
Драйвер для каждого браузера нужно реализовывать самостоятельно тому кто пишет автотесты
Не спорим, за автоматизацией будущее. Но пока мы живем в настоящем, не все так однозначно. Вместе разбираемся, в чем автотесты уступают ручному тестированию и как лучше использовать автоматизацию, чтобы не потонуть в оверхеде.
В Меркури мы много времени работаем со стартапами, где функции постоянно меняются, а код переписывается от спринта к спринту. Если написали автотест, а потом команда решила внести изменения в программу, то он может быстро стать неактуальным. Поэтому, вместо ожидаемой экономии сил и средств, мы тратим время на постоянную починку тестов.
Подобный опыт наша команда пережила с собственным продуктом. Изначально думали так: большой проект, вручную тестировать долго, нужна автоматизация. Но по факту команда QA не успевала переписывать автотесты под новый функционал — продукт менялся с каждым спринтом, то есть буквально раз в две недели.
У нас была ситуация, когда переписывали приложение с Xamarin на натив, а часть нативного кода перенесли на React Native. Команда потратила много часов, чтобы переписать все под новый интерфейс.
В итоге от UI-тестов отказались: времени на поддержку уходит непозволительно много, они не успевают развиваться вместе с остальным проектом, часто пропускают критичные баги и падают из-за несовершенства технологий.
Исходя из нашего опыта определили пять типов автоматизации, которые мы используем в работе с быстроразвивающимися проектами.
Тестируем общение клиента и сервера. Обычно протокол стабилен, а изменения во фронтенде и бэкенде не затрагивают клиент-серверное взаимодействие. Эмулируем запросы от клиента, в редких случаях — ответы от сервера.
Для клиентских запросов чаще всего используем Postman, а также различные самописные решения на основе проверенных библиотек и фреймворков. Это могут быть Python в связке с Requests или Ruby с REST Client.
Вместе с новым билдом получаем высокие риски возможных ошибок. В этом случае, с помощью автоматического смок-тестирования быстро обнаруживаем и устраняем баги на раннем этапе и не тратим драгоценное время на заведомо нестабильный софт.
Ставим эксперимент и пробуем автоматизировать нагрузочные тесты. Пока что рано делать выводы, но в перспективе это должно помочь разработчикам определять падение производительности еще на этапе написания кода, а также помочь тестировщикам сократить время на регрессионное нагрузочное тестирование.
Длинные end-to-end сценарии в участках со стабильным функционаломДаже в постоянно меняющихся проектах рано или поздно часть функциональности приложения становится относительно стабильной. Применяем автотесты, когда такие куски появляются в проекте, и это действительно экономит нам время.
Разработчики просматривают кейсы на выполнение функций приложения и тестируют методы внутри самого кода. Это самый правильный подход, однако здесь возникает соблазн продолжить писать функциональный код, вместо того, чтобы каждый раз писать к коду тест. Редко когда получается выделить достаточное количество часов разработки на юнит-тесты, поэтому мы не так часто их используем.
В остальных случаях чаще всего тестируем вручную. QA продумывают кейс, тестируют и мы сразу получаем результат.
Как правило, автоматизация тестирования в стартапе работает так:
- сначала придумали кейс;
- потом написали тест;
- затем его починили;
- повторить шаг 1.
Если проект меняется быстро, то тесты устаревают еще быстрее. Усилия, которые команда тратит на их поддержку зачастую себя не оправдывают. Этот процесс отнимает много бесценного времени, поэтому мы каждый раз спрашиваем себя: а не проще ли провести ручное тестирование?
Без автотестов не обойтись в энтерпрайзе — сложном продукте, где много повторяющихся действий и невозможно искать баги вручную. В таких компаниях на автоматизацию процесса закладывается дополнительное время, функционал продукта более стабилен, и тесты не переписываются раз в две недели.
В нашем случае все меняется от проекта к проекту, поэтому принимая решение о целесообразности автоматизации приложения задаемся вопросом: «Перевешивают ли преимущества автоматизации ее недостатки?» — хотя бы для некоторой функциональности приложения. Если в проекте есть такие части — автоматизируем.
На самом деле, область автоматизации в тестировании еще только развивается, а современные инструменты ограничены:
- автоматизировать можно не на всех языках;
- часто приходится дописывать ядро тестового фреймворка вручную;
- инструменты для анализа результатов оставляют желать лучшего.
Однако, как и писали в самом начале: будущее за автоматизацией. Уже сейчас QA без серьезных скиллов в автотестировании готовят тестовые сценарии, а автоматизаторы и разработчики работают над созданием ядра для автотестов.
Индустрия развивается, и уже лет через пять большая часть ручного поверхностного UI-тестирования перейдет в простые «human-readable» сценарии. Верим, надеемся, ждем.
Вопрос применения автотестов в любом проекте — это единство грамотно выбранной стратегии тестирования, комплексного анализа и гибкого подхода. В Меркури мы работали над многими проектами, но универсального «правила» так и не нашли.
Зато определили для себя сценарии, когда автоматизация даже в быстроменяющемся продукте наиболее часто окупает себя:
- проверяем клиент-серверное взаимодействие;
- перед релизом новых версий делаем поверхностное смок-тестирование;
- пробуем автоматизировать нагрузочные тесты;
- проверяем участки со стабильной функциональностью;
- любим unit-тесты и хотим использовать чаще.
В этой статье мы делились своим опытом и постарались сами для себя ответить на один из самых сложных вопросов тестирования. И пускай мы не пришли к однозначному ответу, эти выводы помогают команде осознанно подходить к процессу автоматизации в развивающихся продуктах.

Довольно часто среди начинающих (и даже не очень) тестировщиков приходится слышать: «вот если бы я умел писать автотесты, я бы…». Как правило этим «если бы» ребята и ограничиваются. На вопрос: «А почему не учишься писать?» чаще всего отвечают: «Программирование это не мое». Действительно, тем для кого программирование темный лес, погрузиться в мир автотестов довольно затруднительно, ведь скрипт сам себя не напишет. В этой статье я хотел бы поговорить о том, как из ручного тестировщика стать крутым автотестером.
Покопавшись в интернете, я нашел наиболее популярные инструменты для автоматизированного тестирования интерфейсов:
• SilkTest;
• HP QuickTest Pro;
• QF-Test;
• Rational Robot;
• TestComplete;
• TestPartner;
• (кто вспомнит еще что-то просьба писать в комментарии).
При поиске сознательно игнорировались различные фреймворки для тестирования, типа Selenium, Cucumber, Watir, Behave, меня интересовали готовые инструменты.
Однако, все представленные выше утилиты (за исключением QF-test) оказались, по сути, средой для разработки, т.е. они предлагали использование своего «простого» скриптового языка для создания автотестов. В качестве упрощения, можно было записать действия, и они сформировались бы в скрипт, но такие записанные тесты ни к чему хорошему не приводят (да и вообще это не солидно). Сами по себе инструменты неплохи (например SilkTest), но для начинающего автотестровщика абсолютно непригодны.
QF-test оказался привлекательной рабочей лошадкой, способной тестировать и web-интерфейсы и desktop-приложения. Используя его, не нужно писать скриптов и в целом работа в нем построена удобно. Но у этой утилиты нашелся минус: совершенно непривлекательная цена (около 1200 евро).
Перед тем как приуныть окончательно, опустить руки и продолжать использование Selenium WebDriver на пару с Cucumber, мне на глаза попалось приложение Константина Трофимова (моего коллеги QA-инженера), которое я счел невероятно перспективным. Называется оно SpiderTest, скачать и ознакомиться с ним можно здесь.
Приложение изначально создавалось для собственного использования и не предполагалось для распространения, поэтому у него нет шикарного интерфейса с модными всплывающими окнами, вылизанных форм и развитой панели управления, зато утилита обладает мощным инструментарием и низким порогом вхождения, а самое главное не использует скриптов. Все операции, выполняемые пользователем, есть в списке действий. Для создания автотеста нужно только уметь составлять xpath, а этому можно обучить даже домохозяйку! (Вот эта статья и эта хорошо вводят в курс дела). Сейчас проект стал интенсивно развиваться и мы надеемся, что SpiderTest станет распространенным и полезным инструментом в арсенале любого QA-инженера.
Интерфейс приложения
Знакомство с SpiderTest начинается с главной формы, в которой предполагается создать тест-комплект — набор тестов для проверки определенной функциональности. Тест-комплект сохраняется одним файлом в расширении .sff.
Если открыть заполненный файл тест-комплекта каким-нибудь текстовым редактором, типа notepad++, то можно увидеть, что его структура составлена в соответствии с принципами xml.

Вернемся к главной форме SpiderTest: в левом окне список тестов, а в правом окне — детальное описание процедур, выполняемые в тесте. Флагами отмечены тесты, которые будут выполнены.
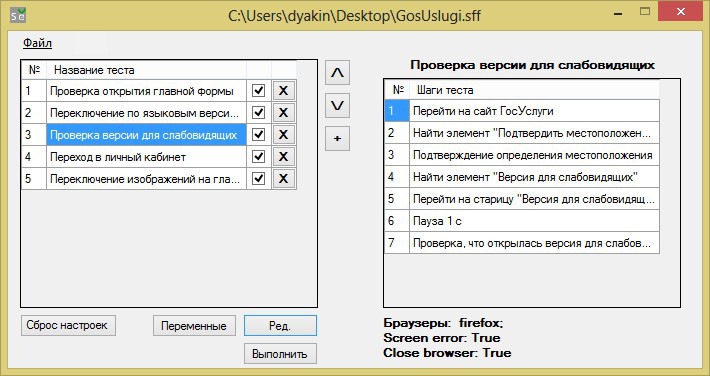
Придумав название для первого теста и сохранив его, мы получаем возможность перейти в форму его создания. Для этого нужно нажать на кнопку «Ред.» («Редактировать» прим. автора).
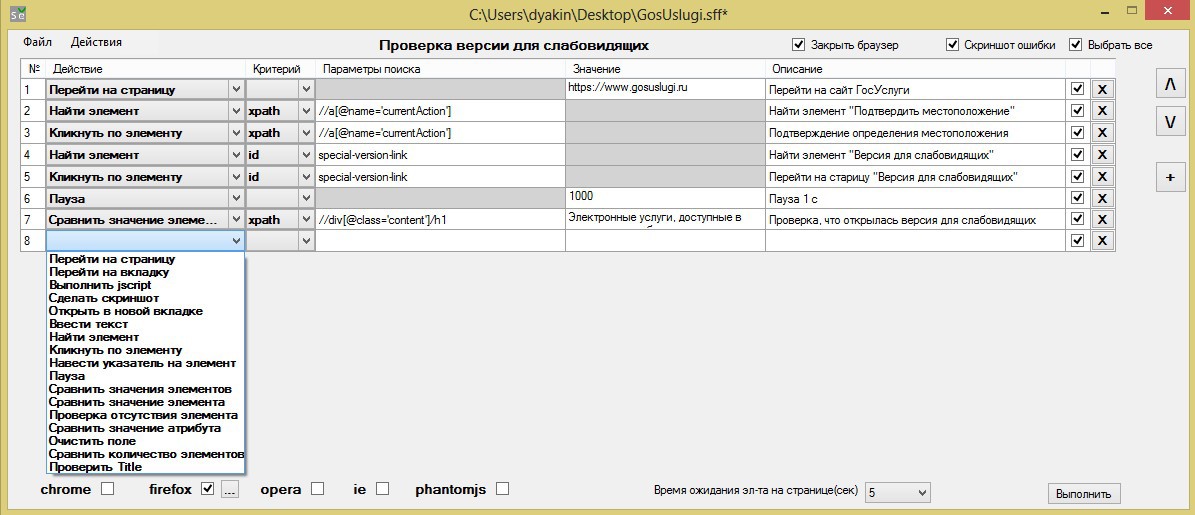
В форме редактирования теста следует выбрать последовательные действия, которые выполнит браузер во время прохождения теста.
Название столбцов явно указывает на их информационное: действие, которое нужно совершить, параметры поиска объекта для осуществления действия, значение параметра (там, где это необходимо, например, переход на сайт или сравнение текстовой информации) и, наконец, описание шагов тестирования человеческим языком (это описание попадает в главную форму).
Приведенный список действий лично мне кажется исчерпывающим, в автотестах на ruby я использовал гораздо меньший функционал.
• Перейти на страницу — открытие указанной страницы в выбранном браузере;
• Перейти на вкладку — переключение на другую вкладку. Возможно указание порядкового номера вкладки, либо можно указать Title;
• Выполнить jscript — выполнить указанный jscript;
• Сделать скриншот – создание скриншота;
• Открыть в новой вкладке — открытие желаемой страницы в новой вкладке: можно указать адрес в поле «Значение», или указать id/class/name/xpath ссылки (но это работает только для тега );
• Ввести текст – процедура ввода текст в указанный элемент;
• Найти элемент — поиск элемента на странице;
• Кликнуть по элементу – имитация клика левой кнопкой мыши по указанному элементу;
• Навести указатель на элемент – имитация наведения указателя мыши на элемент;
• Пауза — остановка выполнения теста на указанное время (в миллисекундах);
• Сравнить значения элементов — сравнение значений всех найденных элементов с указанным, если хотя бы одно значение не равно, то шаг считается проваленным; есть возможность сравнивать значение частично, для этого необходимо поместить значение между знаками *;
• Проверка отсутствия элемента — поиск элемента на странице (время ожидания появления элемента на странице 200 миллисекунд), если элемент не найден, то шаг считается пройденным;
• Сравнение значения атрибута — сравнение значения указанного атрибута элемента с указанным. Указывать атрибут следует так: атрибут|значение;
• Очистить поле — очищение указанного поля от введенного текста;
• Сравнить количество элементов — поиск на странице элементы по указанным критериям, и затем сравнение их количества с указанным;
Некоторые действия не нуждаются в заполнении определенных колонок (параметры поиска или значения), в таком случае неиспользуемые колонки будут недоступны для редактирования и помечены серым цветом – это, кстати, облегчает жизнь, когда путаешь что и куда ввести.
Единственная сложность, которая может возникнуть при составлении тестов – это определение критерия поиска. В списке представлены 5 видов критериев: id, class, name, xpath и css. Критерии – это способы добраться до атрибута, с которым нужно совершить действие, лично я выбираю xpath и прописываю его в колонке «параметры поиска» и не морочусь, но многие считают это мазохизмом, когда у элемента есть id, но тут уж каждому свое.
Когда редактирование теста закончено, предстоит выбрать браузер, в котором будут выполняться тесты. Одна из замечательных особенностей приложения в том, что можно запустить тест в 4 браузерах! Правда тесты будут выполняться последовательно, т.е. браузер за браузером, но информация о поведении приложения в разных браузерах будет получена.
Стоит обратить внимание, что перед использованием всех браузеров, кроме firefox, нужно прописать драйвера в системных переменных, либо закинуть эти драйвера в папку с приложением.
После всех указанных выше процедур, нажимаем на кнопку «Выполнить» и наслаждаемся, программа делает работу за нас. На этом можно было бы закончить, ведь все уже итак работает, но не тут – то было. Приложение не такое примитивное, как кажется на первый взгляд.
Шаги и элементы
Следующей интересной особенностью при создании автотеста – создание списка часто используемых шагов и элементов. Этот список нужен для упрощения написания сценария.
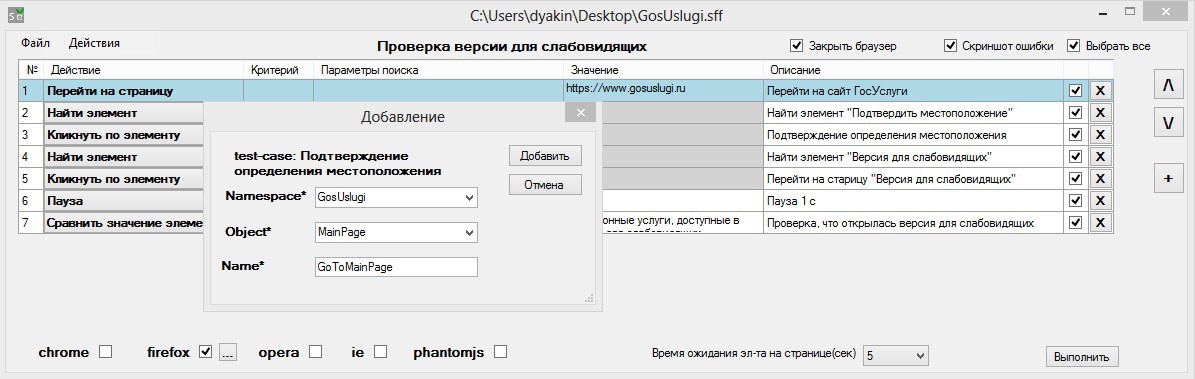
Допустим есть действие, которое регулярно совершается (переход на главную страницу приложения), разумно внести это действие в список часто использующихся и в дальнейшем не прописывать его, а просто вызывать из этого списка (оптимизация!). Список шагов можно редактировать (однако редактировать можно только поле «значение» и «описание», все остальные параметры недоступны).
Список часто используемых элементов, по аналогии со списком шагов, нужен для быстрого доступа к элементам, используемым регулярно. В отличие от шагов, все поля элемента можно редактировать.
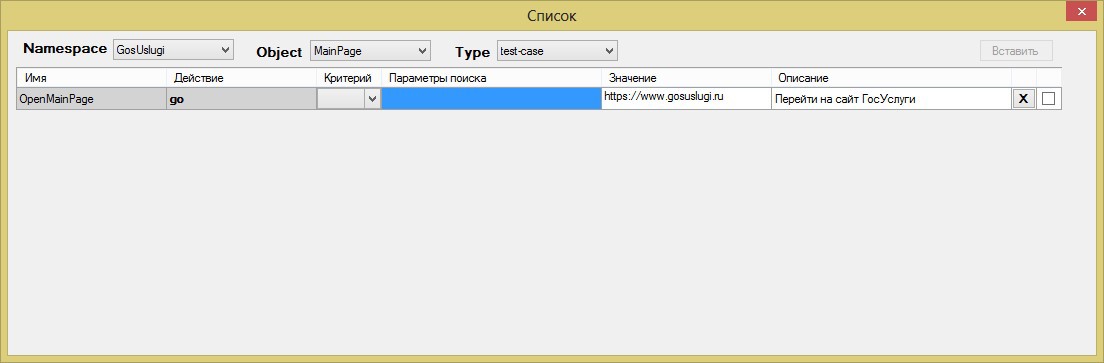
Для редактирования списков есть специальная форма «Изменить список/вставить из списка», попасть в которую можно из меню «Действия».
Переменные
Еще одной «фишечкой» можно считать использование переменных. Об удобстве использовании переменных в программировании должен знать даже начинающий тестировщик.

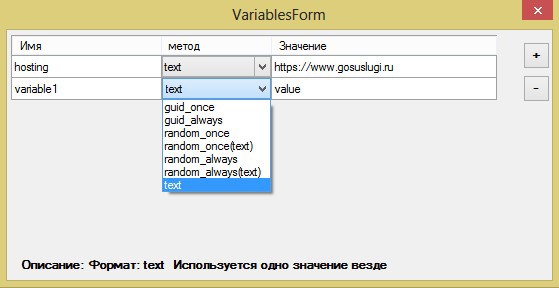
Ввод переменной в структуру теста осуществляется с помощью знаков $variable$

Переменные, кстати, используются разные. Можно выбрать один из 7 представленных методов.
• Guid_once – генерация случайного значение в формате guid. Генерируется один раз и используется при вызове переменной везде одно и то же• Guid_always — генерация случайного значение в формате guid. При вывозе переменной генерируется каждый раз разный guid.
• Random_once – выбор случайного значения в диапазоне указанного минимума и максимуму. Используется одно значение везде
• Random_once(text) — выбор случайного значения из указанных в одноименном столбце. Значения указываются через точку с запятой. Используется одно значение везде
• Random_always — выбор случайного значения в диапазоне указанного минимума и максимуму. Значение меняется при каждом вызове
• Random_always(text) – выбор случайного значения из указанных в одноименном столбце. Значения указываются через точку с запятой. Значение меняется при каждом вызове
• Text – выбор зафиксированного значения.
Стоит обратить внимание, что при выполнении теста в разных браузерах у переменных guid_once и random_once будут генерироваться в каждом браузере свои.
В этой статье рассматривается создание достаточного простого автотеста. Статья будет полезна начинающим автоматизаторам.
Материал изложен максимально доступно, однако, будет значительно проще понять о чем здесь идет речь, если Вы будете иметь хотя бы минимальные представления о языке Java: классы, методы, etc.
- установленная среда разработки Intellij IDEA (является самой популярной IDE, для большинства случаев достаточно бесплатной версии Community Edition);
- установленные Java (jdk/openjdk) и Maven, прописанные в системные окружения ОС;
- браузер Chrome и chromedriver — программа для передачи команд браузеру.
Создание проекта
Запустим Intellij IDEA, пройдем первые несколько пунктов, касающихся отправки статистики, импорта проектов, выбора цветовой схемы и т.д. — просто выберем параметры по умолчанию.
В появившемся в конце окне выберем пункт «Create New Project», а в нем тип проекта Maven. Окно будет иметь вид:

- Maven — это инструмент сборки Java проектов;
- Project SDK — версия Java, которая установлена на компьютере;
- Create from archetype — это возможность создавать проект с определенным архетипом (на данном этапе данный чекбокс отмечать не нужно).
Нажмем «Next». Откроется следующее окно:

Groupid и Artifactid — идентификаторы проекта в Maven. Существуют определенные правила заполнения этих пунктов:
- Groupid — название организации или подразделения занимающихся разработкой проекта. В этом пункте действует тоже правило как и в именовании пакетов Java: доменное имя организации записанное задом наперед. Если у Вас нет своего доменного имени, то можно использовать свой э-мейл, например com.email.email;
- Artifactid — название проекта;
- Version — версия проекта.
Нажмем «Finish»: IDE автоматически откроет файл pom.xml:

В нем уже появилась информация о проекте, внесенная на предыдущем шаге: Groupid, Artefiactid, Version. Pom.xml — это файл который описывает проект. Pom-файл хранит список всех библиотек (зависимостей), которые используются в проекте.

Выберем нужную версию (в примере будет использована версия 3.14.0). Откроется страница:

Копируем содержимое блока «Maven» и вставим в файл pom.xml в блок
Таким образом библиотека будет включена в проект и ее можно будет использовать. Аналогично сделаем с библиотекой Junit (будем использовать версию 4.12).

Создание пакета и класса
Раскроем структуру проекта. Директория src содержит в себе две директории: «main» и «test». Для тестов используется, соответственно, директория «test». Откроем директорию «test», кликом правой клавиши мыши по директории «java» выберем пункт «New», а затем пункт «Package». В открывшемся диалоговом окне необходимо ввести название пакета. Имя базового пакета должно носить тоже имя, что и Groupid — «org.example».
Следующий шаг — создание класса Java, в котором пишется код автотеста. Кликом правой клавиши мыши по названию пакета выберем пункт «New», а затем пункт «Java Class».
В открывшемся диалоговом окне необходимо ввести имя Java класса, например, LoginTest (название класса в Java всегда должно начинаться с большой буквы). В IDE откроется окно тестового класса:

Настройка IDE
Прежде чем начать, необходимо настроить IDE. Кликом правой клавиши мыши по названию проекта выберем пункт «Open Module Settings». В открывшемся окне во вкладке «Sources» поле «Language level» по умолчанию имеет значение 5. Необходимо изменить значение поля на 8 (для использования всех возможностей, присутствующих в этой версии Java) и сохранить изменения:

Далее необходимо изменить версию компилятора Java: нажмем меню «File», а затем выберем пункт Settings.
В открывшемся перейдем «Build, Execution, Deployment» -> «Compiler» -> «Java Compiler». По умолчанию установлена версия 1.5. Изменим версию на 8 и сохраним изменения:

Test Suite
- Пользователь открывает страницу аутентификации;
- Пользователь производит ввод валидных логина и пароля;
- Пользователь удостоверяется в успешной аутентификации — об этом свидетельствует имя пользователя в верхнем правом углу окна;
- Пользователь осуществляет выход из аккаунта путем нажатия на имя пользователя в верхнем правом углу окна с последующим нажатием на кнопку «Выйти…».
Тест считается успешно пройденным в случае, когда пользователю удалось выполнить все вышеперечисленные пункты.
Для примера будет использоваться аккаунт Яндекс (учетная запись заранее создана вручную).
Первый метод
В классе LoginTest будет описана логика теста. Создадим в этом классе метод «setup()», в котором будут описаны предварительные настройки. Итак, для запуска браузера необходимо создать объект драйвера:
WebDriver driver = new ChromeDriver();
Перед созданием объекта WebDriver следует установить зависимость, определяющую путь к chomedriver (в ОС семейства Windows дополнительно необходимо указывать расширение .exe):
Чтобы ход теста отображался в полностью открытом окне, необходимо сказать об этом драйверу:
Случается, что элементы на страницах доступны не сразу, и необходимо дождаться появления элемента. Для этого существуют ожидания. Они бывают двух видов: явные и неявные. В примере будет использовано неявное ожидание Implicitly Wait, которое задается вначале теста и будет работать при каждом вызове метода поиска элемента:
Таким образом, если элемент не найден, то драйвер будет ждать его появления в течении заданного времени (10 секунд) и шагом в 500 мс. Как только элемент будет найден, драйвер продолжит работу, однако, в противном случае тест упадем по истечению времени.
Для передачи драйверу адреса страницы используется команда:
Выносим настройки
Для удобства вынесем название страницы в отдельный файл (а чуть позже и некоторые другие параметры).
Создадим в каталоге «test» еще один каталог с названием «resources», а в нем обычный файл «conf.properties», в который поместим переменную:
а также внесем сюда путь до драйвера

В пакете «org.example» создадим еще один класс «ConfProperties», который будет читать записанные в файл «conf.properties» значения:

Обзор первого метода

Метод «setup()» пометим аннотацией Junit «@BeforeClass», которая указывает на то, что метод будет выполняться один раз до выполнения всех тестов в классе. Тестовые методы в Junit помечаются аннотацией Test.
Page Object
При использовании Page Object элементы страниц, а также методы непосредственного взаимодействия с ними, выносятся в отдельный класс.
Создадим в пакете «org.example» класс LoginPage, который будет содержать локацию элементов страницы логина и методы для взаимодействия с этими элементами.
В результате мы увидим этот элемент среди множества других. Теперь мы можем скопировать его локацию. Для этого кликаем правой кнопкой мыши по выделенному в панели разработчика элементу, выбираем меню «Copy» -> «Copy XPath».
Для локации элементов в Page Object используется аннотация @FindBy.
Напишем следующий код:
@FindBy(xpath = "//*[@id="root"]/div/div/div[2]/div/div/div[3]/div[2]/div/div/div[1]/form/div[1]/div[1]/label") private WebElement loginField;
Таким образом мы нашли элемент на страницу и назвали его loginField (элемент доступен только внутри класса LoginPage, т.к. является приватным).
Однако, такой длинный и страшный xpath использовать не рекомендуется (рекомендую к прочтению статью «Не так страшен xpath как его незнание». Если присмотреться, то можно увидеть, что поле ввода логина имеет уникальный id:

Воспользуемся этим и изменим поиск элемента по xpath:
@FindBy(xpath = "//*[contains(@id, 'passp-field-login')]")
Теперь вероятность того, что поле ввода пароля будет определено верно даже в случае изменения местоположения элемента на странице, возросла.
Аналогично изучим следующие элементы и получим их локаторы.
@FindBy(xpath = "//*[contains(text(), 'Войти')]") private WebElement loginBtn;
Поле ввода пароля:
@FindBy(xpath = "//*[contains(@id, 'passp-field-passwd')]") private WebElement passwdField;
А теперь напишем методы для взаимодействия с элементами.
Метод ввода логина:
public void inputLogin(String login)
Метод ввода пароля:
public void inputPasswd(String passwd)
Метод нажатия кнопки входа:
public void clickLoginBtn()
Для того, чтобы аннотация @FindBy заработала, необходимо использовать класс PageFactory. Для этого создадим конструктор и передадим ему в качестве параметра объект Webdriver:
public WebDriver driver; public LoginPage(WebDriver driver)

package org.example; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.support.FindBy; import org.openqa.selenium.support.PageFactory; public class LoginPage < /** * конструктор класса, занимающийся инициализацией полей класса */ public WebDriver driver; public LoginPage(WebDriver driver) < PageFactory.initElements(driver, this); this.driver = driver; >/** * определение локатора поля ввода логина */ @FindBy(xpath = "//*[contains(@id, 'passp-field-login')]") private WebElement loginField; /** * определение локатора кнопки входа в аккаунт */ @FindBy(xpath = "//*[contains(text(), 'Войти')]/..") private WebElement loginBtn; /** * определение локатора поля ввода пароля */ @FindBy(xpath = "//*[contains(@id, 'passp-field-passwd')]") private WebElement passwdField; /** * метод для ввода логина */ public void inputLogin(String login) < loginField.sendKeys(login); >/** * метод для ввода пароля */ public void inputPasswd(String passwd) < passwdField.sendKeys(passwd); >/** * метод для осуществления нажатия кнопки входа в аккаунт */ public void clickLoginBtn() < loginBtn.click(); >>
После авторизации мы попадаем на страницу пользователя. Т.к. это уже другая страница, в соответствии с идеологией Page Object нам понадобится отдельный класс для ее описания. Создадим класс ProfilePage, в котором определим локаторы для имени пользователя (как показателя успешного входа в учетную запись), а также кнопки выхода из аккаунта. Помимо этого, напишем методы, которые будут получать имя пользователя и нажимать на кнопку выхода.
Итого, страница будет иметь следующий вид:

package org.example; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.support.FindBy; import org.openqa.selenium.support.PageFactory; public class ProfilePage < /** * конструктор класса, занимающийся инициализацией полей класса */ public WebDriver driver; public ProfilePage(WebDriver driver) < PageFactory.initElements(driver, this); this.driver = driver; >/** * определение локатора меню пользователя */ @FindBy(xpath = "//*[contains(@class, 'account__name_hasAccentLetter')]") private WebElement userMenu; /** * определение локатора кнопки выхода из аккаунта */ @FindBy(xpath = "//*[contains(@class, 'menu-item_action_exit menu__item menu__item_type_link')]") private WebElement logoutBtn; /** * метод для получения имени пользователя из меню пользователя */ public String getUserName() < String userName = userMenu.getText(); return userName; >/** * метод для нажатия кнопки меню пользователя */ public void entryMenu() < userMenu.click(); >/** * метод для нажатия кнопки выхода из аккаунта */ public void userLogout() < logoutBtn.click(); >>
Интересный момент: в метод getUserName() пришлось добавить еще одно ожидание, т.к. страница «тяжелая» и загружалась довольно медленно. В итоге тест падал, потому что метод не мог получить имя пользователя. Метод getUserName() с ожиданием:
Вернемся к классу LoginTest и добавим в него созданные ранее классы-страницы путем объявления статических переменных с соответствующими именами:
public static LoginPage loginPage; public static ProfilePage profilePage;
Сюда же вынесем переменную для драйвера
public static WebDriver driver;
В аннотации @BeforeClass создаем экземпляры классов созданных ранее страниц и присвоим ссылки на них. Создание экземпляра происходит с помощью оператора new. В качестве параметра указываем созданный перед этим объект driver, который передается конструкторам класса, созданным ранее:
loginPage = new LoginPage(driver); profilePage = new ProfilePage(driver);
А создание экземпляра драйвера приведем к следующему виду (т.к. он объявлен в качестве переменной):
driver = new ChromeDriver();
Теперь можно перейти непосредственно к написанию логики теста. Создадим метод loginTest() и пометим его соответствующей аннотацией:
Осталось лишь корректно все завершить. Создадим финальный метод и пометим его аннотацией @AfterClass (методы помеченные этой аннотацией выполняются один раз, после завершения всех тестовых методов класса).
В этом методе осуществляется вход в меню пользователя и нажатие кнопки «Выйти», чтобы разлогиниться.
От автора: статья дает обзор концепций, технологий и техник программирования, связанных с автоматическим запуском тестов под управлением WebDriverJS на Windows 10 и Microsoft Edge. Ручное прокликивание разных браузеров, пока они запускают ваш код, локально или удаленно – быстрый способ проверить код. Так можно визуально проверить, что все работает ровно так, как вы предполагали с точки зрения макета и функциональности. Тем не менее, это не решение для тестирования полного кода сайта во всех браузерах и на всех типах устройств, доступных клиентов. Здесь нам поможет автоматизированное тестирование WebDriver API.
Автоматизированное веб-тестирование, возглавляемое проектом Selenium, представляет собой набор инструментов для авторизации, управления и запуска тестов в браузерах на разных платформах.
WebDriverJS API Link
WebDriver API – стандарт, который абстрагирует специфические привязки устройств/браузеров от разработчика, чтобы написанные вами тесты (на выбранном вами языке) можно было один раз написать и запускать в нескольких разных браузерах через WebDriver. В некоторые браузеры уже встроены возможности WebDriver, для других необходимо загружать исполняемый файл для пары браузер/ОС.

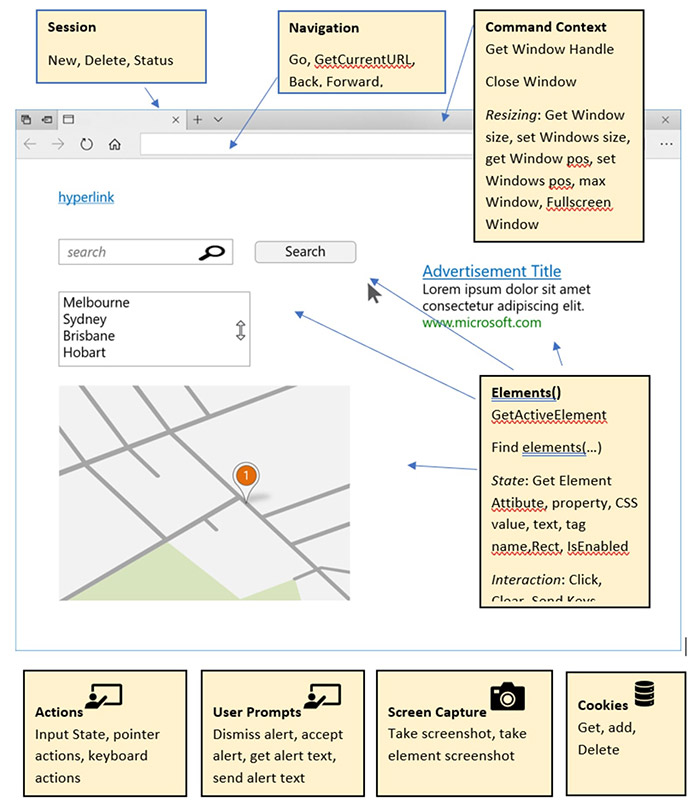
Управление браузером через WebDriver API
В спецификации WebDriver на W3C задокументированы API, доступные разработчикам для программного управления браузером. На рисунке ниже показан пример страницы с основными коллекциями WebDriver и API, с помощью которых можно получать/устанавливать свойства браузера.

JavaScript. Быстрый старт
Изучите основы JavaScript на практическом примере по созданию веб-приложения
Написание тестов
У вас есть выбор из поддерживаемых языков в WebDriver. Языки, поддерживаемые главным проектом Selenium/WebDriverJS:
JavaScript (via Node)
Тесты могут быть разные: от проверки макета страницы, возвращаемых с сервера значений, ожидаемого поведения при взаимодействии до проверки рабочего потока (например, проверка корректности работы корзины).
Позже мы сможем продемонстрировать запуск тестов для React примера и примеров Backbone.js и Vue.js простой сменой URL.
Для демонстрации мы напишем тесты на JS, запускаемые на узле, которые:
Добавят элементы to-do и проверят, что введенный элементы создались.
Изменят элементы с помощью двойного клика, нажатия клавиши backspace и ввода дополнительного текста.
Удалят элемент через API мыши.
Пометят элемент списка, как выполненный.
Настройка базового окружения для автоматизированного тестирования
Начнем с настройки машины на Windows 10 под запуск WebDriver через JS. Вызовы WebDriver с машины почти всегда будут асинхронные. Чтобы код было легче читать, мы использовали ES2016 async/await, а не Promises или колбеки.
Вам понадобится install node.js новее v7.6 или Babel для кросскомпиляции для поддержки функции async/await. Редактирование и отладку кода будем выполнять в Visual Studio Code.
WebDriverJS для Microsoft Edge
У каждого браузера будет бинарный файл, который должен будет храниться локально для взаимодействия с браузером. Этот бинарный файл будет вызываться вашим кодом через Selenium WebDriver API. Последние загрузки и документацию для Microsoft Edge WebDriver можно найти по ссылке.
Версия Edge, под которой вы хотите запускать тесты, должна совпадать с версией MicrosoftWebDriver.exe. Мы будем использовать стабильную версию Edge (16.16299) с соответствующим файлом MicrosoftWebDriver.exe версии 5.16299.
Поместите MicrosoftWebDriver.exe в папку, из которой будет запускаться тест. Если запустить бинарный файл, откроется окно консоли с URL и портом, через который WebDriverJS будет обрабатывать посылаемые запросы.
WebDriverJS для других браузеров
WebDriverJS легко может запускать другой браузер, если установить конфиг переменную и скачать подходящий бинарный драйвер для браузера. Найти все можно здесь:
Apple Safari: Вместе с Safari 10+
Microsoft Internet Explorer: IEDriver для Selenium project
Selenium WebDriverJS для JavaScript
Чтобы взаимодействовать с только что скачанным через JS бинарным файлом, необходимо установить библиотеку автоматизации Selenium WebDriver. Ее можно легко установить как node пакет:






Что пишут в блогах

Онлайн-тренинги
Что пишут в блогах (EN)
Разделы портала
Про инструменты
На конференции SeleniumCamp, состоявшейся в Киеве в феврале 2010 года, я проводил мастер-класс по оптимизации скорости выполнения тестов, разработанных с использованием инструмента Selenium. И самый первый совет, который я дал, вовсе не касается оптимизации самих тестов. Я предложил обратить внимание на то, как запускается браузер, потому что при неудачной конфигурации время, которое тратится на запуск и останов браузера может на порядок превышать “полезное” время выполнения тестов.
Да, при проектировании тестов для автоматизации есть некоторые особенности, тесты надо строить иначе, чем для ручного выполнения. Но иногда тестировщику автоматизатору приходится думать не только о том, как спроектировать тесты, но и об инфраструктуре для их выполнения. И механизм запуска браузера при автоматизации тестирования веб-приложений является важным элементом этой инфраструктуры.
Я разработал для себя универсальный механизм запуска браузера для инструмента Selenium, который позволяет достаточно гибко управлять различными способами использования браузера в зависимости от потребностей – один браузер на все тесты либо перезапуск перед каждым тестовым методом, автоматический останов браузера после завершения выполнения тестов, автоматический перезапуск браузера при сбоях или после заданного количества использований, а также в случае переключения на другой тип браузера или другой Selenium-сервер, чтение параметров запуска из конфигурационного файла или передача параметров из программного кода.
Но прежде чем рассказать про реализацию этого механизма и отдать его в широкое использование, я хочу изложить свою точку зрения на очень важный, как мне кажется, вопрос:
Как правильно запускать браузер?
При рассмотрении будем учитывать следующие характеристики тестового набора:
- производительность – общее время выполнения всех тестов,
- устойчивость к сбоям тестов – возможность продолжения выполнения тестов после сбоя отдельного теста,
- устойчивость к сбоям браузера – возможность продолжения выполнения тестов после сбоя браузера,
- простота локализации дефектов.
Мы оце ним относительно этих характеристик по пятибалльной шкале, а потом построим интегральную оценку для следующих способов запуска браузера:
- отдельный браузер для каждого теста,
- общий браузер для группы тестов,
- общий браузер для всех тестов.
Конечно, первый и третий способы можно считать просто частными случаями более общего второго способа – в первом случае каждая группа состоит из единственного теста, а в третьем случае у нас есть одна большая группа, включающая в себя все тесты. Но я хочу показать, что в данном случае оптимальными являются как раз не эти крайние случаи.
Поэтому правильно было бы поставить вопрос следующим образом: какого размера должны быть группы тестов, для каждой из которых запускается отдельный браузер, чтобы достигалось оптимальное соотношение вышеперечисленных характеристик.
Производительность
Очевидно, что запуск отдельного браузера для каждого теста – это наихудший способ с точки зрения производительности.
На машине, где я сейчас пишу статью, Selenium тратит от 10 до 30 секунд на то, чтобы запустить браузер Firefox 4. При этом тесты я делаю достаточно мелкими, так что среднестатистический тест выполняется не более 10 секунд. То есть “чистое” время выполнения тестов составляет в лучшем случае не более 50%, а в худшем – менее 25% общего времени выполнения тестового набора.
Это же просто расточительство какое-то! За то же время можно было бы выполнить в 4 раза больше тестов без увеличения мощности тестового стенда!
Вы можете спросить – почему браузер так долго стартует? Полминуты это слишком много для современного браузера. Это правда. Однако дело в том, что Selenium сначала готовит для браузера чистый временный профиль, и только потом запускает браузер с этим профилем. Именно эта процедура подготовки профиля занимает так много времени, особенно если учесть, что я обычно предпочитаю иметь в этом профиле пару-тройку полезных для отладки тестов плагинов, таких как Firebug и Web Developer Toolbar. После того, как профиль подготовлен, достаточно быстро стартует браузер, потом в нем столь же быстро выполняются тесты, а затем браузер останавливается, профиль удаляется и надо всё начинать сначала.
Ещё один источник снижения производительности – лишние действия по подготовке тестовой ситуации, которые нужно выполнить после запуска браузера, такие как, например, вход в систему (login) и переход на нужную страницу, при выполнении тестов без перезапуска браузера эти действия если не полностью исчезают, то хотя бы минимизируются. Для медленно работающего приложения это время может быть не меньше, чем время старта браузера.
В общем, этот способ за производительность получает твёрдый кол, то есть единицу.
Полной противоположностью ему является использование одного браузера для всех тестов. Все лишние действия сведены к минимуму. Профиль браузера формируется один раз в самом начале. Если удачно определить порядок выполнения тестов, можно сократить количество действий по входу в систему и выходу из неё (логинимся, выполняем все тесты для одной роли, потом выходим, логинимся с другой ролью, выполняем тесты для неё, и так далее). Иногда можно даже избавиться от “холостых” проходов, если следующий тест начинает выполнение на той странице, на которой завершился предыдущий.
Короче говоря, здесь с производительностью всё хорошо, однозначно высший балл.
Если теперь обратиться к общему случаю, можно сделать вывод, что производительность падает с уменьшением размера группы – чем чаще приходится перезапускать браузер, тем больше на это уходит времени и тем сильнее увеличивается общее время выполнения тестов.
Ставим условно тройку, но помним, что при уменьшении количества тестов в группе она может превратиться в двойку, а при увеличении – в четверку.
И тогда возникает закономерный вопрос – стоит ли делать маленькие группы? Что мы получаем в качестве компенсации за снижение производительности? Давайте посмотрим на другие характеристики, может быть они помогут дать ответ на этот вопрос.
Устойчивость к сбоям тестов
Под “сбоем” теста я подразумеваю здесь такую ситуацию, когда тест после своего завершения оставил сиситему не в том состоянии, в котором ожидал тестировщик, а в некотором другом. Например, тестировщик предполагал, что все тесты будут завершаться возвратом на главную страницу приложения, и поэтому спроектировал тесты исходя из этого предположения. Если теперь некоторый тест после завершения не вернется на главную страницу, у последующих тестов могут возникнуть проблемы, поскольку предусловие для их выполнения нарушено, появляются так называемые “наведенные ошибки”.
Да, иногда “сбои” являются следствием неуспешного завершения теста (test failed) вследствие ошибки в тестируемом приложении или в самом тесте. При этом тест не отрабатывает до конца, его выполнение обрывается где-то посредине и тест “бросает” систему в каком-то промежуточном состоянии.
Но может быть и так, что тест отрабатывает до конца, все проверки, которые тестировщик счел нужным запрограммировать, проходят успешно, но результирующее состояние системы всё таки отличается от ожидаемого (просто тест не содержит соответствующих проверок и это остается незамеченным). Такую ситуацию я также буду называть “сбоем теста”.
По устойчивости к сбоям тестов способ запуска отдельного браузера для каждого теста показывает замечательные результаты – восстановление исходного состояния гарантировано, независимо от того, как завершился предыдущий тест.
Однако высшую оценку мы ему не поставим, ограничимся четверкой, потому что гарантии распространяются только на клиенсткую часть. Если тест оставил в “плохом” состоянии сервер, перезапуск браузера, увы, не поможет.
Поэтому тестировщику всё равно нужно думать о том, как аккуратно выполнить зачистку независимо от успешности или неуспешности завершения теста.
А ещё лучше – спроектировать тесты так, чтобы у них не было предусловий, чтобы они могли стартовать из любого состояния, чтобы каждый тест пытался самостоятельно привести систему в нужное состояние перед началом выполнения основной части теста.
И тогда становится ясно, что перезапускать браузер не нужно, нет необходимости переинициализировать систему, тесты сами позаботятся о создании для себя подходящих условий. Если тесты сами по себе устойчивы к сбоям, тогда теряется главное преимущество способа запуска каждого теста в своем браузере.
Таким образом, второму и третьему способу поставим оценку условно – если тесты спроектированы хорошо, тогда они тоже получают четверку, а для плохих тестов, которым требуется изоляция, эти способы оценим на два балла по устойчивости к сбоям тестов.
Устойчивость к сбоям браузера
Здесь опять некоторое преимущество имеет способ запуска отдельного браузера для каждого теста – если браузер “зависнет” или “упадет”, это окажет негативное влияние только на единственный тест, который выполнялся в этом браузере.
Проблемы могут подстерегать тестировщика в случае, если браузер “зависает” слишком часто, тогда количество неработающих, но не завершившихся процессов будет возрастать, что вскоре приведет к полной неработоспособности компьютера, на котором выполняются тесты. Но на практике такая ситуация встречается крайне редко, поэтому даже не будем снижать за это балл, поставим высшую оценку.
А что будет, если все тесты или группа тестов должны выполняться в одном экземпляре браузера, а он “упал”?
Всё зависит, как и в предыдущем разделе, от того, насколько хорошо спроектированы тесты с точки зрения наличия предусловий. Если тесты могут продолжить выполнение из любого состояния, достаточно просто перезапустить браузер после сбоя, так что пострадает только единственный тест, на котором браузер “упал”.
Следовательно, оценка опять получается условная – если тесты спроектированы правильно, и если имеется механизм перезапуска браузера после падения, второй и третий способы тоже становятся идеально устойчивы к сбоям браузера и тоже получают пятерку. Ну а если тесты не могут продолжить выполнение после перезапуска браузера, тогда способ запуска всех тестов в одном браузере получает единицу, а выделение отдельного браузера для группы тестов в зависимости от размера группы получает оценку от 2 до 4 баллов, потому поставим условную тройку.
Простота локализации обнаруженных дефектов
И вновь способ запуска отдельного браузера для каждого теста в небольшом выигрыше, и для этого есть целых две причины.
Во-первых, для локализации дефекта иногда требуется несколько раз повторно прогнать тест, чтобы понять причину дефекта. Конечно, проще всего это сделать при условии, что выполнять нужно ровно один тест, а не целую группу. Но как и ранее, если тесты спроектированы так, что могут выполняться не только в группе, но и каждый по отдельности – проблема исчезает. Даже если тест “провалился” в составе группы, ничто не мешает впоследствии выполнить его несколько раз в изоляции. Так что опять оценка зависит от того, насколько хорошо написаны тесты, поэтому поставим равные оценки – троечки, потому что локализация дефектов для тестов на уровне пользовательского интерфейса вообще штука достаточно трудоемкая.
Во-вторых, иногда бывает так, что для локализации дефекта всё таки нужно выполнять группу тестов целиком, потому что при выполнении в составе группы тест завершается неуспешно, а если его выполнить в изоляции – всё работает без ошибок. Программисты не любят такие дефекты, их локализация сложна, для воспроизведения нужно прогонять целую серию тестов, а через пользовательский интерфейс они выполняются медленно.
Но давайте взглянем на это с другой стороны – это же замечательно, что такой дефект вообще удалось обнаружить! Если бы все тесты выполнялись в изоляции, мы бы вообще не имели шанса выявить проблему, которая является следствием влияния одной тестируемой функции на другую. Так что это отнюдь не минус, а очень даже жирный плюс! Поэтому оценку снижать не будем.
Подведение итогов
Итак, давайте посмотрим, каких оценок удостоились наши три способа запуска тестов. В представленной ниже таблице в качестве основных оценок указаны те, которые получены при “правильном проектировании тестов”, а в скобках указана оценка для “плохо спроектированных тестов”.
| Все тесты вместе | Группы тестов | Каждый тест отдельно | |
| Производительность | 5 | 3 | 1 |
| Устойчивость к сбоям тестов | 4 (1) | 4 (2) | 4 |
| Устойчивость к сбоям браузера | 5 (1) | 5 (3) | 5 |
| Простота локализации дефектов | 3 | 3 | 3 |
Какие выводы можно сделать из представленной сравнительной таблицы?
- Первый и самый главный вывод – тесты надо проектировать правильно :) , чтобы их можно было использовать с любым из способов запуска браузера.
- Если выполнено условие, упомянутое в первом пункте, лучше все тесты запускать в одном браузере, не изолировать их друг от друга, это обеспечивает существенно более высокую скорость выполнения тестов благодаря отсутствии накладных расходов на перезапуск браузера.
- При удачном (или неудачном? нет, всё таки удачном) стечении обстоятельств отсутствие изоляции позволяет найти трудноуловимые дефекты, связанные с особенностями взаимодействия тестируемых функций при их последовательном использовании.
Что же представляют собой “правильно спроектированные тесты”, какими особенностями должны обладать тесты и/или тестовый фреймворк, чтобы обеспечить возможность выполнения тестов как в изоляции, так и в составе произвольной группы?
- Тесты не должны иметь предусловий. Если для выполнения теста необходимо создать определенную тестовую ситуацию, тест должен сам позаботиться об этом, не полагаясь на то, что это сделают ранее выполненные тесты.
- Необходим механизм отслеживания состояния браузера и перезапуска в случае сбоя. Этим должен, конечно, заниматься фреймворк, а не тесты.
- Необходим механизм принудительного перезапуска браузера по требованию теста – если тест не может создать нужную ситуацию без перезапуска браузера, нужно дать ему последний шанс.
Так что же, неужели всегда лучше выполнять все тесты в одном браузере? Бывают ли ситуации, когда “правильнее” запускать тесты небольшими группами или даже выделять отдельный браузер для каждого теста? Конечно бывают, но я хочу подчеркнуть, что эти потребности не связаны с устойчивостью к сбоям и простотой локализации тестов, с теми “причинами”, которые я чаще всего встречал в блогах и статьях в качестве обоснования необходимости изоляции тестов.
Вот несколько причин выделения отдельного браузера для группы тестов, с которыми мне приходилось сталкиваться в своей практике (список, конечно, не претендует на полноту):
- параллельный запуск, каждая группа выполняется в своем браузере,
- запуск в разных браузерах или в одном и том же браузере, но с разными настройками – группа тестов выполняется сначала в одном браузере, потом в другом (да, можно решить это и другим способом – либо разные браузеры работают параллельно, либо сначала все тесты выполняются в одном браузере, потом в другом, но иногда требуется и выполнение сначала полностью одной группы, а потом переход к другой),
- профилактика сбоев браузера – например, Firefox знаменит тем, что при выполнении большого количества тестов он захватывает много оперативной памяти (вероятно, из-за наличия “утечек”), начинает работать медленнее и может совсем “упасть”, поэтому его необходимо периодически перезапускать,
- необходимость эмуляции “нового пользователя”, который никогда ранее не заходил на сайт и не пользовался приложением (можно пытаться чистить куки и кеш, но проще перезапустить браузер),
На этом теоретическая часть закончена, вторая часть статьи будет содержать описание (и реализацию) универсального механизма запуска браузера, который годится для любого способа, умеет отслеживать состояние браузера и автоматически перезапускать его, а также обеспечивает возможность перезапуска браузера по требованию.
Читайте также: