
Какая программа на сервере принимает и обрабатывает запрос от вашего интернет браузера
Файл .htaccess — это файл для локальной настройки веб-сервера, той программы, которая отдаёт нам сайт. Первый раз мы про него говорили, когда публиковали сайт в интернете, а потом — когда настраивали политику безопасности для сайта. Но это не всё, на что способен .htaccess.
Кратко: сайт, сервер и клиент
На всякий случай вводим в курс дела:
- Когда вы заходите на сайт, вы на самом деле не заходите не на сайт.
- На самом деле вы делаете запрос на удалённый компьютер.
- На удалённом компьютере есть программа, она называется «сервер», то есть «раздатчик».
- Сервер получает ваш запрос и обрабатывает его. Это похоже на работу официанта: вы пришли в ресторан, он принял ваш заказ и пошёл раздавать задания на кухню и в бар
- Когда заказ готов (например, собрана ваша веб-страница), сервер отдаёт её вам по каналу связи. Вы получаете свою страницу. Вам кажется, что вы зашли на сайт, а на самом деле сайт изготовил вам персонально вашу страничку, а вы её получили.
Что такое .htaccess
.htaccess — это файл, в котором записаны инструкции для сервера. Это то же самое, что инструкция официанта, например, «рыбов не продаём». Только официант может эти инструкции запомнить, а серверу нужно записывать. Для этого и нужен файл.
В файле .htaccess можно настроить многое: безопасность, запреты скачивания контента, работу со скриптами, быстродействие сайта и его поведение в разных нештатных ситуациях.
Чтобы добавить любую настройку, скопируйте её код, вставьте его в любое место файла .htaccess и замените наши данные на свои. После этого не забудьте сохранить файл.
👉 В этой статье мы собрали самые простые и полезные настройки файла .htaccess. Если вам нужны все настройки, почитайте официальную документацию.
Что за странное название — .htaccess?
Это тема из Линукса и веб-сервера Apache. Если не в курсе, читайте нашу статью про Linux.
Если вы работаете на Windows, у вас может быть привычка, что у всех файлов должно быть расширение (например, .exe или .pdf). В Линуксе не так: там файлы могут быть вообще без расширения, а тип файла заложен в самом файле, а не в названии.
Поэтому для Линукса нет проблемы с названиями типа .htaccess — это просто очередной файл.
В других операционках могут быть проблемы. Например, на MacOS этот файл может не отображаться: операционка думает, что это скрытый системный файл, и тогда нужно сказать ей «показывай всё». А в Виндоусе вам могут не дать сохранить или переименовать файл с таким названием.
Если же вы будете редактировать или создавать этот файл на удалённом сервере, у вас не будет проблем.
Рецепт: сообщить, что сайт недоступен
Запрещаем спамить в комментариях
Ускоряем загрузку с помощью кеша
Если кто-то уже заходил на ваш сайт, то у него уже есть все ваши стили, картинки и скрипты. Чтобы не загружать одно и то же тем, кто уже был, можно настроить кеширование: браузер проверит, есть ли у него в хранилище эти данные, и если есть — возьмёт их оттуда, чтобы было быстрее.
Но есть и минус: иногда браузер может подтянуть из кеша старую картинку или скрипт, хотя вы вчера залили всё новое. Редко, но бывает.
Настраиваем кодировку
Во всех наших проектах мы прописываем кодировку прямо в HTML-файле. Но есть ещё один способ: указать нужную кодировку в настройках сервера. Тогда, если мы забудем указать её на странице, ничего страшного не произойдёт: сервер сам сообщит браузеру о нужной настройке.
Ещё одна защита от внешних скриптов
В статье про безопасность сайта мы говорили, как можно запретить выполнение разных скриптов на сайте. Кроме этого, есть ещё один способ:
Запрещаем приходить с определённых сайтов
Если вы не хотите, чтобы к вам приходили посетители с какого-то сайта, например, с сайта любителей аниме или клуба любителей пропатчить KDE под FreeBSD, то вы можете установить это в настройках .htaccess. Сервер проверит, с какого сайта приходит посетитель, и если этот сайт есть в вашем личном чёрном списке — доступ посетителю будет запрещён.
👉 Если человек придёт с другого сайта, но при этом будет всё равно иногда заходить на сайты, которые вам не нравятся, — трюк не сработает.
Оптимизируем сайт для SEO
С помощью файла .htaccess можно сделать поисковую оптимизацию сайта — настроить сайт так, чтобы его любили поисковики и приводили к вам из поиска побольше читателей. Но чтобы переходить к настройкам .htaccess, нужно сначала разобраться, что такое SEO и как оно работает. Это и сделаем в следующий раз.
Простыми словами объясняем, как браузер подключается и общается с сервером.
Поэтому первым делом браузеру нужно понять, какой IP-адрес у сервера, на котором находится сайт.
Такая информация хранится в распределенной системе серверов — DNS (Domain Name System). Система работает как общая «контактная книга», хранящаяся на распределенных серверах и устройствах в интернете.
Однако перед тем, как обращаться к DNS, браузер пытается найти запись об IP-адресе сайта в ближайших местах, чтобы сэкономить время:
- Сначала в своей истории подключений . Если пользователь уже посещал сайт, то в браузере могла сохраниться информация c IP-адресом сервера.
- В операционной системе . Не обнаружив информации у себя, браузер обращается к операционной системе, которая также могла сохранить у себя DNS-запись. Например, если подключение с сайтом устанавливалось через одно из установленных на компьютере приложений.
- В кэше роутера , который сохраняет информацию о последних соединениях, совершенных из локальной сети.
Не обнаружив подходящих записей в кэше, браузер формирует запрос к DNS-серверам, расположенным в интернете.
Как только браузер узнал IP-адрес нужного сервера, он пытается установить с ним соединение. В большинстве случаев для этого используется специальный протокол — TCP.
TCP — это набор правил, который описывает способы соединения между устройствами, форматы отправки запросов, действия в случае потери данных и так далее.
Например, для установки соединения между браузером и сервером в стандарте TCP используется система «трёх рукопожатий». Работает она так:
- Устройство пользователя отправляет специальный запрос на установку соединения с сервером — называется SYN -пакет.
- Сервер в ответ отправляет запрос с подтверждением получения SYN-пакета — называется SYN/ACK -пакет.
- В конце устройство пользователя при получении SYN/ACK-пакета отправляет пакет с подтверждением — ACK -пакет. В этот момент соединение считается установленным.
Задача браузера — как можно подробнее объяснить серверу, какая именно информация ему нужна .
Сервер получил запрос от браузера с подробным описанием того, что ему требуется. Теперь ему нужно обработать этот запрос. Этой задачей занимается специальное серверное программное обеспечение — например, nginx или Apache. Чаще всего такие программы принято называть веб-серверами.
Когда ответ сформирован, он отправляется веб-сервером обратно браузеру. В ответе как правило содержится контент для отображения веб-страницы, информация о типе сжатия данных, способах кэширования, файлы cookie, которые нужно записать и так далее.
👉 Чтобы обмен данными был быстрым, браузер и сервер обмениваются сразу множеством небольших пакетов данных — как правило, в пределах 8 КБ. Все пакеты имеют специальные номера, которые помогают отслеживать последовательность отправки и получения данных. 8. Браузер обрабатывает полученный ответ и «рисует» веб-страницуБраузер распаковывает полученный ответ и постепенно начинает отображать полученный контент на экране пользователя — этот процесс называется рендерингом .
Сначала браузер загружает только основную структуру HTML-страницы. Затем последовательно проверяет все теги и отправляет дополнительные GET-запросы для получения с сервера различных элементов — картинки, файлы, скрипты, таблицы стилей и так далее. Поэтому по мере загрузки страницы браузер и сервер продолжают обмениваться между собой информацией.
Параллельно с этим на компьютер как правило сохраняются статичные файлы пользователя — чтобы при следующем посещении не загружать их заново и быстрее отобразить пользователю содержимое страницы.
Как только рендеринг завершен — пользователю отобразится полностью загруженная страница сайта.
Предположим, что он ввёл в адресной строке следующее:
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
Версия протокола здесь задаётся так же, как в запросе.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
А есть дополнительные возможности?
Что-то ещё, кстати, используют?
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Цель лекции: дать определение понятию "веб-сервер" и сформировать представление о работе этого механизма.


Одной из наиболее важных задач, которые решаются при построении веб-сервера является задача обеспечения масштабируемости (т.е. возможности увеличения количества обслуживаемых пользователей) и защищенности от внешних атак. Поскольку веб-сервер работает в открытой среде – глобальной сети Интернет – то зачастую доступ к нему может осуществляться откуда угодно. Это делает веб-сервер подверженным большим нагрузкам и потенциальным атакам. Наиболее распространенными атаками на веб-сервер является обращение к веб-серверу с большим количеством запросов и их высокой частотой. В этом случае веб-сервер не сможет быстро обрабатывать все запросы, а это может сказаться на производительности веб-сервера для настоящих пользователей. Особенно остро подобным атакам подвержены веб-сервера, на которых исполняется какой-то внешний программный код за исключением программного кода самого веб-сервера. Обычно для борьбы с подобными атаками блокируются все запросы, которые приходят с определенного IP-адреса. Кроме того, в подобных случаях следует позаботится об оптимизации программного кода приложения, например, использовать кэширование – в этом случае при обработке каждого запроса нагрузка на центральный процессор будет меньше, что может существенно усложнить задачу атакующим.


При анализе HTTP-запросов хорошо видно, что HTTP-заголовок " Host " отличается в каждом из запросов. Таким образом, становится понятно, что веб-сервер анализирует этот заголовок и отправляет клиенту содержимое соответствующего сайта. Схематически этот процесс можно представить следующим образом.
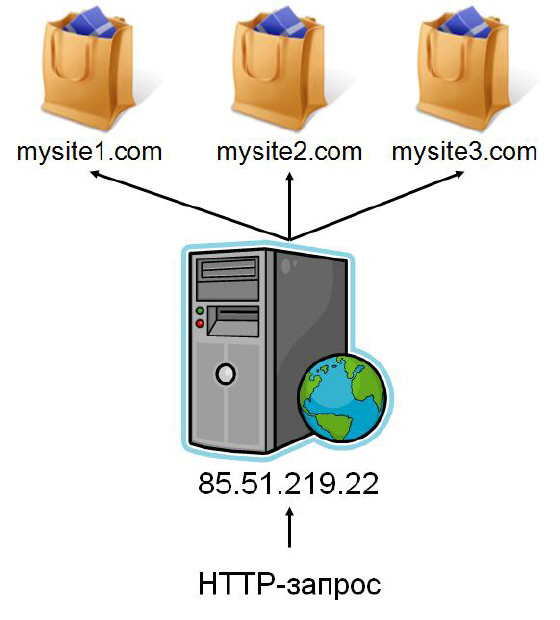
Подобную схему виртуального хостинга использует большинство компаний, занимающихся размещением веб-сайтов в Интернет. Поскольку в этом случае на одном физическом сервере могут размещаться большое количество совершенно различных сайтов, то этот способ один из самых дешевых. Однако, в рамках виртуального хостинга обычно запрещено запускать различные службы и сервисы, а также существует ограничение по степени использования центрального процессора. Это означает, что в случае, когда веб-сайт потребляет слишком много серверных ресурсов, то владельцу сайта предлагается либо перейти на более дорогой тариф (с большим количеством выделенных ресурсов), либо при превышении допустимого порогового значения веб-сайт блокируется на некоторое время. Поскольку иногда от сервера требуется большое количество ресурсов или в рамках этого сервера необходимо запускать дополнительные приложения или службы, виртуальный хостинг можно использовать не всегда. В этом случае обычно арендуют выделенный сервер – физический или виртуальный. Однако, это более дорогой вид размещения веб-приложений в сети Интернет, поэтому зачастую используется именно виртуальный хостинг.
Поскольку программный код веб-приложения обычно упаковывается в отдельные модули и поставляется независимо, то требуются механизмы взаимодействия этих двух частей, т.е. интерфейс взаимодействия. В данном случае под интерфейсом взаимодействия понимается набор правил, по которым веб-сервер и приложение будут взаимодействовать друг с другом. Фактически, схема обработки запроса может выглядеть следующим образом.

Исторически сложилось так, что существует два главных типов интерфейс взаимодействия внешнего приложения и веб-сервера - CGI и ISAPI.
С другой стороны, необходимость создания каждый раз нового процесса влечет за собой дополнительные накладные расходы на создание процесса (создание процесса – дорогостоящая операция с точки зрения операционной системы) и передачи данных через границы процессов. Этот факт является серьезным недостатком и оказывает существенное влияние на масштабируемость веб-приложения (возможность обрабатывать большее количество поступающих запросов).
ISAPI (Internet Server API) – альтернативный способ взаимодействия веб-сервера и веб-приложения. В отличии от CGI, при взаимодействии в рамках интерфейса ISAPI, при поступлении очередного запроса, веб-сервер инициирует создание нового потока в рамках основного процесса, в котором работает веб-сервер. Поскольку с точки зрения операционной системы создание потока – это менее дорогостоящая операция, чем создание процесса, то такие приложения на практике оказываются более масштабируемыми. Кроме того, упрощается взаимодействие веб-сервера и веб-приложения, поскольку в этом случае используется единое адресное пространство в рамках операционной системы (поскольку весь код работает в одном и том же процессе). Однако, в случае серьезных неполадок в веб-приложении, которое взаимодействует с веб-сервером в рамках ISAPI, веб-сервер также потенциально подвергается риску быть завершенным. Поскольку веб-сервер и веб-приложение работают в одном и том же процессе, это действительно так. Поэтому разработчикам программного кода веб-сервера, поддерживающего ISAPI следует уделить этому вопросу особое внимание.
Читайте также: