
Как написать бота для браузера на python
В этой статье, я объясню общий принцип создания ботов на Python, применив полученные знания, вы сможете создать бота который:
Создаем первого бота на Selenium.
Данный способ подойдет для любого сайта, однако, за все нужно платить. Selenium запускает браузер, отъедая огромный запас оперативной памяти. Используйте его только тогда, когда нужно выполнить JS код на странице.
Первым делом нужно установить библиотеку, для этого введите в консоли:
Далее, установите веб-драйвер под браузер Firefox отсюда. Также, необходимо установить браузер Mozilla Firefox, если еще не установлен.
Теперь напишем простейшего бота. Для этого, напишите следующий python скрипт.
Код скрипта описан в комментариях.
Далее, переместите файл скрипта, в одну папку с веб-драйвером geckodriver.exe

И запустите python скрипт. У вас должен открыться браузер.
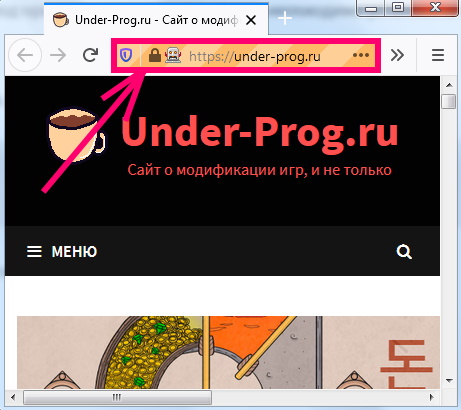
В адресной строке видна иконка робота, это значит, что браузером управляет программа.
Хорошо, бот создан, но он бесполезен. Единственное на что он способен, это заходить на сайт. Давайте добавим ему новых функций. Например, сделаем так, чтобы бот лайкал посты на сайте.
Бот лайкающий посты на сайте.
Последовательность действий у нас следующая.
Первый пункт мы уже сделали, перейдем ко второму.
Пройтись по каждому из постов.
На этом этапе, нужно понимать разметку HTML.
Зайдите на сайт, и нажмите кнопку F12.
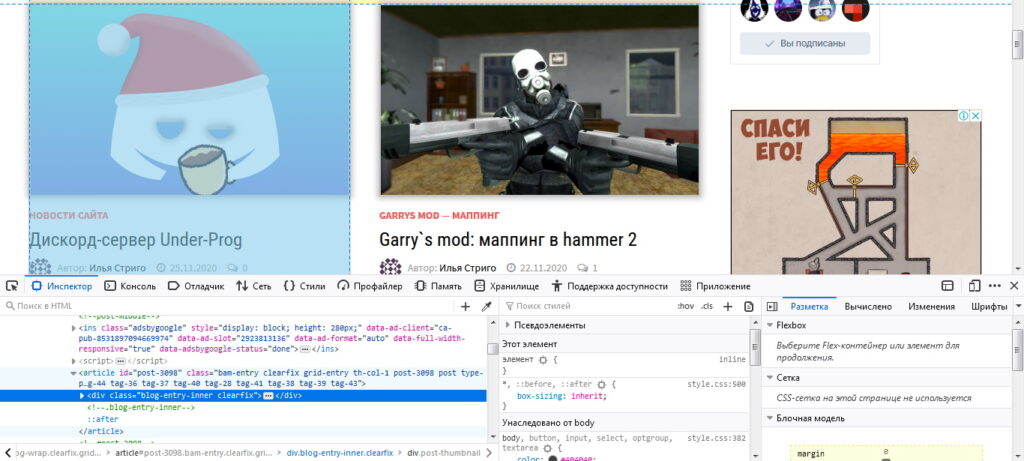
У вас откроются инструменты разработчика. Изучив разметку, мы понимаем, что все посты находятся в теге article.
Сейчас нам нужно получить ссылку, на каждый пост. Для этого будем использовать этот css селектор.
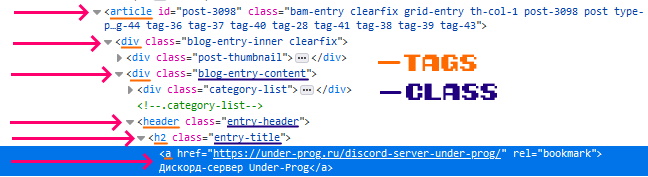
Данный селектор указывает:
- На элемент с тегом a
- который находится находится внутри тега h2 с классом entry-title
- тот, в свою очередь, находится внутри тега header с классом entry-header
- тег header находится внутри тега div с классом blog-entry-content
- тот, находится в теге div
- тег div находится внутри тега article
Теперь, дополним бота.
Разберем новую функцию.
Данная функция ищет элементы по css селектору. В результате своей работы, она возвращает массив элементов.
В-общем, мы из этого массива, достали первый элемент, и при помощи функции get_attribute(), получили значение атрибута href (ссылка на пост).
И вывели его на экран.
Запустите скрипт, в консоли должна появится ссылка на первый пост.
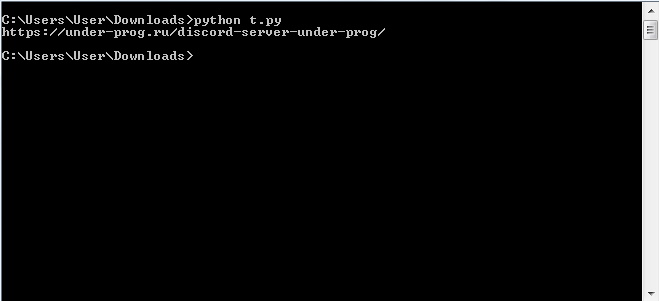
Если закинуть массив элементов в цикл, то получится извлечь ссылки на все посты.
Отлично, ссылки на все посты получены, осталось всем этим постам, поставить лайк.
Нажать кнопку лайк, если она не нажата
Сначала перекопируем наши ссылки в отдельный массив. Замените это:
Далее напишем код, отвечающий за нажатие кнопки лайк.
Разберем данные строки.
Данная строка ищет кнопку с помощью css_селектора, и получает строку с названиями классов нашей кнопки.

Кликаем по кнопке лайк.
Осталось закрыть браузер, делается это с помощью функции quit().
Бот завершен, запустите скрипт, и наслаждайтесь автоматизацией.
Делаем браузер невидимым
Бот работает и все-бы ничего, но своим окном бразуера, он перекрывает все остальные окна. К счастью, у Firefox есть headless режим, позволяющий пользоваться функциями бразура, не открывая окно браузера.
Добавьте следующий код перед инициализацией браузера:
Здесь, мы переопредили настройки браузера, осталось передать их, нашему браузеру.

Чтобы охватить большую аудиторию в Instagram, получить больше лайков и новых подписчиков, мы обращаемся за помощью к специалистам: SocialCaptain, Kicksta, Instavast и другим компаниям. У них есть автоматизированные инструменты, которые делают за вас всю работу. За это мы платим большие деньги – но то же самое можно получить бесплатно, используя InstaPy.
Мы напишем бота на Python, который автоматизирует ваши действия в Instagram. В результате вы получите больше лайков и подписчиков с минимальными усилиями. Параллельно разберемся в автоматизации браузера, работе Selenium и шаблона Page Object , лежащих в основе InstaPy.
Убедитесь, что вы ознакомились с Политикой предоставления услуг Instagram, прежде чем начинать работу.Прежде чем начинать автоматизировать что-либо, давайте подумаем, как получает лайки и подписки в Instagram реальный пользователь?
За счет активности. Человек размещает посты, просматривает ленту, лайкает и комментирует посты других людей. Боты делают то же самое, но не тратя ваше время. Вы лишь устанавливаете критерии выбора.
Но как реализовать это технически? Instagram Developer API ограничен и не подойдет для наших целей. Следует обратиться к браузерной автоматизации.
Это работает очень просто:
- Вы указываете свои учетные данные.
- Устанавливаете критерии для отбора профилей и постов, а также настройки для комментариев.
- Бот открывает браузер, переходит на сайт, авторизуется с вашими данными и начинает выполнять полученные инструкции.
Давайте перейдем к практике. Для начала напишем бота, который сможет самостоятельно зайти в ваш Instagram-профиль.
Для первой версии бота будем использовать Selenium – инструмент, работающий под капотом InstaPy, к которому мы перейдем чуть позже.
Для начала установите сам Selenium. Убедитесь, что на вашем компьютере установлен браузер Firefox и Firefox WebDriver. Мы будем работать с этим браузером, так как в последней версии InstaPy нет поддержки Chrome.
Для работы Selenium вам также может понадобиться установить geckodriver.
1. Открываем браузер
Создайте файл с расширением .py и вставьте туда следующий код:
Сначала мы импортируем нужные пакеты. Затем инициализируется драйвер Firefox и запускается браузер. Бот набирает в адресной строке адрес https://www.instagram.com/ – открывается страница авторизации Instagram. Через 5 секунд ожидания браузер закрывается. Запустите код и проверьте, как он работает. Только что мы написали в своем роде "Hello world" на Selenium.
2. Открываем страницу авторизации
Добавим авторизацию. Для начала составим пошаговый алгоритм действий:
Первый пункт мы уже выполнили. Давайте теперь найдем на странице ссылку для авторизации и кликнем по ней:
Мы используем для поиска нужной ссылки XPath, но есть и другие методы.
Запустите скрипт и убедитесь, что он работает. В браузере должна открыться страница авторизации.
3. Заполнение формы
В форме авторизации – три важных элемента:
- Поле для введения логина;
- Поле для пароля;
- Кнопка Войти .
Давайте найдем их, введем учетные данные и залогинимся:
Устанавливаем двухсекундную задержку для загрузки страницы. Находим и заполняем нужные поля. В конце ищем и нажимаем кнопку для входа.
Если вы укажете правильные данные и запустите этот скрипт, он самостоятельно авторизуется в вашем Instagram аккаунте.
Мы отлично начали, и при желании легко можем продолжить создавать бота. Дальнейшие действия очень похожи на уже сделанные: прокручиваем ленту вниз, ищем интересные посты по определенным критериями, ищем кнопку для лайка и нажимаем на нее, ищем раздел с комментариями и т. д.
Хорошая новость – все эти шаги за вас может сделать InstaPy. Но прежде чем мы начнем с ним работать, давайте разберемся в основах – паттерне Page Object.
Мы написали код для авторизации – но как теперь его тестировать ? Это могло бы выглядеть как-то так:
Что не так с этим кодом? Он не соответствует принципу DRY и идеям чистого кода: одни и те же фрагменты дублируются и в приложении, и в тесте.
В этом контексте дублирование кода особенно плохо, так как Selenium зависит от элементов пользовательского интерфейса, а они имеют тенденцию меняться. Если это происходит, хотелось бы вносить изменения только в одном месте, а не в десятке. Здесь и приходит на помощь шаблон Page Object.
С помощью этого шаблона вы создаете классы page objects для наиболее важных страниц или фрагментов страницы, которые предоставляют удобные интерфейсы для взаимодействия.
Мы можем отрефакторить наш код и создать класс HomePage и класс LoginPage :
Логика осталась без изменений, только теперь домашняя страница и страница входа представлены в виде классов. Они инкапсулируют все действия, необходимые для поиска и обработки данных в пользовательском интерфейсе.
Обратите внимание, при переходе на другую страницу с помощью метода объекта страницы, возвращается новый объект страницы. Взгляните на возвращаемое значение функции go_to_log_in_page() .
Если бы у нас уже был класс FeedPage , то метод login() класса LoginPage вернул бы экземпляр страницы фида ( return FeedPage() ).
Изменим основной код:
Теперь программа выглядит намного проще и понятнее. Тесты тоже можно переписать:
Если в интерфейсе что-то изменится, не придется менять тесты – и это правильно.
Чтобы узнать больше о шаблоне Page Object, обратитесь к официальной документации и статье Мартина Фаулера.
А мы переходим к созданию бота версии 2.0 – с помощью InstaPy.
Для начала установим InstaPy:
Хорошей практикой является использование для каждого проекта отдельных виртуальных сред. Это позволяет изолировать зависимости.Авторизация в Instagram
Перепишем код с использованием InstaPy:
Подставьте правильный логин и пароль и запустите скрипт. Вуаля! Одна строчка кода – а результат тот же самый!
На самом деле, не тот же самый. Instapy выполняет множество других действий: проверяет интернет-соединение, состояние серверов Instagram и пр. Все это вы можете наблюдать напрямую в браузере, а также в логах.
Неплохо для одной строки кода, правда? Переходим к решительным действиям!
Основные настройки бота
Предположим, что ваш профиль посвящен автомобилям. Вы хотите, чтобы бот взаимодействовал с профилями людей, интересующихся автомобилями.
Лайки
Мы передаем методу массив тегов, которые нужно лайкнуть, и количество постов для каждого тега. Другими словами, бот должен поставить 10 лайков – по пять для каждого из двух тегов.
Но взгляните, что происходит в логах после запуска скрипта:
По умолчанию InstaPy будет лайкать первые девять постов в ленте к дополнению к параметру amount . В этом случае общее количество лайков – 14 на один тег (9 + 5).
InstaPy регистрирует каждое действие: упоминает, какой пост ему понравился, ссылку на него, описание, местоположение, указывает, комментировал ли и подписался ли на аккаунт.
Возможно, вы заметили, что почти после каждого действия возникают задержки. Это сделано специально, чтобы Instagram не забанил ваш профиль.
Вы также можете указать параметры постов, которые бот НЕ должен лайкать, с помощью метода set_dont_like() :
Теперь бот будет игнорировать посты, в описании которых есть слова "naked" или "nsfw" (not safe/suitable for work).
Подписки
Кроме лайков бот умеет подписываться на аккаунты. Для этого предназначена функция set_do_follow() :
Если вы запустите этот скрипт, то бот подпишется на 50% от тех юзеров, чьи посты он лайкнул. Опять же каждое действие будет залогировано.
Комментарии
Еще одна опция InstaPy – возможность оставлять комментарии. Для этого нужно сделать две вещи. Сначала разрешите комментирование вызовом метода set_do_comment() :
Затем укажите, что именно писать с помощью set_comments() :
Запустите скрипт, и бот оставит один из трех указанных комментариев под половиной постов, с которыми он взаимодействовал.
Закрытие сессии
После того, как вы сделали все, что хотели, нужно закрыть сессию, вызвав метод end() :
Эта команда закроет браузер, сохранит логи и подготовит отчет, который вы можете увидеть в консоли.
Дополнительные возможности InstaPy
InstaPy – это большой проект, который имеет множество тщательно документированных функций. Рассмотрим несколько наиболее полезных из них.
Квоты
Нельзя скрейпить Instagram целыми днями, сервис быстро это заметит. Поэтому полезно установить квоты на действия бота.
Этот код ограничивает пределы комментирования за час и за целый день. Когда бот достигнет их, он перестанет комментировать и будет ждать истечения периода квоты.
Аргумент headless_browser
Указанный в названии аргумент позволяет запускать бота без графического интерфейса браузера. Она полезна, если вы хотите развернуть бота на сервере, где нет или не нужен интерфейс. Производительность в таком режиме выше, так как меньше нагрузка на процессор.
Обратите внимание, соответствующий флаг устанавливается при инициализации объекта InstaPy.
InstaPy-бот можно интегрировать с ClarifApi – инструментом для распознавания изображений и видео:
Теперь бот будет игнорировать любое изображение, которое ClarifApi посчитает NSFW. 5000 обращений в месяц – бесплатно.
Количество подписчиков
Зачастую не имеет смысла взаимодействовать с аккаунтами с большим количеством подписчиков. InstaPy дает возможность установить границы для этого количества, чтобы бот не тратил впустую вычислительные ресурсы вашей машины:
Теперь бот не будет взаимодействовать с постами пользователей, у которых больше 8,5 тысяч подписчиков.
Множество других опций и конфигураций вы можете найти в документации InstaPy.
InstaPy – гибкий инструмент, который позволяет легко и быстро автоматизировать действия пользователя в Instagram. Его работа основана на браузерной автоматизации (Selenium) и использовании шаблона Page Object для облегчения работы с веб-страницами.
Если вы еще не начали писать код, прочитайте нашу публикацию о том, как создать виртуальное окружение в Python. Это позволит избежать проблем с зависимостями пакетом. Мы также писали о том, как работает распознавание объектов в реальном времен – впоследствии бота можно улучшить, если привлечь собственную модель для анализа фотографий пользователей.

Без бота это выглядело бы так:
- Вы открываете в веб-браузере YouTube.
- Ищете видео, которым хотите поделиться.
- Выбираете общий доступ.
- Возвращаетесь в мессенджер и, наконец, делитесь ссылкой.
Конечно, большинство из нас привыкло к вышеуказанному алгоритму, и это неплохо работает. Однако.
- Вы находитесь в мессенджере.
- Вводите @vid, а затем видео, которым хотите поделиться.
И это всего лишь одна из возможностей ботов. Разработчики Telegram проделали отличную работу и позволили пользователям создавать своих собственных ботов. Отвечая на вопрос, почему это может быть интересно, я могу сказать, что это самый простой способ получить представление об API.
Если это первый опыт, откройте новую вкладку в своем браузере и используйте URL-адрес: так вы отправите запрос на сервер Telegram. Пришедший ответ будет в формате JSON и чем-то напоминающим словарь Python. Вы должны увидеть что-то вроде этого:
Для ответа от бота замените chat_id на значение, которое получите с вызовом /getUpdates. У нас это 303262877. Текстовый параметр зависит от вас. Запрос должен выглядеть так:
Если ваша операционная система – Windows, но еще не установлен Python, скачайте его здесь. Без разницы, будет это версия 2.x или 3.x. Для примера мы будем использовать Python 3.x. На macOS и Linux обе версии уже установлены (либо минимум Python 2.x), поэтому нет необходимости дополнительно скачивать что-либо.
Следующий шаг – установка системы управления пакетами pip. Для Python 2.7.9 и выше, а также Python 3.4 и выше они уже предустановленны (равно как и для операционных систем macOS/Linux). Если нужно, вы всегда можете проверить это, используя в терминале команду pip –version. При отсутствии данной системы установите ее с помощью команды:
Интересная штука: разные версии Python работают с разными pip. Для обладателей macOS подойдет эта инструкция. Если же у вас ОС Windows, загрузите get-pip.py, откройте cmd, перейдите к скачанным файлам (директория) и выполните следующее:
Это было самое сложное. Осталось воспользоваться pip и установить пакет requests:
Дополнительно можно скачать PyCharm, хотя этот шаг и не относится к обязательным.
Если принцип API понятен, и у вас есть все необходимые инструменты, давайте создадим скрипт Python, который будет проверять наличие обновлений и отвечать на них желаемым текстом.
Словарь обновлений состоит из двух элементов - «ok» и «results». Нам нужен второй, который представляет собой список всех обновлений за последние 24 часа. Здесь вы можете посмотреть дополнительную информацию о библиотеке запросов. Основная идея заключается в том, что всякий раз, когда вам нужно получать, обновлять или удалять информацию на сервере, вы отправляете запрос и принимаете ответ.
Помните, как мы привязывали параметры с помощью ? и &? Вы можете сделать то же самое, добавив dict в качестве второго необязательного параметра для запросов get/post.
Telegram скрипт готов
Хотя мы добавили «тайм-аут» в 1 секунду, приведенный выше пример должен использоваться только в целях тестирования, поскольку он использует частые опросы. Это не очень хорошо для серверов Telegram. Есть еще два способа получить обновления через API – вебхуки и длинные опросы. Но так как мы проверяем обновления с использованием метода getUpdates, запросы будут частыми.
Поскольку мы использовали основной цикл, следует переключиться на длинные опросы. Изменим первую функцию, добавив параметр timeout. Тайм-аут сам по себе не сделает проверку скрипта для обновления реже. Кроме того, тайм-аут будет работать только в том случае, если последние обновления отсутствуют. Для отметки просмотренных обновлений нужно добавить параметр offset:
Теперь бот должен работать нормально, но немного изменим код
Неплохо было бы инкапсулировать использованные функции в класс. Модифицированная версия скрипта будет выглядеть таким образом:
Теперь у вас есть тысячи различных способов улучшать своего бота! Можно добавить дополнительные кнопки или даже настроить отправку медиафайлов.
Последний шаг – это как вишенка на торте, которая позволит сделать из вашего Telegram бота настоящего помощника: его необходимо развернуть на сервере. Скорее всего, у вас нет собственного сервера, и уж вряд ли вы захотите покупать для этого дорогостоящую аппаратуру. К счастью, существует множество облачных сервисов, на которых можно бесплатно разместить приложение. Давайте развернем небольшой скрипт на Heroku.
Прежде всего, вам нужна учетная запись на GitHub. Переходите на главную страницу и регистрируйтесь: это обязательный шаг для любого, кто действительно заинтересован в программировании. Помимо учетной записи GitHub, вам также необходимо установить Git.
Если у вас Linux, выполните следующую команду:
Для macOS и Windows можно произвести ручную установку программы. И, конечно же, не забудьте завести аккаунт на Heroku.
Устанавливаем virtualenv, используя команду:
Теперь вам нужно немного упорядочить свои файлы. Создайте новую папку, откройте терминал/cmd и перейдите в нее. Для инициализации в созданной папке virtualenv введите:
Название не имеет особого значения, однако лучше делать его максимально понятным. Перейдите в папку my_env. Следующий шаг – клонировать ваш репозиторий Git. Введите следующую команду:
Поместите свой скрипт в папку и вернитесь в my_env, чтобы запустить virtualenv.
Windows:
Linux/macOS:
При успешном запуске virtualenv командная строка должна начинаться с (my_env). Установите модуль requests, перейдя в папку репозитория:
Для создания зависимостей Heroku введите:
Создайте файл Procfile. В нем вы найдете инструкции для работы со своим скриптом. Имя должно быть Procfile или Procfile.windows, если это Windows. Не стоит включать в название .txt, .py или любые другие расширения. Содержимое файла должно быть следующим (измените my_bot на название вашего скрипта):
Добавьте файл __init__.py в свою папку. Файл может быть пустым, но он должен находиться там. Введите такую команду:
А теперь развернем нашего Telegram бота на Heroku. Потренируемся делать это через консоль. При возникновении проблем, обратитесь к руководству. Для Windows и macOS нужно установить интерфейс командной строки, используя этот гайд. Для Ubuntu используем команды:
Интересный факт: на моем домашнем компьютере все прошло без сучка и задоринки, а вот на ноутбуке последний шаг выполнить не удалось. Если вы столкнулись с такой же проблемой, проверьте терминал на наличие всех зависимостей. После выполните команды:
С этого момента ваше приложение должно работать на сервере Heroku. Если по какой-либо причине оно не работает, проверьте журналы, используя следующую команду:
Коды ошибок можно посмотреть здесь.
Да, используя бесплатный аккаунт, вы столкнетесь с определенными ограничениями. Но даже так после проделанных действий у вас будет полностью функциональный бот.
Как вы думаете, сложно ли написать на Python собственного чатбота, способного поддержать беседу? Оказалось, очень легко, если найти хороший набор данных. Причём это можно сделать даже без нейросетей, хотя немного математической магии всё-таки понадобится.
Идти будем маленькими шагами: сначала вспомним, как загружать данные в Python, затем научимся считать слова, постепенно подключим линейную алгебру и теорвер, и под конец сделаем из получившегося болтательного алгоритма бота для Телеграм.
Этот туториал подойдёт тем, кто уже немножко трогал пальцем Python, но не особо знаком с машинным обучением. Я намеренно не пользовался никакими nlp-шными библиотеками, чтобы показать, что нечто работающее можно собрать и на голом sklearn.

Поиск ответа в диалоговом датасете
Год назад меня попросили показать ребятам, которые прежде не занимались анализом данных, какое-нибудь вдохновляющее приложение машинного обучения, которое можно собрать самостоятельно. Я попробовал собрать вместе с ними бота-болталку, и у нас это действительно получилось за один вечер. Процесс и результат нам понравились, и написал об этом в своем блоге. А теперь подумал, что и Хабру будет интересно.
Я, впрочем, поступлю ещё более по-читерски, и возьму данные из соревнования Яндекс.Алгоритм 2018 — это те же диалоги из фильмов, для которых работники Толоки разметили хорошие и неплохие продолжения. Яндекс собирал эти данные, чтобы обучать Алису (статьи о её кишках 1, 2, 3). Собственно, Алисой я и был вдохновлен, когда придумывал этого бота. В таблице от Яндекса даны три последних фразы и ответ на них (reply), но мы будем пользоваться только самой последней из них (context_0).
Имея такую базу диалогов, можно просто искать в ней каждую реплику пользователя, и выдавать готовый ответ на ней (если таких реплик много, выбирать случайно). С «как дела ?» такое отлично получилось, о чём свидетельствует приложенный скриншот. Это, если что, jupyter notebook на Python 3. Если вы хотите повторить такое сами, проще всего установить Анаконду — она включает Python и кучу полезных пакетов для него. Или можно ничего не устанавливать, а запустить блокнот в гугловском облаке.

Векторизация текстов
Теперь говорим о том, как превратить тексты в числовые векторы, чтобы осуществлять по ним приближённый поиск.
Мы уже познакомились с библиотекой pandas в Python — она позволяет загружать таблицы, осуществлять поиск в них, и т.п. Теперь затронем библиотеку scikit-learn (sklearn), которая позволяет более хитрые манипуляции с данными — то, что называется машинным обучением. Это значит, что любому алгоритму сперва нужно показать данные (fit), чтобы он узнал о них что-то важное. В результате алгоритм «научится» делать с этими данными что-то полезное — преобразовывать их (transform), или даже предсказывать неизвестные величины (predict).
В данном случае мы хотим преобразовать тексты («вопросы») в числовые векторы. Это нужно, чтобы можно было находить «близкие» друг к другу тексты, пользуясь математическим понятием расстояние. Расстояние между двумя точками можно рассчитать по теореме Пифагора — как корень из суммы квадратов разностей их координат. В математике это называется Евклидовой метрикой. Если мы сможем превращать тексты в объекты, у которых есть координаты, то мы сможем вычислять Евклидову метрику и, например, находить в базе вопрос, наиболее всего похожий на «о чём ты думаешь?».
Самый простой способ задать координаты текста — это пронумеровать все слова в языке, и сказать, что i-тая координата текста равна числу вхождений в него i-того слова. Например, для текста «я не могу не плакать» координата слова «не» равна 2, координаты слов «я», «могу» и «плакать» равны 1, а координаты всех остальных слов (коих десятки тысяч) равны 0. Такое представление теряет информацию о порядке слов, но всё равно работает неплохо.
Проблема в том, что у слов, которые встречаются часто (например, частиц «и» и «а») координаты будут несоразмерно большие, хотя информации они несут мало. Чтобы смягчить эту проблему, координату каждого слова можно поделить на логарифм числа текстов, где такое слово встречается — это называется tf-idf и тоже работает неплохо.

Проблема только одна: в нашей базе 60 тысяч текстовых «вопросов», в которых содержится 14 тысяч различных слов. Если превратить все вопросы в векторы, получится матрица 60к*14к. Работать с такой не очень классно, поэтому дальше мы поговорим о сокращении размерности.
Сокращение размерности
Мы уже поставили задачу создания болталочного чатбота, скачали и векторизовали данные для его обучения. Теперь у нас есть числовая матрица, представляющая реплики пользователей. Она состоит из 60 тысяч строк (столько было реплик в базе диалогов) и 14 тысяч столбцов (столько в них было различных слов). Сейчас наша задача — сделать её поменьше. Например, представить каждый текст не 14123-мерным, а всего лишь 300-мерным вектором.
Достичь этого можно, умножив нашу матрицу размера 60049х14123 на специально подобранную матрицу проекции размера 14123х300, в итоге получим результат 60049х300. Алгоритм PCA (метод главных компонент) подбирает матрицу проекции так, чтобы исходную матрицу можно было потом восстановить с наименьшей среднеквадратической ошибкой. В нашем случае получилось сохранить около 44% об исходной матрице, хотя размерность сократилась почти в 50 раз.

Так вот, получается, что метод главных компонент запоминает не все 14 тысяч слов, а 300 типовых контекстов, по которым эти слова потом можно пытаться восстановить. Столбцы матрицы проекции, соответствующие синонимичным словам, обычно похожи друг на друга, потому что эти слова часто встречаются в одном контексте. А значит, можно сократить избыточные измерения, не потеряв при этом в информативности.
Во многих современных приложениях матрицу проекции слов вычисляют нейросети (например, word2vec). Но на самом деле простой линейной алгебры для практически полезного результата уже достаточно. Метод главных компонент вычислительно сводится к SVD, а оно — к расчёту собственных векторов и собственных чисел матрицы. Впрочем, программировать это можно, даже не зная деталей.
Поиск ближайших соседей
В предыдущих разделах мы закачали в python корпус диалогов, векторизовали его, и сократили размерность, а теперь хотим наконец научиться искать в нашем 300-мерном пространстве ближайших соседей и наконец-то осмысленно отвечать на вопросы.
Поскольку научились отображать вопросы в Евклидово пространство не очень высокой размерности, поиск соседей в нём можно осуществлять довольно быстро. Мы воспользуемся уже готовым алгоритмом поиска соседей BallTree. Но мы напишем свою модель-обёртку, которая выбирала бы одного из k ближайших соседей, причём чем ближе сосед, тем выше вероятность его выбора. Ибо брать всегда одного самого близкого соседа — скучно, но не завязываться на сходство совсем — опасно.
Поэтому мы хотим превратить найденные расстояния от запроса до текстов-эталонов в вероятности выбора этих текстов. Для этого можно использовать функцию softmax, которая ещё часто стоит на выходе из нейросетей. Она превращает свои аргументы в набор неотрицательных чисел, сумма которых равна 1 — как раз то, что нам нужно. Дальше полученные «вероятности» мы можем использовать для случайного выбора ответа.

Фразы, которые будет вводить пользователь, надо пропускать через все три алгоритма — векторизатор, метод главных компонент, и алгоритм выбора ответа. Чтобы писать меньше кода, можно связать их в единую цепочку (pipeline), применяющую алгоритмы последовательно.
В результате мы получили алгоритм, который по вопросу пользователя способен найти похожий на него вопрос и выдать ответ на него. И иногда это ответы даже звучат почти осмысленно.

Публикация бота в Telegram
Мы уже разобрались, как сделать чатбота-болталку, который бы выдавал примерно уместные ответы на запросы пользователя. Теперь показываю, как выпустить такого чатбота в Телеграм.
Проще всего использовать для этого готовую обёртку Telegram API для питона — например, pytelegrambotapi. Итак, пошаговая инструкция:
- Регистрируете своего будущего бота в @botfather и получаете токен доступа, который вам надо будет вставить в свой код.
- Разово запускаете команду установки — pip install pytelegrambotapi в командной строке (или через! прям в блокноте).
- Запускаете код примерно как в скриншоте. Ячейка перейдёт в режим исполнения (*), и пока она будет в этом режиме, вы сможете общаться со своим ботом сколько захотите. Чтобы остановить бота, жмите Ctrl+C. Грустная, но важная правда: если вы в России, то, скорее всего, перед запуском этой ячейки вам нужно будет включить VPN, чтобы не получить ошибку при подключении к телеграм. Более простая альтернатива VPNу — писать весь код не на вашем локальном компьютере, а в google colab (примерно так).
- Если вы хотите, чтобы бот работал перманентно, вам надо выложить его код на какой-нибудь облачный сервис — например, AWS, Heroku, now.sh или Яндекс.Облако. О том, как запустить их, вы можете узнать в мельчайших подробностях на сайтах этих сервисов или в статьях тут же на Хабре. Вот, например, репа с небольшим примером бота, запускаемого на heroku и кладущего логи в mongodb.
Полный код к статье я намеренно не выкладываю — вы получите гораздо больше удовольствия и полезного опыта, когда напечатаете его сами, и получите работающего бота в результате собственных усилий. Ну или если вам очень лень это делать, можете поболтать с моей версией ботика.
Давно хотел попробовать свои силы в компьютерном зрении и вот этот момент настал. Интереснее обучаться на играх, поэтому тренироваться будем на боте. В статье я попытаюсь подробно расписать процесс автоматизации игры при помощи связки Python + OpenCV.

Ищем цель
Выбранным внизу экрана цветом заливается произвольная область, при этом соседние области одного цвета сливаются в единую.

Подготовка
Использовать будем Python. Бот создан исключительно в образовательных целях. Статья рассчитана на новичков в компьютером зрении, каким я сам и являюсь.
Для работы бота нам понадобятся следующие модули:
- opencv-python
- Pillow
- selenium
Управление браузером
Мы имеем дело с онлайн-игрой, поэтому для начала организуем взаимодействие с браузером. Для этой цели будем использовать Selenium, который предоставит нам API для управления FireFox. Изучаем код страницы игры. Пазл представляет из себя canvas, которая в свою очередь располагается в iframe.
Ожидаем загрузки фрейма с и переключаем контекст драйвера на него. Затем ждем canvas. Она единственная во фрейме и доступна по XPath /html/body/canvas.
Далее наша канва будет доступна через свойство self.__canvas. Вся логика работы с браузером сводится к получению скриншота canvas и клику по ней в заданной координате.
Полный код Browser.py:
Состояния игры
Приступим к самой игре. Вся логика бота будет реализована в классе Robot. Разделим игровой процесс на 7 состояний и назначим им методы для их обработки. Выделим отдельно обучающий уровень. Он содержит большой белый курсор, указывающий куда нажимать, который не позволит корректно распознавать элементы игры.
- Приветственный экран
- Экран выбора уровня
- Выбор цвета на обучающем уровне
- Выбор области на обучающем уровне
- Выбор цвета
- Выбор области
- Результат хода
Для большей стабильности бота будем проверять, успешно ли произошла смена игрового состояния. Если self.state_next_success_condition не вернет True за время self.state_timeout — продолжаем обрабатывать текущее состояние, иначе переключаемся на self.state_next. Также переведем скриншот, полученный от Selenium, в понятный для OpenCV формат.
Реализуем проверку в методах обработки состояний. Ждем кнопку Play на стартовом экране и кликаем по ней. Если в течении 10 секунд мы не получили экран выбора уровней, возвращаемся к предыдущему этапу self.STATE_START, иначе переходим к обработке self.STATE_SELECT_LEVEL.
Зрение бота
Пороговая обработка изображения
Определим цвета, которые используются в игре. Это 5 игровых цветов и цвет курсора на учебном уровне. COLOR_ALL будем использовать, если нужно найти все объекты, независимо от цвета. Для начала этот случай мы и рассмотрим.
Для поиска объекта в первую очередь необходимо упростить изображение. Для примера возьмем символ «0» и применим к нему пороговую обработку, то есть отделим объект от фона. На этом этапе нам не важно, какого цвета символ. Для начала переведем изображение в черно-белое, сделав его 1-канальным. В этом нам поможет функция cv2.cvtColor со вторым аргументом cv2.COLOR_BGR2GRAY, который отвечает за перевод в градации серого. Далее производим пороговую обработку при помощи cv2.threshold. Все пиксели изображения ниже определенного порога устанавливаются в 0, все, что выше, в 255. За значение порога отвечает второй аргумент функции cv2.threshold. В нашем случае там может стоят любое число, так как мы используем cv2.THRESH_OTSU и функция сама определит оптимальный порог по методу Оцу на основе гистограммы изображения.
Цветовая сегментация
Дальше интереснее. Усложним задачу и найдем все символы красного цвета на экране выбора уровней.

По умолчанию, все изображения OpenCV хранит в формате BGR. Для цветовой сегментации больше подходит HSV (Hue, Saturation, Value — тон, насыщенность, значение). Ее преимущество перед RGB заключается в том, что HSV отделяет цвет от его насыщенности и яркости. Цветовой тон кодируется одним каналом Hue. Возьмем для примера салатовый прямоугольник и будем постепенно уменьшать его яркость.
В отличии от RGB, в HSV данное преобразование выглядит интуитивно — мы просто уменьшаем значение канала Value или Brightness. Тут стоит обратить внимание на то, что в эталонной модели шкала оттенков Hue варьируется в диапазоне 0-360°. Наш салатовый цвет соответствует 90°. Для того, чтобы уместить это значение в 8 битный канал, его следует разделить на 2.
Сегментация цветов работает с диапазонами, а не с одним цветом. Определить диапазон можно опытным путем, но проще написать небольшой скрипт.
Запустим его с нашим скриншотом.

Кликаем по красному цвету и смотрим на полученную маску. Если вывод нас не устраивает — выбираем оттенкам красного, увеличивая диапазон и площадь маски. Работа скрипта основана на функции cv2.inRange, которая работает как цветовой фильтр и возвращает пороговое изображение для заданного цветового диапазона.
Остановимся на следующих диапазонах:
Поиск контуров
Удаление шума
Полученные контуры содержат много шума от фона. Чтобы убрать его воспользуемся свойством наших цифр. Они состоят из прямоугольников, которые параллельны осям координат. Перебираем все контуры и вписываем каждый в минимальный прямоугольник при помощи cv2.minAreaRect. Прямоугольник определяется 4 точками. Если наш прямоугольник параллелен осям, то одна из координат для каждой пары точек должны совпадать. Значит у нас будет максимум 4 уникальных значения, если представить координаты прямоугольника как одномерный массив. Дополнительно отфильтруем слишком длинные прямоугольники, где соотношение сторон больше, чем 3 к 1. Для этого найдем их ширину и длину при помощи cv2.boundingRect.
Объединение контуров
Уже лучше. Теперь нам нужно объединить найденные прямоугольники в общий контур символов. Нам понадобится промежуточное изображение. Создадим его при помощи numpy.zeros_like. Функция создает копию матрицы image с сохранением ее формы и размера, затем заполняет ее нулями. Другими словами, мы получили копию нашего оригинального изображения, залитую черным фоном. Переводим его в 1-канальное и наносим найденные контуры при помощи cv2.drawContours, заполнив их белым цветом. Получаем бинарный порог, к которому можно применить cv2.dilate. Функция расширяет белую область, соединяя отдельные прямоугольники, расстояние между которыми в пределах 5 пикселей. Еще раз вызываем cv2.findContours и получаем контуры красных цифр.
Оставшийся шум отфильтруем по площади контуров при помощи cv2.contourArea. Убираем все, что занимает меньше 500 пикселей².

Вот теперь отлично. Реализуем все вышеописанное в нашем классе Robot.
Распознание цифр
Добавим возможность распознания цифр. Зачем нам это нужно? Потому что мы можем . Данная возможность не является обязательной для работы бота и при желании ее можно смело вырезать. Но так как мы обучаемся, добавим ее для подсчета набранных очков и для понимания бота, на каком он шаге на уровне. Зная завершающий ход уровня, бот будет искать кнопку перехода на следующий или повтор текущего. Иначе пришлось бы осуществлять их поиск после каждого хода. Откажемся от использования Tesseract и реализуем все средствами OpenCV. Распознание цифр будет построено на сравнении hu моментов, что позволит нам сканировать символы в разном масштабе. Это важно, так как в интерфейсе игры есть разные размеры шрифта. Текущий, где мы выбираем уровень, определим SQUARE_BIG_SYMBOL: 9, где 9 — средняя сторона квадрата в пикселях, из которых состоит цифра. Кадрируем изображения цифр и сохраним их в папке data. В словаре self.dilate_contours_bi_data у нас содержатся эталоны контуров, с которым будет происходить сравнение. Индексом будет название файла без расширения (например «digit_0»).
В OpenCV для сравнения контуров на основе Hu моментов используется функция cv2.matchShapes. Она скрывает от нас детали реализации, принимая на вход два контура и возвращает результат сравнения в виде числа. Чем оно меньше, тем более схожими являются контуры.
Сравниваем текущий контур digit_contour со всеми эталонами и находим минимальное значение cv2.matchShapes. Если минимальное значение меньше 0.15, цифра считается распознанной. Порог минимального значения найден опытным путем. Также объединим близко расположенные символы в одно число.
На выходе метод self.scan_digits выдаст массив, содержащий распознанную цифру и координату клика по ней. Точкой клика будет центроид ее контура.
Радуемся полученной распознавалке цифр, но не долго. Hu моменты помимо масштаба инвариантны также к повороту и зеркальности. Следовательно бот будет путать цифры 6 и 9 / 2 и 5. Добавим дополнительную проверку этих символов по вершинам. 6 и 9 будем отличать по правой верхней точке. Если она ниже горизонтального центра, значит это 6 и 9 для обратного. Для пары 2 и 5 проверяем, лежит ли верхняя правая точка на правой границе символа.


Анализируем игровое поле
Пропустим тренировочный уровень, он заскриптован по клику на белом курсоре и приступаем к игре.
Представим игровое поле как сеть. Каждая область цвета будет узлом, который связан с граничащими рядом соседями. Создадим класс self.ColorArea, который будет описывать область цвета/узел.
Определим список узлов self.color_areas и список того, как часто встречается цвет на игровом поле self.color_areas_color_count. Кадрируем игровое поле из скриншота канвы.
Где pt1, pt2 – крайние точки кадра. Перебираем все цвета игры и применяем к каждому метод self.get_dilate_contours. Нахождение контура узла аналогично тому, как мы искали общий контур символов, с тем отличием, что на игровом поле отсутствуют шумы. Форма узлов может быть вогнутой или иметь отверстие, поэтому центроид будет выпадать за пределы фигуры и не подходит в качестве координата для клика. Для этого найдем экстремальную верхнюю точку и опустимся на 20 пикселей. Способ не универсальный, но в нашем случае рабочий.
Связываем области
Будем считать области соседями, если расстояние между их контурами в пределах 15 пикселей. Перебираем каждый узел с каждым, пропуская сравнение, если их цвета совпадают.
Ищем оптимальный ход
У нас есть вся информация об игровом поле. Приступим к выбору хода. Для этого нам нужен индекс узла и цвета. Количество вариантов хода можно определить формулой:
Варианты ходов = Количество узлов * Количество цветов — 1
Для предыдущего игрового поля у нас есть 7*(5-1) = 28 вариантов. Их немного, поэтому мы можем перебрать все ходы и выбрать оптимальный. Определим варианты как матрицу
select_color_weights, в которой строкой будет индекс узла, столбцом индекс цвета и ячейкой вес хода. Нам нужно уменьшить количество узлов до одного, поэтому отдадим приоритет областям, цвет которых уникален на игровом поле и которые исчезнут после хода на них. Дадим +10 к весу ко все строке узла с уникальным цветом. Как часто встречается цвет на игровом поле, мы ранее собрали в self.color_areas_color_count
Далее рассмотрим цвета соседних областей. Если у узла есть соседи цвета color_inx, и их количество равно общему количеству данного цвета на игровом поле, назначим +10 к весу ячейки. Это также уберет цвет color_inx с поля.
Дадим +1 к весу ячейки за каждого соседа одного цвета. То есть если у нас есть 3 красных соседа, красная ячейка получит +3 к весу.
После сбора всех весов, найдем ход с максимальным весом. Определим к какому узлу и к какому цвету он относится.
Полный код для определения оптимального хода.
Добавим возможность перехода между уровнями и радуемся результату. Бот работает стабильно и проходит игру за одну сессию.
Читайте также: