
Что делает браузер в первую очередь чтобы найти ip адрес сайта который вы открываете
Простыми словами объясняем, как браузер подключается и общается с сервером.
Поэтому первым делом браузеру нужно понять, какой IP-адрес у сервера, на котором находится сайт.
Такая информация хранится в распределенной системе серверов — DNS (Domain Name System). Система работает как общая «контактная книга», хранящаяся на распределенных серверах и устройствах в интернете.
Однако перед тем, как обращаться к DNS, браузер пытается найти запись об IP-адресе сайта в ближайших местах, чтобы сэкономить время:
- Сначала в своей истории подключений . Если пользователь уже посещал сайт, то в браузере могла сохраниться информация c IP-адресом сервера.
- В операционной системе . Не обнаружив информации у себя, браузер обращается к операционной системе, которая также могла сохранить у себя DNS-запись. Например, если подключение с сайтом устанавливалось через одно из установленных на компьютере приложений.
- В кэше роутера , который сохраняет информацию о последних соединениях, совершенных из локальной сети.
Не обнаружив подходящих записей в кэше, браузер формирует запрос к DNS-серверам, расположенным в интернете.
Как только браузер узнал IP-адрес нужного сервера, он пытается установить с ним соединение. В большинстве случаев для этого используется специальный протокол — TCP.
TCP — это набор правил, который описывает способы соединения между устройствами, форматы отправки запросов, действия в случае потери данных и так далее.
Например, для установки соединения между браузером и сервером в стандарте TCP используется система «трёх рукопожатий». Работает она так:
- Устройство пользователя отправляет специальный запрос на установку соединения с сервером — называется SYN -пакет.
- Сервер в ответ отправляет запрос с подтверждением получения SYN-пакета — называется SYN/ACK -пакет.
- В конце устройство пользователя при получении SYN/ACK-пакета отправляет пакет с подтверждением — ACK -пакет. В этот момент соединение считается установленным.
Задача браузера — как можно подробнее объяснить серверу, какая именно информация ему нужна .
Сервер получил запрос от браузера с подробным описанием того, что ему требуется. Теперь ему нужно обработать этот запрос. Этой задачей занимается специальное серверное программное обеспечение — например, nginx или Apache. Чаще всего такие программы принято называть веб-серверами.
Когда ответ сформирован, он отправляется веб-сервером обратно браузеру. В ответе как правило содержится контент для отображения веб-страницы, информация о типе сжатия данных, способах кэширования, файлы cookie, которые нужно записать и так далее.
👉 Чтобы обмен данными был быстрым, браузер и сервер обмениваются сразу множеством небольших пакетов данных — как правило, в пределах 8 КБ. Все пакеты имеют специальные номера, которые помогают отслеживать последовательность отправки и получения данных. 8. Браузер обрабатывает полученный ответ и «рисует» веб-страницуБраузер распаковывает полученный ответ и постепенно начинает отображать полученный контент на экране пользователя — этот процесс называется рендерингом .
Сначала браузер загружает только основную структуру HTML-страницы. Затем последовательно проверяет все теги и отправляет дополнительные GET-запросы для получения с сервера различных элементов — картинки, файлы, скрипты, таблицы стилей и так далее. Поэтому по мере загрузки страницы браузер и сервер продолжают обмениваться между собой информацией.
Параллельно с этим на компьютер как правило сохраняются статичные файлы пользователя — чтобы при следующем посещении не загружать их заново и быстрее отобразить пользователю содержимое страницы.
Как только рендеринг завершен — пользователю отобразится полностью загруженная страница сайта.

Примечание: публикация основана на содержании репозитория What happens when.
Мы перенесли перевод в репозиторий GitHub и отправили Pull Request автору материала — оставляйте свои правки к тексту, и вместе мы сможем значительно улучшить его.
1. Нажата клавиша «g»
Далее в статье содержится информация о работе физической клавиатуры и прерывания операционной системы. Но много чего происходит и помимо этого — когда вы нажимаете клавишу «g», браузер получает событие и запускается механизм автоподстановки. В зависимости от алгоритма браузера и его режима (включена ли функция «инкогнито») в выпадающем окне под строкой URL пользователю будет предложено определённое количество вариантов для автоподстановки.
2. Клавиша «enter» нажата до конца
В качестве некой нулевой точки можно выбрать момент, когда клавиша Enter на клавиатуре нажата до конца и находится в нижнем положении. В этой точке замыкается электрическая цепь этой клавиши и небольшое количество тока отправляется по электросхеме клавиатуры, которая сканирует состояние каждого переключателя клавиши и конвертирует сигнал в целочисленный код клавиши (в данном случае — 13). Затем контроллер клавиатуры конвертирует код клавиши для передачи его компьютеру. Как правило, сейчас передача происходит через USB или Bluetooth, а раньше клавиатура подключалась к компьютеру с помощью коннекторов PS/2 или ADB.
В случае USB-клавиатуры:
- Для работы USB-контуру клавиатуры требуется 5 вольт питания, которые поступают через USB-контроллер на компьютере.
- Сгенерированный код клавиши хранится в регистре внутренней памяти клавиатуры, который называется «конечной точкой» (endpoint).
- USB-контроллер компьютера опрашивает эту конечную точку каждые 10 микросекунд и получает хранящийся там код клавиши.
- Затем это значение поступает в USB SIE (Serial Interface Engine) для конвертации в один или более USB-пакетов, которые формируются по низкоуровневому протоколу USB.
- Эти пакеты затем пересылаются с помощью различных электрических сигналов через D+ и D- контакты с максимальной скоростью 1,5 Мб/сек — поскольку HID-устройства (Human Interface Device) всегда были «низкоскоростными».
- Этот последовательный сигнал далее декодируется в USB-контроллере компьютера и интерпретируется универсальным драйвером HID-устройства (клавиатуры). Затем значение кода клавиши передаётся на «железный» уровень абстракции операционной системы.
2.1 Возникло прерывание [не для USB-клавиатур]
Клавиатура отправляет сигналы в свою «линию запросов прерываний» (IRQ), которая затем сопоставляется с «вектором прерывания» (целое число) контроллером прерываний. Процессор использует «таблицу дескрипторов прерываний» (IDT) для сопоставления векторов прерываний с функциями («обработчики прерываний») ядра. Когда появляется прерывание, процессор (CPU) обновляет IDT вектором прерывания и запускает соответствующий обработчик. Таким образом, в дело вступает ядро.
2.3 (В OS X) Событие NSEVent KeyDown отправлено приложению
Сигнал прерывания активирует событие прерывания в драйвере I/O Kit клавиатуры. Драйвер переводит сигнал в код клавиатуры, который затем передаётся процессу OS X под названием WindowServer . В результате, WindowsServer передаёт событие любому подходящему (активному или «слушающему») приложению через Mach-порт, в котором событие помещается в очередь. Затем события могут быть прочитаны из этой очереди потоками с достаточными привилегиями, чтобы вызывать функцию mach_ipc_dispatch . Чаще всего это происходит и обрабатывается с помощью основного цикла NSApplication через NSEvent в NSEventype KeyDown .
2.4 (В GNU/Linux) Сервер Xorg слушает клавиатурные коды
В случае графического X server, для получения нажатия клавиши будет использован общий драйвер событий evdev . Переназначение клавиатурных кодов скан-кодам осуществляется с помощью специальных правил и карт X Server. Когда маппинг скан-кода нажатой клавиши завершён, X server посылает символ в window manager (DWM, metacity, i3), который затем отправляет его в активное окно. Графический API окна, получившего символ, печатает соответствующий символ шрифта в нужном поле.
3. Парсинг URL
Теперь у браузера есть следующая информация об URL:
Resource «/»
Показать главную (индексную) страницу
3.1 Это URL или поисковый запрос?
Когда пользователь не вводит протокол или доменное имя, то браузер «скармливает» то, что человек напечатал, поисковой машине, установленной по умолчанию. Часто к URL добавляется специальный текст, который позволяет поисковой машине понять, что информация передана из URL-строки определённого браузера.
3.2 Список проверки HSTS
3.3 Конвертация не-ASCII Unicode символов в название хоста
4. Определение DNS
- Браузер проверяет наличие домена в своём кэше.
- Если домена там нет, то браузер вызывает библиотечную функцию gethostbyname (отличается в разных ОС) для поиска нужного адреса.
- Прежде, чем искать домен по DNS gethostbyname пытается найти нужный адрес в файле hosts (его расположение отличается в разных ОС).
- Если домен нигде не закэширован и отсутствует в файле hosts , gethostbyname отправляет запрос к сетевому DNS-серверу. Как правило, это локальный роутер или DNS-сервер интернет-провайдера.
- Если DNS-сервер находится в той же подсети, то ARP-запрос отправляется этому серверу.
- Если DNS-сервер находится в другой подсети, то ARP-запрос отправляется на IP-адрес шлюза по умолчанию (default gateway).
4.1 Процесс отправки ARP-запроса
Кэш ARP проверяется для каждого целевого IP-адреса — если адрес есть в кэше, то библиотечная функция возвращает результат: Target IP = MAC .
Если же записи в кэше нет:
- Проверяется таблица маршрутизации — это делается для того, чтобы узнать, есть ли искомый IP-адрес в какой-либо из подсетей локальной таблицы. Если он там, то запрос посылается с помощью интерфейса, связанного с этой подсетью. Если адрес в таблице не обнаружен, то используется интерфейс подсети шлюза по умолчанию.
- Определяется MAC-адрес выбранного сетевого интерфейса.
- Отправляется ARP-запрос (второй уровень стека):
Sender MAC: interface:mac:address:here
Sender IP: interface.ip.goes.here
Target MAC: FF:FF:FF:FF:FF:FF (Broadcast)
Target IP: target.ip.goes.here
В зависимости от того, какое «железо» расположено между компьютером и роутером (маршрутизатором):
- Если компьютер напрямую подключён к роутеру, то это устройство отправляет ARP-ответ (ARP Reply).
- Если компьютер подключён к сетевому концентратору, то этот хаб отправляет широковещательный ARP-запрос со всех своих портов. Если роутер подключён по тому же «проводу», то отправит ARP-ответ.
- Если компьютер соединён с сетевым коммутатором, то этот свитч проверит локальную CAM/MAC-таблицу, чтобы узнать, какой порт в ней имеет нужный MAC-адрес. Если нужного адреса в таблице нет, то он заново отправит широковещательный ARP-запрос по всем портам.
- Если в таблице есть нужная запись, то свитч отправит ARP-запрос на порт с искомым MAC-адресом.
- Если роутер «на одной линии» со свитчем, то он ответит (ARP Reply).
Sender MAC: target:mac:address:here
Sender IP: target.ip.goes.here
Target MAC: interface:mac:address:here
Target IP: interface.ip.goes.here
Теперь у сетевой библиотеки есть IP-адрес либо DNS-сервера либо шлюза по умолчанию, который можно использовать для разрешения доменного имени:
- Порт 53 открывается для отправки UDP-запроса к DNS-серверу (если размер ответа слишком велик, будет использован TCP).
- Если локальный или на стороне провайдера DNS-сервер «не знает» нужный адрес, то запрашивается рекурсивный поиск, который проходит по списку вышестоящих DNS-серверов, пока не будет найдена SOA-запись, а затем возвращается результат.
5. Открытие сокета
- Этот запрос сначала проходит через транспортный уровень, где собирается TCP-сегмент. В заголовок добавляется порт назначения, исходный порт выбирается из динамического пула ядра ( ip_local_port_range в Linux).
- Получившийся сегмент отправляется на сетевой уровень, на котором добавляется дополнительный IP-заголовок. Также включаются IP-адрес сервера назначения и адрес текущей машины — после этого пакет сформирован.
- Пакет передаётся на канальный уровень. Добавляется заголовок кадра, включающий MAC-адрес сетевой карты (NIC) компьютера, а также MAC-адрес шлюза (локального роутера). Как и на предыдущих этапах, если ядру ничего не известно о MAC-адресе шлюза, то для его нахождения отправляется широковещательный ARP-запрос.
В конечном итоге пакет доберётся до маршрутизатора, управляющего локальной подсетью. Затем он продолжит путешествовать от одного роутера к другому, пока не доберётся до сервера назначения. Каждый маршрутизатор на пути будет извлекать адрес назначения из IP-заголовка и отправлять пакет на следующий хоп. Значение поля TTL (time to live) в IP-заголовке будет каждый раз уменьшаться после прохождения каждого роутера. Если значение поля TTL достигнет нуля, пакет будет отброшен (это произойдёт также если у маршрутизатора не будет места в текущей очереди — например, из-за перегрузки сети).
5.1 Жизненный цикл TCP-соединения
a. Клиент выбирает номер начальной последовательности (ISN) и отправляет пакет серверу с установленным битом SYN для открытия соединения.
b. Сервер получает пакет с битом SYN и, если готов к установлению соединения, то:
- Выбирает собственный номер начальной последовательности;
- Устанавливает SYN-бит, чтобы сообщить о выборе начальной последовательности;
- Копирует ISN клиента +1 в поле ACK и добавляет ACK-флаг для обозначения подтверждения получения первого пакета.
- Увеличивает номер своей начальной последовательности;
- Увеличивает номер подтверждения получения;
- Устанавливает поле ACK.
- Когда одна сторона отправляет N байтов, то увеличивает значение поля SEQ на это число.
- Когда вторая сторона подтверждает получение этого пакета (или цепочки пакетов), она отправляет пакет ACK, в котором значение поля ACK равняется последней полученной последовательности.
- Сторона, которая хочет закрыть соединение, отправляет пакет FIN;
- Другая сторона подтверждает FIN (с помощью ACK) и отправляет собственный FIN-пакет;
- Инициатор прекращения соединения подтверждает получение FIN отправкой собственного ACK.
6. TLS handshake
Сервер отвечает специальным кодом, который обозначает статус запроса и включает ответ следующей формы:
200 OK
[заголовки ответа]
304 Not Modified
[заголовки ответа]
и, соответственно, клиенту не посылается никакого контента, вместо этого браузер «достаёт» HTML из кэша.
— Сервер разбирает запрос по следующим параметрам:
— Сервер проверяет, имеет ли клиент право использовать этот метод (на основе IP-адреса, аутентификации и прочее).
— Если на сервере установлен модуль перезаписи ( mod_rewrite для Apache или URL Rewrite для IIS), то он сопоставляет запрос с одним из сконфигурированных правил. Если находится совпадающее правило, то сервер использует его, чтобы переписать запрос.
— Сервер находит контент, который соответствует запросу, в нашем случае он изучит индексный файл.
— Далее сервер разбирает («парсит») файл с помощью обработчика. Если Google работает на PHP, то сервер использует PHP для интерпретации индексного файла и направляет результат клиенту.
8. За кулисами браузера
Задача браузера заключается в том, чтобы показывать пользователю выбранные им веб-ресурсы, запрашивая их с сервера и отображая в окне просмотра. Как правило такими ресурсами являются HTML-документы, но это может быть и PDF, изображения или контент другого типа. Расположение ресурсов определяется с помощью URL.
Способ, который браузер использует для интерпретации и отображения HTML-файлов описан в спецификациях HTML и CSS. Эти документы разработаны и поддерживаются консорциумом W3C (World Wide Wib Consortium), которая занимается стандартизацией веба.
Интерфейсы браузеров сильно похожи между собой. У них есть большое количество одинаковых элементов:
- Адресная строка, куда вставляются URL-адреса;
- Кнопки возврата на предыдущую и следующую страницу;
- Возможность создания закладок;
- Кнопки обновления страницы (рефреш) и остановки загрузки текущих документов;
- Кнопка «домой», возвращающая пользователя на домашнюю страницу.
Высокоуровневая структура браузера
Браузер включает следующие компоненты:
9. Парсинг HTML
Движок рендеринга начинает получать содержимое запрашиваемого документа от сетевого механизма браузера. Как правило, контент поступает кусками по 8Кб. Главной задачей HTML-парсера является разбор разметки в специальное дерево.
Получающееся на выходе дерево («parse tree») — это дерево DOM-элементов и узлов атрибутов. DOM — сокращение от Document Object Model . Это модель объектного представления HTML-документа и интерфейс для взаимодействия HTML-элементов с «внешним миром» (например, JavaScript-кодом). Корнем дерева является объект «Документ».
Алгоритм разбора
HTML-нельзя «распарсить» с помощью обычных анализаторов (нисходящих или восходящих). Тому есть несколько причин:
- Прощающая почти что угодно природа языка;
- Тот факт, что браузеры обладают известной толерантностью к ошибкам и поддерживают популярные ошибки в HTML.
- Процесс парсинга может заходить в тупик. В других языках код, который требуется разобрать, не меняется в процессе анализа, в то время как в HTML с помощью динамического кода (например, скриптовые элементы, содержащие вызовы document.write() ) могут добавляться дополнительные токены, в результате чего сам процесс парсинга модифицирует вывод.
Алгоритм состоит из двух этапов: токенизации и создания дерева.
Действия после завершения парсинга
После этого браузер начинает подгружать внешние ресурсы, связанные со страницей (стили, изображения, скрипты и так далее).
На этом этапе браузер помечает документ, как интерактивный и начинает разбирать скрипты, находящиеся в «отложенном» состоянии: то есть те из них, что должны быть исполнены после парсинга. После этого статус документа устанавливается в состояние « complete » и инициируется событие загрузки (« load »).
Важный момент: ошибки «Invalid Syntax» при разборе не может быть, поскольку браузеры исправляют любой «невалидный» контент и продолжают работу.

Когда вы посещаете веб-сайт в Интернете, ваш браузер только подключается к удаленному компьютеру (веб-серверу) и запрашивает ресурсы для раскраски страницы. Это может показаться тривиальным, но под капотом ваш браузер обрабатывает миллионы чисел, чтобы найти и отобразить веб-сайт на вашем экране.
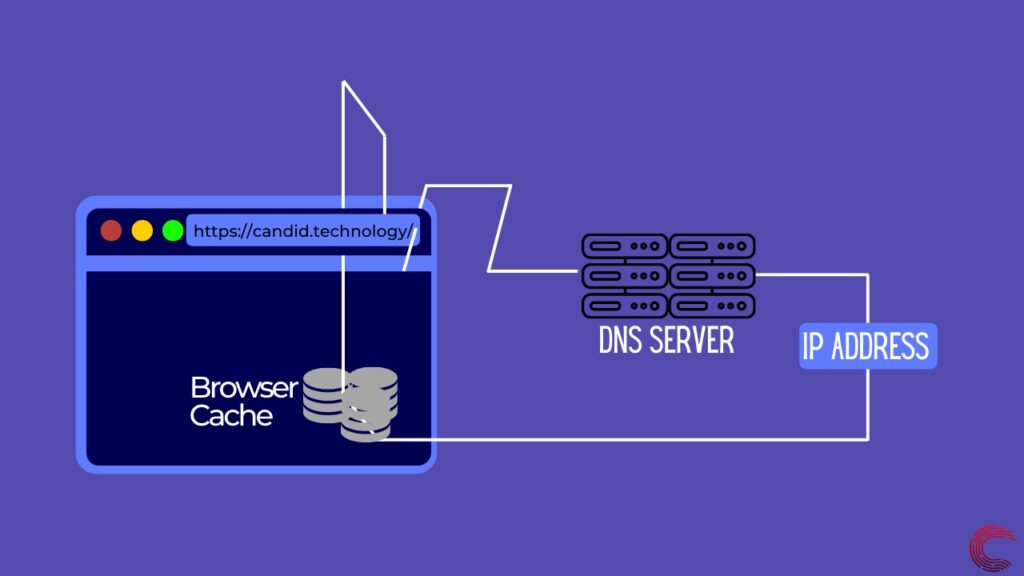
Чтобы найти IP-адрес, браузер выполняет разрешение DNS, которое можно сделать только двумя способами. Он может либо заглянуть в кеш-память вашего браузера, которая может содержать IP-адрес URL-адреса, если вы посещали сайт в прошлом. Если это не так, он запрашивает у вашего интернет-провайдера, Google или Cloudflare IP-адрес определенного веб-сайта, используя их DNS-серверы.
Как только ваш браузер получит IP-адрес веб-сайта, который вы ищете, сетевой уровень вашего браузера начнет работать. Он пытается установить соединение между вашим устройством и сервером, чтобы данные могли передаваться между двумя устройствами. Для создания этого соединения сетевой уровень использует сокеты, которые представляют собой способ соединения двух устройств в сети с использованием их IP-адреса и назначенного порта на каждом устройстве.
Чтобы зашифровать данные, сетевой уровень выполняет рукопожатие TLS между двумя взаимодействующими устройствами. После завершения рукопожатия все данные, передаваемые между устройствами, зашифровываются и не могут быть прочитаны третьими лицами.
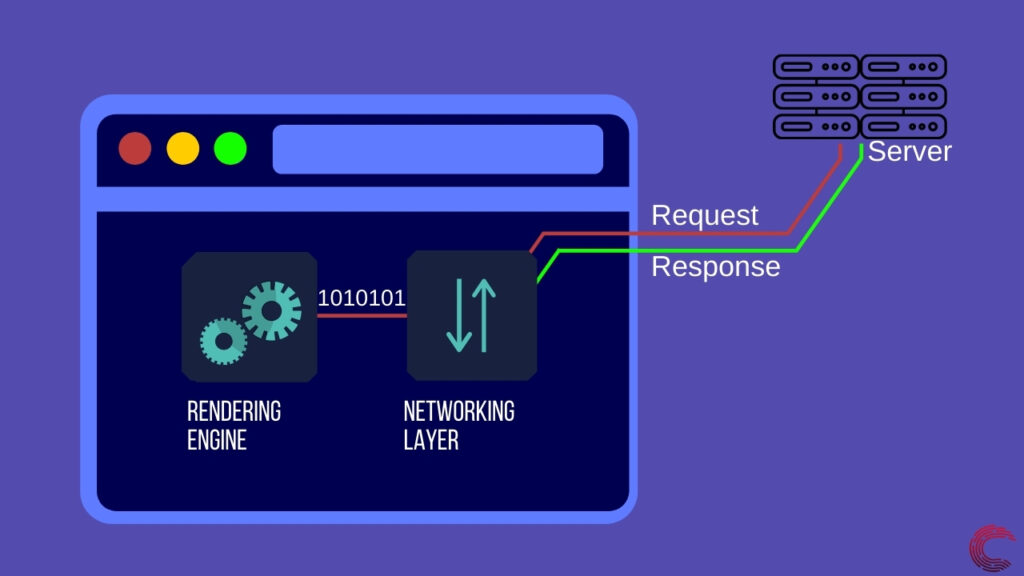
Наконец, в браузере есть ресурсы, необходимые для отображения веб-страницы, но они представлены в виде байтов и должны быть преобразованы в формат, который выглядит как веб-страница. Для этого браузер использует свой механизм рендеринга.
Теперь, когда сетевой уровень сделал запросы к веб-серверу и получил все данные, необходимые браузеру, на сцену выходит механизм визуализации.
- HTML (язык гипертекстовой разметки) используется для определения структуры веб-страницы.
- CSS (каскадные таблицы стилей) используются для указания браузеру, как должен выглядеть каждый элемент на веб-сайте.
- Javascript используется для добавления интерактивности сайту и используется для обработки пользовательского ввода, кликов или любой другой обработки, которая может понадобиться сайту.
Механизм визуализации использует синтаксические анализаторы для преобразования битов данных в значимую информацию, которая может использоваться браузером для визуализации веб-страницы. Механизм рендеринга имеет два разных парсера: один для HTML и один для CSS. Давайте посмотрим, как работает анализатор HTML, чтобы получить представление о процессе синтаксического анализа.
Разбор HTML
Анализатор HTML принимает биты данных в качестве входных данных и создает логическое представление документа HTML в памяти устройства. Это логическое представление данных известно как структура DOM и представляет данные HTML в иерархическом порядке.
Чтобы создать структуру DOM, парсер HTML выполняет несколько шагов, которые можно описать следующим образом.
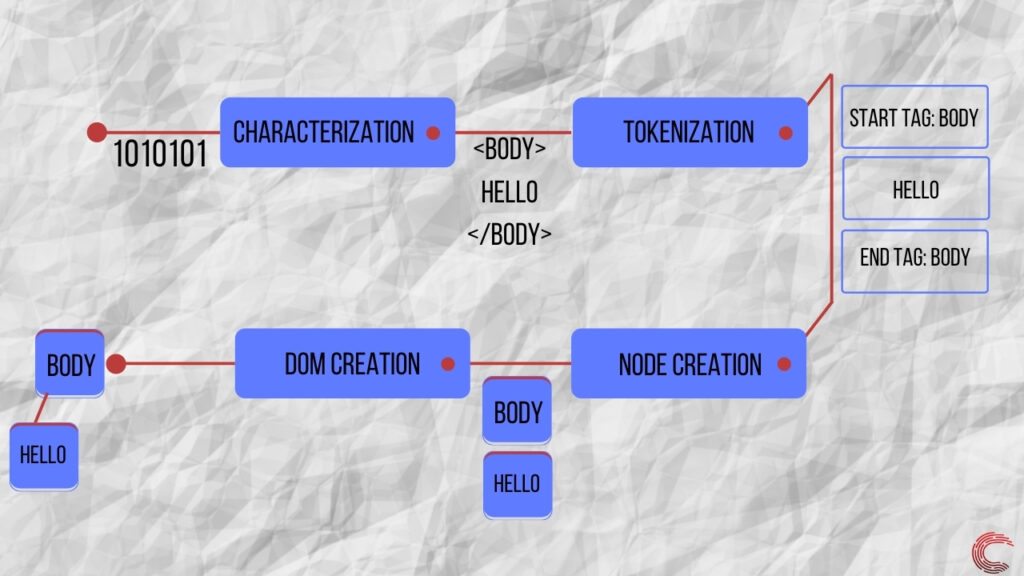
- Характеризация извлекает символы из байтов информации, которую анализатор HTML получает с сетевого уровня.
- Токенизация находит токены в потоке символов, который помогает браузеру определять структуру данных.
- Создание узла После идентификации токенов и содержащейся в них информации браузер создает узлы памяти для хранения этих данных.
- Создание DOM парсер иерархически связывает узлы памяти для создания DOM-представления полученных байтов данных.
HTML-документ, который получает браузер, содержит ссылки на файлы CSS. Эти ссылки обрабатываются сетевым уровнем и отправляются синтаксическому анализатору CSS. Этот синтаксический анализатор создает вывод CSSOM (объектная модель CSS), который определяет, как должен быть стилизован каждый элемент в DOM.
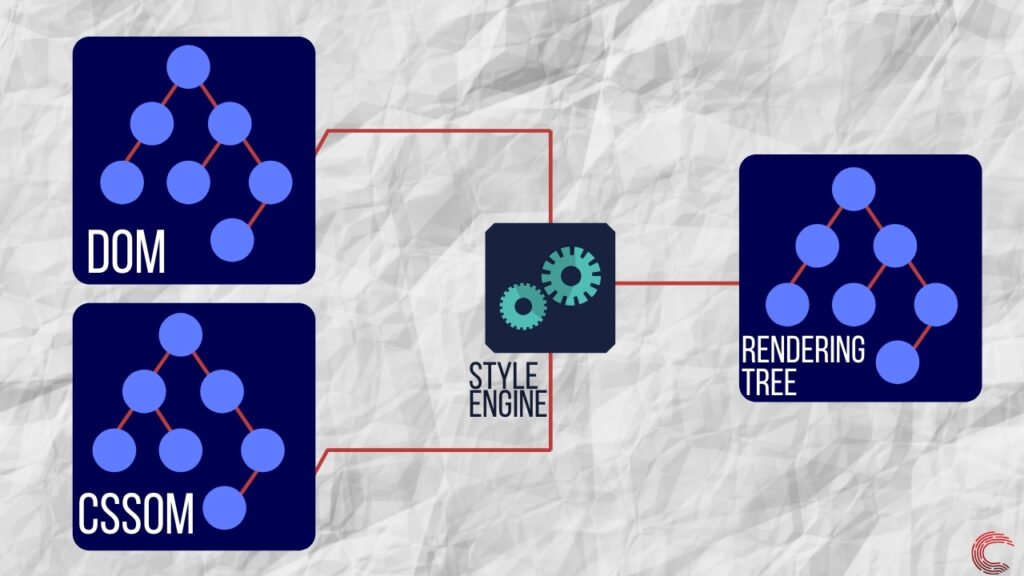
Создание дерева отрисовки и макета для веб-страницы
После создания модели DOM и завершения синтаксического анализа CSS-файла механизм визуализации использует механизм стилей для объединения как CSSOM, так и DOM. Это создает дерево визуализации, которое содержит информацию о структуре и стиле веб-страницы, которая должна отображаться. Дерево рендеринга состоит только из видимых узлов и не имеет узлов, невидимых для пользователя на экране.
После создания дерева рендеринга механизм рендеринга запускает процесс компоновки. Этот процесс учитывает разрешение экрана и то, как каждый элемент должен быть размещен на устройстве. Он также вычисляет размер каждого элемента, который будет отображаться на экране, и его относительное положение по отношению к другим элементам.
Теперь, когда движок рендеринга имеет всю информацию о веб-странице в формате, понятном нашей системе, мы можем начать рендеринг страницы в браузере.
Рисование холста и компоновка веб-страницы на экране
После того, как механизм рендеринга завершил процесс макета, ему необходимо нарисовать каждый пиксель на экране в соответствии с макетом, который был создан с использованием дерева рендеринга. Этот процесс известен как растеризация , то есть процесс рисования экрана. Большинство браузеров используют ЦП для выполнения этой задачи, но, поскольку это процесс, который включает в себя повторяющуюся обработку, для получения лучших результатов его можно передать на ГП.
Операция рисования происходит в многоуровневом формате, и механизм визуализации создает несколько слоев элементов для создания веб-страницы. Эта многоуровневая структура помогает браузеру быстрее вносить изменения, когда пользователь взаимодействует с веб-страницей.
После того, как все слои созданы, механизм визуализации отправляет эту информацию в пользовательский интерфейс, отображая веб-страницу на экране. Этот процесс известен как создание веб-страницы и является последним шагом, выполняемым механизмом рендеринга.
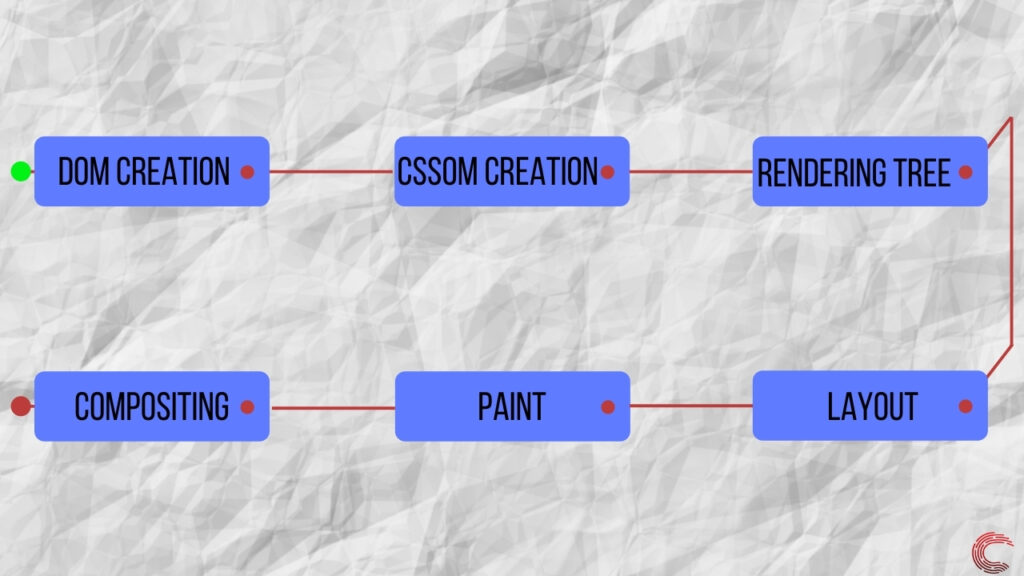
Этот процесс создания веб-страницы из битов данных известен как критический путь отрисовки и является основным фактором, определяющим производительность любой веб-страницы, которую вы посещаете в Интернете.
Теперь, когда механизм рендеринга отрисовал веб-сайт в браузере, вам может быть интересно, что мы нигде не использовали Javascript. Это связано с тем, что Javascript является независимым объектом, который отвечает за внесение изменений в структуру DOM, которая добавляет интерактивности веб-сайту.
После того, как механизм рендеринга завершил рендеринг веб-сайта в пользовательском интерфейсе, пользователь может видеть веб-сайт, но он еще не является интерактивным. Это означает, что если на веб-странице есть кнопка, которая показывает пользователю подсказку, она не будет работать, а Javascript появится на картинке.
Javascript также может вносить изменения в структуру DOM, созданную механизмом рендеринга, и даже создавать новые узлы DOM и подключать их к структуре DOM. Этот код Javascript запускается виртуальной машиной в браузере, известной как механизм Javascript.

Механизм Javascript и структура DOM не используют одну и ту же память и являются независимыми объектами. Тем не менее, движок Javascript может взаимодействовать со структурой DOM и запускаться, когда на странице происходит определенное событие. Это различие между двумя пробелами помогает браузеру отображать страницы с помощью механизма Javascript и отображать их при возникновении события.
В те дни, когда был изобретен Интернет, все браузеры отображали веб-страницы, и при этом не было задействовано много Javascript. Удаленный сервер выполнял большую часть обработки, а движок Javascript мало что делал на веб-странице. Из-за этого большой объем информации должен был передаваться между сервером и браузером, и такая архитектура подходила для Интернета, когда страницы не были такими сложными и интерактивными.
Тем не менее, современный Интернет не может работать на той же архитектуре, поскольку это сильно замедляет работу веб-сайтов. Следовательно, и браузер, и удаленный сервер должны работать симбиотически, чтобы обеспечить лучший пользовательский интерфейс. Это означает, что браузер больше не отвечает только за отображение веб-страниц, но также за обработку большого количества данных, и все это делает движок Javascript.
Javascript дебютировал в 1996 году и был создан Бренданом Эйхом всего за 10 дней. Он был частью Netscape Navigator версии 3 и был создан как язык сценариев, который можно было интерпретировать в самом браузере.
Поскольку Javascript был создан как язык, который мог обрабатываться интерпретатором в веб-браузере, он не создавал машинный код для работы на ЦП, что делало язык чрезвычайно универсальным.
Тем не менее, эта универсальная природа Javascript имела компромисс; низкая производительность. Чтобы решить эту проблему, JIT-компиляторы пришли к Javascript, что сделало их очень быстрыми. Использование JIT-компиляторов сделало Javascript настолько быстрым, что он работает на сервере, на котором размещены ваши веб-сайты.
Теперь, когда мы знакомы с ролью Javascript в работе веб-сайта, мы можем подробно разобраться в том, как работает механизм Javascript.
Как работает движок Javascript?
Точно так же, как сетевой уровень извлекает HTML и CSS в виде байтов для механизма рендеринга, он также извлекает код Javascript и передает его механизму Javascript.
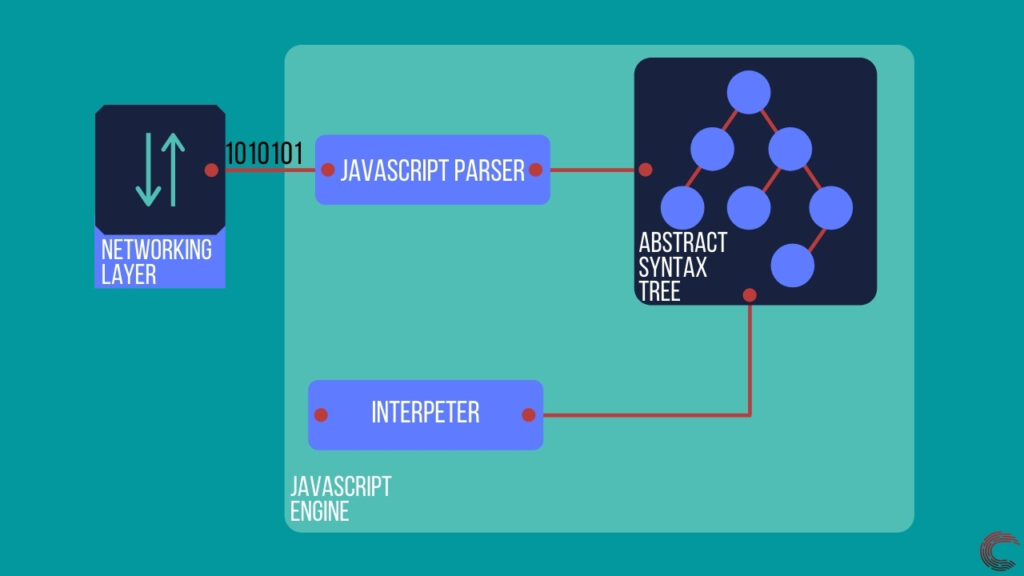
Как только движок получает код Javascript, он отправляет его синтаксическому анализатору, который создает абстрактное синтаксическое дерево (AST). Это дерево является логическим представлением кода Javascript, который может быть запущен компилятором. Компилятор преобразует дерево в промежуточный язык (байт-код), который может выполняться интерпретатором построчно.
Это выполнение Javascript используется, когда код в скрипте не выполняет повторяющиеся задачи (например, цикл). Если в коде Javascript есть обширные циклы, то движок пытается оптимизировать этот код и запускать его на ЦП устройства. Поскольку код выполняется на ЦП машины, он работает намного быстрее по сравнению с интерпретируемой версией.
Для создания машинного кода механизм Javascript использует оптимизирующий компилятор. Этот компилятор принимает байт-код, сгенерированный компилятором, и преобразует его в машинный код для конкретного устройства.
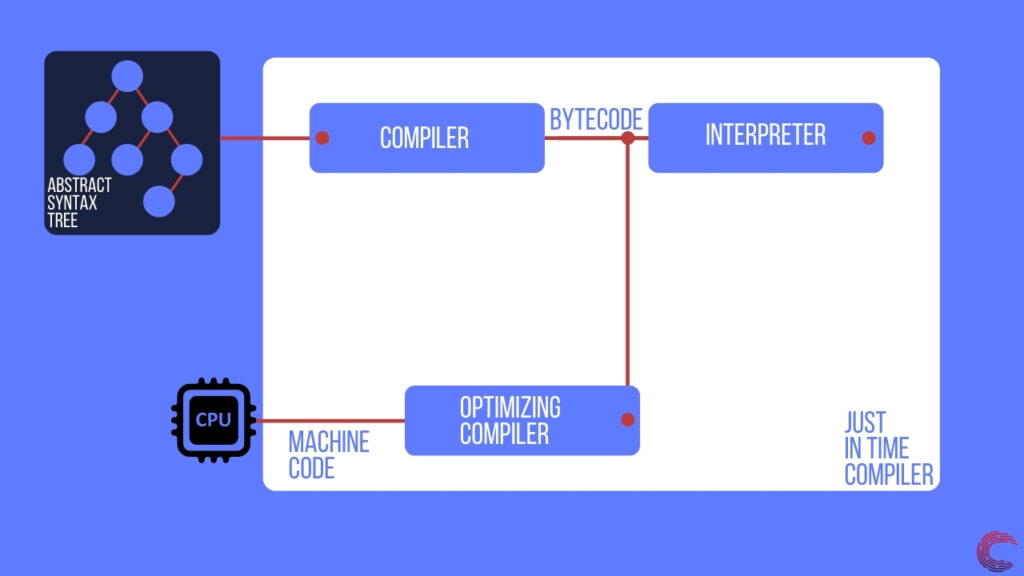
Как только у движка есть оптимизированный машинный код, он может запускать скрипт на невероятно высокой скорости, используя как процессор, так и интерпретатор Javascript.
Хотя браузеры сейчас супер мощные, постоянно появляются инновации, которые еще больше ускоряют просмотр. Одним из таких нововведений является веб-сборка, которая используется с Javascript, чтобы сделать выполнение кода еще быстрее за счет использования кода уровня сборки.
Мало того, браузеры догоняют достижения в области машинного обучения и искусственного интеллекта. С такими библиотеками, как Tensorflow, переход на Javascript означает только то, что браузеры обязательно станут умнее в будущем; дальнейшее улучшение пользовательского опыта, который они предлагают.

На собеседованиях мы часто просим кандидата рассказать настолько подробно, насколько он может, что происходит, когда вводишь в адресной строке браузера адрес сайта и нажимаешь кнопку “Ввод”. В зависимости от того, кого собеседуем — фронтендщика или бекендщика — мы ожидаем разные ответы. А как бы выглядел идеальный ответ на этот вопрос? Ниже мой вариант ответа.
Итак, пользователь вводит в адресной строке браузера адрес сайта и нажимает кнопку “Ввод”.
Браузер состоит из нескольких компонентов, одним из которых является User Interface. Адресная строка как раз является одной из частей этого компонента.
User Interface после ввода URL в адресной строке передаёт управление компоненту Browser Engine, который отвечает за взаимодействие различных компонентов браузера.
Чтобы сделать запрос по указанному URL, браузеру нужно знать IP сервера. Первым делом он смотрим в свой локальный кэш DNS.Компонент Browser Engine как раз имеет доступ к этому кэшу.
Если там нет соответствующей записи, то браузер передаёт управление операционной системе, которая проверяет свой кэш DNS. Если и там отсутствует соответствующая запись, то ОС смотрит в локальные хосты (файл /etc/hosts в Unix-системах). Если запись о хосте отсутствует, то операционная система обращается к интернет провайдеру, у которого тоже есть свой кэш DNS на своих рекурсивных серверах DNS. В случае отсутствия записи в кэше на серверах DNS провайдера, запрос идёт на корневой DNS. У корневого DNS тоже есть кэш. Если соответствующей записи в кэше корневого DNS нет, запрос идёт дальше по цепочке серверов DNS.
Если на любом из этапов находится нужная запись, то она сохраняется во всех кэшах и управление возвращается браузеру, который уже знает IP нужного сервера.
Процесс получения IP адреса называется DNS lookup.
На сервере запрос принимает веб-сервер (например, nginx или apache).
В конфигурационных файлах веб-сервера прописаны обслуживаемые хосты. Веб-сервер достаёт хост из заголовка запроса host и сопоставляет с теми, которые указаны в конфигурации. Если есть совпадение, то веб-сервер находит в конфигурационном файле правила обработки такого запроса и выполняет их. Дальнейшее поведение сервера зависит от технологии и особенностей приложения. Здесь может происходить работа с базами данных, кэшами, запросы к другим серверам и сервисам, выполнение различных скриптов. Для простоты представим, что приложение сгенерировало файл HTML, и веб-сервер отдал его браузеру.
Заголовки ответа сервера можно увидеть в Chrome DevTools на вкладке Networking, выбрав нужный запрос
Если длина контента больше нуля и тип контента поддерживается браузером, то браузер пытается его обработать. В нашем случае браузер получает файл HTML с соответствующим заголовком Content-Type. Браузер начинает разбор (parsing) этого файла с первой инструкции, которой является инструкция <!DOCTYPE>. DOCTYPE указывает на версию HTML, чтобы браузер понимал, каким правилам следовать во время разбора (какие теги как обрабатывать).
Если DOCTYPE отсутствует, то браузер переключится в режим quirks mode и попытается разобрать документ HTML, однако многие элементы будут проигнорированы. Если указан корректный DOCTYPE, то браузер будет работать в standards mode и будет разбирать документ в соответствии с правилами той версии, которая указана в DOCTYPE.
Rendering Engine начинает разбор документа HTML.
Создаётся DOM (Document Object Model). В браузере этот объект доступен по ссылке, которая хранится в переменной document. У документа есть несколько состояний. Первое состояние — loading. Оно означает, что документ только начал формироваться.
Состояние документа хранится в переменной document.readyState.
Также создаётся объект styleSheets, который будет хранить все стили.
Все стили на странице доступны по ссылке, которая хранится в переменной document.styleSheets.
Любой файл — это набор байтов. Браузер берёт полученный набор байтов и преобразует их в символы по таблице символов в соответствии с кодировкой, которая была передана в заголовке Content-Type. В нашем примере это кодировка UTF-8.
Следующий процесс —разбивание текста на смысловые блоки (tokenization). Так браузер распознаёт теги <html>, <head> и проч., а также понимает, какие правила к какому тегу применять (например, поддерживаемые атрибуты).
Далее токены собираются в узлы (nodes). Эти узлы и сохраняются в DOM со всеми взаимными связями.
Во время разбора, если Rendering Engine встречает ссылку на внешний ресурс, то он передаёт команду загрузить этот ресурс компоненту Networking Component. Это может быть ссылка на стили, скрипты, картинки и т.п. Networking Component ставит все ресурсы в очередь на загрузку. Каждому ресурсу Networking Component присваивает приоритет.
Приоритеты ресурсов можно посмотреть в Chrome DevTools на вкладке Networking в колонке Priority.
Так, у HTML, CSS и шрифтов самый высокий приоритет. У изображений приоритет изначально низкий, но если Rendering Engine обнаружит, что изображение попадает в поле видимости (view port) пользователя, то повысит приоритет до среднего. Приоритет скрипта зависит от положения на странице и способа загрузки. У асинхронных скриптов (async/defer) низкий приоритет. У скриптов, которые в документе перед изображениями — высокий, у тех, что после хотя бы одного изображение — средний.
По возможности браузер пытается загружать ресурсы параллельно. Однако, он не может загружать параллельно более 6 ресурсов с одного домена.
Кроме того, когда Rendering Engine отдаёт команду компоненту Networking Component на синхронную загрузку стиля или скрипта, он останавливает разбор документа.
С загрузкой стилей происходит подобный процесс преобразования из байтов в Object Model (CSSOM): байты -> символы -> токены -> узлы -> CSSOM.
Немного иначе происходит загрузка скрипта. Вместо того, чтобы вернуть управление Rendering Engine’у, Networking Component . передаёт управление JavaScript Interpreter, который преобразует байты в исполняемый код: байты -> символы -> токены -> Abstract Syntax Tree (evaluating). Далее в работу вступает компилятор, который оптимизирует AST, кэширует некоторые участки кода, компилирует его на лету (JIT compilation) в исполняемый код и исполняет (executing). Однако исполняется скрипт только, когда готова CSSOM. До тех пор скрипт стоит в очереди на исполнение.
Во многих современных браузерах во время исполнения JavaScript в отдельном потоке продолжается сканирование документа на наличие ссылок на другие ресурсы и постановка ресурсов в очередь на скачивание (Speculative parsing).
Каждый этап разбора HTML, CSS и JS можно увидеть в Chrome DevTools во вкладке Performance
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут async, то он не останавливает разбор документа во время загрузки скрипта. Скрипт также станет в очередь на исполнение, дожидаясь, когда CSSOM будет готова.
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут defer, то он не останавливает разбор документа во время загрузки скрипта, но когда скрипт загрузится, он станет в очередь на исполнение, которая заработает при возникновении события DOMContentLoaded. К этому моменту CSSOM будет уже готова.
Когда Rendering Engine заканчивает разбор документа, он вызывает событие DOMContentLoaded, и состояние документа меняется на interactive. При этом ресурсы (например, картинки) могут продолжать загружаться.
Когда все ресурсы загрузились, вызывается событие load, а состояние документа меняется на complete.
После того, как документ полностью разобран и сформированы DOM и CSSOM, Rendering Engine начинает построение Render Tree. В него попадут все элементы, которые нужно отрисовать. Некоторые элементы изначально могут быть невидимыми — их не нужно рисовать. Для каждого элемента, который “выпадает” из потока (например, используется position: absolute), будет создаваться отдельная ветка в Render Tree.
Во время Rendering Tree происходит сопоставление узлов из DOM и узлов CSSOM.
Свойства узла можно получить с помощью функции window.getComputedStyles(узел).
Когда Rendering Tree готов, Rendering Engine запускает процесс layout. Он заключается в вычислении размеров и позиций каждого элемента на странице.
Следующий этап — paint. Rendering Engine вычисляет цвет каждого пикселя.
И, наконец, последний этап — composite. Компонент UI Backend слой за слоем отрисовывает элементы на странице. При этом, если требуется отрисовать изображение, которое ещё не загрузилось, во время процесса layout, Rendering Engine зарезервирует место для изображения, если у него указаны ширина и высота. Rendering Engine вынесет на отдельный слой те элементы, стили которых содержат правила opacity, transform или will-change. Более того, эти слои Rendering Engine передаст для обработки GPU.
Если требуется отобразить текст, для которого используется нестандартный шрифт, то современные браузеры скроют текст до момента загрузки шрифта (flash of invisible text).
В современных браузерах скачивание документа, его разбор и отрисовка происходят по кускам, частями.
В документе HTML могут присутствовать некоторые мета-теги, которые могут менять порядок загрузки ресурсов, а также их приоритет.
К примеру, мета-тег dns-prefetch вынуждает Rendering Engine обратиться к Networking Component и получить IP нужного домена ещё до того, как Rendering Engine встретить его в документе.
Мета-тег prefetch вынудит Networking Component поставить указанный ресурс в очередь на загрузку с низким приоритетом.
Мета-тег preload вынудит Networking Component поставить указанный ресурс в очередь на загрузку с высоким приоритетом.
Мета-тег preconnect вынудит Networking Component заранее подключиться к другом хосту, то есть пройти нужные этапы: DNS lookup, redirects, hand shakes.
Читайте также: