
Fl studio 20 настройка голоса

Ведущий вокал, конечно же, является основным элементом большинства поп-музыки. Это делает его ключевой частью всего микса. Чистая запись голоса должна производиться с помощью высококачественного студийного (конденсаторного) микрофона в подходящем месте. Это неплохая отправная точка, но даже безупречные вокальные аудио записи могут совершенствоваться, пройдя соответствующую обработку. Часто это будет незаметно, но, как и во многих других аспектах микширования, дьявол кроется в деталях. Вот несколько практических советов по использованию VST эффектов для улучшения вокальной партии.
Питч: Корректируем высоту тона
Предполагается, что опытным вокалистам не потребуется корректировать высоту звука. Здесь продюсер на слух решает, что качество может быть улучшено. Профессиональные плагины коррекции питча (AutoTune, Melodyne и другие) могут автоматически выровнять фальшивую голосовую дорожку. Это действительно полезно, но надо знать о нескольких вещах.
- Любой подключаемый модуль коррекции высоты звука должен быть помещен в первый (верхний) слот микшера. Ему нужно преобладать над любыми другими эффектами, чтобы работать лучше с чистой, необработанной версией сигнала. Это обеспечит более прозрачное исправление высоты тона.
- Хотя редактирование питча можно применить ко всей дорожке, иногда это «излишне исправляет» красивые вокальные приемы. Злоупотребление, например, может испортить орнаментные блюзовые ноты, в которых неровности и тоновые отклонения обязательны. В конечном итоге исполнение окажется чрезмерно «ровным» и «плоским». Исходя из этого, применять обработку следует только там, где она действительно необходима, а не в большей части трека.
- Если вы корректируете высоту звука с помощью пресловутого эффекта AutoTune, то знайте, что он активно используется. Его задействуют очень многие, порой даже избыточно, в течение многих лет. Внимательные слушатели могут отрицательно отреагировать на очередное повторение. Возможно, лучше всего будет использовать эффект разумно или придумать что-то оригинальное.
Эквализация
Вокальная партия, записанная на хороший студийный конденсаторный микрофон, не требует тонны эквалайзера. В идеале она может вообще не нуждаться в эквализации. Более эффективным здесь может оказаться выбор правильного микрофона для определённого типа пения. Наши уши настолько точно настроены на нюансы человеческого голоса, что даже маленькая порция эквалайзера способна иногда немного «законсервировать» пение вокалиста. Просто старайтесь всячески избегать чрезмерную обработку.
Конечно, в контексте музыкальной композиции может потребоваться небольшой тонкий эквалайзер. В зависимости от используемого микрофона какой-то подъем в диапазоне 5–10 000 привнесёт незначительного присутствия. Это позволит вокалу немного преобладать над остальными дорожками. Пары дБ может быть достаточно, тем более что многие высококачественные студийные микрофоны уже содержат этот вид тонкого усиления присутствия.

Особым испытанием для эквалайзера окажется вокальная дорожка, записанная вживую, посредством сценического микрофона, такого как SM58 / 57. Получаем комбинацию менее воздушных верхних частот динамического сценического микрофона и усиления НЧ. Это результат эффекта близости (когда направленный микрофон находится близко ко рту певца). Здесь может потребоваться небольшая поправка эквалайзером. Широкий провал на несколько дБ в низких частотах примерно на 200 Гц помогает убрать излишне басовый тон. Рекомендуется поднять ползунки в диапазоне 10K+, что добавит немного приятной атмосферы. Не стоит ожидать, что это приведет к идеальным ВЧ и прозрачности, подобно студийным конденсаторным микрофонам.
Компрессия
Сжатие неоднократно используется в вокале, ведь многие исполнители имеют излишне широкий динамический диапазон. Лучшие певцы берут его на вооружение для создания драматического музыкального эффекта. Стоит помнить, что обширные колебания уровня в миксе могут сделать вокал слишком громким или чересчур мягким в разных частях песни. Это зависит от динамики минусовки. Компрессия может сохранить тональность и музыкальный эффект более агрессивного или более непринужденного пения, выровняв реальный уровень громкости. Чаще всего это сглаживание должно быть четким. В единичных ситуациях звучание голоса намеренно сжимают для придания «театрального» музыкального эффекта. Это полезно только тогда, когда такая обработка соответствует песне / музыкальному стилю.
Есть несколько способов добиться стабильной вокальной компрессии. Если уровни певца преимущественно равны, но случайное слово или фраза выскакивает слишком сильно, порог компрессора можно установить на более высокое значение, с большим соотношением (6:1, 8:1). Так вы сможете ограничить уровень только этих битов. В остальных случаях можно «ровнять» на пониженных значениях регулятора Ratio (3:1, 4:1). Таким образом сжатие будет применяться на всех уровнях. При втором подходе наиболее громкие отрезки исполнения все равно будут сжаты сильнее, чем более тихие фразы. Общее выравнивание может быть значительно тоньше. Нередко использование двух компрессоров последовательно, как указано выше, для управления различными аспектами детализации.
Конкретные настройки компрессора сильно зависят от его типа и внутреннего алгоритма, который он использует для определения уровня и применения изменения усиления. Многие микшировщики порекомендовали бы оптический компрессор для вокала, такой как знаменитый Teletronix LA-2A. Можно также выбрать что-то среди программных эмуляций (VST плагинов), которые имеют несколько элементов управления для упрощения использования. Большинство таких эффектов могут предоставить множество желаемого сжатия / выравнивания. Они подойдут для превосходного общего контроля уровня в миксе, не делая вокал действительно сжатым.

Время и пространство
Конечно, для вокала обычно используются эффекты, основанные на времени. Самыми популярными из них являются реверберация и задержка. Все слышали, как пение в ванной делает голос полнее и эпичнее благодаря атмосфере помещения и его отражающим поверхностям. В то время как в некоторых музыкальных жанрах требуется относительно сухой фронтальный ведущий вокал, в большинстве случаев небольшая реверберация или окружающая среда добавляют голосу приятную глубину. Однако чрезмерное его использование может отодвинуть вокал на задний план микса, поэтому очень важно грамотно сбалансировать звучание. Изредка добавление небольшой задержки перед началом реверберации может предотвратить ненужное искажение голоса. Это позволяет использовать больше реверберации, не делая вокальный звук очень отдалённым. Такой параметр можно найти в некоторых продвинутых ревербераторах типа Giant Verb (обычно обозначается как Pre-Delay).
Современные VST плагины реверберации предоставляют множество типов этого эффекта. Для более тонкой атмосферы хорошим выбором станет пресет небольшой комнаты. На определённых вокалах будет уместно применение имитации старого механического устройства с подвешенными металлическими пластинами (Plate). Это сделает ваши голосовые аудио записи красивее и ярче.

Помимо реверберации, иногда добавляется дискретная задержка (эхо). Она помогает придать вокалу небольшую глубину, не помещая его полностью в искусственное пространство. Классическая версия этого эффекта называется Slap Echo. Обычно это запаздывание в 100–150 миллисекунд или около того, часто синхронизированная с темпом песни. Обратная связь может быть добавлена для повторяющихся эхо. Многие плагины Delay / Echo умеют воссоздавать звучание старых аналоговых (аппаратных) устройств. Они зачастую обладают более теплыми задержками, имитирующими высокочастотные потери в лентопротяжных механизмах или схемах типа «Bucket Brigade». Это создаст более утончённый тон эхо-эффекта.
Удвоение
Очень короткие задержки (около 15-20 миллисекунд) можно использовать для имитации двух или более вокалистов, поющих вместе одну и ту же партию. Вокальная дорожка дублируется, на копию накладывается Delay-эффект, и оба смешиваются вместе. Без банального эха сдвоенная вокальная партия часто имеет более полную и богатую тональность. Такое удвоение принято называть ADT (Artificial Double-Tracking). В аналоговую эпоху это первоначально было сделано с помощью дополнительного магнитофона, проигрывающего задержанный (дублированный) сигнал. Некоторые современные плагины имитируют тёплый, насыщенный характер удвоения на магнитной ленте. Иногда минимальное тонкое смещение высоты тона сочетается с дублированием, когда копии со смещенным питчем панорамируются в стороны для получения чуть более обширного вокального образа.

Xtra FX
Хотя при записи вокала традиционно избегают искажения, можно прибавить небольшое преднамеренное ухудшение, чтобы придать вокалу более агрессивный тембр. Это может быть имитация насыщенности ленты или даже Robovoice, если использовать плагины искажающих гитарных усилителей. Чтобы сохранить разборчивость, необходимо смешивать чистый вокал с небольшим количеством искаженного, обработанного голоса. Это обеспечивает максимальное наложение без ущерба для основного вокального звука.
Вершина айсберга
Конечно, это был лишь базовый этап некоторых стандартных техник настройки и улучшения вокальных треков. Отдельно выбранные эффекты и то, как они работают в конкретном миксе, было бы подходящей темой для более глубокого обсуждения. Надеюсь, этот беглый взгляд укажет начинающим битмейкерам и аранжировщикам интересные направления для творчества.

Как известно всем пользователям FL Studio, запись в секвенсоре, я думаю в первую очередь, подразумевает запись вокала или же голоса (дикторского, перевода или озвучки) и FL Studio оснащена практически всеми удобствами для данного процесса.
И в целом процесс записи вокала или просто голоса ни чем не отличается от простого процесса записи звука в FL Studio любой версии, описанном подробно в ЭТОЙ статье, хотя стоит упомянуть несколько важных, как я считаю, удобств, фишек и премудростей внутри, в нашем случае, FL Studio 12.
Первым делом для того, что бы записать вокал исполнителя или же просто голос в фл студио, нужно выбрать устройство записи, то есть микрофон, в одной из дорожек микшера, где и будет производиться запись. Меню для выбора, как тебе наверное уже известно находиться здесь:

И помни про то, что если у тебя моно микрофон, то следует выбирать моно источники (они находятся ниже) ну а если стерео микрофон – соответственно стерео выход.
При удачном подключении и выборе нужного источника записи – на канал микшера проследует входной сигнал, и естественно ты увидишь его изменяющийся уровень. Если этого не случилось – проверь 1) подключение микрофона (к звуковой карте, предуселителю (если имеется) или микшеру (если он участвует в цепочке подключения), 2) уровень громкостей во всем где его можно выставить (микшер, предуселитель, и тд…). 3) правильно ли ты выбрал источник записи?
Я думаю, ты уже знаешь, что нужно учитывать акустику помещения, в котором ты записываешь вокалиста или же себя. Даже если нет профессиональных акустических материалов и отделки комнаты, простые люди находят простые и практичные решения – вокалистов сажали в шкаф, сооружали для них легко собираемые будки для записи, в которых установлено достаточно поглотителей и рассеивателей звука, даже есть такие изобретения, как мини будка, в которую помещается только голова вокалиста и микрофон – а что еще нужно для записи?):

Помни что если ты пишешь вокалиста, то ни когда не помешает дать ему распеться перед записью или преподнести ему щедро стакан воды, и лучше съесть ложку меда – это всегда способствует отличному голосу!
Как тебе, наверное, известно из СТАТЬИ по записи звука в FL Studio, у тебя есть два варианта записи: 1) прямиком на диск и с добавлением записанного аудио на playlist fl studio и на ее панель каналов. 2) и [РЕКОМЕНДУЕМЫЙ] через редактор и стандартный плагин в FL Studio, Edison (его стоит добавить в один из слотов на, выбранной для записи голоса, дорожке микшера).
Первым способом можно легко и быстро воспользоваться через вот эту кнопку в панели быстрого доступа FL Studio:

Там же, но только в первой строчке можно достать Edison на ВЫБРАННОЙ дорожке микшера (проследи, что бы выбрана была именно дорожка для записи голоса) и запись начнется автоматически в плагин Edison.
В обоих случаях ты можешь записывать уже обрабатываемый голос, какими-то плагинами или эффектами. К примеру, в некоторых случаях для записи своего голоса, я пользуюсь эквалайзером, срезающим все ниже 80-100 герц, для избегания попадания в запись низких артефактов:

И в некоторых случаях, и без этого можно обойтись, так как следующий процесс можно провести и после записи, я ставлю Noise Gate, я советую плагин от компании Fabfilter Pro-G, он сразу избавит тебя от ненужного шума в записи (устанавливать порог, естественно, стоит в зависимости от ситуации):

Можно использовать любые эффекты обработки при записи (Reverb, Delay, Distortion и тд и тп) Но помни что чем больше обработки и чем она тяжелее для FL Studio, тем больше будет задержка в записи звука, то есть голос будет, конечно же, отставать – что служит очень большим неудобством как для вокалистов, так и для звукорежиссера! И второй момент при записи обрабатываемого (так скажем онлайн) голоса через Edison, следи за тем, где располагается сам плагин Edison в цепочке обработки. Кончено же что бы поймать в запись воздействие всех плагинов обработки, необходимо ставить Edison после всех используемых плагинов обработки.

Есть положительные моменты в процессе записи вокала или голоса в FL Studio у обоих способов,
Прямой записью (на Playlist Fl Studio) записывать очень просто – делается это в один клик и сохраняется все сразу на диск, найти все записи можно вот в этой директории по-умолчанию:

Отличное преимущество данного вида записи – это удобство записи Sound-on-Sound (Звук на Звук). Это полезно для записи Back вокала на основной, или для многослойных записей одних и тех же частей вокальной партии. Это можно организовать, выделив на плейлисте фл студио нужный регион для того что бы он повторялся в режиме Loop\ петли (скорее всего вместе с минусом или фонограммой) и активировав вот эти две кнопочки на панели FL Studio:

И вокалист может безостановочно прописать все дорожки припева, да и затем еще с бек вокалом, если это нужно. Если вокалиста сбивают или ему мешают его предыдущие записи – их можно в записи отключить первой кнопкой из тех самых двух, которые мы активировали для записи Sound-on-Sound.
И через Edison, в силу множества удобств и ухищрений, вот как можно облегчить себе жизнь при записи вокала или голоса в нем: Удобнее всего записывать (если это вокал, он, конечно же, исполняется в сопутствии с минусом или музыкой) через режим записи Edison “On Play”:

Запись начнется со стартом воспроизведения режима songили pattern в проекте FL Studio.
И если производить запись в режиме pattern,где вокалист исполняет определенную часть композиции (только припев, либо только куплет) запись Edison будет продолжаться до тех пор, пока не истечет время или размер, установленный в нем (следом за меню режима, где мы выбрали On Play) а patternбудет проигрываться в режиме петли (Loop) И в записи Edison ты можешь увидеть как создаются автоматические маркеры, по началу каждого нового pattern:

Так удобно производить множественные вариации записи одного и того же фрагмента, и затем выбрать наиболее удачный, это максимально удобно – просто двойным щелчком по маркеру выделить идеально ровный удачный отрезок записи (равный длине паттерна). И перетащить его за эту кнопку – куда угодно, для дальнейших операций:

Так же если Noise Gate не производился в процессе записи, в Edison это реализовано очень даже здорово и удобно, подробнее об этом процессе и о других удобствах Edison можно посмотреть в нашей полнейшей инструкции по данному плагину, но вот что касается Noise Gate то маркер в плеере нужно перетащить на время 16:11.
В последствии, конечно же, любой вокал нужно обработать подходящим для ситуации образом, если нужен процесс нормализации (доведение самого громкого пика в аудио до максимального уровня) то это можно сделать в Edison во вкладке « Обработка» категория Amp, - Normalize. С записанным аудио через прямой способ все еще проще, я думаю, ты уже знаешь где находиться нормализация в FL Studio Sampler:

И естественно в обработке и сведении вокала с остальными инструментами или фонограммой, есть свои подводные камни, и это своя отдельная ниша звукорежиссуры.

Музыканты, диджеи, сиджеи, и те, кто только учатся писать музыку в домашних условиях, часто задают такой вопрос: «какие плагины я должен использовать при сведении» или «подскажи мне идеальный метод и цепочку плагинов для профессионального сведения, КАК СВОДИТЬ ПРОФЕССИОНАЛЬНО?». И я обычно говорю, что можно сделать профессиональное сведение при помощи всего ДВУХ плагинов, причем, они УЖЕ лежат у тебя в папке плагинов-эффектов! Сейчас много видео уроков и видео курсов по сведению – где видно как «учителя» вешают на слоты в микшере дорожки кучу невообразимо продвинутых плагинов и эффектов обработки, – которые может, и делают звук инструментов лучше, но сам микс целиком и процесс сведения - не всегда.
Если спуститься в корень сведения и заглянуть в суть самого сведения, то нам нужны всего три параметра звука, что бы получить в результате отличный микс на мастере, и это громкость, частота и динамика! Громкость мы регулируем при сведении в FL Studio или другом секвенсоре, за счет фейдера самой громкости дорожки на нашем микшере. И теперь частоты и динамика… Что это может быть. Я думаю, если вы свели самостоятельно хотя бы пару ваших треков на компьютере, то вы понимаете, про какие 2 плагина я поговорю в этой статье. Большинству понятно, что это эквалайзер и компрессор.
И действительно, для того, что бы свести трек на профессиональном уровне, вам нужны только эти 2 плагина. Эквалайзер и компрессор. Я не заставляю вас отказаться и выкинуть все плагины пространственной и другой обработки звука, они важны, а иногда так же необходимы для хорошего сведения, но в самом корне, БЕЗ них вы можете обойтись и получиться профессионально сведенный трек в вашем секвенсоре, используя лишь эквалайзер и компрессор.
Но вопрос теперь стоит так – почему же Я, уже тысячу раз использовал эквалайзер и компрессор (причем, иногда не один на дорожке) ни разу не получал идеального сведения в FL Studio? Да, мне знакома эта цепочка EQ+Compressor и я ей много раз уже пользовался – где же мой идеальный микс? Конечно же, стоит уметь применять должным образом вот эту самую цепочку «эквалайзер + компрессор», так как именно вот в этом простом построении последовательности звуковой обработки и кроется понятие ХОРОШЕГО СВЕДЕНИЯ и фраза «такой-то инструмент хорошо сидит в миксе» - так же кроется в этом принципе. Плюс, мы помним про нашу громкость на микшере, так как это понятие должно выскакивать у вас в голове первым делом, когда вы слышите слова «сведение» или «микс»! Лично я, когда слышу слово «микс», то вижу перед собой Дейва Пенсадо, регулирующего фейдеры громкости на своей консоли в Pensado’s Place, и для меня эта картина выскакивает просто потому, что я часто учусь от него и всегда слежу за выпусками Pensado.
Дорожки вашего трека идеально сводятся на мастере, в том случае, когда все частотные составляющие этих дорожек по минимуму конфликтуют друг с другом, и все нужные частотные регионы каждой дорожки доходят до слушателя должным образом (+ без искажений и неприятных перегрузов) через общий микс, который в свою очередь несет в себе по большей части ВЕСЬ частотный диапазон. И как реализовать все это многоэтажное определение в действительности и в моем секвенсоре? Все достаточно просто! С помощью эквалайзера, поставленного ПЕРЕД компрессором на нашей дорожке микса, мы будет ВЫРЕЗАТЬ (а не прибавлять) частотные составляющие нашей дорожки, и с помощью компрессора мы будем поднимать уровень оставшихся частот до нужного уровня – параллельно УМЕНЬШАЯ динамический диапазон нашей составляющий микса.
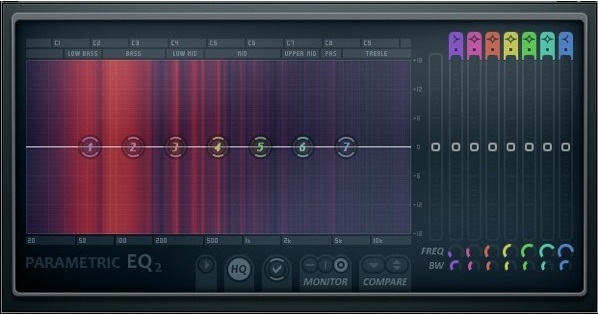
Узнаете? Да, это стандартный плагин обработки в вашей FL Studio - Parametric EQ2.
Я бы настоятельно рекомендовал использовать при сведении в FL Studio именно Parametric EQ2. Позже объясню почему.
Как вы, наверное, уже слышали – стоит первым делом срезать все не нужные нам частоты из начального спектра нашего инструмента и из его конечно спектра – Все правильно! Так и делаем, единственное, что хочется заметить и подчеркнуть – вырезайте действительно все НЕ НУЖНЫЕ частоты из начала и конца! Если ваш инструмент или составляющая микса начинает терять его основной спектр – частотный регион, на котором он более активен - возвращаемся назад. НАМ НЕ НУЖНО ТЕРЯТЬ рабочей частоты инструмента, так как она естественно нужна нам в миксе как никогда! Следите еще за тем, что вам нужно от инструмента! Например, в танцевальной музыке, от фортепиано, зачастую, требуется яркость и цвет в общий микс, а кинематографические саундтреки, в свою очередь, иногда хотят от фортепиано глубины и полноты звучания.
Следующий важный момент сведения это то, что каждый инструмент имеет свой частотный регион или область и нам следует по минимуму накладывать друг на друга инструменты, со схожими рабочими областями. А если это и требуется, выходы всегда есть: и это панорамирование или же, если требуется, то Sidechain компрессия – но, так как статья не про «методы решения частотных конфликтов у схожих инструментов» , а про главные инструменты профессионального сведения – сейчас у нас нет времени окунаться в это. Итак…
Это был первый момент с эквалайзером… Второй, ВАЖНЫЙ момент – удаляйте все пиковые частоты (те частоты и пики, на которых этот инструмент через чур активен), как правило такие регионы и пики есть, и бывает, что не по одной штуке на инструмент! И вырезайте, конечно же, исключительно узкими полосами, (помним золотое правило любого звукорежиссера: «при работе с эквалайзером мы вырезаем узкими полосами, добавляем (хотя я бы не советовал вообще при работе с эквалайзером «добавлять» амплитуды частотам) более широкими». И почему я не советую добавлять амплитуды частотам, хотя многие это делают и миксы получаются просто отличные… Представьте себе аналогию со скульптором; он берет целый блок камня и уже из целого блока этого камня вырезает скульптуру с фигурой и всеми мелочами, которые он хочет, и ни чего не добавляет сам! Этому принципу МЫ должны следовать и при сведении \ обработке трека. Так как уже после эквалайзера мы ставим в нашу цепь компрессор, который уже из всего вырезанного нами спектра, подчеркивает и увеличивает ВСЕ, что мы хотели оставить и донести до слушателя, от отдельно взятой дорожки микса или инструмента. И как найти эти активные пики и регионы? Изобразите вот что:

Сделайте нужную полосу вашего эквалайзера достаточно узкой и пробегитесь по всему частотному диапазону каждого инструмента или семпла – от слишком активных пик и регионов ваши ужи немного заболят (не переборщите с этим – не нужно, чтобы после сессии сведения у нас шла кровь из ушей)). Там, где вы найдете излишние зашкалы и давление – это нужные вам пики для понижения и выреза!
И вот что получилось у меня (в этом случае обрабатывался рояль засэмплированный на плеере KONTAKT) и здесь я вырезал кроме крайних, не присущих роялю регионов, только ОДИН регион частот (подчеркну в моем случае ОДИН):

Можете сказать «зачем ты вырезал так много низких частот – это же РОЯЛЬ! Там - самая глубина у инструмента!» Помните, я говорил выше – знайте, что вам нужно от инструмента! В моем случае пишется не живая композиция – а более танцевальный трек, где я хотел от рояля передать только его реалистичность, мягкость и яркость в мой микс.
Итак, в данном случае только один вырез – и тот случается на определенной ноте, КОТОРАЯ в прописанной партии звучит чаще остальных. Здесь важный момент! Если ваши инструменты (это не одиночные семплы) имеют широкие нотные, игровые диапазоны, будут ноты, у каждого или почти каждого инструмента, которые проявляют себя активнее остальных, и среди них будут через чур активные – их мы и хотим немного успокоить (у них естественно есть свой пиковый регион, и почему я советую использовать при сведении в FL STUDIO именно Parametric EQ2 – так как он показывает нам наглядно, как на блюдичке, что, где и когда активно и на сколько активно). И не забываем про регионы излишней активности инструментов или семплов, как таковых.
Все что осталось в наших частотных диапазонах отдельных дорожек микса теперь передается компрессору на каждой дорожке на дальнейшую обработку. И здесь ваш выбор!


Вы можете использовать встроенный во Fruity Limiter однополосный компрессор, что может быть самым подходящим орудием в вашей ситуации!
Или же использовать (если ситуация требует этого и нужна разная компрессия для разных частотных областей) встроенный многополосный компрессор Fruity Multiband Compressor.

И если уж ситуация совсем тяжкая и нужна тяжелая артиллерия - глубокая компрессия и не только, то возьмите Maximus (подробный видео обзор которого, я сделал в этом видео ЗДЕСЬ, с примерами обработки и сведения).
Но чем бы вы не уменьшали динамический диапазон и не доводили общий уровень, помните, что, скорее всего вам хватит и стандартного однополостного компрессора а FL Studio. Здесь, наша задача на компрессоре, стоит в том, что бы сравнять (сгладить) излишние громкости \ пики дорожки (инструмента) и поднять менее слышимые регионы до требуемого уровня. И помните результат после эквалайзера – мы автоматически поднимаем нужные нам вещи (частоты). А если вы слышите в результате вашей работы над дорожкой, какие то зашкалы и излишнее давление после проделанной работы с эквалайзером – или вы переборщили с компрессией (помним в компрессии тоже есть законы и принципы как ни где в другой области обработки – без фанатизма) или же возвращайтесь именно к эквалайзеру и ищите эти пики, значит, они есть в вашем инструменте! …Если же вы в корне не понимаете принцип работы компрессора и вы - полный новичок в этом деле – это тема для другой статьи и совершенно другой разговор, который стоит назвать ОСНОВЫ РАБОТЫ С КОМПРЕССОРОМ!
Вот как с помощью двух простых и стандартных инструментов, плюс базового метода выреза ненужных и поднятия нужных частот, можно добиться хороших профессиональных результатов. После этого вы - свободны, пользоваться пространственной обработкой – или чем-то еще, что есть в вашем супер-мега арсенале звукорежиссера. Стоит помнить главное - всегда делайте результат лучше прежнего, а не усугубляйте положение и звучание вашего трека, если обрабатываете какими-то дополнительными эффектами – то сравнивайте результат до и после этого эффекта, при помощи простой кнопки (функции Bypass) на вашем слоте микшера. А если ваш микс звучит в результате не так плотно и аккуратно, как вы хотели - возможны проблемы с изначальным уровнем громкости ваших инструментов и дорожек, здесь я могу посоветовать применить при сведении способ «воронки» или «сведение на минимальных уровнях», об этом я ранее рассказал очень плотно вот в ЭТОЙ статье.
Вот и все что я хотел вам донести по поводу этих важных моментов любого профессионального сведения как в FL Studio, так и в любом другом секвенсоре. Главное что бы вы поняли основной принцип и этот главный принцип сведения начал приносить вам отличные результаты, если же вы хотите узнать про этот принцип сведения электронной музыки со всеми его подробностями и ухищрениями, то советую ознакомиться с нашим полным обучающим видео курсом по этой теме "Профессиональное сведение электронной музыки до результата", где данный метод затрагивался не раз и во всех деталях на практике, ПРИОБРЕСТИ КУРС И УЗНАТЬ ВСЕ ПОДРОБНОСТИ можно ЗДЕСЬ.
Подписывайтесь на нашу рассылку статей и исключительно ценных видео материалов, так как именно здесь - на блоге, происходят все интересные вещи и появляются ценные материалы. До скорых встреч в следующих видео-уроках и статьях, на этом у меня все!

Сегодня я хочу рассказать о том, какие основные приемы используются при создании музыкальных произведений в программе FL Studio. Я сам пишу музыку и использую для ее обработки различные инструменты, в том числе продукты от компании Image-Line («FL Studio» и «Deckadance»), и вхожу в ее Power Users List (в этом списке я – единственный музыкант из России). В этом топике я расскажу о том, как использовать прием наслоения (на примере ударных партий и вокала), а также о том, как подготовить записанный вокал к последующей обработке.
Наслоение
Этот приём часто используется музыкальными продюсерами. Так повелось, что музыкальные продюсеры в России по сути являются менеджерами артистов, в остальном же мире продюсеры — это люди, которые создают музыку в так называемых секвенсорах (музыкальных программах по созданию музыки). Например, Lady Gaga, даже если и умеет сочинять песни, не может сама создать конечный продукт и с этим ей помогают те самые продюсеры. Один из известнейших продюсеров, работавший с ней — RedOne.
Так вот, вернемся к наслоению. Этот прием используется для того, чтобы придать полноту звучания любому из ваших инструментов, а также треку в целом. Наиболее часто он используется при создании партии ударных и вокальных партий. Сначала рассмотрим наслоение на примере партии ударных.
Наслоение при создании ударных партий. Я пишу акустическую и электронную музыку, используя при этом библиотеки предзаписанных семплов. Такие библиотеки содержат в себе звуки, записанные в профессиональной студии, доступ к которой не всегда имеется у начинающих музыкантов и продюсеров. Примером таких звуков может быть один удар в том, бочка, хлопок в ладоши, перкуссионный барабан и другие подобные вещи. Такие библиотеки можно легко найти в свободном доступе или в продаже в интернете. Они называются «One Shot Samples» или «One Shot Libraries».
Также оправдано использование уже записанных заранее ударных петель. Они обычно представляют собой уже полные и готовые версии ударных и могут быть разбиты на части (например, бочки отдельно, тарелки отдельно, перкуссии отдельно, тамбурины отдельно), и если сложить их вместе, получится полноценная ударная партия. Они называются «Drum Loops» и в большом количестве представлены в интернете. Помимо прочего, существует множество программ с готовыми библиотеками ударных, ярким примером которых являются «XLN Audio Addictive Drums», «Spectrasonics StyleRMX», «Native Instruments Machine» и другие.
Рассмотрим наслоение основных бочек («kick») на указанном ниже рисунке. Для того, чтобы получить насыщенный и плотный звук бочки, я использую три их разные вариации. Студийная плотная бочка (Studio Kick), сэмпл акустической бочки из библиотеки готовых ударных (Acoustic Kick) и электронная сгенерированная бочка (Electronic Kick).

Каждая из этих бочек имеет собственное звучание, но вместе они начинают звучать намного плотнее, чем по отдельности. При совмещении различных ударных, необходимо учитывать, что они могут и не сочетаться вместе, поэтому порой приходится подвергать их эквализации. На рисунке, представленном снизу, у одной из бочек (слева) убраны низкие басовые частоты, и она создает так называемый хлопок или щелчок в верхнем диапазоне частот, а у другой акцент сделан на низкие частоты, и она заполняет собой басовую составляющую.

При комбинировании ударных, составленных из «One Shot»-сэмплов, можно использовать такие программы, как «Native Instruments Battery» или «Image-Line FPC». Там вы сможете выставить громкость каждого из инструментов, разнести их по панораме. На рисунке внизу представлены 3 бочки, совмещенные в одной ячейке программ «Image-Line FPC».

Кроме того, в музыкальном продюсировании часто используют наслоение уже готовых партий ударных петель. В своей музыкальной практике я использую оба этих подхода, а именно: сам составляю часть партии ударных из «One Shot»-сэмплов, а часть заполняю уже готовыми петлями ударных, подобранных мною из специальных библиотек или программ. На примере внизу зеленым цветом выделены 6 уровней ударных, составленных мной (3 уровня бочки, один хлопок, закрытые тарелки и металлические перкуссии), а так же 4 уровня готовых ударных петель, закрашенных синим. Все вместе они составляют полную ударную партию песни, использованную в припеве. Такой комплексный подход позволяет получить более полноценное звучание ударных.

Работа с вокалом
Начальная обработка вокала. Рассмотрим обработку вокала на начальном этапе, а затем уже поговорим о наслоении вокала. Естественно, первым делом вокал нужно записать. Для этого я использую встроенный в FL Studio плагин «Edison». Чтобы записать вокал, нужно выбрать входящий канал, к которому подключен ваш микрофон, а затем на этот же канал добавить плагин «Edison», выставить переключатели «NOW» и «IN NEW PROJECT», после нажать кнопку записи и записать ваш вокал (все указано на рисунках внизу).


Не спешите сохранять вокал, сразу после того как он будет записан. Для начала нужно избавиться от лишних шумов, которые обычно выдает ваш микрофон, провода, аудиокарта, а также источники звука в помещении. Для этого постарайтесь немного помолчать после записи вокала, тем самым оставив небольшой участок, с которого можно будет считать шумы, образующиеся при записи. Затем выберите данный участок и откройте «Clean Up Tool», как показано на рисунке внизу.

Затем плагину необходимо будет составить так называемую «карту шумов», которую он и будет исключать из вашего вокала. Чтобы сделать это нажмите кнопку «Acquire noise profile».


Затем (в окне «Edison») вы увидите и услышите, что ваш вокал заметно очистился.
Теперь разберем, как убрать из вашего вокала слишком громкие согласные «С» и «З». В производстве данный процесс называется «De-essing». Дэ-эссинг можно выполнить и с помощью плагинов (например, «AVOX Sybil» или «Fabfilter Pro-C»), но этот процесс можно провести и вручную. Это актуально потому, что многие плагины для дэ-эссинга все-таки подвергают обработке и тем самым искажают весь ваш вокал, а не только согласные, и, чтобы оставить остальные части вашей записи нетронутыми, можно использовать «ручной» подход.
Для этого загрузите ваш вокал в «Edison». Переключившись на спектральный вид (как показано внизу):

… вы увидите громкие звуки «С» и «З» (отмечены на рисунке ниже):

Затем выделите в «Edison» один из участков, где расположены согласные и откройте «Equalize», там вы увидите этот участок более подробно. Обычно звонкие согласные располагаются в диапазоне от 5K до 15K. Вырежьте эти частоты, выставьте «Mix» примерно на 50% и нажмите «Accept» (все указано на рисунке внизу).

Далее нужно проделать эту процедуру со всеми звонкими согласными «С» и «З». Также можно поступить и с громкими вдохами, только эквализировать нужно будет весь диапазон частот (по сути просто сделать их тише).
Наслоение при создании вокальных партий. Теперь рассмотрим приём наслоения, который можно и нужно использовать и при создании вокальных партий. Всем известные бэк-вокалы – это, по сути, и есть наслоение. Однако, в данном вопросе есть несколько различных подходов.
Первый подход заключается в том, что вы приглашаете бэк-вокалистов, либо сами исполняете свои бэки. Плюсы данного подхода очевидны, реальный голос пока невозможно ничем заменить. Минусы: вам понадобятся как студия записи, так и хорошие бэк-вокалисты. Далее записанный вокал добавляется к ведущему вокалу без точной подгонки во времени (то есть вокалы могут звучать немного вразнобой, но не сильно).
Второй подход заключается в том, что вы можете использовать такие программы, как «Antares Autotune» или «Image-Line Pitcher», чтобы создавать гармонические бэк-вокалы, имея только одну главную вокальную партию. Вкратце опишу процесс создания этих беков.
Сначала необходимо записать основную вокальную партию (так называемый «Lead Vocal»). Затем обработать её (про обработку вокала речь пойдет чуть ниже) и импортировать в FL Studio. Далее необходимо послать вокал на канал эффектов, где расположен Pitcher, как указано ниже.


В Pitcher необходимо выставить следующие показатели: включить кнопку «MIDI» (когда вы включите эту кнопку в левом нижнем углу появится номер порта, его необходимо запомнить), и кнопку «HARMONIZE». Также можно выставить переключатель «Replace-Mix» в одно из двух положений. Положение «Replace» полностью убирает основной вокал и оставляет только сгенерированные плагином гармоники. Как не сложно догадаться, положение Mix оставляет и ваш вокал, и сгенерированные гармоники.

Затем необходимо добавить в инструменты «MIDI out», и в его настройках указать порт, который ранее был указан в левом нижнем углу Pitcher.

Затем, открыв «Piano Roll», можно задавать гармоники для генерации (плагином). Нужно указать ноты, которые плагин будет генерировать исходя из вашего основного вокала, и расставить их во времени таким образом, чтобы они совпадали с основным вокалом и создавали правильные гармоники, например так, как указано на рисунке внизу.

Плюсы этого подхода заключаются в простоте и быстроте создания гармоник, а также в том, что эти гармоники будут точно копировать ваш вокал, поэтому долго подгонять его по местоположению в миксе не придётся. Ну а главным минусом такого подхода является звучание этих бэков. Как ни крути, но избавиться от синтезированного звучания не получится.
Ясно, что чем больше слоёв бэк-вокалов, тем полнее звучит вокальная партия. Но важно помнить, что каждый раз петь одинаково не получится, и порой одна фраза будет звучать длиннее другой и т.п. Поэтому, бэк-вокалы нужно расставить точно в соответствии с вашим ведущим вокалом (как указано на рисунке внизу).

Как видно, каждый бэк-вокал подогнан к другим и к ведущему вокалу. Если этого не сделать, вокальная партия целиком будет звучать как месиво. Порой, я использую до 10 слоёв вокала (например, при создании хора в песне), и поэтому для меня это вдвойне актуально. Надеюсь, мои советы окажутся для вас полезными. Результаты того, как я сам пользуюсь этими приемами, можно послушать на моем Soundcloud, а еще можно принять участие в моей кампании на Indiegogo – не сочтите за грубую рекламу и спасибо за внимание!
Читайте также: