
Что значит набрать в браузере
Простыми словами объясняем, как браузер подключается и общается с сервером.
Поэтому первым делом браузеру нужно понять, какой IP-адрес у сервера, на котором находится сайт.
Такая информация хранится в распределенной системе серверов — DNS (Domain Name System). Система работает как общая «контактная книга», хранящаяся на распределенных серверах и устройствах в интернете.
Однако перед тем, как обращаться к DNS, браузер пытается найти запись об IP-адресе сайта в ближайших местах, чтобы сэкономить время:
- Сначала в своей истории подключений . Если пользователь уже посещал сайт, то в браузере могла сохраниться информация c IP-адресом сервера.
- В операционной системе . Не обнаружив информации у себя, браузер обращается к операционной системе, которая также могла сохранить у себя DNS-запись. Например, если подключение с сайтом устанавливалось через одно из установленных на компьютере приложений.
- В кэше роутера , который сохраняет информацию о последних соединениях, совершенных из локальной сети.
Не обнаружив подходящих записей в кэше, браузер формирует запрос к DNS-серверам, расположенным в интернете.
Как только браузер узнал IP-адрес нужного сервера, он пытается установить с ним соединение. В большинстве случаев для этого используется специальный протокол — TCP.
TCP — это набор правил, который описывает способы соединения между устройствами, форматы отправки запросов, действия в случае потери данных и так далее.
Например, для установки соединения между браузером и сервером в стандарте TCP используется система «трёх рукопожатий». Работает она так:
- Устройство пользователя отправляет специальный запрос на установку соединения с сервером — называется SYN -пакет.
- Сервер в ответ отправляет запрос с подтверждением получения SYN-пакета — называется SYN/ACK -пакет.
- В конце устройство пользователя при получении SYN/ACK-пакета отправляет пакет с подтверждением — ACK -пакет. В этот момент соединение считается установленным.
Задача браузера — как можно подробнее объяснить серверу, какая именно информация ему нужна .
Сервер получил запрос от браузера с подробным описанием того, что ему требуется. Теперь ему нужно обработать этот запрос. Этой задачей занимается специальное серверное программное обеспечение — например, nginx или Apache. Чаще всего такие программы принято называть веб-серверами.
Когда ответ сформирован, он отправляется веб-сервером обратно браузеру. В ответе как правило содержится контент для отображения веб-страницы, информация о типе сжатия данных, способах кэширования, файлы cookie, которые нужно записать и так далее.
👉 Чтобы обмен данными был быстрым, браузер и сервер обмениваются сразу множеством небольших пакетов данных — как правило, в пределах 8 КБ. Все пакеты имеют специальные номера, которые помогают отслеживать последовательность отправки и получения данных. 8. Браузер обрабатывает полученный ответ и «рисует» веб-страницуБраузер распаковывает полученный ответ и постепенно начинает отображать полученный контент на экране пользователя — этот процесс называется рендерингом .
Сначала браузер загружает только основную структуру HTML-страницы. Затем последовательно проверяет все теги и отправляет дополнительные GET-запросы для получения с сервера различных элементов — картинки, файлы, скрипты, таблицы стилей и так далее. Поэтому по мере загрузки страницы браузер и сервер продолжают обмениваться между собой информацией.
Параллельно с этим на компьютер как правило сохраняются статичные файлы пользователя — чтобы при следующем посещении не загружать их заново и быстрее отобразить пользователю содержимое страницы.
Как только рендеринг завершен — пользователю отобразится полностью загруженная страница сайта.

На собеседованиях мы часто просим кандидата рассказать настолько подробно, насколько он может, что происходит, когда вводишь в адресной строке браузера адрес сайта и нажимаешь кнопку “Ввод”. В зависимости от того, кого собеседуем — фронтендщика или бекендщика — мы ожидаем разные ответы. А как бы выглядел идеальный ответ на этот вопрос? Ниже мой вариант ответа.
Итак, пользователь вводит в адресной строке браузера адрес сайта и нажимает кнопку “Ввод”.
Браузер состоит из нескольких компонентов, одним из которых является User Interface. Адресная строка как раз является одной из частей этого компонента.
User Interface после ввода URL в адресной строке передаёт управление компоненту Browser Engine, который отвечает за взаимодействие различных компонентов браузера.
Чтобы сделать запрос по указанному URL, браузеру нужно знать IP сервера. Первым делом он смотрим в свой локальный кэш DNS.Компонент Browser Engine как раз имеет доступ к этому кэшу.
Если там нет соответствующей записи, то браузер передаёт управление операционной системе, которая проверяет свой кэш DNS. Если и там отсутствует соответствующая запись, то ОС смотрит в локальные хосты (файл /etc/hosts в Unix-системах). Если запись о хосте отсутствует, то операционная система обращается к интернет провайдеру, у которого тоже есть свой кэш DNS на своих рекурсивных серверах DNS. В случае отсутствия записи в кэше на серверах DNS провайдера, запрос идёт на корневой DNS. У корневого DNS тоже есть кэш. Если соответствующей записи в кэше корневого DNS нет, запрос идёт дальше по цепочке серверов DNS.
Если на любом из этапов находится нужная запись, то она сохраняется во всех кэшах и управление возвращается браузеру, который уже знает IP нужного сервера.
Процесс получения IP адреса называется DNS lookup.
На сервере запрос принимает веб-сервер (например, nginx или apache).
В конфигурационных файлах веб-сервера прописаны обслуживаемые хосты. Веб-сервер достаёт хост из заголовка запроса host и сопоставляет с теми, которые указаны в конфигурации. Если есть совпадение, то веб-сервер находит в конфигурационном файле правила обработки такого запроса и выполняет их. Дальнейшее поведение сервера зависит от технологии и особенностей приложения. Здесь может происходить работа с базами данных, кэшами, запросы к другим серверам и сервисам, выполнение различных скриптов. Для простоты представим, что приложение сгенерировало файл HTML, и веб-сервер отдал его браузеру.
Заголовки ответа сервера можно увидеть в Chrome DevTools на вкладке Networking, выбрав нужный запрос
Если длина контента больше нуля и тип контента поддерживается браузером, то браузер пытается его обработать. В нашем случае браузер получает файл HTML с соответствующим заголовком Content-Type. Браузер начинает разбор (parsing) этого файла с первой инструкции, которой является инструкция <!DOCTYPE>. DOCTYPE указывает на версию HTML, чтобы браузер понимал, каким правилам следовать во время разбора (какие теги как обрабатывать).
Если DOCTYPE отсутствует, то браузер переключится в режим quirks mode и попытается разобрать документ HTML, однако многие элементы будут проигнорированы. Если указан корректный DOCTYPE, то браузер будет работать в standards mode и будет разбирать документ в соответствии с правилами той версии, которая указана в DOCTYPE.
Rendering Engine начинает разбор документа HTML.
Создаётся DOM (Document Object Model). В браузере этот объект доступен по ссылке, которая хранится в переменной document. У документа есть несколько состояний. Первое состояние — loading. Оно означает, что документ только начал формироваться.
Состояние документа хранится в переменной document.readyState.
Также создаётся объект styleSheets, который будет хранить все стили.
Все стили на странице доступны по ссылке, которая хранится в переменной document.styleSheets.
Любой файл — это набор байтов. Браузер берёт полученный набор байтов и преобразует их в символы по таблице символов в соответствии с кодировкой, которая была передана в заголовке Content-Type. В нашем примере это кодировка UTF-8.
Следующий процесс —разбивание текста на смысловые блоки (tokenization). Так браузер распознаёт теги <html>, <head> и проч., а также понимает, какие правила к какому тегу применять (например, поддерживаемые атрибуты).
Далее токены собираются в узлы (nodes). Эти узлы и сохраняются в DOM со всеми взаимными связями.
Во время разбора, если Rendering Engine встречает ссылку на внешний ресурс, то он передаёт команду загрузить этот ресурс компоненту Networking Component. Это может быть ссылка на стили, скрипты, картинки и т.п. Networking Component ставит все ресурсы в очередь на загрузку. Каждому ресурсу Networking Component присваивает приоритет.
Приоритеты ресурсов можно посмотреть в Chrome DevTools на вкладке Networking в колонке Priority.
Так, у HTML, CSS и шрифтов самый высокий приоритет. У изображений приоритет изначально низкий, но если Rendering Engine обнаружит, что изображение попадает в поле видимости (view port) пользователя, то повысит приоритет до среднего. Приоритет скрипта зависит от положения на странице и способа загрузки. У асинхронных скриптов (async/defer) низкий приоритет. У скриптов, которые в документе перед изображениями — высокий, у тех, что после хотя бы одного изображение — средний.
По возможности браузер пытается загружать ресурсы параллельно. Однако, он не может загружать параллельно более 6 ресурсов с одного домена.
Кроме того, когда Rendering Engine отдаёт команду компоненту Networking Component на синхронную загрузку стиля или скрипта, он останавливает разбор документа.
С загрузкой стилей происходит подобный процесс преобразования из байтов в Object Model (CSSOM): байты -> символы -> токены -> узлы -> CSSOM.
Немного иначе происходит загрузка скрипта. Вместо того, чтобы вернуть управление Rendering Engine’у, Networking Component . передаёт управление JavaScript Interpreter, который преобразует байты в исполняемый код: байты -> символы -> токены -> Abstract Syntax Tree (evaluating). Далее в работу вступает компилятор, который оптимизирует AST, кэширует некоторые участки кода, компилирует его на лету (JIT compilation) в исполняемый код и исполняет (executing). Однако исполняется скрипт только, когда готова CSSOM. До тех пор скрипт стоит в очереди на исполнение.
Во многих современных браузерах во время исполнения JavaScript в отдельном потоке продолжается сканирование документа на наличие ссылок на другие ресурсы и постановка ресурсов в очередь на скачивание (Speculative parsing).
Каждый этап разбора HTML, CSS и JS можно увидеть в Chrome DevTools во вкладке Performance
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут async, то он не останавливает разбор документа во время загрузки скрипта. Скрипт также станет в очередь на исполнение, дожидаясь, когда CSSOM будет готова.
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут defer, то он не останавливает разбор документа во время загрузки скрипта, но когда скрипт загрузится, он станет в очередь на исполнение, которая заработает при возникновении события DOMContentLoaded. К этому моменту CSSOM будет уже готова.
Когда Rendering Engine заканчивает разбор документа, он вызывает событие DOMContentLoaded, и состояние документа меняется на interactive. При этом ресурсы (например, картинки) могут продолжать загружаться.
Когда все ресурсы загрузились, вызывается событие load, а состояние документа меняется на complete.
После того, как документ полностью разобран и сформированы DOM и CSSOM, Rendering Engine начинает построение Render Tree. В него попадут все элементы, которые нужно отрисовать. Некоторые элементы изначально могут быть невидимыми — их не нужно рисовать. Для каждого элемента, который “выпадает” из потока (например, используется position: absolute), будет создаваться отдельная ветка в Render Tree.
Во время Rendering Tree происходит сопоставление узлов из DOM и узлов CSSOM.
Свойства узла можно получить с помощью функции window.getComputedStyles(узел).
Когда Rendering Tree готов, Rendering Engine запускает процесс layout. Он заключается в вычислении размеров и позиций каждого элемента на странице.
Следующий этап — paint. Rendering Engine вычисляет цвет каждого пикселя.
И, наконец, последний этап — composite. Компонент UI Backend слой за слоем отрисовывает элементы на странице. При этом, если требуется отрисовать изображение, которое ещё не загрузилось, во время процесса layout, Rendering Engine зарезервирует место для изображения, если у него указаны ширина и высота. Rendering Engine вынесет на отдельный слой те элементы, стили которых содержат правила opacity, transform или will-change. Более того, эти слои Rendering Engine передаст для обработки GPU.
Если требуется отобразить текст, для которого используется нестандартный шрифт, то современные браузеры скроют текст до момента загрузки шрифта (flash of invisible text).
В современных браузерах скачивание документа, его разбор и отрисовка происходят по кускам, частями.
В документе HTML могут присутствовать некоторые мета-теги, которые могут менять порядок загрузки ресурсов, а также их приоритет.
К примеру, мета-тег dns-prefetch вынуждает Rendering Engine обратиться к Networking Component и получить IP нужного домена ещё до того, как Rendering Engine встретить его в документе.
Мета-тег prefetch вынудит Networking Component поставить указанный ресурс в очередь на загрузку с низким приоритетом.
Мета-тег preload вынудит Networking Component поставить указанный ресурс в очередь на загрузку с высоким приоритетом.
Мета-тег preconnect вынудит Networking Component заранее подключиться к другом хосту, то есть пройти нужные этапы: DNS lookup, redirects, hand shakes.

Автор: Антон Реймер
Статья основана на вебинаре, который я проводил некоторое время назад. Рассчитана она, в первую очередь на тех, кто не знает, как работают браузеры, или тех, у кого есть пробелы в знаниях. Вероятно, здесь будет много очевидного для тех кто не первый день в веб-разработке. Статью я решил разделить на две части. В первой рассмотрим общие принципы работы браузера. Во второй части я акцентирую внимание на некоторых важных моментах: reflow и repaint, event loop.
Что такое браузер?
Браузер — программа, работающая в операционной системе. Большинство браузеров написано на языке C++. Основное предназначение браузера — воспроизводить контент с веб-ресурсов. В качестве веб-ресурса в большинстве случаев выступает html-страница. Это также может быть pdf-файл, png, jpeg, xml-файлы и другие типы. Среди огромного количества браузеров можно выделить самые популярные: Chrome, Safari, Firefox, Opera и Internet Explorer. Мы рассмотрим браузеры с открытым исходным кодом: Chrome, Firefox, Safari.
Из чего состоит и как работает браузер?
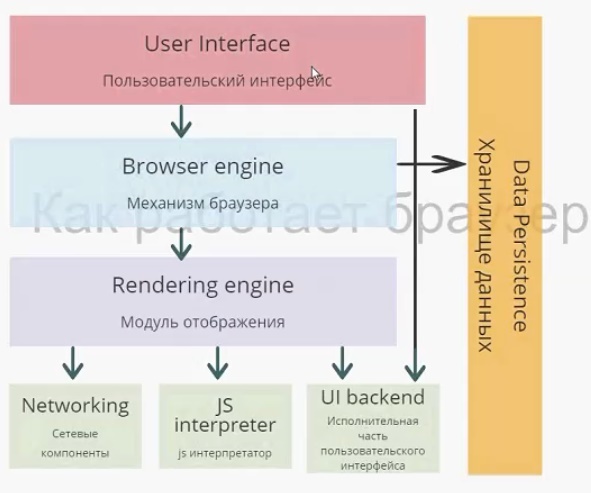
На схеме изображены модули браузера, каждый выполняет собственную функцию. Начнем с пользовательского интерфейса.
Пользовательский интерфейс — то, что видит перед собой пользователь, т. е. адресная строка, элементы навигации, собственное меню и т. д. Несмотря на то что пользовательские интерфейсы очень похожи друг на друга, никакого стандарта, который их описывал бы, не существует. Так исторически сложилось, что браузеры постепенно перенимали интерфейс друг у друга и становились все более похожими.
Механизм браузера отвечает за взаимодействие пользовательского интерфейса и модуля отображения, а также за сохранение данных в памяти.
Модуль отображения. Этот модуль — самый важный для разработчиков. Работа разработчика, в первую очередь, происходит именно с ним, а как можно понять по названию — отвечает он за отображение информации на экране.
Когда мы говорим о браузерных движках, таких как Webkit или Gecko (первый находится «под капотом» у Safari и до 2013 года был у Chrome, второй у Firefox), в первую очередь имеем в виду модуль отображения. Далее мы подробно рассмотрим модуль отображения и более детально разберем, как он работает.
Следующий модуль — сетевые компоненты. Он отвечает за запросы по сети, берет данные с внешних ресурсов и взаимодействует с модулем отображения.
Модуль JS Interpreter отвечает за интерпретацию скрипта, и его выполнение. Существует несколько JS-движков. Самые известные это V8 и JavaScriptCore. Важно не путать движок браузера и JS-движок, который работает в модуле JS Interpreter.
Следующий модуль — исполнительная часть пользовательского интерфейса (UI backend). Она отвечает за отрисовку всего на экране и работу пользовательского интерфейса.
Последний модуль — хранилище данных. Браузеру нужно где-то хранить данные, обычно для этого используется оперативная память. Какие данные нужно хранить? Например, кэш, собственные настройки. Также к хранилищу данных можно отнести indexedDB, который появился в стандарте html5 — собственные базы данных браузера.
Модуль отображения
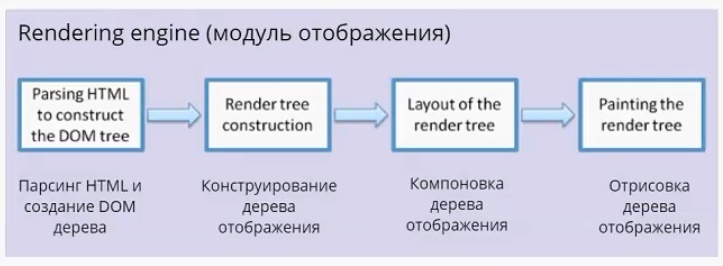
Модуль отображения получает данные от сетевого модуля. Данные поступают пакетами по 8 Кб. Что важно — модуль отображения не ждет, пока придут все данные, он начинает обрабатывать и выводить их на экран по мере поступления. В случае с html-страницами, он начинает их анализировать, происходит парсинг html (это отдельная большая тема, я на ней останавливаться не буду). Главное, что нужно понимать: в результате парсинга у нас появляется DOM-дерево. Также по окончании парсинга срабатывает событие load, которое можно обрабатывать в скрипте. Это значит, что документ готов и скрипт может с ним работать.
DOM-дерево — document object model. По большому счету, «интерфейс», который предоставляет браузер JS-движку для работы с тем или иным html-документом. На основе DOM-дерева происходит конструирование дерева отображения (render tree). Дерево отображения — тоже важная часть модуля отображения. По большому счету, два этих дерева — DOM-дерево и дерево отображения — наиболее важные элементы для разработчика. Дерево отображения во многом повторяет структуру DOM-дерева (далее будет пример, где это будет представлено нагляднее), но имеет некоторые отличия:
- Дерево отображения не содержит скрытых элементов. Если у нас есть html-элемент, у которого прописан display:none , в дереве отображения он присутствовать не будет. При этом, если visibility:hidden , то в дереве отображения он будет. Некоторые DOM-узлы, которые в DOM-дереве представлены как единый узел, в дереве отображения могут быть представлены в виде нескольких. Яркий пример — составной тэг select. Если в DOM-дереве это один узел, в дереве отображение он преобразовывается в минимум три узла. Первый узел отвечает за отображение выбранного элемента. Второй — за выпадающий список с возможными пунктами. И, наконец, третий блок отвечает за стрелочку.
- Текст в DOM-дереве представлен как простая node. DOM-дереву нет никакого дела до того, что там написано, сколько строк этот текст занимает. В то время, как для дерева отображения — это важно, и текст трансформируется в несколько узлов, в зависимости от того сколько строк он занимает. Это нагляднее рассмотрим чуть позже.
Дерево отображения служит для того, чтобы браузер понимал, что выводить на экран. Оно содержит информацию о том, из каких блоков состоит страница. Дальше в тексте для простоты я буду называть составные части дерева отображения прямоугольниками, чтобы не путать с html блоками.
Дерево отображения — совокупность прямоугольников, которая должна быть выведена на экране. После того как дерево отображения сконструировано, следует этап компоновки. На этом этапе всем прямоугольникам присваиваются размеры и координаты. Каждый прямоугольник получает свои ширину и высоту, координаты в окне браузера. После компоновки происходит отрисовка дерева отображения. Пользователь видит уже конечный результат. Модуль отображения в каждом браузере устроен по-своему, но схема работы схожая.

Предлагаю рассмотреть два браузерных движка: Webkit и Gecko.
Webkit. Модуль отображения получает html и стили. В результате парсинга html возникает DOM-дерево. В результате парсинга CSS возникает дерево правил таблиц стилей (Style Rules). Далее идет важный этап, который называется Attachment, можно перевести, как «совмещение». На этом этапе CSS-стили накладываются на DOM-дерево, в результате чего появляется Render Tree. После чего происходит компоновка дерева. Называется она здесь Layout. И в завершении происходит отрисовка (Painting).
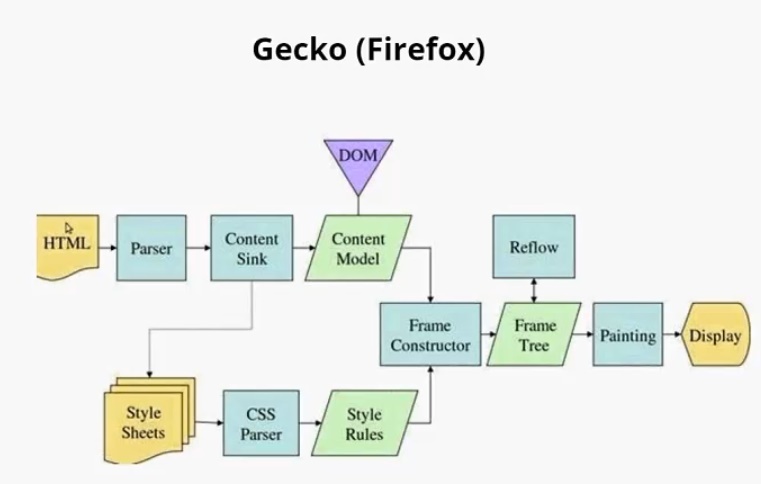
Если посмотреть на Gecko, можно заметить, что схемы очень похожи. Главные отличия — в терминологии. Здесь тоже парсятся HTML, CSS. В результате чего создается DOM-дерево, которое здесь называется Content Model. Парсятся стили, образуется дерево стилей. Этап Attachment здесь называется Frame Constructor, но, по сути, это тоже самое. В результате совмещения образуется дерево отображения, здесь оно называется Frame Tree. Компоновка здесь называется Reflow. А отрисовка называется Painting, так же, как и в Webkit.
- Attachment = Frame constructor = Совмещение
- Render Tree = Frame Tree = Дерево отображения
- Layout= Reflow = Компоновка
Пример

Здесь у нас есть теги:

Модуль отображения строит DOM-дерево. В данном случае оно будет выглядеть следующим образом. Есть корневой элемент (он всегда присутствует), называется он documentElement и соответствует тегу html . В этом дереве присутствуют все теги. И заметим, что текст представлен, как [text node] . И DOM-дереву больше ничего о тексте знать не нужно. На основе этого DOM-дерева строится Render Tree.
Пример
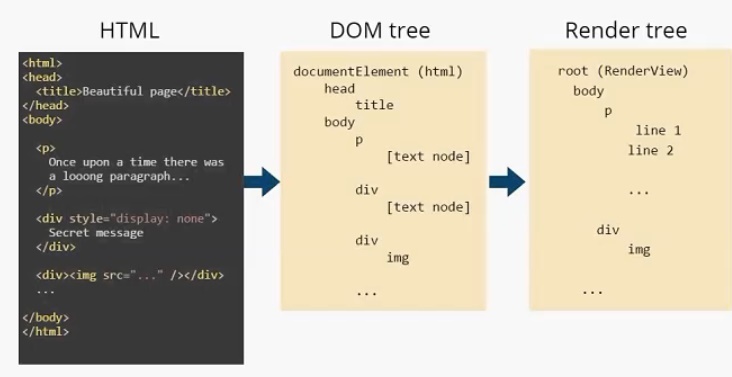
Дерево отображения. У него также есть корневой элемент (RenderView), но уже можно увидеть отличия между DOM-деревом и деревом отображения. Во-первых, нет тега head , т. к. он не отображается на экране. Нет <div style =” display: none”> , есть только
Текст в дереве отображения разделился на две строки и представляет собой два элемента: line 1 и line2. Как я писал выше, узлы дерева отображения мы будем называть прямоугольниками. Для наглядности я так и отобразил их на иллюстрации.
Пример
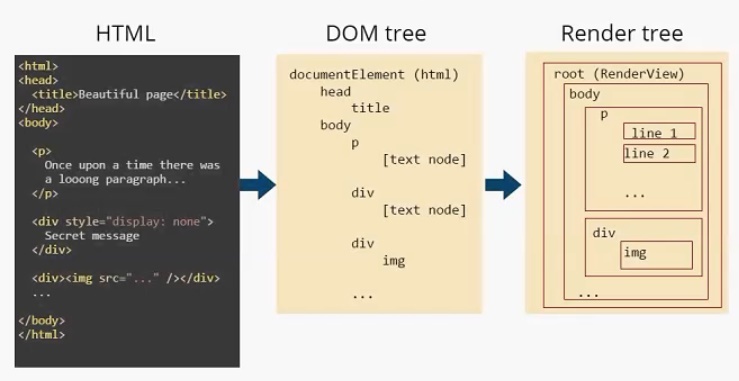
Каждый прямоугольник имеет своего «родителя», кроме корневого элемента root.
Модуль отображения также занимается обработкой скриптов.
Порядок обработки скриптов и таблиц стилей
Важно понимать порядок, в котором происходит обработка скриптов. Рассмотрим следующий пример, где я попытался продемонстрировать все возможные способы подключения скриптов и стилей.
Скрипт 1. Первое, что нужно знать про скрипты, — когда при парсинге html анализатор встречает скрипт, он останавливает дальнейший парсинг документа. Т. е., как только анализатор дошел до скрипта 1, браузеру ничего неизвестно о том, что будет дальше. И пока скрипт 1 не выполнится, дальнейший анализ документа происходить не будет.
Но при этом браузер продолжает выполнять ориентировочный синтаксический анализ. Что это значит? Браузер все равно смотрит, что следует за скриптом. Если находятся ссылки на внешние ресурсы, которые нужно скачать и загрузить, он подгрузит эти данные, пока выполняется скрипт 1. Сделано это для оптимизации.
При этом скрипт 3 все равно не будет выполняться, пока не выполнится скрипт 1. К моменту, когда скрипт 1 уже выполнится, скрипт 3 уже может быть полностью загружен. Скрипты можно вставлять в теги head и body . Разница в том, что в скрипте 2, в отличии от скрипта 1, практически весь документ уже будет проанализирован.
У скрипта могут быть атрибуты, такие как defer и async . Они похожи, но у них есть отличия:
- Атрибут defer сообщает браузеру, чтобы тот не ждал окончания выполнения скрипта, а продолжал парсинг html-страницы. При этом скрипт 4 выполнится только после того, как весь html-документ будет проанализирован и построено DOM-дерево.
- Атрибут async тоже говорит браузеру, что дальнейший html-документ может быть проанализирован, пока скрипт выполняется. При этом он загружается в параллельном потоке и выполняется сразу после загрузки. Это означает, что он может быть выполнен раньше, чем скрипт1, если последний тоже имеет атрибут async. Т. е. порядок подключения в этом случае не соблюдается.
В случае с defer скрипт 4 всегда выполняется после скрипта 1. С атрибутом async неизвестно, когда он будет выполнен и какая часть документа уже будет проанализирована к этому моменту.
Стили, в отличие от скриптов, никак не могут повлиять на документ. Если скрипты могут добавить дополнительные узлы или теги, то стили этого сделать не могут. Поэтому никакой надобности для браузера блокировать дальнейший анализ документа нет.
При этом есть небольшой нюанс. Например, скрипт 1 может работать с теми или иными стилям, и может потребоваться доступ к ним. Т.е. если мы хотим поменять (или узнать) какие-то стили, но при выполнении скрипта 1 они ещё не подгружены — может случиться ошибка.
Браузеры стараются этот нюанс учесть. Firefox, например, если находит какие-то не подгруженные стили в процессе ориентировочного синтаксического анализа, блокирует выполнение скрипта, подгружает стили, после чего завершает выполнение скрипта. Chrome действует аналогичным образом, но чуть более оптимизировано. Он останавливает скрипт, только если понимает, что в этом скрипте происходит работа с не подгруженными стилями.
Компоновка окон

Окно = Прямоугольник = Узел дерева отображения
- Тип окна (свойство display).
- Схема позиционирования (свойства position и float).
- Размеры окна.
- Внешняя информация (размеры изображения, размер экрана).
Компоновка окон — это этап компоновки дерева отображения. Я думаю многим верстальщикам знакома эта схема, она называется “Box model”. Я не буду подробно на ней останавливаться.
При компоновке окон учитываются следующее факторы:
CSS-свойство display. Два основных типа — inline и block. Другие, такие как inline-block table и прочие, появились уже позже. Отличие в том, что display:block, указывает, что ширина прямоугольника будет вычисляться в зависимости от ширины «родителя». А display:inline указывает, что ширина прямоугольника будет вычисляться в зависимости от его содержимого. Если в элементе два слова, ширина прямоугольника будет равна ширине, необходимой для вывода этих слов. Inline-элементы выстраиваются друг за другом. А блочные элементы — друг под другом.
Следующее, что влияет на компоновку элемента, — свойства position и float. Position по умолчанию static, при этом прямоугольник идет в стандартном потоке компоновки. Также есть position:relative и position:absolute. Position:relative указывает, что прямоугольнику выделяется место в стандартном потоке компоновки. При этом позиция элемента может быть сдвинута относительно этого места: влево, вправо, вверх, вниз с помощью соответствующего свойства.
Абсолютное позиционирование, к которому относится position:absolute и position:fixed, указывает, что элемент выходит за пределы своего прямоугольника из общего потока компоновки. Остальные прямоугольники его не учитывают. Он также не учитывает соседние элементы. Координаты его вычисляются относительно корневого элемента страницы, либо относительно предка, у которого position не static. Размеры же вычисляются тоже относительно родителя. Также на позиционирование влияет свойство float. Оно указывает, что наш прямоугольник идет в стандартном потоке, но при этом занимает либо крайнюю левую, либо крайнюю правую позиции. При этом все остальные прямоугольники «обтекают» этот элемент.
В заключение этой части стоит сказать что, основной поток браузера представляет собой бесконечный цикл, поддерживающий рабочие процессы. Он ожидает отправки событий, таких как reflow и repaint. Эти события ему приходят от модуля отображения. Получив их, он выполняет соответствующие действия.
В Firefox модуль отображения работает в одном потоке. Он един на весь браузер. В Chrome все немного иначе: модуль отображения и поток выполнения у каждой вкладки свои.
Важно, что сетевой модуль работает в отдельных параллельных потоках, которые не связаны с модулем отображения. Следовательно, сетевой компонент может использовать ресурсы независимо от того, что происходит в модуле отображения. Обычно у такого компонента есть возможность работать одновременно с несколькими подключениями и подгружать сразу несколько файлов. В Firefox, например, может быть шесть параллельных потоков, с помощью которых можно подгружать контент, скрипты и т. д.
В следующей части мы детально рассмотрим события reflow и repaint и попытаемся понять как грамотная работа с ними может повысить скорость работы приложения.
Многих пользователей интересует вопрос, как посмотреть код страницы в браузере. При помощи таких данных можно узнать множество полезной информации. В данной статье рассказывается, как открыть код и на что обратить внимание, при изучении текста.
Как запустить код страницы в браузере
Чтобы приступить к изучению данных, в первую очередь серферу нужно перейти на нужный сайт. В любой области страницы кликните правой кнопкой мыши, вызвав контекстное меню. В списке доступных команд выберите необходимую. Стоит отметить, что вызывать меню необходимо в месте, где отсутствуют ссылки и изображения. Данный метод подходит для всех без исключения браузеров.

Если по какой-либо причине в контекстном меню отсутствует необходимый пункт, то пользователю следует нажать на три полоски справа, запустив параметры обозревателя, выбрав «Дополнительно».

Далее остановитесь на «Дополнительные инструменты», кликните по искомому элементу.

Максимально быстро открыть нужный текст, рассказывающий о сайте, можно комбинацией клавиш «Ctrl+U».
Что скрывает открытая страница
После запуска нужной информации, многие пользователи не понимают, что именно здесь написано. Пронумерованные строки с различными цветными буквами и знаками рассказывают, как именно создавался сайт. Если желаете разобраться, о чем говориться на странице, следует узнать, на какие участки разделен Html код.
Исходный текст включает в себя:
- таблицу или ссылку на css файл;
- разметку html;
- программы, написанные при помощи JavaScript, или показывает, где располагается файл с текстом платформы.
Чтобы приступить к изучению информации, нажмите на текст правой кнопкой мыши, выберите «Исследовать элемент».

Справа откроется дополнительное окно с инструментами разработчика. Здесь пользователи могут узнать, какой именно блок анализируется, увидеть, какие скрипты, шрифты и изображения использовались для создания ресурса.

Как изменить код сайта
Некоторые из серферов желают попробовать изменить данные сайта, используя инструменты разработчика. Чтобы справится с задачей, необходимо знать язык программирования, ведь именно на нем прописывается любой интернет-ресурс.
Для запуска инструмента, откройте меню, выберите «Дополнительно».
Остановитесь на «Дополнительные инструменты», кликните по искомому элементу.

Откроется окно, нажмите на «Elements». В верхней части написано множество знаков. Наведите курсор мыши на один из них, вызовите контекстное меню.

В высвеченном окне выберите «Edit as HTML».
Теперь пользователь может вносить изменения в текст, которые автоматически сохранятся после выхода из режима редактирования.

Чтобы понять, что скрывает в себе код страницы в браузере,нужно обладать определенными знаниями. Начинающему пользователю будет нелегко разобраться в показанных иероглифах и узнать скрытую в них информацию.
Читайте также: