
Может ли программа эмулируемая на чужом процессоре выполняться быстрее чем на родном
1. Учебная.Ввести понятие процесс и поток. Рассказать о принципах создания и контроля за «процессом» и «потоком».
2. Развивающая.Развивать логическое мышление и естественное - научное мировоззрение.
3. Воспитательная. Воспитывать интерес к научным достижением и открытием.
Межпредметные связи:
· Обеспечивающие: информатика, математика.
· Обеспечиваемые: системное программирование, компьютерные цепи
Методическое обеспечение и оборудование:
1. Методическая разработка к занятию.
3. Учебная программа
4. Рабочая программа.
5. Инструктаж по технике безопасности.
Обеспечение рабочих мест:
3. Ответьте на вопросы:
a. Назовите группы вспомогательных модулей ОС ядра?
b. Какие функции выполняют модули ядра?
c. Назовите слои ядра ОС.
d. Назовите набор средств аппаратной поддержки.
e. Сформулируйте правила к которым необходимо придерживаться для создания мобильных ОС.
f. Какие этапы включает разработка варианта мобильной ОС для новой аппаратной платформы?
g. Опишите порядок взаимодействия приложений с ОС, имеющей микроядерную архитектуру.
h. Какими этапами отличается выполнение системного вызова в микроядерной ОС и ОС с монолитным ядром?
i. Может ли программа, эмулируемая на «чужом» процессоре, выполняться быстрее, чем на «родном»?
Одной из основных подсистем мультипрограммной ОС, непосредственно влияющей на функционирование вычислительной машины, является подсистема управления процессами и потоками, которая занимается их созданием и уничтожением, поддерживает взаимодействие между ними, а также распределяет процессорное время между несколькими одновременно существующими в системе процессами и потоками.
Подсистема управления процессами и потоками ответственна за обеспечение процессов необходимыми ресурсами. ОС поддерживает в памяти специальные информационные структуры, в которые записывает, какие ресурсы выделены каждому процессу. Она может назначить процессу ресурсы в единоличное пользование или в совместное пользование с другими процессами. Некоторые из ресурсов выделяются процессу при его создании, а некоторые — динамически по запросам во время выполнения. Ресурсы могут быть приписаны процессу на все время его жизни или только на определенный период. При выполнении этих функций подсистема управления процессами взаимодействует с другими подсистемами ОС, ответственными за управление ресурсами, такими как подсистема управления памятью, подсистема ввода-вывода, файловая система.
Когда в системе одновременно выполняется несколько независимых задач, то возникают дополнительные проблемы. Хотя потоки возникают и выполняются асинхронно, у них может возникнуть необходимость во взаимодействии, например при обмене данными. Согласование скоростей потоков также очень важно для предотвращения эффекта «гонок» (когда несколько потоков пытаются изменить один и тот же файл), взаимных блокировок или других коллизий, которые возникают при совместном использовании ресурсов. Синхронизация потоков является одной из важных функций подсистемы управления процессами и потоками.
Каждый раз, когда процесс завершается, ОС предпринимает шаги, чтобы «зачистить следы» его пребывания в системе. Подсистема управления процессами закрывает все файлы, с которыми работал процесс, освобождает области оперативной памяти, отведенные под коды, данные и системные информационные структуры процесса. Выполняется коррекция всевозможных очередей ОС и списков ресурсов, в которых имелись ссылки на завершаемый процесс.
Понятия «процесс» и «поток»
Чтобы поддерживать мультипрограммирование, ОС должна определить и оформить для себя те внутренние единицы работы, между которыми будет разделяться процессор и другие ресурсы компьютера. В настоящее время в большинстве операционных систем определены два типа единиц работы. Более крупная единица работы, обычно носящая название процесса, или задачи, требует для своего выполнения нескольких более мелких работ, для обозначения которых используют термины «поток», или «нить».

При использовании этих терминов часто возникают сложности. Это происходит в силу нескольких причин. Во-первых, — специфика различных ОС, когда совпадающие по сути понятия получили разные названия, например задача (task) в OS/2, OS/360 и процесс (process) в UNIX, Windows NT, NetWare. Во-вторых, по мере развития системного программирования и методов организации вычислений некоторые из этих терминов получили новое смысловое значение, особенно это касается понятия «процесс», который уступил многие свои свойства новому понятию «поток». В-третьих, терминологические сложности порождаются наличием нескольких вариантов перевода англоязычных терминов на русский язык. Например, термин «thread» переводится как «нить», «поток», «облегченный процесс», «минизадача» и др. Далее в качестве названия единиц работы ОС будут использоваться термины «процесс» и «поток». В тех же случаях, когда различия между этими понятиями не будут играть существенной роли, они объединяются под обобщенным термином «задача».
Итак, в чем же состоят принципиальные отличия в понятиях «процесс» и «поток»?
Очевидно, что любая работа вычислительной системы заключается в выполнении некоторой программы. Поэтому и с процессом, и с потоком связывается определенный программный код, который для этих целей оформляется в виде исполняемого модуля. Чтобы этот программный код мог быть выполнен, его необходимо загрузить в оперативную память, возможно, выделить некоторое место на диске для хранения данных, предоставить доступ к устройствам ввода-вывода, например к последовательному порту для получения данных по подключенному к этому порту модему, и т. д. В ходе выполнения программе может также понадобиться доступ к информационным ресурсам, например файлам, портам ГСР/UPD, семафорам. И, конечно же, невозможно выполнение программы без предоставления ей процессорного времени, то есть времени, в течение которого процессор выполняет коды данной программы.
В операционных системах, где существуют и процессы, и потоки, процесс рассматривается операционной системой как заявка на потребление всех видов ресурсов, кроме одного — процессорного времени.Этот последний важнейший ресурс распределяется операционной системой между другими единицами работы — потоками, которые и получили свое название благодаря тому, что они представляют собой последовательности (потоки выполнения) команд.
В простейшем случае процесс состоит из одного потока, и именно таким образом трактовалось понятие «процесс» до середины 80-х годов (например, в ранних версиях UNIX) и в таком же виде оно сохранилось в некоторых современных ОС. В таких системах понятие «поток» полностью поглощается понятием «процесс», то есть остается только одна единица работы и потребления ресурсов — процесс. Мультипрограммирование осуществляется в таких ОС на уровне процессов.
Для того чтобы процессы не могли вмешаться в распределение ресурсов, а также не могли повредить коды и данные друг друга, важнейшей задачей ОС является изоляция одного процесса от другого. Для этого операционная система обеспечивает каждый процесс отдельным виртуальным адресным пространством, так что ни один процесс не может получить прямого доступа к командам и данным другого процесса.
Виртуальное адресное пространство процесса — это совокупность адресов, которыми может манипулировать программный модуль процесса. Операционная система отображает виртуальное адресное пространство процесса на отведенную процессу физическую память.
При необходимости взаимодействия процессы обращаются к операционной системе, которая, выполняя функции посредника, предоставляет им средства меж процессной связи — конвейеры, почтовые ящики, разделяемые секции памяти и некоторые другие.
Однако в системах, в которых отсутствует понятие потока, возникают проблемы при организации параллельных вычислений в рамках процесса. А такая необходимость может возникать. Действительно, при мультипрограммировании повышается пропускная способность системы, но отдельный процесс никогда не может быть выполнен быстрее, чем в однопрограммном режиме (всякое разделение ресурсов только замедляет работу одного из участников за счет дополнительных затрат времени на ожидание освобождения ресурса). Однако приложение, выполняемое в рамках одного процесса, может обладать внутренним параллелизмом, который в принципе мог бы позволить ускорить его решение. Если, например, в программе предусмотрено обращение к внешнему устройству, то на время этой операции можно не блокировать выполнение всего процесса, а продолжить вычисления по другой ветви программы. Параллельное выполнение нескольких работ в рамках одного интерактивного приложения повышает эффективность работы пользователя. Так, при работе с текстовым редактором желательно иметь возможность совмещать набор нового текста с такими продолжительными по времени операциями, как переформатирование значительной части текста, печать документа или его сохранение на локальном или удаленном диске. Еще одним примером необходимости распараллеливания является сетевой сервер баз данных. В этом случае параллелизм желателен как для обслуживания различных запросов к базе данных, так и для более быстрого выполнения отдельного запроса за счет одновременного просмотра различных записей базы.
Потоки возникли в операционных системах как средство распараллеливания вычислений. Конечно, задача распараллеливания вычислений в рамках одного приложения может быть решена и традиционными способами.
Во-первых, прикладной программист может взять на себя сложную задачу организации параллелизма, выделив в приложении некоторую подпрограмму диспетчер, которая периодически передает управление той или иной ветви вычислений. При этом программа получается логически весьма запутанной, с многочисленными передачами управления, что существенно затрудняет ее отладку и модификацию.
Во-вторых, решением является создание для одного приложения нескольких процессов для каждой из параллельных работ. Однако использование для создания процессов стандартных средств ОС не позволяет учесть тот факт, что эти процессы решают единую задачу, а значит, имеют много общего между собой — они могут работать с одними и теми же данными, использовать один и тот же кодовый сегмент, наделяться одними и теми же правами доступа к ресурсам вычислительной системы. Так, если в примере с сервером баз данных создавать отдельные процессы для каждого запроса, поступающего из сети, то все процессы будут выполнять один и тот же программный код и выполнять поиск в записях, общих для всех процессов файлов данных. А операционная система при таком подходе будет рассматривать эти процессы наравне со всеми остальными процессами и с помощью универсальных механизмов обеспечивать их изоляцию друг от друга. В данном случае все эти достаточно громоздкие механизмы используются явно не по назначению, выполняя не только бесполезную, но и вредную работу, затрудняющую обмен данными между различными частями приложения. Кроме того, на создание каждого процесса ОС тратит определенные системные ресурсы, которые в данном случае неоправданно дублируются — каждому процессу выделяются собственное виртуальное адресное пространство, физическая память, закрепляются устройства ввода-вывода и т. п.
Из всего вышеизложенного следует, что в операционной системе наряду с процессами нужен другой механизм распараллеливания вычислений, который учитывал бы тесные связи между отдельными ветвями вычислений одного и того же приложения. Для этих целей современные ОС предлагают механизм многопоточной обработки (multithreading). При этом вводится новая единица работы — поток выполнения, а понятие «процесс» в значительной степени меняет смысл. Понятию «поток» соответствует последовательный переход процессора от одной команды программы к другой. ОС распределяет процессорное время между потоками. Процессу ОС назначает адресное пространство и набор ресурсов, которые совместно используются всеми его потоками.
Заметим, что в однопрограммных системах не возникает необходимости введения понятия, обозначающего единицу работы, так как там не существует проблемы разделения ресурсов.
Создание потоков требует от ОС меньших накладных расходов, чем процессов. В отличие от процессов, которые принадлежат разным, вообще говоря, конкурирующим приложениям, все потоки одного процесса всегда принадлежат одному приложению, поэтому ОС изолирует потоки в гораздо меньшей степени, нежели процессы в традиционной мультипрограммной системе. Все потоки одного процесса используют общие файлы, таймеры, устройства, одну и ту же область оперативной памяти, одно и то же адресное пространство. Это означает, что они разделяют одни и те же глобальные переменные.Поскольку каждый поток может иметь доступ к любому виртуальному адресу процесса, один поток может использовать стек другого потока. Между потоками одного процесса нет полной защиты, потому что, во-первых, это невозможно, а во-вторых, не нужно. Чтобы организовать взаимодействие и обмен данными, потокам вовсе не требуется обращаться к ОС, им достаточно использовать общую память — один поток записывает данные, а другой читает их. С другой стороны, потоки разных процессов по-прежнему хорошо защищены друг от друга.
Итак, мультипрограммирование более эффективно на уровне потоков, а не процессов. Каждый поток имеет собственный счетчик команд и стек.Задача, оформленная в виде нескольких потоков в рамках одного процесса, может быть выполнена быстрее за счет псевдопараллельного (или параллельного в мультипроцессорной системе) выполнения ее отдельных частей. Например, если электронная таблица была разработана с учетом возможностей многопоточной обработки, то пользователь может запросить пересчет своего рабочего листа и одновременно продолжать заполнять таблицу. Особенно эффективно можно использовать много поточность для выполнения распределенных приложений, например многопоточный сервер может параллельно выполнять запросы сразу нескольких клиентов.
Использование потоков связано не только со стремлением повысить производительность системы за счет параллельных вычислений, но и с целью создания более читабельных, логичных программ. Введение нескольких потоков выполнения упрощает программирование. Например, в задачах типа «писатель-читатель» один поток выполняет запись в буфер, а другой считывает записи из него. Поскольку они разделяют общий буфер, не стоит их делать отдельными процессами. Другой пример использования потоков — управление сигналами, такими как прерывание с клавиатуры (del или break). Вместо обработки сигнала прерывания один поток назначается для постоянного ожидания поступления сигналов. Таким образом, использование потоков может сократить необходимость в прерываниях пользовательского уровня. В этих примерах не столь важно параллельное выполнение, сколь важна ясность программы.
Наибольший эффект от введения многопоточной обработки достигается в мультипроцессорных системах, в которых потоки, в том числе и принадлежащие одному процессу, могут выполняться на разных процессорах действительно параллельно (а не псевдопараллельно).
Статья, эмулирующая сама себя — может быть лучше самой себя. А может и не быть.
Работа заняла несколько часов. И результаты оказались несколько неожиданными.
В статье автор оптимизировал ход изложения мысли и глубину проработки идей.
Таким образом уменьшались расходы на написание, аналитическую деятельность, оптимизацию форматировния и связности фрагментов текста.
Результаты коррекции впечатлительности доходили до 22%, в среднем по отзывам читателей получалось 9%.
Этот короткий комментарий написан, чтобы кто-нибудь мог узнать что-то новое, а в совсем литературные детали 20-летней давности смысла лезть нет.
Тоже неплохо :)Но я не собирался делать перевод 12-страничной статьи, а просто вспомнилось, и решил рассказать о её существовании
Сожалею, что не оправдал ожидания Оправдали. Интересная статья. Интересный факт. Не принимайте близко к сердцу комментарий a_freeman — он увидел филологическую аналогию, остроумно её изложил, оказался первым, а дальше просто сработал прайминг. По сути это не более чем кривляние перед зеркалом.
Пришлось читать про прайминг что бы понять ваш комментарий, спасибо +1 к словарному запасу
В комментарии должна быть ссылка на исследования комментариев с примерами более короткого изложения мысли. А так рекурсия поломана.
Да, рекурсия поломана, ее надо восстановить.если процессор, эмулирующий сам себя, быстрее себя, то что мешает запустить эмуляцию процессора в эмуляторе процессора на самом процессоре и получить еще большее ускорение? Запускаем рекурсию и получаем процессор, работающий с любой наперед заданной скоростью. А тут вероятно все будет асимптотически сходиться к какому-то предельному значению скорости исполнения программы и каждая последующая итерация будет давать все меньший и меньший прирост скорости.
Хм, а ведь в этом есть доля истины. Это же и к нам можно применить, верно?)
Там какая суть: в одном варианте процессор просто исполнял бинарник, а в другом также исполнял этот бинарник, но уже тратил часть времени на анализ и оптимизации этого же бинарника.
Как итог суммарный выигрыш от оптимизации покрыл все расходы на анализ и эмуляцию, да ещё накинул сверху 20% производительности.
Если отсюда убрать эмуляцию - выигрыш от оптимизации явно будет ещё выше, поскольку эмуляция на старом железе была дорогим удовольствием по времени. Современных технологий виртуализации тогда не было.
Но этот принцип можно использовать и для нашего мозга: что если не выполнять интеллектуальную работу, а сперва проанализировать её и оптимизировать?
В большинстве случаев затраты времени на анализ окупятся сэкономленным оптимизацией времени.
А что касается рекурсии - это работать определенно не будет.
Первый раунд оптимизации уже выявил всё, что могли выявить те алгоритмы.
Второй раунд будет уже оптимизировать исключительно сам слой эмуляции. Но его оптимизировать смысла нет - выгоднее эмуляцию просто исключить из процесса. Современный софт так и собирается: основной набор оптимизаций проводится во время генерации программного кода бинарника, и это довольно тяжёлый по ресурсам процесс, а значит явно эффективнее jit, который не может себе позволить так тщательно анализировать код.
Первый раунд оптимизации уже выявил всё, что могли выявить те алгоритмы.
Не факт.
Первый раунд что-то оптимизировал, эти оптимизации сделали теоретически возможными дальнейшие оптимизации, но оптимизатор не пошёл дальше из-за ограничений по времени работы или по ресурсам.
а в совсем технические детали 20-летней давности смысла лезть нет.
Так ничего и не изменилось. JIT рекомпиляторы как работали тогда, так работают и сейчас. А много народа знает, что в итоге можно получить плюс к производительности на одной и той же архитектуре?
Для меня 20 лет назад это было очень интересным фактом.
Но конечно — в рабочем плане бесполезным.
Мне кажется некорректным говорить, что эмулятор быстрее.
Эмулятор помог оптимизировать оригинальный код. Он получается и без эмуляции быстрее бы запускался
Бинарь, работающий в эмуляторе — работает быстрее, чем на голом железе.Понятно, что чудес нет, и это всё из-за «неэффективности» рантайма на голом железе
Просто оригинальный компилятор фиговый, либо не умеет в PGO (и с архитектурой, которая слишком чувствительна ко всяким branch misprediction-ам).
Чисто «теоретически» — у компилятора меньше инфы, чем у эмулятора в рантайме. Да и PGO — ну оптимизировали на одних данных, а в реальности пошли другие.Дальше просто — если накладные расходы эмулятора меньше, чем получаемый профит, то в итого получим плюс. По вашей статье получается, что код внутри условного qemu может выполняться быстрее, чем на хост-машине. Я правильно понял?
если там JIT то он удаляет недостижимый код перетасовывая вызовы, меньше прыжков в коде, меньше холостых тактов мимо кода)
Что мешало исходному компилятору сделать то же самое, имея «пред глазами» исходный код, а не бинарь? Чем вообще были собраны эти экзешники? Foxpro, что ли? Например исходный компилятор не знает паттерн входящих данных и не может предсказать переходы. Этого хватит? В более общем случае — может быть разная микроархитектура процессоров, и что хорошо одному, то плохо другому.Например исходный компилятор не знает паттерн входящих данных и не может предсказать переходы. Этого хватит?
Не хватит, потому что этим занимается любой современный процессор на гораздо более низком уровне. А отсутствие исходника или промежуточного кода — это гораздо большая проблема для оптимизации.
Статье катастрофически не хватает проверяемых пруфов, потому как подобная ситуация ИМХО возможна только на весьма специфической выборке (бинарников или данных для них).
В современных компиляторах тонны математики и они могут, но на них потрачены тысячи человекочасов и проработанны сотни теорий, а на тот момент такого не было.
Так в статье тоже о «том моменте» написано. Что помешало разработчикам компиляторов применить те же техники, что авторам описываемого JIT-компилятора?проект HP Dynamo. Это эмулятор процессора PA-8000, работающий на этом же процессоре PA-8000, но с технологией JIT. И реальные программы, запускающиеся в эмуляторе — в итоге работают быстрее, чем на голом процессоре.Ээээ, а разве это не значит, что это по сути генерация и эмуляция более эффективного процессора с той же системой команд?
Нет, это получается вообще не более эффективный процессор - это более оптимальная программа.
По идее новая оптимизированная версия будет быстрее и на обычном процессоре
Ага, более оптимизированная версия.Только дополнительный бонус в том, что она заодно оптимизирована на лету под текущие входные данные.
Подозреваю, что это все же и разные запуски
Я не уверен, возможно это теоретически реализуемо, но кажется, что эти оптимизации работают не внутри запущенного процесса, а при следующих запусках
Ну вы-бы статью прочитали. Они оптимизируют на лету. Там вообще сначала эмулятор работаетА где тут, собственно, эмуляция?
Тоже показалось, что это просто перекомпиляция с профилированием.Черт, только с третьего раза правильно слово "Футамура" прочитал. А то все "Футурама" получалась, и это вызывало у меня легкое недоумение.
Черт, только прочитав ваш комментарий правильно прочитал «Футамура» :D И искал Футураму в статье по ссылке.Программистам из HP Labs стало интересно, а что будет, если написать оптимизирующий JIT компилятор под ту же платформу, на которой он работаетКомпилятор который компилирует программу «на лету» по время исполнения. Тогда причём тут это:
Под эмулятором можно было запускать немодифицированные родные бинариЭто получается компиляция уже откомпилированных бинарников.
. Это получается компиляция уже откомпилированных бинарников.
А что вас смущает?
Из известных широкой публике примеров — бинарная трансляция программ, скомпилированных под MacOS на Intel процессорах для их выполнения на MacOS на процессоре Apple M1. До того у них был аналогичный транслятор при миграции с PowerPC на Intel. Статья на Wikipedia.
Ну и JVM JIT тоже транслирует Java-байткод в инструкции процессора.
То что "трансляция" не равно "компиляция".Все эти примеры условны
Не то чтобы это не ошибка, но допустимое обобщение
Машинные коды так же интерпретируются процессором, программы компилируются в байт-код, байт-код интерпретируется виртуальной машиной или компилируется нативный.
Многие системы поддерживают одновременно и jit и интерпретацию и нажимая кнопку сборки программист может даже не знать, что происходит под капотом и называет это компиляцией
Вообще-то компиляция это один из видов трансляции.Впрочем транслятор, описываемый в статье, часто называют JIT recompiler, для удобства. Хотя более правильно называть его Dynamic Recompiler- (dynarec). Вообще-то микрокод тоже компилирует макроинструкции в микроинструкции Big Core от Intel. Там типо почти RISC, горизонтальный микрокод, все дела.
Это получается компиляция уже откомпилированных бинарников.
А что вас удивляет? Приблизительно каждый современный x86 процессор этим занимается. Тут, правда, есть терминологическая путаница, пошедшая со времён Java HotSpot, когда термин JIT-компиляция начали применять к, строго говоря, очень продвинутому, но транслятору. Просто то, что он умеет, было ранее характерно для компиляторов.
Разве компиляторы — не частный случай трансляторов?
Частный, но не каждый транслятор является компилятором. Виноват, комментарий получился мутным.
Compilers ⊂ Translators.
Из того, что (HotSpot ∈ Translators), вовсе не следует, что (HotSpot ∈ Compilers).
То есть мы имеем дело с расширением термина, когда к подмножеству Compilers начинают относить и те члены множества Translators, которые, строго говоря, компиляторами не являются.
Не компиляция, а, скорее, оптимизация и последующее выполнение. Так то действительно, как были машинные коды, так и остались
Эта короткая заметка написана, чтобы кто-нибудь мог узнать что-то новое, а в совсем технические детали 20-летней давности смысла лезть нет.
Только я настроился почитать объёмную статью с geek porn и тут такой облом!
Пойду читать PDF.
Кажется, что дело не в том, что эмулятор быстрее, а в том, что он позволяет за счёт интроспекции оптимизировать программы
Получается, новые бинарники, построенные на основе информации о горячих путях, будут работать быстрее оригинальных программ и на железном процессоре
новые бинарники, построенные на основе информации о горячих путях, будут работать быстрее
Я так понимаю, что в статье ровно о нем и речь.
Но кажется, что это не обязательно особенность Вирт машины - на реальном процессоре оптимизированная программа будет работать аналогично.
Просто статистику для оптимизаций не соберёшь, но результат быстрее для всех
Нет, в статье речь о динамическом рекомпиляторе.PGО же собирает статистику, которая потом используется для финальной статической компиляции.
В теории, конечно никто не мешает статически откомпилировать несколько разных вариантов и выбирать нужны в зависимости от текущих потребностей.
В теории, конечно никто не мешает статически откомпилировать несколько разных вариантов и выбирать нужны в зависимости от текущих потребностей.
Так делает библиотека ATLAS — Automatically Tuned Linear Algebra Software, но чуть хитрее.

Для тех, кого этот феномен заинтересовал, кейворд для дальнейшего чтения — "Проекции Футамуры".
Отлично, первое что у меня нашел гугл на тему Проекции Футамуры он нашел на хабре. Это уже какая-то сама по себе проекция Футамуры.
Получается, что исходный компилятор недостаточно оптимизировал код. Шок контент: сжатый файл занимает меньше, чем несжатый.
P.S. Теперь осталось запустить jit-эмулятор в jit-эмуляторе и запустить программу в нём!
Он не мог оптимизировать лучше, потому что не имел динамической информации о том как исполняется программа.А если запустить эмулятор эмулятора в эмуляторе.
Только тут это на лету, и профилирование идёт по текущим данным, а не каким-то там. То есть потенциально можно ещё больше профита получитьПотенциально да, но не факт, что этот "потенциал" перекроет оверхед от jit обвязки. Особенно на коротких дистанциях, когда времени на амортизацию мало.
Почему тогда, операционные системы в VBOX которые были запущены в VBOX не быстрее хоста? - Потому-то эмуляция современная происходит с аппаратным ускорением. Впрочем насчет не быстрее это обычно баг. Если вы используете нативный nvme для запуска, а не файл вирутальной машины, то можно почти нагнать скорость. (Как я.) Впрочем моного что (скоро вообще все) делается на GPU, а не на CPU, а вот тут прямого доступа нет (пока что, в 21H1 вроде GPU начала тоже пропускаться). Это интересная идейка.Но по факту, если подумать то кажется в процессорах она и так используется уже очень давно. В виде микрокода который дает возможность оптимизаций и который в некотором роде можно считать эмуляцией процессора в самом себе.
С проекциями Футамуры не все так просто, на мой взгляд… Поясню:
0. Специализацией называется процедура конкретизации, допустим, 2^х образует множество решений в зависимости от х, но конкретизируя (специализируя) 2^x числом 3 в качестве значения х, мы получаем вид функции 2^3, как форму абстрагированной записи решения = 8, то есть специализация — это редукция когерентной суперпозиции состояний допустимых решений (редукция множества решений путем коллапса этого множества на детерминированном значении).
Простыми словами, мы детерминируем потенциальную суперпозицию системы, «схлопываем» множество виртуальных возможных состояний до конкретного одного.
1. Первая проекция Футамуры, скажем, на некотором коде высокого уровня по отношению к интерпретатору этого кода (специализация интерпретатора кодом) сформирует редукцию потенциального множества состояний интерпретатора до конкретного состояния — до программы, которая конвертирует конкретный высокоуровневый код в конкретный низкоуровневый, фактически жестко реализуя match'инг из двух множеств.
Иными словами, реализуя конструкцию вида:
IF <тако-то конкретный код> THEN <такой-то выходной>, где информация о выходном была взята специализатором из допустимых возможных состояний интерпретатора.
Первую проекцию называют «компиляцией».
2. Вторая проекция Футамуры предполагает специализацию специализатора кодом самого интерпретатора. Это предполагает следующее:
Код специализатора имеет два аргумента (два входа): что специализировать и чем специализировать. Эти аргументы заранее не определены и могут быть чем угодно, то есть специализатор в отличие от интерпретатора имеет два потенциальных и заранее неопределенных, но связанных множества (по определению специализации).
В таком случае получается, что когда мы специализируем специализатор кодом интерпретатора (правилами интерпретации), мы производим такую редукцию, что, в потенциальном множестве состояний специализатора мы оставляем лишь то множество состояний, которое соотносится один-к-одному с допустимыми состояниями интерпретатора…
Иными словами специализация специализатора интерпретатором порождает не компилятор, а интерпретатор иного рода, по сути индексатор, хеш-функцию. То есть такую программу, которая редуцирована на потенциальном множестве состояний интерпретатора с заранее неопределенным аргументом и создана с целью принимать в качестве аргумента высокоуровневый код и соотносить его с допустимым конкретным значением из (специализированного) потенциального множества низкоуровневых решений.
Фактически специализация — это индексирование. Таким образом, специализация специализатора на интерпретаторе порождает индексатор состояний интерпретатора.
Ладно, едем дальше…
3. Третья проекция Футамуры: специализация специализатора специализатором.
Иными словами, мы делаем редукцию множества состояний специализатора, оставляя из него только то подмножество состояний, которое соотносится к множеству состояний специализатора, которое определено множеством соотносимых друг к другу один-к-одному множеств двух аргументов.
То есть мы получаем на выходе такую программу (редукцию специализатора), которая индексирует все решения, которые могут быть представлены двумерным индексом вида «правила преобразования кода» и «сам код» в качестве «координат», на пересечении которых находится состояние решения проекции конкретного высокоуровневого кода в конкретный низкоуровневый код.
Простыми словами, мы получаем программу представляющую собой уравнение вида F(правила, код) -> низкоуровневый код, таким образом, что:
— подставляя в нее лишь правила, мы получаем подмножество всех допустимых состояний интерпретатора (то есть все возможные виды компиляции всех возможных аргументов — видов компилируемого кода),
— подставляя только код — подмножество всех возможных интерпретаторов с множеством всех возможных интерпретаций, относительно высокоуровневого кода,
— но, подставляя правила и низкоуровневый код — мы можем получить допустимое подмножество исходного высокоуровневого кода в качестве решения (то есть мы вырождаем дизассемблер)
Создание полноценной прикладной среды, полностью совместимой со средой другой ОС, является достаточно сложной задачей, тесно связанной со структурой ОС. Существуют различные варианты построения множественных прикладных сред, отличающиеся как особенностями архитектурных решений, так и функциональными возможностями, обеспечивающими различную степень переносимости приложений.
Во многих версиях ОС UNIX транслятор прикладных сред реализуется в виде обычного приложения. В ОС, построенных с использованием микроядерной концепции, таких как, например, Windows NT или Workplace OS, прикладные среды выполняются в виде серверов пользовательского режима. А в OS/2 с ее более простой архитектурой средства организации прикладных сред встроены глубоко в ОС. Один из наиболее очевидных вариантов реализации множественных прикладных сред основывается на стандартной многоуровневой структуре ОС.

Рис. 3.13. Прикладные программные среды, транслирующие системные вызовы
К сожалению, поведение почти всех функций, составляющих API одной ОС, как правило, существенно отличается от поведения соответствующих функций другой.
В другом варианте реализации множественных прикладных сред ОС имеет несколько равноправных прикладных программных интерфейсов. В приведенном на рис. 3.14 примере ОС поддерживает приложения, написанные для OS1, OS2 и OS3. Для этого непосредственно в пространстве ядра системы размещены прикладные программные интерфейсы всех этих ОС: API OS1, API OS2 и API OS3. В этом варианте функции уровня API обращаются к функциям нижележащего уровня ОС, которые должны поддерживать все три в общем случае несовместимые прикладные среды.
В разных ОС по-разному осуществляется управление системным временем, используется разный формат времени дня, на основании собственных алгоритмов разделяется процессорное время и т. д. Функции каждого API реализуются ядром с учетом специфики соответствующей ОС, даже если они имеют аналогичное назначение. Например, как уже было сказано, функция создания процесса работает по-разному для приложения UNIX и приложения OS/2. Аналогично при завершении процесса ядру также необходимо определять, к какой ОС относится данный процесс. Если этот процесс был создан по запросу UNIX-приложения, то в ходе его завершения ядро должно послать родительскому процессу сигнал, как это делается в ОС UNIX. А по завершении процесса OS/2, ядро должно отметить, что идентификатор процесса не может быть повторно использован другим процессом OS/2. Для того чтобы ядро могло выбрать нужный вариант реализации системного вызова, каждый процесс должен передавать в ядро набор идентифицирующих характеристик.
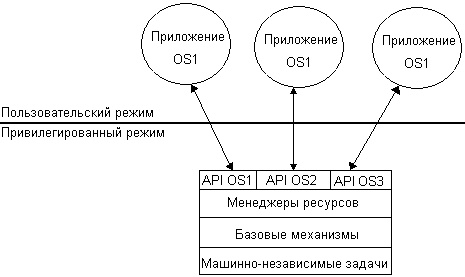
Рис. 3.14.Реализация совместимости на основе нескольких равноправных API
Еще один способ построения множественных прикладных сред основан на микроядерном подходе. При этом очень важно отделить базовые, общие для всех прикладных сред, механизмы ОС от специфических для каждой из прикладных сред высокоуровневых функций, решающих стратегические задачи.
В соответствии с микроядерной архитектурой все функции ОС реализуются микроядром и серверами пользовательского режима. Важно, что каждая прикладная среда оформляется в виде отдельного сервера пользовательского режима и не включает базовых механизмов (рис. 3.15). Приложения, используя API, обращаются с системными вызовами к соответствующей прикладной среде через микроядро. Прикладная среда обрабатывает запрос, выполняет его (возможно, обращаясь для этого за помощью к базовым функциям микроядра) и отсылает приложению результат. В ходе выполнения запроса прикладной среде приходится, в свою очередь, обращаться к базовым механизмам ОС, реализуемым микроядром и другими серверами ОС.
Такому подходу к конструированию множественных прикладных сред присущи все достоинства и недостатки микроядерной архитектуры, в частности:
§ очень просто можно добавлять и исключать прикладные среды, что является следствием хорошей расширяемости микроядерных ОС;
§ надежность и стабильность выражаются в том, что при отказе одной из прикладных сред все остальные сохраняют работоспособность;
§ низкая производительность микроядерных ОС сказывается на скорости работы прикладных сред, а значит, и на скорости выполнения приложений.
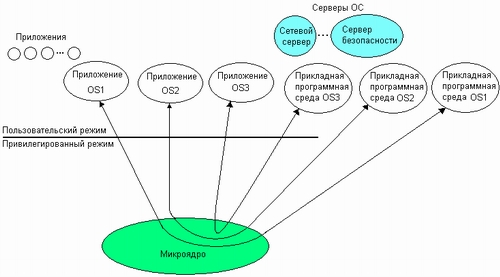
Рис. 3.15. Микроядерный подход к реализации множественных прикладных сред
Создание в рамках одной ОС нескольких прикладных сред для выполнения приложений различных ОС представляет собой путь, который позволяет иметь единственную версию программы и переносить ее между операционными системами. Множественные прикладные среды обеспечивают совместимость на двоичном уровне данной ОС с приложениями, написанными для других ОС. В результате пользователи получают большую свободу выбора ОС и более легкий доступ к качественному программному обеспечению.
§ Простейшая структуризация ОС состоит в разделении всех компонентов ОС на модули, выполняющие основные функции ОС (ядро), и модули, выполняющие вспомогательные функции ОС. Вспомогательные модули ОС оформляются либо в виде приложений (утилиты и системные обрабатывающие программы), либо в виде библиотек процедур. Вспомогательные модули загружаются в оперативную память только на время выполнения своих функций, то есть являются транзитными. Модули ядра постоянно находятся в оперативной памяти, то есть являются резидентными.
§ При наличии аппаратной поддержки режимов с разными уровнями полномочий устойчивость ОС может быть повышена путем выполнения функций ядра в привилегированном режиме, а вспомогательных модулей ОС и приложений — в пользовательском. Это дает возможность защитить коды и данные ОС и приложений от несанкционированного доступа. ОС может выступать в роли арбитра в спорах приложений за ресурсы.
§ Ядро, являясь структурным элементом ОС, в свою очередь, может быть логически разложено на следующие слои (начиная с самого нижнего):
§ машинно-зависимые компоненты ОС;
§ базовые механизмы ядра;
§ интерфейс системных вызовов.
§ В многослойной системе каждый слой обслуживает вышележащий слой, выполняя для него некоторый набор функций, которые образуют межслойный интерфейс. На основе функций нижележащего слоя следующий вверх по иерархии слой строит свои функции — более сложные и более мощные, которые, в свою очередь, оказываются примитивами для создания еще более мощных функций вышележащего слоя. Многослойная организация ОС существенно упрощает разработку и модернизацию системы.
§ Любая ОС для решения своих задач взаимодействует с аппаратными средствами компьютера, а именно: средствами поддержки привилегированного режима и трансляции адресов, средствами переключения процессов и защиты областей памяти, системой прерываний и системным таймером. Это делает ОС машинно-зависимой, привязанной к определенной аппаратной платформе.
§ Переносимость ОС может быть достигнута при соблюдении следующих правил. Во-первых, большая часть кода должна быть написана на языке, трансляторы которого имеются на всех компьютерах, куда предполагается переносить систему. Во-вторых, объем машинно-зависимых частей кода, которые непосредственно взаимодействуют с аппаратными средствами, должен быть по возможности минимизирован. В-третьих, аппаратно-зависимый код должен быть надежно локализован в нескольких модулях.
§ Микроядерная архитектура является альтернативой классическому способу построения ОС, в соответствии с которым все основные функции ОС, составляющие многослойное ядро, выполняются в привилегированном режиме. В микроядерных ОС в привилегированном режиме остается работать только очень небольшая часть ОС, называемая микроядром. Все остальные высокоуровневые функции ядра оформляются в виде приложений, работающих в пользовательском режиме.
§ Микроядерные ОС удовлетворяют большинству требований, предъявляемых к современным ОС, обладая переносимостью, расширяемостью, надежностью и создавая хорошие предпосылки для поддержки распределенных приложений. За эти достоинства приходится платить снижением производительности, что является основным недостатком микроядерной архитектуры.
§ Прикладная программная среда — совокупность средств ОС, предназначенная для организации выполнения приложений, использующих определенную систему машинных команд, определенный тип API и определенный формат исполняемой программы. Каждая ОС создает как минимум одну прикладную программную среду. Проблема состоит в обеспечении совместимости нескольких программных сред в рамках одной ОС. При построении множественных прикладных сред используются различные архитектурные решения, концепции эмуляции двоичного кода, трансляции API.
Задачи и упражнения
1. Какие из приведенных ниже терминов являются синонимами?
2. Можно ли, анализируя двоичный код программы, сделать вывод о невозможности ее выполнения в пользовательском режиме?
3. В чем состоят отличия в работе процессора в привилегированном и пользовательском режимах?
4. В идеале микроядерная архитектура ОС требует размещения в микроядре только тех компонентов ОС, которые не могут выполняться в пользовательском режиме. Что заставляет разработчиков операционных систем отходить от этого принципа и расширять ядро за счет перенесения в него функций, которые могли бы быть реализованы в виде процессов-серверов?
5. Какие этапы включает разработка варианта мобильной ОС для новой аппаратной платформы?
6. Опишите порядок взаимодействия приложений с ОС, имеющей микроядерную архитектуру.
7. Какими этапами отличается выполнение системного вызова в микроядерной ОС и ОС с монолитным ядром?
8. Может ли программа, эмулируемая на «чужом» процессоре, выполняться быстрее, чем на «родном»?
Решение тестов, помощь в закрытии сессии студентам МОИ, Синергии, ГТЕП, Витте, Педкампус, Росдистант


К многозадачным ОС относят: Тип ответа: Множественный выбор OS/2 MS-DOS OC EC MSX Windows 95
Тип установки ОС, при которой устанавливаются основные компоненты и требуется 450 Мб называется: Тип ответа: Одиночный выбор Офис Типовая Разработчику Сервер
Сетевая операционная система – это… : Тип ответа: Множественный выбор Совокупность ОС всех компьютеров сети. ОС отдельного компьютера сети. Набор сетевых служб, выполненных в виде оболочки. Нет правильного ответа
Чем ограничивается максимальный размер виртуального адресного пространства, доступного приложению: Тип ответа: Одиночный выбор Ничем. Разрядностью адреса в системе команд. Разрядностью счетчика команд процессора. Физическим размером оперативной памяти компьютера.
Какие из приведенных ниже терминов являются синонимами : Тип ответа: Множественный выбор Привилегированный режим. Защищенный режим. Режим супервизора. Пользовательский режим. Режим разделения времени. Режим ядра.
Пароль пользователя должен иметь структуру: Тип ответа: Множественный выбор текстовую комбинированную числовую иметь не менее 6 и не белое 256 символов
Слабо связанная совокупность нескольких вычислительных систем, работающих совместно для выполнения общих приложений, и представляющихся пользователю единой системой называется …
Какие события вызывают перепланирование процессов : Тип ответа: Множественный выбор Прерывание от таймера. Аппаратное прерывание по завершению ввода-вывода. Внутреннее прерывание, сообщающее об ошибке выполнения активной задачи. Нет правильного ответа
В результате каких из перечисленных причин процессы переходит в состояние приостановленных процесс : Тип ответа: Множественный выбор Своппинг. Запрос от родительского процесса. Ошибка ввода вывода. Арифметическая ошибка. Завершение родительского процесса.
Комплекс прикладных и системных программных средств, обеспечивающий взаимодействие пользователя с ОС, называется: Тип ответа: Одиночный выбор Программный интерфейс. Интеллектуальный интерфейс. Интерфейс пользователя. Внутренний интерфейс. Интерфейс прикладного программирования.
Средства, предоставляющие разработчику операционной системы возможность разработки модулей ОС (перечислить все правильные ответы): Тип ответа: Множественный выбор Операционная система. Аппаратура компьютера. Утилиты. Прикладные программы.
Корневой каталог имеет путь: Тип ответа: Одиночный выбор /boot /etc / /bin
Можно ли задачу планирования процессов целиком возложить на приложения: Тип ответа: Одиночный выбор нет. да.
Подкаталоги (домашние каталоги) пользователей имеют путь: Тип ответа: Одиночный выбор /home /lib /sbin /root
Мультипроцессирование (multiprocessing): Тип ответа: Одиночный выбор Режим работы, при котором параллельные вычисления обеспечиваются двумя или более процессорами с общим доступом к оперативной памяти. Режим работы, обеспечивающий возможность выполнения нескольких командных процессоров. Режим работы, при котором обеспечивается чередующееся выполнение двух или большего количества программ одним процессором.
… – программа с развитым полноэкранным интерфейсом, включающим использование мыши, предлагающая меню с перечнем всех имеющихся на компьютере ОС.
Элемент занимающий большую часть экрана в графической оболочки ASPLinux, называется: Тип ответа: Одиночный выбор Рабочий стол Ярлыки Персональный каталог Панель
Для того чтобы смонтировать привод CD-ROM в каталог /MyCD, нужно ввести команду: Тип ответа: Одиночный выбор mount -t iso9660 /dev/cdrom /MyCD mount -t iso9660 /dev/cdrom mount /dev/cdrom г. mount -t vfat /dev/fd0 /diskA
Может ли компьютер работать без операционной системы: Тип ответа: Одиночный выбор Может. Нет, не может.
Многозадачность: Тип ответа: Одиночный выбор Режим работы, при котором обеспечивается чередующееся выполнение двух или большего количества программ. Режим работы, при котором параллельные вычисления обеспечиваются двумя или более процессорами с общим доступом к оперативной памяти. Режим работы, при котором обеспечивается параллельная работа пользователей с нескольких подключенных к вычислительной системе терминалов.
Компонент операционной системы управляющий работой фоновых процессов, имеет Login Name: Тип ответа: Одиночный выбор bin daemon Adm
С помощью какой команды можно ввести или изменить пароль пользователя: Тип ответа: Одиночный выбор adduser имя_пользователя userdel -r имя_пользователя passwd имя_пользователя userdel имя_пользователя
Последовательность операций программы или часть программы при ее выполнении, называется: Тип ответа: Одиночный выбор каталогом программой процессом оболочкой
Процесс : Тип ответа: Множественный выбор Процедура загрузки программы. Выполняемая программа, включающая текущее значение счетчика команд, регистров и переменных. Единица активности, которую можно охарактеризовать единой цепочкой последовательных действий, текущим состоянием и связанным с ней набором системных ресурсов. Объектный код программы, хранящийся на диске.
В UNIX для процессов предусмотрены два режима выполнения: Тип ответа: Множественный выбор привилегированный режим стартовый режим обычный режим Стандартный режим
Вытеснение: Тип ответа: Одиночный выбор Возврат ресурса захваченного процессом до окончательного его использования этим процессом. Завершение работающего процесса. Захват памяти родительского процесса порожденным процессом.
Чем ограничивается максимальный размер физической памяти, которую можно установить в компьютере определенной модели: Тип ответа: Одиночный выбор Характеристиками аппаратуры компьютера. Разрядностью адреса в системе команд. Выбранным типом операционной системы.
Можно ли задачу планирования процессов целиком возложить на приложения: Тип ответа: Одиночный выбор нет. да.
Требования, предъявляемые к ОС (указать неверное): Тип ответа: Одиночный выбор расширяемость; переносимость; изолированность; производительность; совместимость.
С помощью какой команды можно вывести список файлов текущего каталога: Тип ответа: Одиночный выбор ls cd имя_каталога ls -al mkdir имя_каталога
Планирование процессов – это … : Тип ответа: Множественный выбор Определение момента времени для смены текущего активного процесса. Выбор для выполнения процесса из очереди готовых для выполнения процессов. Переключение процессора с одного процесса на другой.
Может ли процесс в мультипрограммном режиме выполняться быстрее, чем в монопольном режиме: да нет
Состояние готовности для выполнения процесса относится к задачам, выполняющимся: Тип ответа: Одиночный выбор В однопрограммном режиме. В мультипрограммном режиме. В обоих режимах
Процесс : Тип ответа: Множественный выбор
Процедура загрузки программы.
Выполняемая программа, включающая текущее значение счетчика команд, регистров и переменных.
Единица активности, которую можно охарактеризовать единой цепочкой последовательных действий, текущим состоянием и связанным с ней набором системных ресурсов.
Объектный код программы, хранящийся на диске.
С помощью каких устройств операции ввода-вывода можно выполнять параллельно с вычислительным процессом даже в однопроцессорных системах: Тип ответа: Одиночный выбор
С помощью контроллеров внешних устройств
С помощью диспетчера памяти
С помощью кэш-памяти
К системам, обладающим не вытесняющей многозадачностью, можно отнести: Тип ответа: Множественный выбор NetWare UNIX Windows NT Windows 3.x OS/2
Читайте также: