
Как достать api из приложения
Друзья, недавно для своего клиента М. я сделал обращение к API площадки, которая занимается криптовалютой.
В этой статье попробуем достать из этого API список проектов (криптовалют), которые есть на площадке, разбираясь с каждым этапом отдельно.
С чего начнём
Наш главный документ – это документация API, в документации есть всё (обычно 😁): как получить ключ, возможные методы обращение к API c примерами.
1. Получаем api-ключ
Тут всё просто – находим в документации "How to get access", переходим по ссылке, регистрируемся и нажимаем "Create Access Key".
2. Берём ключ и делаем запрос в браузере
Напомню, что мы получаем список криптовалют, которые есть на площадке. Наш метод – Get Projects.
Ниже - скриншот из документации.
Из скриншота можно понять четыре вещи:
1) тип запроса, который нам нужен: GET
3) параметр – только api_key и он подставляется в ссылку
4) при успешном вызове API вернёт нам объект, с массивом объектов (в каждом объекте - один проект) с ключами: project_id, name, slug, cmc_id, symbol
Собираем ссылку руками и просто запускаем её в браузере (GET-запрос не требует передачи тела и открывается просто в браузере)
Супер, что-то выводится, значит метод и ключ – работают, теперь автоматизируем.
3. Автоматизируем это
Все запросы, GET, POST, . отправляются из Google Apps Script с помощью метода UrlFetchApp.fetch (или fetchAll, если вы хотите отправлять запросы пачкой, как мы делали здесь)
Итак, переходим к практике, код. Вызываем метод, декодируем и превращаем в объект ответ:
//Простой GET отправляется с помощью UrlFetchApp.fetch(наша ссылка на метод + ключ) без дополнений.
//Декодируем строку ответа
const content = response.getContentText();
//Превращаем всё еще строку в объект, с которым можно работать и выводим в лог
const result = JSON.parse(content);
В логе видим такое:
Это объект, если его привести к читабельному виду, то он будет выглядеть как на скриншоте ниже. Внутри него есть объект status (информация о вашем запросе) и объект data, внутри которого массив объектов проектов, которые есть на площадке, то, что мы и хотели получить.
Дописываем скрипт, парсим результат
//обращаемся к массиву data внутри ответа
const data = result.data
//задаём пустой массив
//обходим data в цикле, обращаясь к каждому внутреннему объекту и вставляем его данные в новый массив
const coin = data[n];
Всё, теперь вместо сложного объекта с объектами внутри мы получаем привычную структуру (ряд строк, массив массивов, лист листов, Игорь – привет), которую можно вставить в нашу Таблицу.
Добавляем еще пару строк кода и вставляем данные в Таблицу:
const sh = SpreadsheetApp.getActive().getSheetByName('PROJECTS');
sh.getRange(2, 1, arr.length, arr[0].length).setValues(arr);
Итак, мы разобрались как получить ключ, как написать простой GET-запрос, как декодировать его результат, как обратиться к нужному элементу ответа и привести его к формату, который можно вставить.

Часто возникает задача периодически парсить какой-нибудь сайт на наличие новой информации. Например, если ты пишешь агрегатор контента с новостного сайта или форума, в котором нет поддержки RSS. Проще всего написать скрепер на Питоне и разобрать полученный HTML через beautifulsoup или регулярками. Однако есть более элегантный способ — самому сделать недостающие API для сайта и получать ответы в привычном JSON, как будто бы у сайта есть нативный API.
Не будем далеко ходить за примером и напишем парсер контента с «Хакера». Как ты знаешь, сайт нашего журнала сейчас не предоставляет никакого API для программного получения статей, кроме RSS. Однако RSS не всегда удобен, да и выдает далеко не всю нужную информацию. Исправим это!
Постановка задачи
Итак, наша задача: сделать API вида GET /posts , который бы отдавал десять последних статей с «Хакера» в JSON. Также нам нужно иметь возможность задавать сдвиг, то есть раз за разом получать следующие десять постов.
Ответ должен быть таким:
Также нужно иметь возможность получать следующие десять постов — со второй страницы, третьей и так далее. Это делается через GET-параметр вида GET /posts?page=2 . Если page в запросе не указан, считаем его равным 1 и отдаем посты с первой страницы «Хакера». В общем, задача ясна, переходим к решению.
Фреймворк для веба
WrapAPI — это довольно новый (пара месяцев от роду) сервис для построения мощных кастомных парсеров веба и предоставления к ним доступа по API. Не пугайся, если ничего не понял, сейчас поясню на пальцах. Работает так:
Немного о приватности запросов
Ты наверняка уже задумался о том, насколько безопасно использовать чужой сервис и передавать ему параметры своих запросов с приватными данными. Тем более что по умолчанию для каждого нового API-проекта будет создаваться публичный репозиторий и запускать API из него сможет любой желающий. Не все так плохо:
- Каждый API-репозиторий (а соответственно, и все API-запросы в нем) можно сделать приватным. Они не будут показываться в общем списке уже созданных API на платформе WrapAPI. Просто выбери достаточно сложное имя репозитория, и шанс, что на него кто-то забредет случайно, сведется к минимуму.
- Любой запрос к WrapAPI требует специального токена, который нужно получить в своей учетке WrapAPI. То есть просто так узнать URL к твоему репозиторию и таскать через него данные не получится. Токены подразделяются на два типа: серверные и клиентские, для использования прямо на веб-страничке через JavaScript. Для последних нужно указать домен, с которого будут поступать запросы.
- Ну и наконец, в скором времени разработчик обещает выпустить self-hosted версию WrapAPI, которую ты сможешь поставить на свой сервер и забыть о проблеме утечек данных (конечно, при условии, что в коде WrapAPI не будет бэкдоров).
Приготовления
Несколько простых шагов перед началом.
- Идем на сайт WrapAPI, создаем новую учетку и логинимся в нее.
- Устанавливаем расширение для Chrome (подойдет любой Chromium-based браузер), открываем консоль разработчика и видим новую вкладку WrapAPI .
- Переходим на нее и логинимся.
Это расширение нам понадобится для того, чтобы перехватывать запросы, которые мы собираемся эмулировать, и быстро направлять их в WrapAPI для дальнейшей работы. По логике работы это расширение очень похоже на связку Burp Proxy + Burp Intruder.

Для работы с WrapAPI нужно повторно авторизоваться еще и в расширении в консоли разработчика Chrome
Отлавливаем запросы
Для получения постов я предлагаю использовать запрос пагинации, он доступен без авторизации и может отдавать по десять постов для любой страницы «Хакера», возвращая HTML в объекте JSON (см. ниже).

Запросы, которые генерятся по нажатию на ссылки пагинатора, будем использовать как образец

Запрос пойман, сохраняем его на сервер WrapAPI
Конфигурируем WrapAPI
После того как ты выбрал нужное имя для твоего репозитория (я взял test001 и endpoint posts ) и сохранил его на сервер WrapAPI через расширение для Chrome, иди на сайт WrapAPI и открывай репозиторий. Самое время настраивать наш API.

Обзор нашего будущего API
Переходи на вкладку Inputs and request. Здесь нам понадобится указать, с какими параметрами WrapAPI должен парсить запрашиваемую страницу, чтобы сервер отдал ему валидный ответ.

Конфигурируем входные параметры запроса
Аккуратно перебей все параметры из пойманной WrapAPI полезной нагрузки (POST body payload) в поле слева. Для всех параметров, кроме paginated , выставь тип Constant . Это означает, что в запросы к серверу будут поставляться предопределенные значения, управлять которыми мы не сможем (нам это и не нужно). А вот для paginated выставляй Variable API , указав имя page . Это позволит нам потом обращаться к нашему API по URL вида GET /posts?page=5 (с query-параметром page ), а на сервер уже будет уходить полноценный POST со всеми перечисленными параметрами.
Заголовки запроса ниже можно не трогать, я использовал стандартные из Chromium. Если парсишь не «Хакер», а данные с какого-нибудь закрытого сервера, можешь подставить туда нужные куки, хедеры, basic-auth и все, что нужно. Одним словом, ты сможешь настроить свой запрос так, чтобы сервер безо всяких подозрений отдал тебе контент.

Выставляем необходимые POST-параметры в формате form/urlencoded, чтобы наш запрос отработал правильно
Учим WrapAPI недостающим фичам
Теперь нужно указать WrapAPI, как обрабатывать полученный результат и в каком виде его представлять. Переходи на следующую вкладку — Outputs and response.

Шаг настройки постпроцессоров полученного контента

Тестовый кейс page1, ответ сервера
JSON output
Первым делом нужно вытащить из объекта JSON значение атрибута content. Создавай новый output типа JSON и в появившемся модальном окне указывай имя параметра content . Сразу же под текстовым полем WrapAPI подсветит найденное значение выходной строки. То, что нам нужно. Сохраняем output и идем дальше.

JSON output для получения значения атрибута content на выход
CSS output
Следующий шаг — вытащить нужные нам поля постов из полученной с сервера верстки, а именно title , excerpt , image , date и id .
Во WrapAPI можно создавать дочерние аутпуты. Нажав на + около существующего output, ты создашь дочерний output, который будет принимать на выход значение предыдущего. Не перепутай! Если просто выбрать пункт Add new output, то будет создан новый root-селектор, который на вход получит голый ответ сервера.

Создаем дочерний CSS output
В появившемся окне вводим название класса заголовка .title-text . Внимание: обязательно отметь опцию Select all into an array , иначе будет выбран только первый заголовок, а нам нужно получить все десять по количеству постов в одном ответе сервера.

Задаем параметры получения данных из HTML-верстки
На выходе в ключе titles у нас окажется массив заголовков, которые вернул CSS output. Согласись, уже неплохо, и все это — без единой строки кода!

Полученные заголовки новостей
Как получить остальные параметры
Как ты помнишь, кроме title , для каждого поста нам нужно получить еще excerpt , image , date и id . Тут все не так здорово: WrapAPI имеет два ограничения:
- он не позволяет создавать цепочки из более чем одного уровня вложенности дочерних outputs;
- он не позволяет задавать несколько селекторов для CSS output’a. То есть CSS output может вытащить только title , только date и так далее.
Признаться, мне пришлось немного поломать голову, чтобы обойти эти ограничения. Я сделал много дочерних по отношению к JSON аутпутов CSS — по одному на каждый из параметров. Они выводят мне в итоговый результат несколько массивов: один с заголовками, один с превью статьи, один с датами и так далее.

Массив дочерних аутпутов, каждый из которых выбирает свой атрибут постов
В итоге у меня получился вот такой массив данных:
Стоит отметить, что для backgroundImages нужно указать получение не текста HTML-тега, а значения атрибута style , так как URL картинки задан в свойстве inline-CSS, а не в атрибуте src тега img .
Приводим все в порядок
Сейчас наш API уже выглядит вполне читаемым, осталось решить две проблемы:
- все компоненты поста — заголовок, дата, превью — находятся в разных массивах;
- в backgroundImages попал кусок CSS, а не чистый URL.
Решить эти проблемы нам поможет следующая вкладка — Post-processing script. Она позволяет написать небольшой синхронный скрипт на JavaScript, который может сделать что-то с нашим контентом перед тем, как он отправится на выход.
Скрипт должен содержать функцию postProcess() , которая принимает один аргумент — текущие результаты парсинга. То, что она вернет, и будет конечным ответом нашего API.
Я набросал небольшой скрипт, который быстро собрал все компоненты в единый массив постов, а также почистил URL картинки. Останавливаться на этом подробнее смысла нет, все, я думаю, и так предельно ясно.

Пишем скрипт для постпроцессинга данных
Тестируем результат
Перед тем как пробовать наш запрос, нужно получить API-ключ. Ключи WrapAPI бывают двух типов:
- приватные, для использования на сервере, не имеют ограничений;
- публичные, для использования на клиенте. Они имеют ограничение по домену, с которого происходит запрос.
Для теста получи новый приватный ключ и попробуй сделать запрос к своему API, поставив свой ключ в query-параметр wrapAPIKey .

Получение ключей доступа к API
У меня вышел вот такой запрос:
Ответ сервера показан на скриншоте. Победа! 🙂

Десять постов с 256-й страницы «Хакера» (?page=256)
Выводы
Сегодня почти все сервисы, которые мы используем, имеют своего рода API. Некоторые веб-приложения даже создаются только из точек API и передаются в какое-то интерфейсное представление. Если вы являетесь пользователем службы, предоставляющей API, вам иногда понадобятся дополнительные функции или ограничения, которые может предложить API. В этой статье мы расскажем о сервисе, который полезен как пользователям, так и создателям API.
Я всегда говорю, что если есть веб-интерфейс, вы можете создать собственный API. WrapAPI пытается сделать этот процесс проще. Если вы знакомы с процессом очистки / сканирования (или извлечения данных с веб-сайтов), вы увидите магию WrapAPI.
WrapAPI предлагает сервис, который позволяет легко извлекать информацию с веб-сайтов и создавать API-интерфейсы из данных. Он предоставляет простой, интерактивный способ выбора того, какую информацию вы хотите получить. Всего несколькими щелчками мыши вы можете подключить свой API онлайн.
Как обойти WrapAPI
На сайте WrapAPI вы увидите, что можете приступить к созданию своего проекта сразу, хотя, если вы не создадите учетную запись, ваша работа не будет сохранена.
После того, как вы зарегистрировались, нажмите кнопку Построить API .

Получение данных
Теперь вы должны видеть SitePoint внутри фрейма просмотра браузера .

Помимо селекторов CSS, WrapAPI поддерживает регулярные выражения, селекторы JSON, заголовки, файлы cookie, выходные данные форм и множество других опций. Вы можете использовать их все вместе и извлекать именно то, к чему вы стремитесь. В этом примере мы будем использовать только селекторы CSS.

В правой части интерфейса вы увидите три вкладки. Давайте посмотрим на текущую вкладку Build . Результаты покажут нам селекторы (в нашем случае селекторы CSS), и вы получите более подробную информацию о том, что вы хотели бы выбрать. Мы заинтересованы только в извлечении заголовка, который является текстом. Есть и другие варианты очистки результатов, но мы не будем вдаваться в эти детали. Если вы хотите создать другой селектор, чтобы выбрать описание, автора, дату и т. Д., Просто нажмите Создать новую коллекцию / вывод . Называние ваших селекторов также важно, так как это облегчит использование нескольких селекторов на сайте. Нажав на значок карандаша, вы можете редактировать ваши селекторы.

На вкладке « Предварительный просмотр » будет показано представление наших данных в формате JSON, и вы, вероятно, получите представление о том, как будет выглядеть API. Если вы довольны результатами, вы можете нажать кнопку Сохранить , чтобы сохранить версию API.

Вам нужно будет ввести репозиторий и имя конечной точки API. Это помогает вам управлять и организовывать свои API. Это также будет частью имени вашего API в конце. После ввода информации вы вернетесь к застройщику. Наш API сохранен, но теперь нам нужно протестировать и опубликовать его.
Советы
- Если на сайте есть нумерация страниц (предыдущая / следующая страница), вы можете использовать параметры строки запроса. (Подробнее об этом здесь .)
- Назовите ваши селекторы правильно, так как они будут частью вывода JSON.
Расширение WrapAPI Chrome
На этот раз давайте воспользуемся Hacker News. Посетите сайт, с которого вы хотите получить данные, а затем выполните следующие действия:
Откройте Chrome DevTools и перейдите на вкладку WrapAPI на самой правой вкладке.
Разблокируйте его в отдельном окне.

Войдите с вашими учетными данными WrapAPI.

Когда вы будете готовы, нажмите кнопку Запустить захват запросов .
Обновите главную вкладку, где вы используете.
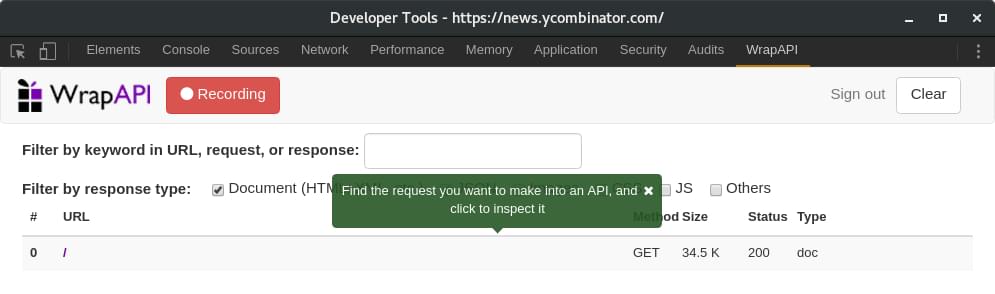
Выберите запрос, который вы хотите сделать в API (используя GET
Наконец, щелкните ссылку: нажмите здесь, чтобы использовать ее для определения входов и выходов конечной точки API…
Вы будете перенаправлены к строителю, чтобы извлечь данные. Преимущество использования этого метода заключается в том, что вы можете обходить страницы входа и использовать уже назначенные файлы cookie.
Публикация API
Перед публикацией нашего API мы должны заморозить его. Выбор номера выпуска, такого как 0.0.1, работает нормально. Обратите внимание, что любые изменения, которые вы вносите в API, вам придется заморозить как новую версию, также увеличив номер версии. Предоставьте простое описание того, что представляет собой ваш API, или, если это обновление, какие изменения оно содержит. Наконец, нажмите Опубликовать .

И вот наш последний API:

Вывод
В течение минуты мы смогли создать API из простого веб-интерфейса.
Есть некоторые вещи, которые вы должны рассмотреть. Очистка / извлечение данных с веб-сайтов может иногда иметь юридические последствия для содержимого, найденного на веб-сайте. Если вам случается использовать веб-сайт в качестве службы для вашего API, рассмотрите вопрос о разрешении использовать этот контент, особенно при распространении его в виде API.
WrapAPI предоставляет некоторые действительно замечательные и простые в использовании функции, но они не обходятся без цены. Бесплатные учетные записи и учетные записи сообщества предоставляются бесплатно, но вы можете создавать только открытые API, и существует ограничение в 30 000 вызовов API в месяц. Есть несколько тарифных планов . Вы всегда можете создать свои собственные API и скребки, но если вам не хватает навыков или у вас нет времени, то, возможно, вы захотите попробовать WrapAPI.
В этом уроке мы расскажем о структуре API и рассмотрим несколько примеров получения данных.
Напомним схему взаимосвязи объектов в API Директа, которую мы показывали в первом уроке:
Для каждого класса объектов в API предусмотрен соответствующий сервис: Campaigns — для управления кампаниями, AdGroups — для управления группами объявлений, Ads — для управления объявлениями и т. д. Полный список сервисов приведен в документации.
Логика работы с объектами в API унифицирована, и методы всех сервисов имеют стандартные названия. Как правило, сервис включает следующие методы:
В сервисе могут быть и другие методы. Например, в сервисе Campaigns доступны следующие методы:
Как получать объекты
Давайте рассмотрим, как получить параметры рекламной кампании, используя метод get .
Метод get разработан так, чтобы можно было запрашивать только нужные данные. Например, можно получить только идентификаторы и названия кампаний, а не все их параметры. Имена нужных вам параметров необходимо перечислить во входном параметре FieldNames .
Критерии отбора объектов нужно указать во входной структуре SelectionCriteria . Если критериев отбора несколько, то сервер будет искать объекты, подходящие сразу под все критерии. Некоторые сервисы позволяют указывать пустую структуру SelectionCriteria — в этом случае возвращаются все объекты.
Тренировка в Песочнице
Напомним пример запроса из предыдущего урока. В этом примере мы получили весь список кампаний, указав пустую структуру SelectionCriteria , и для каждой кампании получили только идентификатор и название, указав соответствующие параметры в FieldNames .
Внимание. Не забудьте изменить токен и идентификаторы в примерах на ваши данные.Некоторые параметры кампании (такие как название и идентификатор) являются общими для всех типов кампаний, а некоторые (например, стратегии показа) зависят от типа кампании. В следующем примере мы получим только кампании с типом «Текстово-графические объявления» . Чтобы получить для таких кампаний стратегии показа, укажем имя соответствующего параметра во входном параметре TextCampaignFieldNames .
cURL cURL для Windows Запрос Ответ Постраничная выборка Если вы работаете с большими массивами данных, все объекты могут не уместиться в ответе на один запрос, так как метод get возвращает не более 10 000 объектов. В этом случае метод get возвращает параметр LimitedBy — порядковый номер последнего возвращенного объекта. Наличие этого параметра указывает, что не все объекты получены. Настроить параметры постраничной выборки можно с помощью входной структуры Page . Укажите количество нужных объектов — например, 10 — и количество объектов, которое должно быть пропущено при выборке, — например, 20, — и вы получите порцию данных: 10 объектов с 21-го по 30-й.
Задание
Мы подготовили несколько примеров и для других сервисов. Попробуйте воспроизвести эти запросы в Песочнице.
Читайте также: