
Файлы приложения содержатся в каких данных
Файловая система позволяет программам обходиться набором достаточно простых операций для выполнения действий над некоторым абстрактным объектом, представляющим файл . При этом программистам не нужно иметь дело с деталями действительного расположения данных на диске, буферизацией данных и другими низкоуровневыми проблемами передачи данных с запоминающего устройства. Все эти функции файловая система берет на себя. Файловая система распределяет дисковую память , поддерживает именование файлов, отображает имена файлов в соответствующие адреса во внешней памяти, обеспечивает доступ к данным, поддерживает разделение, защиту и восстановление данных.
Таким образом, файловая система играет роль промежуточного слоя, экранизирующего все сложности физической организации долговременного хранилища данных и создающего для программ более простую логическую модель этого хранилища, а затем предоставляет им набор удобных в использовании команд для манипулирования файлами.
Классическая схема организации программного обеспечения файловой системы представлена на рис. 7.6.
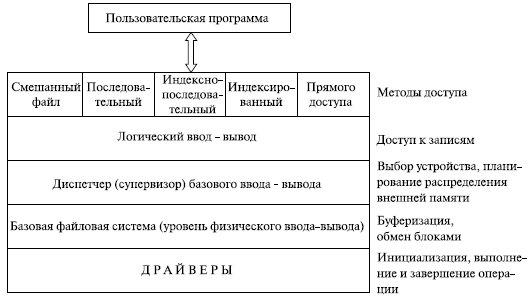
Рис. 7.6. Организация программного обеспечения файловой системы
На нижнем уровне драйверы устройств непосредственно связаны с периферийными устройствами или их котроллерами либо каналами. Драйвер устройства отвечает за начальные операции ввода-вывода устройства и за обработку завершения запроса ввода-вывода. При файловых операциях контролируемыми устройствами являются дисководы и стримеры (накопители на МЛ). Драйверы устройств рассматриваются как часть операционной системы.
Следующий уровень называется базовой файловой системой, или уровнем физического ввода-вывода. Это первичный интерфейс с окружением (периферией) компьютерной системы. Он оперирует блоками данных, которыми обменивается с дисками, магнитной лентой и другими устройствами. Поэтому он связан с размещением и буферизацией блоков в оперативной памяти. На этом уровне не выполняется работа с содержимым блоков данных или структурой файлов. Базовая файловая система обычно рассматривается как часть операционной системы (в MS- DOS эти функции выполняет BIOS , не относящийся к ОС).
Диспетчер базового ввода-вывода отвечает за начало и завершение файлового ввода-вывода. На этом уровне поддерживаются управляющие структуры, связанные с устройством ввода-вывода, планированием и статусом файлов. Диспетчер осуществляет выбор устройства, на котором будет выполняться операция файлового ввода-вывода, планирование обращения к устройству (дискам, лентам), назначение буферов ввода-вывода и распределение внешней памяти. Диспетчер базового ввода-вывода является частью ОС.
Логический ввод- вывод предоставляет приложениям и пользователям доступ к записям. Он обеспечивает возможности общего назначения по вводу-выводу записей и поддерживает информацию о файлах. Наиболее близкий к пользователю уровень ФС часто называется методом доступа. Он обеспечивает стандартный интерфейс между приложениями и файловыми системами и устройствами, содержащими данные. Различные методы доступа отражают различные структуры файлов и различные пути доступа и обработки данных.
7.13. Организация файлов и доступ к ним
Типы, именование и атрибуты файлов
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых входят обычные файлы, содержащие информацию произвольного характера (текст, графика , звук и др.), файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и др.
Обычные файлы, или просто файлы, или регулярные файлы, содержат информацию, которую в них заносит пользователь или которая образуется в результате работы системных и пользовательских программ. Большинство ОС не контролируют содержимое и структуру регулярных файлов , которые в основном являются ASCII-файлами либо двоичными файлами. ASCII-фалы состоят из текстовых строк. Они могут отображаться на экране и выводиться на печать без какого-либо преобразования, и могут редактироваться практически любым текстовым редактором. Двоичные файлы имеют определенную внутреннюю структуру, которая известна программе, использующей данный файл . При выводе двоичного файла на принтер получается случайный набор символов.
Каталоги – это системные файлы, обеспечивающие поддержку структуры файловой системы. Они содержат системную справочную информацию о наборе файлов, сгруппированных пользователем по какому-либо неформальному признаку (договоры, рефераты, курсовые проекты и т.п.). Во многих ОС в каталог могут входить другие файлы, в том числе другие каталоги, за счет чего образуется древовидная структура, удобная для поиска требуемого файла. Каталоги устанавливают соответствие между именами файлов и их характеристиками, используемыми файловой системой для управления файлами. В число таких характеристик входят тип файла , права доступа к файлу, его распоряжение на диске, размер, дата и время создания и др.
Специальные файлы – это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к последовательным устройствам ввода-вывода, таким как терминалы, принтеры и др. (например, MS- DOS рассматривает монитор и клавиатуру как файлы со стандартным именем con – консоль , а принтер – как файл prn ). Блочные специальные файлы используются для моделирования дисков.
Именованные конвейеры (каналы) представляют собой циклические буферы, позволяющие выходной файл одной программы соединить со входным файлом другой программы.
Наконец, отображаемые файлы – это обычные файлы, отображенные на адресное пространство процесса по указанному виртуальному адресу.
Файлы относятся к абстрактному механизму. Они предоставляют способ сохранять информацию на запоминающем устройстве и считывать ее позднее снова. При этом от пользователя должны скрываться такие детали, как способ и место хранения информации, а также детали работы устройства.
Во многих операционных системах имя файла состоит из двух частей, разделенных точкой. Часть имени после точки называется расширением файла и обычно означает его тип. Так, в MS- DOS имя файла может содержать от 1 до 8 символов, а расширение от 0 (отсутствует) до 3.
В некоторых ОС, например, Windows , расширение указывает на программу, создавшую файл . Другие ОС, например, UNIX , не принуждают пользователя строго придерживаться расширений. Некоторые типичные расширения файлов приведены ниже.
В иерархически организованных файловых системах обычно используются три типа имен файлов: простые, составные и относительные.
Простое (короткое) символьное имя идентифицирует файл в пределах одного каталога. Несколько файлов могут иметь одно и то же простое имя , если они принадлежат разным каталогам.
Составное (полное) символьное имя представляет собой цепочку, содержащую имя диска и имена всех каталогов, через которые проходит путь от корневого каталога до данного файла.
Относительное имя файла определяется через текущий каталог , т.е. каталог, в котором в данный момент времени работает пользователь . Таким образом, относительных имен у файла может быть достаточно много, и все они являются частью полного имени.
Понятие файла включает не только хранимые им данные и имя, но и информацию, описывающую свойства файла. Эта информация составляет атрибуты файла. Список атрибутов может быть различным в различных ОС. Пример возможных атрибутов приведен ниже.
Пользователь может получить доступ к атрибутам, используя средства, предоставляемые для этой цели файловой системой. Обычно разрешается читать значение любых атрибутов, а изменять – только некоторые.
Значения атрибутов файлов могут содержаться в каталогах, как это сделано, например, в MS- DOS (рис. 7.7). Другим вариантом является размещение атрибутов в специальных таблицах, в этом случае в каталогах содержатся ссылки на эти таблицы.
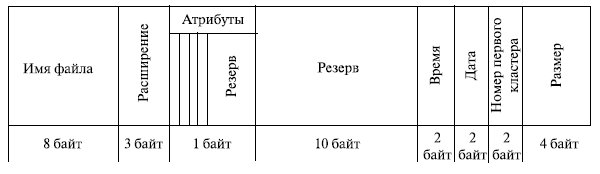
Логическая организация файла
В общем случае данные, содержащиеся в файле, имеют некоторую логическую структуру. Эта структура (организация) файла является базой при разработке программы, предназначенной для обработки этих данных. Поддержание структуры данных может быть целиком возложено на приложение либо в той или иной степени эту работу может взять на себя файловая система .
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла, целиком относятся к ведению приложения, файл представляется файловой системе неструктурированной последовательностью данных. Приложение формирует запросы к файловой системе на ввод- вывод , используя общие для всех приложений системные средства, например, указывая смещение от начала файла и количество байт , которые необходимо считать или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой. Следует подчеркнуть, что интерпретация данных никак не связана с действительным способом их хранения в файловой системе.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью байт , стала популярной вместе с ОС UNIX , и теперь широко используется в современных ОС. Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями, поскольку разные приложения могут по -своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла – структурированный файл . В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением!
Известно пять фундаментальных способов организации файлов [10]:
- смешанный файл,
- последовательный файл ,
- индексно- последовательный файл ,
- индексируемый файл,
- файл прямого доступа.
При выборе способа организации файла нужно учитывать несколько критериев:
- быстрота доступа,
- легкость обновления,
- экономность хранения,
- простота обслуживания,
- надежность.
Смешанный файл . Это наименее сложная форма организации файла. Данные накапливаются в порядке поступления. Запись состоит из одного пакета данных. Записи могут иметь различные или одинаковые поля, расположенные в различном порядке (рис. 7.8). Каждое поле описывает само себя, включая как имя, так и значение . Длина каждого поля должна быть указана явно либо посредством применения разделителя.

Поскольку смешанный файл не имеет никакой структуры, доступ к записи осуществляется полным перебором всех записей файла. Смешанные файлы применяются в том случае, когда данные накапливаются и сохраняются перед обработкой, или если данные неудобны для организации. Файлы этого типа рационально используют дисковое пространство , хорошо подходят для полного набора. Обновление записей достаточно сложно, так же как и вставка записи.
Последовательный файл . Для записей используется фиксированный формат. Все записи имеют одинаковую длину (но иногда и не одинаковую) и состоят из одинакового количества полей фиксированной длины, организованных в определенном порядке (рис. 7.9). Поскольку длина и позиция каждого поля известны, сохранению подлежат только значения полей. Атрибутами файловой структуры является имя и длина каждого поля.
Одно определенное поле (или несколько полей) называется ключевым. Оно однозначно идентифицирует запись , так как это поле различно для каждой записи. Более того, записи сохраняются в "ключевой" последовательности: в алфавитном порядке для текстового ключа и в числовом – для числового. Последовательные файлы часто используются пакетными приложениями и обычно являются оптимальным вариантом, если эти приложения выполняют обработку всех записей. Удобно и то, что такой файл можно хранить как на ленте, так и на магнитном диске.
Для диалоговых приложений последовательный файл малоэффективен, поскольку для нахождения нужной записи требуется последовательный перебор записи файла. Правда, если в оперативную память загрузить весь файл , возможен более эффективный метод поиска. Дополнения к файлу или изменения в записях создают проблемы.
Обычно последовательный файл сохраняется с последовательной организацией записей внутри блока, т.е. физическая организация файла в точности соответствует логической. Новые записи размещаются в отдельном смешанном файле, называемом журнальным файлом, или файлом транзакции. Периодически в пакетном режиме выполняется слияние основного и журнального файлов в новый файл с корректной последовательностью ключей.
Альтернативной организацией может быть физическая организация в виде списка с использованием указателей. В каждом физическом блоке сохраняется одна или несколько записей, и каждый блок содержит указатель на следующий блок. Для вставки новых записей достаточно изменить указатели, и нет необходимости в том, чтобы новые записи занимали определенную физическую позицию. Это удобство достигается за счет определенных накладных расходов и дополнительной работы. Если в последовательном файле записи имеют одну и ту же длину, то можно вычислить адрес требуемой записи по ее номеру, номеру текущей записи и длине записи. Если записи имеют переменную длину, такой подход невозможен.
Индексно- последовательный файл . Одним из методов преодоления недостатков последовательного файла является индексно-последовательная организация файла. В этом случае файл состоит из трех частей (файлов): главный файл , содержащий записи с последовательно идущими ключами, индексный файл , содержащий индексное поле , и указатель в главный с ключами, файл переполнения (рис. 7.10).
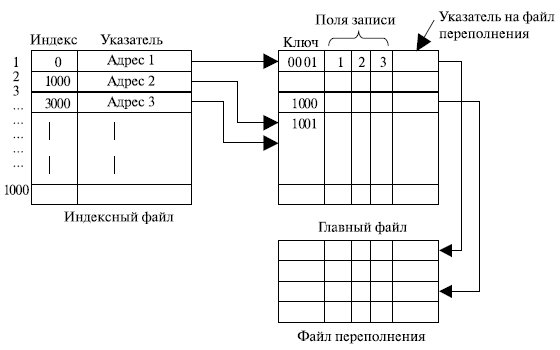
Для поиска нужной записи по ее ключу сначала выполняется поиск в индексном файле. После того как в нем найдено наибольшее значение ключа, которое не превышает искомое, продолжается поиск в главном файле. Например, пусть последовательный файл (главный) содержит 1 млн записей. Для поиска определенного ключевого значения необходимо в среднем 0,5 млн операций доступа к записям. Если создать индексный файл , содержащий 1000 элементов, то потребуется в среднем 500 операций доступа к индексному файлу, после чего еще нужно в среднем 500 операций доступа к главному файлу. В результате средняя длина поиска уменьшилась с 0,5 млн до 1000. Еще лучшего результата можно достичь, используя многоуровневую индексацию. При этом нижний уровень индексного файла рассматривается как последовательный файл , для которого создается индексный файл верхнего уровня.
Дополнения к файлу обрабатываются следующим образом. В каждой записи главного файла содержится дополнительное поле , невидимое для приложения и являющееся указателем на файл переполнения. Если в файле производится вставка новой записи, она добавляется в файл переполнения. Запись в главном файле, непосредственно предшествующая новой записи в логической последовательности, обновляется и указывает на новую запись в файле переполнения. Время от времени выполняется слияние индексно- последовательного файла с файлом переполнения.
Индексированный файл . Индексно- последовательный файл сохраняет одно ограничение последовательного файла : эффективная работа с файлом ограничена работой с ключевым полем. Если необходимо производить поиск записи по какой-либо иной характеристике, отличной от ключевого поля, то оказываются непригодными обе организации последовательного файла , в то время как в некоторых приложениях эта гибкость крайне желательна.
Для достижения гибкости необходимо применение большого количества индексов, по одному для каждого типа поля, которое может быть объектом поиска. В обобщенном индексированном файле доступ к записям осуществляется только по их индексам. В результате в размещении записей нет никаких ограничений до тех пор, пока указатель по крайней мере в одном индексе ссылается на эту запись . Кроме того, в таком файле легко реализуются записи переменной длины.
Используется два типа индексов. Полный индекс содержит по одному элементу для каждого типа записей главного файла. Сам по себе индекс организовывается в виде последовательного файла для облегчения поиска. Частный индекс содержит элементы для записей, в которых имеется интересующее пользователя поле . При добавлении новой записи в главный файл необходимо обновлять все индексные файлы.
Индексированные файлы применяются теми приложениями, в которых время доступа к информации является критической характеристикой и редко требуется обработка всех записей в файле.
Файл прямого доступа. Такой файл использует возможность прямого доступа к блоку с известным адресом при хранении файлов на диске. В каждой записи в этом случае также имеется ключевое поле .

Файловая система . На каждом носителе информации (гибком, жестком или лазерном диске) может храниться большое количество файлов. Порядок хранения файлов на диске определяется используемой файловой системой.
Каждый диск разбивается на две области: обла сть хранения файлов и каталог. Каталог содержит имя файла и указание на начало его размещения на диске. Если провести аналогию диска с книгой, то область хранения файлов соответствует ее содержанию, а каталог - оглавлению. Причем книга состоит из страниц, а диск - из секторов.
Для дисков с небольшим количеством файлов (до нескольких десятков) может использоваться одноуровневая файловая система , когда каталог (оглавление диска) представляет собой линейную последовательность имен файлов (табл. 1.2). Такой каталог можно сравнить с оглавлением детской книжки, которое содержит только названия отдельных рассказов.
Если на диске хранятся сотни и тысячи файлов, то для удобства поиска используется многоуровневая иерархическая файловая система , которая имеет древовидную структуру. Такую иерархическую систему можно сравнить, например, с оглавлением данного учебника, которое представляет собой иерархическую систему разделов, глав, параграфов и пунктов.
Начальный, корневой каталог содержит вложенные каталоги 1-го уровня, в свою очередь, каждый из последних может содержать вложенные каталоги 2-го уровня и так далее. Необходимо отметить, что в каталогах всех уровней могут храниться и файлы.
Например, в корневом каталоге могут находиться два вложенных каталога 1-го уровня (Каталог_1, Каталог_2) и один файл (Файл_1). В свою очередь, в каталоге 1-го уровня (Каталог_1) находятся два вложенных каталога второго уровня (Каталог_1.1 и Каталог_1.2) и один файл (Файл_1.1) - рис. 1.3.
Файловая система - это система хранения файлов и организации каталогов.
Рассмотрим иерархическую файловую систему на конкретном примере. Каждый диск имеет логическое имя (А:, В: - гибкие диски, С:, D:, Е: и так далее - жесткие и лазерные диски).
Пусть в корневом каталоге диска С: имеются два каталога 1-го уровня (GAMES, TEXT), а в каталоге GAMES один каталог 2-го уровня (CHESS). При этом в каталоге TEXT имеется файл proba.txt, а в каталоге CHESS - файл chess.exe (рис. 1.4).
| Рис. 1.4. Пример иерархической файловой системы |
Путь к файлу . Как найти имеющиеся файлы (chess.exe, proba.txt) в данной иерархической файловой системе? Для этого необходимо указать путь к файлу. В путь к файлу входят записываемые через разделитель "\" логическое имя диска и последовательность имен вложенных друг в друга каталогов, в последнем из которых содержится нужный файл. Пути к вышеперечисленным файлам можно записать следующим образом:
Путь к файлу вместе с именем файла называют иногда полным именем файла.
Пример полного имени файла:
Представление файловой системы с помощью графического интерфейса . Иерархическая файловая система MS-DOS, содержащая каталоги и файлы, представлена в операционной системе Windows с помощью графического интерфейса в форме иерархической системы папок и документов. Папка в Windows является аналогом каталога MS-DOS
Однако иерархическая структура этих систем несколько различается. В иерархической файловой системе MS-DOS вершиной иерархии объектов является корневой каталог диска, который можно сравнить со стволом дерева, на котором растут ветки (подкаталоги), а на ветках располагаются листья (файлы).
В Windows на вершине иерархии папок находится папка Рабочий стол. Следующий уровень представлен папками Мой компьютер, Корзина и Сетевое окружение (если компьютер подключен к локальной сети) - рис. 1.5.
| Рис. 1.5. Иерархическая структура папок |
Если мы хотим ознакомиться с ресурсами компьютера, необходимо открыть папку Мой компьютер.
1. В окне Мой компьютер находятся значки имеющихся в компьютере дисков. Активизация (щелчок) значка любого диска выводит в левой части окна информацию о его емкости, занятой и свободной частях.
Сайт учителя информатики. Технологические карты уроков, Подготовка к ОГЭ и ЕГЭ, полезный материал и многое другое.
Информатика. 7 класса. Босова Л.Л. Оглавление
Логические имена устройств внешней памяти компьютера
К каждому компьютеру может быть подключено несколько устройств внешней памяти. Основным устройством внешней памяти ПК является жёсткий диск. Если жёсткий диск имеет достаточно большую ёмкость, то его можно разделить на несколько логических разделов.
Наличие нескольких логических разделов на одном жёстком диске обеспечивает пользователю следующие преимущества:
- можно хранить операционную систему в одном логическом разделе, а данные — в другом, что позволит переустанавливать операционную систему, не затрагивая данные;
- на одном жёстком диске в различные логические разделы можно установить разные операционные системы;
- обслуживание одного логического раздела не затрагивает другие разделы.
Каждое подключаемое к компьютеру устройство внешней памяти, а также каждый логический раздел жёсткого диска имеет логическое имя.
В операционной системе Windows приняты логические имена устройств внешней памяти, состоящие из одной латинской буквы и знака двоеточия:
- для дисководов гибких дисков (дискет) — А: и В:;
- для жёстких дисков и их логических разделов — С:, D:, Е: и т. д.;
- для оптических дисководов — имена, следующие по алфавиту после имени последнего имеющегося на компьютере жёсткого диска или раздела жёсткого диска (например, F:);
- для подключаемой к компьютеру флеш-памяти — имя, следующее за последним именем оптического дисковода (например, G:).
В операционной системе Linux приняты другие правила именования дисков и их разделов. Например:
- логические разделы, принадлежащие первому жёсткому диску, получают имена hdal, hda2 и т. д.;
- логические разделы, принадлежащие второму жёсткому диску, получают имена hdbl, hdb2 и т. д.
Файл
Все программы и данные хранятся во внешней памяти компьютера в виде файлов.
Файл — это поименованная область внешней памяти.
Файловая система — это часть ОС, определяющая способ организации, хранения и именования файлов на носителях информации.
Файл характеризуется набором параметров (имя, размер, дата создания, дата последней модификации) и атрибутами, используемыми операционной системой для его обработки (архивный, системный, скрытый, только для чтения). Размер файла выражается в байтах.
Файлы, содержащие данные — графические, текстовые (рисунки, тексты), называют документами, а файлы, содержащие прикладные программы, — файлами-приложениями. Файлы-документы создаются и обрабатываются с помощью файлов-приложений.
Имя файла, как правило, состоит из двух частей, разделенных точкой: собственно имени файла и расширения. Собственно имя файлу даёт пользователь. Делать это рекомендуется осмысленно, отражая в имени содержание файла. Расширение имени обычно задаётся программой автоматически при создании файла. Расширения не обязательны, но они широко используются. Расширение позволяет пользователю, не открывая файла, определить его тип — какого вида информация (программа, текст, рисунок и т. д.) в нём содержится. Расширение позволяет операционной системе автоматически открывать файл.
В современных операционных системах имя файла может включать до 255 символов, причём в нём можно использовать буквы национальных алфавитов и пробелы. Расширение имени файла записывается после точки и обычно содержит 3-4 символа.
Операционная система Linux, в отличие от Windows, различает строчные и прописные буквы в имени файла: например, FILE.txt, file.txt и FiLe.txt — это в Linux три разных файла.
В таблице приведены наиболее распространённые типы файлов и их расширения:

В ОС Linux выделяют следующие типы файлов:
- обычные файлы — файлы с программами и данными;
- каталоги — файлы, содержащие информацию о каталогах;
- ссылки — файлы, содержащие ссылки на другие файлы;
- специальные файлы устройств — файлы, используемые для представления физических устройств компьютера (жёстких и оптических дисководов, принтера, звуковых колонок и т. д.).
Каталоги
На каждом компьютерном носителе информации (жёстком, оптическом диске или флеш-памяти) может храниться большое количество файлов. Для удобства поиска информации файлы по определённым признакам объединяют в группы, называемые каталогами или папками.
Каталог также получает собственное имя. Он сам может входить в состав другого, внешнего по отношению к нему каталога. Каждый каталог может содержать множество файлов и вложенных каталогов.
Каталог — это поименованная совокупность файлов и подкаталогов (вложенных каталогов).
Каталог самого верхнего уровня называется корневым каталогом.
В ОС Windows любой информационный носитель имеет корневой каталог, который создаётся операционной системой без участия пользователя. Обозначаются корневые каталоги добавлением к логическому имени соответствующего устройства внешней памяти знака «\» (обратный слэш): А:\, В:\, С:\, D:\, Е:\ и т. д.
В Linux каталоги жёстких дисков или их логических разделов не принадлежат верхнему уровню файловой системы (не являются корневыми каталогами). Они «монтируются» в каталог mnt. Другие устройства внешней памяти (гибкие, оптические и флеш-диски) «монтируются» в каталог media. Каталоги mnt и media, в свою очередь, «монтируются» в единый корневой каталог, который обозначается знаком « / » (прямой слэш).
Файловая структура диска
Файловая структура диска — это совокупность файлов на диске и взаимосвязей между ними.
Файловые структуры бывают простыми и многоуровневыми (иерархическими).
Простые файловые структуры могут использоваться для дисков с небольшим (до нескольких десятков) количеством файлов. В этом случае оглавление диска представляет собой линейную последовательность имён файлов (рис. 2.8). Его можно сравнить с оглавлением детской книжки, которое содержит названия входящих в неё рассказов и номера страниц.

Иерархические файловые структуры используются для хранения большого (сотни и тысячи) количества файлов. Иерархия — это расположение частей (элементов) целого в порядке от высшего к низшим. Начальный (корневой) каталог содержит файлы и вложенные каталоги первого уровня. Каждый из каталогов первого уровня может содержать файлы и вложенные каталоги второго уровня и т. д. (рис. 2.9). В этом случае оглавление диска можно сравнить с оглавлением нашего учебника: в нём выделены главы, состоящие из параграфов, которые, в свою очередь, разбиты на отдельные пункты и т. д.

Пользователь, объединяя по собственному усмотрению файлы в каталоги, получает возможность создать удобную для себя систему хранения информации. Например, можно создать отдельные каталоги для хранения текстовых документов, цифровых фотографий, мелодий ит. д.; в каталоге для фотографий объединить фотографии по годам, событиям, принадлежности и т. д. Знание того, какому каталогу принадлежит файл, значительно ускоряет его поиск.
Графическое изображение иерархической файловой структуры называется деревом. В Windows каталоги на разных дисках могут образовывать несколько отдельных деревьев; в Linux каталоги объединяются в одно дерево, общее для всех дисков (рис. 2.10). Древовидные иерархические структуры можно изображать вертикально и горизонтально.

Полное имя файла
Чтобы обратиться к нужному файлу, хранящемуся на некотором диске, можно указать путь к файлу — имена всех каталогов от корневого до того, в котором непосредственно находится файл.
В операционной системе Windows путь к файлу начинается с логического имени устройства внешней памяти; после имени каждого подкаталога ставится обратный слэш. В операционной системе Linux путь к файлу начинается с имени единого корневого каталога; после имени каждого подкаталога ставится прямой слэш.
Последовательно записанные путь к файлу и имя файла составляют полное имя файла. Не может быть двух файлов, имеющих одинаковые полные имена.
Пример полного имени файла в ОС Windows:
Пример полного имени файла в ОС Linux:
Задача 1. Пользователь работал с каталогом С:\Физика\Задачи\Кинематика. Сначала он поднялся на один уровень вверх, затем ещё раз поднялся на один уровень вверх и после этого спустился в каталог Экзамен, в котором находится файл Информатика.dос. Каков путь к этому файлу?
Решение. Пользователь работал с каталогом С:\Физика\Задачи\Кинематика. Поднявшись на один уровень вверх, пользователь оказался в каталоге С:\Физика\Задачи. Поднявшись ещё на один уровень вверх, пользователь оказался в каталоге СДФизика. После этого пользователь спустился в каталог Экзамен, где находится файл. Полный путь к файлу имеет вид: С:\Физика\Экзамен.
Задача 2. Учитель работал в каталоге D:\Уроки\7 класс\Практические работы. Затем перешёл в дереве каталогов на уровень выше, спустился в подкаталог Презентации и удалил из него файл Введение, ppt. Каково полное имя файла, который удалил учитель?
Решение. Учитель работал с каталогом D:\Уроки\7 класс\Практические работы. Поднявшись на один уровень вверх, он оказался в каталоге D:\Уроки\8 класс. После этого учитель спустился в каталог Презентации, путь к файлам которого имеет вид: D:\Уроки\ 7 класс\Презентации. В этом каталоге он удалил файл Введение.ppt, полное имя которого D:\Уроки\8 класс\ Презентации \Введение.ррt.
Работа с файлами
Создаются файлы с помощью систем программирования и прикладного программного обеспечения.
В процессе работы на компьютере над файлами наиболее часто проводятся следующие операции:
- копирование (создаётся копия файла в другом каталоге или на другом носителе);
- перемещение (производится перенос файла в другой каталог или на другой носитель, исходный файл уничтожается);
- переименование (производится переименование собственно имени файла);
- удаление (в исходном каталоге объект уничтожается).
При поиске файла, имя которого известно неточно, удобно использовать маску имени файла. Маска представляет собой последовательность букв, цифр и прочих допустимых в именах файлов символов, среди которых также могут встречаться следующие символы: «?» (вопросительный знак) — означает ровно один произвольный символ; «*» (звездочка) — означает любую (в том числе и пустую) последовательность символов произвольной длины.
Например, по маске n*.txt будут найдены все файлы с расширением txt, имена которых начинаются с буквы «n», в том числе и файл n.txt. По маске п?.* будут найдены файлы с произвольными расширениями и двухбуквенными именами, начинающимися с буквы «n».
Вопросы
1. Ознакомьтесь с материалами презентации к параграфу, содержащейся в электронном приложении к учебнику. Дополняет ли презентация информацию, содержащуюся в тексте параграфа?
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Сидора А.А.
Android популярная мобильная платформа, используемая во множестве мобильных устройств, и даже автомобильных мультимедийных системах, в которых неотъемлемой частью является наличие навигационной системы, использующей спутники ГЛОНАСС и GPS. Для улучшения работы навигационных приложений, требуется хранить и использовать информацию о спутниках (их количестве, положении и т. д.). Рассматриваются способы хранения данных в приложениях операционной системы Android и их назначение. Приведены их характеристики и выделены основные случаи их использования в зависимости от типов данных.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Сидора А.А.
Разработка приложения для управления медиаконтентом информационных ресурсов общего назначения Геолокационные сервисы на мобильных устройствах под управлением операционной системы Android Оценка эффективности движения транспортных потоков на основе обработки навигационных данных о движении транспортных средств i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.THE METHODS OF STORING DATA IN ANDROID OS APPLICATIONS
Android is a popular mobile platform, which is used in many mobile devices, even in the car multimedia systems, in which an integral part is the presence of a navigation system using GLONASS and GPS satellites. To improve the navigation application it is required to store and use information about satellites (their number, position, etc.). The methods of storing data in android operating system applications are considered. Their characteristics are given and major cases of using depending on the types of data are shown.
Текст научной работы на тему «Способы хранения данных в приложениях Android os»
Решетнеескцие чтения. 2015
дорожная разметка (полосы). Первоначальной задачей является выделение разметки на общем фоне. На данном этапе появляется возможность распараллеливания задачи на несколько потоков. Если предположить, что у нас имеется устройство с четырехядерным процессором, то становится очевидным вариант разбиения матрицы изображения на 4 подматрицы [3] (рис. 1).
Рис. 1. Схема разделения матрицы
На данном этапе необходимо произвести выделение разметки на имеющемся изображении. Так как разметка нанесена белым цветом, необходимо выделить пиксели, цветовые составляющие которых больше определенного значения [4]:
[255, если r(x,y) > val, g(x,y) > val, b(x, y) > val,
После первого этапа необходимо проанализировать положение автомобиля относительно полос движения. Для этого рассматривается центральная область изображения, на которой представлена разметка полосы, в которой двигается автомобиль. Принимая во внимание эффект перспективы [5], можно выделить область в центре, которая должна находиться между двух полос движения и не включать в себя элементы разметки. Если же данная область и разметка совпали, то данная ситуация сигнализируется как съезд с полосы движения (рис. 2).
Данный алгоритм был протестирован на входном изображении с разрешением 640*480, результаты времени вычислений представлены в таблице.
Рис. 2. Область «интереса» на бинаризированом изображении
Сравнение времени обработки
Метод Время обработки, мс
Последовательный 1 438
Из представленных в таблице данных можно вычислить, что ускорение при использовании параллельной обработки составило около 270 %.
1. Catanzaro B. Ubiquitous Parallel Computing form Berkeley, Illinois, and Stanford // IEEE Computer Society. 2010. С. 41-55.
3. Yang T., Doolan D. Mobile Parallel computing // Proc. of the Fifth International Symposium on Parallel and Distributed Computing. IEEE International. 2006.
4. Bertozzi M., Broggi A. GOLD: A Parallel RealTime Stereo Vision System for Generic Obstacle and Lane Detection // IEEE Transaction on image processing. 1998. Vol. 7, no. 1.
© Савельев А. С., Томилина А. И., 2015
СПОСОБЫ ХРАНЕНИЯ ДАННЫХ В ПРИЛОЖЕНИЯХ ANDROID OS
Сибирский государственный аэрокосмический университет имени академика М. Ф. Решетнева Российская Федерация, 660037, г. Красноярск, просп. им. газ. «Красноярский рабочий», 31
Android - популярная мобильная платформа, используемая во множестве мобильных устройств, и даже автомобильных мультимедийных системах, в которых неотъемлемой частью является наличие навигационной системы, использующей спутники ГЛОНАСС и GPS. Для улучшения работы навигационных приложений, требуется хранить и использовать информацию о спутниках (их количестве, положении и т. д.). Рассматриваются способы хранения данных в приложениях операционной системы Android и их назначение. Приведены их характеристики и выделены основные случаи их использования в зависимости от типов данных.
Ключевые слова: Android, база данных, способы хранения данных.
Программные средства и информационные технологии
THE METHODS OF STORING DATA IN ANDROID OS APPLICATIONS
Android is a popular mobile platform, which is used in many mobile devices, even in the car multimedia systems, in which an integral part is the presence of a navigation system using GLONASS and GPS satellites. To improve the navigation application it is required to store and use information about satellites (their number, position, etc.). The methods of storing data in android operating system applications are considered. Their characteristics are given and major cases of using depending on the types of data are shown.
Keywords: Android, database, methods of storing data.
Большинству приложений для Android требуется хранить те или иные данные, будь то данные о состоянии активности приложения или различные пользовательские настройки. Некоторым приложениям требуется хранить и оперировать достаточно большим объёмом информации в файлах и базах данных.
В операционной системе Android существует несколько способов хранения данных:
1. Shared Preferences.
2. Обычные файлы, используя внутреннюю или внешнюю память.
3. База данных SQLite.
Каждый из перечисленных способов имеет свои достоинства и недостатки, что обусловлено их предназначением.
Первый из рассматриваемых способов - Shared Preferences (общие настройки). Данный способ представляет собой хранение простых данных в виде «ключ-значение» в XML-файле, находящемся в поддиректории shared-prefs «приватной» папки приложения. Shared Preferences поддерживает базовые типы boolean, string, float, long, int и используется для быстрого сохранения значений по умолчанию, пользовательских настроек, переменных экземпляра класса, текущего состояния пользовательского интерфейса. Чаще всего используется для обеспечения постоянства данных между сессиями пользователя и не подходит для хранения множества однотипных структурированных данных.
Второй способ подходит для чтения и записи больших объёмов данных в порядке от начала к концу без пропусков. Этот способ оптимален для изображений, медиа и других файлов, передаваемых по сети [2]. Большинство Android устройств имеют две области хранения файлов: внутреннюю и внешнюю. Если ко внутреннему хранилищу относится встроенная память, то ко внешним могут относиться как карты памяти, USB-накопители, так и часть внутренней памяти, которая может быть поделена на внутренний и внешний разделы.
Хранение файлов во внутренней памяти лучше подходит для ситуаций, когда ни пользователь, ни другие приложения не должны иметь доступа к файлам вашего приложения. Внутренняя память всегда доступна. При удалении приложения Android удалит из внутренней памяти все его файлы.
Внешнее хранилище в отличие от внутренней памяти доступно не всегда, потому что пользователь может в любое время подключать и отключать такие хранилища. Такие хранилища доступны для чтения везде, поэтому вы не контролируете чтение сохраненных в них данных, из-за чего оно подходит для файлов без ограничений доступа и для файлов, которые вы хотите сделать доступными другим приложениям или пользователю через компьютер. При работе приложения с внешним хранилищем можно выделить две группы файлов:
1. Общедоступные файлы: доступны другим приложениям и пользователю, при удалении приложения должны оставаться доступными.
2. Личные файлы: принадлежат приложению и удаляются вместе с ним.
Для записи во внешнее хранилище нужен запрос на разрешение, в то время как для записи файлов на внутреннюю память разрешений не требуется, приложение всегда может читать и записывать файлы в свой каталог. Также при работе с внешним хранилищем следует проверять его доступность.
Третий способ хранения данных - это использование встраиваемой базы данных SQLite [3]. Данный способ идеально подходит для повторяющихся и сложных структурированных данных. SQLite в Android реализована в виде библиотеки на языке C, и каждая база данных считается частью приложения, которое её создало. Благодаря этому минимизируется число внешних зависимостей, уменьшаются задержки, упрощаются синхронизация и блокирование при выполнении транзакций [1]. Так как по умолчанию доступ к базе есть только у приложения, создавшего её, существует механизм, предоставляющий обмен данными. Источники данных предоставляют общий интерфейс, основанный на простой адресной модели URI для доступа к любой информации путём отделения логики приложения от слоя, отвечающего за хранение данных.
1. Майер Р. Android 2: программирование приложений для планшетных компьютеров и смартфонов : пер. с англ. М. : Эксмо, 2011. 672 с.
Решетневские чтения. 2015
1. Maier R. Professional Android 2 Application Development. Translate from English. М. : Eksmo, 2011. 672 p.
© Сидора А. А., 2015
РАЗРАБОТКА ПРИЛОЖЕНИЯ ДЛЯ УПРАВЛЕНИЯ МЕДИАКОНТЕНТОМ ИНФОРМАЦИОННЫХ РЕСУРСОВ ОБЩЕГО НАЗНАЧЕНИЯ
Представлена информационная система для автоматизации и планирования процесса распространения контента, связанного с ракетно-космической тематикой, в социальных сетях и блогах, а также для хранения контента.
Ключевые слова: информационная система, автоматизация, медиаконтент, социальные сети.
DEVELOPING APPLICATION FOR MEDIA CONTENT MANAGEMENT OF INFORMATION RESOURCES OF GENERAL PURPOSES
An information system to automate the process ofplanning and distribution of content is associated with the rocket-space theme in social networks and blogs, as well as content storage.
Keywords: information system, automation, media content, social networks.
В настоящее время на сайтах в Интернете содержится огромное количество информации, например, научные публикации, связанные с ракетно-космической тематикой. В последние годы особое место заняли веб-ресурсы, где у пользователей есть возможность объединяться по интересам и просматривать только интересующую их информацию. Например, к таким веб-сайтам относятся блоги и социальные сети. А для пользователей, заинтересованных в предоставлении такой информации, появилась возможность легально и незатратно загружать контент для дальнейшего его распространения. С ростом числа пользователей такой процесс превратился в серьёзное дело: на группу в социальной сети может быть подписаны тысячи пользователей, и администратору необходимо своевременно загружать новый контент. Тут администратор сталкивается с рядом процессов, которые можно было бы автоматизировать.
Продукт представляет собой мобильное приложение, которое позволяет автоматизировать процесс размещения содержимого в блоги и социальные сети.
Пользователь, зарегистрировавшись в системе, добавляет сайты, на которые будет происходить дальнейшее размещение контента. При этом он получает следующие преимущества по сравнению с обычной загрузкой:
- единый интерфейс: загрузка ведётся из одного центра;
- единое упорядоченное хранилище: содержимое, загружаемое пользователем, хранится в облаке;
- анализ статистических данных: пользователю доступна статистика, включающая в себя, когда, что и куда он загружал;
- автоматическая загрузка контента: пользователь может установить расписание, и загрузка будет происходить в автоматическом режиме;
- один раз настроив загрузку в установленное время, пользователь может повторять её для разного контента;
- загрузка одинакового контента в одно и то же время доступна сразу для нескольких сайтов.
Варианты использования программного продукта [1] представлены на рисунке.
Читайте также: