Как вывести информацию в excel
Версия этой статьи для Microsoft Visual Basic 6,0 приведена в статье 247412.
Обзор
Метод, наиболее часто используемый для передачи данных в книгу Excel, является автоматизацией. С помощью автоматизации можно вызывать методы и свойства, относящиеся к задачам Excel. Автоматизация предоставляет максимальную гибкость для указания расположения данных в книге, форматирования книги и создания различных параметров во время выполнения.
С помощью автоматизации вы можете использовать различные методы для переноса данных:
- Перемещение ячейки данных по ячейке.
- Передача данных в массиве в диапазон ячеек.
- Перенесите данные из набора записей ADO в диапазон ячеек с помощью метода Копифромрекордсет.
- Создайте объект QueryTable на листе Excel, который содержит результат запроса в источнике данных ODBC или OLEDB.
- Перенесите данные в буфер обмена, а затем вставьте содержимое буфера обмена в лист Excel.
Вы также можете использовать несколько методов, которые не требуют автоматизации для передачи данных в Excel. Если вы используете серверную программу, это может быть хорошим подходом к отходящей обработке данных от клиентов.
Для переноса данных без автоматизации можно использовать следующие подходы:
Способ
Использование автоматизации для передачи ячейки данных по ячейкам
С помощью автоматизации можно переносить данные на лист по одной ячейке за раз:
Опять же, передача данных по ячейке допускается только для небольших объемов данных. Если необходимо перенести большие наборы данных в Excel, рекомендуется использовать один из других подходов, описанных в этой статье, для массовой передачи данных.
Использование автоматизации для переноса массива данных в диапазон листа
Вы можете перенести массив данных в диапазон из нескольких ячеек за один раз:
Если вы переносите данные с помощью массива, а не ячейки по ячейке, вы можете реализовать огромную производительность с большим количеством данных. Рассмотрите следующие строки из вышеупомянутого кода, которые передают данные в 300 ячейки листа:
Этот код представляет два запроса интерфейса: один для объекта Range, возвращаемого методом Range, и другой для объекта Range, который возвращает метод Resize. В отличие от переноса ячейки данных по ячейке, необходимо запросить интерфейсы 300 для объектов Range. Если это возможно, вы можете воспользоваться преимуществами для массового переноса данных и уменьшения количества запросов к интерфейсу.
Для получения дополнительных сведений о том, как использовать массивы для получения и задания значений в диапазонах с помощью автоматизации Excel, щелкните номер статьи ниже, чтобы просмотреть статью в базе знаний Майкрософт:
Использование автоматизации для переноса набора записей ADO в диапазон листа
Объектные модели для Excel 2000, Excel 2002 и Excel 2003 предоставляют метод Копифромрекордсет для переноса набора записей ADO в диапазон листа. В приведенном ниже коде показано, как автоматизировать Excel для переноса содержимого таблицы Orders в образце базы данных Northwind с помощью метода Копифромрекордсет:
Использование автоматизации для создания объекта QueryTable на листе
Объект QueryTable представляет таблицу, созданную на основе данных, возвращаемых из внешнего источника данных. При автоматизации Excel можно создать QueryTable, предоставив строку подключения к OLE DB или источнику данных ODBC, а также строку SQL. Excel создает набор записей и вставляет набор записей на лист в указанном расположении. Объекты QueryTable имеют следующие преимущества по сравнению с методом Копифромрекордсет:
- Excel обрабатывает создание набора записей и его расположение на листе.
- Вы можете сохранить запрос с помощью объекта QueryTable и обновить его позже, чтобы получить обновленный набор записей.
- Когда на лист добавляется новый QueryTable, вы можете указать, что данные, которые уже существуют в ячейках листа, будут сдвинуты для обработки новых данных (Дополнительные сведения см. в свойстве Рефрешстиле).
В приведенном ниже коде показано, как автоматизировать Excel 2000, Excel 2002 или Excel 2003 для создания нового QueryTable на листе Excel с помощью данных из учебной базы данных Northwind:
Использование буфера обмена Windows
Создание текстового файла с разделителями, который Excel может проанализировать по строкам и столбцам
Excel может открывать файлы с разделителями табуляцией и запятыми и правильно анализировать данные в ячейки. Эту функцию можно использовать, если требуется перенести большое количество данных на лист, используя небольшую, при автоматизации. Это может быть хорошим подходом к клиент-серверной программе, так как текстовый файл может быть создан на стороне сервера. Затем можно открыть текстовый файл на клиенте, используя автоматизацию там, где это необходимо.
Приведенный выше код не использует автоматизацию. Однако при желании можно использовать автоматизацию для открытия текстового файла и сохранения файла в формате книги Excel, как показано ниже:
С помощью поставщика OLE DB для Microsoft Jet можно добавлять записи в таблицу из существующей книги Excel. Таблица в Excel — это всего лишь диапазон ячеек; диапазон может иметь определенное имя. Как правило, первая строка диапазона содержит заголовки (или имена полей), а все последующие строки в диапазоне содержат записи.
Приведенный ниже код добавляет две новые записи в таблицу в Book7. xls. В этом случае таблицей является Лист1:
Для получения дополнительных сведений об использовании поставщика OLEDB для Jet с источниками данных Excel щелкните номера статей ниже, чтобы просмотреть статьи базы знаний Майкрософт:
278973 пример: в ексцеладо показано, как использовать ADO для чтения и записи данных в книгах Excel
257819 практическое руководство: использование ADO с данными Excel из Visual Basic или VBA
Передача XML-данных (Excel 2002 и Excel 2003)
Excel 2002 и 2003 могут открыть любой XML-файл с правильным форматом. XML-файлы можно открыть непосредственно с помощью команды открыть в меню файл или программным путем с помощью методов Open и OpenXML коллекции книги. Если вы создаете XML-файлы для использования в Excel, вы также можете создать таблицы стилей для форматирования данных.
Создание новой папки с именем К:\ексцелдата. В этом примере программа будет хранить книги Excel в этой папке.
Создайте новую книгу для примера, в который необходимо выполнить запись:
- Создайте новую книгу в Excel.
- На листе Sheet1 новой книги введите FirstName в ячейке a1 и LastName в ячейке B1.
- Выберите a1: B1.
- В меню Вставка выберите пункт имя, а затем — команду определить. Введите имя MyTable и нажмите кнопку ОК.
- Сохранение книги в виде C:\Exceldata\Book7.xls.
- Закройте Excel.
Добавьте ссылку на библиотеку объектов Excel и основную сборку взаимодействия ADODB. Для этого выполните следующие действия:
- On the Project menu, click Add Reference.
- На вкладке Сеть найдите ADODB и нажмите кнопку Выбрать.
Обратите внимание, что в Visual Studio 2005 нет необходимости щелкать кнопку выбрать.
3. На вкладке COM найдите объектная Библиотека Microsoft Excel 10,0 или библиотека объектов Microsoft Excel 11,0, а затем нажмите кнопку Выбрать.
Обратите внимание, что в Visual Studio 2005 нет необходимости щелкать кнопку выбрать.
Примечание Если вы используете Microsoft Excel 2002, а вы еще не сделали это, корпорация Майкрософт рекомендует скачать и установить основные сборки взаимодействия Microsoft Office XP (PIA).
В диалоговом окне Добавление ссылок нажмите кнопку ОК, чтобы принять выбранные параметры.
Добавление элемента управления "поле со списком" и элемента управления "Кнопка" в форму Form1.
Добавьте обработчики событий для события загрузки формы и событий Click элемента управления Button:
- В представлении конструктора для Form1.cs дважды щелкните элемент Form1.
Обработчик события Load для формы создан и отображается в Form1.cs.
2. В меню Вид выберите конструктор, чтобы переключиться в режим конструктора.
3. Дважды щелкните элемент Button1.
Обработчик события нажатия кнопки создается и отображается в Form1.cs.
В Form1.cs замените приведенный ниже код.
Добавьте следующие директивы using в директивы using в Form1.cs:
Нажмите клавишу F5 для сборки и запуска примера.
Ссылки
Для получения дополнительных сведений посетите следующий веб-сайт Майкрософт:
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Описание
В этой статье приведены пошаговые инструкции по поиску данных в таблице (или диапазоне ячеек) с помощью различных встроенных функций Microsoft Excel. Для получения одного и того же результата можно использовать разные формулы.
Создание образца листа
В этой статье используется образец листа для иллюстрации встроенных функций Excel. Рассматривайте пример ссылки на имя из столбца A и возвращает возраст этого человека из столбца C. Чтобы создать этот лист, введите указанные ниже данные в пустой лист Excel.
Введите значение, которое вы хотите найти, в ячейку E2. Вы можете ввести формулу в любую пустую ячейку на том же листе.
Определения терминов
В этой статье для описания встроенных функций Excel используются указанные ниже условия.
Определение
Вся таблица подстановки
Значение, которое будет найдено в первом столбце аргумента «инфо_таблица».
Просматриваемый_массив
-или-
Лукуп_вектор
Диапазон ячеек, которые содержат возможные значения подстановки.
Номер столбца в аргументе инфо_таблица, для которого должно быть возвращено совпадающее значение.
3 (третий столбец в инфо_таблица)
Ресулт_аррай
-или-
Ресулт_вектор
Диапазон, содержащий только одну строку или один столбец. Он должен быть такого же размера, что и просматриваемый_массив или Лукуп_вектор.
Логическое значение (истина или ложь). Если указано значение истина или опущено, возвращается приближенное соответствие. Если задано значение FALSE, оно будет искать точное совпадение.
Число столбцов, находящегося слева или справа от которых должна указываться верхняя левая ячейка результата. Например, значение "5" в качестве аргумента Оффсет_кол указывает на то, что верхняя левая ячейка ссылки состоит из пяти столбцов справа от ссылки. Оффсет_кол может быть положительным (то есть справа от начальной ссылки) или отрицательным (то есть слева от начальной ссылки).
Функции
LOOKUP ()
Функция Просмотр находит значение в одной строке или столбце и сопоставляет его со значением в той же позицией в другой строке или столбце.
Ниже приведен пример синтаксиса формулы подСТАНОВКи.
= Просмотр (искомое_значение; Лукуп_вектор; Ресулт_вектор)
Следующая формула находит возраст Марии на листе "образец".
= ПРОСМОТР (E2; A2: A5; C2: C5)
Формула использует значение «Мария» в ячейке E2 и находит слово «Мария» в векторе подстановки (столбец A). Формула затем соответствует значению в той же строке в векторе результатов (столбец C). Так как "Мария" находится в строке 4, функция Просмотр возвращает значение из строки 4 в столбце C (22).
Примечание. Для функции Просмотр необходимо, чтобы таблица была отсортирована.
Чтобы получить дополнительные сведения о функции Просмотр , щелкните следующий номер статьи базы знаний Майкрософт:
Функция ВПР или вертикальный просмотр используется, если данные указаны в столбцах. Эта функция выполняет поиск значения в левом столбце и сопоставляет его с данными в указанном столбце в той же строке. Функцию ВПР можно использовать для поиска данных в отсортированных или несортированных таблицах. В следующем примере используется таблица с несортированными данными.
Ниже приведен пример синтаксиса формулы ВПР :
= ВПР (искомое_значение; инфо_таблица; номер_столбца; интервальный_просмотр)
Следующая формула находит возраст Марии на листе "образец".
= ВПР (E2; A2: C5; 3; ЛОЖЬ)
Формула использует значение «Мария» в ячейке E2 и находит слово «Мария» в левом столбце (столбец A). Формула затем совпадет со значением в той же строке в Колумн_индекс. В этом примере используется "3" в качестве Колумн_индекс (столбец C). Так как "Мария" находится в строке 4, функция ВПР возвращает значение из строки 4 В столбце C (22).
Чтобы получить дополнительные сведения о функции ВПР , щелкните следующий номер статьи базы знаний Майкрософт:
INDEX () и MATCH ()
Вы можете использовать функции индекс и ПОИСКПОЗ вместе, чтобы получить те же результаты, что и при использовании поиска или функции ВПР.
Ниже приведен пример синтаксиса, объединяющего индекс и Match для получения одинаковых результатов поиска и ВПР в предыдущих примерах:
= Индекс (инфо_таблица; MATCH (искомое_значение; просматриваемый_массив; 0); номер_столбца)
Следующая формула находит возраст Марии на листе "образец".
= ИНДЕКС (A2: C5; MATCH (E2; A2: A5; 0); 3)
Формула использует значение «Мария» в ячейке E2 и находит слово «Мария» в столбце A. Затем он будет соответствовать значению в той же строке в столбце C. Так как "Мария" находится в строке 4, формула возвращает значение из строки 4 в столбце C (22).
СМЕЩ () и MATCH ()
Функции СМЕЩ и ПОИСКПОЗ можно использовать вместе, чтобы получить те же результаты, что и функции в предыдущем примере.
Ниже приведен пример синтаксиса, объединяющего смещение и сопоставление для достижения того же результата, что и функция Просмотр и ВПР.
= СМЕЩЕНИЕ (топ_целл, MATCH (искомое_значение; просматриваемый_массив; 0); Оффсет_кол)
Эта формула находит возраст Марии на листе "образец".
= СМЕЩЕНИЕ (A1; MATCH (E2; A2: A5; 0); 2)
Формула использует значение «Мария» в ячейке E2 и находит слово «Мария» в столбце A. Формула затем соответствует значению в той же строке, но двум столбцам справа (столбец C). Так как "Мария" находится в столбце A, формула возвращает значение в строке 4 в столбце C (22).
Чтобы получить дополнительные сведения о функции СМЕЩ , щелкните следующий номер статьи базы знаний Майкрософт:
Есть в IT-отрасли задачи, которые на фоне успехов в big data, machine learning, blockchain и прочих модных течений выглядят совершенно непривлекательно, но на протяжении десятков лет не перестают быть актуальными для целой армии разработчиков. Речь пойдёт о старой как мир задаче формирования и выгрузки Excel-документов, с которой сталкивался каждый, кто когда-либо писал приложения для бизнеса.

Какие возможности построения файлов Excel существуют в принципе?
- VBA-макросы. В наше время по соображениям безопасности идея использовать макросы чаще всего не подходит.
- Автоматизация Excel внешней программой через API. Требует наличия Excel на одной машине с программой, генерирующей Excel-отчёты. Во времена, когда клиенты были толстыми и писались в виде десктопных приложений Windows, такой способ годился (хотя не отличался скоростью и надёжностью), в нынешних реалиях это с трудом достижимый случай.
- Генерация XML-Excel-файла напрямую. Как известно, Excel поддерживает XML-формат сохранения документа, который потенциально можно сгенерировать/модифицировать с помощью любого средства работы с XML. Этот файл можно сохранить с расширением .xls, и хотя он, строго говоря, при этом не является xls-файлом, Excel его хорошо открывает. Такой подход довольно популярен, но к недостаткам следует отнести то, что всякое решение, основанное на прямом редактировании XML-Excel-формата, является одноразовым «хаком», лишенным общности.
- Наконец, возможна генерация Excel-файлов с использованием open source библиотек, из которых особо известна Apache POI. Разработчики Apache POI проделали титанический труд по reverse engineering бинарных форматов документов MS Office, и продолжают на протяжении многих лет поддерживать и развивать эту библиотеку. Результат этого reverse engineering-а, например, используется в Open Office для реализации сохранения документов в форматах, совместимых с MS Office.
Но у прямого использования Apache POI есть и недостатки. Во-первых, это Java-библиотека, и если ваше приложение написано не на одном из JVM-языков, вы ей вряд ли сможете воспользоваться. Во-вторых, это низкоуровневая библиотека, работающая с такими понятиями, как «ячейка», «колонка», «шрифт». Поэтому «в лоб» написанная процедура генерации документа быстро превращается в обильную «лапшу» трудночитаемого кода, где отсутствует разделение на модель данных и представление, трудно вносить изменения и вообще — боль и стыд. И прекрасный повод делегировать задачу самому неопытному программисту – пусть ковыряется.
Но всё может быть совершенно иначе. Проект Xylophone под лицензией LGPL, построенный на базе Apache POI, основан на идее, которая имеет примерно 15-летнюю историю. В проектах, где я участвовал, он использовался в комбинации с самыми разными платформами и языками – а счёт разновидностей форм, сделанных с его помощью в самых разнообразных проектах, идёт, наверное, уже на тысячи. Это Java-проект, который может работать как в качестве утилиты командной строки, так и в качестве библиотеки (если у вас код на JVM-языке — вы можете подключить её как Maven-зависимость).
Xylophone реализует принцип отделения модели данных от их представления. В процедуре выгрузки необходимо сформировать данные в формате XML (не беспокоясь о ячейках, шрифтах и разделительных линиях), а Xylophone, при помощи Excel-шаблона и дескриптора, описывающего порядок обхода вашего XML-файла с данными, сформирует результат, как показано на диаграмме:

Шаблон документа (xls/xlsx template) выглядит примерно следующим образом:

Как правило, заготовку такого шаблона предоставляет сам заказчик. Вовлечённый заказчик с удовольствием принимает участие в создании шаблона: начиная с выбора нужной формы из «Консультанта» или придумывания собственной с нуля, и заканчивая размерами шрифтов и ширинами разделительных линий. Преимущество шаблона в том, что мелкие правки в него легко вносить уже тогда, когда отчёт полностью разработан.
Когда «оформительская» работа выполнена, разработчику остаётся
- Создать процедуру выгрузки необходимых данных в формате XML.
- Создать дескриптор, описывающий порядок обхода элементов XML-файла и копирования фрагментов шаблона в результирующий отчёт
- Обеспечить привязку ячеек шаблона к элементам XML-файла с помощью XPath-выражений.
Если бы в форме, которую мы создаём, не было повторяющихся элементов с разным количеством (таких, как строки накладной, которых разное количество у разных накладных), то дескриптор выглядел бы следующим образом:
Здесь root – название корневого элемента нашего XML-файла с данными, а диапазон A1:Z100 – это прямоугольный диапазон ячеек из шаблона, который будет скопирован в результат. При этом, как можно видеть из предыдущей иллюстрации, подстановочные поля, значения которых заменяются на данные из XML-файла, имеют формат
(тильда, фигурная скобка, XPath-выражение относительно текущего элемента XML, закрывающая фигурная скобка).
Что делать, если в отчёте нам нужны повторяющиеся элементы? Естественным образом их можно представить в виде элементов XML-файла с данными, а помочь проитерировать по ним нужным образом помогает дескриптор. Повторение элементов в отчёте может иметь как вертикальное направление (когда мы вставляем строки накладной, например), так и горизонтальное (когда мы вставляем столбцы аналитического отчёта). При этом мы можем пользоваться вложенностью элементов XML, чтобы отразить сколь угодно глубокую вложенность повторяющихся элементов отчёта, как показано на диаграмме:

Красными квадратиками отмечены ячейки, которые будут являться левым верхним углом очередного прямоугольного фрагмента, который пристыковывает генератор отчёта.
Есть и ещё один возможный вариант повторяющихся элементов: листы в книге Excel. Возможность организовать такую итерацию тоже имеется.
Рассмотрим чуть более сложный пример. Допустим, нам надо получить сводный отчёт наподобие следующего:

Пусть диапазон лет для выгрузки выбирает пользователь, поэтому в этом отчёте динамически создаваемыми являются как строки, так и столбцы. XML-представление данных для такого отчёта может выглядеть следующим образом:
Мы вольны выбирать названия тэгов по своему вкусу, структура также может быть произвольной, но с оглядкой на простоту конвертации в отчёт. Например, выводимые на лист значения я обычно записываю в атрибуты, потому что это упрощает XPath-выражения (удобно, когда они имеют вид @имяатрибута ).
Шаблон такого отчёта будет выглядеть так (сравните XPath-выражения с именами атрибутов соответствующих тэгов):

Теперь наступает самая интересная часть: создание дескриптора. Т. к. это практически полностью динамически собираемый отчёт, дескриптор довольно сложен, на практике (когда у нас есть только «шапка» документа, его строки и «подвал») всё обычно гораздо проще. Вот какой в данном случае необходим дескриптор:
Полностью элементы дескриптора описаны в документации. Вкратце, основные элементы дескриптора означают следующее:
- element — переход в режим чтения элемента XML-файла. Может или являться корневым элементом дескриптора, или находиться внутри iteration . С помощью атрибута name могут быть заданы разнообразные фильтры для элементов, например
- name="foo" — элементы с именем тэга foo
- name="*" — все элементы
- name="tagname[@attribute='value']" — элементы с определённым именем и значением атрибута
- name="(before)" , name="(after)" — «виртуальные» элементы, предшествующие итерации и закрывающие итерацию.
- mode="horizontal" — режим вывода по горизонтали (по умолчанию — vertical)
- index=0 — ограничить итерацию только самым первым встреченным элементом
- sourcesheet —лист книги шаблона, с которого берётся диапазон вывода. Если не указывать, то применяется текущий (последний использованный) лист.
- range – диапазон шаблона, копируемый в результирующий документ, например “A1:M10”, или “5:6”, или “C:C”. (Применение диапазонов строк типа “5:6” в режиме вывода horizontal и диапазонов столбцов типа “C:C” в режиме вывода vertical приведёт к ошибке).
- worksheet – если определён, то в файле вывода создаётся новый лист и позиция вывода смещается в ячейку A1 этого листа. Значение этого атрибута, равное константе или XPath-выражению, подставляется в имя нового листа.
Ну что же, настало время скачать Xylophone и запустить формирование отчёта.
Возьмите архив с bintray или Maven Central (NB: на момент прочтения этой статьи возможно наличие более свежих версий). В папке /bin находится shell-скрипт, при запуске которого без параметров вы увидите подсказку о параметрах командной строки. Для получения результата нам надо «скормить» ксилофону все приготовленные ранее ингредиенты:
Открываем файл report.xlsx и убеждаемся, что получилось именно то, что нам нужно:![]()
Так как библиотека ru.curs:xylophone доступна на Maven Central под лицензией LGPL, её можно без проблем использовать в программах на любом JVM-языке. Пожалуй, самый компактный полностью рабочий пример получается на языке Groovy, код в комментариях не нуждается:
У класса XML2Spreadsheet есть несколько перегруженных вариантов статического метода process , но все они сводятся к передаче всё тех же «ингредиентов», необходимых для подготовки отчёта.Важная опция, о которой я до сих пор не упомянул — это возможность выбора между DOM и SAX парсерами на этапе разбора файла с XML-данными. Как известно, DOM-парсер загружает весь файл в память целиком, строит его объектное представление и даёт возможность обходить его содержимое произвольным образом (в том числе повторно возвращаясь в один и тот же элемент). SAX-парсер никогда не помещает файл с данными целиком в память, вместо этого обрабатывает его как «поток» элементов, не давая возможности вернуться к элементу повторно.
Использование SAX-режима в Xylophone (через параметр командной строки -sax или установкой в true параметра useSax метода XML2Spreadsheet.process ) бывает критически полезно в случаях, когда необходимо генерировать очень большие файлы. За счёт скорости и экономичности к ресурсам SAX-парсера скорость генерации файлов возрастает многократно. Это даётся ценой некоторых небольших ограничений на дескриптор (описано в документации), но в большинстве случаев отчёты удовлетворяют этим ограничениям, поэтому я бы рекомендовал использование SAX-режима везде, где это возможно.
Надеюсь, что способ выгрузки в Excel через Xylophone вам понравился и сэкономит много времени и нервов — как сэкономил нам.
Чтобы лучше представить, как функция "Идеи" упрощает, быстрее и интуитивнее анализ данных, функция была переименована в Анализ данных. Возможности и функциональные возможности одинаковы и по-прежнему соответствуют тем же нормативным актам о конфиденциальности и лицензировании. Если вы в канале Semi-Annual Enterprise, вы можете по-прежнему видеть "Идеи", пока Excel не будет обновлен.
![Браузер не поддерживает видео.]()
Анализ данных в Excel анализирует данные и предоставляет высокоуровневые визуальные сводки, тенденции и закономерности.
Есть вопрос? Мы ответим!
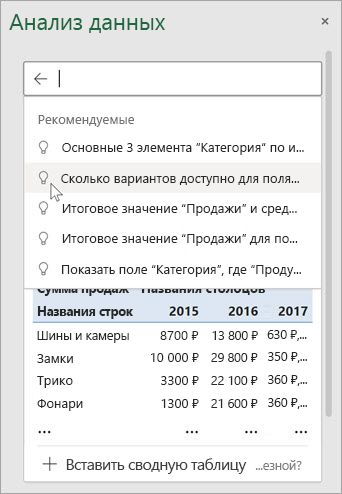
Просто выберем ячейку в диапазоне данных> кнопкуАнализ данных на вкладке Главная.Анализ данных в Excel будут анализировать данные и возвращать интересные визуальные сведения о них в области задач.
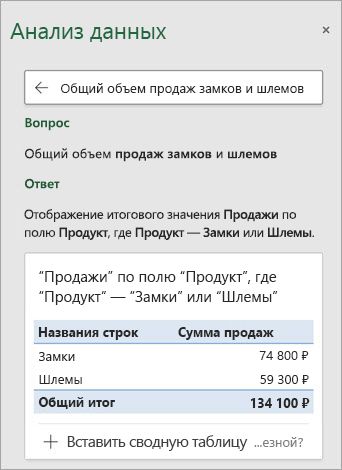
Если вы хотите получить более конкретные сведения, введите свой вопрос в поле запроса в верхней части панели и нажмите ВВОД. Анализ данных предоставляет ответы с помощью визуальных данных, таких как таблицы, диаграммы или с помощью срезов, которые затем можно вставить в книгу.
Если вы хотите изучить свои данные или просто узнать, что возможно, Анализ данных также предлагает персонализированные вопросы, к которым можно получить доступ, выбрав в поле запроса.
Попробуйте воспользоваться предлагаемыми вопросами
Просто задайте вопрос
Выберите текстовое поле в верхней части области Анализ данных, и вы увидите список предложений на основе ваших данных.
![Анализ данных в Excel предложит вам вопросы, основанные на анализе данных.]()
Вы также можете ввести определенный вопрос о своих данных.
![Анализируйте данные в Excel ответе на вопрос о том, сколько было продано блокировок или "Прикрашивание".]()
Анализ данных доступно для Microsoft 365 на английском, французском, испанском, немецком, упрощенном китайском и японском языках. Если вы являетесь подписчиком Microsoft 365, убедитесь, что у вас установлена последняя версия Office. Подробнее о разных каналах обновления Office см. в статье Обзор каналов обновления приложений Microsoft 365.
Функции запросов на естественном языке в Анализ данных постепенно становится доступной для клиентов. Сначала она будет предложена подписчикам Microsoft 365 в Актуальном канале на английском языке.
Получите конкретные Анализ данных
Если у вас нет вопросов, помимо естественного языка, Анализ данных анализирует и предоставляет наглядные визуальные сводки, тенденции и закономерности.
Вы можете сэкономить время и получить более уделяющий больше внимания анализу, выбрав только нужные поля. При выборе полей и подведения итогов Анализ данных исключаются другие доступные данные, что ускоряет процесс и приводит меньше вариантов. Например, вам может потребоваться только общая сумма продаж за год. Вы также можете попросить Анализ данных отобразить среднее значение продаж по годам.
Выберите какие поля вас интересуют больше всего?
![В области Анализ данных со ссылкой укажите, какие поля нужно использовать.]()
Выберите поля и способ обобщения содержащихся в них данных.
![Выберите поля, которые вы хотите включить и обновить, чтобы получить новые рекомендации.]()
Анализ данных предлагает меньше вариантов.
Примечание: Параметр Не является значением в списке полей относится к полям, для которых обычно не выполняется суммирование или вычисление средних значений. Например, вы не можете вычислить сумму отображаемых лет, но вы можете вычислить сумму значений отображаемых лет. Параметр Не является значением, используемый с другим полем, в котором производится суммирование или вычисление среднего значения, работает как метка строки, однако при самостоятельном использовании Не является значением подсчитывает уникальные значения выбранного поля.
Анализ данных лучше всего работает с данными в таблицах.
![Пример таблицы Excel]()
Вот несколько советов, которые помогут вам с Анализ данных.
Анализ данных лучше всего работает с данными, отформатированные как Excel таблицы. Чтобы создать таблицу Excel, щелкните в любом месте данных и нажмите CTRL+T.
Убедитесь, что у вас правильно отформатированы заголовки столбцов. Заголовки должны быть представлены в виде одной строки уникальных непустых имен столбцов. Не используйте двойные строки заголовков, объединенные ячейки и т. д.
При наличии сложных или вложенных данных для преобразования перекрестных таблиц или таблиц с несколькими строками заголовков можно использовать надстройку Power Query.
Не Анализ данных ? Скорее всего, проблема у нас, а не у вас.
Вот некоторые причины, по которым Анализ данных могут не работать с вашими данными:
Анализ данных в настоящее время не поддерживает анализ наборов данных более 1,5 миллионов ячеек. Временного решения этой проблемы пока нет. Тем временем вы можете отфильтровать данные, а затем скопировать их в другое место, чтобы Анализ данных на них.
Строковое даты, такие как "01-01-2017", анализируются как текстовые строки. В качестве временного решения можно создать для них новый столбец и отформатировать как даты с помощью функции ДАТА или ДАТАЗНАЧ.
Анализ данных не будут работать, Excel в режиме совместимости (например, если файл .xls формате). Сохраните файл в формате XLSX, XLSM или XLSB.
Объединенные ячейки также могут представлять сложность для анализа. Если вы хотите выровнять данные по центру, например в заголовке отчета, то в качестве временного решения удалите все объединенные ячейки, а затем выровняйте ячейки по центру выделения. Нажмите клавиши CTRL+1 и перейдите на Выравнивание > По горизонтали > По центру выделения.
Анализ данных лучше всего работает с данными в таблицах.
![Пример таблицы Excel]()
Вот несколько советов, которые помогут вам с Анализ данных.
Анализ данных лучше всего работает с данными, отформатированные как Excel таблицы. Чтобы создать таблицу Excel, щелкните в любом месте данных и нажмите +T.
Убедитесь, что у вас правильно отформатированы заголовки столбцов. Заголовки должны быть представлены в виде одной строки уникальных непустых имен столбцов. Не используйте двойные строки заголовков, объединенные ячейки и т. д.
Не Анализ данных ? Скорее всего, проблема у нас, а не у вас.
Вот некоторые причины, по которым Анализ данных могут не работать с вашими данными:
Анализ данных в настоящее время не поддерживает анализ наборов данных более 1,5 миллионов ячеек. Временного решения этой проблемы пока нет. Тем временем вы можете отфильтровать данные, а затем скопировать их в другое место, чтобы Анализ данных на них.
Строковое даты, такие как "01-01-2017", анализируются как текстовые строки. В качестве временного решения можно создать для них новый столбец и отформатировать как даты с помощью функции ДАТА или ДАТАЗНАЧ.
Анализ данных не могут анализировать данные, Excel в режиме совместимости (например, если файл .xls формате). Сохраните файл в формате XLSX, XLSM или XLSB.
Объединенные ячейки также могут представлять сложность для анализа. Если вы хотите выровнять данные по центру, например в заголовке отчета, то в качестве временного решения удалите все объединенные ячейки, а затем выровняйте ячейки по центру выделения. Нажмите клавиши CTRL+1 и перейдите на Выравнивание > По горизонтали > По центру выделения.
Анализ данных лучше всего работает с данными в таблицах.
![Пример таблицы Excel]()
Вот несколько советов, которые помогут вам с Анализ данных.
Анализ данных лучше всего работает с данными, отформатированные как Excel таблицы. Чтобы создать таблицу Excel, щелкните в любом месте данных и выберите главная > Таблицы > Формат таблицы.
Убедитесь, что у вас правильно отформатированы заголовки столбцов. Заголовки должны быть представлены в виде одной строки уникальных непустых имен столбцов. Не используйте двойные строки заголовков, объединенные ячейки и т. д.
Не Анализ данных ? Скорее всего, проблема у нас, а не у вас.
Вот некоторые причины, по которым Анализ данных могут не работать с вашими данными:
Анализ данных в настоящее время не поддерживает анализ наборов данных более 1,5 миллионов ячеек. Временного решения этой проблемы пока нет. Тем временем вы можете отфильтровать данные, а затем скопировать их в другое место, чтобы Анализ данных на них.
Строковое даты, такие как "01-01-2017", анализируются как текстовые строки. В качестве временного решения можно создать для них новый столбец и отформатировать как даты с помощью функции ДАТА или ДАТАЗНАЧ.
Мы постоянно улучшаем Анализ данных
Даже если ни одно из указанных выше условий не выполняется, поиск рекомендаций может оказаться безрезультатным. Это объясняется тем, что служба пытается найти определенный набор классов аналитических сведений, и ей не всегда это удается. Мы постоянно работаем над расширением типов анализа, поддерживаемых службой.
Вот текущий список доступных типов анализа:
Ранг. Ранжирует элементы и выделяет тот, который существенно больше остальных.
![График, показывающий, что расходы отдела заработной платы значительно выше]()
Тренд. Выделяет тенденцию, если она прослеживается на протяжении всего временного ряда данных.
![График, показывающий увеличение расходов с течением времени]()
Выброс. Выделяет выбросы во временном ряду.
![Точечная диаграмма, показывающая выбросы]()
Большинство. Находит случаи, когда большую часть итогового значения можно связать с одним фактором.
![Кольцевая диаграмма, показывающая, что на долю людей приходится большая часть расходов]()
Если вы не получили результатов, отправьте нам отзыв, выбрав на вкладке Файл пункт Отзывы и предложения.
Так Анализ данных анализируются с помощью служб искусственного интеллекта, возможно, вас беспокоит их безопасность. You can read the Microsoft privacy statement for more details.
Анализ данных используются материалы сторонних сторон. Если вы хотите ознакомиться с подробными сведениями, см. статью Сведения о лицензировании для анализа данных.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Читайте также: