
Как связать бд с приложением
В этой статье демонстрируется простой способ быстрого получения данных из базы данных. Если приложению необходимо изменить данные с помощью нетривиальных способов и обновить базу данных, следует рассмотреть возможность использования Entity Framework и привязки данных для автоматической синхронизации элементов управления пользовательского интерфейса с изменениями в базовых данных.
С целью упрощения код не включает обработку исключений для выполнения в рабочей среде.
Предварительные требования
Для создания приложения вам потребуются следующие компоненты.
SQL Server Express LocalDB. если у вас нет SQL Server Express LocalDB, его можно установить на странице загрузки SQL Server Express.
Настройка образца базы данных
Создайте образец базы данных, выполнив следующие действия.
в Visual Studio откройте окно обозреватель сервера .
щелкните правой кнопкой мыши подключения к данным и выберите команду создать новую базу данных SQL Server.
В текстовом поле имя сервера введите (LocalDB) \mssqllocaldb.
В текстовом поле имя новой базы данных введите Sales, а затем нажмите кнопку ОК.
Пустая база данных Sales создается и добавляется в узел подключения к данным в обозреватель сервера.
Щелкните правой кнопкой мыши подключение к данным о продажах и выберите создать запрос.
Откроется окно редактора запросов.
вставьте скрипт T-SQL в редактор запросов, а затем нажмите кнопку выполнить .
По истечении короткого времени выполнение запроса завершается и создаются объекты базы данных. База данных содержит две таблицы: Customer и Orders. Эти таблицы изначально не содержат данных, но их можно добавить при запуске создаваемого приложения. База данных также содержит четыре простые хранимые процедуры.
Создание форм и добавление элементов управления
Создайте проект для приложения Windows Forms и назовите его SimpleDataApp.
Visual Studio создает проект и несколько файлов, включая пустую форму Windows Forms с именем Form1.
Добавьте две формы Windows Forms в проект, чтобы он включал три формы, и назначьте им следующие имена:
Навигация
NewCustomer
FillOrCancel
Для каждой формы добавьте текстовые поля, кнопки и другие элементы управления, которые отображаются на рисунках ниже. Для каждого элемента управления задайте свойства, указанные в таблицах.
Элементы управления "группа" и "надпись" обеспечивают большую ясность, но не используются в коде.
Форма навигации

Форма NewCustomer

Форма FillOrCancel

Сохранение строки подключения
Когда приложение пытается открыть подключение к базе данных, оно должно иметь доступ к строке подключения. Чтобы не вводить строку вручную в каждой форме, сохраните строку в файле App.config в проекте и создайте метод, возвращающий строку при вызове метода из любой формы в приложении.
Строку подключения можно найти, щелкнув правой кнопкой мыши подключение данных о продажах в Обозреватель сервера и выбрав Свойства. Найдите свойство ConnectionString , а затем с помощью клавиш CTRL + A, CTRL + C выберите и скопируйте строку в буфер обмена.
В столбце имя введите connString .
В списке тип выберите (строка подключения).
В списке область выберите приложение.
В столбце значение введите строку подключения (без кавычек), а затем сохраните изменения.
В реальных приложениях строку подключения следует хранить безопасно, как описано в разделе строки подключения и файлы конфигурации.
Написание кода для форм
Этот раздел содержит краткие обзоры того, что делает каждая форма. Он также предоставляет код, определяющий базовую логику при нажатии кнопки на форме.
Форма навигации
Форма навигации открывается при запуске приложения. Кнопка Добавить учетную запись открывает форму NewCustomer. Кнопка Выполнение или отмена заказов открывает форму FillOrCancel. Кнопка Выход закрывает приложение.
Преобразование формы навигации в начальную форму
если вы используете Visual Basic, в обозреватель решений откройте окно свойства , перейдите на вкладку приложение и выберите симпледатаапп. Navigation в списке начальных форм .
Создание автоматически создаваемых обработчиков событий
Дважды щелкните три кнопки в форме навигации, чтобы создать пустые методы обработчика событий. При двойном щелчке кнопки также добавляется автоматически созданный код в файл кода конструктора, который позволяет нажать кнопку для вызова события.
Добавление кода для логики формы навигации
На странице кода для формы навигации заполните основные тексты методов для трех обработчиков событий нажатия кнопки, как показано в следующем коде.
Форма NewCustomer
если ввести имя клиента, а затем нажать кнопку создать учетную запись , форма NewCustomer создает учетную запись клиента, а SQL Server возвращает значение идентификатора в качестве нового идентификатора клиента. Затем можно разместить заказ для новой учетной записи, указав сумму и дату заказа и нажав кнопку поместить порядок .
Создание автоматически создаваемых обработчиков событий
Создайте пустой обработчик событий щелчка для каждой кнопки в форме NewCustomer, дважды щелкнув каждую из четырех кнопок. При двойном щелчке кнопки также добавляется автоматически созданный код в файл кода конструктора, который позволяет нажать кнопку для вызова события.
Добавление кода для логики формы NewCustomer
Чтобы завершить логику формы NewCustomer, выполните следующие действия.
Перенесите System.Data.SqlClient пространство имен в область, чтобы не указывать полные имена его членов.
Добавьте в класс некоторые переменные и вспомогательные методы, как показано в следующем коде.
Заполните основные тексты методов для четырех обработчиков событий нажатия кнопки, как показано в следующем коде.
Форма FillOrCancel
Форма Филлорканцел запускает запрос для возврата заказа при вводе идентификатора заказа и нажатия кнопки найти заказ . Возвращенная строка отображается в сетке данных только для чтения. Можно пометить заказ как отмененный (X), если нажать кнопку отменить заказ или пометить заказ как заполненный (F), если нажать кнопку заполнить заказ . Если нажать кнопку найти порядок еще раз, появится обновленная строка.
Создание автоматически создаваемых обработчиков событий
Создайте пустые обработчики событий щелчка для четырех кнопок в форме Филлорканцел, дважды щелкнув кнопки. При двойном щелчке кнопки также добавляется автоматически созданный код в файл кода конструктора, который позволяет нажать кнопку для вызова события.
Добавление кода для логики формы Филлорканцел
Чтобы завершить логику формы Филлорканцел, выполните следующие действия.
Перенесите следующие два пространства имен в область, чтобы не указывать полные имена их членов.
Добавьте в класс переменную и вспомогательный метод, как показано в следующем коде.
Заполните основные тексты методов для четырех обработчиков событий нажатия кнопки, как показано в следующем коде.
Тестирование приложения
Нажмите клавишу F5 для сборки и тестирования приложения после написания кода для каждого обработчика события нажатия кнопки и общего кода программы.

Что будет в статье:
Эта статья дополняет код первой части - найти его можно здесь. Код для этой части статьи находится в репозитории по ссылке.
Если вам интересно асинхронное программирование, приходите к нам на курс в KTS, где мы подробно разберем эту тему. Старт — 18 октября.
1 — Поднимаем базу данных PostgreSQL в Docker-контейнере
Это подготовительный этап. Мы будем работать с сервером PostgreSQL версии 11 и старше. Так как Docker все равно понадобится вам для последующей публикации приложения в Интернете, то убьем двух зайцев сразу и запустим сервер PostgreSQL в Docker-контейнере.
Docker-контейнеры по умолчанию не хранят данные, поэтому необходимо создать volume, чтобы не потерять данные нашей базы после перезапуска или после остановки контейнера:
Теперь запустим нашу базу командой:
Мы запустили docker-контейнер с базой данных от имени root-пользователя. Давайте рассмотрим переданные параметры:
-e POSTGRES_PASSWORD=forum_password — задали пароль для пользователя базы данных, передав его через переменную окружения в контейнер
-e POSTGRES_USER=forum_user — задали имя пользователя базы данных аналогичным способом
-p 5432:5432 — опубликовали 5432-ой порт контейнера во внешнюю среду. Подробнее о том, как устроена сеть Docker, можно прочитать тут
--mount source=postgres-data,target=/var/lib/postgresql — примонтировали volume postgres-data к нашему контейнеру. Теперь все данные, которые приложение в контейнере записало в /var/lib/postgresql , сохранятся на жестком диске. Иначе при остановке или перезапуске контейнера мы бы их потеряли.
-d — запустили команду docker run в detached-режиме: можем закрыть консоль, а контейнер продолжит работать
postgres:11 — имя образа, на основе которого необходимо запустить контейнер. Подробнее про docker-образы можно прочитать здесь
Проверим, что база работает. Для этого подключимся к ней через CLI:
Создадим базу данных и дадим все права на нее нашему пользователю:
Подготовка закончена, переходим к написанию приложения.
2 — Создаем модель данных
Чтобы получить доступ к базе данных, нам нужен адрес ее сервера, имя и пароль для входа, а также название самой базы. При локальной разработке приложения на компьютере эти параметры могут быть одни, а при публикации в Интернете совершенно другие. Данные, которые могут меняться, обычно выносят в конфигурационный файл и подменяют этот файл в зависимости от окружения.
В корень проекта добавим папку config, а в ней создадим файл config.yaml. Также сразу же создадим файл settings.py в папке app. Структура проекта должна выглядеть следующим образом:
3 — Работаем с файлами конфигурации приложения
В файл config.yaml добавим следующую конфигурацию:
Теперь нам надо научиться как-то работать с этими данными. Для этого откроем файл app/settings.py и запишем в него:
Теперь в глобальной переменной config хранится словарь с конфигурацией. Например, чтобы получить порт, нам нужно обратиться к config[“common”][“port”] .
Давайте прикрепим config к нашему приложению. Приведем файл main.py к следующему виду:
После этого шага мы можем обратиться к app[“config”] и получить доступ к нашему конфигурационному файлу из любого места в приложении.
4 — Подключаемся к базе данных и пишем свой Accessor
Аксессор — сущность, которая помогает работать с данными, находящимися вне памяти приложения, например, бывает аксессор к базе данных или аксессор к стороннему API. В аксессоре сокрыты детали реализации, такие как установка соединения, выполнение SQL-команд, парсинг ответа и т.д. Остальной код приложения не должен "знать" о реализации того или иного метода аксессора, он просто должен вызвать метод и взаимодействовать со сторонним источником данных в удобной форме.
Давайте создадим подключение к базе данных. Для этого в папке app/ создадим еще один модуль store/, в которой будут хранится наши аксессоры. Добавим в папку app/store/database три файла и не забудем добавить файл __init__.py в store/database:
accessor.py — здесь будет располагаться код для подключения к базе
models.py — здесь находится входная точка для наших моделей, о которых будет сказано ниже
Теперь структура вашего проекта должна выглядеть следующим образом:
Файлы __init__.py оставьте пустыми, они нужны лишь как признак python-модуля.
В файл accessor.py добавим следующий код:
Давайте кратко рассмотрим содержание этого файла. Мы создали класс PostgresAccessor , который отвечает за подключение к базе данных и отключение после завершения работы.
Функция _on_connect берет данные о базе из конфигурационного файла и с помощью команды db.set_bind(self.config[“database_url”]) создает необходимое подключение к базе. Если указана неверная конфигурация базы, или по какой-то причине подключение невозможно, то функция бросит исключение, и сервер не запустится.
Важно, чтобы проблемы с подключением к необходимым для работы сторонним сервисам были видны на этапе запуска приложения — это позволит сразу же среагировать на проблему или откатиться к предыдущей версии приложения, а потом уже решать проблему.
Функция _on_disconnect позволяет отключиться от базы после завершения работы приложения и освободить ресурсы базы, например “правильно” разорвать соединение с ней.
5 — Инстанцируем Gino
Теперь в models.py нужно добавить код:
Это очень важный файл. Он инстацирует экземпляр Gino, с помощью которого мы можем выполнять команды в базе и еще множество других вещей. Мы создаем экземпляр Gino глобально, так как он необходим для проведения миграций.
Чтобы понять, что такое Gino и зачем он нужен, посмотрите на картинку ниже. Зеленым цветом обозначены асинхронные объекты, а желтым — синхронные:

Разберемся по шагам.
1. База данных слева может получать команды и отдавать данные по так называемому DB API, которое основано на собственном протоколе работы.
2. Чтобы выполнить SQL-скрипт из Python, необходимо установить пакет, который умеет работать с DB API. Самый популярный пакет — Psycopg. Но проблема в том, что он синхронный: когда запрос уйдет в базу, необходимо дождаться ответа. Во время ожидания никакой другой код выполнен не будет. Для решения этой проблемы создан Asyncpg — обертка над Psycopg, которая позволяет сделать его асинхронным.
Важно понимать, зачем необходимо асинхронное соединение с базой данных. Пример: мы решили посчитать статистику всех продаж магазина за несколько лет. База выполняет подсчет за 20 секунд. На эти 20 секунд синхронный python-код остановит свою работу и не сможет обрабатывать запросы от других пользователей. Говоря по-простому, сервер просто «зависнет». Асинхронное соединение «заморозит» дальнейшее выполнение функции, сделавшей запрос к базе, пока не дождется ответа, и продолжит выполнять другую работу — например, обслуживать другие запросы клиентов.
3. Достаточно неудобно писать SQL-команды вручную. Гораздо быстрее, надежнее и безопаснее писать с использованием Python-кода, хотя из-за этого немного теряется производительность. Для этого существует пакет SQLAlchemy, который позволяет удобно работать с базой, генерируя SQL-команды по нашему Python-коду и не только. К сожалению, по умолчанию SQLAlchemy синхронный пакет, поэтому появляется необходимость в еще одной обертке — Gino.
4. Gino — последнее звено, после которого наше асинхронное приложение наконец-то может асинхронно общаться с базой.
SQLAlchemy, начиная с версии 1.4 поддерживает asyncio "из коробки", поэтому острая необходимость в Gino в асинхронных приложениях отпадает. Но Gino продолжает развиваться и добавляет функционал в SQLAlchemy, поэтому не стоит сбрасывать его со счетов. Подробнее о жизни после SQLAlchemy 1.4 можно прочитать здесь.
Осталось привязать к нашему приложению PostgresAccessor. Добавим подключение аксессора в main.py, написав функцию setup_accessors и изменив код setup_app:
В реляционных базах данных информация хранится в таблицах. Работать с ними не совсем удобно. Чтобы сделать работу с данными более удобной и прозрачной, создают модели — некие абстракции над данными, которые человек воспринимает лучше, чем строка таблицы. Удобство не единственная причина использования моделей, они также позволяют задавать структуру базы данных из кода и добавляют уровень абстракции.
Хранить эти данные мы будем в таблице Message:

Конечно, можно создать эту таблицу вручную, но это не очень удобно и безопасно при запуске приложения из нового места или если проект ведут несколько разработчиков. Если из-за ошибок в коде структуры базы данных будут несколько различаться это может привести к серьезным и трудно-исправляемым сбоям сервиса. Миграции призваны решить данную проблему.
Миграции — это набор операций, которые надо применить к базе, чтобы привести ее в необходимое состояние. С помощью них можно как повысить, так и понизить версию структуры базы данных.
Пример: можно выполнить миграцию и создать новые таблицы, а в случае ошибки откатить миграцию обратно и удалить таблицы.
При таком подходе несколько разработчиков могут изменять структуру базы параллельно — каждый создает необходимые ему миграции, а во время слияния кода эти миграции объединяются и дают структуру базы, которая удовлетворяет всем новым условиям. Если же мы планируем запустить наше приложение в новом месте, то достаточно выполнить все миграции, чтобы получить новейшую структуру базы.
Подошло время написать нашу первую модель Message. Для этого в папке forum/ создадим файл models.py и вставим в него следующий код:
Этим кодом мы декларативно задали, данные каких типов хотим хранить в таблице message. Также наша модель стала наследником db.Model , где db — экземпляр Gino. Теперь у нас все готово, чтобы сгенерировать первую миграцию.
7 — Генерируем миграцию
Когда нам нужна работа с миграциями, на помощь приходит пакет Alembic. Он позволяет автоматизировать процесс применения миграции и их создание.
Наша миграция будет содержать создание таблицы message со всеми необходимыми полями. Для этого в корне нашего проекта выполним следующую команду:
Если все правильно, в корне вашего проекта должны появиться директорий migrations и файл alembic.ini. Alembic может работать, ничего не зная о наших моделях, которые заданы в коде — но тогда теряется возможность автоматической генерации миграций. Чтобы дать возможность Alembic «познакомиться» с нашим кодом, необходимо сделать два действия:
В файле alembic.ini заменить строку
и сохранить файл.
2. Заменить код файла migrations/env.py на следующий:
Этими действиями мы привязали к конфигурации Alembic конфигурацию нашего приложения. Теперь Alembic знает о наших моделях.
Чтобы сгенерировать миграцию, надо в корне выполнить следующие команды:
Команда export необходима, чтобы Alembic смог понять, о каком приложении мы говорим, так как оно может не находиться в PYTHONPATH — директориях, где python ищет свои модули.
Флаг -m во второй команде позволяет задать человекочитаемое название миграции, чтобы сделать назначение миграции понятнее.
Если все прошло успешно, то в папке migrations/versions появится файл примерно с таким названием: 6356fd90ab82_create_table_message.py. Код в начале названия — уникальный идентификатор миграции, который используется для сопоставления миграции и состояния базы, а также для того, чтобы обеспечить верный порядок применения миграций.
Давайте рассмотрим фрагменты этого файла более детально:
revision — тот же код, который хранится в названии
down_revision — код миграции, которую надо применить для того, после этой при понижении версии базы. Сейчас он пустой, так как это первая миграция в нашем проекте.
branch_labels — указывается, если несколько миграций должны быть выполнены после одной и той же родительской миграции — это может произойти например при слиянии кода нескольких разработчиков, которые создали миграции для одной и той же таблицы.
Также стоит рассмотреть две функции из этого файла: upgrade() — вызывается при повышении версии базы данных, а downgrade() — при понижении.
Повысим версию нашей базы до последней:
Теперь при прямом подключении к БД мы можем увидеть созданную структуру:

8 — Alembic: добавляем взаимодействие с базой данных
В последнем шаге на сегодня рассмотрим взаимодействие с базой данных: получение и создание записей. Для этого необходимо создать новый View в файле app/forum/views.py. Добавьте этот код в конец файла:
Не забудьте указать путь, по которому будет доступен данный View. В файле app/forum/routes.py в функции setup_routes() добавьте:
Теперь выполните команды:
С помощью команды \c мы подключаемся к конкретной базе данных и можем выполнять запросы к ее таблицам, например, выполнить команду INSERT .
Чтобы посмотреть имеющиеся таблицы в базе данных, после подключения к ней необходимо выполнить команду \d :
Заметьте, что у нас существуют две таблицы и одна последовательность:
alembic_version — в ней хранится номер последней примененной к базе миграции, которая должна соответствовать префиксу в последнем примененном файлом миграции:
Теперь, запустив наше приложение командой python main.py в корне проекта и перейдя в браузер по ссылке 0.0.0.0:8080/api/messages.list, мы должны увидеть такую картину:

Готово! Мы получили данные, которые хранятся в нашей базе и передали их в ответ на запрос.
Чтобы добавить данные не вручную, создайте еще один View. Откройте файл app/forum/views.py и добавьте в конец следующий код:
Добавим путь к нашему новому View в app/forum/routes.py в функции setup_routes() :
9 — Добавляем новые возможности в интерфейс

Теперь откроем в браузере 0.0.0.0:8080 и увидим следующее:

10 — Резюме
Подведем итоги. В этой статье мы:
Научились поднимать базу данных PostgreSQL в Docker-контейнере
Поработали с файлами конфигурации приложения
Написали свой Accessor, который позволил нашему приложению получать данные из сторонних источников. По аналогии с ним можно создать каналы получения данных из других источников, например из стороннего API.
Создали модель Message, абстракцию над «сухой» строчкой в таблице базы данных
Узнали как асинхронно общаться с PostgreSQL из Python
Настроили alembic и с его помощью сгенерировали первую миграцию
Код для второй части статьи находится в этом репозитории.
Асинхронное программирование — большая тема. Если хотите разобраться в ней подробнее, приходите к нам на курс. Занятия начнутся 18 октября, а 22 сентября мы проведем вебинар, на котором расскажем, что будет в программе.
В целях изучения Java и сопутствующих технологий решил написать клиент-серверное приложение с базой данных.
Как должно работать:
- есть база данных
- есть серверное приложение, которое будет получать запросы от клиентов для выборки данных из базы данных и отсылать им, парсить данные в базу из txt -файлов или даже с страниц в интернете или эл.почты
- клиенты (десктопный, Android, простенький веб-интерфейс
Изучаю SQL и, в принципе, понимаю как создать базу данных в MySQL. Примерно понимаю как написать серверное приложение. Для изучения Tomcat, наверное, серверное приложение и база данных должны на нём крутиться.
Суть вопроса: как серверное приложение и базу данных разместить на Tomcat'e?
Я знаю, где у меня исходники и *.classes серверного приложения и не знаю, где сохраняется база данных, если я работаю через консоль MySQL.
Как все это запустить на моём PC под Windows 10 Pro?


Итак, в целях обучения можете сделать Rest сервис. Работать это будет примерно следующим образом:
Все это крутится на Tomcat'e А интерфейс это уже отдельная тема. Надеюсь, все доступно объяснил, если есть вопросы, с радостью отвечу.
PS Для подключения к БД используйте (Более подробно почитайте в гугле "JDBC mysql connection"):
Если клиенты отправляют запросы на сервер, то это отправляют Tomcat'y или серверному приложению, которое мне нужно написать?
Да, Tomcat'y, он следит за запросами(если можно так выразиться), а ваше приложение(сервер) их обрабатывает, выглядит это примерно так (если без спринга):
Этот фрагмент кода взят из реализации Сервлета, Если вы не знаете, что это очень рекомендую почитать, без сервлетов в j2ee никуда.
Отлично! Теперь я понимаю, что ещё и с сервлетами нужно познакомиться, чтобы сложилась более полная картина что и к чему нужно прикрутить. А если вернуться к вопросу о БД. Вот второй день изучаю SQL и пишу в консоли MySQL. Где сохраняется эта БД? Как с ней работать из серверного приложения, которое должно обрабатывать клиентские запросы? "jdbc:mysql://hostname:port/dbname" вот эту строку в getConnection надо заменить на jdbc:mysql://localhost:3306/MyDataBaseName, где MyDataBaseName - имя вашей базы данных, localhost значит, что сервер БД стоит на той же машине, а 3306 это порт с которым работает MySql Для подключения базы данных уже с давних пор предлагается использовать ресурсы сервера приложений. Зачем этот вот DriverManager? Только лишь для ознакомления с основами JDBC? Но это не тот путь, который стоит использовать с tomcat и пр. База сохраняется на сервере базы данных. И клиенту точное расположение файлов базы знать совершенно незачем, и не предусмотрено SQL такое знание. Для MySQL на Windows это может быть, например, папка C:\Program Files\MySQL\MySQL Server 5.6\data. Чем это может помочь даже не представляю.Если достаточно хорошо знаете аглицкий для чтения мануалов, то лучше почитать документацию к tomcat, javaee.
На русском легко найти про java, про servlet-ы, про jdbc отдельно. А вместе не попадалось никогда.
Сначала подключение к БД описывается где-то в контексте tomcat-а. Есть варианты как именно, в какой файл записать эти строки (см. документацию):
Обратите внимание на url. Правильно догадались, что надо прописать jdbc:mysql://hostname:port/dbname
Считайте, что url и есть база данных. Это адрес сервера (hostname:port) и имя базы, которое дали ей при созданий. Там она и хранится.
Вполне возможно и у tomcat-а есть web-морда, в которой можно создать такое подключение, вместо ручного написания xml. Не знаю. У других серверов есть такая возможность.
Потом в WEB-INF/web.xml web-приложения помещается ссылка на этот ресурс:
Наконец, используя аннотацию @Resource , внедряем базу например в servlet:
Несмотря на обратный порядок изложения, имя ресурса ( @Resource(name) ) задаётся в программе и это имя с помощью конфигурации связывается с настоящей базой.
Возможно не всё тут правда, но как-то так.
Да. Длинновато получается. Но ничего не поделаешь - разработчику для tomcat-ов всяких надо знать все эти конфигурации (называются дескрипторы развёртывания или deployment descriptor) стандартные из javaee и специфические для конкретного сервера приложений. Зато подключение к базе задаётся не железно в коде, а гибко в конфигурации. Да и кода уже никакого нет, так - одна аннотация. Более-менее приличные IDE иногда упрощают написание этой конфигурации.
⇑
Выполнение
1. Создание приложения типа Windows Forms Application .
⇑
2. Вызов мастера подключения.
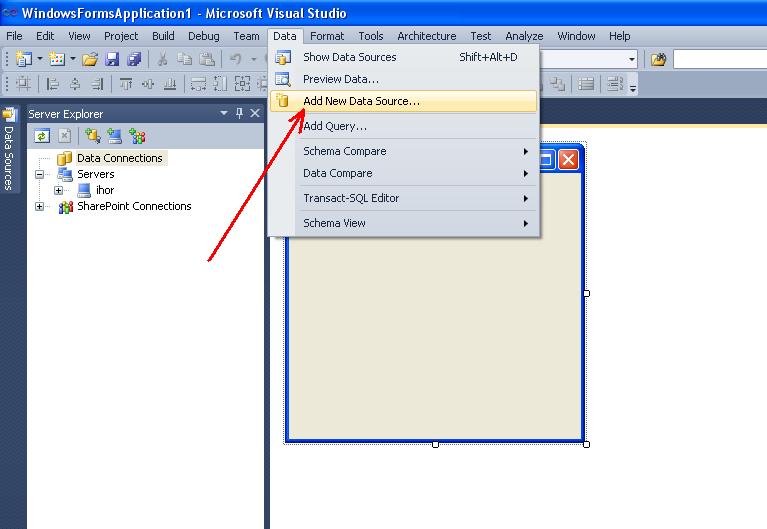
Рисунок. 1. Вызов мастера подключения к файлу базы данных
⇑
3. Выбор типа источника данных.
В результате откроется окно мастера для подключения к источнику данных которое изображено на рис. 2.

Рисунок. 2. Выбор типа подключения из которого приложение будет получать данные
В окне необходимо выбрать один из четырех возможных вариантов подключения к источнику данных. В MS Visual Studio существует четыре типа подключения к источникам данных:
- Database – подключение к базе данных и выбор объектов базы данных;
- Service – открывает диалоговое окно Add Service Reference позволяющее создать соединение с сервисом, который возвращает данные для вашей программы;
- Object – позволяет выбрать объекты нашего приложения, которые в дальнейшем могут быть использованы для создания элементов управления ( controls ) с привязкой к данным;
- Share Point – позволяет подключиться к сайту SharePoint и выбрать объекты для вашей программы.
В нашем случае выбираем элемент Database и продолжаем нажатием на кнопке Next .
⇑
4. Выбор модели подключения к базе данных.
Следующий шаг – выбор модели подключения к базе данных (рис. 3).
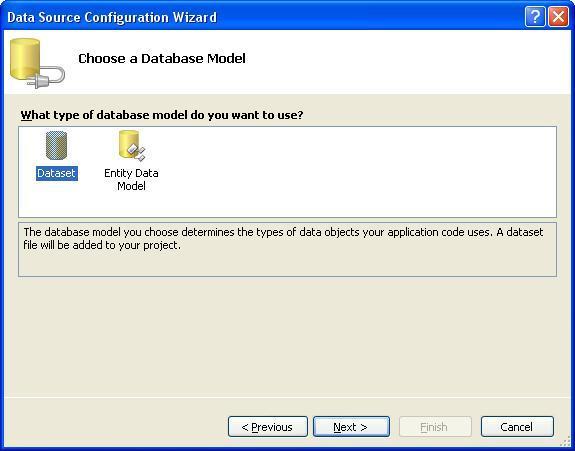
Рис. 3. Выбор модели подключения к базе данных
Система предлагает выбор одного из двух вариантов:
- модели данных на основе набора данных ( Dataset );
- модели данных Entity , что означает, что система может сгенерировать модель данных из базы данных которой могут выступать сервера баз данных Microsoft SQL Server , Microsoftt SQL Server Compact 3.5 или Microsoft SQL Server Database File , либо создать пустую модель как отправную точку для визуального проектирования концептуальной модели с помощью панели инструментов.
В нашем случае выбираем тип модели данных DataSet .
⇑
5. Задание соединения с БД.
Следующим шагом мастера (рис. 4) есть выбор соединения данных которое должно использоваться приложением для соединения с базой данных.

Рис. 4. Выбор соединения с базой данных
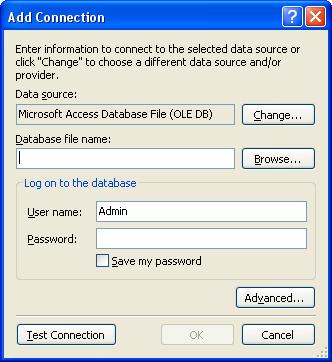
Рис. 5. Добавление нового соединения и выбор файла базы данных
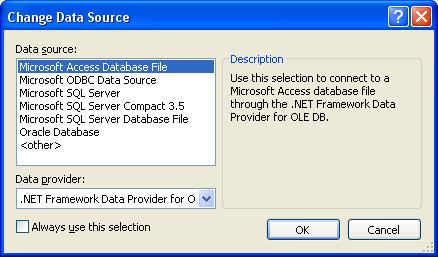
Рис. 6. Смена источника данных
В окне на рисунке 6 системой Microsoft Visual Studio будет предложено следующие виды источников данных:
- Microsoft Access Database File – база данных Microsoft Access ;
- Microsoft ODBC Data Source – доступ к базе данных с помощью программного интерфейса ODBC ( Open Database Connectivity );
- Microsoft SQL Server ;
- Microsoft SQL Server Compact 3.5 ;
- Microsoft SQL Server Database File ;
- Oracle Database – база данных Oracle .
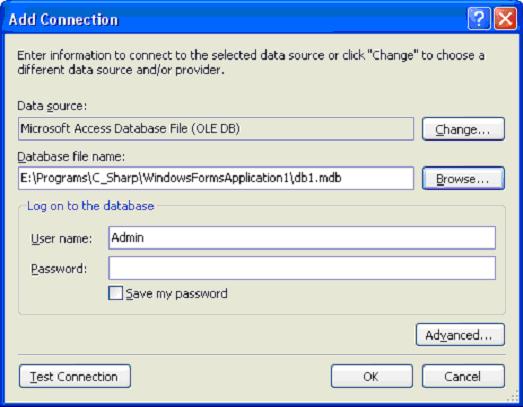

Рис. 8. Строка Connection string
В этом каталоге размещаются все основные исходные модули проекта, например Program.cs (модуль, содержащий основную функцию WinMain() ) , Form1.cs (содержит исходный код обработки главной формы приложения) и другие.

Рисунок 9. Окно добавления файла базы данных в проект
⇑
6. Формирование конфигурационного файла приложения.

Рисунок 10. Предложение записи строки подключения к базе данных в конфигурационный файл приложения
Ничего не изменяем, оставляем все как есть (кликаем на Next ).
⇑
7. Выбор объектов базы данных для использования в программе
Последнее окно мастера (рисунок 11) предлагает выбрать список объектов (таблиц, запросов, макросов, форм и т.д.), которые будут использоваться в наборе данных. Как правило выбираем все таблицы базы данных. В нашем примере база данных содержит всего одну таблицу с именем Tovar .
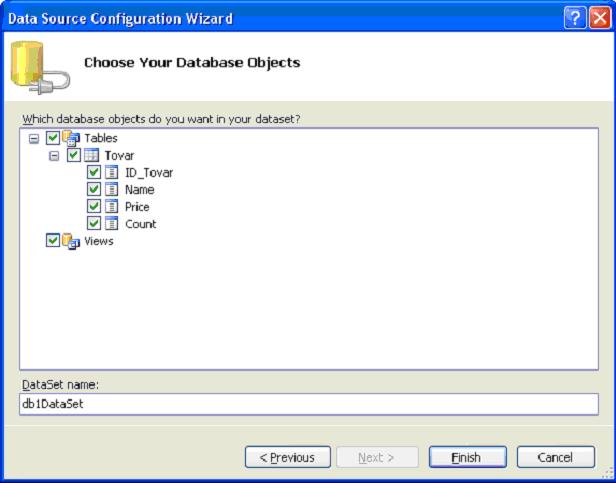
Рисунок 11. Выбор объектов базы данных, которые будут использоваться в данном наборе данных
⇑
8. Что же изменилось в программе после выполнения мастера?
Если выбрать панель Data Source (рисунок 12), то можно увидеть, как подключен набор данных с именем db1Dataset в котором есть таблица с именем Tovar .
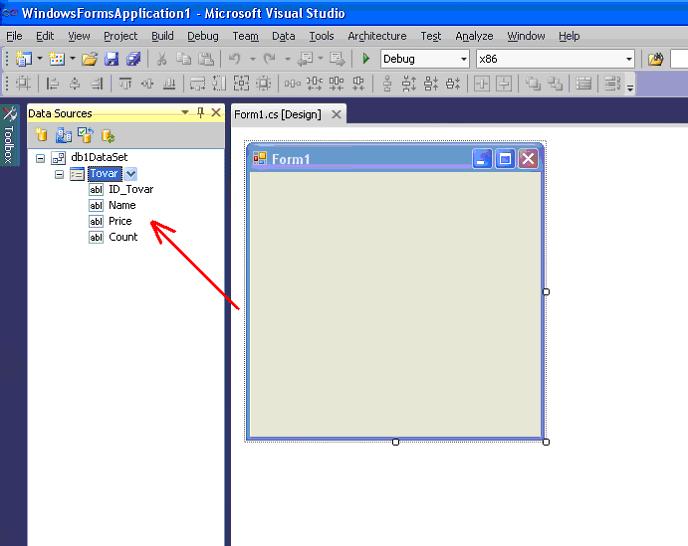
Рисунок 12. Окно DataSources содержит подключение к базе данных

Рис. 13. Окно приложения с изменениями в панели Server Explorer
⇑
9. Подключение методов оперирования базой данных.
Для того, чтобы использовать методы, которые будут работать с базой данных MS Access (и не только MS Access ), необходимо подключить пространство имен System.Data.OleDb .
Для этого в основной форме ( Form1.cs ) в Solution Explorer выбираем режим просмотра кода (View Code) из контекстного меню (рис. 14) и вначале файла добавляем следующую строку:

Рисунок 14. Вызов программного кода главной формы приложения ( Form1.cs ) с помощью Solution Explorer
Общий вид верхней части файла Form1.cs будет следующим:
На этом этапе подключение к базе данных db1.mdb выполнено. Дальнейшими шагами есть создание программного кода для оперирования данными в базе данных.
Эта статья открывает небольшой цикл, посвященный азам взаимодействия с базами данных (БД) в Java и введению в SQL. Многие программы заняты обработкой и модификацией информации, её поддержкой в актуальном состоянии. Поскольку данные — весьма важная часть логики программ, то под них зачастую выделяют отдельное хранилище. Информация в нём структурирована и подчинена специальным правилам, чтобы обеспечить правильность обработки и хранения. Доступ к данным и их изменение осуществляется с помощью специального языка запросов — SQL (Structured Query Language).
Система управления базами данных — это ПО, которое обеспечивает взаимодействие разных внешних программ с данными и дополнительные службы (журналирование, восстановление, резервное копирование и тому подобное), в том числе посредством SQL. То есть программная прослойка между данными и внешними программами с ними работающими. В этой части ответим на вопросы что такое SQL, что такое SQL сервер и создадим первую программу для взаимодействия с СУБД.
Виды СУБД
- Иерархические. Данные организованы в виде древовидной структуры. Пример — файловая система, которая начинается с корня диска и далее прирастает ветвями файлов разных типов и папок разной степени вложенности.
- Сетевые. Видоизменение иерархической, у каждого узла может быть больше одного родителя.
- Объектно-ориентированные. Данные организованы в виде классов/объектов c их атрибутами и принципами взаимодействия согласно ООП.
- Реляционные. Данные этого вида СУБД организованы в таблицах. Таблицы могут быть связаны друг с другом, информация в них структурирована.
- Что такое SQL-Сервер и как он работает? Взаимодействие с СУБД происходит по клиент-серверному принципу. Некая внешняя программа посылает запрос в виде операторов и команд на языке SQL, СУБД его обрабатывает и высылает ответ. Для упрощения примем, что SQL Сервер = СУБД.
- Data Definition Language (DDL) – определения данных. Создание структуры БД и её объектов;
- Data Manipulation Language(DML) – собственно взаимодействие с данными: вставка, удаление, изменение и чтение;
- Transaction Control Language (TCL) – управление транзакциями;
- Data Control Language(DCL) – управление правами доступа к данным и структурам БД.

Первая программа
Разбор кода
Блок констант:
- DB_Driver: Здесь мы определили имя драйвера, которое можно узнать, например, кликнув мышкой на подключенную библиотеку и развернув её структуру в директории lib текущего проекта.
- DB_URL: Адрес нашей базы данных. Состоит из данных, разделённых двоеточием:
- Протокол=jdbc
- Вендор (производитель/наименование) СУБД=h2
- Расположение СУБД, в нашем случае путь до файла (c:/JavaPrj/SQLDemo/db/stockExchange). Для сетевых СУБД тут дополнительно указываются имена или IP адреса удалённых серверов, TCP/UDP номера портов и так далее.
Обработка ошибок:
Вызов методов нашего кода может вернуть ошибки, на которые следует обратить внимание. На данном этапе мы просто информируем о них в консоли. Заметим, что ошибки при работе с СУБД — это чаще всего SQLException.
Читайте также: