
Как посмотреть код сайта в браузере через пайтон
Доброго времени суток! Для начала у меня появился вот такой вопросик. Можно ли считать программную обработку содержимого html старничек веб-программированием? Вроде в вебе работаем, имеем дело с сетевыми протоколами и все такое. Кто точно знает ответ на этот вопрос, поделитесь в комментариях, я буду признателен.
Но перейдем к делу. Недавно в университете нам выдали интересное задание, связанное с чтением веб-страниц с помощью Python на. Научитесь, говорят, считывать страницы. Насколько я знаю, это весьма нетривиальная задача для решения на C/C++. Но чего только нет в стандартной библиотеке Python. Оказывается, существует специальный модуль urllib для работы с урлами. Замечательно! Даже искать не пришлось. Пара слов о том, какие функции мне понадобились из этого модуля.
Как прочитать веб-страницу с помощью Python
Будем пользоваться модулем под названием request , который входит в состав упомянутого выше urllib . И более того, используем всего лишь одну единственную и жутко простую функцию urlopen . Из названия нетрудно догадаться, чем она занимается.
В случае, когда схема ulr а имеет тип file(например урлы файлов в локальной сети), создастся идентификатор этого файла, как при обычном вызове open. Если же ссылка ведет в сеть, страничка будет загружена, считана и нам вернется файло-подобный индентификатор, для которого доступны все любимые нами методы. Такие, как read(), readlines(), close(), info() и некоторые другие.
Пример использования
Задача состоит в том, чтобы вытащить с сайта математического факультета список всех сотрудников и их контактные данные. Поиграем немного в шпионов? Шутка, данные ведь общедоступные. Да и реализация мягко говоря не тянет на секретный алгоритм слежки. Потому что я писал конкретно разбор этого сайта, учитывая структуру его html документов.
Исходный код решения
Заключение
Тут и добавить особо нечего, читать ссылки, как обычные файлы это очень круто. Можно научиться поднимать свой локальный сервер и делать из него агрегатор статей с новостных сайтов. А можно раскачаться окончательно и написать свой аналог google translate. Но это оставим на потом, спасибо за внимание!
Вы когда-нибудь задумывались, как получить исходный код страницы в Selenium WebDriver с помощью Python? В этом блоге мы рассмотрим, как сделать Selenium WebDriver getpagesource и продемонстрируем, как Selenium получает источник XML-страницы в виде…
Получение источника страницы исследуемого веб-сайта является повседневной задачей для большинства инженеров по автоматизации тестирования. Анализ источника страницы помогает устранить ошибки, выявленные в ходе регулярного тестирования пользовательского интерфейса веб-сайта, функционального тестирования или тестирования безопасности. В чрезвычайно сложном процессе тестирования приложений сценарии тестирования автоматизации могут быть написаны таким образом, что если в программе обнаруживаются ошибки, то это происходит автоматически.
- сохраняет исходный код этой конкретной страницы.
- уведомляет лицо, ответственное за URL-адрес страницы.
- извлекает HTML-источник определенного элемента или блока кода и делегирует его ответственным органам, если ошибка произошла в одном конкретном независимом HTML-веб-элементе или блоке кода.
Это простой способ отслеживать, исправлять логические и синтаксические ошибки в интерфейсном коде. В этой статье мы сначала разберемся в терминологии, а затем рассмотрим, как получить исходный код страницы в Selenium WebDriver с помощью Python.
В нетехнической терминологии это набор инструкций для браузеров по отображению информации на экране в эстетическом виде. Браузеры интерпретируют эти инструкции по-своему для создания экранов браузера на стороне клиента. Они обычно пишутся с использованием Языка разметки гипертекста (HTML), Каскадных таблиц стилей (CSS) и Javascript.
Весь этот набор HTML-инструкций, которые создают веб-страницу, называется источником страницы или источником HTML, или просто исходным кодом. Исходный код веб-сайта-это набор исходного кода с отдельных веб-страниц.
Вот пример исходного кода для базовой страницы с заголовком, формой, изображением и кнопкой отправки.
Что Такое Веб-Элемент HTML?
В приведенном выше примере – является веб-элементом HTML, поэтому
и дочерними элементами тегов body также являются веб-элементы HTML, т. Е. , и т. Д.
Selenium WebDriver является надежным инструментом тестирования автоматизации и предоставляет инженерам по тестированию автоматизации широкий набор готовых к использованию API. И чтобы сделать Selenium WebDriver getpagesource, привязки Selenium Python предоставляют нам функцию драйвера под названием page_source для получения HTML-источника текущего активного URL-адреса в браузере.
Мы будем использовать образец небольшой веб-страницы , размещенной на GitHub для всех четырех примеров. Эта страница была создана для демонстрации тестирования перетаскивания в Selenium Python с использованием лямбда-теста.
При успешном выполнении приведенного выше сценария на выходе вашего терминала появится следующий источник страницы.
Выходной код выглядит следующим образом-
Этот метод можно использовать для быстрого хранения исходного кода веб-страницы без загрузки страницы в браузере, управляемом Selenium. Аналогично, мы можем использовать библиотеку Python urllib для извлечения источника HTML-страницы.
Программно, чтобы взять исходный код скриншотов в Python Selenium (при необходимости), вы можете загрузить страницу с помощью –
Четвертый способ заставить Selenium WebDriver получить источник страницы-использовать XPath для его сохранения. Здесь вместо page_source или выполнения JavaScript мы идентифицируем исходный элемент, т. Е. , и извлекаем его. Закомментируйте логику извлечения источника предыдущей страницы и замените ее следующей-
Как Получить HTML-Источник WebElement В Selenium?
Чтобы получить HTML-источник веб-элемента в Selenium WebDriver, мы можем использовать метод get_attribute Selenium Python WebDriver . Во-первых, мы захватываем веб-элемент HTML, используя методы локатора элементов драйвера, такие как (find_element_by_xpath или find_element_by_css_selector). Затем мы применяем метод get_attribute() к этому захваченному элементу, чтобы получить его HTML-источник.
Аналогично, чтобы получить дочерние элементы или innerHTML веб-элемента –
Существует альтернативный способ сделать это и достичь того же результата –
Мы будем использовать Лямбда-тест для этой демонстрации-
Выходные данные содержат источник logoURL и WebElement –
Следующие три строки импортируют необходимые библиотеки: Selenium WebDriver, JSON Python и библиотеку re для обработки объектов JSON и использования регулярных выражений.
Затем мы настраиваем наш скрипт для его успешного запуска в облаке LambdaTest, что довольно быстро и плавно. Мне потребовалось менее 30 секунд, чтобы начать работу (возможно, потому, что у меня был предыдущий опыт работы с платформой). Но даже если вы новичок, это займет менее 1 минуты. Зарегистрируйтесь и войдите в систему с помощью Google и нажмите на Профиль , чтобы скопировать свое имя пользователя и токен доступа.
Мы запускаем драйвер в полноэкранном режиме и загружаем домашнюю страницу cntraveller со следующей строкой кода –
Теперь мы находим объекты JSON, содержащие скрипт, с помощью XPath locator и удаляем ненужные точки с запятой, чтобы правильно загрузить строку в формате JSON.
А затем мы проверяем, присутствует ли URL-адрес логотипа. Если он присутствует, мы его печатаем.
Кроме того, мы проверяем, присутствует ли телефонная информация. Если нет, мы печатаем исходный код веб-элемента.
Наконец, мы бросили водителя.
Если вы загружаете веб-сайт, отображаемый в формате XML, вам может потребоваться сохранить XML-ответ. Вот рабочее решение для создания источника XML-страницы Selenium get –
Вывод
Вы можете использовать любой из продемонстрированных выше методов и использовать гибкость и масштабируемость лямбда-теста Selenium Grid cloud для автоматизации процессов тестирования. Он позволяет выполнять тестовые случаи в более чем 2000 браузерах, операционных системах и их версиях. Кроме того, вы можете интегрировать поток автоматизированного тестирования с современными инструментами CI/CD и придерживаться лучших методов непрерывного тестирования.
Итак, начните автоматизировать свои повседневные задачи и сразу же облегчите свою жизнь с помощью лямбда-теста.
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков?
Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье.
В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.
Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Задача
- Этап 1: выгрузить и сохранить html-страницы
- Этап 2: распарсить html в удобный для дальнейшего анализа формат (csv, json, pandas dataframe etc.)
Инструменты
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого. Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. , lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении. Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html.
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, попробуем просто получить страницу по url и сохранить в локальный файл.

Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные.
Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью "Сеть" в "Инструментах разработчика" в браузере (я использую для этого Firebug), обычно нужный нам запрос — самый продолжительный.

Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.
Скачаем все оценки
Теперь мы умеем сохранять одну страницу с оценками. Но обычно у пользователя достаточно много оценок и нужно проитерироваться по всем страницам. Интересующий нас номер страницы легко передать непосредственно в url. Остается только вопрос: "Как понять сколько всего страниц с оценками?" Я решила эту проблему следующим образом: если указать слишком большой номер страницы, то нам вернется вот такая страница без таблицы с фильмами. Таким образом мы можем итерироваться по страницам до тех, пор пока находится блок с оценками фильмов ( <div > ).

Парсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация). Рассмотрим небольшой пример работы с XPath
Подробнее про синтаксис XPath также можно почитать на W3Schools.
Вернемся к нашей задаче
Теперь перейдем непосредственно к получению данных из html. Проще всего понять как устроена html-страница используя функцию "Инспектировать элемент" в браузере. В данном случае все довольно просто: вся таблица с оценками заключена в теге <div > . Выделим эту ноду:

Каждый фильм представлен как <div > или <div > . Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).
Еще небольшой хинт для debug'a: для того, чтобы посмотреть, что внутри выбранной ноды в BeautifulSoup можно просто распечатать ее, а в lxml воспользоваться функцией tostring() модуля etree.
Резюме

В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске.
Полный код проекта можно найти на github'e.
Если необходимые вам данные разбросаны по разным HTML-страницам для их извлечения применяется скрапинг. Вы создаете код для автоматического посещения определенного перечня страниц, получения конкретного контента с этих страниц и сохранения его в базе данных или в текстовом файле. [1]
Скажем, вы хотите скачать данные по температуре за прошедший год, но у вас не получается найти источник, который предоставил бы вам все сведения за нужный отрезок времени или по нужному городу. К счастью, сайт Weather Underground предоставляет исторические данные о погоде. И плохая новость: на одной странице сведения можно получить только за один день (рис. 1).

Рис. 1. Температура в Москве по данным Weather Underground; чтобы увеличить картинку, кликните на ней правой кнопкой мыши и выберите опцию Открыть картинку в новой вкладке
Проходим по меню More –> Historical Weather и выбираем определенную дату (рис. 2).

Рис. 2. Окно поиска архивных данных о погоде
Нажмите Submit, откроется другая страница, где вам будут представлены подробные данные о погоде в выбранный вами день (рис. 3).

Рис. 3. Подробные сведения о погоде в выбранный день
Допустим вас интересует максимальная температура. Вы могли бы посетить 365 страниц и собрать требуемые данные. Но процесс можно ускорить с помощью кода. Для этого обратитесь к языку программирования Python и к библиотеке под названием BeautifulSoup, созданной Леонардом Ричардсоном.
> python setup.py install
Создайте файл в текстовом редакторе (например, в блокноте) и сохраните его как get-weather-data.py. Теперь вы можете заняться написанием кода. Загрузите страницу, на которой представлены исторические сведения о погоде (как на рис. 3). URL страницы с информаций о погоде в Москве за 1 января 2015 выглядит так (чтобы разместить столь длинную строку мне пришлось разбить ее несколькими пробелами):
Если в этом адресе вы удалите все, что следует за .html, страница будет по-прежнему загружаться, так что избавьтесь от этих лишних символов:
В URL дата указана как /2015/1/1. Чтобы загрузить страницу со сведениями о 2 января 2015 г. без использования выпадающего меню, просто измените параметр даты так, чтобы URL выглядел следующим образом:
Теперь загрузите страницу с помощью Python, используя функцию urlopen, хранящуюся в модуле urllib.request библиотеки urllib. Для начала импортируйте эту функцию в программу:
from urllib.request import urlopen
Чтобы загрузить страницу с данными о погоде за 1 января, введите код:
page = urllib.urlopen( " www.wunderground.com/history/airport/UUEE/2015/1/2/DailyHistory.html " )
Таким образом вы загрузите весь HTML-файл, на который указывает URL в переменной страница. Следующим шагом будет извлечение интересующего вас значения максимальной температуры из этого HTML. Beautiful Soup сделает выполнение данной задачи намного проще. Вслед за urllib импортируйте Beautiful Soup:
from bs4 import BeautifulSoup
Используйте функцию BeautifuLSoup, чтобы прочитать страницу, и произвести ее анализ.
Эта строчка кода прочитывает HTML, который представляет по сути одну длинную строку, а затем сохраняет элементы страницы, такие как заголовок или изображения, в удобном для работы виде. Например, если вы хотите найти все изображения на странице, вы можете использовать код:
images = soup.findAll( ' img ' )
В результате вы получите перечень всех изображений на странице Weather Underground, отображаемых с помощью HTML-тега <img />. Вам нужно первое изображение на странице? Введите:
Хотите второе изображение? Измените ноль на единицу. Если вам нужно значение src в первом теге <img />, тогда используйте:
src = first_image[ ' src ' ]
Ладно, вас ведь не интересуют изображения. Вы просто хотите извлечь максимальную температуру в Москве 1 января 2015 года. Чтобы найти ее, нужно потрудиться чуть подольше, но метод применяется все тот же. Вам нужно выяснить, что вставить в findAll(), а потому просмотрите исходный HTML. Это легко сделать в веб-браузере. В Google Chrome, например, кликните на странице правой кнопкой мыши и выберите Просмотреть код. Появится окно с HTML-кодом (рис. 4).

Рис. 4. Исходный HTML-код страницы Weather Underground
Прокрутите вниз до того места, где показана максимальная температура, или воспользуйтесь функцией поиска в браузере. Строка замыкается тегом <span> с классом wx-value. Это и есть ваш ключ. Вы теперь можете найти все элементы на странице с классом wx-value.
Как и в предыдущем примере, это дает вам в руки перечень всех случаев употребления wx-value. Вас интересует второй из них, который вы найдете с помощью строчки:
Вуаля! Вы впервые в жизни извлекли нужное вам значение из HTML-кода веб-страницы. Следующий шаг — проанализировать все страницы за 2015 год и извлечь из них необходимые данные. Для этого вернитесь к первоначальному URL:
Помните, как вы вручную изменили адрес, чтобы получить сведения о той дате, которая вас интересовала? Приведенный выше код относится к 1 января 2015 года. Если вам нужна страница за 2 января 2015 года, просто измените ту часть URL, в которой указана дата, на соответствующую. Чтобы получить данные за все дни 2015 года, загрузите все месяцы (с 1-го по 12-й), а затем загрузите каждый день каждого месяца. Ниже представлен весь скрипт с комментариями. Сохраните его в вашем файле get-weather-data-full.py.
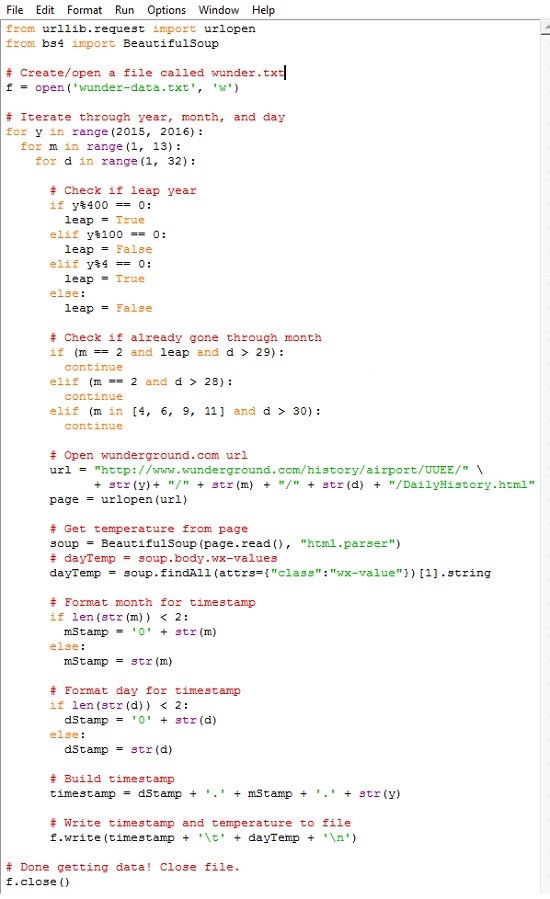
Вы наверняка узнали первые две строчки кода, с помощью которых вы импортировали необходимые библиотеки, — urllib и BeautifulSoup. Далее создается текстовый файл под названием wunder-data.txt с правами на запись, используя метод open(). Все данные, которые вы извлечете, будут сохраняться в этом текстовом файле, расположенном в той же папке, куда вы сохранили свой скрипт.
С помощью следующего блока, используя циклы for, компьютеру отдается команда просмотреть каждый год, месяц и день. Функция range() генерирует последовательность чисел, используемых для итераций цикла. Эта функция генерирует последовательность, начинающуюся с нуля и кончающуюся числом в скобках, не включая его. Поэтому, если вы укажите:
for y in range(2015):
Внешний цикл for проверяет, является ли год високосным. Число, обозначающее месяц, указывается в переменной m. Следующий цикл сообщает компьютеру, что надо посетить каждый день каждого месяца. Каждый отдельный день месяца указывается в переменной d.
Обратите внимание на то, что для повторения операции по дням используется range(1, 32). Это означает, что повтор будет производиться для каждого числа, начиная с 1 и по 31 (последнее значение не включается). Однако не в каждом месяце в году есть 31 день. В феврале их 28; в апреле, июне, сентябре и ноябре — по 30. Температурных показателей за 31 апреля нет, потому что такого дня не существует. Обратите внимание на то, о каком месяце идет речь, и действуйте сообразно этому. Если текущий месяц — февраль, и число больше 28, прервитесь и переходите к следующему месяцу.
Следующие строчки кода вы использовали для извлечения данных из одной конкретной страницы сайта Weather Underground. Отличие состоит в переменной месяца и дня в URL. Ее просто нужно менять для каждого дня, а не оставлять статичной — все прочее тут без изменений. Загрузите страницу, используя библиотеку urllib, произведите анализ контента с помощью Beautiful Soup, а затем извлеките максимальную температуру, с помощью второго появления класса wx-values.
Прогон займет некоторое время, так что наберитесь терпения. По сути, в процессе выполнения программы ваш компьютер загрузит по очереди 365 страниц – по одной на каждый день 2015 года. Когда выполнение скрипта завершится, у вас в рабочем каталоге появится файл под названием wunder-data.txt (рис. 5). Откройте его, и там вы найдете нужные вам данные в формате с разделителями табуляцией. В первой колонке вы увидите дату, во второй – температуру.

Рис. 5. Извлеченные данные в файле с разделителем табуляцией
Обратите также внимание, что, если вы будете запрашивать данные по будущему периоду (дата еще не наступила), то получите некорректный ответ. Запрос найдет второе вхождение тега с классом wx-value, но оно не будет соответствовать максимальной температуре выбранного дня (рис. 6).

Рис. 6. Для будущего периода второй тег класса wx-value не соответствует максимальной температуре выбранного дня
Любопытна история написания этой заметки. Мой друг несколько лет назад подарил мне книгу Нейтана Яу Искусство визуализации в бизнесе. Поскольку меня интересует обработка и представление информации, книга мне показалась любопытной, и я начал ее читать. Но… буквально с первых страниц автор уводит с проторенных дорожек. Критикуя Excel за его недостаточную мощь и гибкость, автор предлагает использовать программную обработку на основе языка Python. Тогда мне это показалось слишком сложным.
Но около месяца назад я вновь вернулся к книге Нейтана Яу. И теперь использование Python меня не отпугнуло. Я решил написать конспект книги, а, чтобы не перегружать его, специфические темы опубликовать отдельно. Первая из таких заметок перед вами. Надо сказать, что далась она непросто.
Для начала, код Нейтана Яу не запустился. Проблемы подстерегали практически на каждом шагу. Выяснилось, что код написан для Python 2, а последняя версия – это Python 3.5. Изучение Интернета подсказало, что язык был существенно переработан при переходе с версии 2 на 3. Мне показалось странным, потчевать читателей устаревшим кодом. Поэтому я установил последнюю из доступных на данный момент версий Python 3.5.1.
Чтобы попытаться самому переписать код, или хотя бы более грамотно задавать вопросы на форумах, я прочитал книгу Майк МакГрат. Программирование на Python для начинающих. Книга мне понравилась. Очень хорошо структурирована, сопровождается файлами с примерами. То, что надо! Она мне здорово помогла.
Следующая проблема была с запуском модуля BeautifulSoup. После импорта внутрь кода Python модуль не был виден. Я менял папки, запускал скрипт setup.py, ничего не помогало. Интенсивный поиск в Интернете натолкнул меня на только что вышедшую в издательстве ДМК Пресс книгу Райана Митчелла Скрапинг вебсайтов с помощью Python. Оцените, книга вышла 30 апреля 2016 г.! Здесь я почерпнул знания о библиотеке urllib, и о том, как установить модуль BeautifulSoup под Python 3. Критически важным было выполнить в командной строке
> python setup.py install
Эта команда конвертирует код модуля BeautifulSoup, адаптируя его к версии Python 3.
Далее оказалось, что с момента написания Нейтаном Яу своей книги на сайте Weather Underground произошли изменения в стилевом оформлении CSS. Поменялось имя тега, используемого для представления значения температуры: с nobr на wx-value.
И наконец, с переходом на версию Python 3, наверное, поменялся синтаксис извлечения значения из тега. У Нейтана Яу было:
Т.е., [ ].span.string следовало заменить на [ ].string. Я нигде не мог найти подсказки, что же следует изменить в первоначальном коде, чтобы извлечь не весь тег
а только его значение
Обращение на форум python.su не помогло. Я применил метод научного тыка, и после нескольких попыток получил то, что нужно.
Успехов вам в освоении языка Python!
[1] Заметка написана на основе материалов книги Нейтан Яу. Искусство визуализации в бизнесе. – М.: Манн, Иванов и Фербер, 2013. – С. 44–53.
Рассказываем о том, как можно сэкономить время и нервы при автоматизации процесса получения данных с веб-сайтов без соответствующего API-интерфейса.

Предположим, что в поисках данных, необходимых для вашего проекта, вы натыкаетесь на такую веб-страницу:
Вот они — все необходимые данные для вашего проекта.
Но что же делать, если нужные вам данные находятся на сайте, который не предоставляет API для их получения? Конечно же, можно потратить несколько часов и написать обработчик, который получит эти данные и преобразует их в нужный для вашего приложения формат.
Но есть и более простое решение — это библиотека Pandas и ее встроенная функция read_html() , которая предназначена для получения данных с html-страниц.
Прим. перев. В данной статье используется версия Pandas 0.20.3
ABBYY , Москва, можно удалённо , До 230 000 ₽
Да, все настолько просто. Pandas находит html-таблицы на странице и возвращает их как новый объект DataFrame .
Теперь попробуем указать Pandas, что первая (а точнее нулевая) строка таблицы содержит заголовки столбцов, а также попросим ее сформировать datetime -объект из строки, находящейся в столбце с датой и временем.
На выходе мы получим следующий результат:
Теперь все эти данные находятся в DataFrame -объекте. Если же нам нужны данные в формате json, добавим еще одну строчку кода:
В результате вы получите данные в формате json с правильным форматированием даты по стандарту ISO 8601:
При желании данные можно сохранить в CSV или XLS:
Выполните код и откройте файл calls.csv . Он откроется в приложении для работы с таблицами:

И, конечно же, Pandas упрощает анализ:
И обработку данных:
Результат метода unique :
Теперь вы знаете, как с помощью Python и Pandas можно быстро получить данные с практически любого сайта, не прилагая особых усилий. Освободившееся время предлагаем посвятить чтению других интересных материалов по Python на нашем сайте.
Читайте также: