
Почему в программе abbyy finereader при работе с ластиком появляется серый цвет
Подскажите . ABBYY FineReader не желает воспринимать сканер(Samsung SCX-4200) ,хотя его полностью видит, после начала сканирования
пишет "Автоподатчик пуст .Поместите изоброжение или документ в устройство подачи " , в чём может быть проблема ? При помощи стандартной проги сканирует без вопросов .
запусти файн ридер далее по вкладкам : сервис/опции/1.сканировать\открыть и переключи использовать интерфейс сканера. ок. И будет тебе счастье с Samsung SCX-4200:beer:
После сканирования и распознавания pdf в вордовском файле появилась куча разрывов. Как их убрать (разрыв раздела, разрыв страницы, разрыв колонки)?выделить текст, нажать правой кнопкой мыши и выбрать "абзац", и там, проставить нужные значения. Лучше, с левой стороны всё по нулям проставить. А дальше,- видно будет
Но, всё-таки не всё понятно что было сканировано и что получилось и как?
"Несовпадение типов"
Но, скорее всего старая версия Ворда
Так что не стоит петь диферамбов девятке, как это делают на многих форумах и верить рекламе.
С первых же дней у меня было точно такое же впечатление
Восьмая обеспечивает и качество и скорость, что немаловажно, когда времени в обрез.
Что восьмёрка прекраснее девятки
Но, если уж быть справедливыми, у девятки есть то преимущество, что DejaVu распознаёт. И ещё одну вещь она делает неплохо,- выравнивание строк, если в книге кривоватые строки. Не всегда, правда, но всё же. иногда. Даже очень хорошо выравнивает. На фоне остальных недостатков вроде бы мелочь, но, иногда, приятная и полезная.
В FineReader перед распознанием можно как то автоматически выделять для распознавания четные или нечетные страницы?
Непонятно зачем это может понадобиться. Но ладно.
Кажется, это можно сделать только выделив страницы по отдельности
Нажать Ctrl и держа нажатой мышкой выделять нужные страницы
Потом нажать на кнопочку "Распознать"
выделить текст, нажать правой кнопкой мыши и выбрать "абзац", и там, проставить нужные значения. Лучше, с левой стороны всё по нулям проставить. А дальше,- видно будет
Но, всё-таки не всё понятно что было сканировано и что получилось и как?
Проблема решилась просто : все разрывы после finereader-a были массово заменены на пробелы
Возможно, окончательная победа цифровых технологий уже не за горами, но сегодня мы все еще находимся в переходном периоде и вынуждены приводить разнородные потоки и источники информации к «общему знаменателю». Оцифровка печатных материалов (OCR, Optical Character Recognition), одна из наиболее типичных задач, хорошо знакома отечественным пользователям и на просторах СНГ однозначно ассоциируется с ABBYY FineReader. Популярность этого продукта вполне заслуженна, а компания-разработчик не почивает на лаврах и неутомимо отслеживает современные тенденции и развивает свое детище. Так, в девятой версии FineReader стал работать не с отдельными блоками или даже страницами, а с целыми документами (ADRT, Adaptive Document Recognition Technology), что позволило ему гораздо правильнее воссоздавать их структуру, включая такие элементы как таблицы, колонтитулы и пр. В десятой приоритет сместился в сторону качественной обработки изображений, полученных не со сканеров, а с цифровых фотокамер. Популярность последних продолжает расти, так, согласно информации ABBYY, фотокамеры для оцифровки печатной продукции (учебников и научной литературы, юридических и деловых документов, газет и журналов, анкет и пр.) применяют более 30% пользователей. Представленный в конце августа FineReader 11 также имеет немало полезных нововведений, хотя выделить главное направление довольно сложно. Скорее, в нынешней версии разработчики сосредоточились на совершенствовании накопленных технологий и, конечно, на повышении удобства работы.
Общая информация
На текущий момент доступны две редакции FineReader 11 — Professional и Corporate. Home пока осталась в 10-й версии. На сайте ABBYY есть довольно объемная таблица с описанием возможностей всех трех редакций, хотя проводить такое сравнение не совсем корректно — наверняка со временем появится и FineReader 11 Home Edition, который сократит отставание от старших собратьев. Однако принципиально картину это не изменит — функциональность редакции Home сильно урезана. Так, отсутствуют возможности обработки документов PDF, DjVu, XPS; распознавание штрихкодов; встроенный редактор; вывод во многие форматы; поддержка многоядерных процессоров и пр. Конечно, кому-то базовой функциональности будет достаточно, особенно для эпизодического применения, но в общем случае сниженная стоимость не компенсирует потери.
- возможность создавать пользовательские сценарии, аналогичные встроенным типовым задачам;
- режим совместной работы с одним документом, когда несколько пользователей могут параллельно выполнять различные действия;
- передачу документов на серверы SharePoint;
- режим Цензура, позволяющий в буквальном смысле вымарать лишнюю информацию, причем, в документах, которые поддерживают графический и текстовый слои, она будет удалена из обоих;
- программу ABBYY Hot Folder, обеспечивающую автоматическую обработку документов, поступающих в папку, почтовый ящик или на FTP-сервер;
- программу ABBYY Business Card Reader для преобразования визиток в электронные контакты.
Системные требования и установка
- операционная система Windows XP, Windows Server 2003 или более новая;
- процессор с частотой от 1 ГГц;
- объем оперативной памяти не менее 1 ГБ плюс по 512 МБ на каждое вычислительное ядро;
- 700 МБ дискового пространства непосредственно для установки и столько же для рабочих файлов.
Программа более чувствительна к производительности процессора, ресурсы которого обычно задействуются на все 100%, чем к объему оперативной памяти.
Установка FineReader 11 довольно проста — настолько, что даже не описана в руководстве пользователя. Инсталляционная процедура запустится на языке, указанном в системных настройках, но на первом же экране можно выбрать нужную локализацию. Выборочная установка позволит отказаться от некоторых инструментов и функций, вроде ABBYY Screenshot Reader (для распознавания снимков экрана) и интеграции в сторонние приложения. Но все это относится к клиентской части, в основном, к редакции Professional. FineReader 11 Corporate в общем случае предполагает сетевое развертывание, описание которого приведено в руководстве администратора. С дистрибутивного диска вначале нужно установить сервер и менеджер лицензий. Последний представляет собой управляющую утилиту и также может размещаться на любой рабочей станции. Сервер лицензий на самом деле не требует серверной ОС, а учитывая минимальную вычислительную нагрузку, его вполне разумно установить в виртуальной машине. Принципиально только соединение с Интернетом, так как с помощью менеджера лицензий необходимо регистрировать и активировать имеющиеся лицензии.
Для установки FineReader 11 Corporate на рабочие станции есть несколько способов, самый простой (но не всегда самый эффективный) — формирование административного дистрибутива в папке общего доступа и запуск инсталляции на каждом рабочим месте. При этом все параметры сервера лицензий будут прописаны автоматически, так что никаких дополнительных действий не понадобится. При использовании per-seat лицензий FineReader 11 Corporate можно устанавливать и локально.
Работа с FineReader 11
Несмотря на то, что за ABBYY FineReader стоит целая отрасль искусственного интеллекта и весьма изощренные алгоритмы, сама по себе программа достаточно проста и интуитивна. По сути она решает одну единственную задачу — распознавание текста, соответственно, в ней нет изобилия инструментов и сложных меню, хотя все необходимые опции и средства появляются при работе с конкретными объектами, будь то изображение, выделенный блок или распознанный текст. За последнее время интерфейс программы практически не менялся (никаких «лент») и это хорошо, так как пользователи предыдущих версий найдут привычные инструменты на своих местах. Работать с FineReader можно двумя основными способами: либо воспользоваться одним из типовых сценариев, к примеру, со сканера сразу в EPUB, либо проделать основные операции вручную. В любом случае обработка документов состоит из четырех основных этапов: получение изображения, его распознавание, проверка, сохранение результата, — и на каждом доступно некоторое количество опций и дополнительных возможностей, способных существенно повлиять на качество результата. С опытом каждый пользователь отработает собственный стиль взаимодействия с FineReader, но для начала вполне разумно полагаться на автоматические настройки, тем более, что программа оповестит о всех проблемах, скажем, о необходимости отсканировать с большим разрешением оригиналы, на которых имеется мелкий шрифт. Кроме того, в рабочем документе отмечаются все неуверенно распознанные символы, так что их можно будет быстро проверить, в том числе, в специальном окне с укрупненным фрагментом оригинала. В большинстве случаев FineReader и сам примет правильные решения, особенно если сомнения возникают в известных словах, в противном случае имеет смысл добавить слово в словарь и повторить распознавание. При возникновении большого количества ошибок следует обратить внимание на качество оригинала и его изображения — это самый важный фактор, нивелировать который в дальнейшем практически невозможно.
Для сравнения доступных режимов обработки был проведен небольшой тест. В качестве оригинала был взят 10-страничный, отпечатанный на цветном принтере материал со сравнительно сложной версткой, но почти без иллюстраций. Такое задание можно считать достаточно типичным, так как главной задачей программ распознавания является именно извлечение текста. Затем в опциях FineReader 11 была отключена автоматическая обработка и сформированы три документа: один в черно-белом режиме и два в цветном, отсканированные в цвете и в оттенках серого. Сканирование выполнялось на МФУ с разрешением 300 dpi, что также является типичной ситуацией. Все прочие настройки FineReader 11 не менялись, в частности, использовался тщательный режим собственно распознавания. Серии операций по распознаванию проводились на компьютере с двухъядерным процессором, усредненные результаты можно видеть в следующей таблице:
Табл. Сравнение различных режимов обработки документаНесмотря на достаточно высокое качество оригинала, в черно-белом режиме значительно большее число символов было распознано неуверенно. Однако, львиная доля их приходилась на фрагменты с изображениями. При этом на одной чисто текстовой странице лучшее качество распознавания оказалось именно в черно-белом режиме. Сканирование в оттенках серого считается ABBYY FineReader 11 оптимальным для OCR, с чем, пожалуй, можно согласиться, глядя на результаты теста. По физическим характеристикам, в том числе скорости, серый режим близок к черно-белому, а по качеству распознавания — к цветному. Справедливости ради, отметим, что результаты в черно-белом режиме было несложно значительно улучшить, предварительно разметив иллюстрации или добавив в словарь несколько часто встречающихся в документе аббревиатур (в них программа ошибалась наиболее часто). Тем не менее, цветной режим со сканированием в оттенках серого действительно выглядит не компромиссом, а оптимальным выбором.
Дополнительные возможности
Несмотря на прозрачность работы и наличие типовых сценариев, ABBYY FineReader 11 имеет в своем арсенале и достаточно тонкие инструменты, которые при умелом использовании существенно могут облегчить жизнь пользователям. К примеру, программу можно обучить для работы с декоративными шрифтами или специальными символами (вначале, конечно, следует убедиться, что она с ними не справляется). Хотя это довольно трудоемкий процесс, и применять его целесообразно только в исключительных случаях. Другим примером могут служить шаблоны областей для обработки однотипных документов. Достаточно проанализировать один образец, скорректировать его разметку, выделить нужные блоки и сохранить шаблон. В дальнейшем его можно будет применять к аналогичным документам, не повторяя рутинную работу. В полной мере возможности этой функции раскрываются при использовании вместе с Hot Folder для автоматической обработки документов.
ABBYY Hot Folder, в свою очередь, является одним из дополнительных компонентов FineReader 11 (только редакции Corporate). Это специализированный планировщик, управляющий заданиями для автоматической обработки документов. По указанному расписанию он может проверять один из типов источников (папки, ftp-серверы, почтовые ящики, документы ABBYY FineReader, которые сами по себе также являются папками) и инициировать их обработку с предварительно настроенными параметрами. Типичное применение Hot Folder — централизованное распознавание документов, которые вводятся сотрудниками через сетевые МФУ. Как правило такие устройства умеют сохранять отсканированные изображения в папках общего доступа, за которыми как раз и будет следить Hot Folder.
Наконец, еще одно дополнение — ABBYY Screenshot Reader — присутствует в редакциях и Corporate, и Professional. Как и следует из названия, данная программа распознает информацию на экране компьютера (можно выделять окно или прямоугольную область). Таким образом, к примеру, можно быстро извлечь информацию о программной ошибке для поиска в базе знаний. Результат можно сохранять в файлах распространенных форматов или копировать в буфер обмена.
Резюме
ABBYY FineReader 11 сделал еще несколько шагов к тому, чтобы освободить пользователей от рутины и приблизить нашу жизнь к цифровому будущему. В программе внешняя простота сочетается с мощными алгоритмами, что позволяет даже неподготовленным пользователям добиваться хороших результатов. Все нововведения нынешней версии наверняка будут оценены по достоинству, начиная с повышенной производительности и заканчивая поддержкой популярных форматов электронных книг. Преимущества редакции Corporate также очевидны, хотя, с учетом более высокой стоимости лицензии, ее внедрение требует предварительной оценки реальной потребностей в OCR всех сотрудников.

Функциональное решение для сканирования документов ABBYY FineReader предоставляет возможность пользователю выбрать, в каком из популярных текстовых форматов сохранить файл. Помимо сканирования документации программа может перевести текстовую информацию из формата Word, например, в файл PDF обратно.
ABBYY FineReader 12, имеющаяся в наличии в SoftMagazin, обладает множеством полезных функций и значительно упрощает процесс распознавания текста и перевода его в формат PDF.
Как пользоваться программой ABBYY FineReader 12, описано в инструкции к программе, однако у пользователей могут остаться некоторые вопросы по ее настройке и запуску. В данном обзоре будут даны ответы о работе в ABBYY FineReader, как пользоваться этой программой, в частности последними ее версиями.
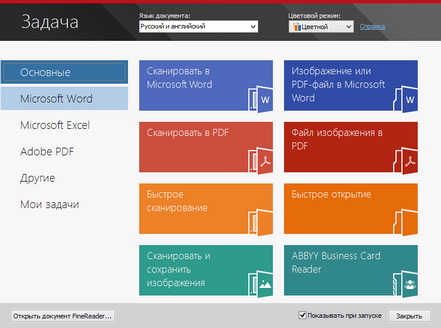
ABBYY FineReader: как работать
Для эффективной работы со сканируемыми документами нужно знать, для чего нужна ABBYY FineReader, как пользоваться основными функциями программы и правильно запускать ее. Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.
Особых различий в версии ABBYY FineReader 11, и как пользоваться 12 выпуском программы не наблюдается. Обе версии отличаются наличием хорошего функционала, поддержкой более 150 языков, в том числе и языков программирования и математических формул. Чтобы начать пользоваться программой, достаточно установить лицензионную версию на домашний или рабочий ПК и запустить ярлык ABBYY FineReader с рабочего стола или из меню Пуск.
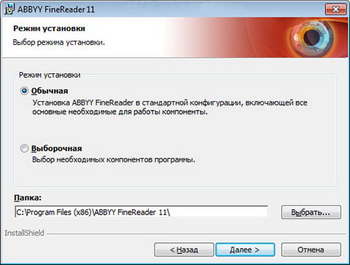
Как установить ABBYY FineReader 11
Для установки программы на ПК нужно после приобретения лицензии, запустить из папки с программой или диска файл setup.exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке.

Как запустить ABBYY FineReader
Запустить ярлык с рабочего стола компьютера
Выбрать в меню Пуск раздел Программы и запустить ABBYY FineReader
Если вы пользуетесь приложениями Microsoft Office, то достаточно нажать на инструментальной панели значок программы
Выберите в проводнике нужный документ и нажав правой кнопкой мыши, выберите в появившемся меню «Открыть с помощью ABBYY FineReader».
Как настроить ABBYY FineReader 12 Professional
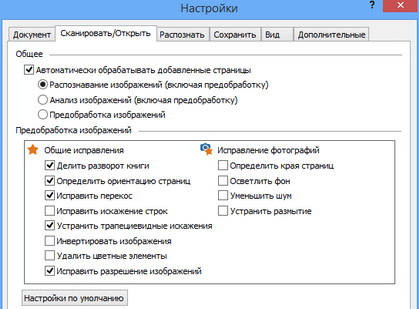
Профессиональная версия ABBYY FineReader приобретается организациями для эффективной работы с программой в корпоративной сети и совместного редактирования файлов. Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.
Все автоматические функции могут использоваться в ручном режиме. Для комфортной работы перейдите на панели инструментов в «Сервис» и выберите пункт «Настройки», чтобы отрегулировать параметры. Можно самостоятельно задать настройки вида документа, режима сканирования, распознавания и сохранения файла.
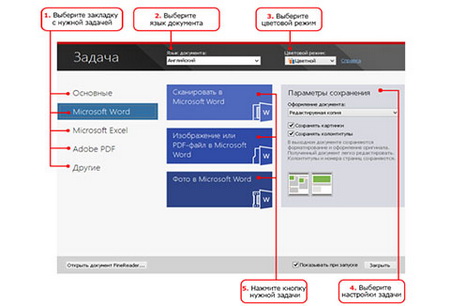
ABBYY FineReader - как переводить
Для качественной конвертации документов в программе предусмотрены встроенные стандартные задачи, используя которые можно перевести документ в нужный формат, затратив минимум усилий. Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания.
ABBYY FineReader: как распознать текст
Для качественной конвертации полученной информации в PDF-формат, программа должна ее распознать. В ABBYY FineReader можно установить режим автоматического распознавания текста или ручного. Качество отсканированного документа можно отрегулировать настройками распознавания, такими как: режим сканирования, язык распознавания, тип печати и многое другое. Перед распознаванием текста, на этапе сканирования программа будет работать по одному из стандартных сценариев, который можно выбрать.
В меню выберите «Сервис», перейдите в «Опции» и укажите режим распознавания: тщательное или быстрое распознавание. Тщательный режим будет удобен для работы с некачественными текстовыми файлами, текстами на цветном фоне или сложными таблицами. Быстрое распознавание рекомендовано для больших объемов файлов или когда ограничены временные рамки.
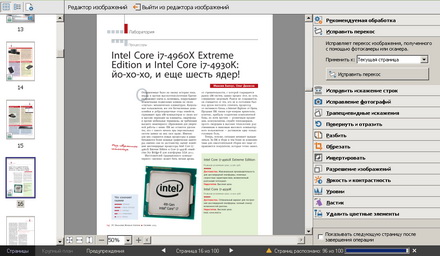
Как в ABBYY FineReader изменить текст
Чтобы не возникало сложностей при редактировании в ABBYY FineReader 12, как изменить текст в этой программе, разработчики создали интуитивно понятный интерфейс и удобную навигацию по пунктам. Отредактировать текст можно двумя способами: непосредственно в окне «Текст», либо выбрав на панели инструментов «Сервис» и далее «Проверка». Доступные средства для изменения текста находятся над окном «Текст» и включают в себя стандартный набор для редактирования шрифта, его размера, отступов и замены символов. Для редактирования непосредственно PDF-изображения, нужно зайти в меню в «Редактор изображений» и выбрать из списка нужную функцию.

Каждая следующая версия ABBYY FineReader становится всё более интуитивно понятной. В частности, в последние версии включена система встроенных сценариев, которые дают возможность выполнить стандартные последовательности действий за несколько щелчков мышью. Так мы стараемся облегчить работу с программой для большинства наших пользователей. И, тем не менее, FineReader обладает рядом возможностей, которые не лежат на поверхности, но могут быть полезны пользователям «продвинутым». О нескольких таких возможностях мы расскажем в этом посте.
Начнем с функции создания языков в ABBYY FineReader 10 Professional Edition. Для чего и кому это нужно? В основном, для тех, кто занимается распознаванием текста, содержащего много специфических конструкций, например, артикулов, небуквенных символов, аббревиатур или цифр. На первый взгляд кажется, что такие случаи бывают редко, но мы довольно часто сталкиваемся с подобными вопросами от наших пользователей. Например, интересный случай был описан на форуме FineReader, где пользователю нужно было распознать книгу по покеру, в которой, разумеется, встречались символы-масти. Чтобы решить проблему с корректным отображением мастей, мы посоветовали создать в программе новый язык. Эта процедура облегчает работу с подобными документами и значительно сокращает время их обработки. Сам процесс создания не займет много времени и не требует специфических знаний, здесь просто нужно быть внимательным. Чтобы вам легче было разобраться, мы покажем, как это делается.
Основной диалог, в котором настраиваются параметры нового языка, вызывается из меню Сервис -> Редактор языков нажатием кнопки Новый…. Язык создается на основе одного из существующих, поэтому перед тем как редактировать свойства нового языка, выберите тот, который будет принят за основу. Если текст, который вы будете распознавать, на русском языке, его и стоит выбрать в качестве базового. Открываем окно Свойства языка.

"
Нетрудно догадаться, что начинать данный процесс придется с создания алфавита. Нажимаем кнопку редактирования и попадаем в диалог с широкими возможностями для создания собственного алфавита: здесь можно добавить любые символы из более чем шестидесяти наборов – от привычной кириллицы до специальных математических и декоративных. Находим нужные символы, добавляем их в алфавит и закрываем окно редактирования.

После того как работа с алфавитом завершена, нужно выбрать словарь, который будет использоваться системой при распознавании и проверке, и указать дополнительные свойства (например, символы, которые могут встречаться в начале и конце слова и т.д.). Теперь FineReader готов к распознаванию вашего текста.
Когда вы создавали новый язык, наверняка заметили вторую опцию, доступную в диалоге Редактор языков – «Создать новую группу языков». Пригодится она тем, кому приходится распознавать документы, тексты которых составлены одновременно на нескольких нетрадиционных языках одновременно. Например, вам внезапно понадобилось распознать научную диссертацию, составленную на языках аймара, конго и зулу…
Сразу напомню, что в программе есть и предопределённые группы языков. Они используются для распознания документов, составленных на двух-трех распространенных языках, например, на русском и английском, или на английском, немецком и французском и т.д. Для таких документов создавать новую группу каждый раз совсем не обязательно. А если вам вдруг понадобится сочетание китайского упрощенного и простых химических формул, или английского и того, который вы ранее создали сами, то вам сюда. Смело устанавливайте флажок на опцию «Создать новую группу языков» и из предложенного списка выбирайте и добавляйте нужные вам языки. Не забудьте придумать оригинальное название для вновь созданной группы – тогда вы сможете использовать ее в следующий раз.
Следующая возможность – «Распознавание с обучением» – пригодится, когда нужно распознать текст, напечатанный декоративным шрифтом. В таких случаях составить алфавит из имеющихся символов просто физически невозможно, но зато вы сможете создать свой эталон букв, которые будут использованы в тексте, и с их помощью распознать декоративный шрифт. Еще эту возможность удобно использовать при распознавании текста с большим количеством сложных математических формул и для больших объемов текста плохого качества.
Если вы все же решились на создание эталона, отправляйтесь в меню Сервис -> Опции на вкладку Распознать. Здесь в группе Обучение нужно установить флажок в положение Распознать с обучением и нажать кнопку Эталоны, которая вызывает диалог создания нового эталона. Введите название для нового эталона, закройте все открытые диалоги и начинайте процесс распознавания. Как только встретится незнакомый символ, откроется диалог Ручное обучение эталона с изображением этого символа.


В результате распознавания вы получите именно те значения незнакомых символов, которым научили FineReader сами. Вот таким нехитрым способом происходит обучение FineReader. Кстати, созданные эталоны можно сохранять – тогда вы сможете их использовать их несколько раз, а также редактировать при необходимости.
Сегодня мы рассказали вам о двух возможностях FineReader, о которых вы, возможно, еще не знали и которые, быть может, окажутся вам полезными. Эти и другие интересные функции FineReader описаны в справке, поэтому рекомендуем вам иногда туда заглядывать.
Алиса Рахманова,
Департамент продуктов для распознавания текстов
В данной статье рассмотрим, как использовать Abbyy Finereader для распознавания текстов.
Как распознать текст с картинки при помощи Abbyy Finereader
Для того, чтобы распознать текст на растровом изображении, достаточно просто загрузить его в программу, и Abbyy Finereader автоматически распознает текст. Вам остается только редактировать его, выделив нужное и сохранить в требуемом формате или скопировать в текстовый редактор.
Распознать текст можно прямо с подключенного сканера.
Более подробно читайте на нашем сайте.
Как создать документ PDF и FB2 при помощи Abbyy Finereader
Программа Abbyy Finereader позволяет конвертировать изображения в универсальный формат PDF и формат FB2 для чтения на электронных книгах и планшетах.
Процесс создания таких документов схож.

2. Найдите и откройте требуемый документ. Он загрузится в программу постранично (это может занять некоторое время).

После сохранения можно остаться в режиме редактирования текста и перевести его в формат Word или PDF.
Особенности редактирования текста в Abbyy Finereader
Для текста, который распознал Abbyy Finereader предусмотрено несколько опций.
В исходом документе сохраните картинки и колонтитулы, чтобы они перенеслись в новый документ.

Проведите анализ документа, чтобы знать какие ошибки и проблемы могут возникнуть в процессе преобразования.

Редактируйте изображение страницы. Доступны опции кадрирования, фотокоррекции, изменения разрешения.

Вот мы и рассказали как пользоваться Abbyy Finereader. Он обладает довольно широкими возможностями редактирования и конвертирования текстов. Пусть эта программа поможет в создании любых нужных вам документов.

Отблагодарите автора, поделитесь статьей в социальных сетях.
Читайте также: