
Дан файл с таблицей в формате tsv с информацией о росте школьников разных классов

Теперь у нас есть ссылка типа:
Ссылка несет в себе уникальный идентификатор файла в системе Google Docs. Переход по такой ссылке откроет файл в режиме редактирования.* (*в данной статье приведены заведомо не рабочие ссылки, однако их структура корректна)
Теперь перейдем в FileMaker. Раз у нас есть ссылка на файл, то мы можем воспользоваться командой Insert From URL И тут у нас есть два варианта (в CampSoftware рассматривают только первый вариант, то мы рассмотрим также и более автоматизированный процесс):

Очевидно, что вариант с обработкой данных как единого теста выглядит не слишком производительным. Можно ли просто импортировать данные воспользовавшись Import Records? Конечно, можно. Для этого выполним команду Insert From URL применительно не к текстовому полю, а к полю-контейнер. В этом случае в поле запишется не содержимое файла TSV, а сам файл. Дальше все просто: импортируем полученный файл во временную папку FileMaker и выполняем команду Import Records из только что сохраненного файла.

Обращаем внимание, что в качестве котировки при импорте я указал UTF-8, иначе у нам могут быть проблемы с русскими символами.
Небольшой бонус:
Тем кто заинтересовался возможностью скачивания файлов из Google Docs , приведем основные поддерживаемые форматы, которые можно подставить в ссылку доступа:
Sheets: xlsx, pdf, tsv, csv, ods, and zip (a folder with the sheet as html).
Docs: docx, pdf, rtf, txt, odt, and zip (a folder with the sheet as html).
Slides: pptx, pdf, txt, png, jpg, and svg.

Подпишитесь на бесплатную почтовую рассылку по созданию видео.
В любой момент вы cможете отказаться от подписки, если она вас не устроит.
Популярные статьи

Свежие статьи
Современные телевизоры и ресиверы позволяют записывать телевизионные фильмы или программы в режиме отложенного просмотра. Эту возможность используют, когда интересный фильм транслируется в неудобное время. Телевизионный приемник запишет его, а пользователь может посмотреть в любое время.
Многие ТВ-приемники делают такие записи в видеофайл с расширением TSV (Time-Shifted Viewing - отложенный просмотр).
Некоторые пользователи пытаются скопировать эти видеофайлы и просмотреть на компьютере. В результате возникает проблема: компьютер видео не воспроизводит.
В такой ситуации люди обращаются в поиск Интернета и получают ответ, что TSV - формат электронных таблиц, а про видео информации практически нет.
Видео с расширением TSV - специальный контейнер, который разработан для телеприемников, а компьютеры его не понимают. Хотя видео, которое находится в контейнере, чаще всего имеет формат MPEG-4 (транспортный поток MPEG-4 TS).
Существует более общий случай расширения - TS, который является стандартным форматом для передачи и хранения аудио, видео и данных. Расширения имен файлов ТС являются .ts, TSV, .tsa.
Кроме спутникового или эфирного цифрового вещания файлы с таким расширением могут давать некоторые HD-видеокамеры, такие как Panasonic, Cannon, Sony и др.
К сожалению, все разновидности TS-файлов не совместимы с большинством медиаплееров, портативных устройств и программ для редактирования видео. Для того, чтобы свободно пользоваться файлами TS, нужно конвертировать их в другие более популярные форматы файлов.
Не все популярные конвертеры видео понимают TS-файлы, поэтому приходится заниматься поисками подходящей программы. Одним из таких конвертеров является:
Bigasoft Total Video Converter - конвертирует любые форматы видео (свыше 40 видео и аудио форматов) в MP4/ MKV/DivX/WMV/ AVI/MPEG/FLV/VOB и др. Программа платная, есть триальная версия.
Конвертер поддерживает стандарты видео DVD/SVCD/VCD, имеет собственный встроенный плеер для просмотра и прослушивания.
Total Video Converter работает на основе мощного алгоритма преобразования медиафайлов, благодаря чему конвертация совершается на очень высокой скорости.
Программа имеет понятный интерфейс с поддержкой русского языка и работа с ней не представлет никаких сложностей.
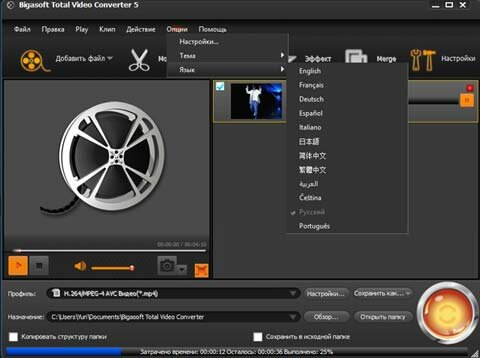
Кроме того, программа может редактировать видео, например, разрезать на части, удалить ненужное, ликвидировать черные края и пр.
Этот конвертер может выручить пользователя в случае, когда другие аналогичные кодировщики отказываются работать с каким-нибудь видеофайлом.
Теперь у нас есть ссылка типа:
Ссылка несет в себе уникальный идентификатор файла в системе Google Docs. Переход по такой ссылке откроет файл в режиме редактирования.* (*в данной статье приведены заведомо не рабочие ссылки, однако их структура корректна)
Теперь перейдем в FileMaker. Раз у нас есть ссылка на файл, то мы можем воспользоваться командой Insert From URL И тут у нас есть два варианта (в CampSoftware рассматривают только первый вариант, то мы рассмотрим также и более автоматизированный процесс):
Очевидно, что вариант с обработкой данных как единого теста выглядит не слишком производительным. Можно ли просто импортировать данные воспользовавшись Import Records? Конечно, можно. Для этого выполним команду Insert From URL применительно не к текстовому полю, а к полю-контейнер. В этом случае в поле запишется не содержимое файла TSV, а сам файл. Дальше все просто: импортируем полученный файл во временную папку FileMaker и выполняем команду Import Records из только что сохраненного файла.
Обращаем внимание, что в качестве котировки при импорте я указал UTF-8, иначе у нам могут быть проблемы с русскими символами.
Небольшой бонус:
Тем кто заинтересовался возможностью скачивания файлов из Google Docs , приведем основные поддерживаемые форматы, которые можно подставить в ссылку доступа:
Sheets: xlsx, pdf, tsv, csv, ods, and zip (a folder with the sheet as html).
Docs: docx, pdf, rtf, txt, odt, and zip (a folder with the sheet as html).
Slides: pptx, pdf, txt, png, jpg, and svg.
Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».
- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:

Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.

DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.

В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv() .
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:

затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…

…и назовем его zoo.csv!

Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:

Готово! Это файл zoo.csv , перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:

Если кликнуть на него…

…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
Данные загружены в pandas!

Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!

Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл .csv через URL напрямую. В этом случае данные не загрузятся на сервер данных.
Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!

Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:

Или последние 5 строк:

Или 5 случайных строк:

Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:

Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:

Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли 'SEO' значением колонки article_read.source ? Результат всегда будет булевым значением ( True или False ).

Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read .

Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2 . Выведите первые 5 строк!
А вот и решение!
Его можно преподнести одной строкой:
Или, чтобы было понятнее, можно разбить на несколько строк:
В любом случае, логика не отличается. Сначала берется оригинальный dataframe ( article_read ), затем отфильтровываются строки со значением для колонки country — country_2 ( [article_read.country == 'country_2'] ). Потому берутся три нужные колонки ( [['user_id', 'topic', 'country']] ) и в конечном итоге выбираются только первые пять строк ( .head() ).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
Читайте также: