
Набор файлов из которых после компиляции получается программа это
Создание исполняемого файла из одиночного файла .c выглядит довольно просто. Сначала .c-файл компилируется в объектный код (файл .o -- "object"), который затем при помощи сборщика (loader; его еще называют линкером -- linker) с добавлением системных библиотек превращается собственно в исполняемый файл.
| Создание программы из одного исходного файла |
Большинство же программ состоят из нескольких исходных файлов (крупные программы содержат по несколько сотен и даже тысяч файлов). Эти файлы также компилируются в объектный код, а потом сборщик делает из них исполняемый файл.
| Создание крупной программы |
Многие пакеты состоят из нескольких исполняемых файлов, в этом случае каждый из них собирается точно так же. При этом многие пакеты содержат собственные библиотеки, которые также компилируются из исходных текстов в объектные файлы (совершенно аналогично обычным исходным файлам -- на рисунке это показано упрощенно для экономии места) и затем при помощи программы-библиотекаря (archiver) собираются в т.н. архивы -- файлы .a.
Компиляторы языка Си в Unix обычно называются cc (C Compiler), а зачастую (особенно в Linux) используется т.н. GNU C Compiler -- gcc . Компиляторы Си++ аналогично называются c++ и g++ . Сборщики именуются ld , хотя можно для этих целей пользоваться и gcc . Библиотекарь-архиватор -- программа ar .
| Практически все современные клоны Unix поддерживают также разделяемые библиотеки (именуемые .so (shared object) или .sa (shared archive)), которые подключаются к программе непосредственно перед исполнением (аналогично .dll в Windows). Собственно, большинство библиотек являются именно разделяемыми. Здесь мы разделяемые библиотеки не затрагиваем во-первых для краткости, а во-вторых потому, что обычно при компиляции никакого внешнего отличия между .a и .so нет. |
Утилита make
Для чего нужен make
Приведенная в предыдущем разделе картина способна повергнуть в уныние -- неужели все эти действия надо выполнять "вручную"?
Естественно, нет -- для этого существует утилита make , которая все и делает ("make" -- дословно "делать").
Утилита make считывает из специального файла с именем Makefile или makefile в текущей директории инструкции о том, как (при помощи каких команд) компилировать и собирать программы, а также информацию, из каких файлов состоит программа, которую надо "сделать".
Одним из главных достоинств make (чрезвычайно полезным при создании больших программ) является то, что он сравнивает времена модификации файлов, и если, к примеру, файл file1.c новее, чем получаемый из него file1.o , то make поймет, что перекомпилировать надо только его, а остальные -- не нужно (если они не изменились).
- Правила, как из одних файлов создавать другие (например, .o из .c ).
- Так называемые "зависимости", которые указывают, что, например, исполняемый файл proggie собирается из файлов prg_main.o и prg_funcs.o , а те, в свою очередь, получаются из файлов prg_main.c и prg_funcs.c .
- Определения переменных, позволяющие делать Makefile более гибкими.
Ниже приведен пример простейшего Makefile (он и используемые файлы .c доступны здесь):
В правилах всегда используются специальные переменные " $@ " и " $< ". Переменная " $@ " обозначает "тот файл, который надо получить" (в данном случае .o), а " $< " -- "исходный файл" (в данном случае .c). Такие переменные называются автоматическими .
Команда располагается на следующей строке, причем эта строка обязательно должна начинаться с символа табуляции .
Это довольно странное правило является основным источником ошибок и запутанности Makefile'ов -- ведь визуально отличить символ табуляции от цепочки пробелов невозможно. Поэтому, к примеру, редактор Midnight Commander автоматически цветом выделяет строки, начинающиеся с символа табуляции.
| Makefile в редакторе MC |
Зависимости. Запись вида
означает, что файл proggie зависит от файлов prg_main.o и prg_funcs.o . Файл proggie называется целью (target), а файлы .o -- зависимостями (dependencies).Несмотря на то, что зависимости по внешнему виду похожи на правила, make их различает.
В принципе в данном Makefile не помешали бы и строки
но у make хватит интеллекта догадаться об этом самому (исходя из правила " .c.o ").Более длинные правила и зависимости.
В правилах можно указывать не только одну команду, но и несколько. Дополнительные команды должны располагаться на следующих строках, причем дополнительные строки также должны начинаться с символа табуляции.
Аналогично после зависимости на следующих строках можно указать команды, при помощи которых ее надо "делать". Например,
| В Linux используется GNU-версия программы make (GNU Make), имеющий более богатый синтаксис (он включает условные конструкции, директиву include для "вставки" других файлов, более гибкий формат определения правил (вида %.c: %.o )). Поэтому многие программы пользуются Makefile'ами именно под GNU Make. В других ОС для вызова GNU Make обычно служит команда " gmake ". |
При запуске без параметров make пытается сделать самую первую цель из перечисленных в Makefile. Обычно в качестве первой ставят дополнительную цель " all ", зависящую от всех файлов, которые надо сделать для изготовления программы.
Если же указать в командной строке имя цели, то make выполнит команды, необходимые для этой цели (и, при надобности, команды для изготовления промежуточных целей).
выполнит только команду компиляции файла prog_main.c в prog_main.o , да и то только если файл .c новее чем .o .Если запустить make с ключом " -n ", то он лишь напечатает на экране команды, которые следует выполнить, не не станет реально их запускать. (Мнемоника для запоминания: " -n " -- "do Nothing" -- "Nичего не делай".)
Ключ " -f " позволяет заставить make читать инструкции из указанного файла, вместо Makefile или makefile , используемых по умолчанию. Пример:
Если при компиляции или сборке возникает ошибка, то make прекращает процесс, не выполняя последующие команды.
Если возникает необходимость создать свой Makefile, то лучше всего взять за образец Makefile от какой-нибудь несложной программы.
Кроме того, очень подробная документация (включая введение для начинающих) есть в info-документации на GNU Make, вызываемой командой " info make ", -- там содержится буквально "все, что вы хотели знать о Make, но боялись спросить".
Конфигурация, компиляция и установка программ из исходных текстов
При разработке программ под Unix авторы обычно стараются сделать так, чтобы их продукт можно было использовать с любым клоном Unix.
Но, поскольку разные клоны довольно сильно отличаются (особенно BSD-системы от SystemV), то написать код, который компилировался и работал бы без изменений на большом количестве систем, практически невозможно. Причем, чем больше программа, тем эта задача сложнее.
Поэтому перед компиляцией надо сначала произвести настройку.
- Если к дистрибутиву прилагается скрипт configure , то надо его запустить (командой " ./configure ").
- Возможно, в Makefile имеется специальная цель " config " -- в таком случае для конфигурирования служит команда " make config ".
- В Makefile могут быть разные цели для разных ОС, в таком случае для компиляции под Irix надо будет дать команду типа " make irix ", а под Linux -- " make linux ".
Первые два способа создают файлы настроек, специфичные для данной ОС (обычно это или include-файлы (.h), или же сразу генерируется нужный Makefile). В третьем случае сразу запускается компиляция с параметрами, специфичными для данной системы.
Какой из способов используется в конкретной программе -- надо смотреть в прилагаемой документации (т.е. в файлах типа README и INSTALL).
Непосредственно для инсталляции же практически всегда используется специальная цель " install " в Makefile. Т.е. для того, чтобы после компиляции и сборки установить программу, надо дать команду
Для примера рассмотрим компиляцию двух программ -- Wget, использующей первый способ, и NetCat, использующей третий.
| В принципе, обе программы (вследствие своей популярности) существуют и в виде .rpm-пакетов, но они являют собой очень простые и "чистые" примеры обоих вариантов конфигурирования, поэтому мы ими и воспользуемся. |
Компиляция и установка программы Wget
Wget -- это утилита командной строки, служащая для скачивания файлов с WWW- и FTP-серверов. Она имеет множество достоинств, в частности, рекуррентную перекачку и автоматическую докачку после обрыва соединения. (Более подробно Wget описан в разделе "Программа wget").
Развернув архив, мы увидим в нем файл INSTALL и скрипт configure , а вот Makefile там нет!
Как и следовало ожидать, в INSTALL рекомендуют запустить configure , а затем набрать " make ".
В ответ на команду " ./configure " компьютер сообщает, что конфигурирует программу GNU Wget 1.5.3, а затем около минуты печатает список свойств системы, которые он проверяет. В конце он уведомляет, что создает несколько Makefile (в разных поддиректориях).
Набрав теперь " make ", запускаем процесс компиляции и сборки, который занимает некоторое время.
По его окончании можно набрать " make install ". Вот и все!
Компиляция программы NetCat
NetCat -- это, вообще говоря, хакерская программа для "отладки" сети, позволяющая передавать данные в сеть по протоколам TCP и UDP и принимать их из сети. Как обычно, воспользуемся локальной копией дистрибутива версии 1.10.
Первым делом развернем архив:
Из файла README узнаем, что для компиляции надо указать команде make тип ОС. То же увидим, и запустив make без параметров:
Беглый просмотр Makefile показывает, что в нем есть цель под названием " linux ". Итак,
Как мы видим, после компиляции появился исполняемый файл nc . Поскольку цель " install " в Makefile отсутствует, то для установки надо просто скопировать этот файл в общесистемную директорию:
Особенности компиляции программ под X-Window
Imakefile и программа xmkmf
К моменту появления системы X-Window проблема различий при компиляции под разные клоны Unix стала уже широко известна, и был разработан способ, позволяющий унифицированно компилировать ПО для X под разными системами.
Идея заключалась в том, чтобы перед компиляцией Makefile автоматически генерировался специальной утилитой xmkmf , "знающей" про специфику конкретной системы, из другого файла, под названием Imakefile. В Imakefile же на некоем специальном языке записывается примерно та же информация, что в Makefile.
| Аббревиатура " xmkmf " расшифровывается очень просто -- "MaKe MakeFile" -- "сделай Makefile", а " x " -- префикс, обозначающий принадлежность программы к X-Window. |
Тем не менее, большинство программ под X-Window поставляются именно с Imakefile.
Пример сборки и установки программы под X-Window
В качестве примера рассмотрим сборку и установку программы XRoach (той самой, что пускает бегать по экрану тараканов). Воспользуемся локальной копией дистрибутива.
Сначала развернем дистрибутив:
Прочтя файл README.linux , мы узнаем лишь, что при компиляции должно быть предупреждение (warning) в строке 373.
Запускаем xmkmf и затем make :
Теперь, аналогично обычным программам, делаем " make install ":
Единственно что, автор поленился сделать автоматическую установку man-страницы, хотя она и есть. Что ж, не беда -- скопируем ее в нужное место "руками":
(Поскольку " make install " установил программу в /usr/X11R6/bin/ , то и man-страницу надо положить "рядом" -- внутри /usr/X11R6/ . А поскольку xroach -- пользовательская программа, то ее man-страница должна лежать в разделе 1 (поддиректория man1/ .)
Мы то и дело повторяем слово "Проект". В первой лекции мы говорили, что проект - это набор связанных файлов различного типа, из которых, в конце концов, после компиляции, получается программа.
Из каких же файлов состоит проект?
Выберите команду Главного меню "Сервис -> Параметры", и в ветке "Окружение" перейдите на раздел "Файловые фильтры". Вы увидите 6 основных типов файлов, которые могут встречаться в проекте:
- Модуль Lazarus (*.pas;*.pp)
- Проект Lazarus (*.lpi)
- Форма Lazarus или Delphi (*.lfm;*.dfm)
- Пакет Lazarus (*.lpk)
- Исходный код проекта Lazarus (*.lpr)
- Иной файл Lazarus (*.inc;*.lrs;*.lpl)
Если мы перейдем в папку с нашим проектом, то увидим, что он состоит из восьми файлов:
- project1.exe (Исполняемый файл программы).
- project1.ico (Файл с "иконкой" проекта - изображением в виде лапы гепарда, которое появляется в верхнем левом углу окна программы).
- project1.lpi (Информационный файл проекта). Если вы желаете открыть данный проект в Lazarus, то запускать нужно именно этот, информационный файл.
- project1.lpr (Исходный файл проекта). Запуск этого файла также приведет к запуску Lazarus с загрузкой данного проекта.
- project1.lps (Конфигурация проекта в виде xml-кода)
- project1.res (Файл ресурсов, используемых в проекте)
- unit1.lfm (Файл формы модуля. В нем в текстовом виде отображены настройки всех компонентов, используемых в модуле. Редактировать этот файл в ручную настоятельно не рекомендуется, для редактирования этих данных нужно использовать Редактор форм).
- unit1.pas (Исходный код модуля на языке Object Pascal).
Файлы с именем project1 - это файлы всего проекта в целом, файлы с именем unit1 - это файлы модуля.
Модуль> - это отдельная единица исходного кода, выполненная в виде файла с расширением *.pas. Совокупность таких единиц составляет программу.
Когда мы создаем окно, то для него создается два файла: модуль - файл *.pas с исходным кодом, и файл *.lfm, в котором содержатся настройки используемых на форме компонентов. Текст модуля мы можем видеть в Редакторе кода. Однако модуль не всегда имеет окно, это может быть и просто текстовый файл с исходным кодом. О модулях и их разделах мы поговорим подробней в одной из следующих лекций. В нашем проекте всего один модуль , но вообще их может быть сколько угодно. И каждый модуль будет представлен этой парой файлов.
Кроме того, в папке проекта находится папка lib, в которой располагаются подключаемые к проекту данные и информация о компиляции. Если же вы изменяли проект, и сохраняли эти изменения, то появится также папка backup, в которой будут храниться резервные копии старых вариантов проекта.
Нередко программист добавляет в проект и свои типы файлов. Например, в проекте можно использовать базу данных, какой-нибудь текстовый файл или ini-файл для сохранения пользовательских настроек. Разумно располагать эти файлы также в папке с проектом.
Теперь пару советов по поводу наименования проекта и модулей. Проект следует называть так, как мы хотим, чтобы называлась наша программа . Например, проекту из первой лекции было бы уместней дать имя "Hello" вместо нейтрального "project1".
Модули же нужно называть, исходя из их значения. Всегда в проекте есть главный модуль. В наших проектах пока что было по одному окну. Модуль , созданный для этого окна, и будет главным. В учебной литературе есть множество рекомендаций, как обозначать модули, остановимся на одной из них. Давайте договоримся в будущем главный модуль называть Main (англ. main - главный), а другим модулям давать смысловые названия, например, Options, Editor и т.п. Форму этого модуля (точнее, свойство Name формы) будем называть также, но с приставкой f-, обозначающей форму. То есть, fMain , fOptions , fEditor и так далее. Закрепим этот материал на практике.
В запросе вместо имени проекта project1 укажите новое имя Hello, не забывайте, что мы договорились сохранять проекты в папки с именем по номеру лекции, и номеру проекта в ней. В нашем примере это будет
C:\Education\02-02\
Как только вы нажмете кнопку "Сохранить", выйдет запрос на сохранение главного модуля. Форму мы назвали fMain, значит, модулю дадим название просто Main. В Lazarus строчные и заглавные буквы не различаются, однако для удобочитаемости кода лучше приучиться использовать заглавные буквы, чтобы выделять названия. Например, FileEdit, SaveAll и т.п.
В свойстве Caption формы впишем слово "Приветствие" (разумеется, без кавычек), это будет более понятным заголовком для окна. Не забывайте после ввода новых значений свойств в Инспекторе объектов нажимать <Enter>, чтобы изменения вступили в силу. Теперь установим на форму компонент TLabel (метку), который позволит выводить на форме текст. Компонент находится на вкладке Standard:
Щелкните мышкой по метке, затем по форме, в верхней части окна. Поскольку метка у нас одна, то можно оставить ей имя (свойство Name ) по умолчанию - Label1 . А вот в свойстве Caption метки напишите:
Как вас зовут?
Ниже метки поместите компонент TEdit - редактируемое текстовое поле , в котором пользователь сможет написать что-то:

У этого компонента свойство Name также оставим по умолчанию - Edit1 . Как вы можете заметить, у этого компонента свойства Caption нет, зато появилось свойство Text - именно тут и содержится текст, отображенный в поле . По умолчанию, он совпадает с именем компонента. Просто очистим это свойство, удалив из него старый текст (не забывайте про <Enter>).
Еще ниже установим кнопку TButton. Оставим ее имя по умолчанию, а в свойстве Caption напишем
Изменим положение и размеры компонентов и самой формы так, чтобы форма приняла примерно такой вид:

Теперь запрограммируем нажатие кнопки. Щелкните по ней дважды, чтобы сгенерировалось событие, и автоматически открылся Редактор кода. В месте, где мигает курсор , впишем следующий код:
Редактор кода должен выглядеть так:
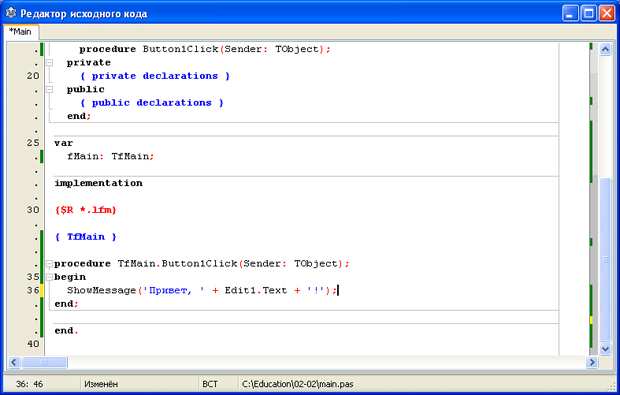
Сохраните проект и запустите его. Когда программа загрузится, впишите в окне Edit1 свое имя и нажмите кнопку "Выполнить". Вы должны получить примерно такой результат:

Вы можете сколько угодно раз менять имя в текстовом поле и снова нажимать кнопку "Выполнить", получая приветствие уже с другим текстом. У нас получилась настоящая интерактивная программа , то есть, программа , взаимодействующая с пользователем.
В дальнейших лекциях мы не будем так подробно останавливаться на том, как сохранять проект или модуль , ограничиваясь кратким

Все языки программирования делятся на два типа — интерпретируемые и компилируемые.
Интерпретаторы
Программируя на интерпретируемом языке, мы пишем программу не для выполнения в процессоре, а для выполнения программой-интерпретатором. Ее также называют виртуальной машиной.
Как правило, программа преобразуется в некоторый промежуточный код, то есть набор инструкций, понятный виртуальной машине.

При интерпретации выполнение кода происходит последовательно строка за строкой (от инструкции до инструкции). Операционная система взаимодействует с интерпретатором, а не исходным кодом.
Скомпилированные программы работают быстрее, но при этом очень много времени тратится на компиляция исходного кода.
Программы же, рассчитанные на интерпретаторы, могут выполняться в любой системе, где таковой интерпретатор присутствует. Типичный пример — код JavaScript. Интерпретатором его выступает любой современный браузер. Вы можете однократно написать код на JavaScript, включив его в html-файл, и он будет одинаково выполняться в любой среде, где есть браузер. Не важно, будет ли это Safari в Mac OS, или же Internet Explorer в Windows.
Компиляторы
Компилятор — это программа, превращающая исходный текст, написанный на языке программирования, в машинные инструкции.
По мере преобразования текста программы в машинный код, компилятор может обнаруживать ошибки (синтаксиса языка, например). Поэтому все проблемы забытых точек с запятыми, забытых скобок, ошибок в названиях функций и переменных в данном случае решаются на этапе компиляции.
При компиляции весь исходный программный код (тот, который пишет программист) сразу переводится в машинный. Создается так называемый отдельный исполняемый файл, который никак не связан с исходным кодом. Выполнение исполняемого файла обеспечивается операционной системой. То есть образуется, например,.EXE файл.
Примеры компилируемых языков: C, C++, Pascal, Delphi.
Препроцессинг
Эту операцию осуществляет текстовый препроцессор.
Исходный текст частично обрабатывается — производятся:
- Замена комментариев пустыми строками
- Подключение модулей и т. д. и т. п.
Компиляция
Результатом компиляции является объектный код.
Объектный код — это программа на языке машинных кодов с частичным сохранением символьной информации, необходимой в процессе сборки.
Компоновка
Компоновка также может носить следующие названия: связывание, сборка или линковка.
Это последний этап процесса получения исполняемого файла, состоящий из связывания воедино всех объектных файлов проекта.
EXE файл.
Заходим в Сервис -> Настройки -> Опции компиляции. Поверяем, стоит ли галочка напротив 2 пункта. Если стоит, то убираем ее.
Теперь откройте свою программу и запустите ее.
Откройте директорию, в которой у вас лежит исходный код программы.
Кликаем по приложению. Как вы видите, после ввода данных, окошко сразу закрывается. Для того чтобы окно не закрывалось сразу, следует дописать две строчки кода, а именно: uses crt (перед разделом описания переменных) и readkey (в конце кода, перед оператором end).

Подключаем внешнюю библиотеку crt и используем встроенную в нее функцию readkey.
Теперь окно закроется по нажатию любой клавиши.

Среда разработки включает в себя:
- текстовый редактор;
- компилятор;
- средства автоматизации сборки;
- отладчик.
На сегодня все! Задавайте любые вопросы в комментариях к этой статье. Не забывайте кликать по кнопочкам и делится ссылками на наш сайт со своими друзьями. А для того, чтобы не пропустить выход очередной статьи, рекомендую вам подписаться на рассылку новостей от нашего сайта. Одна из них находится в самом верху справа, другая — в футере сайта.

Компиляция — это сборка программы, включающая трансляцию всех модулей программы, написанных на одном или нескольких исходных языках программирования в эквивалентные программные модули на машинном (двоичном) языке (коде) и последующие действия по сборке исполняемой машинной программы. Программное обеспечение выполняющее эти многоступенчатые операции (см. ниже) называется компилятором.
Первый компилятор был создан Грейс Хоппер (1906 — 1992) — американской учёной и коммодором флота США. (Ей также приписывается популяризация термина debugging для устранения сбоев в работе компьютера.)
Процесс создания программы
Верстка исходного кода
Препроцессор
Компиляция
Компоновка
Тестирование и отладка программы
Структура программы
Пустая программа
В С++ main() называется главной функцией программы. В ней осуществляется реализация основного алгоритма программы: вызовы функций, обращения к объектам библиотечных и пользовательских классов, инициализация, ввод и вывод данных, взаимодействие с операционной системой.
говорит о том, что мы будем использовать пространство имен стандартной библиотеки (STD). Это позволит сделать код более лаконичным. В противном случае строка 11 выглядела бы следующим образом:
Создание консольного приложения
Сохраним этот файл с именем mypro1.cpp в директории

/workspace/my_pro_1/
Для компиляции и линковки приложения необходимо ввести следующую команду в окне терминала Konsole:

Данная команда состоит из следующих элементов: g++ - вызов программы-компилятора (GCC) с флагом -o . Далее вводится имя бинарного файла и имя компилируемого "исходника".
В результате выполнения этой команды в директории
/workspace/my_pro_1/ появится исполняемый бинарный файл с именем mypro1 . В окне терминала запустим эту программу обращаясь по имени файла: ./mypro1 . Результат работы программы появится здесь же, в окне терминала - это символьная строка ". Hello World. " .
В компиляторе GCC, по умолчанию, не включена поддержка стандарта C++11 . Для включения поддержки этого стандарта в команду g++ необходимо добавить следующий флаг: -std=c++11 . (Отметим, что программы нашего курса требуют включения поддержки стандарта не ниже C++11).
Флаги стандартов:
- -std=c++11 или -std=c++0x
- -std=c++14 или -std=c++1y
- -std=c++17 или -std=c++1z
- -std=c++2a
Интегрированные среды разработки (IDE)
Мы не будем использовать при создании программ текстовые редакторы, поскольку они не предлагают разработчикам никакого инструментария для быстрой верстки приложений. Для эти целей мы будем использовать интегрированную среду разработки (IDE). IDE включают в себя редакторы кода, средства работы с компилятором и отладчиком, интеграцию с системами управления версиями, конструкторы GUI. IDE существенно облегчают и ускоряют верстку программного кода, так как встроенные редакторы обладают возможностью подсветки синтаксиса, автодополнения, навигации и рефакторинга. Существует большое семейство IDE для программирования на C/C++ как проприетарных, так и free software. Крупнейшие производители коммерческого ПО предлагают некоторые свои продукты, такие как IDE и компиляторы, совершенно свободно, но с весьма усеченным комплектованием.
Однако, в настоящее время, разработчики обеспечены значительным количеством свободных IDE, которые имеют довольно мощные интерфейсы, ничем не уступающие интерфейсам коммерческих аналогов. Динамично развивающиеся проекты доступны на гораздо большем числе платформ, что позволяет свободно писать кроссплатформенные приложения. Ими поддерживается большой спектр компиляторов, включая коммерческие. Среди крупнейших, из свободных IDE, можно отметить следующие:
- Eclipse IDE for C/C++ Developers (Допускается к использованию на Всероссийской олимпиаде по информатике)
- Code::Blocks (Допускается к использованию на Всероссийской олимпиаде по информатике, является базовым в нашем курсе)
- QtCreator (это среда будет базовой в нашем курсе при знакомстве с технологией RAD)
- CodeLite
Qt-creator

Qt Creator — кроссплатформенная свободная IDE для разработки на С, С++ и QML. Разработана Trolltech для работы с фреймворком Qt. Включает в себя графический интерфейс отладчика и визуальные средства разработки интерфейса как с использованием QtWidgets, так и QML. Данная IDE является базовой в нашем курсе.
IDE Code::Blocks

Code::Blocks написана на С++ и использует библиотеку wxWidgets. Имея открытую архитектуру, может масштабироваться за счёт подключаемых модулей. Поддерживает языки программирования С, С++, D, Fortran. Code::Blocks разрабатывается для Windows, Linux и Mac OS X.
Потоки. Поток вывода

В программе b-2.2 мы впервые столкнулись с понятием потока. Что же такое поток? Поток ( stream ) — это абстракция, отражающая перемещение данных от источника к приемнику. В большинстве программ требуется получать данные из-вне (например, с клавиатуы), а также отправлять результаты вычислений на стандартное устройство (монитор).
Такое движение данных называется стандартным потоком ввода/вывода. Разумеется, среда C++ реализует потоки не сама по себе, а в непосредственном взаимодействии с операционной системой. Реализация потоков в языке C++ выполнена таким образом, что потоки для различных источников и приемников выглядят единообразно. Синтаксически вывод на языке C++ действительно напоминает поток. Инструкция потока вывода начинается соответствующим объявлением cout (читается "си-аут"). cout является объектом класса библиотеки C++ отвечающей за ввод и вывод - iostream . Данные отправляют (или добавляются) в поток с помощью операции вставки (вывода) . Например:
Такая строка может быть очень длинной, поэтому, для читабельности кода, эту строку можно (и даже нужно!) оформлять в виде столбца:
Как мы уже сказали ранее, поток завершается манипулятором endl . (Манипуляторы - это инструкции форматирования, которые вставляются непосредственно в поток). Этот манипулятор вставляет завершающий ("нулевой") символ, являющийся признаком конца строки и освобождает буфер вывода. На самом деле, данные не выводятся сразу же на устройство, а накапливаются в специальной области памяти, называемой буфером. Буфер не является чем-то недоступным в программе и в процессе работы, с помощью специальных функций, мы можем получать доступ к элементам буфера непосредственно.
Примечание. Хотя endl и производит переход на новую строку, внутри потока использовать его не следует (но возможно). Для того, чтобы осуществить переход на новую строку используется специальная управляющая последовательность "\n" (как во фрагменте программы выше).Форматированный вывод
Язык С++ имеет средства форматированного вывода данных. Форматированный вывод обеспечивают манипуляторы. Манипуляторы вставляются в поток, также как и прочие данные - с помощью операции вставки. Полный список манипуляторов вы можете увидеть в методичке.
Постановка задачи. Вывести на экран фигуру по образцу:
В этой программе используется манипулятор setw() , который определяет ширину поля вывода (выравнивание осуществляется справа по умолчанию). В отличие от прочих манипуляторов, для использования setw требуется подключить заголовочный файл iomanip .
Читайте также: