
Как сделать компрессию в adobe audition
Как обрабатывать дикторский голос? Это был один из самых частых вопросов в комментариях в уходящем 2019 году.
Конечно, в наше время уже нет таких строгих требований к дикторской речи, какие были ещё буквально несколько десятилетий назад. Сегодня правило фактически одно: качественную запись слушают охотнее. В этом видео мы расскажем вам про 9 составляющих успеха для диктора. В том числе рассмотрим: обязательный контроль над голосом (выразительность, интонация), дефекты речи и можно ли их убрать программным образом, звукопоглощение и звукоизоляция, расстояние от микрофона, использование поп-фильтра, эквализация, компрессия, сатурация или насыщение звука, добавление эффектов хоруса и ревера, а также каким должен быть итоговый уровень громкости.
Итак, что нужно для того, чтобы мы с вами звучали плотно сочно и эффектно, чтобы не было ни громко, ни тихо, и чтобы наша речь по качеству ничем не уступала радийным ведущим?
Контроль над речью
Нет таких примочек. Поэтому или превращаем свой дефект в фишку, как можно слышать это на некоторых радиостанциях, типа Comedy Radio, или стараемся работать максимально пряча свои дефекты. Ну либо обращаемся к логопедам, преподавателем по технике речи и так далее. Кстати, можем пригласить таковых профи в нашу студию, которые разбираются в физиологии этих процессов намного больше нас, и попробуем разобрать эти нюансы и рассмотреть методы борьбы с ними.
Подготовка к записи
В этом пункте обращаем самое серьёзное внимание на комнату. Она должна иметь звукопоглощение или звукоизоляцию. А также на правильное расстояние до микрофона, и его положение. И собственно, на уровень громкости.
Использование поп-фильтра
Чистка записанного материала
Убираем все ненужные шумы, которые могут быть слышны в паузах. Можем это делать как вручную, так и с использованием различных нойз-гейтов.
Последний случай будет особенно приемлем, когда наша речь будет идти под какую-нибудь фоновую музыку, поскольку без неё работа гейта будет скорее всего слышна и это может несколько испортить картину.
Ну и здесь же сразу избавляемся от шипящих и свистящих, если они нам будут мешать. Обычно это делается деэссером.
А также в этом пункте можем вручную подравнять всю нашу динамику. Прибираем какие-то громкие фрагменты, тихие поднимаем.
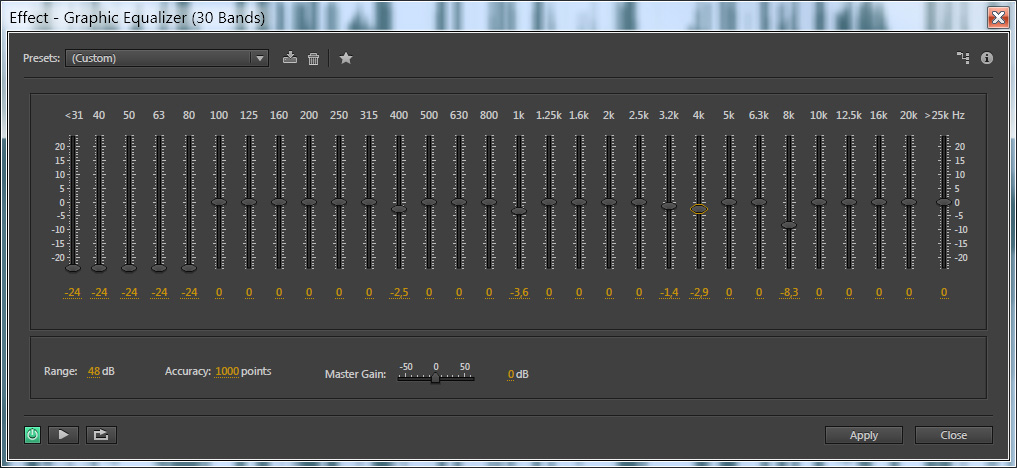
Эквализация
Это пункт сугубо индивидуальный. У каждого голоса есть свои тембральные особенности, и соответственно, преобладание или наоборот нехватка каких-либо частот.
Но как правило, любому голосу всё, что ниже 60 герц не надо, поэтому смело их отрезаем, хотя в некоторых случаях границы среза может доходить и до 160 герц. И помимо характера голоса надо ещё учитывать и реакцию вашего микрофона, который в большинстве случаев кардиоидный, и эффект близости там будет присутствовать.
Напомню, что это тот случай, когда выразительность достигается путём близкого расположения микрофона и минимального уровня громкости. И однонаправленные микрофоны обязательно дадут порцию низкочастотных призвуков.
Идём дальше и пытаемся вычислить неприятное бубнение, которое может засесть в диапазоне от 150 до 300 герц. Если обнаружили, аккуратно прибираем.
Компрессия
Атака 0-10, релиз 5-50, ratio 2 к 20. Ну а что касается самих приборов, я имею ввиду виртуальные, то их сейчас огромное количество и лучшим наверное будет тот, к которому вы
привыкли или в котором вам максимально удобно работать.
Сатурация
Главное, чтобы этим прибором мы действительно добились нужного нам эффекта.
Эффекты хорус и ревер
Эти прелести также могут создать дополнительный кайф звучанию вашего голоса, но это исключительно по вашему желанию, и в случае, если по-прежнему нужного объема вы никак не сумели добиться, или вообще хотите придать звуку так называемую радиальность.
Работайте с этими эффектами очень ювелирно, ведь если перестараетесь, это будет некая каша из голоса и кучи примочек.
Конечный уровень
Это финальная стадия обработки, на которой мы выставляем окончательный уровень громкости нашей голосовой дорожки.
Здесь нам помогут любые устройства, имеющее в себе усилитель и лимитер. Это всевозможные ультрамаксимайзеры, нормализаторы, и так далее. И делается всё для того, чтобы среди прочих выступлений спикеров или каких-то рекламных роликов мы со своим прочтением не потерялись. Какого же финального уровня надо придерживаться?
Вопрос на самом деле очень непростой. На него не всегда могут ответить даже те люди, которые работают на ТВ или радио, и выдают нам технические требования.
Вот вам для смеха одно из них, присланное с одного из наших федеральных каналов.
Частота дискретизации 48 тысяч герц, глубина дискретизации 24 бит. Нормально?
И кстати, больше ни слова.
А вот ещё одно требование от авторитетного российского телеканала, где вроде бы всё по уму и красиво, но со слов тех же коллег по цеху ни одно рекламное агентство такие цифры не принимает, мол это очень тихо. Вот и думай, что хочешь. Одним словом, если ориентироваться на опыт многих, кто занимается дикторской начиткой, всё делается в основном на слух с подглядыванием на измерительную шкалу.
Во время записи вокала, одни его части звучат громче других. Всё это происходит по нескольким причинам. Первая – это отдаление и приближение к микрофону вокалиста в процессе пения. Вторая – разница в громкости при пении куплетов и припевов. Обычно припевы получаются более громкими из-за более эмоционального исполнения.
Обработка вокала с помощью инструмента Dynamics Processing
Для устранения разницы в громкости применяются специальные приборы динамической обработки звука, называемые компрессорами.
Рассмотрим процесс обработки вокала инструментом Dynamics Processing программы Adobe Audition 3.0
1. Запустим программу Adobe Audition 3.0 и загрузим наш вокал, выбрав в меню File / Open. На графике волновой формы вокала отчетливо видна разница в громкости на разных участках. Также мы можем увидеть превышение сигналом порога в 0 дБ, что чревато появлением клиппирования.

2. Используем для обработки вокала инструмент Dynamics Processing. Для этого выберем в меню Effects / Amplitude and Compression / Dynamics Processing.

3. Настраиваем плагин. Для этого давайте рассмотрим 4 его вкладки.
Вкладка Graphic используется для прорисовки графика компрессии.
По горизонтальной оси регулируется уровень входного сигнала, а по вертикальной – выходного. Инструмент может быть использован как компрессор, лимитер, экспандер или гейт.
На этой вкладке вы можете добавлять на график дополнительные точки и регулировать их положение по необходимости.

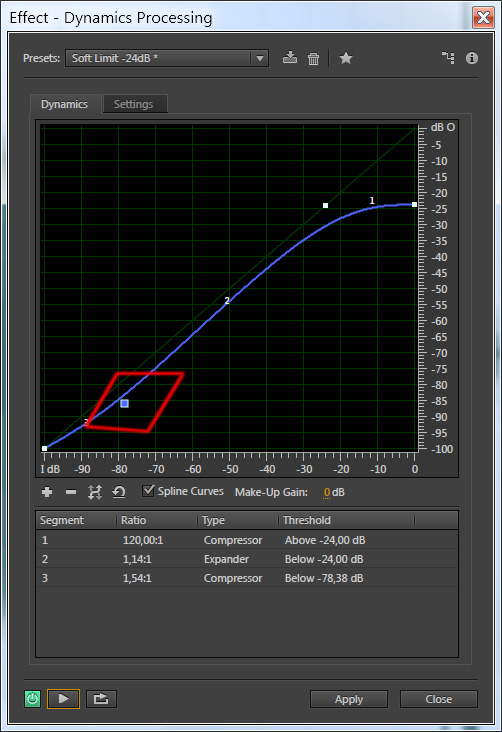
На вкладке Traditional настройки плагина представлены в более привычном виде. Здесь можно настроить порог срабатывания (Threshold), коэффициент компрессии (Ratio) и режим работы плагина для шести точек, а также уровень сигнала на выходе после компрессии.

Вкладка Attack / Release предназначена соответственно для настроек параметров атаки (скорости срабатывания) и восстановления (скорости выключения). Здесь также можно увеличить уровень выходного сигнала.

Вкладка Band Limiting предназначена для выбора диапазона компрессирования с помощью параметров Low Cutoff (отсечение сигнала, который находится ниже заданного порога) и High Cutoff (отсечение сигнала, который находится выше заданного порога).

Для правильной настройки компрессора установите следующие значения: Threshold – 0 дБ, Ratio – 2, Attack – 2-10 мс, Release – 150 мс. Начинайте опускать порог срабатывания (Threshold) пока не почувствуете, что сигнал подвергается обработке. После этого, начинайте подбирать соответствующую степень сжатия с помощью параметра Ratio. Это значение колеблется в пределах 2:1 – 8:1. Большие значения могут сделать вокал сухим и безжизненным. Будьте аккуратны, постоянно сравнивайте обработанный сигнал с необработанным.
Если вы услышите так называемую «накачку» (один из нежелательных артефактов) сигнала в промежутках между фразами, попробуйте увеличить время восстановления или поднять порог срабатывания. Если теряется артикуляция отдельных слов, отрегулируйте атаку.
Я выставил следующие параметры:
Ratio – 3, 98: 1
Attack – 8 мс
Release – 270 мс
Output Gain – 5 дБ
Вы можете увидеть эти параметры на рисунках выше.
4. После выполнения необходимых настроек нажимаем Ок.
Давайте сравним вокал до обработки и после.
Послушаем голос до обработки.

Послушаем голос после обработки
Как видим динамический диапазон стал намного уже. Теперь весь вокал имеет приблизительно одинаковый уровень громкости.
Хочется отметить, что для компрессии вы можете использовать более удобные и привычные для вас компрессоры, например Waves C1, Tube-modeled Compressor программы Adobe Audition и многие другие.

На этом этап обработки вокала с помощью компрессии можно считать завершённым.
В следующей статье поговорим о коррекции вокала с помощью инструмента Melodyne.

Голос до обработки
Микрофон: Perception 120.
Задача: Записать голосовое сопровождение для некоего ролика и наложить его на музыку. В качестве примера буду приводить отрывок.
Записанный трек звучит следующим образом:
Пошаговая обработка голоса
1 шаг. Откроем трек в программе Adobe Audition.
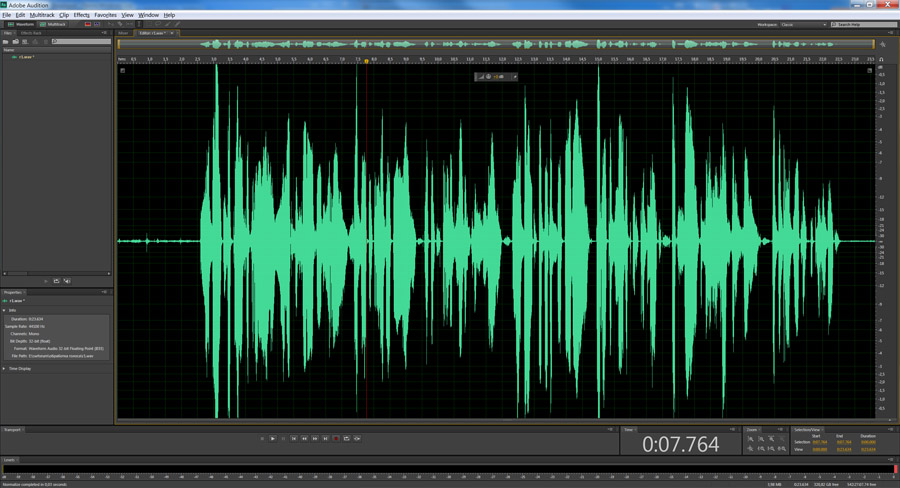
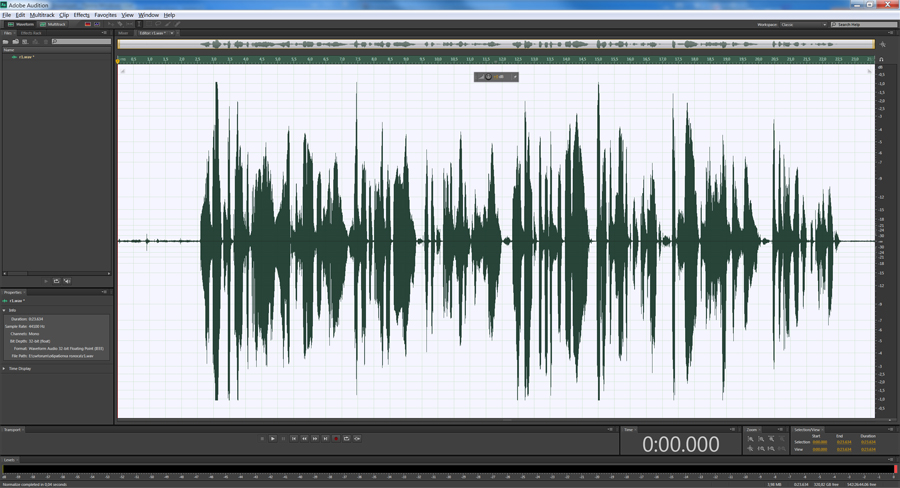
Трек будет выглядеть вот так:
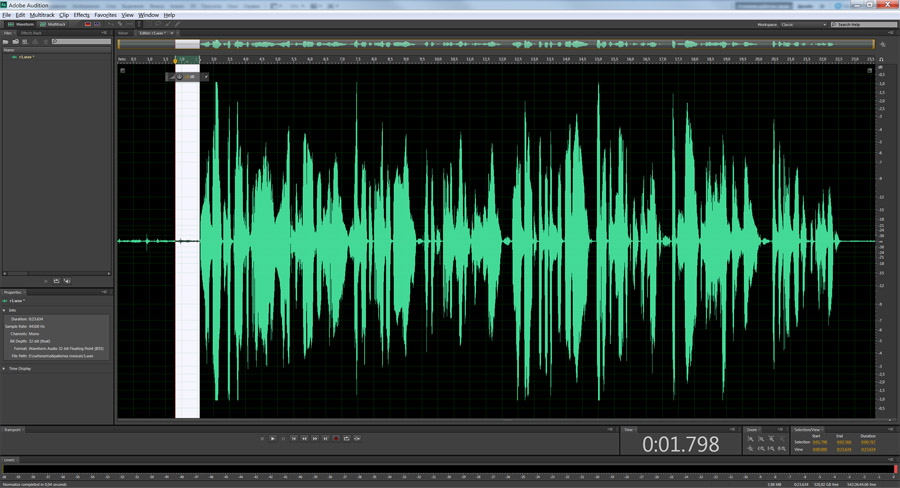
3 шаг. Избавимся от шумов. Для этого, пользуясь указателем мыши, выделим на треке небольшой кусочек шума, как здесь:
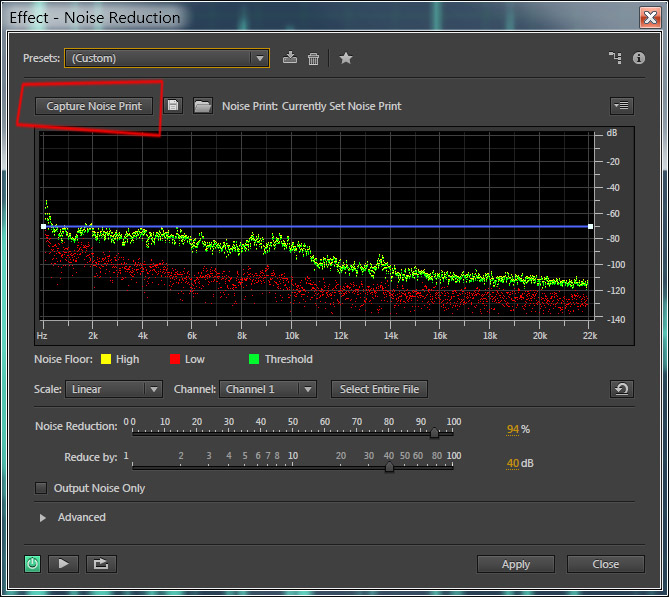
Здесь, нужно будет нажать на кнопку Capture Noise Print и в окне ниже появится график выделенного звукового сэмпла шума. Если данная кнопка не активна, то это означает, что вы выбрали слишком маленький кусочек шума, нужно закрыть диалоговое окно, выделить заново шум и вызвать эффект Noise Reduction. Смысл данного действия заключается в том, что программа запомнит частотную дорожку шума и попытается автоматически убрать все похожие частоты из трека. параметр Noise Reduction в 94% (можно и 100%, зависит от силы шума), остальное оставим по умолчанию и нажмем клавишу Applay .
Теперь обратите внимание, как будет выглядеть кусочек выделенного шума после применения эффекта. Звуковая волна стала практически прямой.
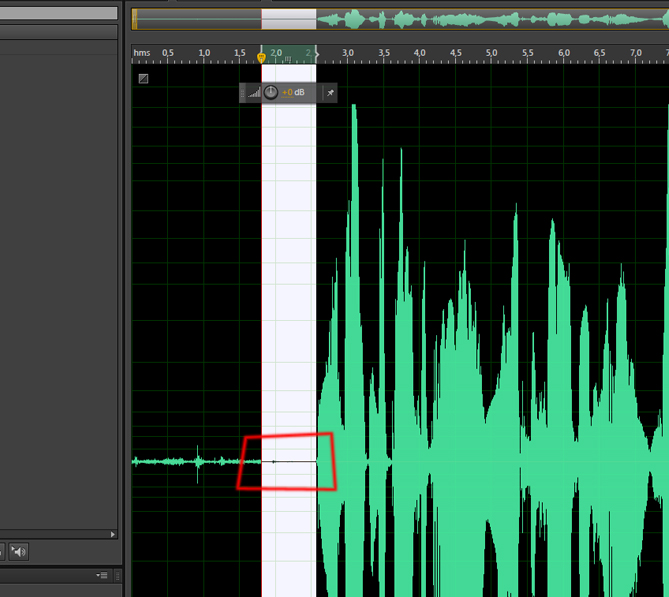
Теперь нужно избавиться от шумов во всем треке, для этого, выделим трек, нажав ctrl+A, вызовем тот же эффект и просто нажмем на кнопку Applay , образец шума будет использоваться старый, поэтому никаких настроек делать не надо. Трек будет выглядеть так:
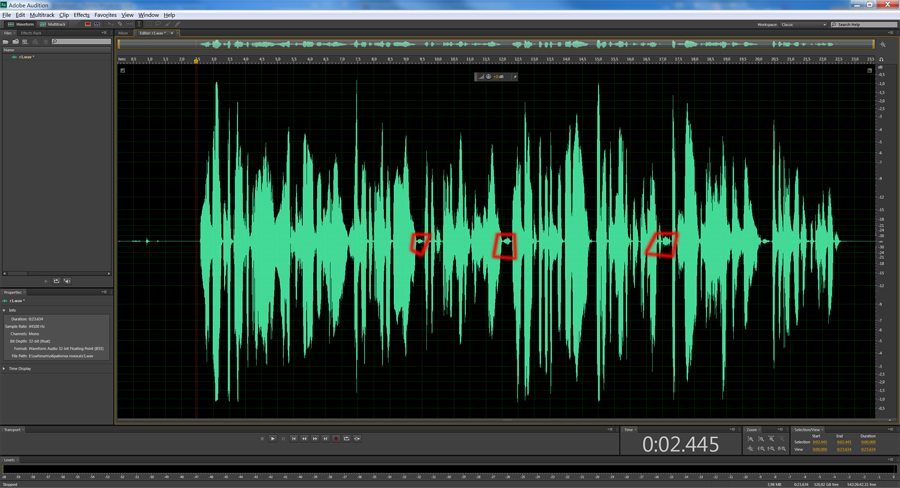


Голос после обработки
Теперь в принципе можно уже прослушать результат:
На этом я решила не останавливаться, поэтому:

В результате получилось следующее:
Надеюсь, моя статья оказалась для вас полезной. И не судите строго, так как все, что я сейчас показала я раскопала сама на просторах интернета без помощи профессионалов. Если вы считаете, что обладаете куда большими знаниями по качественной обработке голоса, то напишите о своем опыте в комментариях к данному посту. Будет очень интересно. Всего доброго!
Подписывайтесь на обновления блога «Дизайн в жизни»
по e-mail или социальных сетях
и мы обязательно опубликуем для вас еще больше полезной и интересной информации!

Случалось ли вам раздражаться из-за того, что звук на видео то слишком громкий, то слишком тихий? И что бы вы ни делали, все сводилось к ручной регулировке громкости. Больше это не будет выводить вас из себя. Сегодня я расскажу вам, как избежать подобных косяков, и что такое компрессия звука.
ПРИЧЕМ ЗДЕСЬ КОМПРЕССИЯ?
Если в вашей монтажной программе включено отображение звуковых волн аудиосигнала, вы видели как они постоянно скачут. Они то очень большие (громкие), то маленькие (тихие). Такой звук невозможно слушать: приходится то прислушиваться, то затыкать уши.
Возьмите любую хорошую аудиозапись песни и киньте ее в монтажную программу. Вы увидите ровные звуковые волны. Это значит, что песня практически на всей длительности звучит с одним уровнем звука. Такой звук комрпессированный.
КАК КОМПРЕССИРОВАТЬ ЗВУК?
Любые методы компрессии звука сосредоточены на одном: тихий звук сделать громче. И есть несколько шагов, которые помогают этого достичь.
I. Правильная запись:

Для пост-обработки звука я использую программу Adobe Audition CS6. Она предоставляет очень удобные инструменты для работы со звуком. Итак, что мы делаем:
- Импортируем наш аудиофайл.
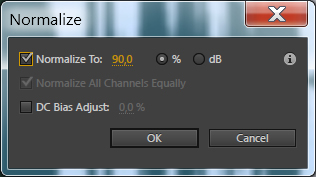
- Нормализуем его, чтобы звук не запирал: Effects/Amplitude and Compression/Normalize (process). Нормализуем звук до 95,8%.
- Чистим звук: вручную убираем все хлопки, клацанья и т. д.
- Поднимаем тихий звук: Effects/Amplitude and Compression/Dynamics Processing. Гризонтальная шкала показывает какой громкости звук мы собираемся поднимать. Вертикальная шкала показывает, на какой уровень мы хотим этот звук поднять. Я поднял звук, который находился на уровне -20dB до уровня -10dB.
- Снова нормализуем звук как в шаге №2.
- Поднимаем низкие и высокие частоты, они бывают на записи очень тихими: Effects/Filter and EQ/Parametric Equalizer. Здесь поднимаем на несколько dB низкие и высокие частоты.
- Последний раз нормализуем как в шаге №2.
Компрессия звука закончена! Теперь у вас плотный звук, который приятно слушать.
Также вы можете посмотреть видео, на котором я показываю как сделать компрессию звука в Adobe Audition CS6:
Поделитесь своим опытом. Случалось ли вам иметь дело с перепадами громкости звука и как вы с этим боролись?
2 комментария к “Компрессия звука (видео)”
Согласен по поводу хоррора. Там то и дело зрителя пугают громкими звуками. И такие скачки вполне оправданы. Думаю, в этом и состоит мастерство звукорежиссера, чтобы сознательно делать звук комфортным или не комфортным. У новичков такие перепады звука получаются случайно, и потом приходится долго думать, что же он хотел этим сказать. Неоправданные скачки звука говорят о плохом качестве работы.
Читайте также: