Что такое валидация данных в 1с
Итак, вы написали несколько страниц HTML , и они, кажется, выводятся нормально, но имеется несколько не совсем правильных вещей. Как лучше всего начать поиск того, что неправильно, и гарантировать, что эти страницы (и написанные в будущем страницы) будут выводиться правильно в различных браузерах, без каких-либо ошибок?
Ответом является валидация (проверка на соответствие правилам)! Существует много доступных средств на сайте W3C и в других местах, которые позволяют выполнить валидацию кода сайта.
Наиболее известными валидаторами являются следующие:
В этой статье будет рассмотрен первый из этих инструментов, чтобы показать, как его использовать, и как интерпретировать типичные результаты, которые возвращает валидатор . Проверка ссылок достаточно очевидна, а валидатор CSS также станет вполне понятен после прочтения этой статьи и статей по CSS , которые будут представлены дальше в курсе.
Статья имеет следующую структуру:
- Ошибки
- Что такое валидация?
- Зачем нужна валидация?
- Различные браузеры интерпретируют неправильный код HTML по разному
- Quirksmode
Ошибки
В программировании компьютеров существует, вообще говоря, два вида проблем кода:
- синтаксические ошибки - когда ошибки в записи кода не позволяют компьютеру правильно выполнить или скомпилировать программу.
- ошибки программирования (или логики) — когда код не полностью отражает замысел программиста.
В большинстве языков программирования ошибки первого рода достаточно легко обнаружить - программа просто отказывается выполняться или компилироваться, пока ошибка не будет исправлена. Это делает поиск и исправление таких ошибок значительно проще в ситуациях "почему она не делает то, что я хочу".
HTML не является языком программирования. Синтаксические ошибки на Web -странице обычно не ведут к тому, что Web - браузер отказывается открыть страницу (хотя XHTML является более строгим, чем HTML -- по крайней мере, когда обрабатывается как данные application/xhtml+xml или text/xml , как и должно быть - и некоторые doctype запрещают использование определенных типов элементов HTML ). Это является одной из основных причин быстрого принятия и распространения Web .
Что такое валидация?
Хотя браузеры Web будут принимать плохие (недействительные в нашей терминологии) Web -страницы и делать максимум возможного для визуализации кода, делая наилучшие предположения о намерении автора, тем не менее, можно проверить, был ли HTML написан правильно, и на самом деле это нужно делать, как мы увидим ниже. Мы называем этот процесс "валидацией" HTML .
Программа валидации сравнивает код HTML на странице Web с правилами сопровождающего doctype и сообщает, какие правила и где были нарушены.
Зачем нужна валидация?
Существует распространенное мнение среди некоторых Web -разработчиков, что если Web -страница выглядит в браузерах хорошо, то не имеет значения, что ее валидация не была выполнена. Они называют валидацию идеальной целью, но не чем-то, что является черно-белой проблемой.
Существует некоторая доля истины в таком подходе, спецификация HTML не является совершенной, и сейчас существенно устарела. Некоторые вещи, которые, возможно, правильны (такие как начало упорядоченного списка в точке, отличной от 1) являются недействительными в HTML . Однако как говорит пословица:
Учите правила, чтобы знать, как нарушать их правильно
Существует две крайне важные причины для валидации кода HTML при его создании.
- Человек не совершенен, как и создаваемый им код — все делают ошибки, и Web -страницы будут более высокого качества (т.е., работать более согласованно), если выполоть все ошибки.
- Браузеры изменяются. В будущем браузеры, скорее всего, будут менее снисходительны при синтаксическом анализе недействительного кода.
Валидация является системой раннего предупреждения о существовании ошибок на страницах, которые могут проявлять себя разнообразным и трудно определяемым образом. Когда браузер встречает недействительный код HTML , он вынужден делать обоснованное предположение о том, что вы собирались делать - и различные браузеры могут приходить к различным ответам.
Различные браузеры интерпретируют неправильный код HTML по разному
Действительный код HTML является только контрактом, который вы заключаете с производителями браузеров. Спецификация HTML говорит, как вы должны написать это, и как они должны интерпретировать ваш документ. В последнее время соответствие браузеров стандартам достигло той точки, где, если вы пишете действительный код, все основные браузеры должны интерпретировать ваш код одинаково. Это почти всегда касается в любом случае HTML , в то время как другие стандарты имеют немного больше различий в поддержке в различных браузерах.
Но что будет, если передать браузеру недействительный (невалидный) код? Что тогда произойдет? Ответ состоит в том, что в браузере начинает работать обработка ошибок, чтобы определить, что делать с кодом. Браузер , как правило, поступает следующим образом: "ладно, этот код недействителен, как можно представить эту страницу конечному пользователю? Давайте заполним недостающее следующим образом!"
Звучит прекрасно, не правда ли? Если на странице имеется несколько ошибок, то браузер заполнит вместо вас недостающее? Не совсем так, так как каждый браузер делает это по-разному. Например:
Ошибки состоят в том, что элемент strong неправильно вложен в несколько блочных элементов , а элемент анкера не закрыт.
Когда вы попробуете вывести этот код в различных браузерах, они интерпретируют код совершенно по разному:
- Opera сделает последующие элементы потомками элемента strong .
- Firefox добавит дополнительные элементы strong между параграфами, которые не присутствуют в разметке.
- Internet Explorer поместит текст "This text should be a link" ("Этот текст должен быть ссылкой") вне тега анкера , который создает ссылку.
Ни одно из поведений различных браузеров не является неправильным; все они пытаются заполнить пробелы неправильного кода. Главный вывод состоит в том, что надо стараться избегать на странице недействительной разметки, если это возможно!
Quirksmode
Надо знать еще о так называемом режиме Quirksmode . Браузер переходит в этот режим, если встречает страницу, которая имеет неправильный doctype , или вообще не имеет doctype . В этом режиме браузер делает наилучшие предположения о множестве правил, согласно которым он должен интерпретировать код, и снова заполняет пробелы как можно лучшим образом. Этот режим существует в действительности для того, чтобы можно было все еще выводить старые страницы, и не должен никогда использоваться при создании новых страниц.
Привет, Хабр! В преддверии старта курса "Архитектор сетей" предлагаем прочитать перевод полезной статьи.
Оптимизация модели данных и удаление повторений — это, конечно, здорово, но каким образом мы можем убедиться, что работаем с валидной моделью данных?
На этот вопрос легко ответить в рамках традиционной реализации IPAM/CMDB с использованием внутренней базы данных и пользовательской логики обработки данных, предлагающей REST API, графический интерфейс или и то, и другое. Пользовательская логика обработки данных проверяет данные перед их вводом в базу данных, и, таким образом мы получаем гарантию того, что база данных содержит синтаксически и семантически допустимые данные.
В более простом решении, использующем текстовые файлы для хранения сетевой модели данных (также известной как источник истины или source-of-truth), сложно выполнить тщательную проверку каждой транзакции, тем более, если для изменения этих файлов вы используете текстовый редактор. В этих случаях вам нужно писать собственный конвейер валидации, используя инструменты, которые проверяют:
синтаксис текстового файла;
соответствие схеме модели данных;
Используя нашу последнюю модель данных с per-link префиксами, которые хранятся как куча Ansible host_vars файлов и network.yml файл, конвейер валидации должен проверить что:
Все файлы соответствуют синтаксису YAML (чтобы сделать это, вы можете использовать такие инструменты как yamllint );
Факты о хостах содержат значения hostname и bgp_as для каждого хоста;
Сетевая модель данных содержит значение links , которое представляет из себя массив core и edge ссылок;
Core ссылки содержат prefix и как минимум два других значения;
Edge ссылки содержат одно значение, которое является словарем (или объектом, если вы предпочитаете терминологию JSON) с одним значением.
Для выполнения этих тестов вы можете написать небольшую программу на любом языке программирования или же использовать языки моделирования данных (также называемые схемами), такие как YANG, JSON Schema или XML Schema, которые наложат большинство необходимых проверочных ограничений. Поскольку файлы YAML легко преобразовать в JSON, мы будем использовать jsonschema .
Зачастую проверить ссылочную целостность с помощью языка моделирования данных бывает сложно. Для этого вам, возможно, придется написать свое собственное программное решение, но, по крайней мере, вы можете спихнуть скучную рутину проверки структур и форматов данных на стороннее решение.
Валидация данных хоста
Первым этапом в нашей логике валидации модели данных будет проверка фактов хоста Ansible. Эти факты часто расползаются по нескольким файлам и каталогам или генерируются «на лету» с помощью внешнего скрипта или плагина Ansible. Таким образом, лучший способ получить их — передать задачу программе ansible-inventory , которая создает JSON структуру данных в соответствии с требованиями внешнего инвентарного скрипта (external inventory script).
Из полученной JSON структуры данных нам нужно извлечь только переменные хоста, и jq идеально подходит для этой работы:
Если мы хотим использовать утилиту командной строки jsonschema , нам необходимо сохранить результаты в текстовом файле, а затем вызвать утилиту jsonschema с именем текстового файла и файла JSON Schema, в соответствии с которым следует проверить данные.
Валидация сетевой модели данных
Для проверки network.yml файла мы будем использовать аналогичный подход:
Convert YAML file into JSON format with yq
Преобразуем YAML файл в формат JSON с помощью yq
Run jsonschema on the resulting JSON file
Запустим jsonschema на полученном JSON файле
Как упоминалось выше, JSON Schema позволяет нам проверять грамматику модели данных, а ссылочную целостность — нет. Например:
Мы не можем проверить, валидны ли имена хостов, указанные для core или edge ссылок.
Хотя мы можем проверить формат имени интерфейса, у нас нет средств, позволяющих проверить, обладают ли устройства интерфейсами, которые мы хотим использовать, без подключения к сетевым устройствам или извлечения данных из системы управления сетью.
Пару слов о JSON Schema
Языки моделирования данных не для слабонервных, и JSON Schema не исключение. Замысловатая подача спецификации тоже не особо облегчает жизнь (мне было интереснее читать стандарты ISO или IEEE). К счастью, онлайн-книга Разбираемся с JSON Schema довольно хорошо объясняет все тонкости.
Просто чтобы вы прочувствовали, что такое JSON Schema: вот документ JSON, описывающий ожидаемую структуру данных переменных хоста, полученный из инвентаря Ansible:
Вот что можно сказать об этой схеме:
Она описывает инвентарные данные Ansible (Ansible inventory data);
Она содержит определения дополнительных схем (см. ниже).
Элемент верхнего уровня — это объект (словарь) с некоторыми свойствами (мы знаем, что это инвентарные имена хостов), и каждое свойство должно соответствовать схеме router
Минимальное количество свойств — одно (хотя бы один хост в файле инвентаризации).
Определение схемы router находится в свойстве definitions :
Согласно этой схеме роутер (если быть точнее, факты хоста Ansible, описывающие роутер) — это объект со следующими свойствами:
Числовым свойством bgpas , которое должно быть от 1 до 65535;
Строковым свойством hostname
Оба свойства являются обязательными, и в объекте не должно быть других свойств.
Закатываем рукава
JSON схемы хоста и сети, а также исходный код скрипта проверки доступны на GitHub. Не стесняйтесь клонировать репозиторий, менять host_vars файлы или сетевую модель данных и запускать скрипт проверки в своих целях.
Вам также может захотеться исследовать JSON Schema побольше, в частности:
выяснить, что делает JSON схема network ;
добавить необязательное свойство description в модель данных роутера;
скорректировать валидацию свойства bgp_as , чтобы разрешить 4-байтовые AS номера в точечной нотации.
Вам понадобятся следующие инструменты:
Больше о валидации данных
Мы рассматриваем валидацию данных и конвейеры CI/CD более подробно в части Validation, Error Handling and Unit Tests нашего онлайн-курса Building Network Automation Solutions.
Дополнительная информация
Чтобы узнать больше об использовании моделей данных в решениях для автоматизации сети, ознакомьтесь с модулем 3 нашего онлайн-курса Building Network Automation Solutions.
Далее в программе
Data Model Hierarchy
Иерархия моделей данных
Подробнее о курсе "Архитектор сетей". Посмотреть запись открытого урока на тему "Overlay. Что это такое и зачем необходимо" можно здесь.
Очень часто путают два понятия валидация и верификация. Кроме того, часто путают валидацию требований к системе с валидацией самой системы. Я предлагаю разобраться в этом вопросе.
В статье «Моделирование объекта как целого и как композиции» я рассмотрел два подхода к моделированию объекта: как целого и как конструкции. В текущей статье нам это деление понадобится.
Пусть у нас есть проектируемый функциональный объект. Пусть этот объект рассматривается нами как часть конструкции другого функционального Объекта. Пусть есть описание конструкции Объекта, такое, что в нем присутствует описание объекта. В таком описании объект имеет описание как целого, то есть, описаны его интерфейсы взаимодействия с другими объектами в рамках конструкции Объекта. Пусть дано описание объекта как конструкции. Пусть есть информационный объект, содержащий требования к оформлению описания объекта как конструкции. Пусть есть свод знаний, который содержит правила вывода, на основании которых из описания объекта как целого получается описание объекта как конструкции. Свод знаний – это то, чему учат конструкторов в институтах – много, очень много знаний. Они позволяют на основе знанию об объекте спроектировать его конструкцию.
Итак, можно начинать. Мы можем утверждать, что если правильно описан объект как целое, если свод знаний верен, и если правила вывода были соблюдены, то полученное описание конструкции объекта, будет верным. То есть, на основе этого описания будет построен функциональный объект, соответствующий реальным условиям эксплуатации. Какие могут возникнуть риски:1. Использование неправильных знаний об Объекте. Модель Объекта в головах у людей может не соответствовать реальности. Не знали реальной опасности землетрясений, например. Соответственно, могут быть неправильно сформулированы требования к объекту.
2. Неполная запись знаний об Объекте – что-то пропущено, сделаны ошибки. Например, знали о ветрах, но забыли упомянуть. Это может привести к недостаточно полному описанию требований к объекту.
3. Неверный свод знаний. Нас учили приоритету массы над остальными параметрами, а оказалось, что надо было наращивать скорость.
4. Неправильное применение правил вывода к описанию объекта. Логические ошибки, что-то пропущено в требованиях к конструкции объекта, нарушена трассировка требований.
5. Неполная запись полученных выводов о конструкции системы. Все учли, все рассчитали, но забыли написать.
6. Созданная система не соответствует описанию.
Понятно, что все артефакты проекта появляются, как правило, в завершенном своем виде только к концу проекта и то не всегда. Но, если предположить, что разработка водопадная, то риски такие, как я описал. Проверка каждого риска – это определенная операция, которой можно дать название. Если кому интересно, можно попытаться придумать и озвучить эти термины.
Что такое верификация? По-русски, верификация – это проверка на соответствие правилам. Правила оформляются в виде документа. То есть, должен быть документ с требованиями к документации. Если документация соответствует требованиям этого документа, то она прошла верификацию.
Что есть валидация? По-русски валидация – это проверка правильности выводов. То есть, должен быть свод знаний, в котором описано, как получить описание конструкции на основе данных об объекте. Проверка правильности применения этих выводов – есть валидация. Валидация — это в том числе проверка описания на непротиворечивость, полноту и понятность.
Часто валидацию требований путают с валидацией продукта, построенного на основе этих требований. Так делать не стоит.
Валидация – это процесс проверки данных на соответствие различным критериям. При разработке любого приложения в большинстве случаев разработчику приходится иметь дело с обработкой данных, которые ввел пользователь в соответствующие поля на форме. По разным причинам пользователь может вводить некорректные данные. Например, в поле "Возраст" он по ошибке может указать отрицательное или вовсе нечисловое значение . На практике встречается множество ситуаций, где определенные поля в пользовательском интерфейсе могут содержать только те данные, которые строго соответствуют определенным шаблонам. Если не учитывать подобные ситуации, то в процессе работы приложения могут возникать сбои, связанные с некорректным вводом пользователя. Ошибки могут быть допущены случайно или намеренно. В последнем случае пользователь может вводить некорректные данные с целью вывести приложение из строя и таким образом произвести атаку на приложение . Поэтому каждое приложение , которое работает с данными, которые вводит пользователь (а таких приложений большинство) должно производить предварительную проверку корректности введенных данных. Именно по этой причине каждый разработчик должен быть знаком с механизмом валидации данных, которые указал пользователь .
Исторически, механизмы валидации данных разрабатывались самими разработчиками прикладных приложений. Это означает, что при каждой обработке запроса логике обработки запроса предшествовало большое количество условных операторов, определяющих условия корректности данных. Примером такого подхода может являться следующий фрагмент кода.
![]()
Приведенный фрагмент кода является лишь небольшой демонстрацией того, насколько громоздким может быть код валидации данных. Тем не менее, приведенный выше пример является упрощенной демонстрацией того, как может выглядеть подобный код. Как видно при относительно малом количестве проверяемых параметров, создается большое количество кода. В реальных условиях эти проверки обычно сложнее, а параметров больше.
Поскольку подобный подход вносит множество программного кода в процесс обработки запроса и ухудшает читаемость программы, платформа ASP . NET содержит ряд механизмов для выполнения валидации в виде отдельных программных компонентов.
Существует два вида валидации данных, введенных пользователем.
- клиентская валидация;
- серверная валидация.
Клиентская валидация производится в бразуере на стороне клиента. Как правило, логика валидации на стороне клиента реализуется посредством сценариев JavaScript, которые запускаются внутри браузера. Клиентская валидация обычно содержит несложные алгоритмы проверки. Это происходит в силу того, что клиентский код физически не может обратиться к серверным ресурсам (например, к базе данных). Поэтому на стороне клиента проверяются самые тривиальные сценарии (такие как проверка длины строки, проверка на вхождение в диапазон и т.д.).
Клиентская валидация может отсутствовать в приложении. Однако, если сценарии валидации присутствуют на стороне клиента, это может избавить от необходимости лишних обращений к серверу в случае невыполнения простых условий проверки.
Серверная валидация работает в рамках программного кода, размещенного на стороне сервера. Здесь проверяются всевозможные случаи, в том числе те, которые уже были проверены на стороне клиента. Кроме тривиальных проверок, на стороне сервера могут работать более сложные алгоритмы. Необходимость дублирования проверки сценариев, которые уже были проверены на стороне клиента, обусловлена тем, что клиентские проверки могут не сработать, если в браузере у клиента отключено исполнение сценариев JavaScript. Другими словами наличие клиентской валидации не может гарантировать успешную проверку определенных там ограничений.
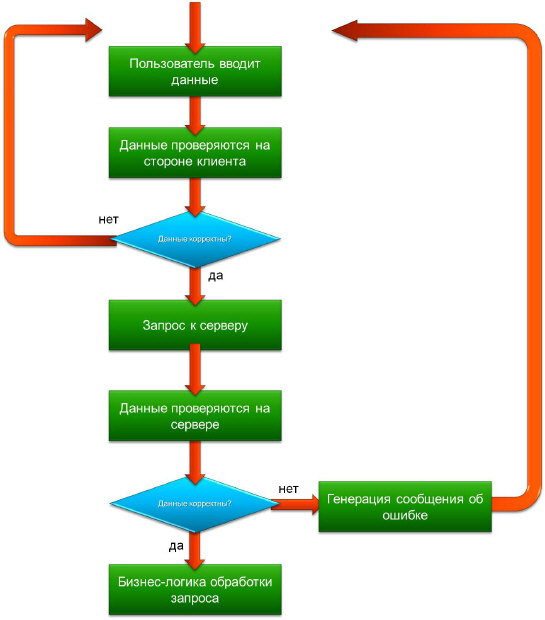
Общий алгоритм валидации данных, введенных пользователем можно представить следующим образом.
![]()
Таким образом, серверная валидация – это необходимый процесс, который должен выполнятся всякий раз, когда обрабатывается пользовательский ввод, а клиентская валидация – это опциональный компонент , который позволяет избавить пользователя от необходимости лишних обращений к серверу и повысить удобство работы с приложением.
Краткие итоги
Большинство приложений так или иначе обрабатывает данные, которые вводит пользователь на странице. Пользователь может случайно или намеренно вводить некорректные данные. Поэтому требуется проверка пользовательского ввода при обработке запроса. Процесс проверки данных, введенных пользователем называется валидацией. Существует два типа валидации – серверная и клиентская. Серверная валидация производит всевозможные проверки и является основным механизмом валидации. Клиентская валидация позволяет обрабатывать алгоритмы валидации более интерактивно (на стороне клиента) и таким образом делает использование веб-приложения более удобным.
Читайте также: