно находит фрагменты любого размера; скорость индексации и поиска не отличается от таковой по иным простым типам. Хранилища значений индексируются и ищутся аналогично, прямой зависимости от объёмов не выявлено.
Сортировка индексированной таблицы в релизах до 8.3.9 медленнее на 10-15%, чем неиндексированной, даже если делается по неиндексированным полям; в новых релизах - медленнее на 2-5%.
При использовании ЗначениеВСтрокуВнутр и ЗначениеВФайл, и обратно, при сериализации через СериализаторXDTO, индексы сохраняются и работоспособны, время выполнения этих действий практически не зависит от наличия и характера индексов.
При передаче по ссылке, т.е. "ТЗ2=ТЗ1", при ТЗ2=ТЗ1.Скопировать() и Скопировать(,""), индексы сохраняются и работоспособны. Но при любом прямом указании колонок, в т.ч. если копируются все индексированные колонки, сами индексы не копируются. При указании любых отборов на строки индексы не копируются. Копирование индексированной ТЗ в среднем на 10-20% дольше копирования неиндексированной, в зависимости от её объёма и характера индексов.
При передаче ТЗ в процедуру/функцию и присвоении реквизиту соответствующего типа, при возвращении функцией - индексы сохраняются и работоспособны, единожды сделанные индексы везде "сопровождают" ТЗ. Важно, что директива "ЗНАЧ" в объявлении аргументов игнорируется: индексы, добавленные/изменённые для ТЗ внутри процедуры/функции, продолжают существовать и работать по её завершении, вне её контекста. Изменения ТЗ и индексы никак не связаны с принудительно объявляемыми транзакциями.
Явное удаление ненужных индексов или очистка всех индексов означает немедленный вызов сборщика мусора сеансовых данных.
Любая таблица значений состоит из колонок, каждая из которых имеет свой тип и уникальное название, а также из строк. Если таблица значений размещена на управляемой форме в виде элемента Таблица, то колонки создаются изначально на этапе разработки, а строки пользователь может создать самостоятельно, нажав на кнопку «Добавить» в командной панели этой таблицы.

Также пользователь может удалять строки или перемещать. Но, гораздо интереснее программная работа со строками таблицы значений.
Программное добавление строк таблицы значений в 1С
Для того чтобы создать новую строку таблицы значений, используется метод Добавить, данный метод не имеет параметров и является функцией.
Новая строка таблицы значений создается следующим образом:
НоваяСтрока = ФИО.Добавить();
Как видите, с помощью метода Добавить мы создали переменную НоваяСтрока, тип значения которой Строка таблицы значений. Но, просто создать строку мало, нам еще необходимо записать в нее определенные данные. Как получить доступ к колонкам данной строки?
Осуществить это можно двумя способами:
Допустим, у нас есть некоторая таблица значений ФИО с колонками Фамилия, Имя, Отчество, ФИО и ДатаРождения, то добавить новую строку этой таблицы и заполнить колонки этой строки можно следующим образом.
С помощью метода Добавить мы создаем строку, которая вставляется в конец таблицы значений. Для того чтобы поместить строку в нужное место таблицы значений, необходимо использовать метод Вставить. Параметром данного метода является индекс, на который вставляется данная строка.
Добавим с помощью этого метода еще одну строку в таблицу ФИО. И поставим ее на первое место.
Программный обход строк таблицы значений в 1С
Оператор цикла Для…Цикл.
В этом цикле нам необходимо получить индексы всех строк, для этого мы осуществляем обход, начиная с нуля и заканчивая значением, которое возвращает метод Количество за минусом единицы.
Когда мы используем квадратные скобки применительно к таблице значений (например, ФИО[н]), то результатом данной операции является строка таблицы с соответствующим индексом.
Индекс строки таблицы значений
Каждая строка имеет свой уникальный индекс. Все индексы идут по порядку и начинаются с 0. Для того, чтобы узнать индекс нужно строки необходимо применить метод Индекс таблицы значений, где в качестве параметра указать нужную строк.
В этом коде в переменную Инд будет записываться индекс строки при каждой итерации цикла.
Программное удаление строк таблицы значений
Для программного удаление определенной строки таблицы значений нужно использовать метод Удалить этой таблицы. В качестве параметра указывается или индекс нужной строки или сама строка.
ФИО . Удалить ( 0 )
У новичков основные сложности возникают, когда нужно удалить несколько строк из таблицы значений. Если делать обход таблицы значений циклом, то данное удаление пройдет не совсем корректно. Я в этом случае поступаю так: сохраняю нужные строки в массиве, а потом обхожу этот массив циклом и уже в нем их все удаляю. Получается примерно так:
МассивДляУдаления = Новый Массив ;
Для Каждого Стр из ФИО цикл
Если тогда //какое-то условие
МассивДляУдаления . Добавить ( Стр );
КонецЕсли
КонецЦикла;
Для Каждого СтрМассива из МассивДляУдаления Цикл
ФИО . Удалить ( стрМассива )
КонецЦикла

Отличное пособие по разработке в управляемом приложении 1С, как для начинающих разработчиков, так и для опытных программистов.
- Очень доступный и понятный язык изложения
- Книга посылается на электронную почту в формате PDF. Можно открыть на любом устройстве!
- Поймете идеологию управляемого приложения 1С
- Узнаете, как разрабатывать управляемое приложение;
- Научитесь разрабатывать управляемые формы 1С;
- Сможете работать с основными и нужными элементами управляемых форм
- Программирование под управляемым приложением станет понятным
Если Вам помог этот урок решить какую-нибудь проблему, понравился или оказался полезен, то Вы можете поддержать мой проект, перечислив любую сумму:
можно оплатить вручную:
Продолжаем изучать программную работу с таблицей значений в 1С. В прошлых статьях мы научились создавать таблицу значений (как программно, так и на управляемой форме), добавлять колонки и строки таблицы значений. Осталось научиться работать с самой таблицей значений. В первой части мы узнаем, как находить строки по нужному отбору, и научимся копировать таблицу значений с нужным отбором.
Поиск в таблице значений 1С 8.3
Поиск в таблице значений можно осуществить с помощью двух методов: Найти и НайтиСтроки. Метод Найти является функцией, которая вернёт первую строку, где встречается искомое значение. Рекомендуется метод применять для поиска уникальных значений, т.к. при наличии нескольких строк с искомым значением, будет возвращена только одна. Если же нам нужно найти все строки, где встречается искомое значение, то необходимо использовать метод НайтиСтроки, который возвращает массив строк с нужным значением.
Разберем оба этих метода на примере.
Метод Найти таблицы значений 1С 8.3
Этот метод является функцией, которая возвращает строку, если искомое значение найдено, и Неопределено, если нет. При помощи этого метода можно найти любое значение, которое имеется в таблице значений. Причем, не обязательно знать колонку, где это значение может содержаться.
Данная функция имеет следующий синтаксис:
Найти(Значение, Колонки)
Значение – то значение, которое мы ищем в таблице.
Колонки – колонки таблицы значений, по которым осуществляется поиск (необязательный параметр, можно осуществлять поиск по всем колонкам таблицы значений).
Работа этого метода показана на следующем примере:
Если мы посмотрим на значение переменной стрТарасов в отладке, то увидим ссылку на конкретную строку таблицы значений.

Точно такой же результат будет, если мы очистим второй параметр.

Если же мы сделаем поиск по второй колонке, то результат будет Неопределено.

Такой же результат Неопределено будет и при поиске несуществующего значения.

Метод НайтиСтроки таблицы значений 1С 8.3
Если метод Найти возвращает конкретную строку таблицы значений, то метод НайтиСтроки, возвращает массив строк, которые соответствуют нужному условию. Данный метод имеет следующий синтаксис
НайтиСтроки(СтруктураПоиска)
Переделаем предыдущую таблицу значений:
Теперь найдем все строки таблицы значений, где встречается имя Петр
Посмотрим на результат.
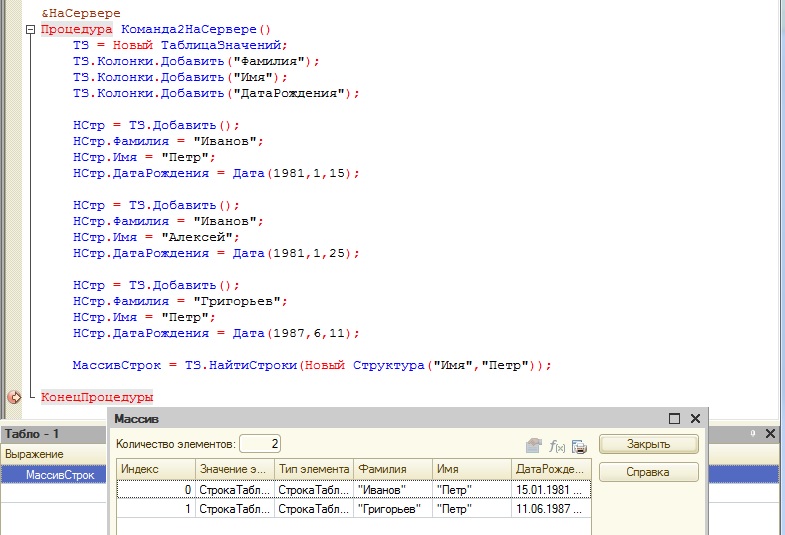
Или найдем всех Петров, родившихся 11.06.1987 года.
В этот раз найденных строк будет меньше.

Если же мы зададим имя, которого нет в нашей таблице, то получим пустой массив.

Причем обратите внимание, в массиве содержится ссылка на строку таблицы значений. Это значит, что если Вы измените строку в массиве, то также изменится строка в таблице значений.
Скопировать таблицу значений 1С
В языке разработке 1С можно одну таблицу значений скопировать в другую. Причем можно просто скопировать структуру таблицы значений, т.е. создать точно такую же таблицу значений, с тем же набором колонок, но без строк. Такое копирование осуществляется при помощи метода СкопироватьКолонки. А также скопировать одну таблицу в другую с различными отборами, это можно сделать, используя метод Скопировать. Разберем оба этих метода.
Метод СкопироватьКолонки таблицы значений 1С 8.3
Данный метод является функцией, которая возвращает пустую таблицу значений, с набором колонок, как у изначальной. У этого метода следующий синтаксис:
СкопироватьКолонки(СписокКолонок)
Где, параметр СписокКолонок необязательный параметр, в нем должны быть перечислены имена колонок, которые присутствуют в изначальной таблице, и которые должны быть в новой. Если он не указан, то в новой таблице значений будут такие же колонки, что и в изначальной.
В примере выше, в таблице НовТЗ1 будет тот же набор колонок, что и в таблице ТЗ, а в таблице НовТЗ2 будут только колонки Фамилия и Имя.
Метод Скопировать таблицы значений 1С 8.3
Научимся копировать одну таблицу значений в другую, а в этом нам поможет метод Скопировать. Этот метод является функцией, которая возвращает новую таблицу значений. У него имеется два синтаксиса
Скопировать(Строки,Колонки)
Строки – массив строк таблицы значений, которые должны будут присутствовать в новой таблице. Необязательный параметр, если он пуст, то копируются все строки.
Колонки – строка имен колонок, которые перечислены через запятую. Также необязательный параметр, если он пуст, то в новой таблице будут все колонки.
Второй вариант синтаксиса
ПараметрыОтбора – структура, при помощи которой мы отберем нужные строки в новую таблицу значений. В качестве ключей структуры должны быть перечислены названия колонок, по которым будет вестись отбор, а в качестве значений – те значения, по которым должны отобраться нужные строки.
Рассмотрим примеры с обоими вариантами параметров. Будем использовать ту же таблицу, что и в предыдущих примерах, но отберем только те строки, у которых год рождения 1981.
Посмотрим на результат работы этой функции
Теперь скопируем таблицу значений, так, чтобы в новую таблицу вошли только те строки, где есть имя Петр и дата рождения равна 15.01.1981.
В этот раз будет следующий результат.

Если Вам помог этот урок решить какую-нибудь проблему, понравился или оказался полезен, то Вы можете поддержать мой проект.
Более подробно и основательно работа с таблицей значений в дается в моей книге:
Отличное пособие по разработке в управляемом приложении 1С, как для начинающих разработчиков, так и для опытных программистов.
Читайте также: