
Как сохранить файл в формате log
Здесь мы рассмотрим некоторые возможности powershell при сохранении данных в файл. Этот функционал применяется практически всегда, когда речь заходит о больших выгрузках, о результатах работы каких-либо автоматизаций. Банальным примером будет настройка логирования выполнения скрипта в планировщике задач.
Экспорт данных в файл. Add-Content, Set-Content
Исходя из названия команд, не сложно догадаться, как они работают. Командлет Add-Content выполняет добавление информации в указанный файл. В то время как Set-Content выполняет полную перезапись файла теми данными, которые он получил на вход.
Синтаксис группы этих команд идентичен друг другу и достаточно прост. Чтобы получить содержимое файла, необходимо просто указать путь к файлу в параметре -Path:
Так как командлет по умолчанию ожидает получение параметра -Path, его имя можно опустить: “Set-Content D:\processes.txt “.
Так же здесь работает принцип конвейеризации – "Hello World!" | Add-Content C:\Test.txt или Set-Content C:\Test.txt -Value "Hello World!" по принципу действия будут похожи. За тем исключением, что в первом случае данные передаются по конвейеру, а во втором указаны явно в параметре -Value.
Out-File
Out-File – пожалуй основной способ сохранения текстовых данных на жесткий диск. Этот командлет является более универсальной альтернативой командам Add-Content и Set-Content. Этот командлет выводит в файл данные в том виде, в котором они поступают ему на вход. По этой причине его довольно часто используют в связке с командами, предварительно конвертирующими вывод в необходимый формат. Примером таких команд могут служить команды ConvertTo-Csv, ConvertTo-Html, ConvertTo-Json, ConvertTo-Xml. О том как получить справку по командам, можно узнать здесь .
Get-Volume | ConvertTo-Html | Out-File C:\ProcessList.html
В этом примере перед сохранением в файл данные конвертируются в HTML код. И Вы можете сохранить их в HTML документ. При этом возможно вносить элементы форматирования страницы, используя CSS. Если есть необходимость просто сохранить данные на диск в первозданном виде, тогда необходимо просто использовать командлет Out-File.
Некоторые полезные параметры:
- -Force – выполнение с этим ключом приведет к перезаписи файла в случае его существования на момент выполнения команды;
- -Append – если файл уже существует, то выполнение с этим ключом не перезапишет весь файл. А данные будут добавлены в конец файла. Отличный способ для настройки логирования. В сочетании с параметром -Force данные будут добавлены в файл даже при установленном флаге – только чтение;
- -Encoding – позволяет определять кодировку для данных перед их записью в файл;
- -NoClobber – при указании этого параметра, если файл уже существует с таким именем, он не будет перезаписан.
Export-Csv
Этот вид экспорта наиболее подходит и чаще всего применяется для формирования табличных выгрузок или отчетов. В параметрах этого командлета есть возможность указать, какой символ будет служить разделителем. Для демонстрации выгрузим все виртуальные машины на хосте виртуализации в файл .csv. Подробнее ►

Простейшая read-only файловая система
Начнем с самого понятия файловой системы. Когда речь заходит о файловой системе, то сразу возникает ощущение чего то большого, а следовательно и имеющего большие накладные расходы. Да, это правда, накладные расходы присутствуют, ведь для описания файлов, хотя бы их имен или идентификаторов, необходимо место. Да, существует проблема достаточно больших накладных расходов при применение универсальных файловых систем. Стремление сделать универсальные файловые менее ресурсоемкими привели к созданию littleFS, но даже она требует 10кб (RAM + ROM), что для микроконтроллера порой избыточно, ведь требуется всего лишь хранить несколько десятков параметров.
Но давайте можно ли ограничив функционал уменьшить накладные расходы?
Конечно можно, ведь файл это просто именованная последовательность упорядоченных данных. Давайте поместим наши параметры в некий блок данных, и присвоим этому блоку имя, и по сути дела получим файл. А теперь давайте сделаем несколько файлов с данными, запакуем их в cpio формат и поместим этот cpio в наше firmware, при этом сохраним адрес начала нашего архива.
Сделать это можно очень просто. Нужен ассемблерный файл в котором бинарные данные помещаются в специальную секцию
И добавив линкер скрипт
Этого достаточно, теперь мы можем внутри программы ходить по файлам, метки и другие метаданные доступны. Наша файловая система упакована в очень простой формат cpio , который почти не требует накладных расходов. Собственно в Embox мы называем эту файловую систему initfs. Она является полноценной файловой read-only системой в которой доступны как файлы так и папки.
Файлы в этом случае представляют из себя описание файла содержащее имя и адрес начала данных и сами данные. Причем данные это просто массив байт. Аналогично можно представить файл в виде си-массива и включить его в проект при компиляции. Этот метод широко используется например при создании веб-сайтов на базе lwIP. Об преимуществах Embox при создании web-сайтов мы рассказывали в статье.
.
В итоге предлагаемый подход на основе cpio имеет сопоставимые накладные расходы по сравнению с внедрением массива байт, и они меньше по сравнению с littleFS. Что не удивительно, ведь мы создали еще более специализированное решение.
Общие сведения о файловой системе
Прежде чем продолжить нам необходимо сделать небольшое отступление и немного разобраться с общими принципами файловых систем. Ведь когда мы говорим об littleFS, имеют в виду тип файловой системы и драйвер для данного типа. А для того чтобы работать с файлами, потребуется еще несколько понятий. Например индексный дескриптор описывающий открытый файл. Который как минимум должен иметь методы чтения и записи этого файла.
Мы рассмотрим только несколько типов объектов без которых трудно обойтись. Начнем с описателей файла. Есть два типа описаний файла. Первый это описатель представления файла на носителе (inode ). Отмечу, что имя файла хранится не в самом inode, а в записи об этом файле в родительской директории (directory entry (dentry)). dentry хранит имя файла и ссылку на его inode эта информация нужна для поиска файла в файловой системе.
Вторым описателем файла является описатель открытого файла представленный в виде индексного дескриптора. Этот описатель получается с помощью стандартного POSIX вызова open(). Отмечу что объект FILE получаемый с помощью fopen() является описателем потока (stream) а не файла, хотя во многих вещах это одно и тоже. Индексный дескриптор для файла должен как минимум содержать текущую позицию по которой происходит чтение или запись и ссылку на его inode.
Тип файловой системы определяет формат в котором хранятся метаданные и данные в этой файловой системы. Драйвер файловой системы это реализацию функций работы с форматом для данного типа файловой системы, например, упомянутые littleFS и initfs (в Embox) это драйвера файловой системы.
Еще одним важным объектом является описатель файловой системы (superblock). В нем хранится информация о методах работы с файловой системой и ее состояние (например блочное устройство на котором оно работает).
Драйвер initFS
Вернемся к цели нашей статьи файловая система внутри микроконтроллера. Мы уже поняли, что создать удобную read-only файловую систему с очень маленькими накладными расходами возможно. Для удобной работы через привычные open/read/write нам не хватает совсем немного. Например нужно чтобы наш драйвер имел какое то API. Давайте рассмотрим некоторые функции драйвера в Embox, для общего понимания каким может быть это API.
Определяем сам драйвер. У него есть имя файловой системы и функция заполнения superblock. В драйвере еще могут быть функция форматирования блочного устройства в формате файловой системы и очистка superblock, но у нас read-only файловая система и этого точно не требуется.
Функция заполнения superblock
В ней мы заполняем несколько указателей на различные функции работы с файловой системой. А также выделяем экземпляр структуры inode для данной файловой системы. Выделение нужно поскольку любая файловая система имеет точку монтирования, что тоже является файлом, точнее директорией.
Функция сreate() создает новую inode на файловой системе, в нашем случае она просто возвращает ошибку прав доступа. Нам же понадобятся пара функций для операций с inode: lookup функция поиска по имени в заданной папке и iterate — функция для перебора и получения имени всех inode в папке.
На самом деле, если нужно только open/read/write то без iterate можно было бы попробовать обойтись. По сути дела она используется в readdir, но для красоты реализации (и универсальности конечно) функцию open() лучше выразить через readdir().
Функция lookup() ищет файл с указанным именем в директории и в случае обнаружения возвращает указатель на новую inode.
Из функций superblock интересна open_idesc. Для регулярных файлов она должна выделить объект idesc, тот самый описатель файла по которому будут происходить операции read/write. inode который описывает файл на диске уже заполнен с помощью функции lookup.
Нам осталось рассмотреть только функции для работы с файлами read/write. write() будет пустой и просто вернет ошибку. Функция read() тоже не сложная:
Переставляет текущий курсор и копирует данные в буфер.
Файловая система
Теперь когда у нас есть драйвер в нашей файловой системе, давайте посмотрим что это нам дает и оценим затраты.
Что дает хорошо видно на этом скриншоте.

Мы можем работать с данными размещенными внутри нашего образа, как с обычными файлами. Я вызываю обычную команду ‘ls’ и затем вывожу информацию с помощью обычной команды ‘cat’.
Сколько это стоит? То есть сколько требуется ресурсов для подобное удобство. Оказалось не так уж и много. Я использовал STM32F4-discovery и я сравнил образы с файловой системой и без, оказалось на text + rodata (то есть код и константы в том числе и сами файлы) нужно порядка 8 кБ. При этом я даже не включал оптимизацию. Для RAM потребовалось порядка 700 байт. Откуда они берутся. Нужен объект superblock, и inode для каждой примонтированной файловой системы, Нужны объекты dentry включающие inode для каждой открытой папки и файла. нужен idesc для каждого открытого файла.
Наверное кто то скажет что несколько кБ за read-only файловую систему для микроконтроллера много. Но нужно учитывать что я оценивал всю подсистему, причем вместе с файлами сайта которые занимали пару киллобайт, а не только драйвер. А добавление еще одного драйвера требует гораздо меньше ресурсов (если он простой конечно).
DumbFS
Давайте разработаем драйвер который может работать во внутренней флеш микроконтроллера. Наш драйвер для хранения настроек и лог-файлов, может быть очень простым. Например, нам не нужно хранить атрибуты файлов, мы можем обойтись без директорий, мы даже можем сказать что там нужно только 3 файла ведь на этапе проектирования, мы можем определить какие именно файлы нужны и можем задать их максимальных размер. Максимальный размер для файла может пригодиться, потому что мы сможем сразу отформатировать наше устройство хранение под заданные характеристики, зарезервировав и количество dentry (записей в директориях) и место под каждый файл.
Наш superblock может выглядеть следующим образом:
Первые два байта это просто идентификатор файловой системы, для проверки что наше устройство хранения отформатировано нужным образом. Далее идут счетчик файлов, на случай если мы хотим не сразу отформатировать все файлы, а все таки иметь возможность создавать как в настоящей файловой системе. Далее идет максимальное количество этих файлов. Оба параметра имеют размер 1 байт, вряд ли нужно хранить больше 255 файлов на подобной системе. Затем идет максимальная длина файла. И дальше пара необязательных параметров. free_space это свободное нераспределенное пространство, хотя его можно вычислить в через inode_count. А buff_bk служит для определения буферизации. Он полезен поскольку во внутренней флешь памяти перед записью нужно стереть целый блок. Этот параметр тоже может быть вычислен и его не обязательно хранить на устройстве.
Далее мы можем сразу разместить записи для директории, она у нас одна поэтому данные могут располагаться сразу за superblock
Все просто, первый параметр имя файла. Второй смещение начала данных в устройстве хранения. Третий текущая длина. И четвертый необязательный флаги или атрибуты файла.
Рассмотрим некоторые функции драйвера:
Функция заполнения suberblock похоже на аналогичную в initfs тоже устанавливаем обработчики операций, но так как у нас реальная файловая система нужно считать данные superblock с устройства и еще заполнить inode для корневой папки
Функции iterate и lookup тоже аналогичны initfs, разница только в формате представления dentry.
Поскольку у нас добавилась возможность записи на файловую систему, то необходимо реализовать например функцию itruncate которая изменяет текущий размер файла.
Тут тоже все просто, считываем dentry для файла, меняем текущую длину и записываем.
Самая интересная функция конечно запись, ведь если чтение это просто копирование из определенного адреса (ну или считывание блока и копирование, если флешь все таки внешняя), то запись как известно достаточно сложная операция. Причем записать можно только ячейку которую предварительно стерли. То есть для того чтобы записать какой то блок данных, нужно сохранить (закешировать) блок при этом еще и вместо старых данных записать новые, стереть изначальный блок и записать его новыми данными.
То есть мы сначала чистим ассоциативный кэш, затем копируем в этот кэш данные из блока которые не будут изменены, затем записываем новые данные, и копируем оставшиеся не измененные данные из старого блока. И наконец данные из кэш переносятся обратно в блок данных, перед этим он конечно стирается.
Зачем стирать кэш? Ведь обычно это просто массив данных в RAM размером с блок данных. Но в некоторых микроконтроллерах присутствует достаточно много flash памяти, но RAM ограничена. Пример STM32F4-discovery имеет 1024 кБ flash. Среди них 4 блока по 16кБ которые можно было бы использовать под наши нужды. Но при этом есть всего 128+64кБ ОЗУ. И не всегда есть достаточно памяти чтобы выделить 16 кБ в ОЗУ. Тогда для кэширования можно использовать второй блок по 16КБ.
Наша файловая система почти готова. Осталось только научиться писать в правильные блоки внутренней флешь. То есть нужно выделить несколько блоков памяти и превратить их в блочное устройство. Давайте поступим также как и с cpio архивом. Скажем линкеру зарезервировать соответствующую память.
Операции работать с блочным устройством рассматривать не будем, это выходит за рамки данной статьи.
Собственно все, у нас получилось сделать примитивную файловую систему с ограниченным количеством файлов, без директорий с ограниченной длиной файлов, но перезаписываемую имеющую минимально возможные накладные расходы, и позволяющую разместить ее где угодно, даже в 2 кБ внутренней памяти. (количество файлов и их максимальный размер будут соответствующие).

На этом скриншоте виден файл с настройками сети, которые могут быть изменены в процессе работы. А также приведены данные самой файловой системы. Можно увидеть и superblock и dentry и поскольку файл первый содержимое самого файла.
То же самое можно увидеть напрямую в памяти.

Остается отметить сколько нужно ресурсов. Сам драйвер занимает меньше килобайта, мы его почти весь разобрали. Накладные расходы на RAM, собственно их и нет, точнее они включены в расходы самой файловой системы, нужно иметь superblock и другие объекты, чтобы работать с файлами, но они у нас уже были включены для работы с initfs. Ну и конечно есть код драйвера для работы с flash, сама флешь и кэш буфер для нее. Но все это также нужно и при работе напрямую без файловой системы.
Лог-файлы
Для этого можно создать специальную файловую систему. Но у нас же есть файловая система, а по сути дела лог-файл, это просто файл который записывается по кругу. Таким образом мы можем разработать библиотеку и приложение, которое будет независимым от формата файловой системы, флешь памяти и самого микроконтроллера. Следовательно разрабатывать будет куда проще. Можно даже взять какой нибудь существующий логгер, но я все таки хочу добавить немного специфики. Пусть наш файл будет иметь ограниченное количество записей и записи будут одинакового размера.
Разрабатывать и отлаживать прикладной код можно прямо на Linux, но я это сделаю для Embox и запущу в qemu.
Функция печати лога:
Приложение настолько простое что пояснять его не нужно.
Таким образом формат нашей записи будет:
Результаты хорошо видно на скриншоте:

Добавим наш логгер в конфигурацию для платы STM32F4-Discovery. И получим тоже самое поведение:

Простое устройство
Файловая система это конечно хорошо, но давайте попробуем применить ее на каком нибудь простом устройстве.
Все, теперь просто скриншоты, на которых по моему мнению все понятно.




Заключение
Из статьи видно, что для организации файловой системы на микроконтроллере действительно требуются некоторые ресурсы. Но они не такие большие как кажется на первый взгляд. Несколько кБ если нужно сохранить 16 байт настроек, избыточны. Но с другой стороны большинство современных устройств и так имеют веб интерфейс или какой то другой интерфейс для управления, а значит в любом случае потребуются ресурсы для хранения этих данных.
Кроме того нужно учитывать, что флеш память имеет блочную структуру, следовательно если мы хотим хранить внутри микроконтроллера изменяемые настройки, нужно выделить как минимум один блок. А даже для f4 это 16 кБ.
Если же устройство имеет SD карту и требуется уметь читать FAT то в этом случае, добавление файловой системы для настроек и логирования, точно имеет смысл, поскольку за незаметные накладные расходы мы получаем удобство и универсальность решения. Например описанная в статье DumbFS работает на сериях STM32 (f3, f4, f7, h7) причем другие просто не пробовали. А сам приведенный в статье логгер вообще работает на любой файловой системе.
P.S. Спасибо за комментарии. Решил немного дополнить, изначально думал, что это понятно.
Статья направлена не на рассмотрение правильного способа сохранять настройки или логи в микроконтроллере. Есть разные способы это сделать. В статье показываются удобства и преимущества использования файловой системы и приводятся данные о том, что затраты могут быть очень небольшими. Поэтому этот подход можно использовать в том числе в микроконтроллерах.
В статье не разбираются особенности организации блочных устройств или flash памяти. Это отдельная тема. Все тоже самое, или только лог могут быть размещены не внутри микроконтроллера, а во внешней flash или другом носителе. Для этого нужен только драйвер этого устройства. Проблема учета износа ячеек также не рассматривается, это можно сделать либо на уровне драйвера блочного устройства, либо на уровне файловой системы. Ну и конечно, все исходники доступны в репозитории Embox
Термины Редактор: Дмитрий Сокол 20382 22 мин АудиоЛог-файлы (файлы регистрации, журнальные файлы) на Linux - это текстовые файлы о событиях, произошедших на сайте: информация о параметрах посещений сайта и ошибках, которые возникали на нем.
Вебмастерам нужно получать информацию о том, как работает их сайт и сервер. Это можно узнать из log-файлов.
На виртуальном хостинге владельцы сайтов работают с логами web-сервера, доступ к которым предоставляет провайдер.
На VPS/VDS и выделенных серверах можно работать с самыми разнообразными логами, которые записывают все работающие на сервере службы.
Информация, хранящаяся в лог-файлах, служит основой для диагностики работы различных системных служб, а также для разнообразной аналитики, например, о посещаемости сайта или о попытках взлома системы.
На платформе Windows также имеется служба журналирования событий, но там информация записывается не в текстовые файлы, а в журналы специального формата, доступ к информации которых возможен через службу Event Viewer.
Log-файлы и виртуальный хостинг
Провайдер хостинга обеспечивает доступ к лог-файлам web-сервера через панель управления. Например, у провайдера Beget это выглядит так.

Также доступ к лог-файлам конкретного сайта можно получить через файл-менеджер (или по протоколу FTP).
У провайдера Beget в менеджере файлов их можно найти здесь.

При использовании популярной панели ISPmanager log-файлы доступны пользователю и располагаются в каталоге /log. Для каждого из сайтов присутствуют два лог-файла:
- посещений (doman.name.access.log);
- ошибок (domain.name.error.log).

Виды лог-файлов
Все программы и сервисы Linux ведут log-файлы.
Самые важные - это логи:
- веб-сервера;
- почтового сервера (maillog);
- FTP-сервера;
- сервера базы данных;
- подсистемы авторизации (auth.log)
- логи самой системы (messages, syslog).
Log-файлы на сервере хранятся в специальном каталоге /var/log, внутри которого создаются отдельные файлы и папки для того или иного сервиса.
Различие в хранении log-файлов по версиям Linux
Дистрибутивы Linux имеют разный набор программного обеспечения и различные правила хранении log-файлов. В настоящее время наибольшее распространение получили два семейства дистрибутивов Linux:
- системы, основанные на Debian (например, Ubuntu);
- основанные на RedHat (Centos, Fedora).
Конкретная версия операционной системы для VPS/VDS выбирается у провайдера в личном кабинете пользователя перед заказом виртуального сервера.
Общие принципы для всех систем Linux одинаковы: log-файлы хранятся в папке /var/log. Разница проявляется лишь в наименовании отдельных файлов и каталогов для определенных подсистем, что зависит не только от версии Linux, но и от используемой панели управления хостингом.
Системные log-файлы
Опишем наиболее важные системные лог-файлы, хранящиеся в каталоге /var/log.
1. Общий системный журнал, в зависимости от версии Linux, записывается в файлы /var/log/syslog (Debian) или /var/log/messages (Redhat). В него пишется информация, начиная от старта системы:
2. Логи авторизации: /var/log/auth.log (Debian) или /var/log/secure (Redhat). Сюда записывается информация об авторизации пользователей, включая неудачные попытки входа в систему.
4. /var/log/boot.log - log загрузки операционной системы Linux.
5. /var/log/cron - отчет службы запуска по расписанию CRON.
Почти все log-файлы Linux представляют собой текстовые файлы, в которых каждая строчка содержит метку времени и описывает определенное событие. Исключение - это бинарный файл “wtmp”, в котором содержится информация о последних заходах пользователей на сервер.
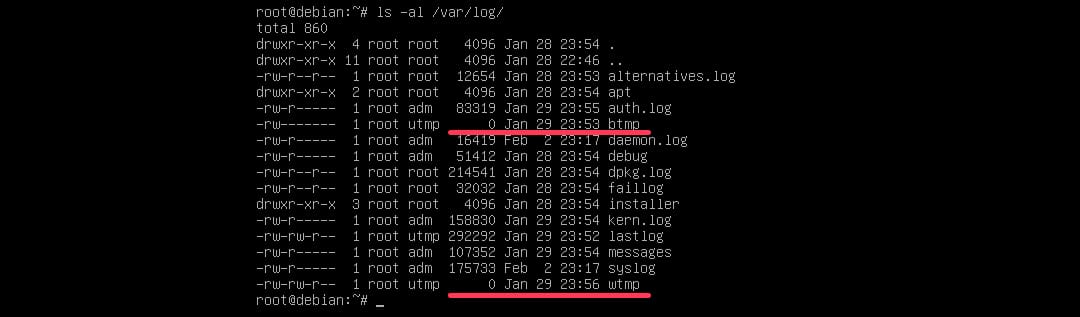
Пример: содержимое каталога /var/log на Linux-системе. Видны текстовые .log-файлы системы, а также двоичный файл wtmp.
Логи web-сервера
Как правило, сайты на сервере работают под управлением web-сервера Apache или Nginx. Также их можно применять на сервере вместе, что позволит использовать сильные стороны каждой программы.
И Apache, и Nginx создают по два файла: один - для записи посещений, второй - для хранения информации об ошибках.
Также к логам веб-сервера относятся лог-файлы интерпретатора PHP (php-fpm) и файлы ошибок PHP.
Логи web-сервера Apache
Web-сервер Apache создает два лог-файла:
Для удобства эти файлы могут создаваться по отдельности для каждого сайта, размещенного на сервере. Тогда они имеют названия “domain.name_access.log” и “domain.name_error.log”.

Пример лог-файла посещений Apache. Список файлов в каталоге показывается командой linux “ls -l”
Для чтения информации из log-файла можно использовать команду “cat имя-лог-файла” или “tail имя-log-файла”.

В зависимости от конкретной панели управления файлами, внутри этого каталога могут находиться папки domains или domlogs, в которых будут записываться лог-файлы отдельно для каждого сайта.
Логи web-сервера Nginx
Nginx также создает два лог-файла для посещений и ошибок. Они располагаются в каталоге /var/log/nginx . В случае совместной работы с Apache лог-файлы Nginx иногда объединяются в один файл с логами Apache, но это несколько неудобно, с точки зрения обнаружения ошибок.
Если Nginx настроен для обслуживания нескольких сайтов, то его лог-файлы записываются отдельно для каждого сайта.
В случае использования Nginx совместно с панелью управления Vesta, log-файлы для отдельных сайтов хранятся в папке /var/log/nginx/domains , а в папке конкретного пользователя в каталоге logs создаются псевдонимы для этих файлов.

Пример: вывод командой “ls *.log” списка log-файлов web-сервера nginx в папке /var/log/nginx/domains (на снимке экрана видно, что там хранятся файлы сразу нескольких сайтов)
Логи интерпретатора PHP
В PHP есть возможность записи ошибок для определенной страницы сайта в отдельный лог-файл (это делается через файл .htaccess). В таком случае файлы ошибок PHP располагаются в одном каталоге с конкретной страницей сайта и имеют вид “php_error.log” или просто “error.log”.
Ротация log-файлов
Для посещаемого сайта размеры лог-файлов могут достигать сотен мегабайт. Рано или поздно они начинают занимать много дискового пространства, поэтому на серверах Linux используется механизм ротации log-файлов.
Как это работает?
1. Данные о посетителях (или ошибках) сайта записываются в файл с обычным названием, например, access.log.
2. Раз в сутки (обычно в ночное время) этот файл автоматически переименовывается в “access.log.1” и сжимается архиватором Gzip.
3. Имя файла становится вида “access.log1.gz”.
4. Вместо этого файла web-сервер начинает записывать информацию в новый файл access.log.
5. Еще через сутки архивный файл “access.log.1.gz” переименовывается в “access.log.2.gz”, и вместо него создается новый архив “access.log.1.gz” из текущего log-файла web-сервера и так далее.
Всего на сервере хранятся сжатые log-файлы за последний месяц.
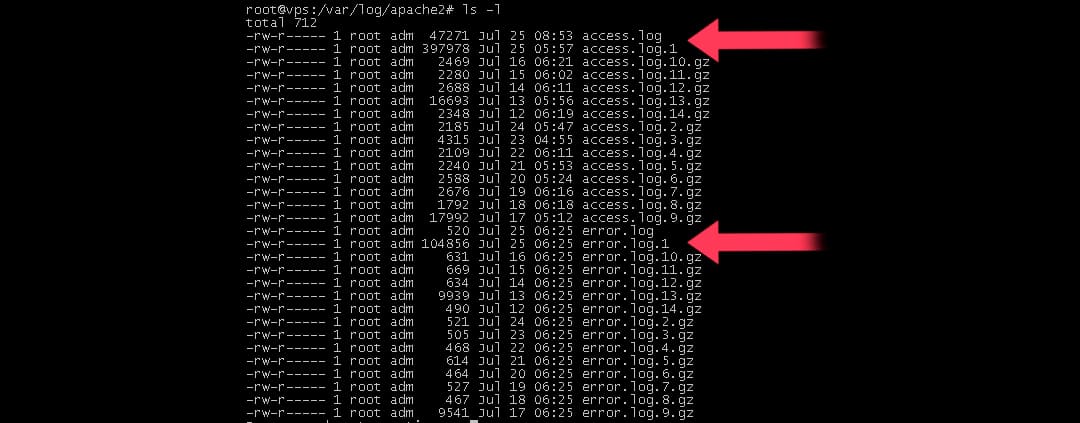
Пример: на снимке экрана виден список log-файлов web-сервера. Среди них присутствуют как текущие файлы access.log и error.log за сегодняшний день, так и файлы за предыдущие дни access.log.1, error.log.1 и так далее.
То же происходит и с log-файлами других сервисов: почта, FTP, системные логи - все они проходят через ротацию.
Таким образом, ротация файлов помогает сохранять место на диске. Зная общий принцип, по которому именуются сжатые лог-файлы, системный администратор может найти нужную информацию за конкретный период времени.
Log-файлы почтовой системы
На сервере Linux могут быть установлены разнообразные программы для работы почтовой подсистемы. В последнее время большинство панелей управления хостингом (VestaCP, cPanel, ISPmanager) используют связку из почтовой программы Exim для отправки и приема писем (протокол SMTP) и другой почтовой программы Dovecot - для доступа пользователей к почтовым ящикам (протоколы IMAP/POP3).

Пример: log-файлы сервера Exim в папке /var/log/exim. На снимке экрана - вывод списка файлов командой ls -l
Log-файлы FTP-сервера
Вариантов программного обеспечения для FTP Linux много, но принцип хранения log-файлов примерно одинаковый. В папке /var/log создаются log-файлы FTP-сервера, например, vsftpd.log или proftpd.log. Также практически всеми FTP-серверами создается файл xferlog, в котором записывается информация о файлах, скачанных с сервера или закачанных на сервер по протоколу FTP.

Пример: log-файлы FTP-сервера vsftpd. На снимке экрана - вывод команды списка файлов, созданных FTP-сервером (vsftpd.log и xferlog)
Log-файлы сервера базы данных
Популярный сервер базы данных MySQL также ведет log-файл “mysqld.log”. Он располагается в папке /var/log/mysql или /var/log/mariadb, в зависимости от используемой версии MySQL.
Также сервер MySQL может создавать в этой папке файл отладки медленных запросов к базе данных. Обычно он называется “mysql_slow.log”.

Пример: содержимое файла медленных запросов MySQL. Вывод содержимого log-файла командой “tail mysql_slow.log”
Использование log-файлов для отладки работы web-сайтов
Если, например, конкретный web-сайт показывает в браузере ошибку 500, то можно зайти в этот файл и посмотреть, что именно происходит на сервере.

Пример: просмотр лог-файла ошибок web-сервера из панели провайдера Beget через файл-менеджер

При работе с лог-файлами web-сервера на виртуальном сервере необходимо знать, в каком каталоге находятся log-файлы для того или иного сайта. Это зависит от установленного на сервере программного обеспечения, в частности, - от конкретной панели управления.

Пример: содержимое рабочего каталога панели VestaCP. Виден каталог logs, в котором хранятся log-файлы
- проблему с файлом .htaccess;
- ошибку подключения к серверу базы данных;
- ошибку языка PHP.

Использование log-файлов для аналитики
Любому владельцу сайта нужно знать аудиторию своих посетителей. Эта информация содержится в лог-файлах посещений web-сервера (access.log). Для удобной обработки информации провайдеры хостинга, а также панели управления предлагают такие системы: Webalizer и AWStats.
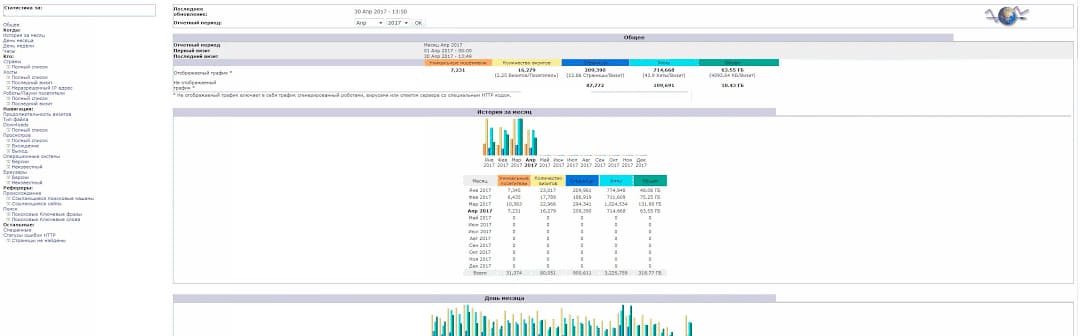
Пример: аналитика посещений web-сайта с использованием системы AWStats
Также на основе лог-файлов можно получить представление о распределении нагрузки на сайт по времени суток, следить за ошибками ненайденных страниц, вести мониторинг безопасности.
Я пытался использовать JSON.stringify(object) , но это не влияет на всю структуру и иерархию.
С другой стороны, console.log(object) делает это, но я не могу его сохранить.
В выводе console.log я могу по одному развернуть все дочерние элементы, выбрать и скопировать / вставить, но структура для этого слишком большая.
Вы можете использовать этот фрагмент devtools, показанный ниже, чтобы создать метод console.save. Он создает FileBlob из входных данных, а затем автоматически загружает его.
Существует еще один инструмент с открытым исходным кодом, который позволяет сохранить все выходные данные console.log в файле на вашем сервере - JS LogFlush (подключи!).
- кросс-браузерная замена консоли.log без пользовательского интерфейса - на стороне клиента.
- Система хранения журналов - на стороне сервера.
Это действительно поздно для вечеринки, но, возможно, это поможет кому-то. Мое решение похоже на то, что OP описал как проблемный, но, возможно, это особенность, которую Chrome предлагает сейчас, но не тогда. Я попытался щелкнуть правой кнопкой мыши и сохранить файл .log после того, как объект был записан в консоль, но все, что мне дало, было текстовым файлом с этим:
console.js: 230 Выполнено: массив (50000) [0… 9999] [10000… 19999] [20000… 29999] [30000… 39999] [40000… 49999] длина: 50000__proto__: массив (0)
Который был никому не нужен.
В итоге я нашел console.log(data) в коде, отбросил на нем точку останова и набрал JSON.Stringify(data) в консоли, которая отображала весь объект в виде строки JSON, а консоль Chrome фактически дает вам кнопку, чтобы скопировать его . Затем вставьте в текстовый редактор, и вот ваш JSON

- Щелкните правой кнопкой мыши объект в консоли и нажмите Store as a global variable
- вывод будет что-то вроде temp1
- введите в консоли copy(temp1)
- вставить в ваш любимый текстовый редактор
Существует плагин javascript с открытым исходным кодом, который делает именно это - debugout.js
Debugout.js записывает и сохраняет console.logs, чтобы ваше приложение могло получить к ним доступ. Полное раскрытие, я написал это. Он соответствующим образом форматирует различные типы, может обрабатывать вложенные объекты и массивы, а также может дополнительно ставить отметку времени рядом с каждым журналом. Это также включает живую регистрацию в одном месте.
Щелкните правой кнопкой мыши на консоли .. нажмите "Сохранить как . ", это так просто . вы получите выходной текстовый файл
Вы можете использовать команду Chrome DevTools Utilities API copy() для копирования строкового представления указанного объекта в буфер обмена.

Что за формат файлов evtx
Не так давно я вам делал подробную, обзорную статью, о том, как просматривать логи событий в Windows. Данный навык является базовым для системного администратора или продвинутого пользователя, так как позволял быстро локализовать и найти причину ошибок, синего экрана или других сбоев, которые очень часто появляются в данной операционной системе, что далеко ходить, достаточно вспомнить черные экраны или ситуации, когда пропадает звук в Windows 10, данный список очень масштабный.
Файлы формата evtx - это специальный тектово-архивный формат хранения файлов в которых содержатся все события операционной системы Windows. Открывать формат evtx можно с помощью оснастки "Просмотр событий". Для того, чтобы вы могли их посмотреть в других специализированных утилитах, вам необходимо их конвертировать в другой формат.
Формат LOG является более распространенным форматом для хранения различных событий и открывается большим количеством приложений. Поэтому я вас хочу научить, как буквально в одну команду вы можете преобразовывать формат EVTX в LOG.
Скачивание и установка LogParser 2.2
LogParser (Анализатор журналов) - это мощный универсальный инструмент, который обеспечивает универсальный доступ к запросам к текстовым данным, таким как файлы журналов, файлы XML и CSV, а также к ключевым источникам данных в операционной системе Windows, таким как журнал событий, реестр, файловая система и Active Directory. Так же он умеет производить конвертирование форматов. Чтобы загрузить LogParser 2.2 перейдите по ссылке:
Запускаем файл LogParser.msi, у вас будет запущен мастер установки "Log Parcer 2.2 Setup Wizard". Нажимаем сразу "Next".
Соглашаемся с лицензионным соглашением, выставив пункт "I accept the terms in the License Agreement".
Достаточно выбрать режим "Complete".
Далее нажимаем "Install".
Установка LogParser 2.2 завершена.

В результате чего у вас по пути "C:\Program Files (x86)\Log Parser 2.2" будет установлена утилита командной строки.
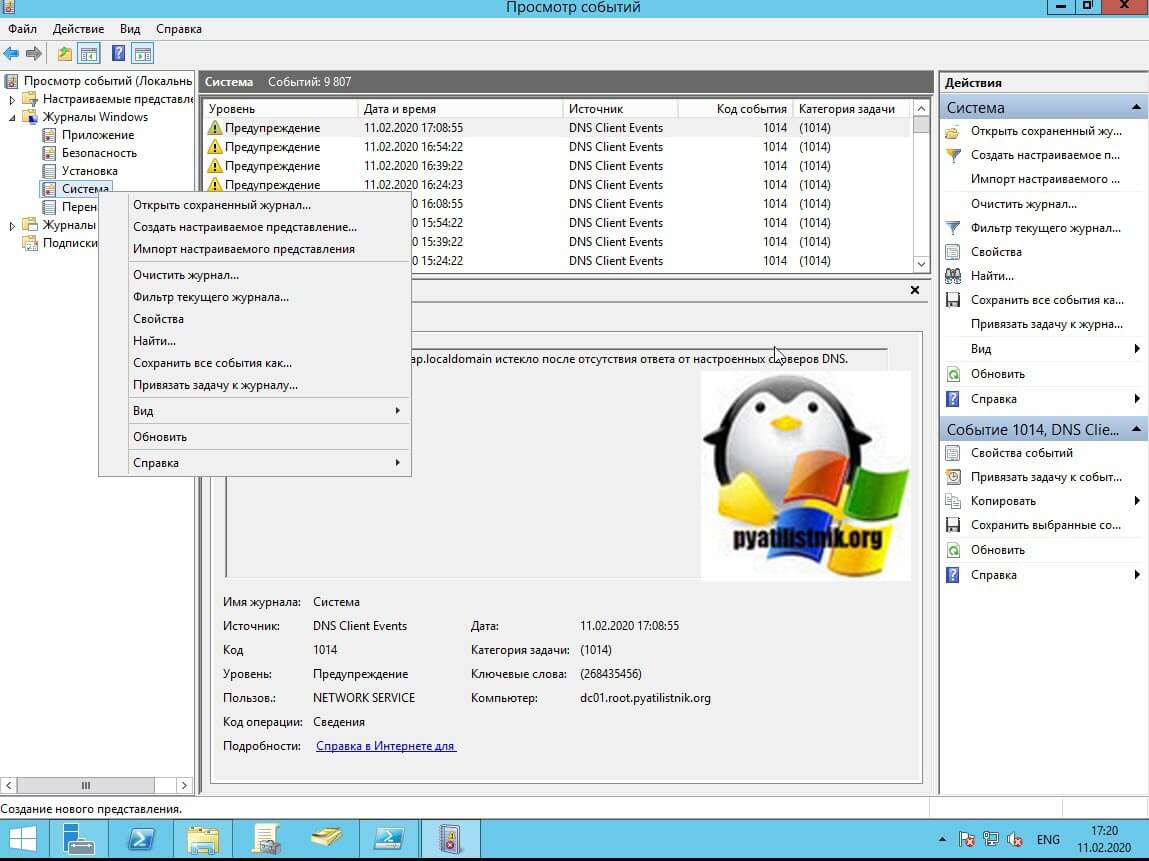
Теперь для тестирования я со своего контроллера домена сохраню логи из журнала система в формате evtx. Делается это через правый клик и выбор пункта меню "Сохранить все события как".
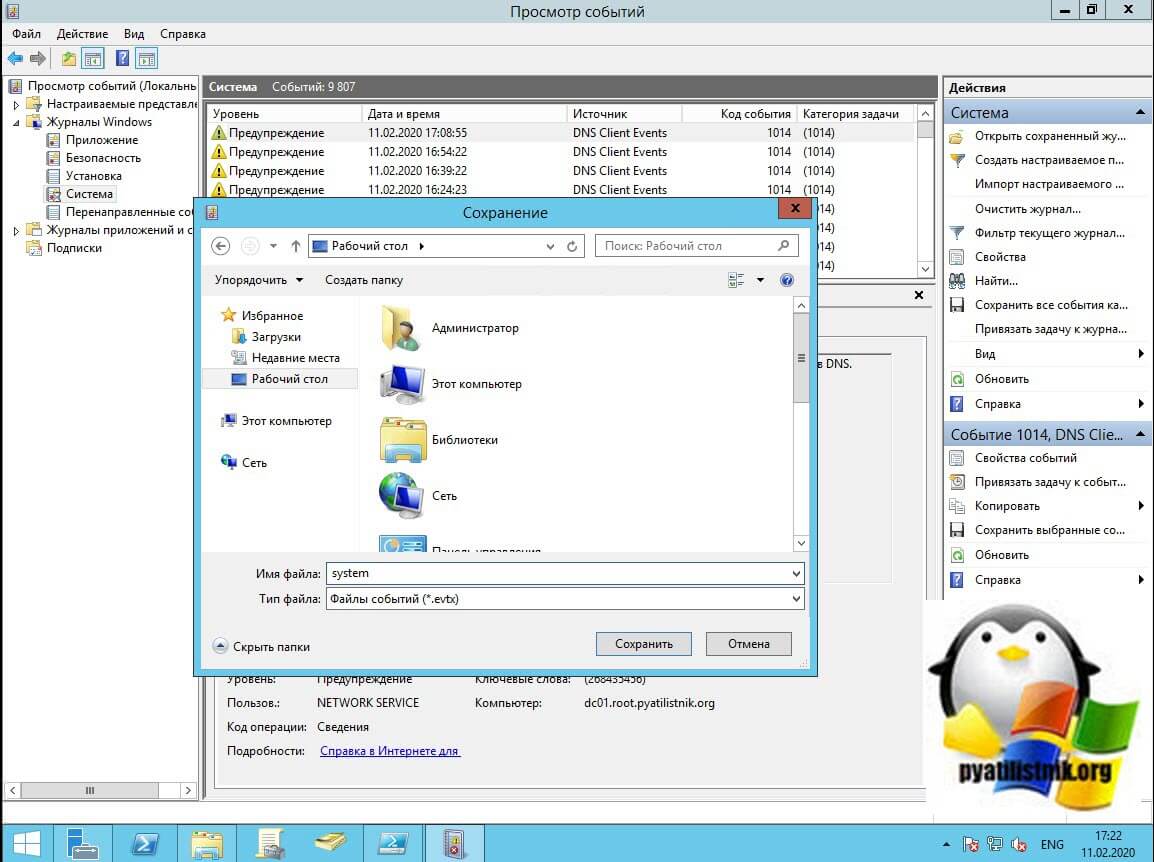
задайте имя и месторасположение файла.
Далее вам необходимо выполнить вот такой скрипт в PowerShell, единственное указав какой файл вы будите конвертировать. В моем примере файл лежит по пути "C:\scripts\system.evtx", а так же задайте папку куда будет сохранен файл в формате log. Я для тестирования открою PowerShell в режиме ISE.
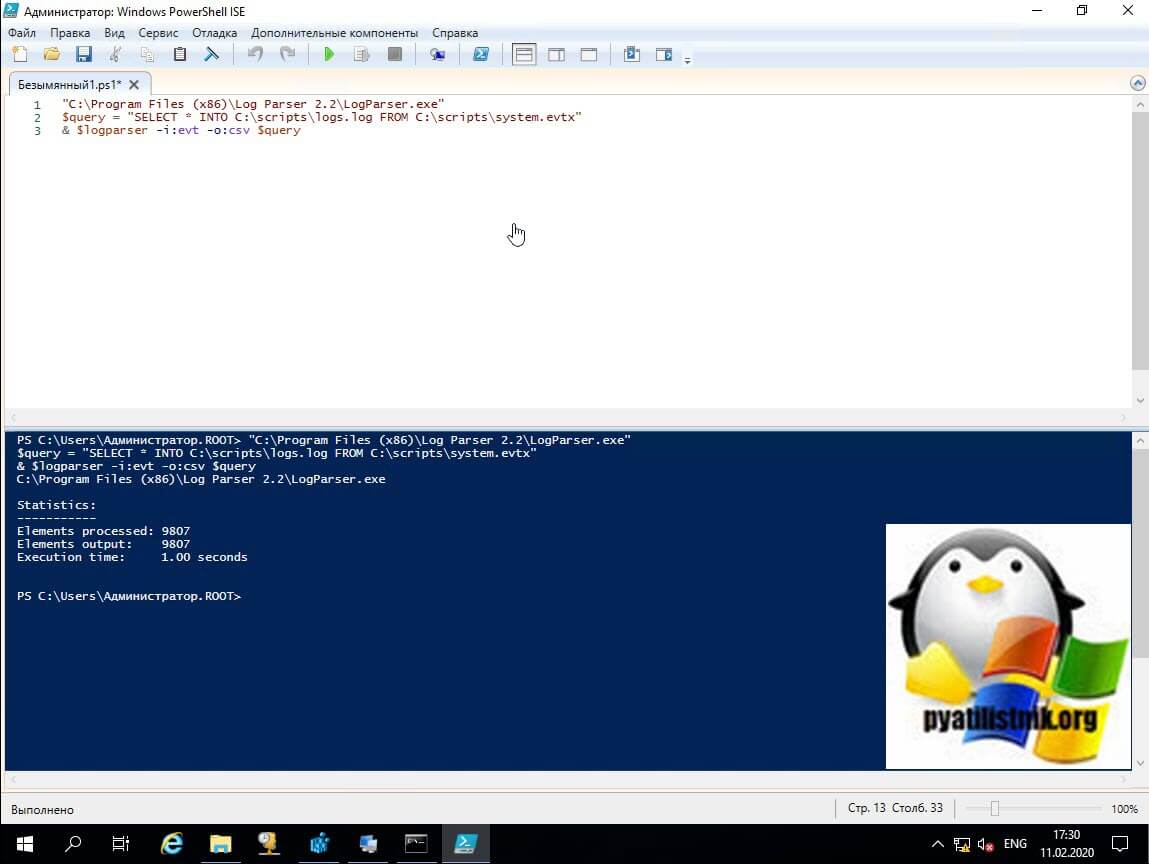
$query = "SELECT * INTO C:\scripts\logs.log FROM C:\scripts\system.evtx"
& $logparser -i:evt -o:csv $query
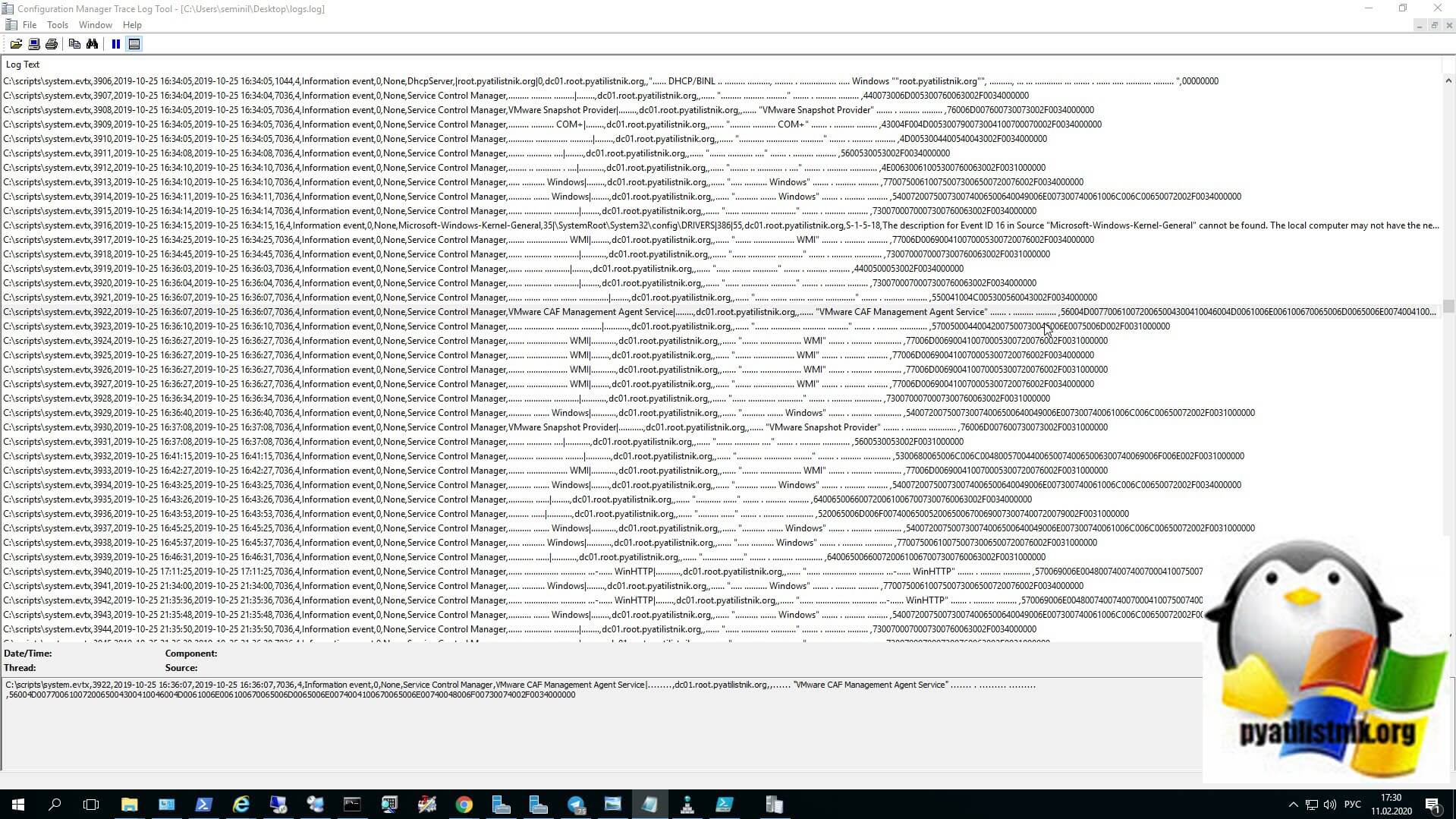
В результате вы видите. что скрипт успешно отработал и утилита LogParser 2.2 произвела конвертирование файла логов из формата evtx в log. Проверяем, что файл открывается, например простым блокнотом.

Пробую открыть файл в "Configuration Manager Tracelog Tool". Как видно, все отлично читается.
Конвертирование evtx в log через LogViewPlus
LogViewPlus - это очень удобный инструмент по работе с файлами журналов Windows и не только. Утилита полностью бесплатная. LogViewPlus умеет:
- С LogViewPlus вы можете открыть столько файлов журнала, сколько вам нужно, и нажать одну кнопку, чтобы объединить их. Объединенные записи файла журнала автоматически сортируются по дате, поэтому информация представляется записываемой одним процессом. Объединение файлов журнала поможет вам лучше понять, как несколько процессов взаимодействуют друг с другом.
- Быстрые фильтры данных журнала лучше, чем поиск, потому что фильтры могут быть связаны. Например, вы можете сузить файл журнала до определенной цепочки, а затем выполнить поиск только в этой цепочке. Фильтры также могут применяться автоматически при настройке файла журнала. Это похоже на работу tail и grep, но полностью переработано для Windows.
- Вы можете открывать файлы более 4 ГБ - LogViewPlus любит большие файлы журналов и может открыть файл журнала 500 МБ примерно за 30 секунд (в зависимости от вашего оборудования). Открытие больших файлов ограничено только объемом памяти, который у вас есть на вашем компьютере. LogViewPlus может разделить файл на части и позволить вам решить, какой блок вам интересен. Вы даже можете открыть несколько частей и затем объединить свои журналы по мере необходимости.
- LogViewPlus обрабатывает обновления файла журнала в реальном времени с помощью функциональности, аналогичной команде Unix 'tail', которая отслеживает записи журнала по мере их записи в файл журнала. Это означает, что вы сразу видите новые записи в вашем журнале просмотра. Не нужно возиться с кнопкой обновления. Хвост файлы журнала в окнах, как профи. Командная строка не требуется.
- LogViewPlus включает встроенную поддержку таких технологий, как SFTP, FTP, SCP и SSL, а также подключенные диски и общие ресурсы Samba. Теперь вы можете читать и записывать все свои файлы журналов в Windows без запуска сеанса telnet.
- LogViewPlus поддерживает подсветку синтаксиса для всех записей журнала. LogViewPlus может даже распечатывать записи журнала, содержащие XML или JSON.
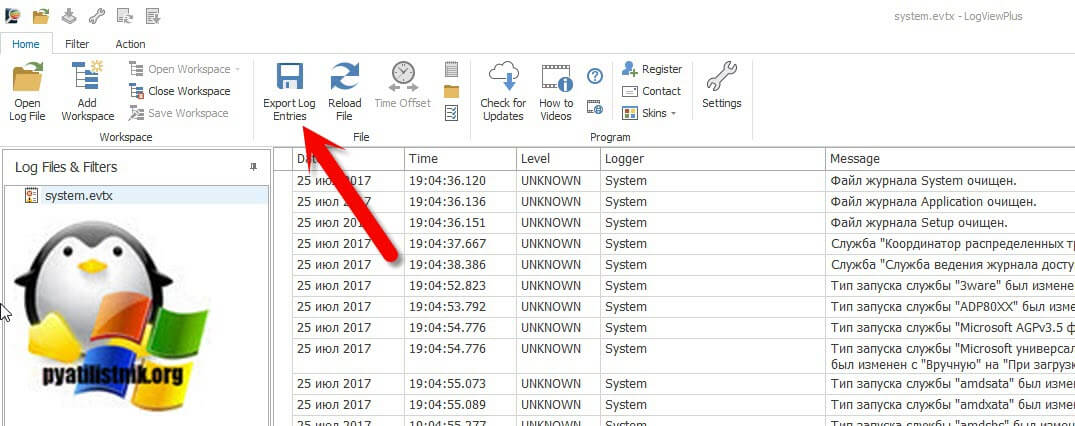
После установки LogViewPlus вам нужно открыть ваш файл в формате evtx. Далее находите кнопку "Export log Entries".
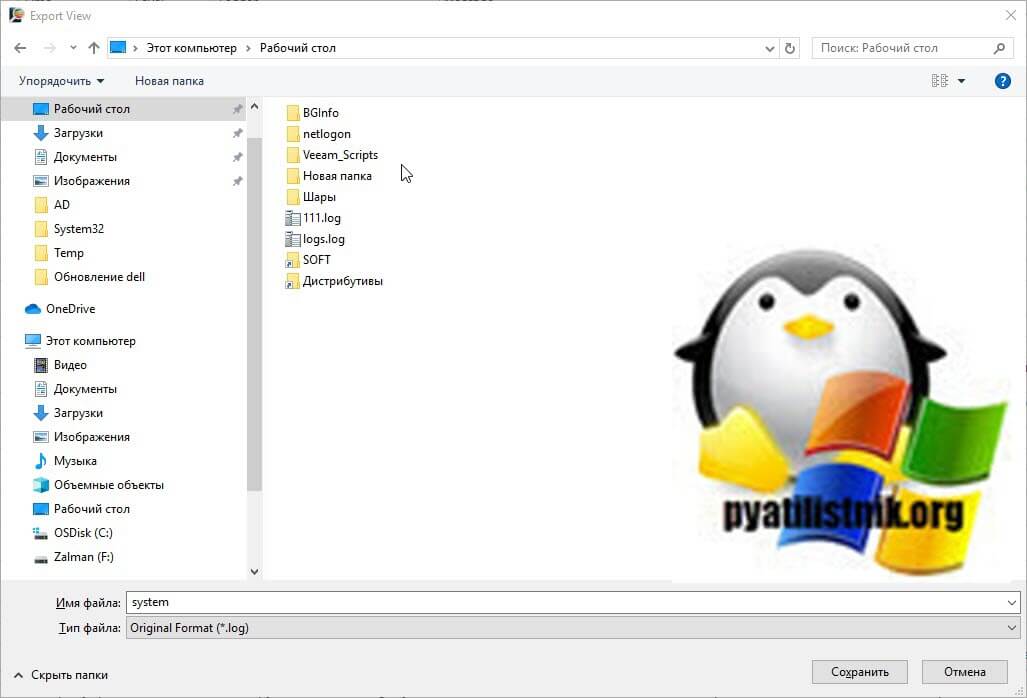
Задаете имя экспортируемого файла в формате log и нажимаете сохранить.
Конвертирование evtx в log через wevtutil
wevtutil - это встроенная в Windows утилита. Позволяет получать информацию о журналах событий и издателях. Эту команду также можно использовать для установки и удаления манифестов событий, для выполнения запросов, а также для экспорта, архивирования и очистки журналов. Данная утилита так же помогает в одну команду произвести преобразование формата evtx в log. Откройте командную строку и введите:
Читайте также: