
На основе каких интерфейсов может взаимодействовать веб сервер и веб приложение
Что такое архитектура веб-приложений? Из этого руководства вы можете изучить основы архитектуры веб-приложений. Мы обсудим, как работает архитектура веб-приложения, какие компоненты, слои и модели существуют
Архитектура веб-приложения в основном представляет отношения и взаимодействия между такими компонентами, как пользовательские интерфейсы, мониторы обработки транзакций, базы данных и другие. Основная цель - убедиться, что все элементы правильно работают вместе.
Логика довольно проста: когда пользователь вводит URL-адрес в браузере и нажимает «ввод», браузер делает запрос к серверу. Сервер отвечает, а затем показывает требуемую веб-страницу. Все эти компоненты создают архитектуру веб-приложения.
Как работает системная архитектура для веб-приложений?
Все приложения состоят из двух частей - клиентской (front-end) и серверной (back-end).
Поэтому, когда вы вводите свои учетные данные в регистрационную форму, вы имеете дело с внешним интерфейсом, но как только вы нажимаете «ввод» и регистрируетесь - это серверная часть заставляет его работать.
При правильной работе клиентская и серверная стороны составляют архитектуру программного обеспечения веб-приложения.
Слои и компоненты архитектуры веб-приложений
Чтобы лучше понять архитектуру веб-приложения, вам следует погрузиться в его компоненты и уровни. Веб-приложения разделяют свои основные функции на уровни. Это позволяет заменять или обновлять каждый слой независимо.
Базовые компоненты архитектуры веб-приложений
Веб-архитектура имеет компоненты пользовательского интерфейса и структурные компоненты. Последние также делятся на клиентские и серверные.
Компоненты пользовательского интерфейса
Компоненты пользовательского интерфейса обозначают все элементы интерфейса, такие как журналы активности, информационные панели, уведомления, настройки и многое другое. Они являются частью макета интерфейса веб-приложения.
Структурные компоненты состоят из клиентской и серверной сторон:
Клиентский компонент разработан с HTML, CSS или JavaScript. Веб-браузеры запускают код и преобразуют его в интерфейс, поэтому нет необходимости в настройке операционной системы.
Уровни архитектуры веб-приложений
Существует четыре общих уровня веб-приложений:
- Уровень представления (PL)
- Уровень обслуживания данных (DSL)
- Уровень бизнес-логики (BLL)
- Уровень доступа к данным (DAL)
Уровень службы данных
DSL передает данные, обработанные уровнем бизнес-логики, на уровень представления. Этот уровень гарантирует безопасность данных, изолируя бизнес-логику со стороны клиента.
Уровень доступа к данным
DAL предлагает упрощенный доступ к данным, хранящимся в постоянных хранилищах, таких как двоичные файлы и файлы XML. Уровень доступа к данным также управляет операциями CRUD - создание, чтение, обновление, удаление.
Типы архитектуры веб-приложений
Можно выделить несколько типов архитектуры веб-приложений, в зависимости от того, как логика приложения распределяется между клиентской и серверной сторонами. Наиболее распространенные архитектуры веб-приложений:
- Одностраничные веб-приложения
- Многостраничные веб-приложения
- Архитектура микросервисов
- Бессерверная архитектура
- Прогрессивные веб-приложения
Одностраничное приложение или SPA
SPA - это веб-сайт или веб-приложение, которое загружает всю необходимую информацию при входе на страницу. Одностраничные приложения имеют одно существенное преимущество - они обеспечивают потрясающий пользовательский интерфейс, поскольку пользователи не испытывают перезагрузки веб-страниц. Одностраничные веб-приложения часто разрабатываются с использованием фреймворков JavaScript, таких как Angular, React и других.
Известные СПА : Gmail, Facebook, Twitter, Slack.
Многостраничное приложение или MPA
Многостраничные приложения более популярны в Интернете, так как в прошлом все веб-сайты были MPA. В наши дни компании выбирают MPA, если их веб-сайт довольно большой (например, eBay). Такие решения перезагружают веб-страницу для загрузки или отправки информации с / на сервер через браузеры пользователей.
Известные MPA: eBay, Amazon.
Одностраничное приложение или многостраничное приложение ? У многостраничного и одностраничного приложения есть недостатки и преимущества.
Архитектура микросервисов
Чтобы понять архитектуру микросервисов , лучше сравнить ее с монолитной моделью.
Традиционная монолитная архитектура веб-приложения состоит из трех частей - базы данных, клиентской и серверной сторон. Это означает, что внутренняя и внешняя логика, как и другие фоновые задачи, генерируются в одной кодовой базе. Чтобы изменить или обновить компонент приложения, разработчики программного обеспечения должны переписать все приложение.
Что касается микросервисов, этот подход позволяет разработчикам создавать веб-приложение из набора небольших сервисов. Разработчики создают и развертывают каждый компонент отдельно.
Архитектура микросервисов выгодна для больших и сложных проектов, поскольку каждый сервис может быть изменен без ущерба для других блоков. Поэтому, если вам нужно обновить логику оплаты, вам не придется на время останавливать работу сайта.
Известные проекты: Netflix, Uber, Spotify, PayPal.
- Монолитные и микросервисы
- Бессерверная архитектура
Что это означает?
Чтобы сохранить веб-приложение в Интернете, разработчики должны управлять серверной инфраструктурой (виртуальной или физической), операционной системой и другими процессами хостинга, связанными с сервером. Поставщики облачных услуг, такие как Amazon или Microsoft, предлагают виртуальные серверы, которые динамически управляют распределением машинных ресурсов. Другими словами, если ваше приложение испытывает огромный всплеск трафика, к которому ваши серверы не готовы, приложение не будет отключено.
Прогрессивные веб-приложения или PWA
Одна из основных тенденций в разработке веб-приложений последних лет - это прогрессивные веб-приложения. Это веб-решения, которые работают как собственные приложения на мобильных устройствах. PWA предлагают push-уведомления, автономный доступ и возможность установить приложение на домашний экран.
Для создания PWA разработчики используют «языки веб-программирования», такие как HTML, CSS и JavaScript. Если приложению требуется доступ к функциям устройств, разработчики используют дополнительные API - NFC API, API геолокации, Bluetooth API и другие.
Известные PWA: Uber, Starbucks, Pinterest.
Как разработать архитектуру для веб-приложения
Качественная архитектура веб-приложения делает процесс разработки более эффективным и простым. Веб-приложение с продуманной архитектурой легче масштабировать, изменять, тестировать и отлаживать.
Цель лекции: дать определение понятию "веб-сервер" и сформировать представление о работе этого механизма.


Одной из наиболее важных задач, которые решаются при построении веб-сервера является задача обеспечения масштабируемости (т.е. возможности увеличения количества обслуживаемых пользователей) и защищенности от внешних атак. Поскольку веб-сервер работает в открытой среде – глобальной сети Интернет – то зачастую доступ к нему может осуществляться откуда угодно. Это делает веб-сервер подверженным большим нагрузкам и потенциальным атакам. Наиболее распространенными атаками на веб-сервер является обращение к веб-серверу с большим количеством запросов и их высокой частотой. В этом случае веб-сервер не сможет быстро обрабатывать все запросы, а это может сказаться на производительности веб-сервера для настоящих пользователей. Особенно остро подобным атакам подвержены веб-сервера, на которых исполняется какой-то внешний программный код за исключением программного кода самого веб-сервера. Обычно для борьбы с подобными атаками блокируются все запросы, которые приходят с определенного IP-адреса. Кроме того, в подобных случаях следует позаботится об оптимизации программного кода приложения, например, использовать кэширование – в этом случае при обработке каждого запроса нагрузка на центральный процессор будет меньше, что может существенно усложнить задачу атакующим.


При анализе HTTP-запросов хорошо видно, что HTTP-заголовок " Host " отличается в каждом из запросов. Таким образом, становится понятно, что веб-сервер анализирует этот заголовок и отправляет клиенту содержимое соответствующего сайта. Схематически этот процесс можно представить следующим образом.
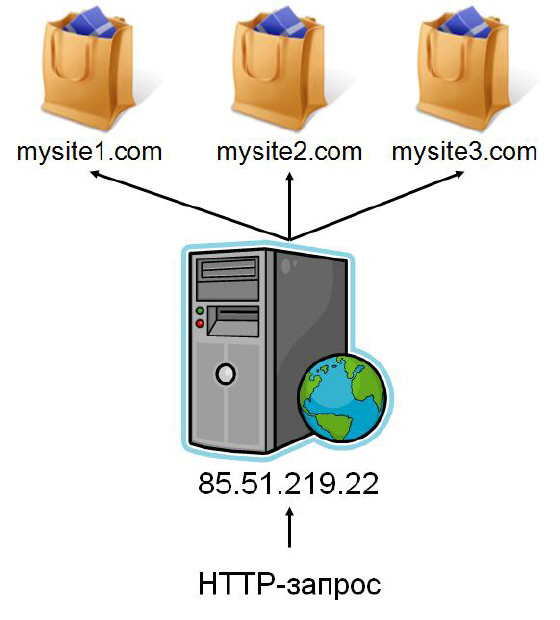
Подобную схему виртуального хостинга использует большинство компаний, занимающихся размещением веб-сайтов в Интернет. Поскольку в этом случае на одном физическом сервере могут размещаться большое количество совершенно различных сайтов, то этот способ один из самых дешевых. Однако, в рамках виртуального хостинга обычно запрещено запускать различные службы и сервисы, а также существует ограничение по степени использования центрального процессора. Это означает, что в случае, когда веб-сайт потребляет слишком много серверных ресурсов, то владельцу сайта предлагается либо перейти на более дорогой тариф (с большим количеством выделенных ресурсов), либо при превышении допустимого порогового значения веб-сайт блокируется на некоторое время. Поскольку иногда от сервера требуется большое количество ресурсов или в рамках этого сервера необходимо запускать дополнительные приложения или службы, виртуальный хостинг можно использовать не всегда. В этом случае обычно арендуют выделенный сервер – физический или виртуальный. Однако, это более дорогой вид размещения веб-приложений в сети Интернет, поэтому зачастую используется именно виртуальный хостинг.
Поскольку программный код веб-приложения обычно упаковывается в отдельные модули и поставляется независимо, то требуются механизмы взаимодействия этих двух частей, т.е. интерфейс взаимодействия. В данном случае под интерфейсом взаимодействия понимается набор правил, по которым веб-сервер и приложение будут взаимодействовать друг с другом. Фактически, схема обработки запроса может выглядеть следующим образом.

Исторически сложилось так, что существует два главных типов интерфейс взаимодействия внешнего приложения и веб-сервера - CGI и ISAPI.
С другой стороны, необходимость создания каждый раз нового процесса влечет за собой дополнительные накладные расходы на создание процесса (создание процесса – дорогостоящая операция с точки зрения операционной системы) и передачи данных через границы процессов. Этот факт является серьезным недостатком и оказывает существенное влияние на масштабируемость веб-приложения (возможность обрабатывать большее количество поступающих запросов).
ISAPI (Internet Server API) – альтернативный способ взаимодействия веб-сервера и веб-приложения. В отличии от CGI, при взаимодействии в рамках интерфейса ISAPI, при поступлении очередного запроса, веб-сервер инициирует создание нового потока в рамках основного процесса, в котором работает веб-сервер. Поскольку с точки зрения операционной системы создание потока – это менее дорогостоящая операция, чем создание процесса, то такие приложения на практике оказываются более масштабируемыми. Кроме того, упрощается взаимодействие веб-сервера и веб-приложения, поскольку в этом случае используется единое адресное пространство в рамках операционной системы (поскольку весь код работает в одном и том же процессе). Однако, в случае серьезных неполадок в веб-приложении, которое взаимодействует с веб-сервером в рамках ISAPI, веб-сервер также потенциально подвергается риску быть завершенным. Поскольку веб-сервер и веб-приложение работают в одном и том же процессе, это действительно так. Поэтому разработчикам программного кода веб-сервера, поддерживающего ISAPI следует уделить этому вопросу особое внимание.
В предыдущем материале мы рассмотрели, как работает Интернет на базовом уровне, включая взаимодействие между клиентом (вашим компьютером) и сервером (другим компьютером, который отвечает на запросы клиента о веб-сайтах).
В этой же части рассмотрим, как устроены клиент, сервер и веб-приложение, что мы можем удобно серфить в Интернете.
Модель клиент-сервер
На самом деле, модель клиент-сервер - это ни что иное, как способ описать отношения между клиентом и сервером в веб-приложении. Это детали того, как информация переходит от одного конца к другому, где картина усложняется.
Базовая конфигурация веб-приложения
Существует сотни способов настройки веб-приложения. При этом большинство из них следуют одной и той же базовой структуре: клиент , сервер , база данных .
Клиент
Клиент - это то, с чем взаимодействует пользователь. Так что «клиентский» код отвечает за большую часть того, что на самом деле видит пользователь. Это включает в себя:
- Определение структуры веб-страницы
- Настройка внешнего вида веб-страницы
- Реализация механизма пользовательского взаимодействия (нажатие кнопок, ввод текста и т.д.)
Структура : Макет и содержимое веб-страницы определяются с помощью HTML (обычно HTML 5, если речь идет о современных веб-приложениях, но это другая история.)
HTML означает язык гипертекстовой разметки (Hypertext Markup Language). Он позволяет описать основную физическую структуру документа с помощью HTML-тэгов. Каждый HTML-тэг описывает определенный элемент документа.
- Содержимое тега «<h1>» описывает заголовок.
- Содержимое тега «<p>» описывает абзац.
- Содержимое тега «<button>» описывает кнопку.
- И так далее.
Веб-браузер использует эти HTML-тэги для определения способа отображения документа.
Look and Feel : Чтобы определить внешний вид веб-страницы, веб-разработчики используют CSS , который расшифровывается как каскадные таблицы стилей (Cascading Style Sheets). CSS - это язык, который позволяет описать стиль элементов, определенных в HTML, позволяя изменять шрифт, цвет, макет, простые анимации и другие поверхностные элементы.
Стили для указанной выше HTML-страницы можно задать следующим образом:
Взаимодействие с пользователем : Наконец, для реализации механизма взаимодействия с пользователем, на сцену выходит JavaScript .
Например, если вы хотите что-то сделать, когда пользователь нажимает кнопку, вы можете сделать что-то подобное:
Иногда взаимодействие с пользователем, может быть реализовано без необходимости обращения к вашему серверу - отсюда и термин "JavaScript на стороне клиента". Другие типы взаимодействия требуют отправки запросов на сервер для обработки.
Например, если пользователь публикует комментарий в потоке, может потребоваться сохранить этот комментарий в базе данных, чтобы весь материал был структурирован и собран в одном месте. Таким образом, вы отправляете запрос на сервер с новым комментарием и идентификатором пользователя, а сервер прослушивает эти запросы и обрабатывает их соответствующим образом.
Сервер
База данных
Базы данных – это подвалы веб-архитектуры - большинство из нас боятся туда спускаться, но они критически важны для прочного фундамента. База данных - это место для хранения информации, чтобы к ней можно было легко обращаться, управлять и обновлять.
Например, при создании сайта в социальных сетях можно использовать базу данных для хранения сведений о пользователях, публикациях и комментариях. Когда посетитель запрашивает страницу, данные, вставленные на страницу, поступают из базы данных сайта, что позволяет нам воспринимать взаимодействие пользователей в реальном времени как должное на таких сайтах, как Facebook или в таких приложениях, как Gmail.
Как масштабировать простое веб-приложение
Вышеописанная конфигурация отлично подходит для простых приложений. Но по мере роста приложения один сервер не сможет обрабатывать тысячи - если не миллионы - одновременных запросов от посетителей.
Чтобы выполнить масштабирование в соответствии с этими большими объемами, можно распределить входящий трафик между группой внутренних серверов.
Ответ очевиден - никак. Управление всеми этими отдельными экземплярами приложения происходит через средство балансировки нагрузки.
Подсистема балансировки нагрузки действует как гаишник, который маршрутизирует клиентские запросы по серверам как можно быстрее и эффективнее, насколько это возможно.
Поскольку вы не можете транслировать IP-адреса всех экземпляров сервера, вы создаете виртуальный IP-адрес, который транслируется клиентам. Этот виртуальный IP-адрес указывает на подсистему балансировки нагрузки. Таким образом, когда DNS ищет ваш сайт, он указывает на балансировщик нагрузки. Затем подсистема балансировки нагрузки перескакивает для распределения трафика на различные внутренние серверы в реальном времени.
Возможно, вам интересно, как подсистема балансировки нагрузки узнаёт, на какой сервер следует отправлять трафик. Ответ: алгоритмы.
Один популярный алгоритм, Round Robin , включает равномерное распределение входящих запросов по ферме серверов (все доступные серверы). Вы обычно выбираете такой подход, если все ваши серверы имеют одинаковую скорость обработки и память.
С помощью другого алгоритма, Least Connections , следующий запрос отправляется на сервер с наименьшим количеством активных соединений.
Существует гораздо больше алгоритмов, которые вы можете реализовать, в зависимости от ваших потребностей.
Неопытные разработчики вряд ли поймут, что изображено на диаграмме ниже. Но без понимания концептуальных основ работы современного веба тяжело назвать себя хорошим веб-программистом. В материале будет приведено краткое объяснение, которое поможет разобраться в происходящем, а после каждый элемент будет разобран в деталях.

Пользователь ищет в Google «Strong Beautiful Fog And Sunbeams In The Forest». Первый результат отправляет его на Storyblocks. Пользователь нажимает на ссылку, которая перенаправляет его браузер на страницу с изображением. Тем временем браузер отправляет запрос на DNS-сервер, чтобы установить соединение со Storyblock, и, получив ответ, отправляет запрос на сайт.
Запрос попадает на балансировщик нагрузки, который случайным образом выбирает для обработки запроса один из десяти (или около того) веб-серверов, на которых запущен сайт. Веб-сервер достаёт некоторую часть информации об изображении из службы кэширования, а остальное — из основной базы данных. Если цветовой профиль для изображения ещё не был вычислен, задача «определить цветовой профиль» будет добавлена в очередь заданий. Эти задания серверы обрабатывают асинхронно и соответствующим образом обновляют базу данных с результатами.
Затем происходит поиск похожих фотографий: в службу полнотекстового поиска отправляется запрос с заголовком фотографии в качестве входных данных. Если пользователь авторизовался в Storyblocks, информация о его учётной записи загружается из базы данных учётных записей. Наконец, данные о просмотре страницы отправляются в firehose-хранилище для последующей записи в облачную систему хранения. В конечном счёте, эти данные будут загружены в хранилище данных, которое аналитики используют для обработки.
Далее будет рассказано про каждый элемент в деталях. Конечно, каждую тему можно рассмотреть гораздо подробнее, но в рамках этой статьи будут разобраны только основы. Этого должно хватить для понимания архитектуры современного веб-проекта.
Прежде чем начать обсуждение балансировки нагрузки, нужно сделать шаг назад, чтобы обсудить горизонтальное и вертикальное масштабирование приложений. Что это и в чём разница? Эта тема хорошо объяснена в посте на StackOverflow: «горизонтальное» масштабирование характеризуется добавлением новых машин в пул ресурсов, тогда как «вертикальное» подразумевает, что наращивается мощность (например, увеличивается CPU или RAM) существующей машины.
В веб-разработке проект масштабируется горизонтально как минимум потому, что всё ломается. Серверы падают по непонятным причинам. Сети деградируют. В некоторых ЦОД-ах время от времени отключается свет. Несколько серверов позволит переживать незапланированные отключения без нарушения работы приложения. Другими словами, приложение становится «отказоустойчивым». Горизонтальное масштабирование позволяет минимально связывать разные части проекта (веб-сервер, базу данных и т. д.), потому что каждая из них запускается на разных серверах. Наконец, может наступить такой момент, когда вертикальное масштабирование более невозможно, так как в мире нет достаточно мощного компьютера для выполнения всех вычислений приложения. Поисковая платформа Google является типичным примером, хотя это относится и к компаниям с гораздо меньшими масштабами. Например, Storyblocks обычно использует от 150 до 400 AWS-машин EC2 в любой момент времени. Было бы сложно получить всю эту вычислительную мощность с помощью вертикального масштабирования.
Давайте вернёмся к балансировщикам нагрузки. Благодаря им возможно горизонтальное масштабирование. Они направляют входящие запросы на один из множества серверов приложения, которые обычно являются зеркальными копиями друг друга, и отправляют ответ обратно пользователю. Любой сервер обрабатывает запросы одинаково, так что балансировщик занимается распределением заданий, чтобы никакой из них не был перегружен.
Вот и всё. Концептуально балансировщики нагрузки довольно просты и понятны.
Если смотреть издалека, серверы веб-приложений относительно просты. Они выполняют основную бизнес-логику, которая обрабатывает запрос пользователя и отправляет HTML обратно браузеру. Чтобы выполнять свою работу, они обычно общаются с различными бэкэнд-инфраструктурами, такими как базы данных, серверы кэширования, очереди заданий, службы поиска и т. д. Как упоминалось выше, обычно есть как минимум два, а то и больше, сервера, подключённых к балансировщику нагрузки для обработки пользовательских запросов.
Каждое современное веб-приложение использует одну или несколько баз данных для хранения информации. Базы данных предоставляют инструменты для организации, добавления, поиска, обновления, удаления и выполнения вычислений над данными. В большинстве случаев серверы веб-приложений напрямую общаются с серверами заданий. Кроме того, у каждой серверной службы может быть соответствующая база данных, изолированная от остальной части приложения.
Здесь стоит упомянуть SQL и NoSQL.
SQL расшифровывается как «Structured Query Language» (язык структурированных запросов). Он был изобретён в 1970-х годах, чтобы создать стандартный способ запросов к реляционным наборам данных, доступных широкой аудитории. SQL-базы данных хранят данные в таблицах, которые связаны между собой общими ключами. Такие ключи обычно представлены целыми числами.
Рассмотрим типичный пример хранения информации об истории адресов пользователей. Получатся две таблицы — user и user_addresses, — связанные друг с другом идентификатором пользователя (id в таблице user). Их можно увидеть на изображении ниже. Таблицы связаны, потому что столбец user_id в user_addresses является «внешним ключом» в столбце id в таблице users.

Эта технология используется в веб-разработке почти везде, поэтому стоит хотя бы понимать основы для правильного построения приложений.
NoSQL расшифровывается как «не-SQL» и представляет собой более новый набор технологий баз данных. Он был разработан для обработки очень больших объёмов информации, которые могут генерироваться крупномасштабными веб-приложениями. Большинство вариантов SQL плохо масштабируются горизонтально, а масштабироваться вертикально могут только до определённого момента. Если вы ничего не знаете о NoSQL, рекомендуем начать знакомство со следующих статей:
Также хочется отметить, что индустрия повсеместно полагается на SQL даже как на интерфейс для баз данных NoSQL, поэтому нужно изучать SQL, даже если он не требуется в вашей работе. В современных реалиях почти невозможно этого избежать.
Служба кэширования предоставляет простое хранилище данных в формате ключ-значение, которое позволяет хранить и искать информацию за время, близкое к линейному (O(1)). Обычно приложения используют функции кэширования, чтобы сохранять результаты дорогостоящих вычислений и воспользоваться ими позже из кэша, а не пересчитывать их еще раз. Приложение может кэшировать результаты запроса в базы данных, результаты обращения к внешним службам, HTML для заданного URL-адреса и многое другое. Вот некоторые примеры из реального мира:
- Google кэширует результаты поиска для популярных поисковых запросов, таких как «собака» или «Тейлор Свифт», а не ищет их каждый раз заново;
- Facebook кэширует большую часть данных, которые вы видите при входе в систему, например, списки постов или друзей. Подробнее, о технологии кэширования используемого в Facebook, можно почитать в этой статье на Medium;
- Storyblocks кэширует HTML-страницы от React, результаты поиска и другое.
Двумя наиболее распространёнными технологиями кэширования являются Redis и Memcache.
Большинству веб-приложений требуется выполнять некоторую работу, напрямую не связанную с ответом на запросы пользователей, асинхронно, в фоновом режиме. Например, Google должен сканировать и индексировать весь интернет, чтобы возвращать релевантные результаты поиска. Он не делает это при каждом запросе, а сканирует сеть асинхронно, обновляя поисковые индексы «по пути».
Выполнять асинхронную работу позволяют разные архитектуры, но наиболее распространённой является архитектура «очередь задач». Она состоит из двух компонентов: очереди «заданий», которые необходимо выполнить, и одного или нескольких рабочих серверов (часто называемых «работниками»), которые обрабатывают задания из очереди.
В очередях задач хранятся списки заданий, которые нужно выполнить асинхронно. Всякий раз, когда приложению нужно выполнить какую-то задачу, которая должна выполняться по расписанию или в соответствии с действием пользователя, оно добавляет её в очередь. Проще всего организованы очереди FIFO — «первым пришёл — первым ушёл», но большинство приложений в конечном итоге нуждаются в какой-то системе балансировки очередей.
Например, в Storyblocks очередь заданий используется для выполнения многих скрытых работ, необходимых для поддержания проекта: кодирование видео и фотографий, обработка CSV-файлов для тегов метаданных, агрегирование статистики пользователей, отправка писем с паролями для сброса и т. д. Со временем проект отказался от простой очереди FIFO в пользу приоритетной очереди, чтобы операции с фиксированным временем выполнения, такие как отправка писем о сбросе пароля, были завершены как можно скорее.
Сервера заданий выполняют задания из очереди. Они запрашивают её, чтобы определить, есть ли работа, и если есть, — приступают к выполнению.
Многие, если не большинство, веб-приложений поддерживают функцию поиска по текстовому вводу (часто называемого «запрос»), в котором приложение возвращает наиболее «релевантные» результаты. Технология, использующая эту функцию, обычно называется «полнотекстовым поиском» и использует инвертированный индекс для быстрого поиска документов, содержащих ключевые слова запроса.

В этом примере три заголовка документов преобразуются в инвертированные индексы, что облегчает поиск по определённому ключевому слову среди документов с этим ключевым словом в заголовке. Обратите внимание, что обычные слова, также называемые стоп-словами («in», «the», «with» и т. д.), обычно не включаются в инвертированный индекс.
В действительности можно выполнять полнотекстовый поиск непосредственно из некоторых баз данных (например, его поддерживает MySQL), но обычно принято запускать отдельную службу, которая вычисляет и сохраняет инвертированные индексы и предоставляет интерфейс для запросов. Самая популярная полнотекстовая поисковая платформа сегодня — Elasticsearch, хотя есть и другие варианты, такие как Sphinx или Apache Solr.
Когда приложение достигает определённого масштаба, как правило, появляются определённые «службы», созданные специально для запуска в виде отдельных приложений. Они не выставлены на всеобщее обозрение, но приложение и другие службы взаимодействуют с ними. Например, в Storyblocks имеются несколько операционных и плановых служб:
- служба учётных записей хранит пользовательские данные для всех сайтов компании, что позволяет работать перекрёстно и создаёт более унифицированный опыт использования;
- служба контента хранит метаданные для видео, аудио и изображений, а также предоставляет интерфейсы для загрузки содержимого и просмотра истории загрузок;
- служба оплаты предоставляет интерфейс для оплаты кредитными картами;
- HTML → PDF сервис предоставляет простой интерфейс, который принимает HTML-код и возвращает соответствующий PDF-документ.
Будет компания жить или нет во многом определяется тем, как она работает с данными. Почти каждое современное приложение, достигая определённого масштаба, переходит к одной и той же организации сбора, хранения и анализа данных. Работа с данными проходит в три основных этапа:
- Приложение отправляет данные в «firehose»-хранилище, которое обеспечивает потоковый интерфейс для поглощения и обработки данных. Как правило, это информация о действиях пользователей. Часто необработанные данные преобразуются или дополняются и передаются в другие «firehose»-хранилища. Наиболее распространённые технологии для этого процесса — AWS Kinesis и Kafka.
- Исходные, а также окончательно преобразованные и дополненные данные сохраняются в облачном хранилище. AWS Kinesis предлагает сервис под названием Firehose, который позволяет сохранять необработанные данные в облачном хранилище (S3), которое чрезвычайно просто в настройке.
- Преобразованные и дополненные данные загружаются в хранилище данных для анализа. Типичным примером является AWS Redshift, им пользуется большинство стартапов, хотя крупные компании предпочитают решения от Oracle или другие проприетарные технологии хранения. Если наборы данных достаточно велики, то для анализа может потребоваться технология NoSQL MapReduce, например, Hadoop.
На диаграмме не изображён ещё один шаг: загрузка данных из приложения и баз данных различных служб в хранилище. Например, Storyblocks каждую ночь загружает VideoBlocks, AudioBlocks, Storyblocks, службу учётных записей и базы данных портала разработчиков в Redshift. Это даёт аналитикам целостное представление, так как основные бизнес-данные и данные действий пользователей хранятся в одном и том же месте.


Неопытные разработчики вряд ли поймут, что изображено на диаграмме ниже. Но без понимания концептуальных основ работы современного веба тяжело назвать себя хорошим веб-программистом. В материале будет приведено краткое объяснение, которое поможет разобраться в происходящем, а после каждый элемент будет разобран в деталях.
Пользователь ищет в Google «Strong Beautiful Fog And Sunbeams In The Forest». Первый результат отправляет его на Storyblocks. Пользователь нажимает на ссылку, которая перенаправляет его браузер на страницу с изображением. Тем временем браузер отправляет запрос на DNS-сервер, чтобы установить соединение со Storyblock, и, получив ответ, отправляет запрос на сайт.
Запрос попадает на балансировщик нагрузки, который случайным образом выбирает для обработки запроса один из десяти (или около того) веб-серверов, на которых запущен сайт. Веб-сервер достаёт некоторую часть информации об изображении из службы кэширования, а остальное — из основной базы данных. Если цветовой профиль для изображения ещё не был вычислен, задача «определить цветовой профиль» будет добавлена в очередь заданий. Эти задания серверы обрабатывают асинхронно и соответствующим образом обновляют базу данных с результатами.
Затем происходит поиск похожих фотографий: в службу полнотекстового поиска отправляется запрос с заголовком фотографии в качестве входных данных. Если пользователь авторизовался в Storyblocks, информация о его учётной записи загружается из базы данных учётных записей. Наконец, данные о просмотре страницы отправляются в firehose-хранилище для последующей записи в облачную систему хранения. В конечном счёте, эти данные будут загружены в хранилище данных, которое аналитики используют для обработки.
3–4 декабря, Онлайн, Беcплатно
Далее будет рассказано про каждый элемент в деталях. Конечно, каждую тему можно рассмотреть гораздо подробнее, но в рамках этой статьи будут разобраны только основы. Этого должно хватить для понимания архитектуры современного веб-проекта.
1. DNS
2. Балансировщик нагрузки
Прежде чем начать обсуждение балансировки нагрузки, нужно сделать шаг назад, чтобы обсудить горизонтальное и вертикальное масштабирование приложений. Что это и в чём разница? Эта тема хорошо объяснена в посте на StackOverflow: «горизонтальное» масштабирование характеризуется добавлением новых машин в пул ресурсов, тогда как «вертикальное» подразумевает, что наращивается мощность (например, увеличивается CPU или RAM) существующей машины.
В веб-разработке проект масштабируется горизонтально как минимум потому, что всё ломается. Серверы падают по непонятным причинам. Сети деградируют. В некоторых ЦОД-ах время от времени отключается свет. Несколько серверов позволит переживать незапланированные отключения без нарушения работы приложения. Другими словами, приложение становится «отказоустойчивым». Горизонтальное масштабирование позволяет минимально связывать разные части проекта (веб-сервер, базу данных и т. д.), потому что каждая из них запускается на разных серверах. Наконец, может наступить такой момент, когда вертикальное масштабирование более невозможно, так как в мире нет достаточно мощного компьютера для выполнения всех вычислений приложения. Поисковая платформа Google является типичным примером, хотя это относится и к компаниям с гораздо меньшими масштабами. Например, Storyblocks обычно использует от 150 до 400 AWS-машин EC2 в любой момент времени. Было бы сложно получить всю эту вычислительную мощность с помощью вертикального масштабирования.
Давайте вернёмся к балансировщикам нагрузки. Благодаря им возможно горизонтальное масштабирование. Они направляют входящие запросы на один из множества серверов приложения, которые обычно являются зеркальными копиями друг друга, и отправляют ответ обратно пользователю. Любой сервер обрабатывает запросы одинаково, так что балансировщик занимается распределением заданий, чтобы никакой из них не был перегружен.
Вот и всё. Концептуально балансировщики нагрузки довольно просты и понятны.
3. Серверы веб-приложений
Если смотреть издалека, серверы веб-приложений относительно просты. Они выполняют основную бизнес-логику, которая обрабатывает запрос пользователя и отправляет HTML обратно браузеру. Чтобы выполнять свою работу, они обычно общаются с различными бэкэнд-инфраструктурами, такими как базы данных, серверы кэширования, очереди заданий, службы поиска и т. д. Как упоминалось выше, обычно есть как минимум два, а то и больше, сервера, подключённых к балансировщику нагрузки для обработки пользовательских запросов.
4. Сервер баз данных
Каждое современное веб-приложение использует одну или несколько баз данных для хранения информации. Базы данных предоставляют инструменты для организации, добавления, поиска, обновления, удаления и выполнения вычислений над данными. В большинстве случаев серверы веб-приложений напрямую общаются с серверами заданий. Кроме того, у каждой серверной службы может быть соответствующая база данных, изолированная от остальной части приложения.
Здесь стоит упомянуть SQL и NoSQL.
SQL расшифровывается как «Structured Query Language» (язык структурированных запросов). Он был изобретён в 1970-х годах, чтобы создать стандартный способ запросов к реляционным наборам данных, доступных широкой аудитории. SQL-базы данных хранят данные в таблицах, которые связаны между собой общими ключами. Такие ключи обычно представлены целыми числами.
Рассмотрим типичный пример хранения информации об истории адресов пользователей. Получатся две таблицы — user и user_addresses, — связанные друг с другом идентификатором пользователя (id в таблице user). Их можно увидеть на изображении ниже. Таблицы связаны, потому что столбец user_id в user_addresses является «внешним ключом» в столбце id в таблице users.

Если вы мало что знаете о SQL, настоятельно рекомендуем ознакомиться с нашим курсом по этой теме. Эта технология используется в веб-разработке почти везде, поэтому стоит хотя бы понимать основы для правильного построения приложений.
NoSQL расшифровывается как «не-SQL» и представляет собой более новый набор технологий баз данных. Он был разработан для обработки очень больших объёмов информации, которые могут генерироваться крупномасштабными веб-приложениями. Большинство вариантов SQL плохо масштабируются горизонтально, а масштабироваться вертикально могут только до определённого момента. Если вы ничего не знаете о NoSQL, рекомендуем начать знакомство со следующих статей:
Также хочется отметить, что индустрия повсеместно полагается на SQL даже как на интерфейс для баз данных NoSQL, поэтому нужно изучать SQL, даже если он не требуется в вашей работе. В современных реалиях почти невозможно этого избежать.
5. Кэширование
Служба кэширования предоставляет простое хранилище данных в формате ключ-значение, которое позволяет хранить и искать информацию за время, близкое к линейному (O(1)). Обычно приложения используют функции кэширования, чтобы сохранять результаты дорогостоящих вычислений и воспользоваться ими позже из кэша, а не пересчитывать их еще раз. Приложение может кэшировать результаты запроса в базы данных, результаты обращения к внешним службам, HTML для заданного URL-адреса и многое другое. Вот некоторые примеры из реального мира:
- Google кэширует результаты поиска для популярных поисковых запросов, таких как «собака» или «Тейлор Свифт», а не ищет их каждый раз заново;
- Facebook кэширует большую часть данных, которые вы видите при входе в систему, например, списки постов или друзей. Подробнее, о технологии кэширования используемого в Facebook, можно почитать в этой статье на Medium;
- Storyblocks кэширует HTML-страницы от React, результаты поиска и другое.
Двумя наиболее распространёнными технологиями кэширования являются Redis и Memcache.
6. Очереди задач
Большинству веб-приложений требуется выполнять некоторую работу, напрямую не связанную с ответом на запросы пользователей, асинхронно, в фоновом режиме. Например, Google должен сканировать и индексировать весь интернет, чтобы возвращать релевантные результаты поиска. Он не делает это при каждом запросе, а сканирует сеть асинхронно, обновляя поисковые индексы «по пути».
Выполнять асинхронную работу позволяют разные архитектуры, но наиболее распространённой является архитектура «очередь задач». Она состоит из двух компонентов: очереди «заданий», которые необходимо выполнить, и одного или нескольких рабочих серверов (часто называемых «работниками»), которые обрабатывают задания из очереди.
В очередях задач хранятся списки заданий, которые нужно выполнить асинхронно. Всякий раз, когда приложению нужно выполнить какую-то задачу, которая должна выполняться по расписанию или в соответствии с действием пользователя, оно добавляет её в очередь. Проще всего организованы очереди FIFO — «первым пришёл — первым ушёл», но большинство приложений в конечном итоге нуждаются в какой-то системе балансировки очередей.
Например, в Storyblocks очередь заданий используется для выполнения многих скрытых работ, необходимых для поддержания проекта: кодирование видео и фотографий, обработка CSV-файлов для тегов метаданных, агрегирование статистики пользователей, отправка писем с паролями для сброса и т. д. Со временем проект отказался от простой очереди FIFO в пользу приоритетной очереди, чтобы операции с фиксированным временем выполнения, такие как отправка писем о сбросе пароля, были завершены как можно скорее.
Сервера заданий выполняют задания из очереди. Они запрашивают её, чтобы определить, есть ли работа, и если есть, — приступают к выполнению.
7. Полнотекстовый поиск
Многие, если не большинство, веб-приложений поддерживают функцию поиска по текстовому вводу (часто называемого «запрос»), в котором приложение возвращает наиболее «релевантные» результаты. Технология, использующая эту функцию, обычно называется «полнотекстовым поиском» и использует инвертированный индекс для быстрого поиска документов, содержащих ключевые слова запроса.

В этом примере три заголовка документов преобразуются в инвертированные индексы, что облегчает поиск по определённому ключевому слову среди документов с этим ключевым словом в заголовке. Обратите внимание, что обычные слова, также называемые стоп-словами («in», «the», «with» и т. д.), обычно не включаются в инвертированный индекс.
В действительности можно выполнять полнотекстовый поиск непосредственно из некоторых баз данных (например, его поддерживает MySQL), но обычно принято запускать отдельную службу, которая вычисляет и сохраняет инвертированные индексы и предоставляет интерфейс для запросов. Самая популярная полнотекстовая поисковая платформа сегодня — Elasticsearch, хотя есть и другие варианты, такие как Sphinx или Apache Solr.
8. Службы
Когда приложение достигает определённого масштаба, как правило, появляются определённые «службы», созданные специально для запуска в виде отдельных приложений. Они не выставлены на всеобщее обозрение, но приложение и другие службы взаимодействуют с ними. Например, в Storyblocks имеются несколько операционных и плановых служб:
- служба учётных записей хранит пользовательские данные для всех сайтов компании, что позволяет работать перекрёстно и создаёт более унифицированный опыт использования;
- служба контента хранит метаданные для видео, аудио и изображений, а также предоставляет интерфейсы для загрузки содержимого и просмотра истории загрузок;
- служба оплаты предоставляет интерфейс для оплаты кредитными картами;
- HTML → PDF сервис предоставляет простой интерфейс, который принимает HTML-код и возвращает соответствующий PDF-документ.
9. Хранилище данных
Будет компания жить или нет во многом определяется тем, как она работает с данными. Почти каждое современное приложение, достигая определённого масштаба, переходит к одной и той же организации сбора, хранения и анализа данных. Работа с данными проходит в три основных этапа:
- Приложение отправляет данные в «firehose»-хранилище, которое обеспечивает потоковый интерфейс для поглощения и обработки данных. Как правило, это информация о действиях пользователей. Часто необработанные данные преобразуются или дополняются и передаются в другие «firehose»-хранилища. Наиболее распространённые технологии для этого процесса — AWS Kinesis и Kafka.
- Исходные, а также окончательно преобразованные и дополненные данные сохраняются в облачном хранилище. AWS Kinesis предлагает сервис под названием Firehose, который позволяет сохранять необработанные данные в облачном хранилище (S3), которое чрезвычайно просто в настройке.
- Преобразованные и дополненные данные загружаются в хранилище данных для анализа. Типичным примером является AWS Redshift, им пользуется большинство стартапов, хотя крупные компании предпочитают решения от Oracle или другие проприетарные технологии хранения. Если наборы данных достаточно велики, то для анализа может потребоваться технология NoSQL MapReduce, например, Hadoop.
На диаграмме не изображён ещё один шаг: загрузка данных из приложения и баз данных различных служб в хранилище. Например, Storyblocks каждую ночь загружает VideoBlocks, AudioBlocks, Storyblocks, службу учётных записей и базы данных портала разработчиков в Redshift. Это даёт аналитикам целостное представление, так как основные бизнес-данные и данные действий пользователей хранятся в одном и том же месте.
10. Облачное хранилище
11. CDN
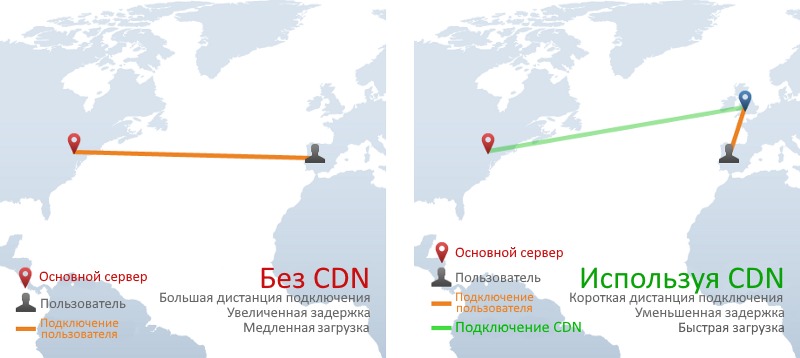
Для более полного понимания принципов работы современного веба вы можете также ознакомиться с другими нашими материалами:
Читайте также: