
Как посчитать коэффициент корреляции в excel
Excel – это эффективный инструмент для статистической обработки данных. И определение корреляций является очень важной составляющей этого процесса. Программа имеет весь необходимый инструментарий для осуществления расчетов такого плана. Сегодня мы более детально разберемся, что нам нужно для осуществления анализа этого типа.
Что представляет собой корреляционный анализ
Простыми словами, корреляция – это связь между двумя явлениями. В свою очередь, под корреляционным анализом подразумевают выявление этой связи. Очень частое утверждение гласит, что корреляция – это зависимость между разными объектами, но на деле это неточное определение. Ведь существует множество изображений, которые показывают связь между явлениями, которые никак не могут быть зависимы друг от друга или одного третьего фактора, который влияет на них.
Для определения зависимости используется другой тип анализа, который называется регрессионным.
Величина, определяющая степень выраженности взаимосвязи, называется коэффициентом корреляции. Это единственная величина, которая рассчитывается корреляционным анализом по сравнению с регрессионным. Возможные вариации коэффициента корреляции могут быть в пределах от -1 до 1. Если это число положительное, взаимосвязь между динамикой изменения значений прямая. Если же отрицательное, то увеличение числа 1 приводит к аналогичному уменьшению числа 2. Если число меньше единицы по модулю, то корреляция неполная. Например, увеличение числа 1 на единицу приводит к увеличению числа 2 на 0,5. В таком случае коэффициент корреляции составляет 0,5. Если же коэффициент корреляции составляет 0, то взаимосвязи между двумя переменными нет.
Интересный факт: корреляции делятся на истинные и ложные. То есть, иногда то, что графики идут в одинаковом направлении, может быть чистой случайностью, а не закономерным следствием воздействия одной переменной на другую или влияния общего фактора на обе переменные. В узких кругах довольно популярны картинки, где коррелируют между собой абсолютно не связанные явления. Вот некоторые примеры:
- Количество человек, которые стали утопленниками в бассейнах, четко коррелирует с количеством фильмов, в которых Николас Кейдж был актером.
- Количество съеденной моцареллы и количество человек, которые получили докторскую степень, также коррелирует на протяжении 2000-2009 годов. Наверно, действительно, моцарелла как-то влияет на мозг и стимулирует желание совершать научные открытия.
- Почти во всех случаях средний возраст женщин, которые получили статус «Мисс Америка» коррелирует с количеством людей, которые погибли от нахождения в горячем паре.
- Число людей, которое погибло в результате дорожно-транспортного происшествия, четко коррелирует с количеством сметаны, которое съедают люди.
- Мало кто знает, что чем больше курятины человек ест, тем больше сырой нефти импортируется в мире. Правда, это тоже пример ложной корреляции. Кстати, импорт сырой нефти родом из Норвегии тесно связано с количеством людей, которые погибли в результате столкновения автомобиля с поездом. Причем в этом случае корреляция почти 100 процентов.
- А еще маргарин негативно влияет на статистику разводов. Чем больше людей, которые проживали в штате Мэн, потребляли маргарина, тем выше была частота разводов. Правда, здесь еще может быть рациональное зерно. Ведь частота потребления маргарина имеет обратную корреляцию с экономическим положением в семье. В свою очередь, плохое экономическое положение в семье имеет непосредственную связь с количеством разводов. И это уже доказано научно. Так что кто знает, может, эта корреляция и не является такой ложной. Правда, никто этого не перепроверял.
- Количество денег, которое правительство США тратит на развитие науки, космоса и технологий, имеет тесную связь с количеством самоубийств, проведенных в форме повешения или удушения.
Ну и наконец, еще один пример ложной корреляции – чем больше сыра люди едят, тем больше людей умирает из-за того, что они запутываются в своих простынях.
Поэтому несмотря на то, что корреляция является эффективным статистическим инструментом, нужно учиться отфильтровывать истинные взаимосвязи между явлениями и ложные. Иначе исследование может получить такие интересные результаты. А теперь переходим непосредственно к тому, как проводить корреляционный анализ в Excel.
Вычисление коэффициента корреляции осуществляется двумя способами. Первый – это использование Мастера функций, который позволяет ввести формулу КОРРЕЛ. Второй инструмент – это пакет анализа, требующий отдельной активации.
Как рассчитать коэффициент корреляции
Давайте продемонстрируем механизм получения коэффициента корреляции на реальном кейсе. Допустим, у нас есть таблица с информацией о суммах продаж и рекламу. Нам нужно понять, в какой степени количество продаж и количество денег, которые были использованы на продвижение, взаимосвязаны.
Способ 1. Определение корреляции с помощью Мастера Функций
Функция КОРРЕЛ – один из самых простых методов, как можно реализовать поставленную задачу. В своем общем виде этот оператор имеет следующий вид: КОРРЕЛ(массив1;массив2). Как же ее ввести? Для этого нужно осуществлять следующие действия:
- С помощью левой кнопки мыши выделяем ту ячейку, в которой будет находиться получившийся коэффициент корреляции. После этого находим слева от строки формул кнопку fx, которая откроет инструмент ввода функций.
- Далее выбираем категорию «Полный алфавитный перечень», в котором ищем функцию КОРРЕЛ. Как видно из названия категории, все названия функций располагаются в алфавитном порядке.
- Далее открывается окно ввода параметров функции. У нас два основных аргумента, каждый из которых являет собой массив данных, которые сравниваются между собой. В поле «Массив 1» указываем координаты первого диапазона, а в поле «Массив 2» – адрес второго диапазона. Для ввода данных массива, используемого для расчета, достаточно выделить нажать левой кнопкой мыши по соответствующему полю и выделить правильный диапазон.
- После того, как мы введем данные в аргументы, нажимаем кнопку «ОК», чем подтверждаем совершенные действия.

После выполнения описанных выше шагов мы видим в ячейке, выбранной нами на первом этапе, коэффициент корреляции. В нашем примере он составляет 0,97, что указывает на очень сильно выраженную взаимосвязь между данными двух диапазонов.
Способ 2. Вычисление корреляции с помощью пакета анализа
Также довольно неплохой инструмент для определения корреляции между двумя диапазонами – пакет анализа. Но перед тем, как его использовать, нам надо его включить. Для этого выполняем следующие действия:

Все, теперь наша надстройка включена. Теперь мы во вкладке «Данные» можем увидеть кнопку «Анализ данных». Если она появилась, то мы все сделали правильно. Нажимаем на нее.

Появляется перечень с выбором разных способов анализа информации. Нам следует выбрать пункт «Корреляция» и нажать на «ОК».
Затем нам нужно ввести настройки. Основное отличие этого метода от предыдущего заключается в том, что нам нужно вводить полностью диапазон, а не разрывать его на две части. В нашем случае, это информация, указанная в двух столбцах «Затраты на рекламу» и «Величина продаж».
Не вносим никаких изменений в параметр «Группирование». По умолчанию выставлен пункт «По столбцам», и он правильный. Эта настройка определяет, каким образом программа будет разбивать данные. Если же наши данные были бы представлены в двух рядах, то надо было бы изменить этот пункт на «По строкам».
В настройках вывода уже стоит пункт «Новый рабочий лист». То есть, информация о корреляции будет располагаться на отдельном листе. Пользователь может настроить место самостоятельно с помощью соответствующего переключателя – на текущий лист или в отдельный файл. Проверяем, все ли настройки были введены правильно. Если да, подтверждаем свои действия нажатием на клавишу «ОК».


Поскольку мы оставили поле с данными о том, куда будут выводиться результаты, таким, каким оно было, мы переходим на новый лист. На нем можно найти коэффициент корреляции. Конечно, он такой же самый, как был в предыдущем методе – 0,97. Причина этого в том, что вычисления производятся одинаковые, исходные данные мы также не меняли. Просто разными методами, но не более.
Таким образом, Эксель дает сразу два метода осуществления корреляционного анализа. Как вы уже понимаете, в результате вычислений итог получится таким же. Но каждый пользователь может выбрать тот метод расчета, который ему больше всего подходит.
Как построить поле корреляции в Excel

Итак, давайте теперь разберемся, как построить поле корреляции. Для начала нужно разобраться, что это вообще такое. Под корреляционным полем подразумевается фактически график корреляции. Главное требование к такой диаграмме – каждая точка должна соответствовать единице совокупности. Поле корреляции поможет установить более глубокие связи и проанализировать данные более качественно. Для начала нам нужно найти коэффициент корреляции между двумя диапазонами, используя функцию КОРРЕЛ.
После того, как мы это сделали, мы теперь можем сделать поле корреляции. Для этого выполняем следующие действия:
Этот график можно построить не только на основе корреляции, определенной через функцию КОРРЕЛ.
Диаграмма рассеивания. Поле корреляции
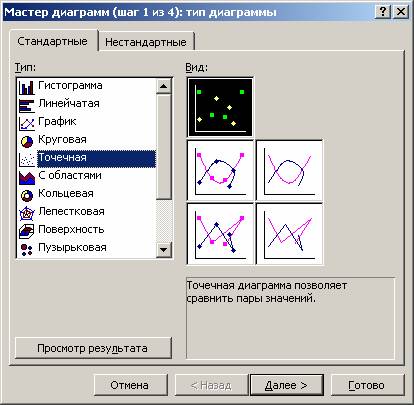
До сих пор часть пользователей сидит на старой версии Word. Как построить корреляционное поле в этом случае? Для этого существует специальный инструмент, который называется мастером диаграмм. Найти его можно на панели инструментов по специфическому изображению диаграммы. Если навести на эту иконку мышкой, то появится всплывающая подсказка, которая поможет нам убедиться в том, что это действительно мастер диаграмм.
После этого появится диалоговое окно, в котором нам надо выбрать точечный тип диаграммы. Видим, что логика действий в старых версиях офисного пакета в целом остается той же самой, просто немного другой интерфейс. Немного правее мы можем увидеть, как будет выглядеть точечная диаграмма и выбрать подходящий вид, а также прочитать описание этого типа диаграммы. После этого нажимаем на кнопку «Далее».
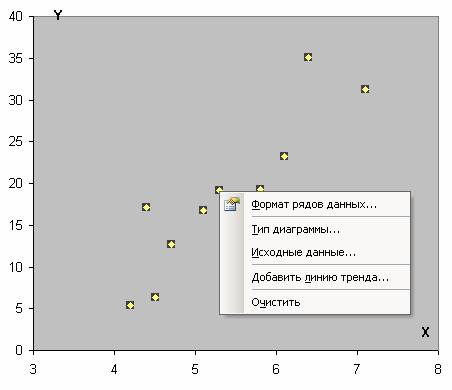
Затем выбираем диапазон данных, и наша линия появляется. После этого можно добавить линию регрессии к графику. Для этого необходимо сделать клик правой кнопкой мыши по одной из точек и в появившемся перечне найти «Добавить линию тренда» и сделать клик по этому пункту.
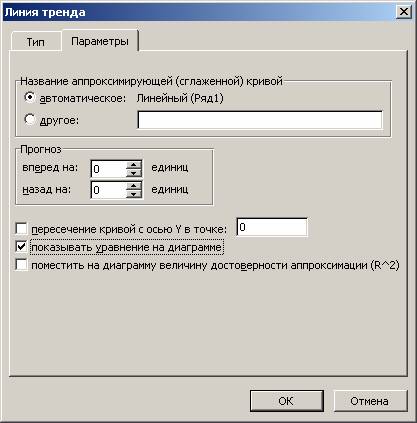
Далее выставляем настройки. Нас интересует тип «Линейная», а в окне параметров нужно поставить флажок «Показывать уравнение на диаграмме».
После подтверждения действий у нас появится что-то типа такого графика.
Как видим, возможных вариантов построения может быть огромное количество.

Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
Вычисление коэффициента детерминации
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
В последнем случае качество модели говорит о невозможности её использования для прогноза.
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН, а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.

- Выделяем ячейку, где будет произведен вывод коэффициента детерминации после его расчета, и щелкаем по пиктограмме «Вставить функцию».


Синтаксис этого оператора такой:
Таким образом, функция имеет два оператора, один из которых представляет собой перечень значений функции, а второй – аргументов. Операторы могут быть представлены, как непосредственно в виде значений, перечисленных через точку с запятой (;), так и в виде ссылок на диапазоны, где они расположены. Именно последний вариант и будет использован нами в данном примере.
Устанавливаем курсор в поле «Известные значения y». Выполняем зажим левой кнопки мышки и производим выделение содержимого столбца «Y» таблицы. Как видим, адрес указанного массива данных тут же отображается в окне.
Аналогичным образом заполняем поле «Известные значения x». Ставим курсор в данное поле, но на этот раз выделяем значения столбца «X».


Способ 2: вычисление коэффициента детерминации в нелинейных функциях
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия», который является составной частью пакета «Анализ данных».
-
Но прежде, чем воспользоваться указанным инструментом, следует активировать сам «Пакет анализа», который по умолчанию в Экселе отключен. Перемещаемся во вкладку «Файл», а затем переходим по пункту «Параметры».





Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
- Область на текущем листе;
- Другой лист;
- Другая книга (новый файл).
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал». В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия».


Способ 3: коэффициент детерминации для линии тренда
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
-
Мы имеем график, построенный на основе таблицы аргументов и значений функции, которая была использована для предыдущего примера. Произведем построение к нему линии тренда. Кликаем по любому месту области построения, на которой размещен график, левой кнопкой мыши. При этом на ленте появляется дополнительный набор вкладок – «Работа с диаграммами». Переходим во вкладку «Макет». Клацаем по кнопке «Линия тренда», которая размещена в блоке инструментов «Анализ». Появляется меню с выбором типа линии тренда. Останавливаем выбор на том типе, который соответствует конкретной задаче. Давайте для нашего примера выберем вариант «Экспоненциальное приближение».








Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.

В Экселе существуют два основных варианта вычисления коэффициента детерминации: использование оператора КВПИРСОН и применение инструмента «Регрессия» из пакета инструментов «Анализ данных». При этом первый из этих вариантов предназначен для использования только в процессе обработки линейной функции, а другой вариант можно использовать практически во всех ситуациях. Кроме того, существует возможность отображения коэффициента детерминации для линии трендов графиков в качестве величины достоверности аппроксимации. С помощью данного показателя имеется возможность определить тип линии тренда, который располагает самым высоким уровнем достоверности для конкретной функции.

Отблагодарите автора, поделитесь статьей в социальных сетях.
Помогла ли вам эта статья?
Еще статьи по данной теме:
получены по формуле .y=x+sinx
Берем модель y=a+bx и находим
ВЫВОД ИТОГОВ
Регрессионная статистика
Множественный R 0,986714919
R-квадрат 0,973606331
Нормированный R-квадрат 0,971576049
Стандартная ошибка 0,765569136
Наблюдения 1 5
Дисперсионный анализ
df SS MS F Значимость F
Регрессия 1 281,0579051 281,0579051 479,5423556 1,20615E-11
Остаток 13 7,619249319 0,586096101
Итого 14 288,6771544
Коэффициенты Стандартная ошибка t-статистика P-Значение
Y-пересечение 0,113947 0,415978241 0,273925746 0,788445813
Переменная X 1,001887 0,045751507 21,89845555 1,20615E-11
P-Значение показывает, что константу надо обнулить a=0 . Снова обращаемся к Регрессии
ВЫВОД ИТОГОВ
Регрессионная статистика
Множественный R 0,997002
R-квадрат 0,994013
Нормированный R-квадрат 0,922584
Стандартная ошибка 0,739847
Наблюдения 15
Дисперсионный анализ
df SS MS F Значимость F
Регрессия 1 1272,235 1272,235 2324,254 4,8053E-16
Остаток 14 7,663227 0,547373
Итого 15 1279,898 ? и здесь напахали TSS=288,6771544 и не должно меняться от вида модели.
То, что называется «приплыли»:
R*-квадрат 0,994013 > 0,9736; F*=2324,254 > 479,542.
Однако, основной показатель RSS=7,619 < SSR*=7,663 говорит, что первоначальная модель, все-таки точнее (в смысле МНК).
Могу предположить, что разработчики Регрессии не учли, что при насильственном изменении модели, Теорема о 3-х дисперсиях не выполняется: TSS 288,6771544 > )
У меня не вопрос. А благодарность разработчикам сайта. Спасибо за понятные и доступные разъяснения при построении требуемых данных.
Задайте вопрос или оставьте свое мнение Отменить комментарий

Для определения степени зависимости между несколькими показателями применяется множественные коэффициенты корреляции. Их затем сводят в отдельную таблицу, которая имеет название корреляционной матрицы. Наименованиями строк и столбцов такой матрицы являются названия параметров, зависимость которых друг от друга устанавливается. На пересечении строк и столбцов располагаются соответствующие коэффициенты корреляции. Давайте выясним, как можно провести подобный расчет с помощью инструментов Excel.
Вычисление множественного коэффициента корреляции
Принято следующим образом определять уровень взаимосвязи между различными показателями, в зависимости от коэффициента корреляции:
- 0 – 0,3 – связь отсутствует;
- 0,3 – 0,5 – связь слабая;
- 0,5 – 0,7 – средняя связь;
- 0,7 – 0,9 – высокая;
- 0,9 – 1 – очень сильная.
Если корреляционный коэффициент отрицательный, то это значит, что связь параметров обратная.
Для того, чтобы составить корреляционную матрицу в Экселе, используется один инструмент, входящий в пакет «Анализ данных». Он так и называется – «Корреляция». Давайте узнаем, как с помощью него можно вычислить показатели множественной корреляции.
Этап 1: активация пакета анализа
Сразу нужно сказать, что по умолчанию пакет «Анализ данных» отключен. Поэтому, прежде чем приступить к процедуре непосредственного вычисления коэффициентов корреляции, нужно его активировать. К сожалению, далеко не каждый пользователь знает, как это делать. Поэтому мы остановимся на данном вопросе.
- Переходим во вкладку «Файл». В левом вертикальном меню окна, которое откроется после этого, щелкаем по пункту «Параметры».



После указанного действия пакет инструментов «Анализ данных» будет активирован.
Этап 2: расчет коэффициента
Теперь можно переходить непосредственно к расчету множественного коэффициента корреляции. Давайте на примере представленной ниже таблицы показателей производительности труда, фондовооруженности и энерговооруженности на различных предприятиях рассчитаем множественный коэффициент корреляции указанных факторов.
-
Перемещаемся во вкладку «Данные». Как видим, на ленте появился новый блок инструментов «Анализ». Клацаем по кнопке «Анализ данных», которая располагается в нём.


Так как у нас факторы разбиты по столбцам, а не по строкам, то в параметре «Группирование» выставляем переключатель в позицию «По столбцам». Впрочем, он там уже и так установлен по умолчанию. Поэтому остается только проверить правильность его расположения.
Около пункта «Метки в первой строке» галочку ставить не обязательно. Поэтому мы пропустим данный параметр, так как он не повлияет на общий характер расчета.
В блоке настроек «Параметр вывода» следует указать, где именно будет располагаться наша корреляционная матрица, в которую выводится результат расчета. Доступны три варианта:
- Новая книга (другой файл);
- Новый лист (при желании в специальном поле можно дать ему наименование);
- Диапазон на текущем листе.
Давайте выберем последний вариант. Переставляем переключатель в положение «Выходной интервал». В этом случае в соответствующем поле нужно указать адрес диапазона матрицы или хотя бы её верхнюю левую ячейку. Устанавливаем курсор в поле и клацаем по ячейке на листе, которую планируем сделать верхним левым элементом диапазона вывода данных.


Этап 3: анализ полученного результата
Теперь давайте разберемся, как понимать тот результат, который мы получили в процессе обработки данных инструментом «Корреляция» в программе Excel.
Как видим из таблицы, коэффициент корреляции фондовооруженности (Столбец 2) и энерговооруженности (Столбец 1) составляет 0,92, что соответствует очень сильной взаимосвязи. Между производительностью труда (Столбец 3) и энерговооруженностью (Столбец 1) данный показатель равен 0,72, что является высокой степенью зависимости. Коэффициент корреляции между производительностью труда (Столбец 3) и фондовооруженностью (Столбец 2) равен 0,88, что тоже соответствует высокой степени зависимости. Таким образом, можно сказать, что зависимость между всеми изучаемыми факторами прослеживается довольно сильная.
Как видим, пакет «Анализ данных» в Экселе представляет собой очень удобный и довольно легкий в обращении инструмент для определения множественного коэффициента корреляции. С его же помощью можно производить расчет и обычной корреляции между двумя факторами.
Отблагодарите автора, поделитесь статьей в социальных сетях.

Приветствую всех читателей моего блога! Думаю вы наверняка замечали, что некоторые явления связаны между собой. Например, температура воздуха на улице и количество прогуливающихся людей, время суток и количество друзей онлайн в соцсети, благосостояние страны и количество нобелевских лауреатов (хотя тут все же спорно). Одни явления связаны сильнее, другие слабее и сила этой связи называется корреляцией. Ее измерение имеет непосредственное отношение к портфельному инвестированию и диверсификации инвестиционных активов.
Например, проанализировав данные по ВВП на душу населения и продолжительности жизни в странах мира, мы невооруженным глазом заметим тенденцию:
А благодаря расчёту коэффициента корреляции мы можем узнать силу взаимосвязи в конкретном числовом выражении. Это очень удобно и полезно при анализе данных в самых разных областях науки, в том числе в экономике и инвестировании.
Сегодня я расскажу вам подробнее о том, что такое корреляция простыми словами, без сложных формул и терминов. Также я покажу вам, как правильно и легко рассчитать коэффициент корреляции в Excel и как правильно интерпретировать результаты, чтобы использовать их для составления инвестиционного портфеля.
Спасибо за внимание, продолжаем!
Что такое корреляция простыми словами
Не хочу вас сразу грузить формулами и расчётами, об этом поговорим ближе к концу. Давайте сначала разберемся, что по своей сути означает цифра коэффициента корреляции, которую вы можете встретить в какой-нибудь книге или статье.
Значение коэффициента может меняться от -1 до +1:

Околонулевые значения, в свою очередь, говорят об отсутствии какой-либо зависимости между явлениями. Нет конкретного предела, где заканчивается случайность и начинается взаимосвязь, все зависит от предмета исследования и количества данных. Навскидку, обычно при значениях от -0.3 до 0.3 можно говорить о том, что зависимость отсутствует.
При высокой положительной корреляции вслед за графиком А растёт и график B, и чем выше значение, тем слаженнее оба движутся. Для наглядности, вот как выглядит корреляция +1:

Движения графиков полностью повторяют друг друга, причем это как в случае простого добавления, так и с множителем.
При сильной отрицательной корреляции рост графика А приводит к падению графика B и наоборот. Вот так выглядит корреляция -1:

Движения графиков похожи на зеркальные отражения.
Также нужно следить за тем, чтобы найденные корреляции не были ложными.
Ложные корреляции
В общем, на результаты корреляционного анализа есть смысл обращать внимание, когда связь между явлениями уже известна или подозревается. В противном случае это может быть всего лишь число, которое ничего не значит.
Корреляция и диверсификация


А вот пример портфеля двух активов с корреляцией близкой к 0:

Где-то графики следуют друг за другом, где-то в противоположных направлениях, какой-либо однозначной связи не наблюдается. И вот здесь диверсификация уже работает:

Мы видим заметное снижение СКО, а значит портфель будет менее волатильным и более стабильно расти. Также видим небольшое снижение максимальной просадки, особенно если сравнивать с Активом 1. Инвестиционные инструменты без корреляции достаточно часто встречаются и из них имеет смысл составлять портфель.
Впрочем, это не предел. Наиболее эффективный инвестиционный портфель можно получить, используя активы с корреляцией -1:


Несмотря на то, что каждый из активов обладает определенным риском, портфель получился фактически безрисковым. Какая-то магия, не правда ли? Очень жаль, но на практике такого не бывает, иначе инвестирование было бы слишком лёгким занятием.
Коэффициент корреляции и ПАММ-счета
С расчётом корреляции я как студент экономического ВУЗа познакомился еще на втором курсе. Тем не менее, долгое время недооценивал важность расчёта корреляции именно для подбора ПАММ-портфеля. 2018 год очень четко показал, что ПАММ-счета с похожими стратегиями в случае кризиса могут вести себя очень похоже.
Случилось так, что с середины года отказала не просто одна стратегия управляющего, а большинство торговых систем, завязанных на активные движения валютной пары EUR/USD:

Рынок был для каждого управляющего по-своему неблагоприятным, но присутствие их всех в портфеле привело к большой просадке. Совпадение? Не совсем, ведь это были ПАММ-счета с похожими элементами в торговых стратегиях. Без опыта торговли на рынке Форекс может быть сложно понять, как это работает, но по корреляционной таблице степень взаимосвязи видна и так:

Мы ранее рассматривали корреляцию вплоть до +1, но как видите на практике даже совпадение в районе 20-30% уже говорит о некоторой схожести ПАММ-счетов и, как следствие, результатов торговли.
Чтобы снизить шансы на повторение ситуации, как в 2018 году, я считаю в портфель стоит подбирать ПАММ-счета с низкой взаимной корреляцией. По сути, нам нужны уникальные стратегии с разными подходами и разными валютными парами для торговли. На практике, конечно, сложнее подобрать прибыльные счета с уникальными стратегиями, но если хорошо покопаться в рейтинге ПАММ-счетов, то все возможно. К тому же, низкая взаимная корреляция снижает требования для диверсификации, 5-6 счетов вполне хватит.
Данные о прибыльности ПАММов изначально хранятся в формате накопленной доходности, нам это не подходит. Корреляция стандартных графиков доходности двух прибыльных ПАММ-счетов всегда будет очень высокой, просто потому что они все движутся в правый верхний угол:


Как видите, некоторые корреляции стали нулевыми, а некоторые остались на высоком уровне. Мы теперь видим, какие ПАММ-счета действительно похожи между собой, а какие не имеют ничего общего.
Напоследок давайте разберёмся, что делать и как посчитать корреляцию, если у вас появилась в этом необходимость.
Коэффициент корреляции в Excel и формула расчёта
Вероятно, вас интересует, как самостоятельно рассчитать корреляцию двух инвестиционных активов. До изобретения компьютеров приходилось делать это вручную, для чего использовалась вот такая формула коэффициента корреляции:

Кстати, студентам на экзамене до сих пор компьютеров не выдают, хоть калькулятор можно и на том спасибо. Как вы понимаете, занятие все равно трудоёмкое :)
Профессиональному инвестору может понадобиться рассчитать сотни корреляций, так что вариант по формуле не подходит. Естественно, эта задача уже давно автоматизирована, и, как по мне, проще всего рассчитать коэффициент корреляции в Excel.
Чтобы далеко за примером не ходить, давайте рассчитаем корреляцию двух популярных ПАММ-счетов Lucky Pound и Hohla EUR. Они находятся на площадке компании Alpari, а значит мы можем скачать историю доходности прямо с сайта:

Далее нам надо скопировать историю доходности в один файл, для удобства. Для точного расчета корреляции в Excel нам в принципе хватит и двух лет истории, располагаем данные так:

Теперь, как я уже писал выше, для ПАММ-счетов (и для многих других инвестиционных инструментов) надо рассчитать дневные доходности:


Получили значение 0.12, а значит стратегии ПАММ-счетов практически не имеют ничего общего. Это хорошо для диверсификации, так что можно добавлять обоих в инвестиционный портфель.
При желании, можно сделать табличку на весь ваш портфель. Тогда если у вас появится новый вариант для инвестирования, вы сможете сразу сравнить его с каждым активом и увидеть, есть ли нежелательные корреляции.
Читайте также: